从https://pic.netbian.com/4kfengjing/网站爬取图片,并保存 def get_htmls ( pages= list ( range ( 2 , 5 ) ) ) : """获取待爬取网页""" pages_list = [ ] for page in pages: url = f"https://pic.netbian.com/4kfengjing/index_ { page} .html" = requests. get( url) response. encoding = 'gbk' pages_list. append( response. text) return pages_list
get_htmls( pages= list ( range ( 2 , 5 ) ) )
def get_picturs ( htmls) : """获取所有图片,并下载""" for html in htmls: soup = BeautifulSoup( html, 'html.parser' ) pic_li = soup. find( 'div' , id = 'main' ) . find( 'div' , class_= 'slist' ) . find( 'ul' , class_= 'clearfix' ) image_path = pic_li. find_all( 'img' ) for file in image_path: pic_name = './practice05/' + file [ 'alt' ] . replace( " " , '_' ) + '.jpg' src = file [ 'src' ] src = f"https://pic.netbian.com/ { src} " = requests. get( src) with open ( pic_name, 'wb' ) as f: f. write( response. content) print ( "图片已下载并保存为:{}" . format ( pic_name) ) htmls = get_htmls( pages= list ( range ( 2 , 5 ) ) )
get_picturs( htmls)
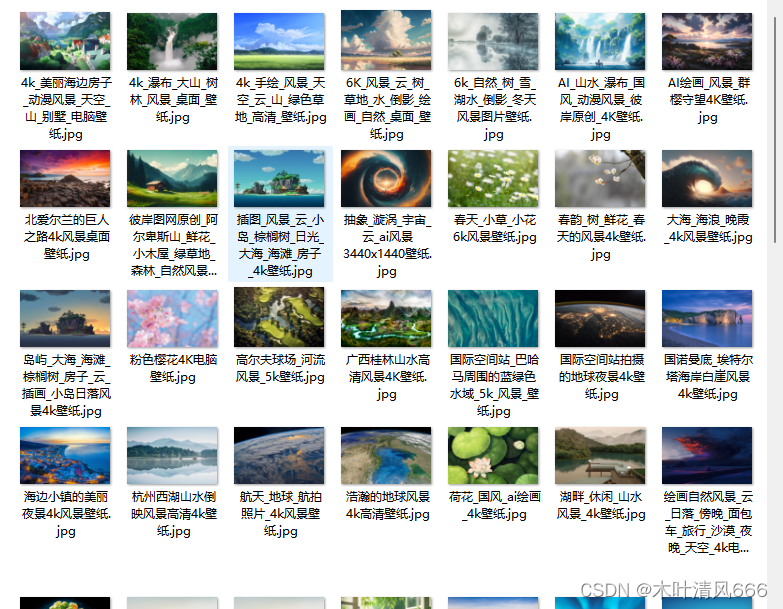
爬取结果展示