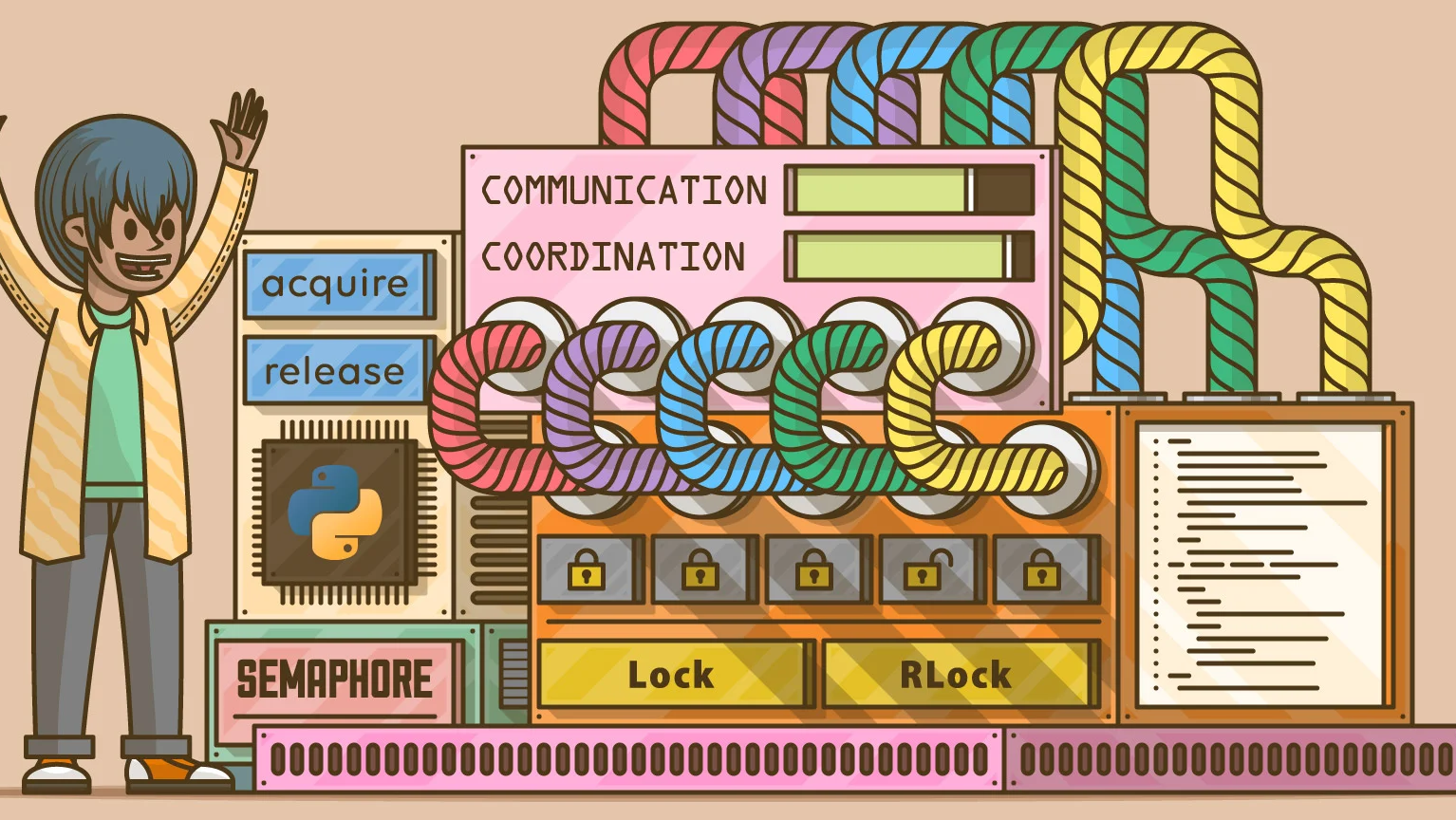
 在 Python 多线程编程中,线程同步是确保多个线程安全访问共享资源的关键技术。本篇文章介绍了互斥锁(Lock)、递归锁(RLock) 和 信号量(Semaphore) 的概念与应用。互斥锁用于防止多个线程同时修改数据,递归锁适用于嵌套锁定场景,而信号量则限制同时访问资源的线程数。
在 Python 多线程编程中,线程同步是确保多个线程安全访问共享资源的关键技术。本篇文章介绍了互斥锁(Lock)、递归锁(RLock) 和 信号量(Semaphore) 的概念与应用。互斥锁用于防止多个线程同时修改数据,递归锁适用于嵌套锁定场景,而信号量则限制同时访问资源的线程数。一文速通 Python 并行计算:03 Python 多线程编程-多线程同步(上)—基于互斥锁、递归锁和信号量
摘要:
在 Python 多线程编程中,线程同步是确保多个线程安全访问共享资源的关键技术。本篇文章介绍了互斥锁(Lock)、递归锁(RLock) 和 信号量(Semaphore) 的概念与应用。互斥锁用于防止多个线程同时修改数据,递归锁适用于嵌套锁定场景,而信号量则限制同时访问资源的线程数。

关于我们更多介绍可以查看云文档: Freak 嵌入式工作室云文档 ,或者访问我们的 wiki: https://github.com/leezisheng/Doc/wik
原文链接:
FreakStudio的博客
往期推荐:
学嵌入式的你,还不会面向对象??!
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与“file-like object“
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
全网最适合入门的面向对象编程教程:53 Python字符串与序列化-字符串与字符编码
全网最适合入门的面向对象编程教程:54 Python字符串与序列化-字符串格式化与format方法
全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
全网最适合入门的面向对象编程教程:56 Python字符串与序列化-正则表达式和re模块应用
全网最适合入门的面向对象编程教程:57 Python字符串与序列化-序列化与反序列化
全网最适合入门的面向对象编程教程:58 Python字符串与序列化-序列化Web对象的定义与实现
全网最适合入门的面向对象编程教程:59 Python并行与并发-并行与并发和线程与进程
一文速通Python并行计算:00 并行计算的基本概念
一文速通Python并行计算:01 Python多线程编程-基本概念、切换流程、GIL锁机制和生产者与消费者模型
一文速通Python并行计算:02 Python多线程编程-threading模块、线程的创建和查询与守护线程
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一文搞懂 CM3 单片机调试原理
肝了半个月,嵌入式技术栈大汇总出炉
电子计算机类比赛的“武林秘籍”
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
Avnet ZUBoard 1CG开发板—深度学习新选择
工程师不要迷信开源代码,还要注重基本功
什么?配色个性化的电机驱动模块?!!
什么?XIAO主控新出三款扩展板!
手把手教你实现Arduino发布第三方库
万字长文手把手教你实现MicroPython/Python发布第三方库
文档获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc
该文档是一份关于 并行计算 和 Python 并发编程 的学习指南,内容涵盖了并行计算的基本概念、Python 多线程编程、多进程编程以及协程编程的核心知识点:
正文
1.线程同步的基本概念
在 Python 多线程编程中,线程同步(Thread Synchronization)是确保多个线程安全地访问共享资源的机制,在多线程环境下,如果多个线程同时访问和修改共享资源,可能会导致 数据竞争(Race Condition) 和 数据不一致性(Data Inconsistency) 问题。例如:
import threading# 共享变量
counter = 0def increment():global counterfor _ in range(1000000):counter += 1# 创建两个线程
t1 = threading.Thread(target=increment)
t2 = threading.Thread(target=increment)# 启动线程
t1.start()
t2.start()# 等待线程执行完毕
t1.join()
t2.join()# 预期是 2000000,但可能小于这个值
print("Final Counter:", counter)
由于 counter += 1 并不是原子操作,而是 读取 -> 计算 -> 写入 三步操作,因此两个线程可能同时读取 counter,导致写入时丢失部分数据,最终的结果可能小于 2000000,这就是 竞争条件(Race Condition)。
再举一个实例,下面的代码我们了跑 200 个线程,但是这 200 个线程都会去访问 counter 这个公共资源,并对该资源进行处理(counter += 1),我们看下运行结果:
import threading
import timecounter = 0class MyThread(threading.Thread):def __init__(self):threading.Thread.__init__(self)def run(self):global countertime.sleep(1);counter += 1print("I am %s, set counter:%s" % (self.name, counter))if __name__ == "__main__":for i in range(0, 200):my_thread = MyThread()my_thread.start()
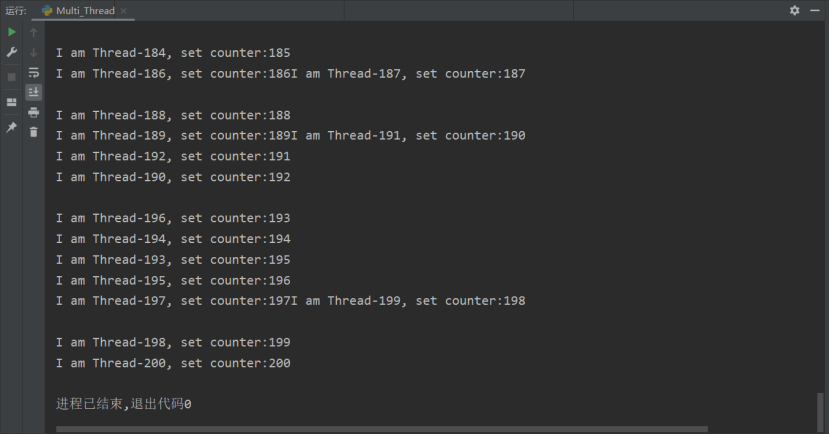
从中我们已经看出了这个全局资源(counter)被抢占的情况,问题产生的原因就是没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预期。这种现象称为“线程不安全”。在开发过程中我们必须要避免这种情况。
2.基于互斥锁的线程数据同步
“线程不安全”最简单的解决方法是使用锁。锁的操作非常简单,当一个线程需要访问部分共享内存时,它必须先获得锁才能访问。此线程对这部分共享资源使用完成之后,该线程必须释放锁,然后其他线程就可以拿到这个锁并访问这部分资源了。
在 Python 中我们使用 threading 模块提供的 Lock 类来实现互斥锁的机制。我们对上面的程序进行整改,为此我们需要添加一个锁变量 mutex`` = threading.Lock(),然后在争夺资源的时候之前我们会先抢占这把锁 mutex``.acquire``(),对资源使用完成之后我们在释放这把锁 mutex``.release``()。
代码如下:
import threading
import timecounter = 0
mutex = threading.Lock()class MyThread(threading.Thread):def __init__(self):threading.Thread.__init__(self)def run(self):global counter, mutextime.sleep(1);if mutex.acquire():counter += 1print("I am %s, set counter:%s" % (self.name, counter))mutex.release()if __name__ == "__main__":for i in range(0, 100):my_thread = MyThread()my_thread.start()
下图为输出,可以看到 counter 变量不断递增,全局资源(counter)被抢占的情况得到解决。主要过程为:当一个线程调用 Lock 对象的 acquire() 方法获得锁时,这把锁就进入 “locked” 状态。因为每次只有一个线程 1 可以获得锁,所以如果此时另一个线程 2 试图获得这个锁,该线程 2 就会变为 “block“ 同步阻塞状态。直到拥有锁的线程 1 调用锁的 release() 方法释放锁之后,该锁进入 “unlocked” 状态。线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
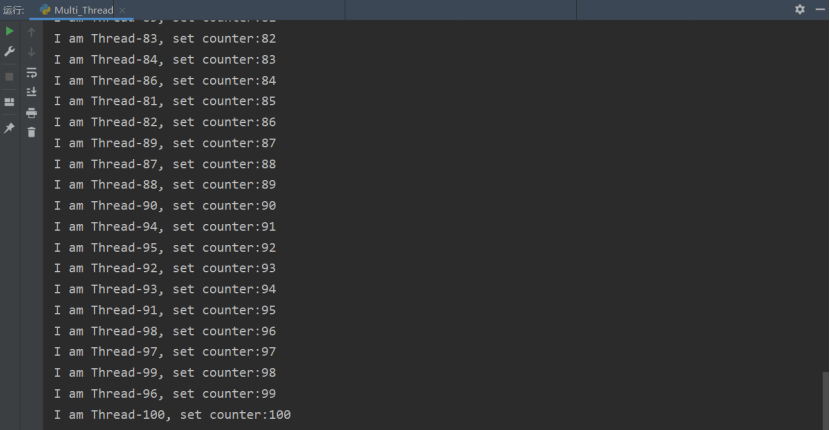
然而,在实际使用的过程中,我们发现这个方法经常会导致一种糟糕的死锁现象。当不同的线程要求得到一个锁时,死锁就会发生,这时程序不可能继续执行,因为它们互相拿着对方需要的锁。
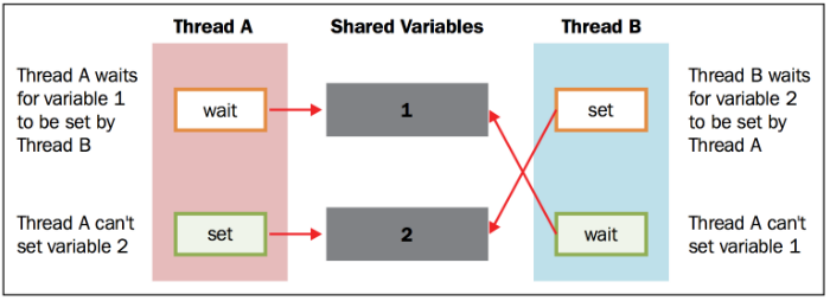
为了简化问题,我们设有两个并发的线程( 线程 A 和 线程 B ),需要 资源 1 和 资源 2 .假设 线程 A 需要 资源 1 , 线程 B 需要 资源 2 .在这种情况下,两个线程都使用各自的锁,目前为止没有冲突。现在假设,在双方释放锁之前, 线程 A 需要 资源 2 的锁, 线程 B 需要 资源 1 的锁,没有资源线程不会继续执行。鉴于目前两个资源的锁都是被占用的,而且在对方的锁释放之前都处于等待且不释放锁的状态。这是死锁的典型情况。
我们来看如下代码:
import threadingcounterA = 0
counterB = 0mutexA = threading.Lock()
mutexB = threading.Lock()class MyThread(threading.Thread):def __init__(self):threading.Thread.__init__(self)def run(self):self.fun1()self.fun2()def fun1(self):global mutexA, mutexBif mutexA.acquire():print("I am %s , get res: %s" % (self.name, "ResA"))if mutexB.acquire():print("I am %s , get res: %s" % (self.name, "ResB"))mutexB.release()mutexA.release()def fun2(self):global mutexA, mutexBif mutexB.acquire():print("I am %s , get res: %s" % (self.name, "ResB"))if mutexA.acquire():print("I am %s , get res: %s" % (self.name, "ResA"))mutexA.release()mutexB.release()if __name__ == "__main__":for i in range(0, 100):my_thread = MyThread()my_thread.start()
代码中展示了一个线程的两个功能函数分别在获取了一个竞争资源之后再次获取另外的竞争资源,我们看运行结果:
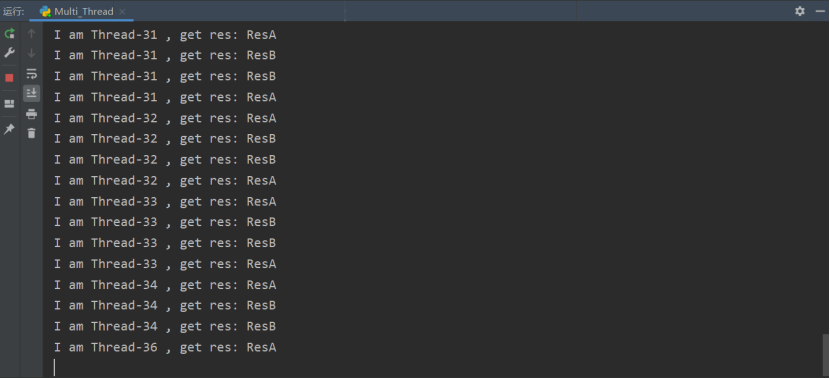
可以看到,程序已经挂起在那儿了,这种现象我们就称之为”死锁“。避免死锁主要方法就是:正确有序的分配资源,避免死锁算法中最有代表性的算法是 Dijkstra E.W 于 1968 年提出的银行家算法。
3.基于递归锁的线程数据同步
考虑这种情况:如果一个线程遇到锁嵌套的情况该怎么办,这个嵌套是指当我一个线程在获取临界资源时,又需要再次获取。代码如下:
import threading
import timecounter = 0
mutex = threading.Lock()class MyThread(threading.Thread):def __init__(self):threading.Thread.__init__(self)def run(self):global counter, mutextime.sleep(1);if mutex.acquire():counter += 1print("I am %s, set counter:%s" % (self.name, counter))if mutex.acquire():counter += 1print("I am %s, set counter:%s" % (self.name, counter))mutex.release()mutex.release()
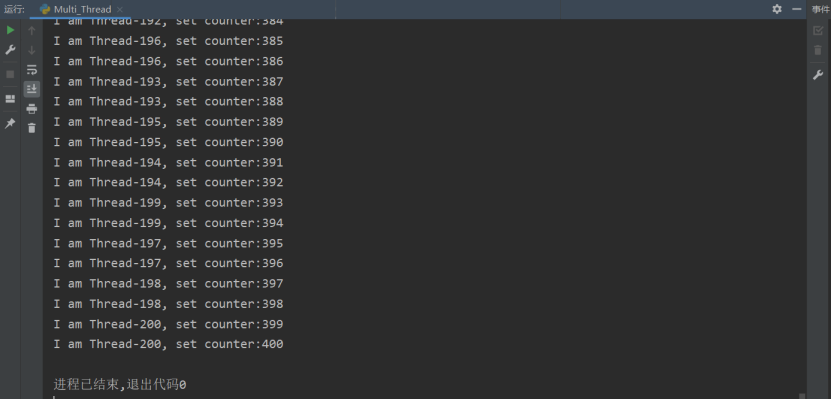
if __name__ == "__main__":for i in range(0, 200):my_thread = MyThread()my_thread.start()
这种情况的代码运行情况如下,可以看到线程获取一次互斥锁后,需要再次使用临界变量 counter,于是再次尝试获取互斥锁:

之后就直接挂起了,这种情况形成了最简单的死锁。
那有没有一种情况可以在某一个线程使用互斥锁访问某一个竞争资源时,可以再次获取呢?在 Python 中为了支持在同一线程中多次请求同一资源,python 提供了“可重入锁”:threading.RLock。这个 RLock 内部维护着一个 Lock 和一个 counter 变量,counter 记录了 acquire 的次数,从而使得资源可以被多次 require。直到一个线程所有的 acquire 都被 release,其他的线程才能获得资源。上面的例子如果使用 RLock 代替 Lock,则不会发生死锁:
代码只需将上述的:
mutex = threading.Lock()
替换成:
mutex = threading.RLock()
这种锁对比 Lock 有是三个特点:
- 谁拿到谁释放。如果线程 A 拿到锁,线程 B 无法释放这个锁,只有 A 可以释放;
- 同一线程可以多次拿到该锁,即可以
acquire多次; acquire多少次就必须release多少次,只有最后一次release才能改变RLock的状态为unlocked。
嵌套锁也有缺点,它给我们的锁检测带来了麻烦。
4.基于信号量的线程数据同步
信号量由 E.Dijkstra 发明并第一次应用在操作系统中,信号量是由操作系统管理的一种抽象数据类型,用于在多线程中同步对共享资源的使用。本质上说,信号量是一个内部数据,用于标明当前的共享资源可以有多少并发读取。
同样的,在 threading 模块中,信号量的操作有两个函数 acquire() 和 release() ,解释如下:
(1)每当线程想要读取关联了信号量的共享资源时,必须调用 acquire() ,此操作减少信号量的内部变量, 如果此变量的值非负,那么分配该资源的权限。如果是负值,那么线程被挂起,直到有其他的线程释放资源;
(2)当线程不再需要该共享资源,必须通过 release() 释放。这样,信号量的内部变量增加,在信号量等待队列中排在最前面的线程会拿到共享资源的权限。
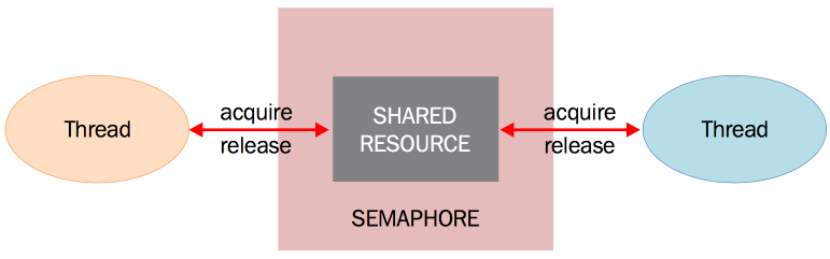
一般说来,为了获得共享资源,线程需要执行下列操作:
- 测试控制该资源的信号量。
- 若此信号量的值为正,则允许进行使用该资源。线程将信号量减 1。
- 若此信号量为 0,则该资源目前不可用,线程进入睡眠状态,直至信号量值大于 0,进程被唤醒,转入步骤 1。
- 当线程不再使用一个信号量控制的资源时,信号量值加 1。如果此时有线程正在睡眠等待此信号量,则唤醒此线程。
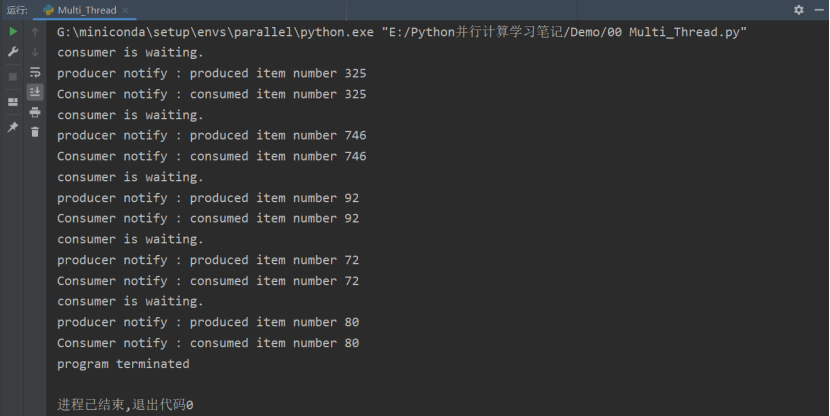
在以下的代码中,我们使用生产者-消费者模型展示通过信号量的同步。我们有两个线程, producer() 和 consumer(),它们使用共同的资源 item。 producer() 的任务是生产 item,consumer() 的任务是消费 item。当 item 还没有被生产出来,consumer() 一直等待,当 item 生产出来, producer() 线程通知消费者资源可以使用了。
import threading
import time
import random_# 通过将信号量初始化为0,我们得到一个所谓的信号量事件_
_# Semaphore可选参数给出内部变量的初始值,默认为1。_
_# 如果给定的值小于0,则抛出ValueError。_
semaphore = threading.Semaphore(0)def consumer():print("consumer is waiting.")if semaphore.acquire():_# 如果消费者获取到信号量,即信号量大于0_print("Consumer notify : consumed item number %s " % item)_# 如果消费者没有获取到信号量,即信号量等于0,此时消费者线程阻塞_def producer():global itemtime.sleep(1)item = random.randint(0, 1000)print("producer notify : produced item number %s" % item)_# 释放信号量,通知消费者线程_semaphore.release()if __name__ == '__main__':for i in range (0,5):t1 = threading.Thread(target=producer)t2 = threading.Thread(target=consumer)t1.start()t2.start()t1.join()t2.join()print("program terminated")
看一下代码运行结果:
信号量的一个特殊用法是互斥量。互斥量是初始值为 1 的信号量,可以实现数据、资源的互斥访问。信号量在支持多线程的编程语言中依然应用很广,然而这可能导致死锁的情况。
threading.BoundedSemaphore 用于实现有界信号量。有界信号量通过检查以确保它当前的值不会超过初始值。如果超过了初始值,将会引发 ValueError 异常。在大多情况下,信号量用于保护数量有限的资源。如果信号量被释放的次数过多,则表明出现了错误。没有指定时, value 的值默认为 1。