cuDNN vs 推理框架
内容
深度学习中计算加速库与推理框架有明确的定位差异。以下从技术架构角度解析两者的区别,并列举主流推理框架及其应用场景:
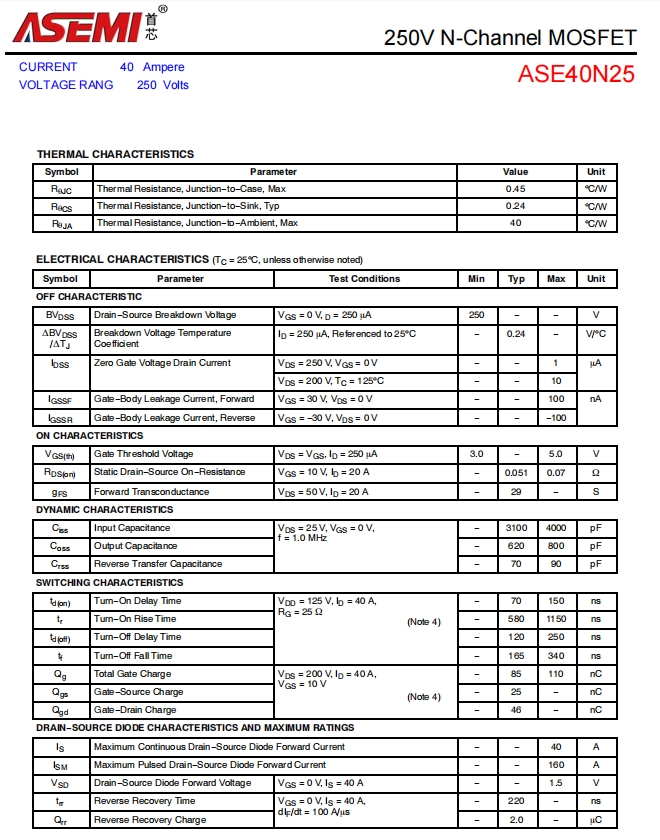
CUDA Deep Neural Network (cuDNN) 核心定位
| 属性 | 说明 |
|---|---|
| 层级 | GPU加速库(底层计算原语) |
| 主要场景 | 训练/推理阶段的算子加速(如卷积、LSTM、Softmax等) |
| 依赖关系 | 需配合深度学习框架(TensorFlow/PyTorch等)使用 |
| 硬件绑定 | 仅支持NVIDIA GPU |
| 典型优化 | Winograd算法加速卷积运算、FP16/INT8量化支持 |
推理框架核心能力
| 功能维度 | 关键技术 |
|---|---|
| 模型优化 | 图优化(算子融合/常量折叠)、量化(INT8/FP16)、剪枝 |
| 硬件适配 | 跨平台支持(CPU/GPU/TPU/NPU) |
| 运行时管理 | 内存复用、异步流水线、多线程调度 |
| 部署形态 | 支持Serverless、容器化、边缘设备(TinyML) |
| 生态集成 | ONNX标准兼容、多框架模型导入(TF/PyTorch/MXNet) |
主流推理框架对比
1. TensorRT (NVIDIA)
- 优势:极致GPU性能优化(层融合+张量核心利用)
- 场景:自动驾驶(Jetson系列)、云端推理服务
- 技术亮点:显式批处理(Explicit Batch)、动态形状支持
2. ONNX Runtime
- 优势:跨框架兼容性强(标准ONNX模型格式)
- 场景:多后端部署(CPU/GPU/移动端)
- 扩展性:支持自定义算子插件(CUDA/OpenCL)
3. OpenVINO (Intel)
- 优势:x86 CPU深度优化(AVX-512指令集)、集成OpenCV
- 硬件支持:Intel集成显卡/VPU(Movidius神经计算棒)
- 部署工具:Model Optimizer自动优化工具链
4. TensorFlow Lite
- 优势:移动端轻量化(Android/iOS原生支持)
- 量化技术:全整数量化(Full Integer Quantization)
- 硬件加速:NNAPI(Android GPU/DSP)、Core ML(iOS)
5. NCNN (Tencent)
- 优势:无第三方依赖的纯CPU推理(ARM架构优化)
- 场景:嵌入式设备(树莓派)、手机端轻量级模型
- 内存效率:动态内存复用机制(<1MB内存占用)
协同工作示例
# PyTorch训练 -> ONNX导出 -> TensorRT部署
import torch
import tensorrt as trt# 1. 训练模型
model = torch.nn.Linear(10, 2).cuda()# 2. 导出为ONNX
torch.onnx.export(model, torch.randn(1,10).cuda(), "model.onnx")# 3. TensorRT优化
trt_logger = trt.Logger(trt.Logger.WARNING)
builder = trt.Builder(trt_logger)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
parser = trt.OnnxParser(network, trt_logger)with open("model.onnx", "rb") as f:parser.parse(f.read())
engine = builder.build_serialized_network(network, builder.create_builder_config())
选型决策树
-
硬件平台:
- NVIDIA GPU → TensorRT
- Intel CPU/VPU → OpenVINO
- ARM边缘设备 → NCNN/TFLite
-
延迟敏感度:
- 超低延迟(<5ms) → TensorRT + FP16精度
- 中等延迟 → ONNX Runtime + CUDA EP
-
模型复杂度:
- 大模型(>1GB) → 服务端框架(TensorRT/OpenVINO)
- 小模型 → 端侧框架(TFLite/NCNN)
cuDNN作为底层加速库为各类框架提供基础算力支撑,而推理框架通过系统级优化实现端到端部署效率。开发者应根据硬件约束和业务需求选择技术栈组合。