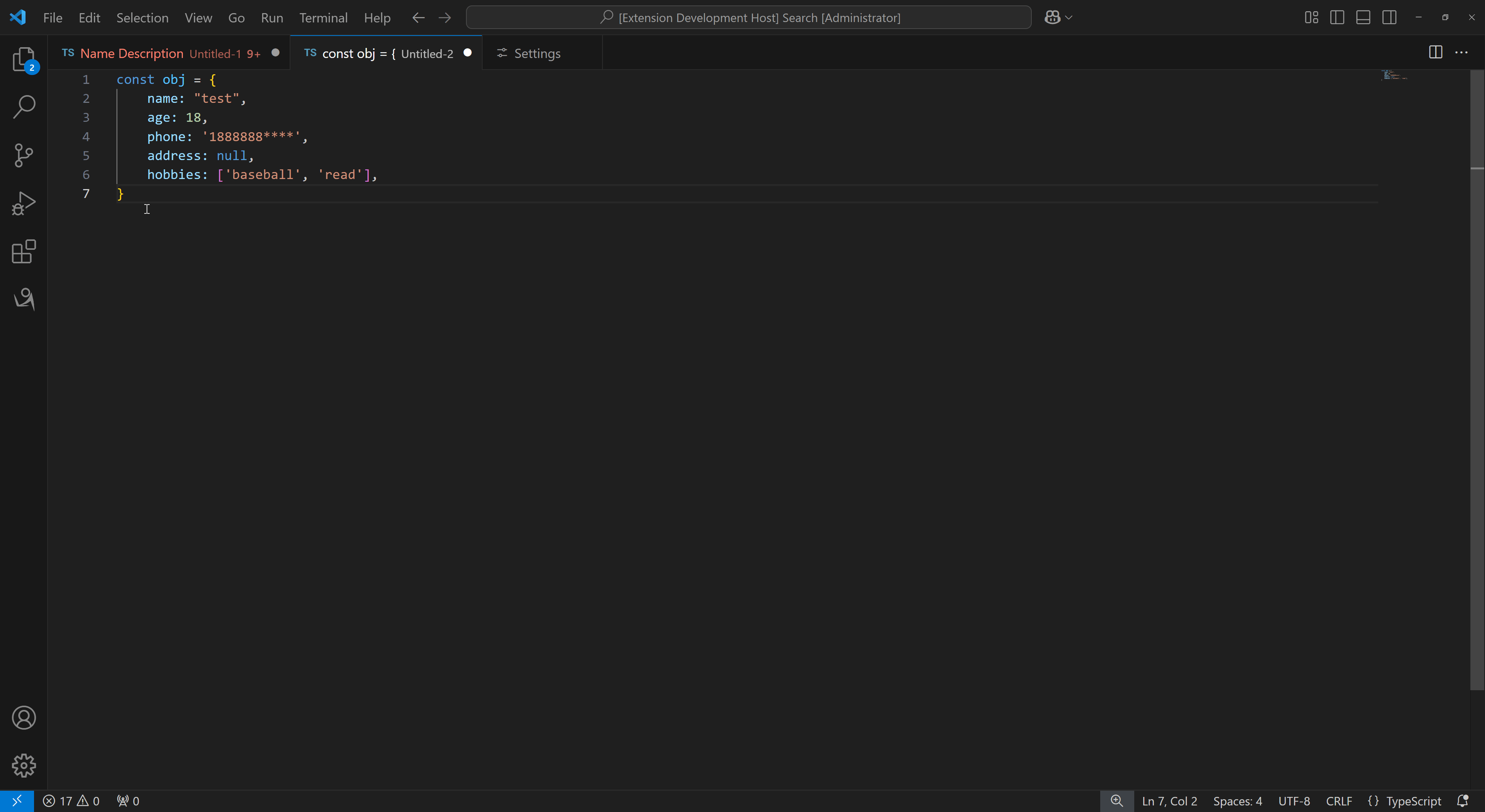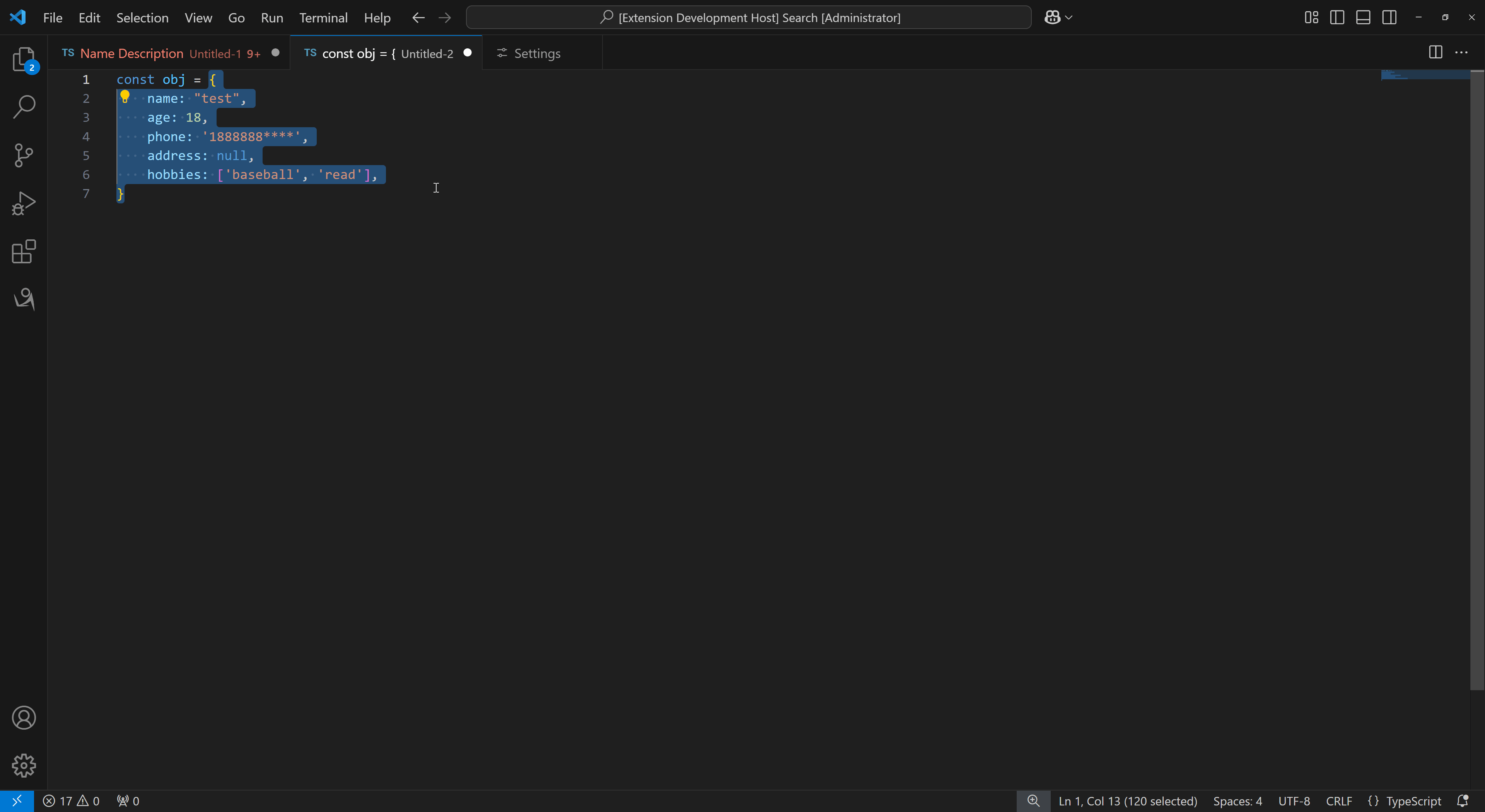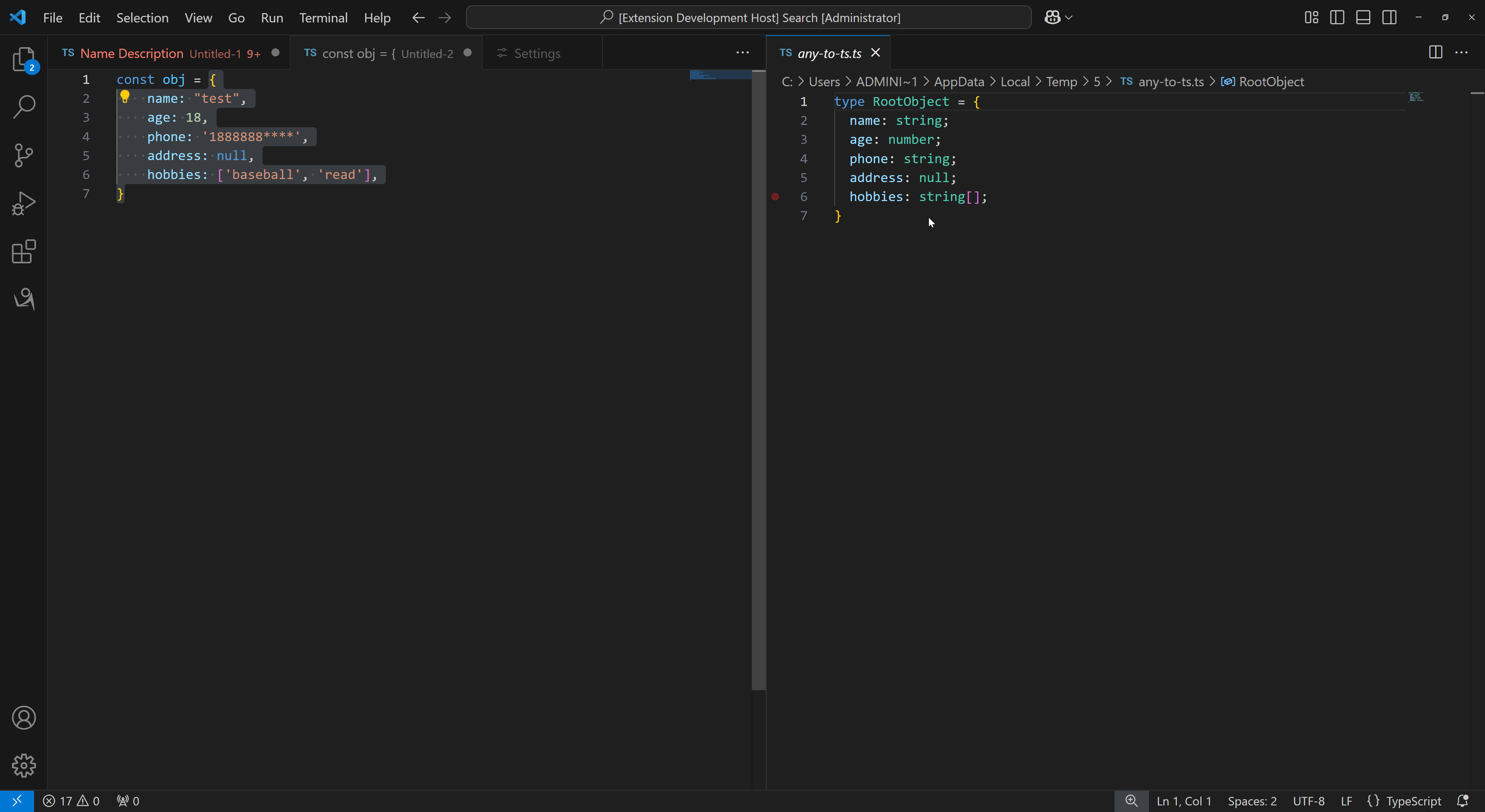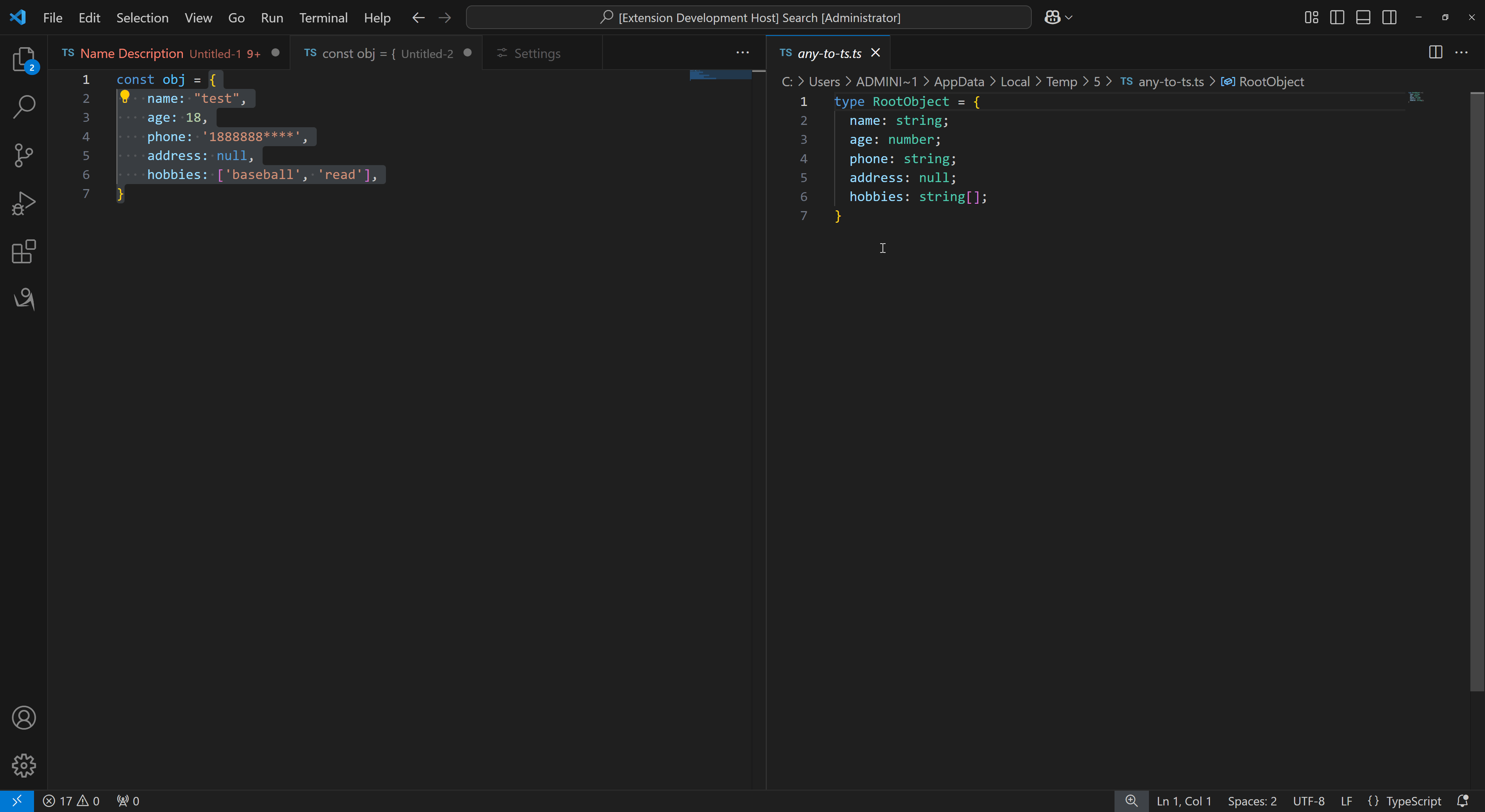
Hive中的基本操作
创建 (Create)
- 使用
CREATE TABLE语句创建新表。 - 示例:
CREATE TABLE table_name (column1 datatype,column2 datatype,... ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
Hive支持的五种存储类型
Hive支持以下五种主要的存储类型:
- 托管表 (Managed Tables): Hive同时管理元数据和数据。
- 外部表 (External Tables): Hive仅管理元数据,数据存储在外部位置。
- 分区表 (Partitioned Tables): 表被划分为多个分区,以提高查询性能。
- 分桶表 (Bucketed Tables): 表被划分为多个桶,以便高效的采样和连接操作。
- ACID表 (ACID Tables): 支持事务操作(插入、更新、删除)的表,具有ACID属性。
创建分区和分桶表 (Partition and Bucket Table)
分区和分桶的意义
- 分区: 将数据按分区列的值存储在不同的目录中,适合按分区列查询数据,减少扫描的数据量,从而提高查询效率。
- 分桶: 将数据按桶列的哈希值分布到不同的桶中,适合优化采样和连接操作,进一步提升查询性能。
- 组合使用: 分区和分桶结合使用可以在大数据集上实现更高效的存储和查询。
创建分区表
- 使用
PARTITIONED BY语句创建分区表。 - 示例:
CREATE TABLE partitioned_table (column1 datatype,column2 datatype ) PARTITIONED BY (partition_column datatype) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
创建分桶表
- 使用
CLUSTERED BY语句创建分桶表,并指定桶的数量。 - 示例:
CREATE TABLE bucketed_table (column1 datatype,column2 datatype ) CLUSTERED BY (bucket_column) INTO number_of_buckets BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
创建分区和分桶表
- 可以同时使用
PARTITIONED BY和CLUSTERED BY创建分区和分桶表。 - 示例:
CREATE TABLE partitioned_bucketed_table (column1 datatype,column2 datatype ) PARTITIONED BY (partition_column datatype) CLUSTERED BY (bucket_column) INTO number_of_buckets BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
注意事项
- 分区表将数据按分区列的值存储在不同的目录中,适合按分区列查询数据。
- 分桶表将数据按桶列的哈希值分布到不同的桶中,适合提高查询性能。
- 分区和分桶的选择应根据数据规模和查询模式进行权衡。
- 使用
SET hive.enforce.bucketing=true;和SET hive.enforce.partition=true;确保插入数据时强制执行分桶和分区规则。
读取 (Read)
- 使用
SELECT语句从表中查询数据。 - 示例:
SELECT column1, column2 FROM table_name WHERE condition;
更新 (Update)
- Hive 不支持直接的
UPDATE语句。可以通过以下方式实现:- 创建一个包含更新数据的新表。
- 使用
INSERT OVERWRITE替换旧表为新表。
删除 (Delete)
- Hive 不支持直接的
DELETE语句。可以通过以下方式实现:- 使用
INSERT OVERWRITE将表覆盖为所需数据,排除需要删除的行。 - 示例:
INSERT OVERWRITE TABLE table_name SELECT * FROM table_name WHERE condition_to_keep_rows;
- 使用
注意事项
- Hive 设计用于批处理,不适合行级更新或删除操作。
- 使用分区和分桶优化大数据集的性能。
- 考虑使用 ACID 表以支持事务操作。
修改表 (Alter Table)
删除所有数据
- 使用
TRUNCATE TABLE语句删除表中的所有行,但不删除表本身。 - 示例:
TRUNCATE TABLE table_name;
更改表字符集
- Hive 不直接支持更改表的字符集。但可以通过以下步骤实现:
- 创建一个具有所需字符集设置的新表。
- 将旧表中的数据插入到新表中。
- 如果需要,可以删除旧表。
重命名表
- 使用
ALTER TABLE ... RENAME TO语句重命名表。 - 示例:
ALTER TABLE old_table_name RENAME TO new_table_name;
添加/替换列
- 使用
ALTER TABLE ... ADD COLUMNS或REPLACE COLUMNS语句修改表结构。 - 示例(添加列):
ALTER TABLE table_name ADD COLUMNS (new_column1 datatype, new_column2 datatype); - 示例(替换列):
ALTER TABLE table_name REPLACE COLUMNS (column1 datatype, column2 datatype, ...);
更改表属性
- 使用
ALTER TABLE ... SET TBLPROPERTIES语句修改表属性。 - 示例:
ALTER TABLE table_name SET TBLPROPERTIES ('property_name'='property_value');
常见的Hive表属性
以下是一些常见的Hive表属性及其用途:
-
EXTERNAL- 指定表是外部表。
- 示例:
CREATE EXTERNAL TABLE table_name (...);
-
STORED AS- 指定表的数据存储格式。
- 常见格式包括:
TEXTFILE,SEQUENCEFILE,ORC,PARQUET,AVRO。 - 示例:
STORED AS PARQUET;
-
LOCATION- 指定表数据存储的HDFS路径(通常用于外部表)。
- 示例:
LOCATION '/path/to/data';
-
TBLPROPERTIES- 设置表的自定义属性。
- 示例:
TBLPROPERTIES ('property_name'='property_value');
-
ROW FORMAT- 定义表的行格式。
- 示例:
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-
PARTITIONED BY- 定义分区列。
- 示例:
PARTITIONED BY (partition_column datatype);
-
CLUSTERED BY- 定义分桶列及桶的数量。
- 示例:
CLUSTERED BY (bucket_column) INTO number_of_buckets BUCKETS;
-
COMMENT- 为表或列添加注释。
- 示例:
COMMENT 'This is a sample table';
-
SERDE- 指定表的序列化和反序列化库。
- 示例:
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde';
-
COMPRESSION
- 指定表的压缩格式(通常与存储格式结合使用)。
- 示例:
sql STORED AS ORC TBLPROPERTIES ('orc.compress'='SNAPPY');
截断表
- 使用
TRUNCATE TABLE语句删除表中的所有行,但不删除表本身。 - 示例:
TRUNCATE TABLE table_name; - 如果表是分区表,可以截断特定分区:
TRUNCATE TABLE table_name PARTITION (partition_column='value');- 注意:确保表不是外部表,因为
TRUNCATE TABLE不适用于外部表。
- 注意:确保表不是外部表,因为