Radeon GPU上使用ROCm一些技术点
1. 使用最新的高端AMD Radeon™7000系列GPU,将桌面变成机器学习平台
AMD已扩展了对RDNA™3 GPU上机器学习开发的支持,该GPU具有Radeon™软件,适用于Linux 24.10.3和ROCm™6.1.3!
使用PyTorch、ONNX运行时或TensorFlow的机器学习(ML)模型,开发人员可以在Linux®上使用ROCm 6.1.3,以利用最新高端AMD Radeon 7000系列台式机GPU的并行计算能力,并基于AMD RDNA 3 GPU架构。
基于强大的高端AMD GPU构建的客户端解决方案,可以实现本地、私有和经济高效的工作流程,为完全依赖云解决方案的用户开发ROCm和训练机器学习。
2. 为桌面提供更高的机器学习性能
当今的模型很容易超过非人工智能设计的标准硬件和软件的能力,机器学习工程师正在寻找经济高效的解决方案,开发和训练他们的机器学习驱动的应用程序。由于24GB或48GB的超大GPU内存的可用性,使用配备最新高端AMD Radeon 7000系列GPU的本地PC或工作站,提供了一种强大/有效但经济的选择,以应对这些不断扩大的ML工作流程挑战。
AMD Radeon 7000系列GPU基于RDNA 3 GPU架构构建,与上一代相比,每个计算单元(CU)的AI性能提高了2倍以上。配备了192个AI加速器,提供高达24GB或48GB的GPU内存来处理大型ML模型。
AMD ROCm6.1软件解决方案堆栈,如图2-12所示。
图2-12 AMD ROCm6.1软件解决方案堆栈
根据2022年11月AMD的内部测量结果,将Radeon RX 7900 XTX在2.505 GHz升压时钟下,与96个CU在每个时钟下发出2倍的Bfloat16数学运算进行比较,而Radeon RX 6900 XT GPU在2.25 GHz升压时钟上,与80个CU在每个时钟下发出1倍的B浮点16数学运算。结果可能会有所不同。
3. 将应用程序从桌面迁移到数据中心
ROCm是用于图形处理单元(GPU)编程的开源软件栈。ROCm涵盖了多个领域:GPU上的通用计算(GPGPU)、高性能计算(HPC)和异构计算。
AMD ROCm 6.1.3 GPU编程软件栈,释放了这些RDNA 3 GPU的大规模并行计算能力,可用于各种ML框架。同一软件栈还支持AMD CDNA™GPU架构,因此开发人员可以将应用程序从首选框架迁移到数据中心。
4. 自由定制
ROCm主要是开源软件(OSS),它允许开发人员自由地根据自己的需求定制和定制GPU软件,同时与其他开发人员社区合作,以敏捷、灵活、快速和安全的方式帮助彼此找到解决方案。AMD ROCm允许用户最大限度地提高GPU硬件投资。ROCm旨在帮助在自由、开源、集成和安全的软件生态系统中开发、测试和部署GPU加速的HPC、AI、科学计算、CAD和其他应用程序。计算
5. 提高互操作性
提高互操作性,包括以下几种。
1)支持PyTorch,领先的机器学习框架之一。
2)支持ONNX运行时对更广泛的源数据进行推理,包括使用MIGraphX的INT8。
3)支持TensorFlow。
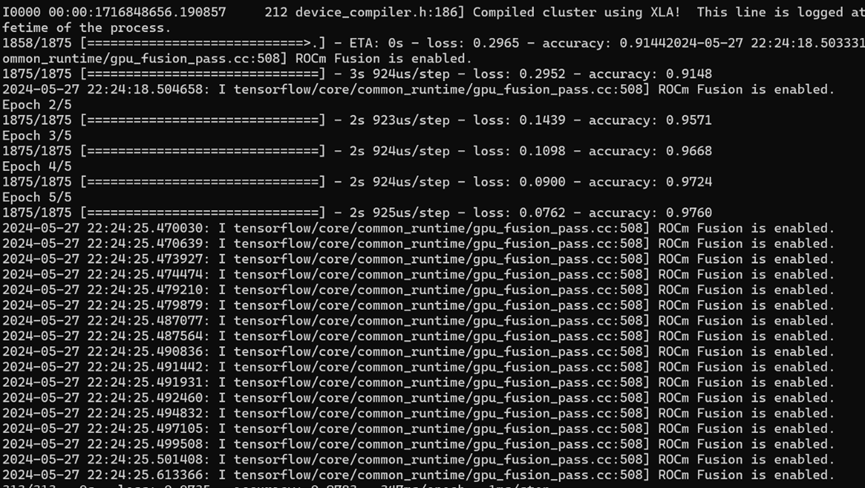
如果成功,应该看到输出,表明图像分类器现在已在此数据集上训练到约98%的准确率,如图2-13所示。
图2-13 图像分类器在数据集上训练到约98%的准确率
环境设置已完成,系统已准备好与TensorFlow一起使用,以处理机器学习模型和算法。
6. Linux兼容性
7. ROCm 6.1.3
最新ROCm版本的兼容操作系统、GPU和框架支持矩阵。
要回滚以前版本的支持列表和安装说明,单击屏幕右上角的版本列表,或选择左下角的版本(v:)菜单。
8. 操作系统支持矩阵
操作系统内核支持信息,见表2-8。
表2-8 操作系统内核支持信息
|
操作系统
|
内核
|
支持
|
|
Ubuntu® 22.04.4带HWE的桌面版本
带硬件的Ubuntu®22.04.4桌面版,
|
Ubuntu内核6.5
|
是
|
9. 框架+ROCm支持矩阵
查看PyTorch、ONNX和TensorFlow框架的ROCm支持矩阵。
10. PyTorch+ROCm支持矩阵
PyTorch版本、ROCm版本说明信息,见表2-9。
表2-9 PyTorch版本、ROCm版本说明信息
|
PyTorch版本
|
ROCm版本
|
说明
|
|
2.1.2
|
6.1.3
|
官方生产支持。可从AMD.com获取
|
|
2.5+/Nightly
|
6.1
|
可从PyTorch.org获取夜间构建版本,未经AMD广泛测试
|
|
2.3/Stable
|
6.0
|
Radeon 7000系列不支持
|
11. AI数据操作(PyTorch)[n3] 精度
AI数据操作(PyTorch)支持多种精度,例如:
1)FP32
2)FP16
3)混合精度 (FP32/FP16)
4)INT8
12. ONNX + ROCm支持矩阵
ONNX版本、ROCm版本说明信息,见表2-10。
表2-10 ONNX版本、ROCm版本说明信息
|
ONNX版本
|
ROCm版本
|
说明
|
|
1.17
|
6.1.3
|
官方生产支持。可从AMD.com获取。
|
AI数据操作(ONNX)支持多种精度,例如:
1)FP32
2)FP16
3)INT8 (MIGraphX)
4)混合精度 (FP32/FP16)
14. TensorFlow+ROCm支持矩阵
Tensorflow版本、ROCm版本说明信息,见表2-11。
表2-11 Tensorflow版本、ROCm版本说明信息
|
TensorFlow版本
|
ROCm版本
|
说明
|
|
2.15
|
6.1.3
|
官方生产支持。可从AMD.com获取。
|
15. AI数据操作(TensoFlow)精度
AI数据操作(TensorFlow)支持多种精度,例如:
1)FP32
2)FP16
2.8.2 ROCm兼容矩阵(WSL)
1. ROCm 6.1.3
提供有关ROCm™组件、Radeon™GPU和适用于Windows Linux的Radeon软件®子系统(WSL)兼容性的信息。
1. GPU支持矩阵
AMD ROCm支持的操作系统与硬件信息,见表2-12。
表2-12 AMD ROCm支持的操作系统与硬件信息
|
ROCm版本
|
适用于Linux®版本的Radeon™软件
|
适用于Windows版本的Radeon™软件
|
支持的AMD Radeon™硬件
|
|
6.1.3
|
24.10.3
|
AMD软件:适用于WSL 2的Adrenalin Edition™24.6.1
|
AMD Radeon RX 7900 XTX
AMD Radeon RX 7900 XT
AMD Radeon RX 7900 GRE
AMD Radeon PRO W7900
AMD Radeon PRO W7900DS
AMD Radeon PRO W7800 |
2. 框架+ROCm支持矩阵
查看PyTorch的ROCm支持矩阵。
PyTorch+ROCm支持矩阵
AMD ROCm支持的操作系统与硬件信息,见表2-12。
表2-12 AMD ROCm支持的操作系统与硬件信息
|
PyTorch版本 |
ROCm版本 |
说明 |
|
2.1.2 |
6.1.3 |
官方生产支持。可从AMD.com获取。 |
|
2.5+/Nightly |
6.1 |
可从PyTorch.org获取夜间版本,未经AMD广泛测试。 |
|
2.3/Stable |
6.0 |
Radeon 7000系列不支持。 |
3. 局限性
Radeon™PRO系列图形卡不是为数据中心使用而设计的,也不建议使用GD-239。在数据中心设置中使用可能会对可管理性、效率、可靠性和/或性能产生不利影响。
ROCm在任何移动SKU上都不受官方支持。
4. 多GPU配置
在Windows
Linux子系统(WSL)
[n7] [8] 环境中的ROCm中,由于此时对Radeon™WSL配置上的ROCm™验证有限,因此确定了常见错误和适用建议。
ROCm 6.1.3版本仅限于对WSL配置的预览支持。[1]
5. ROCm smi支持
由于WSL架构对原生Linux用户内核界面(UKI)的限制,不支持rocm-smi,见表2-13。
表2-13 WSL架构对原生Linux用户内核界面(UKI)的限制,不支持rocm-smi[n2] [3]
|
由于WSL架构对原生Linux用户内核界面(UKI)的限制,不支持rocm-smi
|
|
问题
|
局限性
|
|
UKI目前不支持rocm-smi
|
目前不支持:
1)主动计算进程
2)GPU利用率
3)可修改的状态特征
|
6. 在虚拟环境中运行PyTorch
在虚拟环境中运行PyTorch,需要手动libhsa-runtime64.so更新。
当使用WSL用例和hsa-runtime-rocr4wsl-amdgpu包(与PyTorch轮子一起安装)时,用户需要更新到WSL兼容的运行库。
7. 解决方案
输入以下命令:
location=`pip show torch | grep Location | awk -F ": " '{print $2}'`
cd ${location}/torch/lib/
rm libhsa-runtime64.so*
cp /opt/rocm/lib/libhsa-runtime64.so.1.2 libhsa-runtime64.so