一、Java基础语法
1.1 环境搭建与开发
1、JDK、JRE、JVM的关系和区别?(高频plus)
- JDK:Java Development Kit,Java开发工具包,包含了JRE和一系列Java开发工具。
- JRE:Java Runtime Environment,Java程序的运行环境,包含JVM、Java核心类库等。JRE只能用来运行Java应用程序,不能用于开发编译,它是JDK的子集。
- JVM:Java Virtual Machine,Java虚拟机。Java程序必须运行在JVM中。
2、Oracle JDK 和 Open JDK 有啥区别?
OracleJDK由甲骨文公司(Oracle)开发并维护,是一款商业产品。尽管其源代码与OpenJDK相似,但OracleJDK在发行版中可能会包含一些专有组件和工具。OracleJDK在2019年之后采用了商业许可证,免费使用仅限于开发、测试和个人用途。对于生产环境的使用,可能需要购买商业许可证。
OpenJDK是一个开源的、免费的、可修改的Java开发工具包。它是Java平台标准版(Java SE)的一个开源实现,提供了Java开发所需的所有组件,包括编译器、调试工具、运行时环境等。OpenJDK的目的是通过开源社区的参与和协作,提高Java平台的质量和可维护性。
3、如何编译和运行Java文件?
public class HelloWorld{publics static void main(String[] args){System.out.println("atguigu");}
}
使用Java原生命令编译和运行:
-
使用javac命令来编译Java文件
javac HelloWorld.java -
使用java命令来运行
java HelloWorld
1.2 注释、关键字、标识符
1、Java的注释有几种?
Java中的注释分为3种:
- 单行注释
//注释内容
- 多行注释
/*
注释内容
注释内容
*/
- 文档注释
/**
文档注释内容
*/
2、Java有几个关键字?
全局关键字(48个),保留字(3个),上下文关键字(16个)
(1)全局关键字(48个)
数据类型有关(12个):byte、short、int、long、float、double、char、boolean、void、class、interface、enum
流程控制语句结构(11个):if、else、switch、case、default、for、while、do、break、continue、return
包相关(2个):package、import
对象和引用(4个):new、this、super、instanceof
继承和实现(2个):extends、implements
修饰符(11个):private、protected、public、static、final、native、abstract、transient、strictfp、synchronized、volatile
测试和异常处理(6个):assert、try、catch、finally、throw、throws
| 关键字 | 解释 | 关键字 | 解释 | 关键字 | 解释 |
|---|---|---|---|---|---|
| abstract | 抽象类或抽象方法 | float | 单精度浮点型 | private | 私有化 |
| assert | 断言 | for | for循环结构 | return | 返回 |
| byte | 字节类型 | final | 类不可被继承、方法不能被重写 、常量 | short | 短整型 |
| boolean | 布尔类型 | finally | try-catch-finally最终处理 | switch | switch-case结构 |
| break | 中断循环或switch | int | 整型 | static | 静态的 |
| char | 字符类型 | if | if-else分支结构 | super | 父类的 |
| class | 定义类 | instanceof | 判断是否xx类的实例 | synchronized | 同步的 |
| case | switch-case结构 | import | 导包 | this | 当前对象 |
| continue | 继续循环 | interface | 定义接口 | throw | 抛出异常对象 |
| catch | try-catch异常处理 | implements | 实现接口 | throws | 声明抛出的异常类型 |
| double | 双精度浮点型 | long | 长整型 | try | try-catch异常处理 |
| do | do-while循环 | new | 创建对象 | transient | 瞬时的 |
| default | switch-case结构、接口默认方法、默认值等 | native | 本地的 | void | 空的 |
| else | if-else分支结构 | package | 定义包 | volatile | 线程可见 |
| enum | 定义枚举 | public | 公共的 | while | while、do-while循环 |
| extends | 继承 | protected | 受保护的 | strictfp | 精确浮点(已废弃) |
(2)保留字(3个)
| 保留字 | 解释 | 保留字 | 解释 |
|---|---|---|---|
| const | 常量 | _ | 下划线 |
| goto | 跳转 |
相关的面试题:
问:Java中有没有goto关键字?有,但是goto属于保留字。
问:保留字是什么意思?保留字是指在语言中已经定义但当前未使用的字,相当于预留的关键字。
(3)上下文关键字(16个)
| 关键字 | 解释 |
|---|---|
| yield | switch-case表达式用于返回某个case分支的结果 |
| record | 声明记录类 |
| sealed | 声明类是密封 |
| permits | 用于指定密封类允许哪些子类继承它或哪些实现类实现它 |
| non-sealed | 声明类是非密封的,密封类的子类只能是final、non-sealed、sealed之一 |
| var | 在方法体中定义局部变量,变量的具体类型由首次赋值给该变量的值类型来自动推断 |
| module | 在模块声明文件module-info.java中用于模块声明,例如:module 模块名 |
| exports | 在模块声明文件module-info.java中用于指定哪些包对外部模块可见,例如:exports 包名 【to 模块名1,模块名2】,表示允许外部模块在编译时和运行时访问指定包的public成员 |
| to | 与exports一起使用 |
| open | 在模块声明文件module-info.java中用于声明该模块的所有包在runtime允许使用反射访问,例如:open module 模块名 |
| opens | 在模块声明文件module-info.java中用于声明该模块的指定包在runtime允许使用反射访问,例如:opens 包名; |
| requires | 在模块声明文件module-info.java中用于指定当前模块依赖哪些模块,例如: requires 另一个模块名; |
| transitive | requires transitive 另一个模块名; |
| uses | 在模块声明文件module-info.java中用于声明当前模块需要xx服务,例如:use 接口名; |
| provides | 在模块声明文件module-info.java中用于指定当前模块提供了某些服务,例如:provides 接口 with 实现类; |
| with | 与provides一起使用 |
(4)特殊值(3个)
| 特殊值 | 解释 |
|---|---|
| null | 空值 |
| true | 真 |
| false | 假 |

3、Java中能不能用中文当标识符?(高频plus)
可以,因为Java支持Unicode字符集,但是实际中不会这么用。
public class 中文类名 {public static void main(String[] args) {String 姓名 = "尚硅谷";System.out.println("姓名 = " + 姓名);}
}
4、请简述Java标识符命名规则?
Java标识符命名规则如下:
- 标识符只能用字母(a-z,A-Z)、数字(0-9)、下划线(_)和美元符号($)组成;
- 标识符不能以数字开头;
- 标识符不能直接使用Java关键字、保留字、特殊值;
- 标识符严格区分大小写;
- 一个标识符名中间不能包含空格,否则会被识别为两个标识符;
5、请简述Java标识符命名规范?(高频plus)
(1)见名知意
(2)类名、接口名等:遵循大驼峰命名法,即每个单词的首字母都大写,形式:XxxYyyZzz,例如:HelloWorld,String,System等
(3)变量、方法名等:遵循小驼峰命名法,即从第二个单词开始首字母大写,其余字母小写,形式:xxxYyyZzz,例如:age,name,bookName,main
(4)包名等:每一个单词都小写,单词之间使用点.分割,形式:xxx.yyy.zzz,例如:java.lang; 自己命名的包不能以java开头,习惯上以公司域名倒置的写法,例如:com.atguigu.bean;
(5)常量名等:每一个单词都大写,单词之间使用下划线_分割,形式:XXX_YYY_ZZZ,例如:MAX_VALUE,PI
1.3 变量与常量
1、Java中常量与变量有什么区别?(高频plus)
常量是一个固定的值,赋值后就不能被修改。
变量是一个不固定的值,赋值后仍然可以被修改。
2、如何定义一个常量?
加final关键字修饰的变量,就是常量了。
3、Java中的常量有几种?
- 局部变量 + final,一般直接初始化
- 实例变量 + final,一般通过构造器初始化
- 静态变量 + final,建议大写,一般直接初始化
class Demo{static final String INFO = "尚硅谷";//静态变量 + finalprivate final int a = 1;//实例变量 + finalprivate final int b;private final int c;public Demo(int b, int c) {this.b = b;this.c = c;}public int getA() {return a;}public int getB() {return b;}public int getC() {return c;}@Overridepublic String toString() {return "Demo{" + "a=" + a + ", b=" + b + ", c=" + c + '}';}
}
public class TestFinal {public static void main(String[] args) {System.out.println("Demo.INFO = " + Demo.INFO);Demo d1 = new Demo(1,1);System.out.println("d1 = " + d1);Demo d2 = new Demo(2,2);System.out.println("d2 = " + d2);final int x = 1; //局部变量 + final
// x = 2;}
}
1.4 数据类型
1、String是Java的基本数据类型吗?(高频plus)
答:String不属于Java的基本数据类型,属于Java的引用数据类型,程序中每一个""的内容都是一个String类的对象。
2、Java的基本数据类型有哪些?(高频plus)
Java的基本数据类型有8种:
| 基本数据类型 | 类型名称 | 字节宽度 | 值范围 | 默认值 | 对应包装类 |
|---|---|---|---|---|---|
| byte | 单字节类型 | 1 | -128~127 | 0 | Byte |
| short | 短整型 | 2 | -32768~32767 | 0 | Short |
| int | 整型 | 4 | -2147483648~2147483647 | 0 | Integer |
| long | 长整型 | 8 | -9223372036854775808~9223372036854775807 | 0L | Long |
| float | 单精度浮点型 | 4 | -3.402823E38~3.402823E38 | 0.0F | Float |
| double | 双精度浮点型 | 8 | -1.797693E308~1.797693E308 | 0.0D | Double |
| char | 单字符类型 | 2 | 0~65535,采用Unicode字符集 | '\u0000' | Character |
| boolean | 布尔型 | 1bit | true和false | false | Boolean |
问:boolean类型的宽度是多少?
答:boolean类型的变量用于存储真(true)或假(false)值。JVM规范并没有规定 boolean 类型的具体位数,这取决于JVM的实现。
通常情况下,为了效率考虑,boolean 可能会被实现为8位(1字节),但这不是固定的,也可能占用更少或更多的位。问:Java的数据类型有哪些?
答:Java的数据类型分为基本数据类型(8种)和引用数据类型(包括数组、类、接口、注解、枚举类、记录类、密封类等)。
3、自动类型提升与强制类型转换代码题(高频plus)
1、判断如下代码是否编译通过,如果能,结果是多少?
short s1 = 120;
short s2 = 8;
short s3 = s1 + s2;//编译报错 ,short+short是int2、判断如下代码是否编译通过,如果能,结果是多少?
short b1 = 120;
short b2 = 8;
byte b3 = (byte)(b1 + b2);//结果是-128 发生截断
/*
b1+b2:00000000 00000000 00000000 10000000
(byte)(b1+b2):10000000
*/3、判断如下代码是否编译通过,如果能,结果是多少?
char c1 = '0';
char c2 = '1';
char c3 = c1 + c2;//编译报错,char+char是int4、判断如下代码是否编译通过,如果能,结果是多少?
char c4 = '0';
char c5 = '1';
System.out.println(c4 + c5);//975、判断如下代码是否编译通过,如果能,结果是多少?
int i = 4;
long j = 120;
double d = 34;
float f = 1.2;//编译报错 1.2是double类型
System.out.println(i + j + d + f);6、判断如下代码是否编译通过,如果能,结果是多少?
int a = 1;
int b = 2;
double result = a/b;//a/b得到0,再自动升级为double
System.out.println(result);//0.0
System.out.println((double)a/b);//0.5 取a的值1强制转换为double,1.0/b结果是0.5
System.out.println((double)(a/b));//0.0 a/b得到0,再强制转换为double
4、如何理解自动类型提升?
自动类型提升是指当我们在计算时候,将取值范围小的类型自动提升为取值范围大的类型。自动类型提升规则如图所示:

(1)当把存储范围小的值(字面量值、变量的值、表达式计算的结果值)赋值给了存储范围大的变量时;
(2)当存储范围小的数据类型与存储范围大的数据类型一起混合运算时,会按照大的类型运算;
(3)当byte,short,char数据类型进行算术或位运算时,按照int类型处理;
相关的面试题:
问:自动类型提升就一定是安全的吗?
答:不是,也可能损失精度
int i = 'A';//char自动升级为int
double j = 10;//int自动升级为double
System.out.println(i);//65
System.out.println(j);//10.0int a = 1;
char b = 'A';
long c = 1L;
float d = 1.0F;
System.out.println(a + b + c + d);//升级为float 68.0byte b1 = 1;
byte b2 = 2;
//byte b3 = b1 + b2; //编译报错,b1+b2计算升级为intlong num = 8765432198765432198L;
float fNum = num; //升级为float类型
System.out.println(fNum);//8.765432E18
double dNum = num; //升级为double类型
System.out.println(dNum);//8.7654321987654318E18
5、如何理解强制类型转换?
强制类型转换是指:将取值范围大的类型强制转换成取值范围小的类型,或者有时候也可以将取值范围小的类型强制提升为取值范围大的类型。
(1)当把存储范围大的值(常量值、变量的值、表达式计算的结果值)赋值给了存储范围小的变量时,需要强制类型转换,提示:有风险,可能会损失精度或溢出

int i = 200;
byte b = (byte)i;//溢出
System.out.println(b);double a = 1.2;
int j = (int)a;//损失精度
System.out.println(j);
(2)当某个值想要提升数据类型时,也可以使用强制类型转换
int x = 1;
int y = 2;
double z = (double)x/y;
System.out.println(z);
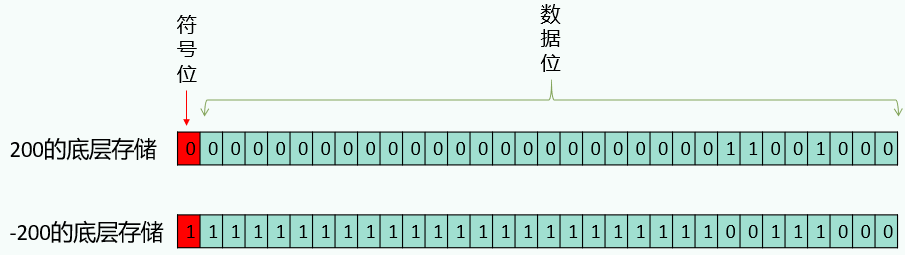
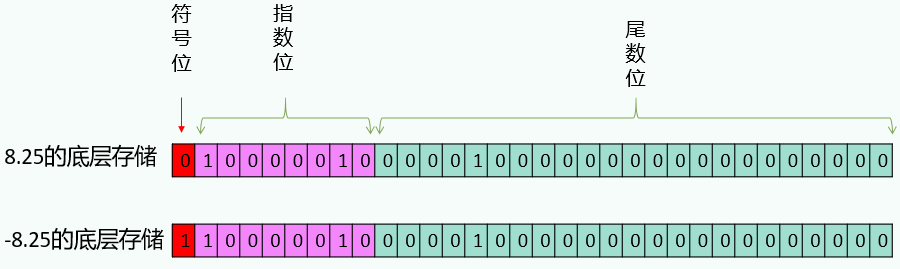
6、为什么4个字节float类型比8个字节long类型存储范围大?
整数采用补码形式存储,即符号位 + 补码数据位。正数的原码、反码、补码三码合一,负数的原码、反码、补码都不相同。
浮点数不采用补码表示法,而是采用IEEE 754标准表示法,即符号位 + 指数位 + 尾数位。
这里的指数和尾数是指二进制科学计数法中的指数和尾数。例如:科学计数法 1.00001 * 2的3次 的3是指数,00001是尾数。
为了便于浮点数的比较和计算,指数存储需要加上偏移量(float偏移127,double偏移量1023)
•float类型的指数位共8位。指数范围:-127 ~ 128,偏移后:0~2551
•double类型的指数位共11位。指数范围:-1023 ~ 1024,偏移后:0~2047

7、为什么0.1+0.2不是0.3?(高频plus)
在代码中测试0.1 + 0.2,你会惊讶的发现,结果不是0.3,而是0.3000……4。这是为什么?
几乎所有现代的编程语言都会遇到上述问题,包括 JavaScript、Ruby、Python、Swift 和 Go 等。引发这个问题的原因是,它们都采用了IEEE 754标准。
IEEE是指“电气与电子工程师协会”,其在1985年发布了一个IEEE 754计算标准,根据这个标准,小数的二进制表达能够有最大的精度上限提升。但无论如何,物理边界是突破不了的,它仍然
不能实现“每一个十进制小数,都对应一个二进制小数”。正因如此,产生了0.1 + 0.2不等于0.3的问题。
具体的:
整数变为二进制,能够做到“每个十进制整数都有对应的二进制数”,比如数字3,二进制就是11;再比如,数字43就是二进制101011,这个毫无争议。
对于小数,并不能做到“每个小数都有对应的二进制数字”。举例来说,二进制小数0.0001表示十进制数0.0625 (至于它是如何计算的,不用深究);二进制小数0.0010表示十进制数0.125;二进制小数0.0011表示十进制数0.1875。看,对于四位的二进制小数,二进制小数虽然是连贯的,但是十进制小数却不是连贯的。比如,你无法用四位二进制小数的形式表示0.125 ~ 0.1875之间的十进制小数。
所以在编程中,遇见小数判断相等情况,比如开发银行、交易等系统,可以采用四舍五入或者“同乘同除”等方式进行验证,避免上述问题。
1.5 运算符
1、Java有几个运算符?哪些运算符会修改变量的值?
Java有38个运算符。只有自增自减 ++,--,=,+=等赋值运算符会修改变量的值。
Java中标点符号如下:

(1)按照功能分:算术运算符、赋值运算符、比较运算符、逻辑运算、条件运算符、Lambda运算符
| 分类 | 运算符 |
|---|---|
| 算术运算符(7个) | +、-、*、/、%、++、-- |
| 赋值运算符(12个) | =、+=、-=、*=、/=、%=、>>=、<<=、>>>=、&=、|=、^=等 |
| 关系、比较运算符(6个) | >、>=、<、<=、==、!= |
| 逻辑运算符(3个) | &&、||、! |
| 位运算符(7个) | &、|、^、~、<<、>>、>>> |
| 条件运算符(2个) | ? : |
| Lambda运算符(1个) | -> |
(2)按照操作数个数分:一元运算符(单目运算符)、二元运算符(双目运算符)、三元运算符 (三目运算符)
| 分类 | 运算符 |
|---|---|
| 一元运算符(单目运算符) | 正号(+)、负号(-)、++、--、!、~ |
| 二元运算符(双目运算符) | 除了一元和三元运算符剩下的都是二元运算符 |
| 三元运算符 (三目运算符) | (条件表达式)?结果1:结果2 |
2、++在前在后有什么区别?(高频plus)
以下以自增为例,自减类同。
(1)单独运算
- 自增表达式单独成语句的时候,
++在前和++在后,变量的值是一样的;++在前,例如++a;++在后,例如a++;
(2)复合运算
- 自增表达式与其他操作合成一个语句时,
++在前和++在后,变量本身的值是一样的,但是参与其他操作的值是不一样的。++在前:变量先自身加1,紧接着再取变量的值,然后进行其他计算。++在后:变量先取值,紧接着变量再自身加1,然后用之前取的值进行其他计算。
案例1
public class IAddDemo1 {public static void main(String[] args) {int a = 1;a++;System.out.println("a = " + a);//a=2++a;System.out.println("a = " + a);//a=3}
}
案例2
public class IAddDemo2 {public static void main(String[] args) {int a = 1;System.out.println("a++:" + a++);//a++:1 先取a的值1,紧接着a自增1,即a=2,然后将1与“”进行拼接输出System.out.println("a = " + a);//a=2System.out.println("++a:" + ++a);//++a:3 a先自增1,即a=3,紧接着取a的值3,,然后将3与“”进行拼接输出System.out.println("a = " + a);//a = 3}
}
案例3
public class IAddDemo3 {public static void main(String[] args) {int i = 1;int j = i++ + ++i * i++;/*i++:取i的值1,紧接着i自增1,即i=2,然后用1进行后续的求和运算++i:先对i自增1,即i=3,紧接着取i的值3,然后用3进行后续的乘法运算i++:取i的值3,紧接着i自增1,即i=4,然后用3进行后续的乘法运算先乘后加,3*3+1=10*/System.out.println("i = " + i); // i=4System.out.println("j = " + j); // j=10}
}
案例4
public class IAddDemo3 {public static void main(String[] args) {int a = 1;a = ++a;//a先自增1,即a=2,紧接着取a的值2,然后将2赋值给a,最后a=2System.out.println("a = " + a); //a = 2a = a++;//取a的值2,紧接着a自增1,即a=3,然后将2赋值给a,最后a=2System.out.println("a = " + a);// a = 2int b = a++;//取a的值2,紧接着a自增1,即a=3,然后将2赋值给b,最后a=3,b=2System.out.println("b = " + b);//b = 2System.out.println("a = " + a);//a = 3}
}
3、/与%的区别
案例1
public class DivideAndModDemo1 {public static void main(String[] args) {System.out.println(5 / 2);//2 5/2 = 5÷2=2商...余1System.out.println(5 % 2);//1System.out.println(5 / -2);//-2 5/-2 = 5÷-2=-2商...余1System.out.println(5 % -2);//1//被除数 ÷ 除数 = 商 ... 余数//演算:商 * 除数 + 余数 = 被除数}
}
案例2
public class DivideAndModDemo2 {public static void main(String[] args) {
// System.out.println(1/0);//发生运行时异常ArithmeticException
// System.out.println(1%0);//发生运行时异常ArithmeticExceptionSystem.out.println(1.0/0);//InfinitySystem.out.println(1.0%0);//NaN, Not a Number}
}4、&和&&、|和||的区别(高频plus)
&: 按位与
- 如果左边两边是数值,将两个操作数的二进制对齐后,1 & 1 为1,其余都为0。
- 如果左右两边是boolean值,true底层为1,false底层为0。只有两边为true,结果才为true。当左边为false时,右边继续计算。
&&:短路与
- 左右两边必须是boolean值,只有两边为true,结果才为true。当左边为false时,右边表达式不计算。
public class AndOrDemo1 {public static void main(String[] args) {System.out.println(9 & 5); //结果是1/*9的二进制:00000000 00000000 00000000 000010015的二进制:00000000 00000000 00000000 000001019&5的: 00000000 00000000 00000000 00000001(十进制1)*/int x = 1, y = 1;System.out.println(x++ == 2 & ++y == 2);//false & true结果false//取x的1,x自增为2, 1==2 false, y自增为2,取y的值2,2==2 trueSystem.out.println("x = " + x + ", y = " + y);//x=2,y=2System.out.println(++x == 2 && ++y == 2);//结果false//x自增为3,取x的3, 3==2 false, 短路System.out.println("x = " + x + ", y = " + y);//x=3,y=2 }
}
|:按位或
- 如果左边两边是数值,将两个操作数的二进制对齐后,0 | 0 为0,其余都为1。
- 如果左右两边是boolean值,true底层为1,false底层为0。只要一边为true,结果就为true。当左边为true时,右边表达式仍然要计算。
||:短路或
- 左右两边必须是boolean值,只要一边为true,结果就为true。当左边为true时,右边表达式不计算。
public class AndOrDemo2 {public static void main(String[] args) {System.out.println(9 | 5);//结果13/*9的二进制:00000000 00000000 00000000 000010015的二进制:00000000 00000000 00000000 000001019|5的: 00000000 00000000 00000000 00001101(十进制13)*/int x = 1, y = 1;System.out.println(x++ == 1 | ++y == 1);//true | false 结果是true//取x的1,x自增为2, 1==1 true, y自增为2,取y的值2, 2==1 falseSystem.out.println("x = " + x + ", y = " + y);//x=2,y=2System.out.println(x++ == 2 || ++y == 2);//true//取x的2,x自增为3, 2==2 true, 短路System.out.println("x = " + x + ", y = " + y);//x=3,y=2 }
}
5、>>与>>>、<<的区别?
<<:左移,快速口诀:左移几位相当于乘以2的几次方
>>:右移,快速口诀:右移几位相当于除以2的几次方>>>:无符号右移,即左边补位时不考虑原来符号位,直接补0
public class BitOperatorDemo {public static void main(String[] args) {System.out.println(9<<2);//相当于 9 * 2的2次 = 9 * 4 = 36System.out.println(-9<<2);//相当于 -9 * 2的2次 = -9 * 4 = -36System.out.println(9>>2);//相当于 9 / 2的2次 = 9 / 4 = 2.5 = 2(向下取整) System.out.println(-9>>2);//相当于 -9 / 2的2次 = -9 / 4 = -2.5 = -3(向下取整)System.out.println(9>>>2);//对于正数,结果与 >> 相同System.out.println(-9>>>2);//1073741821/*9的二进制:00000000 00000000 00000000 000010019<<2: 左边截掉2位,右边补2个000000000 00000000 00000000 00100100(十进制36)-9的二进制:11111111 11111111 11111111 11110111-9<<2: 左边截掉2位,右边补2个011111111 11111111 11111111 11011100(十进制-36)9的二进制:00000000 00000000 00000000 000010019>>2: 左边补2个0,右边截掉2位00000000 00000000 00000000 00000010(十进制2)-9的二进制:11111111 11111111 11111111 11110111-9>>2: 左边补两个1(因为原来最高位是1),右边截掉2位11111111 11111111 11111111 11111101(十进制-3)9>>>2: 左边补2个0,右边截掉2位00000000 00000000 00000000 00000010(十进制2)-9>>>2:左边补2个0,右边截掉2位00111111 11111111 11111111 11111101(十进制1073741821)*/System.out.println(9 << 65);//18}
}
6、2 * 8 最有效率的计算方式是什么?(高频plus)
答:2 << 3。当乘以或除以1个2的n次方都可以用<<或>>。
7、==、=的区别(高频plus)
==:用于比较两个值是否相等
=:用于赋值
public class OperatorsDemo1 {public static void main(String[] args){boolean flag = false;if(flag == true){ //判断flag变量中的值是不是trueSystem.out.println("真1");}if(flag == false){//判断flag变量中的值是不是trueSystem.out.println("假1");}}
}
public class OperatorsDemo2 {public static void main(String[] args){boolean flag = false;if(flag = true){//将flag变量修改为true,然后用flag变量的值作为条件System.out.println("真2");}if(flag = false){//将flag变量修改为false,然后用flag变量的值作为条件System.out.println("假2");}}
}
8、=和+=的区别
=:直接将=右边的值赋值给左边的变量。并且要求右边的值的类型必须小于等于左边变量的类型,否则编译报错。
+=:将左边变量的值 与 右边的值进行+运算之后再把结果赋值给左边的变量。当最终结果的类型大于左边变量的类型时,会隐式的发生强制类型转换,即发生溢出截断或损失精度。
案例1
public class OperatorsDemo3 {public static void main(String[] args) {byte a = 127;byte b = 1;a += b; //a = (byte)(a+b)System.out.println("a = " + a); //a = -128// a = a + b;//编译报错}
}
案例2
public class OperatorsDemo4 {public static void main(String[] args) {int a = 3;int b = 4;a *= a + b;// a = a * (a+b)System.out.println("a = " + a);//a = 21}
}
9、三元运算符结果的类型看:前的还是:后的? (高频plus)
条件表达式?结果1:结果2
两个结果表达式的类型必须一致。
public class ConditionOperatorDemo2 {public static void main(String[] args) {char x = 'a';int i = 10;System.out.println(true? x : i);//97System.out.println(true? 'a' : 10);//aSystem.out.println(true? 'a' : 70000);//97}
}
10、+与>>的优先级谁高?
Java操作符和运算符优先级如下:
一元运算符 > 算术运算符 > 移位运算符 > 关系运算符 > 其他位运算符 > 逻辑运算符 > 条件运算符 > 赋值运算符
| 优先级 | 符号 | 优先级 | 符号 |
|---|---|---|---|
| 1 | ( ) | 9 | == != |
| 2 | .(成员访问操作符) [ ](数组元素访问符) |
10 | & |
| 3 | +(正) -(负) | 11 | ^ |
| 4 | ++ -- ~ ! | 12 | | |
| 5 | * / % | 13 | && |
| 6 | +(加:求和、拼接) -(减) | 14 | || |
| 7 | << >> >>> | 15 | ? : |
| 8 | < > <= >= instanceof | 16 | = += -= *= /= %= <<= >>= >>>= &= ^= |= |
public class OperatorPriorityDemo1 {public static void main(String[] args){int a = 10;a = a + a>>2; //+先计算, 等价于a = (a+a)>>2 = (a+a)/4System.out.println("a = " + a); //a = 5a = a + (a>>2);//先计算a>>2 等价于 a = a + a/4System.out.println("a = " + a);//a = 6}
}
11、Java的运算符可以重载吗?(高频plus)
Java没有运算符重载,Java中只有方法重载。
补充说明:
Java中的+确实有两种含义:求和与拼接,但计算规则也是预先定义好的,有字符串就是拼接,否则就是求和。
1.6 流程控制语句结构
1、if-else和switch-case有什么区别?(高频plus)
- 适用性:if语句的条件是一个布尔类型值,if条件表达式为true则进入分支,可以用于范围的判断,也可以用于等值的判断,使用范围更广。switch语句的条件是一个常量值(byte,short,int,char,及其它们的包装类,枚举,String),只能判断某个变量或表达式的结果是否等于某个常量值,使用场景较狭窄。
- 效率:当条件是判断某个变量或表达式是否等于某个固定的常量值时,使用if和switch都可以实现,但是使用switch效率更高。
- 穿透性:使用switch可以利用穿透性,同时执行多个分支,而if...else没有穿透性。
案例1:只能使用if
从键盘输入一个整数,判断是正数、负数、还是零。
import java.util.Scanner;public class TestIfOrSwitchDemo1 {public static void main(String[] args) {Scanner input = new Scanner(System.in);System.out.print("请输入整数:");int num = input.nextInt();if (num > 0) {System.out.println(num + "是正整数");} else if (num < 0) {System.out.println(num + "是负整数");} else {System.out.println(num + "是零");}input.close();}
}
案例2:使用switch效率更高
使用if实现根据星期值输出对应的英文单词
import java.util.Scanner;public class TestIfOrSwitchDemo2 {public static void main(String[] args) {//定义指定的星期Scanner input = new Scanner(System.in);System.out.print("请输入星期值:");int weekday = input.nextInt();//使用if...else实现if (weekday == 1) {System.out.println("Monday");} else if (weekday == 2) {System.out.println("Tuesday");} else if (weekday == 3) {System.out.println("Wednesday");} else if (weekday == 4) {System.out.println("Thursday");} else if (weekday == 5) {System.out.println("Friday");} else if (weekday == 6) {System.out.println("Saturday");} else if (weekday == 7) {System.out.println("Sunday");} else {System.out.println("你输入的星期值有误!");}input.close();}
}import java.util.Scanner;public class TestIfOrSwitchDemo3 {public static void main(String[] args) {//定义指定的星期Scanner input = new Scanner(System.in);System.out.print("请输入星期值:");int weekday = input.nextInt();//switch语句实现选择switch(weekday) {case 1:System.out.println("Monday");break;case 2:System.out.println("Tuesday");break;case 3:System.out.println("Wednesday");break;case 4:System.out.println("Thursday");break;case 5:System.out.println("Friday");break;case 6:System.out.println("Saturday");break;case 7:System.out.println("Sunday");break;default:System.out.println("你输入的星期值有误!");break;}input.close();}
}案例3:巧用switch的穿透性
用year、month、day分别存储今天的年、月、日值,然后输出今天是这一年的第几天。
注:判断年份是否是闰年的两个标准,满足其一即可
1)可以被4整除,但不可被100整除
2)可以被400整除
例如:1900,2200等能被4整除,但同时能被100整除,但不能被400整除,不是闰年
import java.util.Scanner;//判断这一天是当年的第几天==>从1月1日开始,累加到xx月xx日这一天
//(1)[1,month-1]个月满月天数 + 第month个月的day天
//(2)单独考虑2月份是否是29天(判断year是否是闰年)
public class TestIfOrSwitchDemo4 {public static void main(String[] args) {Scanner input = new Scanner(System.in);System.out.print("请输入年 月 日");int year = input.nextInt();int month = input.nextInt();int day = input.nextInt();int days = 0;//存储总天数switch (month) {case 12:days += 30;//30代表11月份的满月天数,没有break,继续往下走,累加的1-11月case 11:days += 31;//31代表10月份的满月天数,没有break,继续往下走,累加的1-10月case 10:days += 30;//9月case 9:days += 31;//8月case 8:days += 31;//7月case 7:days += 30;//6月case 6:days += 31;//5月case 5:days += 30;//4月case 4:days += 31;//3月case 3:days += year % 4 == 0 && year % 100 != 0 || year % 400 == 0 ? 29:28;//2月case 2:days += 31;//1月case 1:days += day;//第month月的day天}System.out.println(year + "年" + month + "月" + day + "日是这一年的第" + days + "天");input.close();}
}
2、switch支持哪几种数据类型?(高频plus)
switch只支持4种基本数据类型(byte,short,int,char)及其包装类,JDK1.5之后枚举、JDK1.7之后String。
相关面试题:
问:switch表达式支持任意类型?
答:switch表达式只有在模式匹配语法中才支持任意引用数据类型。Java中switch表达式支持模式匹配在JDK21正式转正。
public class SwitchDemo {public static void main(String[] args) {Object[] arr = {"hello",8,3.1415926};for (int i = 0; i < arr.length; i++) {switch (arr[i]) {case String str -> System.out.println(str + "首字母:" + str.charAt(0));case Integer integer -> System.out.println(integer + "是" + (integer % 2 == 0 ? "偶数" : "奇数"));case Double num -> System.out.printf("%f保留小数点后2位%.2f", num, num);default -> throw new RuntimeException();}}}
}
3、switch语句和switch表达式有什么区别?(高频plus)
| switch语句 | switch表达式 | |
|---|---|---|
| case后面的标志性符号 | : | -> |
| case后面写多个常量值 | 否 | 是 |
| 是否会穿透 | 是 | 否 |
| 整个switch结构是否可以作为表达式 | 否 | 是 |
| case分支后面写什么 | 只能写语句 | 可以是表达式、单个语句、多个语句的代码块 |
| 一个case分支写多个语句是否强制加{} | 否 | 是 |
| 是否必须有default分支 | 否 | 作为表达式使用时,就必须有default分支 |
案例:根据指定的月份输出对应季节
import java.util.Scanner;public class TestOldSwitchDemo1 {public static void main(String[] args) {Scanner input = new Scanner(System.in);System.out.print("请输入月份:");int month = input.nextInt();switch(month) {case 1:System.out.println("冬季");break;case 2:System.out.println("冬季");break;case 3:System.out.println("春季");break;case 4:System.out.println("春季");break;case 5:System.out.println("春季");break;case 6:System.out.println("夏季");break;case 7:System.out.println("夏季");break;case 8:System.out.println("夏季");break;case 9:System.out.println("秋季");break;case 10:System.out.println("秋季");break;case 11:System.out.println("秋季");break;case 12:System.out.println("冬季");break;default:System.out.println("你输入的月份有误");break;}input.close();}
}
import java.util.Scanner;public class TestNewSwitchDemo1 {public static void main(String[] args) {Scanner input = new Scanner(System.in);System.out.print("请输入月份:");int month = input.nextInt();switch(month) {case 3,4,5 -> System.out.println("春季");case 6,7,8 -> System.out.println("夏季");case 9,10,11 -> System.out.println("秋季");case 12,1,2 -> System.out.println("冬季");default -> throw new RuntimeException("月份输入有误!");}input.close();}
}
import java.util.Scanner;public class TestNewSwitchDemo2 {public static void main(String[] args) {Scanner input = new Scanner(System.in);System.out.print("请输入月份:");int month = input.nextInt();String monthName = switch(month) {case 3,4,5 -> "春季";case 6,7,8 -> "夏季";case 9,10,11 -> "秋季";case 12,1,2 -> "冬季";default -> throw new RuntimeException("月份输入有误!");};System.out.println("monthName = " + monthName);input.close();}
}
import java.util.Scanner;public class TestNewSwitchDemo3 {public static void main(String[] args) {Scanner input = new Scanner(System.in);System.out.print("请输入月份:");int month = input.nextInt();String monthName = switch(month) {case 3,4,5 -> "春季";case 6,7,8 -> "夏季";case 9,10,11 -> "秋季";case 12,1,2 -> {System.out.println("我最害怕冬天!");yield "冬季";}default -> throw new RuntimeException("月份输入有误!");};System.out.println("monthName = " + monthName);input.close();}
}
4、for、while和do-while有什么区别?
-
从循环次数角度分析
- do...while循环至少执行一次循环体语句
- for和while存在循环体语句可能一次都不执行的情况
-
如何选择
- 首先,从实现功能角度来看:三种循环完全可以互换,没有非彼不可的问题。
- 其次,从使用习惯来看:有明显的循环次数(范围)的需求,通常选择for循环;循环次数不明显,但是循环条件明确的情况下,通常选择while循环;如果循环体语句块至少执行一次,可以考虑使用do...while循环。
5、如何跳出Java中的循环?
使用break语句就可以跳出Java中的循环。
for(int i=1; i<=5; i++){if(i==3){break;}System.out.println(i);}
6、如何跳出Java中的多层循环?(高频plus)
使用标签+break语句就可以跳出Java中的循环。
public class TestBreak1 {public static void main(String[] args) {out:for (int i = 1; i <= 5; i++) {System.out.println("i=" + i);for (int j = 1; j <= 5; j++) {System.out.println("\tj=" + j);if (j == i) {break out;}}}}
}
或变量标记法 + break来控制循环
public static void main(String[] args) {boolean flag = true;for(int i=1; i<=5 && flag; i++){System.out.println("i=" + i);for(int j=1; j<=5; j++){System.out.println("\tj=" + j);if(j==i){flag = false;break;}}}}
7、break、continue、return的区别?(高频plus)
| continue | break | return | |
|---|---|---|---|
| 用在哪里 | 循环体中 | 循环体或switch-case结构中 | 方法体中 |
| 作用 | 跳过本次循环剩下的语句,直接准备下一次循环 | 结束本层循环或switch-case结构 | 结束当前方法 |
1.7 数组
1、Java怎么进行数组初始化?
(1)静态初始化
元素类型[] 数组名 = {元素1,元素2,元素3};
元素类型[][] 数组名 = {{元素1,元素2,元素3},{元素1,元素2,元素3},{元素1,元素2,元素3}};
(2)动态初始化
元素类型[] 数组名 = new 元素类型[长度];
元素类型[][] 数组名 = new 元素类型[行数][列数];
元素类型[][] 数组名 = new 元素类型[行数][];
数组名[行下标] = new 元素类型[列数];
2、数组元素的默认值是多少?
| 基本数据类型 | 默认值 |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0L |
| float | 0.0F |
| double | 0.0D |
| char | '\u0000' |
| boolean | false |
| 引用数据类型 | null |
3、数组有没有length方法?String呢?(高频plus)
数组没有length方法,数组有length属性,String有length方法。
int[] arr = {10,20,30,40};
System.out.println("数组的长度:" + arr.length);
String str = "hello";
System.out.println("字符串的长度:" + str.length());
4、数组下标为什么从0开始?
数组的元素是连续存储的,通过下标可以直接计算每一个元素的地址。数组名中存储的数组的首地址,每一个元素地址的计算方式:首地址 + 对象头大小(固定字节数量) + 下标 * 元素字节宽度。
数组的下标范围是[0, 数组名.length -1 ]
二、Java基础算法题(8题/9题)
1、循环算法题
案例1:图形打印(高频plus)
输出n行*组成的等腰三角形。
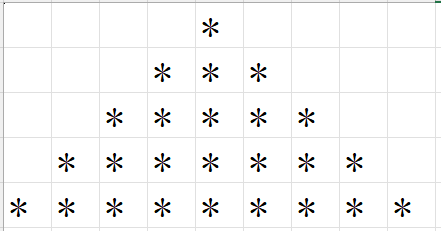
public class IsoscelesTriangleDemo {public static void main(String[] args) {printTriangle(5);}public static void printTriangle(int n) {/*假设n=5第1行:空格4个,* 1个第2行:空格3个,* 3个第3行:空格2个,* 5个第4行:空格1个,* 7个第5行:空格0个,* 9个*/for (int i = 1; i <= n; i++) {// 打印前导空格for (int j = 1; j <= n - i; j++) {System.out.print(" ");}// 打印 *for (int k = 1; k <= 2 * i - 1; k++) {System.out.print("*");}// 换行System.out.println();}}
}
案例2:九九乘法表(高频plus)
打印九九乘法表(要求格式对齐,算法优化)。
public class MultiplicationTableDemo {public static void main(String[] args) {int m = 9;int n = 9;String str =m +"*" + n + "=" + m*n;int maxLength = str.length();for(int i=1; i<=m; i++){for(int j=1; j<=i; j++){str = String.format("%-" + maxLength + "s\t", i +"*" + j + "=" + i*j);System.out.print(str);}System.out.println();}}
}

案例3:百钱买百鸡(高频plus & 高xinplus)
有一人去买鸡,公鸡每只5元,母鸡每只3元,小鸡每3只1元,用100元去买100只鸡,要求公鸡、母鸡、小鸡都要有,各买多少只,用Java程序实现。
public class ChickenDemo {public static void main(String[] args) {int totalMoney = 100; // 总金额int totalChickens = 100; // 总鸡数for (int roosters = 1; roosters <= totalMoney / 5; roosters++) {for (int hens = 1; hens <= totalMoney / 3; hens++) {int chicks = totalChickens - roosters - hens;int cost = roosters * 5 + hens * 3 + chicks / 3;// 检查是否满足条件if (chicks >= 1 && chicks % 3 == 0 && cost == totalMoney) {System.out.println("公鸡: " + roosters + "只, 母鸡: " + hens + "只, 小鸡: " + chicks + "只");}}}}
}
2、数组算法题
案例1:循环删除(高频plus)
有一个数组依次存储0-999,要求每隔2个数删掉一个数,到末尾后循环到开头继续进行,直到只剩下1个元素。求最后一个元素。
public class ArrayDeleteDemo {public static void main(String[] args) {int[] arr = new int[1000];for (int i = 0; i < arr.length; i++) {arr[i]=i;}//循环删除int count = arr.length;int index = 0;while(count>1){index = (index+2) % count;//计算删除元素的下标System.arraycopy(arr,index+1,arr,index,count-index-1);//删除index位置元素count--;//元素个数减少}System.out.println("最后剩下的元素是:" + arr[0]);}
}
案例2:产生一组素数(高频plus)
用Java实现素数生成,输入参数n,返回不大于n的素数数组。
public class PrimeGenerator {public static int[] generatePrimes(int n) {//素数:大于1的自然数中,只能被1和它本身整除的数boolean[] isPrime = new boolean[n + 1];// 初始化所有数为素数for (int i = 2; i <= n; i++) {isPrime[i] = true;}// 使用埃拉托斯特尼筛选法(简称埃氏筛法)筛选素数for (int p = 2; p * p <= n; p++) {if (isPrime[p]) {for (int i = p * p; i <= n; i += p) {isPrime[i] = false;}}}// 计算素数的数量int count = 0;for (int i = 2; i <= n; i++) {if (isPrime[i]) {count++;}}// 创建素数数组int[] primes = new int[count];int index = 0;for (int i = 2; i <= n; i++) {if (isPrime[i]) {primes[index++] = i;}}return primes;}public static void main(String[] args) {int n = 30; // 示例输入int[] primes = generatePrimes(n);for (int prime : primes) {System.out.print(prime + " ");}}
}
案例3:杨辉三角
循环打印n行的杨辉三角。

public class YangHuiTriangle {public static void main(String[] args) {printTriangle(6);}/*(1)n行有n个数字(2)每一行的第1个和最后一个元素都是1(3)从第三行开始, 对于非第一个元素和最后一个元素的元素triangle[i][j] = triangle[i - 1][j - 1] + triangle[i - 1][j]
*/public static void printTriangle(int n) {int[][] triangle = new int[n][];for (int i = 0; i < n; i++) {triangle[i] = new int[i+1];for (int j = 0; j <= i; j++) {if (j == 0 || j == i) {triangle[i][j] = 1;} else {triangle[i][j] = triangle[i - 1][j - 1] + triangle[i - 1][j];}System.out.print(triangle[i][j] + "\t");}System.out.println();}}
}
案例4:二分查找(高频plus)
请使用二分查找算法在数组中查找目标值target的下标,例如:{8,15,23,35,45,56,75,85}
import java.util.Scanner;public class BinarySearchDemo {public static void main(String[] args) {int[] arr = {8,15,23,35,45,56,75,85};//数组一定是有序的Scanner input = new Scanner(System.in);System.out.print("请输入你要查找的值:");int target = input.nextInt();int index = -1;int left = 0;int right = arr.length-1;while(left<=right){int mid = left + (right-left)/2;//计算中间值下标if(arr[mid] == target){//找到了index = mid;break;}else if(target < arr[mid]){//说明target在左边right= mid-1;//修改右边界,缩小查找范围}else if(target > arr[mid]){//说明target在右边left = mid+1;//修改左边界,缩小查找范围}}if(index!=-1){System.out.println("找到了,下标是"+index);}else{System.out.println("不存在");}}
}
案例5:冒泡排序(高频plus & 高xinplus)
随机产生10个[0,100)的整数,然后用冒泡排序算法实现从小到大排列。
import java.util.Random;public class BubbleSortDemo {public static void main(String[] args) {int[] arr = new int[10];Random random = new Random();for (int i = 0; i < arr.length; i++) {arr[i] = random.nextInt(100);System.out.print(arr[i] + " ");}System.out.println();//冒泡排序for (int i = 1; i < arr.length; i++) {for (int j = 0; j < arr.length-i; j++) {if(arr[j]>arr[j+1]){int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}System.out.println("排序后:");for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();}
}案例6:选择排序(高频plus)
随机产生10个[0,100)的数字,然后用任意一种排序算法实现排序。
import java.util.Random;public class SelectSortDemo {public static void main(String[] args) {int[] arr = new int[10];Random random = new Random();for (int i = 0; i < arr.length; i++) {arr[i] = random.nextInt(100);System.out.print(arr[i] + " ");}System.out.println();//选择排序for (int i = 0; i < arr.length-1; i++) {int min = arr[i];int index = i;for (int j = i+1; j < arr.length; j++) {if(arr[j]<min){min = arr[j];index = j;}}if(index != i){int temp = arr[i];arr[i] = arr[index];arr[index] = temp;}}System.out.println("排序后:");for (int i = 0; i < arr.length; i++) {System.out.print(arr[i] + " ");}System.out.println();}
}三、面向对象基础(13题/30题)
3.1 形参与实参
1、Java到底是值传递还是引用传递?(高频plus)
Java中只有值传递。
- 对于基本数据类型,传递的是它们数据值的副本,即调用方法时,实参将数据值复制一份给形参,在被调用的方法内部对形参做任何修改对实参的值都没有影响。
- 对于引用数据类型,传递的是对象引用的副本,即对象内存地址的副本,而不是对象本身。引用类型的传递虽然可以修改引用对象的内容,但不能修改引用本身,所以,Java中引用传递其实仍然是值传递的一种形式。
2、传参的代码分析题(高频plus)
import org.junit.Test;import java.util.Arrays;public class PassParamValueDemo {public void change(int a,int[] arr){a++;arr[0]++;arr[1] = 100;}@Testpublic void test1(){int x = 1;int[] nums = {1,1};change(x,nums);System.out.println("change后:x = " + x);System.out.println("change后nums[0] = " + nums[0] + ", nums[1] = " + nums[1]);}public void change(String s1,StringBuffer s2){s1.concat("atguigu");s2.append("atguigu");}@Testpublic void test2(){String x = "hello";StringBuffer y = new StringBuffer("hello");change(x,y);System.out.println("change后:x = " + x);System.out.println("change后:y = " + y);}public void change(int[] arr){arr = new int[arr.length*2];}@Testpublic void test3(){int[] nums = {1,1};change(nums);System.out.println("change后:" + Arrays.toString(nums));}
}
3、Java中有没有指针?
Java中没有指针的概念。
在Java中,每一个对象(除了基本数据类型以外)都是一个引用,这种引用在Java中被称为“句柄”。它们的使用受到了严格的限制和规范,可以被认为是“安全指针”。Java中的引用和C语言中的指针虽然功能相似,都是用来表示内存地址,但Java中的引用是对类进行的,即针对对象进行的,而C中的指针可以指向任何类型的数据。在Java中,引用被广泛用于对象之间的交互和数据的传递。例如,当一个对象的方法需要另一个对象的数据时,可以通过传递引用(即对象的地址)来实现数据的访问和修改,但不能修改引用。这种机制使得Java在内存管理上更加安全和高效,避免了指针操作可能带来的风险。
此外,有些观点认为Java中的引用可以看作是“特殊的指针”,它们不是直接指向内存地址,而是由虚拟机实现者决定的。
3.2 静态
1、static关键字有什么用?(高频plus & 高xinplus)
static代表静态的意思。static可以用于如下5个位置:
- 静态变量(静态变量属于类,不需要实例化对象就能使用,它的值可以被当前类及其子类、以及这些类的所有实例对象共享)
- 静态方法(静态方法属于类方法,不需要实例化对象就能调用)
- 静态代码块(静态代码块只会在类被加载时执行且执行一次)
- 静态内部类(静态内部类可以不依赖外部类实例对象而被使用,当在成员内部类中不需要访问外部类的实例成员时,就可以把成员内部类定义为静态内部类)
- 静态导入(在当前类上方静态导入另一个类的静态成员后,当前类就可以直接使用另一个类的静态成员的简名称,而不需要加类名.)
问:在static方法中可以使用this或super吗,为什么?
答:不可以,因为this代表当前对象的引用,super用于让当前对象去调用在父类中声明的成员,而静态方法属于类,不依赖于当前类的实例对象,那么在静态方法中就不存在当前对象的引用,所以在静态方法中不能使用this和super。
2、静态变量与普通变量的区别(高频plus & 高xinplus)
| 静态变量 | 实例变量 | 局部变量 | |
|---|---|---|---|
| 声明位置 | 类中方法外 | 类中方法外 | 方法/构造器/代码块内部 |
| static | √ | × | × |
| 权限修饰符 | √ | √ | × |
| 有默认初始值 | √ | √ | × |
| 内存位置 | 方法区 | 堆 | 栈 |
| 初始化时机 | 类加载的初始阶段 | new对象时 | 方法调用执行时 |
| 生命周期 | 与类加载而分配内存,类卸载而消亡 | 随着对象创建而分配内存,对象被GC回收而消亡 | 随着方法调用而分配内存,方法出栈而消亡 |
| 层次级别 | 类级别,是类信息的一部分,所有实例对象共享 | 对象级别,每一个实例对象独立 | 局部级别,每次方法调用都是全新的 |
| 使用方式 | (1)本类中任意位置可以直接使用 (2)权限修饰符允许的情况下跨类使用,建议用类名.静态变量,不推荐对象名.静态变量 (3)权限修饰符不允许的情况下跨类使用,建议遵循封装原则使用get/set方法 |
(1)本类中仅限于非静态方法、构造器、非静态代码块中可以直接使用 (2)权限修饰符允许的情况下跨类使用,只能通过对象名.实例变量 (3)权限修饰符不允许的情况下跨类使用,建议遵循封装原则使用get/set方法 |
仅限于当前方法/构造器/代码块局部使用 |
类似的面试题:
问:静态变量与实例变量的区别?
答:见上表
问:static可以修饰局部变量吗?
答:不可以
问:static变量的值能修改吗?
答:可以。在Java中只要变量不是final修饰的,值就可以修改。
public class Demo {static int a;int b;static int d;public void method(String str){int c = 1;int d = 1;a++;b++;c++;d++;System.out.println(str);System.out.println("静态变量a = " + a);System.out.println("实例变量b = " + b);System.out.println("局部变量c = " + c);System.out.println("局部变量d = " + d);}public static void main(String[] args) {Demo d1 = new Demo();d1.method("d1.method():");d1.method("d1.method():");Demo d2 = new Demo();d2.method("d2.method():");}
}
3、你简述一下main方法?
main方法是Java程序的入口,方法签名如下:
public static void main(String[] args){}
相关的问题:
问:Java中的main方法有什么用?Java程序的入口
问:main一定要静态的吗?为什么?是,因为这样JVM再调用main方法时,就无须创建主类的实例对象
问:main方法可以被继承吗?可以
问:main方法可以重载吗?可以,但是JVM只会选择public static void main(String[] args)进行调用
问:main方法可以被重写吗?不可以
问:main方法可以加同步吗?可以
问:怎么向main方法传递参数?命令行程序参数,java 主类名 参数值1 参数值2 参数值3
问:不用main方法如何运行一个类?(1)可以通过JUnit的@Test(2)使用Servlet类结合Web请求
3.3 面向对象编程的特征
1、面向对象编程有哪些特征?(高频plus & 高xinplus)
面向对象编程(OOP)的特征有抽象、封装、继承和多态。这些特性共同构成了面向对象设计的基础,使代码更具模块性、可重用性和可维护性。下面分别解释这四个特征:
-
封装(Encapsulation): 封装是指将数据(属性)和操作这些数据的方法捆绑在一起,形成一个整体。同时,封装还意味着隐藏对象的内部状态和实现细节,只暴露必要的公共接口供外部访问。这样做的好处是可以保护对象的状态不被外部代码随意更改,从而增加了代码的安全性和稳定性。
在Java中,封装主要通过访问控制符(如
private、protected和public)来实现,private关键字可以限制只有类内部的代码可以访问某些属性和方法,而public则可以让外部代码访问。此外,还可以通过提供getter和setter方法来间接访问和修改属性,以增加对属性的控制。 -
继承(Inheritance): 继承允许创建一个新类(子类),该类继承了现有类(父类)的属性和方法。子类可以复用父类的代码,同时也可以覆盖或扩展父类的行为。继承支持代码的重用,减少了代码重复,使得程序结构更加清晰和模块化。
在Java中,继承通过
extends关键字实现,体现事物之间is-a的关系。Java中的类之间只支持单继承,接口之间支持多继承。 -
多态(Polymorphism): 多态是指同一种事物在不同情况下有不同的表现形式。多态有两种形式:静态多态(也称为编译时多态,如方法重载)和动态多态(也称为运行时多态,如方法重写)。通常我们说的多态都是指动态多态,动态多态是通过继承实现的,允许我们使用父类或接口类型的引用指向子类对象,然后调用方法时,会根据对象的实际类型来决定调用哪个类的方法实现。这样可以编写出更加灵活和可扩展的代码。
-
抽象(Abstract):抽象就是对同一类事物的共有的属性/特征、方法/功能/行为等进行抽取并归纳总结,它是一种将复杂现实简化为模型的过程,它关注的是对象的行为,而不用关注具体的实现细节。在面向对象编程中,抽象主要是通过抽象类和接口来实现的。抽象可以在不知道具体实现的情况下编程,提高了代码的灵活性和扩展性。
Animal a = new Dog();
a.eat(); //执行Dog重写的eat()
问:面向对象的基本特征是什么?或面向对象三大核心特性是什么?
答:封装、继承、多态的内容。
问:怎么理解Java中的多态机制?
2、public、protected、缺省、private的区别?
public、protected、缺省、private的可见性范围如下:
| 修饰符 | 本类 | 本包 | 其他包子类 | 其他包非子类 |
|---|---|---|---|---|
| private | √ | × | × | × |
| 缺省 | √ | √ | × | × |
| protected | √ | √ | √ | × |
| public | √ | √ | √ | √ |
相关的面试题:
问:Java中的权限修饰符有哪些,可见性范围分别是什么?见上表
问:如果希望某个成员只是本类可见,可以加什么修饰符?private
问:子类可以继承父类私有成员吗?
答:(1)从事物特征以及内存分配角度来说,会继承,即创建子类对象时,子类对象中包含父类以及本类声明的所有实例变量,无论它们是不是private修饰的。
(2)从可访问性角度来说,不会继承,即子类不能直接访问父类私有的成员,这一点也是封装性的体现。
package com.atguigu.oop.one;public class Father {private int a;int b;protected int c;public int d;public void selfMethod(){System.out.println("本类访问私有的a = " + a);System.out.println("本类访问缺省的b = " + b);System.out.println("本类访问受保护的c = " + c);System.out.println("本类访问公共的d = " + d);}
}package com.atguigu.oop.one;public class TestFather{public static void main(String[] args) {//与Father类同包Father f = new Father();
// System.out.println("本包其他类访问Father私有的a:" + f.a);//不可System.out.println("本包其他类访问Father缺省的a:" + f.b);System.out.println("本包其他类访问Father受保护的a:" + f.c);System.out.println("本包其他类访问Father公共的a:" + f.d);}
}
package com.atguigu.oop.two;import com.atguigu.oop.one.Father;public class Son extends Father {//与Father类不同包public void method(){
// System.out.println("跨包子类访问父类私有的a = " + a);//不可
// System.out.println("跨包子访问父类缺省的b = " + b);//不可System.out.println("跨包子访问父类受保护的c = " + c);System.out.println("跨包子访问父类公共的d = " + d);}
}package com.atguigu.oop.two;import com.atguigu.oop.one.Father;public class TestFatherInOtherPkg {//与Father类不同包public static void main(String[] args) {Father f = new Father();
// System.out.println("跨包其他类访问Father私有的a:" + f.a);//不可
// System.out.println("跨包其他类访问Father缺省的a:" + f.b);//不可
// System.out.println("跨包其他类访问Father受保护的a:" + f.c);//不可System.out.println("跨包其他类访问Father公共的a:" + f.d);}
}3、Java支持多继承吗?(高频plus)
- Java的类与类之间只支持单继承。
- Java的接口与接口之间支持多继承。
- Java的类支持同时实现多个接口。
相关的面试题:
问:Java中接口可以继承接口吗?可以,而且支持多继承
4、为什么Java不支持类多继承?
首先,如果一个类继承了两个含有同名方法的父类,会导致在子类中调用或重写该方法时产生歧义。这种歧义增加了代码的复杂性,并可能导致编译错误。
另外,如果不同父类拥有相同名称的成员变量,在没有清晰规则的情况下,编译器无法确定应该使用哪个成员,这增加了代码逻辑的复杂性。
5、子类继承父类时,为什么要调用父类的构造器?
构造器的作用是为实例变量进行初始化。子类对象会包含所有父类以及本类声明的实例变量,而父类声明的实例变量的初始化规则在父类的构造器中已经定义好了,子类无需也不应该重新指定规则。所以,子类应该直接调用父类的构造器来为它们完成初始化。这是代码复用性的体现。
另外,从封装性的角度来说,父类的实例变量通常是私有化的,子类无法直接访问它们,只能通过调用父类的构造器为其初始化。
相关的面试题:
问:Java中可以定义多个构造器吗?
答:可以
问:Java中构造器有返回值类型吗?
答:没有
问:Java中的构造方法是什么?
答:构造方法,又称为构造器,构造函数。
- 构造器是名称与类名完全一致,没有返回值类型的特殊方法,用于在实例化时为对象的实例变量进行初始化。
- 每一个类都有构造器,当我们没有手动编写任何构造器时,编译器将会自动给这个类添加默认的无参构造。如果我们手动编写了构造器,编译器就不会自动添加任何构造器了。
- 当然,我们可以手动定义多个重载形式的构造器。
- 构造器的修饰符只能是public、protected、缺省、private权限修饰符,不能添加其他修饰符。
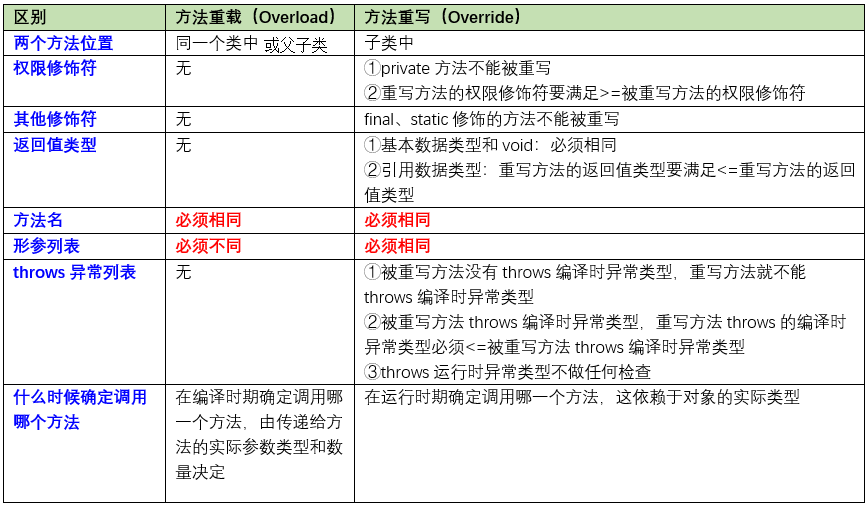
5、重载与重写有什么区别?(高频plus & 高xinplus)
相关的面试题:
问:Java支持运算符重载吗?为什么?
Java不支持运算符重载。Java的设计目的是为了提供一种简洁清晰的编程语言,避免过度使用运算符重载导致代码难以理解和维护。
问:构造器可以被重载和重写吗?构造器可以重载,但不能重写。
问:私有方法能被重载或重写吗?私有方法可以重载,但是不能重写。
问:静态方法可以被继承吗?可以。调用父类的静态方法可以通过“父类名.静态方法”,也可以通过“子类名.静态方法”
问:静态方法能被重载或重写吗?静态方法可以重载,但不能重写。子类如果定义了相同签名的静态方法,也不算重写。
class Father{public static void method(){System.out.println("Father.method");}
}
class Son extends Father{public static void method(){System.out.println("Son.method");}
}
class TestFatherSon{public static void main(String[] args){Father f = new Son();f.method();//无论子类是否有签名相同的静态方法,都只调用父类声明的静态方法,因为静态方法与实例对象无关,只看f编译时声明的类型。}
}
6、多态引用时都是编译看左边运行看右边吗?(高频plus )
public class Father {int a = 1;public static void m(){System.out.println("Father.m");}public void n(){System.out.println("Father.n");}
}public class Son extends Father{int a = 2;public static void m(){System.out.println("Son.m");}public void n(){System.out.println("Son.n");}
}
public class TestFatherSon {public static void main(String[] args) {Father f = new Son();System.out.println("f.a = " + f.a);//1f.m();//Father.mf.n();//Son.n/*多态引用遵循编译看左边运行看右边的只有调用虚方法(可能被子类重写的方法)。多态引用对于调用“对象.成员变量”的方式访问成员变量和"对象.静态方法"的方式调用静态方法,遵循只看左边的原则。*/}
}
7、多态引用调用虚方法时又有重载又有重写怎么办?(高频plus )
在Java中虚方法是指在编译阶段和类加载阶段都不能确定方法的调用入口地址,在运行阶段才能确定的方法,即可能被重写的方法。
当我们通过“对象.方法”的形式调用一个虚方法时,要如何确定它具体执行哪个方法呢?
(1)编译时静态分派:先看这个对象xx的编译时类型,在这个对象的编译时类型中找到能匹配的方法
匹配的原则:看实参的编译时类型与方法形参的类型的匹配程度
A:找最匹配 实参的编译时类型 = 方法形参的类型
B:找兼容 实参的编译时类型 < 方法形参的类型
(2)运行时动态绑定:再看这个对象xx的运行时类型,如果这个对象xx的运行时类重写了刚刚找到的那个匹配的方法,那么执行重写的,否则仍然执行刚才编译时类型中的那个匹配的方法
class MyClass{public void method(Father f) {System.out.println("father");}public void method(Son s) {System.out.println("son");}
}
class MySub extends MyClass{public void method(Father d) {System.out.println("sub--father");}public void method(Daughter d) {System.out.println("daughter");}
}
class Father{}
class Son extends Father{}
class Daughter extends Father{}
public class TestVirtualMethod {public static void main(String[] args) {Father f = new Father();Son s = new Son();Daughter d = new Daughter();MyClass my = new MySub();my.method(f);//sub--father/*(1)静态分派:看my的编译时类型MyClass,在MyClass中找最匹配的匹配的原则:看实参的编译时类型与方法形参的类型的匹配程度A:找最匹配 实参的编译时类型 = 方法形参的类型B:找兼容 实参的编译时类型 < 方法形参的类型实参f的编译时类型是Father,形参(Father f) 、(Son s)最匹配的是public void method(Father f)(2)动态绑定:看my的运行时类型MySub,看在MySub中是否有对 public void method(Father f)进行重写发现有重写,如果有重写,就执行重写的public void method(Father d) {System.out.println("sub--");}*/my.method(s);//son/*(1)静态分派:看my的编译时类型MyClass,在MyClass中找最匹配的匹配的原则:看实参的编译时类型与方法形参的类型的匹配程度A:找最匹配 实参的编译时类型 = 方法形参的类型B:找兼容 实参的编译时类型 < 方法形参的类型实参s的编译时类型是Son,形参(Father f) 、(Son s)最匹配的是public void method(Son s)(2)动态绑定:看my的运行时类型MySub,看在MySub中是否有对 public void method(Son s)进行重写发现没有重写,如果没有重写,就执行刚刚父类中找到的方法*/my.method(d);//sub--father/*(1)静态分派:看my的编译时类型MyClass,在MyClass中找最匹配的匹配的原则:看实参的编译时类型与方法形参的类型的匹配程度A:找最匹配 实参的编译时类型 = 方法形参的类型B:找兼容 实参的编译时类型 < 方法形参的类型实参d的编译时类型是Daughter,形参(Father f) 、(Son s)最匹配的是public void method(Father f)(2)动态绑定:看my的运行时类型MySub,看在MySub中是否有对 public void method(Father f)进行重写发现有重写,如果有重写,就执行重写的public void method(Father d) {System.out.println("sub--");}*/}
}
3.4 抽象类与接口
1、抽象类与接口有什么区别?(高频plus)
在面向对象编程中,特别是在Java语言中,抽象类(Abstract Class)和接口(Interface)都是用来提供一种形式的抽象和代码复用的方式。尽管它们有相似之处,但它们在设计意图和实现细节上有显著的区别。以下是抽象类和接口的一些关键区别:
| 抽象类 | 接口 | |
|---|---|---|
| 关键字 | abstract class | interface |
| 继承限制 | 单继承 | 多继承、多实现 |
| 设计意图 | 代表对事物通用特性的抽象, 可以包含属性和方法等成员 |
主要关注事物的行为, 所以它主要是方法的集合 |
| 成员 | 没限制 | 有限制 |
不允许有构造方法和初始化块(静态代码块和非静态代码块) |
||
接口成员变量默认也只能是public、static和final的,即常量。 |
||
JDK8之前只有公共的抽象方法,JDK8之后允许定义公共的静态方法和默认方法,JDK9之后允许定义private的静态或非静态方法。 |
相关的面试题:
问:抽象类与普通类有什么区别?抽象类可以包含抽象方法,不能直接实例化。普通类不能包含抽象方法,可以实例化。
问:抽象类是否可以实现接口?可以
问:抽象类是否可以继承具体类?可以
问:抽象类一定要包含抽象方法吗?不是,包含抽象方法的类必须是抽象类,但是抽象类却可以没有抽象方法。
问:抽象类能有final修饰吗?不能,因为抽象类是需要被继承的,而final修饰的类不能被继承。
问:抽象方法能定义为native的吗?不能,抽象方法不能同时定义为private,static,native,final等
问:抽象类和接口有构造器吗?抽象类有构造器,接口没有构造器。
问:接口里面都是抽象方法吗?JDK8之后不是
问:接口里面可以写方法实现吗?JDK8之后可以
问:接口默认方法和静态方法、抽象方法有什么区别?
抽象方法:没有方法体,非抽象实现类是必须重写的。
默认方法:有方法体,不冲突的情况下,默认方法的重写是可选的。
静态方法:有方法体,实现类不能继承也不能重写。
问:Java8的接口为什么新增了静态方法和默认方法?
按照之前接口中只能有抽象方法,如果接口需要更新增加新方法,那么一增加新抽象方法,就会影响所有已有的实现类,而这个新方法不见得是所有实现类必须重写的。所以Java8引入的默认方法。
之前所有和该接口实现类有关的静态方法,都专门用一个工具类来统一维护,例如:Collection接口、Map接口和Collections工具类,这样反而增加了维护成本。而静态方法本身与实例对象无关,因此直接放到对应接口中更合适。
2、接口的成员变量可以修改吗?实现类中如何访问呢?
public class SuperClass {int x = 1;
}
public interface FatherInterface {int x = 2;int y = 2;
}
public interface MotherInterface {int x = 3;
}
public class SubClass extends SuperClass implements FatherInterface,MotherInterface {public void method(){
// System.out.println("x = " + x);//模糊不清System.out.println("super.x = " + super.x);System.out.println("FatherInterface.x = " + FatherInterface.x);System.out.println("MotherInterface.x = " + MotherInterface.x);System.out.println("y = " + y);//没有重名问题,可以直接访问y = 3;//编译报错,因为接口的x,y前面默认有public static final}
}
3、接口的默认方法冲突怎么办?
public class Father {public void date(){//约会System.out.println("爸爸约吃饭");}
}
public interface Friend {default void date(){//约会System.out.println("吃喝玩乐");}
}
public interface GirlFriend {default void date(){//约会System.out.println("看电影");}
}
public class BoyOne extends Father implements Friend {@Overridepublic void date() {//(1)不重写默认保留父类的//(2)调用父类被重写的
// super.date();//(3)保留父接口的
// Friend.super.date();//(4)完全重写System.out.println("学Java");}
}
public class BoyTwo implements Friend ,GirlFriend{//不重写报错@Overridepublic void date() {//(1)保留父接口的
// Friend.super.date(); 或 GirlFriend.super.date();//(2)完全重写System.out.println("学Java");}
}
3.5 类初始化与实例初始化
类初始化:参考《jvms17.pdf》的$2.9.2和chapter5引言
- 目的:类初始化的目的是通过相关代码,在类加载后为类变量(即静态变量)进行初始化赋值操作。
- 本质:类初始化与(1)静态变量直接赋值语句(2)静态代码块中的语句有关,本质上编译器在编译过程中,会对源文件中的代码进行重组,将(1)和(2)的代码按照编写的顺序组装到一个
的类初始化方法中,在类加载后会执行这个 方法来完成类初始化过程。 - 提示:父类的
方法一定先于子类的 方法执行。一个类的 方法只会执行一次,不会重复执行。
实例初始化:参考《jvms17.pdf》的$2.9.1和$3.8
- 目的:实例初始化的目的是通过相关代码,在new对象时为实例变量(即非静态成员变量)进行初始化赋值操作。
- 本质:实例初始化与(1)super()或super(参数) (2)本类实例变量直接赋值语句(3)非静态代码块中的语句(4)构造器中除了(1)之外的语句有关。本质上编译器在编译过程中,会对源文件中的代码进行重组,将(1)(2)(3)(4)的代码组装到一个一个的
的实例化方法中,有几个构造器,就会有几个 方法。其中(2)和(3)与编写顺序有关,(1)必须在最前,(4)必须在最后。 - 提示:
- 源码中通过new调用构造器创建对象,本质上都是调用该构造器对应的
实例初始化方法完成实例初始化过程。 - 子类实例初始化的过程中,一定会依据super()或super(参数)执行父类对应的
实例初始化方法的。
1、类初始化
public class T {public static int k = 1;public static T t = new T();public static int n = 99;static{System.out.println("静态块:k=" + k + ", n=" + n);}public int j = 100;{System.out.println("构造块:k=" + k + ", n=" + n + ", j=" + j);}public T(){System.out.println("构造器:k=" + k + ", n=" + n +",j=" + j);}public static void main(String[] args) {}
}
2、实例初始化
public class Father {private int a;public Father() {System.out.println("(1)Father类的无参构造");}public Father(int a) {this.a = a;System.out.println("(2)Father类的有参构造");}{System.out.println("(3)Father类的非静态代码块");}static{System.out.println("(4)Father类的静态代码块");}
}
public class Son extends Father{private int b;public Son() {System.out.println("(5)Son类的无参构造");}public Son(int a, int b) {this.b = b;System.out.println("(6)Son类的有参构造");}{System.out.println("(7)Son类的非静态代码块");}static{System.out.println("(8)Son类的静态代码块");}
}
public class TestFatherSon {public static void main(String[] args) {Son s1 = new Son();Son s2 = new Son(1,2);}
}
3.6 this和super关键字
1、this和super有什么区别?(高频plus)
| this | super | |
|---|---|---|
| 代表意义 | 当前对象 | 让当前对象在子类中去直接使用父类声明的成员 (隐含但不能这么写 super = this.super) |
| 能否在静态方法/静态代码块中使用 | 不可以 | 不可以 |
| 引用成员变量 | this.成员变量 当局部变量与成员变量重名时,在成员变量前面加this.,不重名,不用加。 |
super.成员变量 当子类与父类非私有的成员变量重名时,在父类成员变量前面加super.,不重名,不用加。 |
| 引用成员方法 | this.成员方法 在本类中调用当前对象的任何方法,都可以省略this.。 |
super.成员方法 当子类重写了父类的成员方法,在子类中又想要调用父类被重写的方法时,需要加super.。如果子类没有重写父类的方法,在子类中可以直接调用父类非私有方法,不需要加super.。 |
| 引用构造器 | this()或this(实参列表) 在本类的一个构造器中调用本类的另一个构造器,必须在构造器首行。 |
super()或super(实参列表) 在子类构造器首行,用于调用直接父类的构造器。如果没写,默认是super(); |
| 其他 | 外部类名.this.成员 当非静态内部类与外部类的成员重名时,可以在非静态内部类中使用该形式。 |
父接口名.super.默认方法 当父类与父接口,或两个父接口的方法签名冲突时,可以用它明确调用哪个父接口的默认方法。 |
| 找寻成员范围 | 除构造器外,所有this.后面的成员,都会先从本类开始找,如果本类没有找到,会继续追溯到父类。 | 除构造器外,所有super.后面的成员,都会先从直接父类开始找,如果直接父类没有找到,会继续追溯父类的父类。 |
提示:
(1)虽然不重名的情况下,通过this也可以调用父类非私有的成员,但是从可读性角度来说,还是建议用super来引用父类声明的成员
(2)就像阿里规范中明确说明的那样,不建议子父类声明同名的成员变量

2、子父类成员变量重名的问题?
提示:阿里规范中明确说明的那样,不建议子父类声明同名的成员变量
案例1
class Father{int x = 10;public Father(){this.print();x = 20;}public void print(){System.out.println("Father.x = " + x);}
}
class Son extends Father{int x = 30;public Son(){this.print();x = 40;}public void print(){System.out.println("Son.x = " + x);}
}
public class TestFatherSon {public static void main(String[] args) {Father f = new Son();System.out.println("f.x = " + f.x);}
}
案例2
class Father{private String info = "atguigu";public void setInfo(String info){this.info = info;}public String getInfo(){return info;}
}
class Son extends Father{private String info = "尚硅谷";public void test(){System.out.println(this.getInfo());System.out.println(super.getInfo());}
}public class Test{public static void main(String[] args) {Father f = new Father();Son s = new Son();System.out.println(f.getInfo());System.out.println(s.getInfo());s.test();System.out.println("-----------------");s.setInfo("大硅谷");System.out.println(f.getInfo());System.out.println(s.getInfo());s.test();}
}
案例3
class Father{private String info = "atguigu";public void setInfo(String info){this.info = info;}public String getInfo(){return info;}
}
class Son extends Father{private String info = "尚硅谷";public void setInfo(String info){this.info = info;}public String getInfo(){return info;}public void test(){System.out.println(this.getInfo());System.out.println(super.getInfo());}
}
public class Test{public static void main(String[] args) {Father f = new Father();Son s = new Son();System.out.println(f.getInfo());System.out.println(s.getInfo());s.test();System.out.println("-----------------");s.setInfo("大硅谷");System.out.println(f.getInfo());System.out.println(s.getInfo());s.test();}
}
3、内部类可以使用外部类的私有成员吗?重名了怎么办?
内部类可以使用外部类的成员,包括私有化的。具体来说的话,非静态内部类可以直接使用外部类的所有成员,但是静态内部类只能使用外部类的静态成员。
| 内部类 | 外部类的成员 | 直接操作 | 重名问题 | |
|---|---|---|---|---|
| 1 | 静态内部类 | 静态成员 | √ | 外部类名.静态成员 |
| 2 | 静态内部类 | 非静态成员 | × | |
| 3 | 非静态内部类 | 静态成员 | √ | 外部类名.静态成员 |
| 4 | 非静态内部类 | 非静态成员 | √ | 外部类名.this.非静态成员 |
3.7 final关键字
1、final关键字有哪些用法?(高频plus)
| 形式 | 作用 |
|---|---|
| final修饰类 | 该类不能被继承 |
| final修饰方法 | 该方法不能被重写 |
| final修饰变量 | 该变量的值不能被修改 |
相关的面试题:
问:final和abstract可以一起使用吗?不能
问:final可以修饰抽象类吗?不能
问:final可以修饰native方法吗?可以
问:final可以修饰static方法吗?可以,但一般不这么做
问:final可以修饰构造器吗?不可以
问:实例变量可以加final吗?可以,但必须手动初始化
问:成员变量加final,一定要同时加static吗?不是
2、final、finally、finalilze有什么区别?
- final是修饰符关键字,修饰类表示不能被继承,修饰方法表示不能被重写,修饰变量表示值不能被修改。
- finally也是关键字,需要与try-catch结构一起使用,用于编写无论是否发生异常,以及异常是否能被捕获都要执行的语句块,通常编写资源释放的代码。JDK7引入try-catch-with-resource,可以实现自动关闭try()中资源。
- finalize是一个Object类的方法名,在JDK9版本已经废弃了,之前用于编写对象被GC回收之前需要执行的代码,通常用于资源类释放所占用的系统资源。
3.8 特殊类型
1、什么是枚举类型?枚举类与普通类有什么区别?(高频plus)
Java中的枚举使用enum关键字定义,它是一种特殊的数据类型,用于定义一组常量,例如星期、月份、颜色等,它提供了一种更简洁、可读性更好的方式来表示一组相关的常量。
| 类 | 枚举 | |
|---|---|---|
| 定义关键字 | class | enum |
| 继承关系 | 可以继承其他类 | 不能继承,默认直接父类是Enum |
| 子类 | 可以有子类 | 不能有子类 |
| 构造器 | 四种权限修饰符 | private |
| 实例化 | 需要的地方new | 枚举常量就是枚举类型的实例 |
| 字段 | 可以有自己的字段 | 可以有自己的字段,一般情况字段都建议用final修饰 |
| 方法 | 可以有自己的方法 | 可以有自己的方法 |
| 比较 | 一般用equals方法进行比较 | 使用==进行比较即可 |
| 用途 | 封装数据和行为,实现复杂的功能 | 表示一组相关的常量 |
2、枚举类的对象可以修改吗?
枚举的常量对象实际上是枚举类的静态实例,它们是在编译时就确定的,固定的,在运行时不可修改的。
public enum Color {RED,GREEN,BLUE;
}
但是枚举常量对象的字段值是可以修改的,比如:颜色枚举类的chineseName属性值,可以有set方法。
public enum Color {RED("红色"),GREEN("绿色"),BLUE("蓝色");private String chineseName;Color(String chineseName) {this.chineseName = chineseName;}public String getChineseName() {return chineseName;}public void setChineseName(String chineseName) {this.chineseName = chineseName;}
}
但是实际开发中不会这么做,而是给枚举类中的字段加final修饰,限制对齐进行修改,例如:private final String chineseName;
3、记录类和普通类有什么区别?
记录类在JDK14、15预览特性,在JDK16中转正。
记录类是一种全新的类型,它本质上是一个 final类,同时所有的属性都是 final修饰,它会自动编译出get、hashCode 、比较所有属性值的equals、toString 等方法,减少了代码编写量。使用 Record 可以更方便的创建一个常量类。
- 记录类需要用关键字record声明;
- 记录类只会有一个全参构造;
- 可以在记录类声明的类中定义静态字段、静态方法或实例方法;
- 不能在记录类中定义实例字段;
- 不能显式的声明父类,默认父类是java.lang.Record类;
public record Triangle(double a, double b, double c) {public double area() {if (a > 0 && b > 0 && c > 0 && a + b > c && b + c > a && a + c > b) {double p = (a + b + c) / 2;return Math.sqrt(p * (p - a) * (p - b) * (p - c));}return 0.0;}public double perimeter() {if (a > 0 && b > 0 && c > 0 && a + b > c && b + c > a && a + c > b) {return a + b + c;}return 0.0;}
}
4、密封类和普通类有什么区别?
其实很多语言中都有密封类的概念,在Java语言中,也早就有密封类的思想,就是final修饰的类,该类不允许被继承。而从JDK15开始,针对密封类进行了升级,最终在JDK17转正。密封类用于限制超类的使用,密封的类和接口限制其他可能继承或实现它们的其他类或接口。
- 密封类或接口必须用 sealed 修饰符来修饰;
- sealed修饰的类或接口必须有子类或实现类,需要通过 permits 关键字来指定可以继承或实现该类/接口的类型有哪些;
- 一个类继承密封类或实现密封接口时,该类必须是sealed、non-sealed、final修饰的;
【修饰符】 sealed class 密封类 【extends 父类】【implements 父接口】 permits 子类{}
【修饰符】 sealed interface 接口 【extends 父接口们】 permits 实现类{}
示例:
sealed class Graphic permits Circle,Rectangle, Triangle {}
final class Triangle extends Graphic{}
non-sealed class Circle extends Graphic{}
sealed class Rectangle extends Graphic permits Square{}
final class Square extends Rectangle{}
3.9 注解
1、一些基础注解的作用?
-
@Override 注解:用于标记那些重写的方法。重写方法加上@Override注解有两个好处:(1)可读性更好(2)编译器可以对方法做严格的格式校验,看是否违背重写的要求。当然,如果一个方法正确重写的情况下,加不加@Override都不会影响重写的本质。
-
@Deprecated 注解:用于标记那些已经过时或不再推荐使用的类、方法、字段或其他程序元素。使用 @Deprecated 注解可以帮助开发者识别和避免使用这些过时的元素,从而提高代码的质量和可维护性。
-
@SuppressWarnings注解:用于抑制编译器警告,比如未使用的变量、泛型类型的未经检查的转换等。需要指定要忽略的警告类型。
-
@FunctionalInteface注解:用于标记函数式接口。
-
@NotNull 注解:用于指示某个参数、返回值或字段不能为 null。它有助于静态分析工具(如IDE)检测潜在的空指针异常。
-
@Serial 注解:仅适用于序列化相关的成员变量或方法。它用于标记与序列化过程有关的元素,通常出现在实现 Serializable 接口的类中。
2、Java中常用的元注解有哪些?
这些元注解在定义自定义注解时非常有用,可以帮助你更好地控制注解的行为和生命周期。
- @Retention:指定注解的保留策略。有3种策略:
- RetentionPolicy.SOURCE:注解仅保留在源代码级别,编译时会被丢弃。
- RetentionPolicy.CLASS:注解保留在编译后的字节码中,但在运行时不可用。
- RetentionPolicy.RUNTIME:注解保留在编译后的字节码中,并且在运行时可以通过反射访问。
- @Target:指定注解可以应用的程序元素类型。例如:类型、字段、方法、构造器、局部变量、包等,它们由ElementType枚举类定义。
- @Documented:指定注解应该被包含在JavaDoc中。
- @Inherited:指定注解可以被子类继承。
- @Repeatable:是Java 8引入的一个元注解,指定注解可以在同一个程序元素上多次出现。
- @Native:指示注解的值可以安全地传递给本地方法。这是一个内部注解,通常不用于自定义注解。
import java.lang.annotation.*;@Repeatable(AuthorList.class)
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface Author {//可重复注解String value();
}
import java.lang.annotation.*;@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface AuthorList {//可重复注解的容器注解Author[] value();
}
import java.lang.annotation.*;@Inherited //可以被子类继承
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface MyAnnotation { //普通注解String value();int num() default 0;
}
@Author("尚硅谷")
@Author("atguigu")
@MyAnnotation(value="老父亲",num=8)
public class Father {
}
public class Son extends Father{
}public class TestAnnotation {public static void main(String[] args) {Class<Son> clazz = Son.class;MyAnnotation ma = clazz.getAnnotation(MyAnnotation.class);//从父类继承的注解System.out.println("ma.num() = " + ma.num());System.out.println("ma.value() = " + ma.value());//读取可重复注解Class<Father> fc = Father.class;AuthorList list = fc.getAnnotation(AuthorList.class);Author[] authors = list.value();for (Author author : authors) {System.out.println("author.value() = " + author.value());}}
四、面向对象进阶面试题(59题/135题)
4.1 异常(5题)
1、Error和Exception有什么区别?
Throwable 类是 Java 语言中所有错误或异常的超类。两个子类的实例,Error 和 Exception,通常用于指示发生了异常情况。通常,这些实例是在异常情况的上下文中新近创建的,因此包含了相关的信息(比如堆栈跟踪数据)。
Error 表示严重的系统级问题,通常是不可恢复的,例如虚拟机故障、内存不足等。这些问题通常不在应用程序的控制范围内,也不应该由应用程序处理。捕获 Error 只是为了记录日志或进行一些清理工作。示例:
OutOfMemoryError:内存不足。StackOverflowError:栈溢出。NoClassDefFoundError:找不到类定义。
Exception 表示程序在运行过程中可以预见的异常情况,这些异常通常是由于程序逻辑错误或外部条件引起的,可以通过适当的处理来恢复程序的正常运行。Exception 可以被捕获和处理,通常使用 try-catch 块来处理异常。如果一个方法可能会抛出 Exception,那么调用该方法的代码必须通过 try-catch 块捕获异常,或者在方法签名中使用 throws 关键字声明该方法可能抛出的异常。
2、Java异常有哪些分类?(高频plus)
在Java中,异常(Exception)是程序执行过程中发生的一些意外情况,这些情况会中断程序的正常流程。Java中的异常分为两大类:受检异常(Checked Exceptions)和非受检异常(Unchecked Exceptions)。此外,还有错误(Errors)。
(1)受检异常(Checked Exceptions)
- 定义:受检异常是指在编译时必须被处理的异常,又被称为编译时异常。如果一个方法可能会抛出受检异常,那么调用该方法的代码必须通过
try-catch块捕获异常,或者在方法签名中使用throws关键字声明该方法可能抛出的异常。 - 继承关系:受检异常继承自
Exception等RuntimeException(含其子类)的其他异常类。 - 示例:IOException、SQLException、ClassNotFoundException
(2)非受检异常(Unchecked Exceptions)
- 定义:非受检异常是指在编译时不需要强制处理的异常,又被称为运行时异常。这些异常通常是由于编程错误引起的,如空指针异常、数组越界等。
- 继承关系:非受检异常继承自
RuntimeException类。 - 示例:NullPointerException、ArrayIndexOutOfBoundsException、IllegalArgumentException
相关的面试题:
问:运行时异常和编译时异常有什么区别?
问:受检异常和非受检异常有什么区别?
3、Java中常见的异常有哪些?(高频plus)
(1)受检异常(Checked Exceptions)
-
IOException输入/输出操作失败或中断异常- 子类:
FileNotFoundException文件找不到异常、EOFException到达文件末尾异常、SocketException网络通信中断异常
- 子类:
-
SQLException与数据库操作相关的异常- 子类:
DataTruncation数据截断抛出、BatchUpdateException批处理更新失败异常
- 子类:
-
ClassNotFoundException类找不到异常 -
InterruptedException线程中断异常
(2)非受检异常(Unchecked Exceptions)
NullPointerException空指针异常ArrayIndexOutOfBoundsException数组下标越界异常IllegalArgumentException:非法参数异常IllegalStateException:对象状态不合法异常NumberFormatException:数字格式化异常ArithmeticException:算术异常ClassCastException:类型转换异常UnsupportedOperationException:不支持当前操作异常InputMismatchException:输入不匹配异常
(3)错误(Errors)
OutOfMemoryError:堆内存不足时抛出。常见场景:内存泄漏或大量数据处理。StackOverflowError:调用栈深度超过限制时抛出。常见场景:递归调用过深。NoClassDefFoundError:运行时找不到类定义时抛出。常见场景:类路径配置错误或类加载问题。LinkageError:类链接失败时抛出。常见场景:类加载冲突或版本不一致。
相关面试题:
问:Java中常见的运行时异常有哪些?
问:Java中常见的错误有哪些?
4、什么时候会发生空指针异常?
当一个变量的值为null是,在Java里面表示一个不存在的空对象,没有实际内容,没有给它分配内存。所以,此时你调用这个“对象”的方法等成员时,就会出现空指针异常。
5、你知道哪些避免空指针异常的方法?
如下是一些常见示例场景:
(1)字符串比较:常量放前面
if("atguigu".equals(字符串变量))
(2)在对象初始化的时候给它一个默认值
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
Object[] elementData;
无参构造器中:
elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
(3)返回空集合
public List getUserList(){List list = userMapper.getUserList();return list == null ? new ArrayList() : list;
}
(4)Optional
Optional是JDK8新增的新特性,再也不用 != null来判断了,这个子啊一个对象里面的多个子对象连续判断的时候非常有用。
public static User getUser() {List<User> users = userMapper.getUserList();return Optional.ofNullable(Optional.ofNullable(users).orElse(new ArrayList<>()).get(0)).orElse(new User());}
(5)两个对象比较相等,使用Objects工具类的equals方法
Objects的equals(对象1,对象2)
6、使用try-catch会影响性能吗?(高频plus & 高xinplus)
一般情况下,try-catch块的执行时间很短,不会对性能产生显著的影响。
但是在极端情况下,try-catch块的使用可能会对性能产生影响,例如高并发时,代码中频繁地抛出和捕获异常可能会成为瓶颈。阿里的开发手册中有如下异常处理的相关规约:

7、try-catch-finally中哪个部分可以省略?
try后面的catch或finally都可能出现省略的情况。
省略finally:
try(FileInputStream fis = new FileInputStream("文件路径名");){业务代码
}catch(IOException e){异常处理代码
}
省略catch和finally:
public void method()throws IOException{try(资源类对象){业务代码}
}
8、Java可以一次catch多个异常吗?
try{//尚硅谷出品}catch(IOException | SQLException | ClassNotFoundException e){//异常处理代码}
9、在循环里try-catch还是循环外面try-catch?
import java.util.Random;public class LoopTryCatch {public static void main(String[] args) {Random random = new Random();for (int i = 1; i <= 5; i++) {try {int num = random.nextInt(0, 2);System.out.println(i + "/" + num + " = " + i / num); //本次循环异常,不影响下一次循环} catch (ArithmeticException e) {System.out.println("除数为0");}}System.out.println("=======================");try {for (int i = 1; i <= 5; i++) {int num = random.nextInt(0, 2);System.out.println(i + "/" + num + " = " + i / num);//一旦发生异常,循环就结束了}} catch (ArithmeticException e) {System.out.println("除数为0");}}
}
10、throw和throws的区别?
在Java编程语言中,throw 和 throws 都与异常处理相关,但它们的用途和语法有着明显的区别:
(1)throw
throw是一个关键字,用于在代码中显式地抛出一个异常。- 它后面跟着一个异常对象,这个对象通常是某个异常类的实例。
throw通常出现在方法体内部,当特定条件满足时执行。- 使用
throw抛出异常会立即终止当前方法的执行,并将控制权转移到调用栈上的上一层,寻找适当的异常处理器(如catch块)。
(2)throws
throws也是一个关键字,但它用于方法的声明部分,而不是方法体内部。- 它后面跟着一个或多个异常类的名称,这些异常是方法可能抛出的,用逗号分隔。
- 当一个方法不能或不应该处理它内部发生的某些异常时,可以使用
throws来声明这些异常,这样调用者必须处理这些异常,要么捕获处理,要么继续声明抛出。 throws提供了对调用者的一种合同,表明方法可能抛出哪些类型的异常,使调用者能够做出相应的准备。
总结来说:
throw用于抛出具体的异常对象,它意味着一个异常正在发生。throws用于声明方法可能抛出的异常类型,它意味着如果在方法内部发生这些异常,方法本身不会处理它们,而是将它们抛给调用者。
11、try-catch和throws该如何选择?(高频plus)
如果当前方法无法明确处理的异常,请将该异常抛给它的调用者,通过throws声明处理,让调用者能够做出相应的准备。但是在最外层的业务使用者必须使用try-catch处理,并将其转化为用户可以理解的内容。

12、finally和return(高频plus)

案例1
public class FinallyReturnDemo1{public static void main(String[] args) {int test = test(3,5);System.out.println(test);}public static int test(int x, int y){int result = x;try{if(x<0 || y<0){return 0;}result = x + y;return result;}finally{result = x - y;}}
}
案例2
public class FinallyReturnDemo2 {static int i = 0;public static void main(String[] args) {System.out.println(test());}public static int test(){try{return ++i;}finally{return ++i;}}
}
13、try-catch-with-resource是什么?
try-catch-with-resources 是 Java 7 引入的一种异常处理机制,它确保每个资源在使用完毕后都能被关闭。这里所说的资源指的是实现了 java.lang.AutoCloseable 接口的对象,比如IO流、网络连接、数据库连接等。
主要特点:
- 自动关闭资源:不再需要显式调用 close() 方法。
- 简化代码:减少了 try-catch-finally 结构的复杂度。
- 异常处理:如果 try 块中抛出异常,且资源关闭时也抛出异常,则资源关闭时抛出的异常会被抑制(suppressed),并添加到原始异常中。
import org.junit.Test;import java.io.*;public class TryCatchWithResource {@Testpublic void test1()throws Exception{copy("d:\\1.txt","d:\\2.txt");}public void copy(String srcFilePath,String destFilePath){FileInputStream fis = null;BufferedInputStream bis = null;FileOutputStream fos = null;BufferedOutputStream bos = null;try {fis = new FileInputStream(srcFilePath);bis = new BufferedInputStream(fis);fos = new FileOutputStream(destFilePath);bos = new BufferedOutputStream(fos);byte[] data = new byte[1024];int len;while ((len = bis.read(data)) != -1) {bos.write(data, 0, len);}}catch (IOException e){e.printStackTrace();}finally {try {if(bos != null) {bos.close();}} catch (IOException e) {e.printStackTrace();}try {if(fos != null) {fos.close();}} catch (IOException e) {e.printStackTrace();}try {if(bis != null) {bis.close();}} catch (IOException e) {e.printStackTrace();}try {if(fis != null) {fis.close();}} catch (IOException e) {e.printStackTrace();}}}@Testpublic void test2()throws Exception{copyUseNewTry("d:\\1.txt","d:\\2.txt");}public void copyUseNewTry(String srcFilePath,String destFilePath){try (FileInputStream fis = new FileInputStream(srcFilePath);BufferedInputStream bis = new BufferedInputStream(fis);FileOutputStream fos = new FileOutputStream(destFilePath);BufferedOutputStream bos = new BufferedOutputStream(fos);){byte[] data = new byte[1024];int len;while ((len = bis.read(data)) != -1) {bos.write(data, 0, len);}}catch (IOException e){e.printStackTrace();}}
}4.2 基础API(5题)
1、Math.round(1.5)和Math.round(-1.5)是多少?(高频plus)
public class TestMath {public static void main(String[] args) {System.out.println(Math.round(1.5));//2System.out.println(Math.round(-1.5));//-1// round(x) 等价于 (int)(x + 0.5)}
}
相关的面试题:
问:Math.floor(x),Math.ceil(x),Math.round(x)的区别
Math.floor(x):向下取整,Math.floor(2.4) 与 Math.floor(2.6)都是2.0,Math.floor(-2.4) 与 Math.floor(-2.6)都是-3.0
Math.ceil(x):向上取整,Math.ceil(2.4) 与 Math.ceil(2.6)都是3.0,Math.ceil(-2.4) 与 Math.ceil(-2.6)都是-2.0
Math.round(x):接近于四舍五入,本质上是 (int)(x + 0.5)向下取整。Math.round(2.4)是2,Math.round(2.6)是3,Math.round(-2.4)是-2,Math.round(-2.6)是-3,Math.round(1.5)是2,Math.round(-1.5)是-1。
2、Java怎么获取当前系统时间戳?
相关的面试题:
问:Java怎么统计一段代码的耗时?
public class TestTime {public static void main(String[] args) {long start = System.currentTimeMillis();//代码long end = System.currentTimeMillis();System.out.println("耗时:" + (end-start) +"毫秒");}
}
3、LocalDateTime和Date的区别?(高频plus)
- Date是Java早期版本中的日期类位于java.util包中。LocalDateTime是Java8引入的新日期时间API的一部分,位于java.time包中。
- Date 表示特定的瞬间,精确到毫秒,通常用于表示时间戳。LocalDateTime 表示不带时区的日期和时间,包括年、月、日、时、分、秒和纳秒。
- Date是线程不安全的,Date对象是可变的,可以通过方法修改其值。LocalDateTime是线程安全的,LocalDateTime对象是不可变的,所有操作都会返回一个新的 LocalDateTime 实例。
- Date格式化用SimpleDateFormat,LocalDateTime 的格式化用DateTimeFormatter,支持的方式更多。
import java.text.SimpleDateFormat;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.time.format.FormatStyle;
import java.util.Date;public class TestDate {public static void main(String[] args) {Date date = new Date();System.out.println(date);date.setTime(123456789L);//修改Date对象System.out.println(date);SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String dateStr = sf.format(date);//格式化System.out.println(dateStr);System.out.println("==================");LocalDateTime now = LocalDateTime.now();System.out.println(now);LocalDateTime future = now.plusDays(100);System.out.println(future);DateTimeFormatter df = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.FULL).withZone(ZoneId.of("Asia/Shanghai"));String datetimeStr = df.format(future);System.out.println(datetimeStr);}
}
相关面试题:
问:为什么要引入第三代日期时间类?
答:
第一代:Date日期时间类,及其格式化工具SimpleDateFormat
第二代:Calendar日历类,TimeZone时区类
第三代:LocalDate、LocalTime、LocalDateTime、ZonedDateTime、Instant、Period、Duration、及其格式化工具DateTimeFormatter等等
第1代和第2代的日期时间类有如下一些问题:
(1)使用不方便
(2)对象可变性
(3)线程不安全
(4)没有考虑闰秒
4、Java日期格式中YYYY与yyyy的区别?
在Java日期格式中,YYYY 和 yyyy 有以下区别:
yyyy:
- 表示日历年。
- 用于表示标准的日历年份,通常是我们日常生活中使用的年份,一年从1月1日到12月31日。
- 例如,2023年10月1日的格式化字符串为 "2023-10-01"。
YYYY:
- 表示周历年。
- 周历年是指根据ISO 8601标准定义的年份。一周从周日开始,周六结束,只要本周跨年,出现新年的1月1日,那么这周就算入下一年。
- 这种年份可能会与日历年有所不同,特别是在年初和年末。
- 例如,2022-12-31是2022年最后一周的,但2023年12月31日是2024年的第1周。
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;public class TestYYYY {public static void main(String[] args) {ArrayList<LocalDate> list = new ArrayList<>();list.add(LocalDate.of(2022,12,31));list.add(LocalDate.of(2023,12,31));for (LocalDate datetime : list) {DateTimeFormatter df = DateTimeFormatter.ofPattern("日历年:yyyy,周历年:YYYY,第w周");String datetimeStr = df.format(datetime);System.out.println(datetimeStr);}}
}
5、Java的根父类是谁,都有哪些方法?
Java的根父类是Object,包含如下方法:
| 方法 | 概述 |
|---|---|
public String toString() |
在Object类中默认返回对象的运行时类型@对象的hashCode十六进制值。建议实体Javabean重写。 |
public final native Class<?> getClass() |
返回当前对象的运行时类型。 |
public native int hashCode() |
返回当前对象的hash值。 |
public boolean equals(Object obj) |
比较当前对象与指定对象obj是否相等。在Object类中默认比较地址值(等价于==)。equals和hashCode方法要一起重写。 |
protected native Object clone() throws CloneNotSupportedException |
克隆当前对象。子类如果要在子类外部使用克隆功能,必须实现java.lang.Cloneable接口,并重写该方法。 |
protected void finalize() throws Throwable |
当当前对象被GC回收时,自动由GC调用。该方法从JDK9之后已被废弃。 |
public final native void wait(long timeoutMillis) throws InterruptedException |
当前对象作为同步锁对象,执行该方法,使得当前线程进入阻塞状态,并是否同步锁对象和CPU资源。直到时间到,或当前线程被其他唤醒。 |
public final void wait(long timeoutMillis, int nanos) throws InterruptedException |
当前对象作为同步锁对象,执行该方法,使得当前线程进入阻塞状态,并是否同步锁对象和CPU资源。直到时间到,或当前线程被其他唤醒。 |
public final void wait() throws InterruptedException |
当前对象作为同步锁对象,执行该方法,使得当前线程进入阻塞状态,并是否同步锁对象和CPU资源。直到当前线程被其他唤醒。 |
public final native void notify() |
唤醒其中一个等待被唤醒的线程,而且只能唤醒以当前对象为同步锁对象的等待线程。 |
public final native void notifyAll() |
唤醒所有等待被唤醒的线程,并且这些线程也以当前对象为同步锁对象。 |
6、equals和hashCode的区别和联系?(高频plus & 高xinplus )
equals方法用于比较两个对象是否相等,hashCode方法用于返回对象的哈希值,这两个方法必须一起重写,而且选择的属性必须一致,因为:
hashCode方法必须遵循:
(1)如果进行 equals 比较时所用的信息没有被修改,那么同一对象多次调用 hashCode 方法时,必须结果一致。
(2)如果两个对象 equals为true,那么它们的 hashCode值也必须相同。
(3)如果两个对象 equals为false,那么它们的 hashCode值同或不同都可以。当然不同可以提高哈希表的性能。
另外,equals方法必须遵循:
(1)自反性:x不为null,那么x.equals(x)必须为true。
(2)对称性:x,y不为null,y.equals(x)与x.equals(y)结果必须相同。
(3)传递性:x,y,z不为null,如果x.equals(y)true && y.equals(z)true,那么x.equals(z)应返回true。
(4)一致性:x,y不为null且x和y用于eqauls比较的属性值也没有修改,那么多次调用x.equals(y)结果必须一致。
(5)如果x不为null,x.equals(null)必须返回 false。
问:两个对象的equals方法相等,hashCode方法也会相等吗?
答:对
问:两个对象的hashCode方法相等,equals方法也会相等吗?
答:不对
问:为什么重写equals就要重写hashCode?
答:因为hashCode必须遵循上述3条常规协定,这些规定是为
HashMap、HashSet等基于哈希的集合类型提供正确行为的基础。如果不遵守这个约定,对象在使用这些集合类型时可能会表现出不可预测的行为。
7、hashCode和identityHashCode的区别?
在Java中,identifyHashCode和hashCode都用于获取对象的哈希码,但它们之间有一些区别:
-
identifyHashCode是System.identityHashCode方法,它返回的是对象的本身的哈希码,这个值对于不同的对象是唯一的,即使两个对象的内容完全相同,可以理解为对象的内存地址(但本质上是不是对象的内存地址与JVM的底层实现有关,不同的JVM实现方式不同)。
-
hashCode是Object类的一个方法,它也返回对象的哈希码,但是通常在自定义类中需要重写这个方法以保证满足哈希码的一些规则,如果两个对象通过equals方法比较为true,那么它们的hashCode应该相同。
import java.util.Objects;public class Student {private String name;private int score;public Student(String name, int score) {this.name = name;this.score = score;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return score == student.score && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(name, score);}
}
public class TestHashCode {public static void main(String[] args) {Student s1 = new Student("尚硅谷",96);Student s2 = new Student("尚硅谷",96);System.out.println("s1.hashCode()=" + s1.hashCode());System.out.println("s2.hashCode()=" + s2.hashCode());System.out.println("s1.identityHashCode = " + System.identityHashCode(s1));System.out.println("s2.identityHashCode = " + System.identityHashCode(s2));}
}
相关的面试题:
问:IdentityHashMap和HashMap的区别?
答:取key的哈希值时分别identifyHashCode方法和hashCode方法。
8、Comparable和Comparator接口的区别?
| Comparable |
Comparator |
|
|---|---|---|
| 称呼 | 自然比较接口 | 定制比较器接口 |
| 谁实现它 | 哪个类的对象要比较大小,哪个类实现它 | 单独的类(通常是匿名内部类)实现它 |
| 抽象方法 | int compareTo(T t) | int compare(T t1, T t2) |
| 示例 | String等字符串,Integer等包装类,LocalDate等日期类,.... | 字符串比较器Collator |
import lombok.AllArgsConstructor;
import lombok.Data;@Data
@AllArgsConstructor
public class Employee implements Comparable<Employee>{private int id;private String name;private double salary;@Overridepublic int compareTo(Employee o) {return id-o.id;}
}
import java.util.Comparator;public class TestEmployee {public static void main(String[] args) {Employee e1 = new Employee(1,"谷姐",15000);Employee e2 = new Employee(2,"谷哥",15000);System.out.println(e1.compareTo(e2));Comparator<Employee> c = new Comparator<Employee>() {@Overridepublic int compare(Employee o1, Employee o2) {return Double.compare(o1.getSalary(),o2.getSalary());}};System.out.println(c.compare(e1,e2));}
}9、什么是包装类型?有什么用?
在Java中,包装类型(Wrapper Classes)是基本数据类型(Primitive Types)的引用类型封装。因为Java是一种面向对象编程的高级语言,但是8种基本数据类型存在无法实现面向对象编程的问题,所以,Java为每个基本数据类型都设计了对应的包装类。
| 序号 | 基本数据类型 | 包装类(java.lang包) |
|---|---|---|
| 1 | byte | Byte |
| 2 | short | Short |
| 3 | int | Integer |
| 4 | long | Long |
| 5 | float | Float |
| 6 | double | Double |
| 7 | char | Character |
| 8 | boolean | Boolean |
应用场景:
- 包装类型允许你将基本数据类型(如
int、boolean等)转换为对象,从而可以将这些值存储在集合(如List、Set、Map)中,因为集合只能存储对象,不能存储基本数据类型。 - 基本数据类型不能支持null值
- 如果把属性设置为基本数据类型,例如:int,那么其默认值是0,而默认值0和手动赋值的0没法区分
- 如果把某些方法的形参设置为基本数据类型,例如:method(int a),那么调用方法必须传入一个具体的整数值,如果改为method(Integer a),那么调用方法时可以传入null值
10、什么是自动装箱、拆箱?
Java 5 引入了自动装箱(Autoboxing)和自动拆箱(Unboxing)功能,这使得在基本数据类型和包装类型之间转换变得更加方便。
- 自动装箱:将基本数据类型自动转换为对应的包装类型。
- 自动拆箱:将包装类型自动转换为对应的基本数据类型。
示例:
Integer boxedValue = 10; // 自动装箱
int unboxedValue = boxedValue; // 自动拆箱
但是需要注意,自动装箱与拆箱只支持对应类型之间。
Double d = 1;//编译报错,1是int类型,不是double类型
11、int和Integer、BigInteger有什么区别?(高频plus)
| int | Integer | BigInteger | |
|---|---|---|---|
| 类型 | 基本数据类型(Primitive Type) | 包装类型(Wrapper Class),位于java.lang包 |
不可变的任意精度整数类,位于 java.math 包 |
| 范围 | 范围是从 -2,147,483,648 到 2,147,483,647 | 范围是从 -2,147,483,648 到 2,147,483,647 | 理论上无限制,取决于可用内存 |
| 适用 | 适用于大多数整数运算,性能较高,因为它是基本类型,不需要对象开销 | 用于将 int 转换为对象。 提供了许多有用的静态方法,如 parseInt、valueOf 等。 支持空值(null) |
用于处理超出 int 和 long 范围的大整数。 提供了许多数学运算方法,如加法、减法、乘法、除法、幂运算等。 支持高精度计算。 |
12、IntegerCache类有什么用?
IntegerCache类的基本概念和作用
缓存机制:IntegerCache类在Java中用于缓存-128到127之间的整数对象。当通过自动装箱将int类型转换为Integer类型时,如果值在这个范围内,Java会直接从缓存中返回已存在的对象,而不是创建一个新的Integer实例。这样可以显著减少内存的使用,并提高性能。
实现方式:IntegerCache类通过在类加载时创建一定数量的Integer对象,并将它们存储在一个静态数组中。这样,当需要创建这些范围内的Integer对象时,可以直接从缓存中获取,避免了重复创建对象的开销。
| 包装类 | 缓存对象 |
|---|---|
| Byte | -128~127 |
| Short | -128~127 |
| Integer | -128~127 |
| Long | -128~127 |
| Float | 没有 |
| Double | 没有 |
| Character | 0~127 |
| Boolean | true和false |
13、== 和 equals比较有什么区别(高频plus & 高xinplus)
类似或相关的考题:
问:字符串比较是用equals还是==?为什么?
答:字符串支持==和equals比较,但是实际开发中通常用equals比较,用于比较两个字符串的内容值是否相同
问:==和equals能不能用于null比较?
答:==可以用于比较null值,equals只能是非null.equals(null),反过来不可以。
问:能不能写a ≠null?
答:不支持,这个写法是IDEA开发工具的显示效果,实际上是 a != null
(1)== 和 equals的区别
| == | equals | |
|---|---|---|
| 使用形式 | a==b | a.equals(b) |
| 适用类型 | a和b可以是8种基本数据类型的值,也可以是两个引用数据类型的值 | 只能比较两个引用数据类型的值 |
| 要求 | a,b必须类型相同或兼容(兼容是指可以通过自动类型转换达到相同) | a,b不要求类型相同 |
| 作用 | 比较两个引用数据类型的值时,表示比较对象的地址值 | 如果没有重写Object类的equals方法,实际上也是比较对象的地址值。如果该类型重写了Object类的equals方法,按重写后的规则比较两个对象,例如:String类重写了equals方法,表示比较两个字符串的字符内容是否相等 |
| 支持null值 | a == b,其中a和b都可以是null,当两边为null时,结果为true,当一边为null时,结果为false,当两边都不是null时,按实际值比较 | a.equals(b),其中a不能为null,否则会发生空指针异常,b可以为null,当b为null时,结果为false |
package com.atguigu.oop;import org.junit.Test;public class EqualsDemo1 {@Testpublic void test1(){int a = 1;int b = 1;System.out.println(a == b);//true,数据值相等
// System.out.println(a.equals(b));//错误}@Testpublic void test2(){String s1 = new String("hello");StringBuffer s2 = new StringBuffer("hello");
// System.out.println(s1 == s2);//编译报错,s1和s2的类型不一致System.out.println(s1.equals(s2));//false,s1和s2的类型不一致}@Testpublic void test3(){String s1 = "hello";String s2 = "hello";System.out.println(s1 == s2);//true,"hello"是字符串常量对象,可以被共享,s1和s2指向同一个"hello"对象,地址值相同System.out.println(s1.equals(s2));//true,地址值相同,equals肯定是true}@Testpublic void test4(){String s1 = new String("hello");String s2 = new String("hello");System.out.println(s1 == s2);//false,地址值不相同System.out.println(s1.equals(s2));//true 重写equals,比较字符串的内容}@Testpublic void test5(){StringBuffer s1 = new StringBuffer("hello");StringBuffer s2 = new StringBuffer("hello");System.out.println(s1 == s2);//false,地址值不相同System.out.println(s1.equals(s2));//false 没重写equals,仍然比较地址值}@Testpublic void test6(){String s1 = new String("hello");String s2 = null;String s3 = null;System.out.println(s1 == s2);//false 非null与null不相等System.out.println(s2 == s3);//true 两个null值相同System.out.println(s1.equals(s2));//false 非null与null不相等System.out.println(s2.equals(s3));//空指针异常 s2是null空值,没有指向任何对象}
}
(2)包装类的==和equals问题
import org.junit.Test;public class EqualsDemo3 {@Testpublic void test1() {int a = 1;int b = 1;System.out.println(a == b);//true 基本数据类型,比较数据值a = 200;b = 200;System.out.println(a == b);//true 基本数据类型,比较数据值}@Testpublic void test2() {Integer a = 1;Integer b = 1;System.out.println(a == b);//true 1是常量对象,可以共享,a,b指向同一个Integer对象System.out.println(a.equals(b));//true 重写了equals,比较内容值a = 200;b = 200;System.out.println(a == b);//false 200非常量对象,不可以共享,a,b指向不同Integer对象,地址值不相同System.out.println(a.equals(b));//true 重写了equals,比较内容值}@Testpublic void test3() {Integer a = 1;int b = 1;System.out.println(a == b);//true 拆箱,按照基本数据类型处理,比较数据值System.out.println(a.equals(b));//true 装箱,按照包装类出来,Integer重写了equals,比较内容值a = 200;b = 200;System.out.println(a == b);//true 拆箱,按照基本数据类型处理,比较数据值System.out.println(a.equals(b));//true 装箱,按照包装类出来,Integer重写了equals,比较内容值}@Testpublic void test4(){Integer a = 1;double b = 1.0;System.out.println(a == b);//true 拆箱,按照基本数据类型处理,比较数据值int的1和double的1.0,//int自动升级为double,比较1.0==1.0System.out.println(a.equals(b));//false 装箱,按照包装类出来,Integer对象和Double对象,类型不一致,false}@Testpublic void test5(){Integer a = 1;Double b = 1.0;
// System.out.println(a == b);//编译报错,==比较两个对象地址时,要求类型相同System.out.println(a.equals(b));//false,Integer对象和Double对象,类型不一致}
}
4.3 字符串(6题)
1、String类可以被继承吗?(高频plus & 高xinplus)
String类不可以被继承,因为它有final修饰。
问:你还知道其他final修饰的类吗?
System,Math,包装类等
问:它们为什么是final修饰的?
因为它们太重要,太基础了,是整个Java程序的基石,所以它们的设计不允许或没有必要进行扩展。
2、String , StringBuilder , StringBuffer,StringJoiner有什么区别?(高频plus & 高xinplus)
String , StringBuilder , StringBuffer用于表示一串字符,即字符序列。StringJoiner是JDK8引入的一个String拼接工具。
| String | StringBuffer | StringBuilder | |
|---|---|---|---|
| 引入的JDK版本 | JDK1.0 | JDK1.0 | JDK1.5 |
| 对象是否可变 | 不可变字符序列 | 可变字符序列,默认缓冲区大小16 | 可变字符序列,默认缓冲区大小16 |
| 线程安全 | 安全 | 安全 | 不安全 |
| 拼接 | + 或 concat | append | append |
问:String和StringBuffer为什么是线程安全的?
String对象是不可对象。凡是修改都会得到新对象,不同线程的修改会各自得到一个新对象。
StringBuffer的操作方法是同步方法,所以是线程安全的。
延伸的面试题:
问:String对象真的不可变吗?
除非用反射操作获取字符串对象内部数组的引用,然后修改数组元素,否则字符串对象不可变。
import java.util.StringJoiner;public class TestStringJoiner {public static void main(String[] args) {String[] arr = {"hello","world","java"};StringJoiner joiner = new StringJoiner("-","(",")");for (int i = 0; i < arr.length; i++) {joiner.add(arr[i]);}System.out.println(joiner);//(hello-world-java)}
}
import java.lang.reflect.Field;public class TestStringModify {public static void main(String[] args) throws Exception{String str = "atguigu";Class<? extends String> clazz = str.getClass();Field valueField = clazz.getDeclaredField("value");valueField.setAccessible(true);byte[] value = (byte[]) valueField.get(str);value[0] = 'A';System.out.println(str);}
}
//--add-opens java.base/java.lang=ALL-UNNAMED
问:String类的哪些设计保证对象的不可变的?对象不可变有什么好处?
String底层的value数组是private修饰,在String类的外部,除了用反射之外的其他方法,不可支持操作它。
String底层的value数组是final修饰的,意味着value数组的引用不可修改,即value不能被替换为新数组,所以String对象一旦创建,长度就固定了,不像StringBuffer和StringBuilder,内部value数组可以扩容,缩容。
String类中所有方法一旦要修改字符串的内容,都会返回新的字符串对象。
String对象不可变意味着线程安全,意味着String对象是常量对象,可以被共享。
3、String有没有长度限制?
有限制,因为字符串内部是字符或字节数组,而数组长度是int类型,有大小约束。
Java中数组的最大长度是Integer.MAX_VALUE-8
4、String底层实现是怎样的?
-
JDK9之前,String底层是char[],每一个字符占2个字节,采用UTF16编码方式。
-
JDK9之后,String底层是byte[],每一个字符可能占1个字节或2个字节。
-
如果当前字符串所有字符都是Latin1字符集中的字符(这些字符覆盖了大多数西欧语言,如英语、法语、德语、西班牙语等所需的字母和符号,编码值范围是[0-255]),那么当前字符串每一个字符占1个字节,采用Latin1编码方式。
-
如果当前字符串中有任意一个字符不是Latin1字符集中的字符,例如中文、韩文、日文等,那么当前字符串每一个字符占2个字节,采用UTF16编码方式。
-
相关的面试题:
问:字符串在JVM中采用什么编码?JDK9之前,每一个字符占2个字节,采用UTF16编码方式。每一个字符占2个字节,采用UTF16编码方式。每一个字符可能占1个字节或2个字节,采用Latin1或UTF16编码方式
问:Java中一个字符占几个字节?
如果是char类型的一个字符,无论是什么字符,都是占2个字节。
如果是字符串中的一个字符,JDK9之前,每一个字符占2个字节,采用UTF16编码方式。Java9之后,每一个字符可能占1个字节或2个字节,采用Latin1或UTF16编码方式。
问:Java中一个汉字占几个字节?2个字节
5、String如何实现编码和解码?(高频plus)
如果Java程序在IO操作时,例如读写文件或网络中接收或发送数据,就涉及到编码与解码操作。
编码是指将字符转为字节的过程,通过String类的getBytes方法可以完成。
解码是指将字节解析为字符的过程,通过String类的构造器或String.valueOf方法可以完成。
import java.io.UnsupportedEncodingException;
import java.util.Arrays;public class TestStringEncodeDecode {public static void main(String[] args)throws UnsupportedEncodingException {String str = "love尚硅谷";byte[] bytes = str.getBytes("GBK");System.out.println(Arrays.toString(bytes));String result = new String(bytes,"GBK");System.out.println("result = " + result);System.out.println("===============");byte[] bytes2 = str.getBytes("UTF-8");System.out.println(Arrays.toString(bytes2));String result2 = new String(bytes2, "UTF-8");System.out.println("result2 = " + result2);System.out.println("=====================");String result3 = new String(bytes, "UTF-8");System.out.println("result3 = " + result3);}
}目前最常用的中文字符集GB2312,涵盖了所有简体字符以及一部分其他字符;GBK(K代表扩展的意思)则在GB2312的基础上加入了对繁体字符等其他非简体字符。这两个字符集的字符都是使用1-2个字节来表示。Windows系统采用936代码页来实现对GBK字符集的编解码。在解析字节流的时候,如果遇到字节的最高位是0的话,那么就使用936代码页中的第1张码表进行解码,这就和单字节字符集的编解码方式一致了。如果遇到字节的最高位是1的话,那么就表示需要两个字节值才能对应一个字符。

UTF-8是一种变长的编码方式。它可以使用1~4个字节表示一个符号。从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换(即Uncidoe字符集≠UTF-8编码方式)。
Unicode编码值范围(十六进制) | UTF-8编码方式(二进制)
—————————————————————————————————————
0000 0000-0000 007F | 0xxxxxxx(兼容原来的ASCII)
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx

因此,Unicode只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。推荐的Unicode编码是UTF-16和UTF-8。
在内存中每一个字符使用它在Unicode字符集中的唯一编码值表示,这是没有问题的。因为Unicode字符集中字符编码值的范围是[0, 65535],在Java的JVM内存中无论这个字符的编码值是多少,都分配2个字节,即UTF-16的编码方式。但是在其他环境中,例如文件中、IO流中等,Unicode就不完美了,这里有3个的问题,一个是,在文件或IO流中英文字母等ASCII码表中的字符只用一个字节表示,第二个问题是如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,不够表示所有字符,第三个,如何才能区别这是几个字节表示一个符号。
6、String如何实现转码?
例如:从网络或文件中读取了一段数据,它是一段文本(即字符串)用UTF-8编码后的结果,那么怎么转换为GBK编码后的结果呢?
方式一:
import java.nio.charset.Charset;
import java.util.Arrays;public class TestStringTransferCoder {public static void main(String[] args)throws Exception {Charset utf8Charset = Charset.forName("UTF-8");Charset gbkCharset = Charset.forName("GBK");//originalBytes的内容可能是从文件中读取,或从网络中接收,这里临时模拟一下//总之,读取的是以UTF-8编码规则处理的数据String str ="尚硅谷";byte[] originalBytes = str.getBytes(utf8Charset);byte[] destBytes = change(originalBytes, utf8Charset, gbkCharset);System.out.println("Bytes in UTF-8: " + Arrays.toString(originalBytes));System.out.println("Bytes in GBK:" + Arrays.toString(destBytes));System.out.println("UTF-8的字符串内容:" + new String(originalBytes,utf8Charset));System.out.println("GBK的字符串:" + new String(destBytes,gbkCharset));}public static byte[] change(byte[] originalBytes, Charset originalCharset, Charset destCharset){String temp = new String(originalBytes,originalCharset);byte[] destBytes = temp.getBytes(destCharset);return destBytes;}
}
方式二:
import java.io.FileReader;
import java.io.FileWriter;
import java.nio.charset.Charset;public class TestStringTransferCoder2 {public static void main(String[] args)throws Exception {Charset utf8 = Charset.forName("UTF-8");Charset gbk = Charset.forName("GBK");FileReader fr = new FileReader("d:\\UTF8.txt",utf8);FileWriter fw = new FileWriter("d:\\GBK.txt", gbk);char[] data = new char[10];int len;while((len=fr.read(data))!=-1){fw.write(data,0,len);}fw.close();fr.close();}
}
7、String字符串如何进行反转?
方式一:可以将String字符串对象转换为StringBuffer或StringBuilder对象,然后调用reverse方法完成反转,再转为String类型对象。
方式二:将String字符串转为char[]数组,然后反转数组,再构建为String对象。
public class TestStringReverse {public static void main(String[] args) {String srcStr = "尚硅谷";StringBuilder builder = new StringBuilder(srcStr);builder.reverse();//反转String destStr = builder.toString();System.out.println("反转前:" + srcStr);System.out.println("反转后:" + destStr);System.out.println("=========================");char[] charArray = srcStr.toCharArray();//数组反转for(int left=0,right=charArray.length-1; left<right; left++,right--){char temp = charArray[left];charArray[left] = charArray[right];charArray[right] = temp;}String result = new String(charArray);System.out.println("反转前:" + srcStr);System.out.println("反转前:" + result);}
}
8、String类isEmpty和isBlank的区别?(高频plus & 高xinplus)
- isEmpty用于判断字符串是不是为空,这里的空是指长度为0的字符串,即不包含任何字符的字符串。
- isBlank用于判断字符串是不是为空,这里的空是指字符串长度为0或全部由空白字符(例如空格、\t、\n等)构成的字符串。
public class TestStringEmptyBlank {public static void main(String[] args) {String str1 ="";String str2 =" \t\n ";System.out.println("字符串1[" + str1 +"],isEmpty:" + str1.isEmpty() + ",isBlank:" + str1.isBlank());System.out.println("字符串2[" + str2 +"],isEmpty:" + str2.isEmpty() + ",isBlank:" + str2.isBlank());}
}9、String类的concat和+有什么区别?
如果是两个""字符串拼接,concat会产生新对象,而+会在编译时直接合并为一个字符串。
import org.junit.Test;public class TestConcat {@Testpublic void test1(){String s1 = "helloworld";String s2 = "hello" + "world";System.out.println(s1 == s2);//true}@Testpublic void test2(){String s1 = "helloworld";String s2 = "hello".concat("world");System.out.println(s1 == s2);//false}
}10、字符串拼接什么时候用+,什么时候不推荐用+?(高频plus & 高xinplus)
少量的字符串拼接建议使用+更简洁方便。大量的字符串拼接建议使用StringBuffer或StringBuilder的append,这样不会产生大量中间对象。
import org.junit.Test;public class TestAppend {@Testpublic void testString(){long start = System.currentTimeMillis();String s = new String("0");for(int i=1;i<=10000;i++){s += i;}long end = System.currentTimeMillis();System.out.println("String拼接+用时:"+(end-start));//367long memory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();System.out.println("String拼接+memory占用内存: " + memory);//473081920字节}@Testpublic void testStringBuilder(){long start = System.currentTimeMillis();StringBuilder s = new StringBuilder("0");for(int i=1;i<=10000;i++){s.append(i);}long end = System.currentTimeMillis();System.out.println("StringBuilder拼接+用时:"+(end-start));//5long memory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();System.out.println("StringBuilder拼接+memory占用内存: " + memory);//13435032}
}
11、String str = new String("尚硅谷");创建了几个对象?(高频plus & 高xinplus)
2个。"尚硅谷"是一个字符串对象,又新new了一个字符串对象。
import org.junit.Test;public class TestStringCount {@Testpublic void test1(){String s1 = "尚硅谷";String s2 = new String("尚硅谷");System.out.println(s1==s2);}
}
12、String类的intern()方法有什么用?
当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(用 equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并返回此 String 对象的引用。
String s = str.intern();
代码分析题考核:
import org.junit.Test;public class TestStringIntern {@Testpublic void test1(){String s1 = new String("尚硅谷");/*这句代码有2个字符串对象,一个是"尚硅谷",一个是新new的,s1引用的是新对象的地址"尚硅谷"在常量池,新new的不在常量池*/String s2 = s1.intern();/*s1的intern()在池中找s1.equals(池中字符串)返回true的字符串,如果可以找到,返回该对象地址,没找到,将s1字符串地址放入常量池这里池中有"尚硅谷",可以找到,返回"尚硅谷"地址*/String s3 = "尚硅谷";/*引用池中"尚硅谷"对象地址*/System.out.println(s1 == s2);System.out.println(s1 == s3);System.out.println(s2 == s3);/*JDK17:false,false,trueJDK6:false,false,true*/}@Testpublic void test2(){String s1 = "尚".concat("硅谷");/*这句代码有3个字符串对象,(1)"he" (2)"llo" (3) 新new字符串,内容是尚硅谷s1指向新new的字符串地址*/String s2 = s1.intern();/*s1的intern()在池中找s1.equals(池中字符串)返回true的字符串,如果可以找到,返回该对象地址,没找到,将s1字符串地址放入常量池这里池中没有"尚硅谷",将s1字符串地址放入池中*/String s3 = "尚硅谷";/*直接用池中内容为尚硅谷的字符串地址*/System.out.println(s1 == s2);System.out.println(s1 == s3);System.out.println(s2 == s3);/*JDK17:true,true,trueJDK6:false,false,true*/}
}
13、Java中3个双引号是什么语法?
Java 13中引入了文本块预览特性,在Java15转正。
import org.junit.Test;public class TestStringBlock {@Testpublic void test1(){String htmlStr = "<html>\n" +" <body>\n" +" <p>Hello, 尚硅谷</p>\n" +" </body>\n" +"</html>\n";System.out.println(htmlStr);String story = "Elly said,\"Maybe I was a bird in another life.\"\n" + "Noah said,\"If you're a bird , I'm a bird.\";";System.out.println(story);}@Testpublic void test2() {String htmlStr = """<html><body><p>Hello, world</p></body></html>""";System.out.println(htmlStr);String story = """Elly said,"Maybe I was a bird in another life."Noah said,"If you're a bird , I'm a bird."""";System.out.println(story);String text = """\s\s人最宝贵的东西是生命,生命对人来说只有一次。\因此,人的一生应当这样度过:当一个人回首往事时,\不因虚度年华而悔恨,也不因碌碌无为而羞愧;\这样,在他临死的时候,能够说,\我把整个生命和全部精力都献给了人生最宝贵的事业\——为人类的解放而奋斗。""";System.out.println(text);}
}
4.4 集合(20题)
1、说说常见的集合有哪些?(高频plus & 高xinplus)
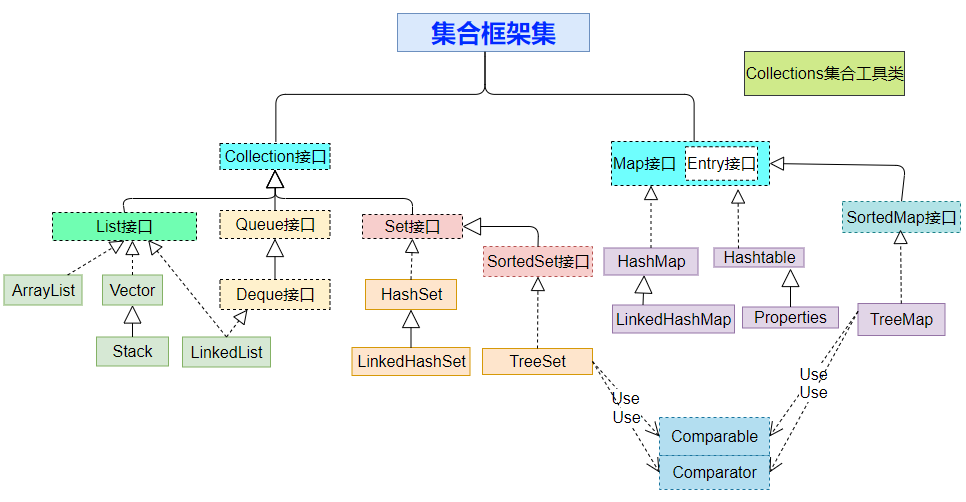
相关的面试题:
问:描述一下常用的Collection集合的类结构?
问:描述一下常用的Map集合的类结构?
问:常用的List集合有哪些?
问:常见的Set集合有哪些?
问:Hashtable为什么不叫HashTable?
答:Hashtable 是 Java 早期版本中的一个类,当时 Java 的命名规范尚未完全成熟,它的设计和命名受到了当时其他编程语言的影响。
问:为什么ArrayList、LinkedList都以List结尾,Vector没有?
答:像Vector,Stack,Hashtable ,Properties这几个集合都是早期版本的集合,它们比List、Set、Map这些接口都早出现,当时还未形成集合框架体系。
2、Collection和Collections的区别?(高频plus )
Collection 是一个单列集合的顶层接口。
Collections是集合类的一个工具类,包含了对集合元素进行排序和线程安全等各种操作方法。
3、List、Set、Map之间的区别是什么?
| List | Set | Map | |
|---|---|---|---|
| 单列or双列 | 单列集合 | 单列集合 | 双列集合,存储键值对 |
| 索引 | 支持 | × | × |
| 重复 | 重复 | × | key不重复,value可重复 |
| 存取一致性 | 一致 | LinkedHashSet一致,其余不一致 | LinkedHashMap一致,其余不一致 |
4、为什么Map接口不继承Collection接口?
Map继承Collection没有意义。Collection代表的是一组独立元素的集合,操作的是单个元素。而Map代表的是一组key-value键值对形式的集合,操作的是键值对,而不是“一组对象”的概念。分开两个不同的集合,语义上更清晰。
5、ArrayList和Vector有什么区别?(高频plus & 高xinplus)
ArrayList和Vector都是List接口的实现类,它们都是动态数组。
| Vector | ArrayList | |
|---|---|---|
| 版本 | JDK1.0(最古老) | JDK1.2(较新) |
| 线程安全 | 安全 | 不安全 |
| 默认初始化容量 | 10 | 0 ,首次添加元素是默认初始化长度是10 |
| 是否支持手动指定初始化容量 | 支持 | 支持 |
| 扩容 | 2倍 | 1.5倍 |
| 是否支持手动指定增量 | 支持 | 不支持 |
补充说明:
- Vector无参构造创建Vector对象时,直接创建长度为10的数组;ArrayList无参构造创建ArrayList对象时,数组先初始化为DEFAULTCAPACITY_EMPTY_ELEMENTDATA,首次add元素时才创建长度为10的数组;
- Vector扩容频率低,空间利用率低;ArrayList扩容频率高,空间利用率更高;
相关的面试题:
问:什么是Vector?它是List接口的实现类,是古老的动态数组。
问:ArrayList默认大小是多少,是如何扩容的?见上表
问:ArrayList是线程安全的吗?不是
问:ArrayList为什么不是线程安全的?ArrayList 没有内置的同步机制来确保多线程环境下的操作安全。这意味着在多线程环境下使用 ArrayList 时,需要外部手动添加同步机制,如使用 synchronized 关键字或 Collections.synchronizedList 方法。
问:ArrayList初始化1万条数据,怎么优化?用ArrayList(初始化容量)构造器创建集合,避免了频繁扩容的过程。
import org.junit.Test;import java.util.Vector;public class TestVector {@Testpublic void test1(){Vector<Integer> vector = new Vector<>();for(int i = 1; i<= 10; i++){vector.add(i);}vector.add(11);}@Testpublic void test2(){Vector<Integer> vector = new Vector<>(5,1);//指定初始化容量和增量for(int i = 1; i<= 5; i++){vector.add(i);}vector.add(11);}
}import org.junit.Test;import java.util.ArrayList;public class TestArrayList {@Testpublic void test1(){ArrayList<Integer> list = new ArrayList<>();for(int i = 1; i<= 10; i++){list.add(i);}list.add(11);}@Testpublic void test4(){ArrayList<Integer> list = new ArrayList<>(5);//手动指定初始化容量for(int i = 1; i<= 5; i++){list.add(i);}list.add(11);}
}
6、ArrayList和LinkedList有什么区别?(高频plus & 高xinplus)
| ArrayList | LinkedList | |
|---|---|---|
| 底层结构 | 数组 | 双向链表 |
| 与数据结构有关的接口 | List |
List |
| 容量限制 | 受数组的最大长度限制 | 受限于可用内存 |
| 查询时间复杂度 | O(1),O(n) | O(n) |
| 是否需要扩容 | 需要 | 不需要 |
| 是否需要移动元素 | 需要 | 不需要 |
| 占用内存 | 少,元素连续存储 | 多,每个结点除了存储元素本身外,还需要存储两个额外的引用(前驱和后继结点) |
| 效率对比 | 理论上:查询快,增删慢 | 理论上:查询慢,增删快 |
补充说明:
理论上数组结构的增删慢,链表结构的增删快,但现在内存拷贝技术性能提高之后,ArrayList 的整体性能反而优于 LinkedList,因为 LinkedList 内部需要创建结点对象,这是一个耗时耗力的过程。附某次测试结果如下:
import org.junit.Test;import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Random;public class TestLinkedList {@Testpublic void test1(){long start = System.currentTimeMillis();ArrayList<Integer> list = new ArrayList<>();for(int i=1; i<=100000; i++){list.add(i-1, i);}long end = System.currentTimeMillis();System.out.println("ArrayList末尾位置添加时间:" + (end-start));}@Testpublic void test2(){long start = System.currentTimeMillis();LinkedList<Integer> list = new LinkedList<>();for(int i=1; i<=100000; i++){list.add(i-1, i);}long end = System.currentTimeMillis();System.out.println("LinkedList末尾位置添加时间:" + (end-start));}@Testpublic void test3(){long start = System.currentTimeMillis();ArrayList<Integer> list = new ArrayList<>();list.add(1);//这里先添加1个,保证list.size()不为0Random random = new Random();for(int i=1; i<=100000; i++){int index = random.nextInt(0, list.size());list.add(index, i);}long end = System.currentTimeMillis();System.out.println("ArrayList任意位置添加时间:" + (end-start));}@Testpublic void test4(){long start = System.currentTimeMillis();LinkedList<Integer> list = new LinkedList<>();list.add(1);//这里先添加1个,保证list.size()不为0Random random = new Random();for(int i=1; i<=100000; i++){int index = random.nextInt(0, list.size());list.add(index, i);}long end = System.currentTimeMillis();System.out.println("LinkedList任意位置添加时间:" + (end-start));}
}运行结果:
ArrayList末尾位置添加时间:6
LinkedList末尾位置添加时间:13
ArrayList任意位置添加时间:207
LinkedList任意位置添加时间:15022
相关面试题:
问:ArrayList有没有容量限制?见上表
问:LinkedList有没有容量限制?见上表
问:ArrayList和LinkedList哪个更占空间?见上表
问:ArrayList和LinkedList哪个效率更高?见上表
7、哪些集合支持对元素随机访问?
只有实现RandomAccess接口的集合支持对元素随机访问。RandomAccess接口的常见实现类有:
- ArrayList:线程不安全。它的迭代器是快速失败的(fail-fast)。
- Vector:线程安全,每次访问都需要加锁,因此在高并发环境下性能较差。它的迭代器是快速失败的(fail-fast)。
- CopyOnWriteArrayList:线程安全,它的迭代器是副本机制(fail-safe)。它在读操作频繁而写操作较少的情况下性能较好,因为读操作不加锁。但在写操作频繁的情况下,频繁的数组复制会导致较大的开销。迭代器是弱一致性的(weakly consistent),可以在遍历过程中允许其他线程修改集合,不会抛出异常,但可能会看不到部分更新的结果。
8、List和Array之间如何互相转换?(高频plus )
- List -> Array 可以通过集合的toArray方法完成
- Array -> List 可以通过Arrays的asList方法 或 Collections的addAll方法完成
import org.junit.Test;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;public class TestListArray {@Testpublic void test1(){ArrayList<String> list = new ArrayList<>();list.add("尚硅谷");list.add("atguigu");list.add("good");Object[] array = list.toArray();}@Testpublic void test2(){ArrayList<String> list = new ArrayList<>();list.add("尚硅谷");list.add("atguigu");list.add("good");String[] array = new String[0];array = list.toArray(array);}@Testpublic void test3(){String[] array = {"尚硅谷","atguigu","good"};List<String> list = Arrays.asList(array);ArrayList<String> arrayList = new ArrayList<>(list);}@Testpublic void test4(){String[] array = {"尚硅谷","atguigu","good"};ArrayList<String> list = new ArrayList<>();Collections.addAll(list,array);}
}
9、Arrays.asList有什么使用限制?
Arrays.asList方法返回的List集合不支持添加、删除元素,会发生UnsupportedOperationException异常。
import org.junit.Test;import java.util.Arrays;
import java.util.List;public class TestArraysAsList {@Testpublic void test1(){List<String> list = Arrays.asList("尚硅谷", "atguigu");list.add("java");//java.lang.UnsupportedOperationException}@Testpublic void test2(){List<String> list = Arrays.asList("尚硅谷", "atguigu");list.remove(1);//java.lang.UnsupportedOperationException}
}10、栈和队列有什么区别?(高频plus & 高xinplus)
栈:先进后出(FILO:First In Last Out)。队列:先进先出(FIFO:First In First Out)。
栈和队列只是逻辑结构,其物理结构可以是数组,也可以是链表。
核心类库中的栈结构有Stack和LinkdeList。Stack就是顺序栈,它是Vector的子类。LinkedList是链式栈。
| 操作 | 方法 |
|---|---|
| 入栈 | push(e) |
| 出栈 | pop(e) |
| 查看栈顶元素 | peek() |
Queue除了基本的 Collection操作外,队列还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。Queue 实现通常不允许插入 元素,尽管某些实现(如 )并不禁止插入 。即使在允许 null 的实现中,也不应该将null插入到中,因为null也用作 方法的一个特殊返回值,表明队列不包含元素,此时不好区分。
| 抛出异常 | 返回特殊值 | |
|---|---|---|
| 插入 | add(e) | offer(e) |
| 移除 | remove() | poll() |
| 检查 | element() | peek() |
Deque,名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。此接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。Deque接口的实现类有ArrayDeque和LinkedList,它们一个底层是使用数组实现,一个使用双向链表实现。
| 第一个元素(头部) | 最后一个元素(尾部) | |||
|---|---|---|---|---|
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 移除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
import org.junit.Test;import java.util.LinkedList;
import java.util.Stack;public class TestStack {@Testpublic void test1(){System.out.println("进栈:java,hello,atguigu");Stack<String> stack = new Stack<>();stack.push("java");stack.push("hello");stack.push("atguigu");System.out.println("栈顶元素:" + stack.peek());System.out.println("栈顶元素:" + stack.peek());System.out.println("出栈:");while (!stack.isEmpty()){System.out.println(stack.pop());}}@Testpublic void test2(){System.out.println("进栈:java,hello,atguigu");LinkedList<String> stack = new LinkedList<>();stack.push("java");stack.push("hello");stack.push("atguigu");System.out.println("栈顶元素:" + stack.peek());System.out.println("栈顶元素:" + stack.peek());System.out.println("出栈:");while (!stack.isEmpty()){System.out.println(stack.pop());}}@Testpublic void test3()throws Exception{System.out.println("进队:java,hello,atguigu");LinkedList<String> queue = new LinkedList<>();queue.addLast("java");queue.addLast("hello");queue.addLast("atguigu");System.out.println("队头元素:" + queue.getFirst());System.out.println("队尾元素:" + queue.getLast());System.out.println("出队列:");while (!queue.isEmpty()){System.out.println(queue.removeFirst());}// System.out.println(queue.removeFirst());//异常}@Testpublic void test4()throws Exception{System.out.println("进队:java,hello,atguigu");LinkedList<String> queue = new LinkedList<>();queue.offerLast("java");queue.offerLast("hello");queue.offerLast("atguigu");System.out.println("队头元素:" + queue.peekLast());System.out.println("队尾元素:" + queue.peekLast());System.out.println("出队列:");while (!queue.isEmpty()){System.out.println(queue.pollFirst());}System.out.println(queue.pollFirst());}
}11、什么是阻塞队列?
阻塞队列(Blocking Queue)是一种特殊的队列,它在队列为空时,从队列中获取元素的操作将会被阻塞,直到队列中有新的元素被添加;同样,在队列满时,向队列中添加元素的操作也会被阻塞,直到队列中有空闲的位置。
阻塞队列是线程安全的,在多线程编程中非常有用,特别是在生产者-消费者模式中。
Java 提供了多种阻塞队列的实现,位于 java.util.concurrent 包中,例如:ArrayBlockingQueue(基于数组的有界阻塞队列)、PriorityBlockingQueue(支持优先级排序的无界阻塞队列)。
相关面试题:
问:Java中的阻塞队列有哪些?
问:阻塞队列是线程安全的吗?
问:阻塞队列有哪些常用的应用场景?
12、几种Set集合的区别?(高频plus & 高xinplus)
| HashSet | LinkedHashSet | TreeSet | |
|---|---|---|---|
| 底层集合 | HashMap | LinkedHashMap | TreeMap |
| 数据结构 | 数组+单链表+红黑树 | 数组+单链表+红黑树+双链表 | 红黑树 |
| 顺序特点 | 无序 | 插入顺序 | 按元素大小顺序 |
| key支持null | √ | √ | × |
| 线程安全 | 不安全 | 不安全 | 不安全 |
相关的面试题:
问:HashSet是线程安全的吗?不是
问:HashSet中元素是有顺序的吗?不是
问:HashSet怎么按插入顺序排列?改用LinkedHashSet
问:HashSet怎么按自然顺序排列?改用TreeSet
问:HashSet的底层实现原理是什么?底层是HashMap
问:TreeSet的数据结构是什么?红黑树
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
@AllArgsConstructor
public class Employee implements Comparable<Employee>{private int id;private String name;private double salary;@Overridepublic int compareTo(Employee o) {return this.id - o.id;}
}import org.junit.Test;import java.util.*;public class TestSet {@Testpublic void test1(){HashSet<String> set = new HashSet<>();set.add("atguigu");set.add("java");set.add("hello");System.out.println(set);}@Testpublic void test2(){LinkedHashSet<String> set = new LinkedHashSet<>();set.add("atguigu");set.add("java");set.add("hello");System.out.println(set);}@Testpublic void test3(){TreeSet<String> set = new TreeSet<>();set.add("atguigu");set.add("java");set.add("hello");System.out.println(set);}@Testpublic void test4()throws Exception{TreeSet<Employee> set = new TreeSet<>();set.add(new Employee(2,"谷粒",15000));set.add(new Employee(1,"谷姐",16000));set.add(new Employee(3,"谷子",13000));for (Employee e : set) {System.out.println(e);}}@Testpublic void test5()throws Exception{Comparator<Employee> c = new Comparator<Employee>() {@Overridepublic int compare(Employee o1, Employee o2) {return Double.compare(o1.getSalary(),o2.getSalary());}};TreeSet<Employee> set = new TreeSet<>(c);set.add(new Employee(2,"谷粒",15000));set.add(new Employee(1,"谷姐",16000));set.add(new Employee(3,"谷子",13000));for (Employee e : set) {System.out.println(e);}}@Testpublic void test6()throws Exception{TreeSet<Employee> set = new TreeSet<>(Comparator.comparingDouble(Employee::getSalary));set.add(new Employee(2,"谷粒",15000));set.add(new Employee(1,"谷姐",16000));set.add(new Employee(3,"谷子",13000));for (Employee e : set) {System.out.println(e);}}
}13、HashMap和Hashtable有什么区别?(高频plus & 高xinplus)
| Hashtable | HashMap | |
|---|---|---|
| 引入时间 | JDK1.0(最古老) | JDK1.2(较新) |
| 线程安全 | 安全 | 不安全 |
| key和value支持null | 不支持 | 支持 |
14、几种Map有什么区别?(高频plus & 高xinplus)
所有Map都是存储键值对的,key不可重复,不可修改,value可以重复,可以修改。
| Hashtable | HashMap | LinkedHashMap | TreeMap | |
|---|---|---|---|---|
| 数据结构 | 数组+单链表 | 数组+单链表+红黑树 | 数组+单链表+红黑树+双链表 | 红黑树 |
| 顺序特点 | 无序 | 无序 | 插入顺序 | 按key大小顺序 |
| key支持null | × | √ | √ | × |
| 线程安全 | 安全 | 不安全 | 不安全 | 不安全 |
相关的面试题:
问:HashMap和TreeMap、LinkedHashMap怎么选?
import org.junit.Test;import java.util.HashMap;
import java.util.Hashtable;
import java.util.LinkedHashMap;
import java.util.TreeMap;public class TestMap {@Testpublic void test1(){HashMap<Integer,String> map = new HashMap<>();map.put(111,"hello");map.put(888,"java");map.put(666,"atguigu");map.put(null,null);System.out.println(map);}@Testpublic void test2(){LinkedHashMap<Integer,String> map = new LinkedHashMap<>();map.put(111,"hello");map.put(888,"java");map.put(666,"atguigu");map.put(null,null);System.out.println(map);}@Testpublic void test3(){TreeMap<Integer,String> map = new TreeMap<>();map.put(111,"hello");map.put(888,"java");map.put(666,"atguigu");// map.put(null,null);System.out.println(map);}@Testpublic void test4(){Hashtable<Integer,String> map = new Hashtable<>();map.put(111,"hello");map.put(888,"java");map.put(666,"atguigu");// map.put(null,null);System.out.println(map);}
}
15、常用的并发集合有哪些?(高频plus )
Java 并发包 java.util.concurrent 提供了多种线程安全的集合类,这些集合类在多线程环境中提供了高效的并发访问。例如:ConcurrentHashMap、CopyOnWriteArrayList、ThreadLocal等。
相关面试题:
问:常用的线程安全的集合有哪些?
答:java.util包:Vector,Stack,Hashtable、Properties等
java.util.concurrent 包:CopyOnWriteArrayList、ConcurrentHashMap等
问:CopyOnWrite*并发集合有哪些优缺点?应用场景是什么?
答:优点:所有的写操作(如添加、删除)都会创建一个新的数组副本,然后将引用指向新的数组,从而避免了数据竞争。读操作和写操作之间不会产生冲突,确保了线程安全。
缺点:每次写操作都会创建一个新的数组副本,这会导致较大的内存开销,特别是在集合较大时。如果写操作频繁,可能会导致频繁的垃圾回收,影响性能。读操作看到的是写操作开始前的数据,因此可能会有数据延迟的问题。
应用场景:适用于读操作远多于写操作的场景,例如日志记录、配置管理等。在这些场景中,读操作的性能至关重要,而写操作较少,可以容忍一定的延迟。
16、如何把一个线程不安全的List集合转成线程安全的List集合?
方案一:直接使用Collections集合工具类的synchronizedList()方法。
方案二:直接选择Vector或CopyOnWriteArrayList。
相关面试题:
问:什么是SynchronizedList?
答:SynchronizedList 是通过 Collections.synchronizedList 方法创建的线程安全列表,适用于简单的线程安全需求和已有集合的线程安全包装。
问:常用的线程安全的List集合有哪些?
答:Vector,Stack,CopyOnWriteArrayList等。
17、foreach与普通for循环的区别?(高频plus & 高xinplus)
作用与应用场景:
-
普通for循环,可以用于所有需要重复执行某些语句的场景。也可以用于遍历数组与支持索引访问的List集合。
-
增强for循环,只能用于遍历数组与Collection集合。
使用区别:
-
如果使用普通for遍历数组,需要指定下标值,可以修改数组的元素。
-
如果使用增强for遍历数组,不需要指定下标,但无法修改数组的元素。
-
另外,增强for循环只是一种语法糖,增强for循环遍历数组时编译器仍然会将对应代码转换为普通for循环;增强for循环遍历Collection集合时编译器会将对应代码转换为Iterator迭代器遍历集合的代码。
18、foreach和迭代器有什么关系?
增强for循环只是一种语法糖,增强for循环遍历数组时编译器仍然会将对应代码转换为普通for循环;增强for循环遍历Collection集合时编译器会将对应代码转换为Iterator迭代器遍历集合的代码。
import org.junit.Test;import java.util.ArrayList;public class TestForeach {@Testpublic void test1(){String[] arr = {"尚硅谷","atguigu"};for (String s : arr) {System.out.println(s);}}@Testpublic void test2(){ArrayList<String> list = new ArrayList<>();list.add("尚硅谷");list.add("atguigu");for (String s : list) {System.out.println(s);}}
}
相关面试题:
问:Java中的语法糖是什么?
答:在 Java 中,语法糖(Syntactic Sugar)是指编译器提供的某些语法特性,这些特性使得代码更简洁、更易读,但底层实现仍然是相同的。语法糖并不会改变程序的行为,只是让程序员编写代码更加方便。
19、List遍历有哪几种方式?(高频plus & 高xinplus)
List遍历有4种方式:
- 普通for循环
- foreach
- Iterator
- ListIterator
import org.junit.Test;import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;public class TestListIterate {@Testpublic void test1(){ArrayList<String> list = new ArrayList<>();list.add("尚硅谷");list.add("atguigu");//使用普通for循环遍历for (int i = 0; i < list.size(); i++) {String s = list.get(i);System.out.println(s);}}@Testpublic void test2(){ArrayList<String> list = new ArrayList<>();list.add("尚硅谷");list.add("atguigu");//使用增强for循环遍历for (String s : list) {System.out.println(s);}}@Testpublic void test3(){ArrayList<String> list = new ArrayList<>();list.add("尚硅谷");list.add("atguigu");//使用Iterator迭代器遍历Iterator<String> iterator = list.iterator();while(iterator.hasNext()){String s = iterator.next();System.out.println(s);}}@Testpublic void test4(){ArrayList<String> list = new ArrayList<>();list.add("尚硅谷");list.add("atguigu");//使用ListIterator迭代器遍历ListIterator<String> iterator = list.listIterator();System.out.println("从前往后遍历:");while(iterator.hasNext()){String s = iterator.next();System.out.println(s);}System.out.println("从前往后遍历:");while(iterator.hasPrevious()){String s = iterator.previous();System.out.println(s);}}
}20、编程实现删除List集合的元素?(高频plus & 高xinplus)
List集合提供了如下3个删除元素的方法:
- remove(元素)
- remove(索引)
- removeIf(Predicate
p)
Iterator迭代器也提供了删除元素的方法:
- remove()
import org.junit.Test;import java.util.ArrayList;
import java.util.Iterator;public class TestListRemove {@Testpublic void test1(){ArrayList<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(4);list.remove(Integer.valueOf(2)); //删除元素2list.remove(0);//删除索引[0]位置的元素System.out.println(list);}@Testpublic void test2(){ArrayList<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(4);list.add(3);list.add(4);list.removeIf(num->num % 2 == 0);//根据条件删除元素System.out.println(list);}@Testpublic void test3(){ArrayList<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(4);list.add(3);list.add(4);Iterator<Integer> iterator = list.iterator();while(iterator.hasNext()){Integer num = iterator.next();if(num % 2 == 0){iterator.remove();//使用迭代器删除元素}}System.out.println(list);}@Testpublic void test5(){ArrayList<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(4);list.add(3);list.add(4);//普通for循环删除元素for(int i=0; i<list.size(); i++){Integer num = list.get(i);if(num % 2 == 0){list.remove(i);}}System.out.println(list);}@Testpublic void test4(){ArrayList<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(4);list.add(3);list.add(4);//ConcurrentModificationExceptionfor (Integer num : list) {if(num % 2 == 0){list.remove(num);}}}
}
相关面试题:
问:循环删除List集合可能会发生什么异常?
答:如果在foreach循环或Iterator迭代器遍历集合的过程中,调用集合的remove方法,可能会发生ConcurrentModificationException。
问:编程实现删除List集合的重复元素?
答:见上面代码
21、fail-fast和fail-safe有什么区别?
fail-fast 和 fail-safe 是 Java 中处理集合在遍历过程中被修改的不同策略。这两种策略在多线程环境下尤其重要,因为它们直接影响到集合的安全性和一致性。
(1)fail-fast 意味着在检测到集合在遍历过程中被修改时立即抛出异常。这种策略通常用于单线程环境,以防止编程错误导致的未定义行为。
- 检测机制:fail-fast 集合(如 ArrayList、LinkedList、HashSet 等)在迭代器中维护一个 exepectedModCount变量,记录集合的修改次数。
- 检查:每次调用 next() 或 remove() 方法时,迭代器都会检查 modCount 是否发生变化。如果发生变化,说明集合在遍历过程中被修改,迭代器会抛出 ConcurrentModificationException 异常。
(2)fail-safe 意味着在遍历过程中即使集合被修改,也不会抛出异常。这种策略通常用于多线程环境,以确保遍历操作的健壮性和安全性。
- 副本机制:fail-safe 集合(如 CopyOnWriteArrayList、ConcurrentHashMap 等)在遍历时使用集合的一个快照(副本)。
- 独立性:遍历操作和修改操作是独立的,遍历操作不会受到修改操作的影响。
相关的面试题:
问:什么是fail-safe?
问:什么是fail-fast?
22、HashMap的数据结构是什么?(高频plus & 高xinplus)
- JDK8之前:数组 + 单链表
- JDK8(含)之后:数组 + 单链表 + 红黑树
23、HashMap为什么要用数组和单链表?
因为数组元素访问的时间复杂度是O(1),即与数组长度无关。所以HashMap基于“key的hash & table.length -1” 来确定键值对在数组中的存取位置,效率极高。
但是key的hash值可能相同,或者hash值不同,但是映射后index位置相同,即哈希冲突,此时就需要用链表来实现在同一个桶中存储多个键值对。
24、JDK8HashMap为啥要引入红黑树?为啥不直接使用红黑树?(高频plus & 高xinplus)
当多个键的哈希值相同或映射到同一个桶时,会发生哈希冲突,哈希冲突严重时会导致链表的长度增加,从而影响性能。单链表查询的时间复杂度是O(n),而红黑树查询的时间复杂度是O(logn)。
链表的实现相对简单,插入和删除操作较为直观。红黑树的实现较为复杂,需要处理旋转和重新着色操作,如果每个桶都使用红黑树,会增加代码的复杂性和维护成本。红黑树在最坏情况下性能优于链表,但在平均情况下不如链表。
相关的面试题:
问:HashMap是怎么解决hash冲突的?
答:HashMap 解决哈希冲突的主要方法是使用链地址法(即单链表)和红黑树的结合。
25、为什么引入红黑树,而不是AVL树?
AVL 树是一种高度平衡的二叉搜索树,每个节点的左右子树的高度差不超过 1。AVL 树的平衡性更好,但维护这种平衡性的代价更高。AVL 树的插入和删除操作需要更多的旋转操作来维持平衡,复杂度较高。
红黑树的平衡性稍逊于 AVL 树,但维护平衡性的代价较低。红黑树允许节点的左右子树高度差最多为 2,这使得插入和删除操作的复杂度更低。红黑树通过最多三次旋转和一次重新着色即可恢复平衡。
26、JDK8 HashMap什么情况会出现红黑树?(高频plus & 高xinplus)
当某个桶单链表转为红黑树(该过程称为树化),需要同时满足如下两个条件:
(1)table.length >= MIN_TREEIFY_CAPACITY(其值是64)
(2)该桶单链表的长度 >= TREEIFY_THRESHOLD(其值是8)
27、为啥是链表长度达到8才转红黑树?为什么是8?(高频plus & 高xinplus)
在用户 hashCode 分布良好的使用中,树桶很少被使用。理想情况下,在随机 hashCode 下,桶中节点的频率遵循泊松分布,对于负载因子为 0.75 的 HashMap,树化阈值TREEIFY_THRESHOLD定为8时,出现红黑树的概率接近为千万分之一。
28、哈希表中的红黑树还会转为链表吗?(高频plus & 高xinplus)
会。该过程称为反树化。当结点数量比较少时,链表的平均性能优于红黑树。当对哈希表做如下两个操作并满足对应条件时,就会出现反树化:
(1)remove操作时:判断红黑树满足根结点、根的左结点,根的左左结点,根的右结点之一为null时,在删除就会反树化
(2)put操作触发了扩容操作,如果此时红黑树结点数量 <= UNTREEIFY_THRESHOLD(其值是6),就会反树化
package com.atguigu.map;import java.util.Objects;public class MyKey {private int num;public MyKey(int num) {this.num = num;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;MyKey myKey = (MyKey) o;return num == myKey.num;}@Overridepublic int hashCode() {if(num<=20){return 1;//人为制造冲突}return Objects.hashCode(num);}
}package com.atguigu.map;import org.junit.Test;import java.util.HashMap;public class TestHashMap {@Testpublic void test1(){HashMap<Integer,String> map = new HashMap<>(40);map.put(1,"hello");System.out.println(map);}@Testpublic void test2(){String s1 = "Aa";String s2 = "BB";String s3 = "CC";System.out.println(s1.hashCode());//2112System.out.println(s2.hashCode());//2112System.out.println(s3.hashCode());//2144/*因为hashCode不等价于内存地址,它是根据对象的属性值来计算出来的。计算的时候有一个公式/算法。假设 y代表hashCode值,x代表对象,f代表某个函数或公式y = f(x)是不是会存在两个x值不同,但是y值相同。所以 存储两个不同的Java对象,但是它们的hashCode相同的。例如:Aa和BB*/}@Testpublic void test3(){HashMap<MyKey, Integer> map = new HashMap<>();for(int i=1; i<=8; i++){map.put(new MyKey(i), i);}map.put(new MyKey(9),9);map.put(new MyKey(10),10);map.put(new MyKey(11),11);//树化map.put(new MyKey(12),12);}@Testpublic void test4(){HashMap<MyKey, Integer> map = new HashMap<>();for(int i=1; i<=11; i++){map.put(new MyKey(i), i);}//上面的代码保证出现树//上面有11对map.remove(new MyKey(1));map.remove(new MyKey(2));map.remove(new MyKey(3));map.remove(new MyKey(4));map.remove(new MyKey(5));//到这一步之后,红黑树中剩下6对map.remove(new MyKey(6));map.remove(new MyKey(7));map.remove(new MyKey(8));//反树化map.remove(new MyKey(9));}@Testpublic void test5(){HashMap<MyKey, Integer> map = new HashMap<>();for(int i=1; i<=11; i++){map.put(new MyKey(i), i);}//上面的代码保证出现树//上面有11对map.remove(new MyKey(1));map.remove(new MyKey(2));map.remove(new MyKey(3));map.remove(new MyKey(4));map.remove(new MyKey(5));//到这一步之后,红黑树中剩下6对//继续putfor(int i=21; i<100; i++){map.put(new MyKey(i),i);}//扩容的临界值 threshold = table.length * loadFactor// threshold = 64 * 0.75 = 48//size >= 48 扩容}
}29、HashMap的put方法逻辑是什么?
- 计算键的哈希值
- 初始化 table 数组(如果尚未初始化)。
- 根据键的哈希值和数组长度来确定桶的位置,key.hash & table.length - 1。
- 处理桶中的节点。如果桶为空(即 table[i] == null),则直接创建一个新的 Node 并插入到桶中。
- 如果桶不为空,遍历链表或红黑树,查找是否存在相同的键。
- 如果有相同的key,直接替换原来的value,然后返回旧值结束put方法。
- 如果没有相同的key,
- 桶中已经是树,直接添加新的树结点。
- 桶中是链表,看是否达到树化要求,如果达到树化要求,就转为红黑树,然后添加新结点;如果没有达到树化要求,就直接添加新链表结点。
- 更新 size 计数器。
- 如果size达到扩容阈值,就进行扩容。
- 返回null。
相关的面试题:
问:HashMap是先插入元素还是先扩容?为什么这么设计?
答:先插入再扩容。因为插入操作是在查询重复key的过程中完成的,如果key重复,就不插入新结点了,此时也不需要扩容。
30、HashMap的数组长度有什么特点,扩容原理是什么?(高频plus & 高xinplus)
1、HashMap的默认的初始化的容量是16,也可以手动指定数组长度,数组长度一定是2的n次方,如果指定的长度不是2的n次方,会被纠正为大于该值的最近的2的n次方。这是因为K-V键值对存储到HashMap中时,会通过key 来决定每一个 entry 的存储槽位index,index=(数组的长度-1)& key的hash值,此时数组的长度是2的n次方值,才能确保每一个Node[]数组的位置都有均等的机会。

2、当HashMap中的元素size值,超过了HashMap的阈值时进行扩容,每次扩容2倍。阈值threshold = table.length * loadFactor(loadFactor的默认值DEFAULT_LOAD_FACTOR是0.75)。
第一次扩容: 阈值12 ,扩容完毕以后最大容量:32
第二次扩容: 阈值24 , 扩容完毕以后最大容量:64
依次类推。
3、另一种特定场景可能也会发生扩容:某个桶链表的结点数量达到TREEIFY_THRESHOLD(其值是8),但是数组的长度却未达到MIN_TREEIFY_CAPACITY(其值是64),此时数组会先考虑扩容而不是直接树化(即将链表转为红黑树)。
相关的面试题:
问:HashMap有没有容量限制?有,受数组长度限制
31、HashMap的负载因子是什么?(高频plus & 高xinplus)
负载因子loadFactor的默认值DEFAULT_LOAD_FACTOR是0.75。
当size达到阈值threshold = table.length * loadFactor时,HashMap的数组就会扩容。
相关的面试题:
问:负载因子默认值为什么是0.75?负载因子设置为多少合适?
答:负载因子过低会导致频繁的扩容操作,增加时间和空间开销。负载因子过高则会导致哈希冲突增多,影响查找、插入和删除操作的性能。在理想的哈希函数下,桶中元素的数量服从泊松分布。对于负载因子为 0.75 的 HashMap,桶中元素的数量分布如下:
0 个元素的概率约为 0.6065
1 个元素的概率约为 0.3033
2 个元素的概率约为 0.0758
3 个元素的概率约为 0.0126
4 个元素的概率约为 0.0016
5 个元素的概率约为 0.0002
6 个元素的概率约为 0.000013
7 个元素的概率约为 0.00000094
8 个元素的概率约为 0.00000006
更多元素的概率极低
32、HashMap键可以使用可变对象吗?
不可以。所有Map的key都不可以使用可变对象,因为可变对象无法保证存、取位置一致。
4.5 泛型(1题)
1、什么是泛型?
在Java中,泛型(Generics)是提供类型安全的机制,它允许在定义类、接口和方法时使用类型参数。通过使用泛型,可以重用相同的代码来处理不同类型的对象,同时保持类型的安全性,避免了运行时类型错误。
2、集合使用泛型有什么优点?(高频plus )
- 强制集合只容纳指定类型的对象,避免了在运行时出现ClassCastException类型转换异常,把元素类型的检查从运行时提前到了编译时。
- 代码更整洁,使用时不需要instanceof判断和显式转换。
- 优化了JVM运行时环境,因为它不会产生类型检查的字节码指令,类型检查在编译时就完成了。
3、Java中泛型的T,R,K,V,E是什么?
在Java中,泛型使用类型参数来表示不确定的数据类型。常见的类型参数有以下几个,它们通常代表特定的含义,但这些只是约定俗成的命名习惯,并不是强制性的。下面是一些常用的类型参数及其常见含义:
| 字母 | 含义 | 应用场景 | 示例 |
|---|---|---|---|
| T | 表示任意类型Type | 常用于表示泛型类或泛型方法中的某个类型 | Comparable<T>,表示T类型的比较器接口。 |
| R | 表示返回(Return)类型 | 常用于泛型方法中,表示方法的返回值类型。 | 函数式接口Function<T,R>,抽象方法 R apply(T t) |
| K | 表示键(Key)类型 | 常用于表示键值对中的键类型,尤其是在与 Map 相关的类或接口中。 |
Map<K, V>,表示一个键值对映射,其中 K 是键的类型。 |
| V | 表示值(Value)类型 | 常用于表示键值对中的值类型,尤其是在与 Map 相关的类或接口中。 |
Map<K, V>,表示一个键值对映射,其中 V 是值的类型。 |
| E | 表示元素(Element)类型 | 常用于表示集合中的元素类型,尤其是在与 List、Set 等集合相关的类或接口中。 |
List<E>,表示一个可以存储任意类型元素的列表。 |
4、泛型中的<? extends T >和 <? super T>有什么区别?
在Java泛型中,<? extends T> 和 <? super T> 是两种通配符限制,用于更灵活地处理泛型类型。它们分别表示上界通配符和下界通配符。下面详细解释这两种通配符的区别和用途。
(1)上界通配符 <? extends T>
- 含义:表示未知类型,但该类型是
T或者T的子类型。 - 用途:主要用于读取数据,让编译器知道该类型是
T或其子类型,所以可以从该类型中安全地读取T类型数据,但不能写入(除了null)。
示例:假设有一个方法需要从一个列表中读取 Number 类型的数据:
public void readNumbers(List<? extends Number> list) {for (Number number : list) {// 可以安全地读取数据System.out.println(number);}// 不能写入数据,除非写入 null// list.add(1); // 编译错误list.add(null); // 允许
}
在这个例子中,List<? extends Number> 可以接受 List<Number>、List<Integer>、List<Double> 等类型,但不能向列表中添加新的元素(除了 null),因为编译器无法确定具体类型。
(2)下界通配符 <? super T>
- 含义:表示未知类型,但该类型是
T或者T的父类型。 - 用途:主要用于写入数据,因为编译器知道该类型至少是
T或其父类型,所以可以安全地向该类型中写入数据,但不能读取(除非读取为Object类型)。
示例:假设有一个方法需要向一个列表中写入 Integer 类型的数据:
public void writeIntegers(List<? super Integer> list) {list.add(1); // 可以安全地写入数据list.add(2);// 不能读取数据,除非读取为 Object 类型// Integer number = list.get(0); // 编译错误Object obj = list.get(0); // 允许
}
在这个例子中,List<? super Integer> 可以接受 List<Integer>、List<Number>、List<Object> 等类型,可以向列表中添加 Integer 类型的数据,但不能从列表中读取数据(除非读取为 Object 类型)。
总结:
-
<? extends T>:表示未知类型是T或其子类型,主要用于读取数据。-
集合工具类Collections: public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)
-
-
<? super T>:表示未知类型是T或其父类型,主要用于写入数据。-
集合工具类Collections: public static <T> boolean addAll(Collection<? super T> c, T... elements) :添加elements的元素到c集合中 public static <T> void copy(List<? super T> dest, List<? extends T> src):复制src集合的元素到dest集合中 public static <T> void fill(List<? super T> list, T obj):用obj对象填充list集合
-
这两种通配符限制使得泛型更加灵活,能够在保证类型安全的同时,处理不同类型的数据。正确使用这些通配符可以避免不必要的类型转换和潜在的运行时错误。
5、泛型的实现原理是什么?
Java中的泛型实现主要依赖于一种称为“类型擦除”(Type Erasure)的技术。类型擦除是指在编译阶段,Java编译器会将泛型类型信息擦除,并替换为相应的原始类型(raw type),同时在编译时插入必要的类型转换和类型检查代码,以确保类型安全。下面是泛型实现原理的详细过程:
-
擦除类型参数:编译器会将泛型类型参数替换为它们的边界类型(通常是
Object)。例如,List<E>在编译后会变成List,边界类型是ObjectStudent<S extends Number>在编译后会变成Student,边界类型是Number
-
插入类型检查和转换:编译器会在适当的位置插入类型转换代码,以确保类型安全。例如,从
List中取出的对象会被自动转换为指定的类型。 -
生成桥接方法:如果泛型方法覆盖了父类中的方法,编译器会生成桥接方法(bridge method),以确保多态行为的正确性。
(1)类型擦除(Type Erasure)
假设有一个泛型类:
public class Box<T> {private T item;public void set(T item) {this.item = item;}public T get() {return item;}
}
类型擦除是指在编译期间,编译器会移除泛型类型信息,将泛型代码转换为非泛型代码。这样做的目的是为了兼容Java 1.5之前的版本,因为在Java 1.5之前没有泛型。
编译后的字节码(简化版):
public class Box {private Object item; // 擦除后的类型public void set(Object item) {this.item = item;}public Object get() {return item;}
}
(2)类型转换和类型检查
首先,编译器还会在编译时进行类型检查,确保在使用泛型时不会出现类型不匹配的错误。例如:
Box<String> box = new Box<>();
box.set(123); // 编译错误,123 不是 String 类型
其次,编译器会在适当的位置插入类型转换代码,以确保类型安全。例如:
Box<String> box = new Box<>();
box.set("Hello");
String message = box.get(); // 编译器插入类型转换
编译后的字节码:
Box box = new Box();
box.set("Hello");
String message = (String) box.get(); // 插入类型转换
(3)桥接方法(Bridge Method)
桥接方法是编译器自动生成的方法,用于解决泛型方法覆盖父类方法时的类型擦除问题。
class Generic<T>{public void print(T obj) {System.out.println(obj);}
}
class SubGeneric extends Generic<String>{}
编译后的字节码(简化版)
class Generic{public void print(Object obj) {System.out.println(obj);}
}
class SubGeneric extends Generic<String> {// 实际的方法public void print(String obj) {System.out.println(obj);}// 桥接方法public void print(Object obj) {print((String) obj); // 调用实际的方法}
}
6、泛型擦除会带来什么问题?
Java中的泛型通过类型擦除(Type Erasure)技术实现了类型安全和兼容性。编译器在编译时会移除泛型类型信息,并插入必要的类型转换和类型检查代码,以确保程序的正确性和安全性。但它也带来了一些问题和限制。以下是类型擦除可能导致的主要问题:
(1)运行时类型信息丢失
例如,你不能在运行时检查一个 List 的具体类型参数。
List<String> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>();System.out.println(list1.getClass() == list2.getClass()); // 输出 true
解决方案:如果你需要在运行时获取泛型类型信息,可以使用反射或其他方法来传递类型信息。例如,可以通过传递 Class 对象来保留类型信息。
(2)泛型数组的创建问题
List<String>[] stringLists = new List<String>[10]; // 编译错误
解决方案:可以使用类型转换和原始类型数组来间接创建泛型数组,但这样做会有潜在的运行时风险。
List<String>[] stringLists = (List<String>[]) new List[10]; // 不推荐,会有警告
(3)泛型方法的重载问题
由于类型擦除,编译器可能无法区分具有相同签名的泛型方法,导致重载冲突。
public class Example {public void method(List<String> list) {}public void method(List<Integer> list) {} // 编译错误
}
解决方案:可以通过改变方法名或参数列表来避免重载冲突。
(4)无法使用基本类型作为泛型参数
由于类型擦除,Java泛型不支持基本类型作为类型参数。必须使用包装类型(如 Integer 而不是 int)。
List<int> intList = new ArrayList<>(); // 编译错误
List<Integer> intList = new ArrayList<>(); // 正确
解决方案:使用包装类型,或者在需要频繁操作基本类型的情况下,考虑使用非泛型的解决方案。
(5)泛型类型的实例化问题
问题描述
由于类型擦除,你不能直接实例化一个泛型类型。
T t = new T(); // 编译错误
解决方案:可以使用工厂方法或传递 Class 对象来实例化泛型类型。
(6)桥接方法的生成
编译器为了支持多态,会生成桥接方法(Bridge Method),这可能会导致字节码膨胀,并且在某些情况下可能会引入额外的复杂性。
4.6 Lambda和StreamAPI(1题)
1、Java8新增了哪些新特性?
- 接口的默认方法和静态方法。
- 默认方法:接口中可以定义默认方法,子类可以选择性地重写这些方法。
- 静态方法:接口中可以定义静态方法,可以直接通过接口调用。
- 新的日期和时间 API:Java 8 引入了 java.time 包,提供了更丰富的日期和时间处理功能。
- Optional 类:Optional 类用于表示可能为 null 的值,避免空指针异常。
- 函数式接口:函数式接口是只有一个抽象方法的接口,可以用 @FunctionalInterface 注解标记。函数式接口的变量可以采用Lambda 表达式进行赋值。
- Lambda 表达式:Lambda 表达式允许你将函数作为参数传递。
- 方法引用:方法引用允许你直接引用已有的方法或构造器,而无需显式地创建 Lambda 表达式。
- 移除 PermGen 空间:Java 8 移除了 PermGen(永久代) 空间,取而代之的是 Metaspace(元空间)。
2、函数式接口是什么?函数式接口分为哪几类?
函数式接口是只包含一个抽象方法的接口(简称SAM接口,Single Abstract Method)。当然函数式接口可以有多个默认方法和静态方法。
Java 8 引入了 @FunctionalInterface 注解来标记和检查一个接口是否为函数式接口。这个注解不是必须的,但它可以帮助编译器在编译时检查接口是否符合函数式接口的要求。
| 代表接口 | 抽象方法 | 抽象方法特点 | 方法体/Lambda体 | |
|---|---|---|---|---|
| 任务型接口 | Runnable | void run() | 无参无返回值 | 完成某个任务,不返回结果 |
| 消费型接口 | Consumer |
void accept(T t) | 有参无返回值 | 对参数完成某个操作,不返回结果 |
| 生产型接口 | Supplier |
T get() | 无参有返回值 | 产生一个结果返回 |
| 功能型接口 | Function<T,R> | R apply(T t) | 有参有返回值 | 对参数进行修改,返回新结果 |
| 判断型接口 | Predicate |
boolean test(T t) | 有参有返回值,返回值是boolean | 对参数进行条件判断,返回true或 |
| 比较型接口 | Comparator |
int compare(T t1, T t2) | 有参有返回值,返回值是int | t1>t2返回正整数,t1<t2返回负整数,t1==t2返回0 |
3、Lambda表达式是什么?有什么用?(高频plus & 高xinplus)
Lambda表达式其实就是匿名函数,它是实现SAM接口(Single Abstract Method,函数式接口)的一种语法糖,它使得Java也成为支持函数式编程的语言。Lambda写的好可以极大的减少代码冗余,同时可读性也好过冗长的(啰嗦的)匿名内部类。
Lambda表达式可以用于给函数式接口的变量赋值。例如:当某个方法的参数或返回值类型是函数式接口类型时,Lambda表达式可以被用作参数传递或者返回值。
4、方法引用是什么?分为哪几类?
方法引用是Java 8引入的一种新的特性,它允许你直接引用已有的方法或构造器,而无需显式地创建Lambda表达式。方法引用可以使代码更加简洁和易读。方法引用的类型:
- 静态方法引用:引用类的静态方法,形式:类名::静态方法名
- 实例方法引用:引用特定对象的实例方法,形式:对象名::实例方法名
- 对象方法引用:引用任意对象的实例方法,形式:类名::实例方法名
- 构造器引用:引用类的构造器,形式:类名::new
5、请写一个Lambda表达式的使用案例?
import org.junit.Test;import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.function.Consumer;public class TestLambda {@Testpublic void test1(){ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "hello","java","hi","尚硅谷","atguigu");//把上面的字符串按照从短到长排序//方式一:匿名内部类list.sort(new Comparator<String>() {@Overridepublic int compare(String o1, String o2) {return Integer.compare(o1.length(), o2.length());}});list.forEach(new Consumer<String>() {@Overridepublic void accept(String s) {System.out.println(s);}});}@Testpublic void test2(){ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "hello","java","hi","尚硅谷","atguigu");//把上面的字符串按照从短到长排序//方式二:Lambda表达式list.sort((o1, o2) -> Integer.compare(o1.length(), o2.length()));list.forEach(s -> System.out.println(s));}@Testpublic void test3(){ArrayList<String> list = new ArrayList<>();Collections.addAll(list, "hello","java","hi","尚硅谷","atguigu");//把上面的字符串按照从短到长排序//方式三:Lambda表达式 进一步用方法引用简化list.sort(Comparator.comparingInt(String::length));list.forEach(System.out::println);}
}
6、自定义一个函数式接口,并运用它?
@FunctionalInterface
public interface IntCalculate {int calculate(int a, int b);
}
import org.junit.Test;public class TestIntCalculate {@Testpublic void test1(){IntCalculate c1 = (a,b)->a+b;System.out.println(c1.calculate(2,3));IntCalculate c2 = (a,b)->a>b?a:b;System.out.println(c2.calculate(2,3));}
}
7、Stream流是什么?
Stream 流是Java 8引入的一个强大的功能,用于处理数据集合。Stream 提供了一种高效且易于使用的处理数据的方式,支持顺序和并行处理。Stream 不存储数据,而是通过管道操作(如过滤、映射、归约等)对数据进行处理。
Stream的主要特点:
- 懒加载:Stream 的许多操作是懒加载的,这意味着它们不会立即执行,而是在终端操作(如 collect、forEach 等)时才会执行。
- 链式调用:Stream 支持链式调用,可以将多个操作串联起来,形成一个流水线。
- 函数式编程:Stream 支持函数式编程风格,可以使用Lambda表达式和方法引用来简化代码。
- 并行处理:Stream 可以很容易地转换为并行流,利用多核处理器进行并行处理,提高性能。
8、Stream流分为哪几类?怎么创建?
Stream 流在Java 8中主要分为两类:顺序流(Sequential Stream)和并行流(Parallel Stream)。这两类流的主要区别在于处理数据的方式和性能表现。
- 顺序流(Sequential Stream):顺序流按顺序处理数据,即每次只处理一个元素。单线程执行。适用于数据量较小或对顺序有要求的场景。代码容易理解和调试。创建方式:
- 使用 Collection 接口的 stream() 方法。
- 使用 Arrays 类的 stream() 方法。
- 使用 Stream 类的静态方法 of()、iterate()、generate() 等。
- 并行流(Parallel Stream):并行流可以同时处理多个数据元素,利用多核处理器的并行计算能力。多线程执行。适用于数据量较大且对顺序无严格要求的场景。性能提升明显,但可能会增加代码复杂性和调试难度。创建方式:
- 使用 Collection 接口的 parallelStream() 方法。
- 使用 Stream 类的 parallel() 方法将顺序流转换为并行流。
9、Stream中map和flatMap方法的区别?
- map方法不会影响流中元素的个数,但是流中元素的类型、元素值可能发生变化。它的原理是按照统一的规则将现在流中每一个元素改造为另一个对象。
- flatMap方法会影响流中元素的个数,同时流中元素的类型、元素值也可能发生变化。它的原理是按照某个规则将现在流中每一个元素计算为一个新的Stream,然后最后将所有Stream合并为一个大的Stream。
import org.junit.Test;import java.util.Arrays;
import java.util.stream.Stream;public class TestMapFlatMap {@Testpublic void test13(){Stream.of("hello","java","atguigu") //取出首字母.map(t->t.charAt(0)).forEach(System.out::println);//map操作,元素的个数不会发生变化,类型可能变化}@Testpublic void test14(){Stream.of("hello","java","atguigu") //把所有单词的每一个字母取出来.flatMap(s-> Arrays.stream(s.split("|"))).forEach(System.out::println);}
}10、Stream中map、peek、forEach方法的区别?
- map方法不会影响流中元素的个数,但可能会影响元素的类型、值。方法的返回值仍然是一个Stream,后续还可以对新流进行操作。
- peek方法不会影响流中元素的个数、类型、值,只是利用元素完成一个操作。方法的返回值仍然是一个Stream,后续还可以对新流进行操作。
- forEach方法也不会影响流中元素的个数、类型、值,只是利用元素完成一个操作。方法的返回值是void,到此流操作结束。
4.7 IO流(6题)
1、什么是IO?
IO(Input/Output,输入/输出)是指计算机系统中数据的传输过程。在编程中,IO 主要涉及数据的读取和写入操作,这些操作通常涉及到文件、网络、设备等外部资源。
2、IO中输入流和输出流有什么区别?
在Java的I/O系统中,输入流(InputStream)和输出流(OutputStream)是两个基本的概念,它们分别用于读取和写入数据。
3、常用的IO类有哪些?
Java 语言提供了丰富的 IO 库来处理各种输入输出任务。Java IO 的主要组成部分:
- 字节流(Byte Streams):InputStream和OutputStream系列。
- 字符流(Character Streams):Reader和Writer系列。
- 文件操作:以File开头的IO流类。
- 缓冲流:以Buffered开头的IO流类。
- 数据流:以Data开头的IO流类。
- 对象流:以Object开头的IO流类。
- 管道流:以Piped开头的IO流类。
- 打印流:以Print开头的IO流类。
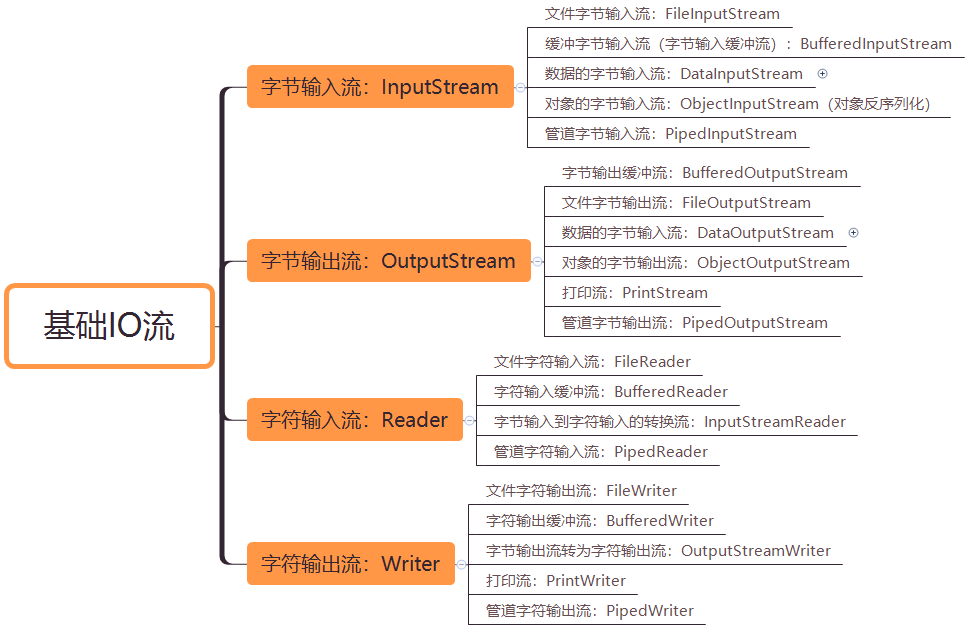
4、什么是比特、字节、字符?
- 比特:是最小的信息单位,表示一个二进制位。
- 字节:由8个比特组成,是计算机中常见的数据单位。
- 字符:是人类可读的符号,需要通过编码方式转换为字节,以便在计算机中存储和传输。
5、字节流和字符流有什么区别?
在Java的I/O系统中,字节流和字符流是两种不同的流类型。
- 字节流用于读取和写入二进制数据,以字节(8位)为单位进行操作。适用于处理所有类型的二进制数据,如图像、音频、视频文件等。
- 字符流用于读取和写入字符数据,以字符(一个字符占几个字节与具体的编码方式有关)为单位进行操作。适用于处理文本数据,如文本文件、日志文件等。
6、缓冲区和缓存有什么区别?
在计算机科学和软件工程中,缓冲区和缓存是两个常用的概念,虽然它们都用于临时存储数据,但它们的用途和工作原理有所不同。以下是它们的主要区别:
- 在数据从一个地方传输到另一个地方的过程中,缓冲区可以暂时存储数据,以减少频繁的I/O操作,提高效率。缓冲区中的数据通常是临时的,一旦数据被处理完毕,缓冲区中的内容就会被清空或覆盖。缓冲区通常有固定的大小,超出缓冲区大小的数据需要分批处理。数据通常按照先进先出(FIFO)的方式处理。
- 缓存是一种高速存储区域,用于存储经常访问的数据,以减少访问低速存储设备的次数,提高数据访问速度。缓存中的数据可以长时间保留,直到被显式清除或替换。缓存的内容通常是动态变化的,根据数据的访问频率和重要性进行更新。缓存通常有特定的替换策略,如LRU(最近最少使用)、LFU(最不经常使用)等,以决定哪些数据应该保留在缓存中。
7、字节流怎么转换为字符流?
在Java中,字节流和字符流之间可以通过一些适配器类进行转换。具体来说,可以使用 InputStreamReader 和 OutputStreamWriter 来实现字节流和字符流之间的转换。
import org.junit.Test;import java.io.*;public class TestByteToChar {@Testpublic void test1()throws Exception{try (// 创建字节输入流FileReader fr = new FileReader("GBK.txt");){// 读取字符int data;while ((data = fr.read()) != -1) {System.out.print((char) data);}} catch (IOException e) {e.printStackTrace();}}@Testpublic void test2(){try (// 创建字节输入流FileInputStream fis = new FileInputStream("input.txt");// 使用 InputStreamReader 将字节输入流转换为字符输入流,同时指定字符编码,例如 GBKInputStreamReader reader = new InputStreamReader(fis, "GBK");){// 读取字符int data;while ((data = reader.read()) != -1) {System.out.print((char) data);}} catch (IOException e) {e.printStackTrace();}}@Testpublic void test3()throws Exception{try(FileWriter fw = new FileWriter("GBK.txt");){String data = "尚硅谷";// 写入字符fw.write(data);}catch (IOException e) {e.printStackTrace();}}@Testpublic void test4(){try (// 创建字节输出流FileOutputStream fos = new FileOutputStream("GBK.txt");// 使用 OutputStreamWriter 将字符输出流转换为字节输出流,同时指定字符编码,例如 GBKOutputStreamWriter writer = new OutputStreamWriter(fos, "GBK");){String data = "尚硅谷";// 写入字符writer.write(data);} catch (IOException e) {e.printStackTrace();}}}
8、读写文本文件时如何处理字符编码?(高频plus)
FileReader和FileWriter在读写文本文件时,可以直接指定文件的字符编码。
import org.junit.Test;import java.io.*;
import java.nio.charset.Charset;public class TestFileReaderWriter {@Testpublic void test1(){try (//从UTF8的文件中读取内容FileReader fr = new FileReader("D:\\UTF8.txt", Charset.forName("UTF-8"));//写内容到GBK的文件中FileWriter fw = new FileWriter("D:\\GBK.txt",Charset.forName("GBK"));){int len;char[] data = new char[10];while((len = fr.read(data)) != -1){fw.write(data,0,len);}} catch (IOException e) {e.printStackTrace();}}
}
9、Java序列化是什么?(高频plus & 高xinplus)
序列化和反序列化是Java中实现对象持久化的重要机制。
- 序列化是指将对象的状态信息转换为字节流的过程,以便于将这些字节流保存到文件、数据库或通过网络传输。
- 反序列化则是将字节流恢复为对象的过程。
要使一个对象可序列化,需要实现 Serializable 接口。Serializable 接口是一个标记接口,没有任何方法需要实现。
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@AllArgsConstructor
@NoArgsConstructor
public class Student implements java.io.Serializable{private static String school;private String name;private int score;
}
import org.junit.Test;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;public class TestStudentSerialize {@Testpublic void test1(){Student student = new Student("谷姐", 100);try(FileOutputStream fos = new FileOutputStream("student.obj");ObjectOutputStream oos = new ObjectOutputStream(fos);){oos.writeObject(student);} catch (Exception e) {e.printStackTrace();}}@Testpublic void test2(){try(FileInputStream fis = new FileInputStream("student.obj");ObjectInputStream ois = new ObjectInputStream(fis);){Object stu = ois.readObject();System.out.println(stu);} catch (Exception e) {e.printStackTrace();}}
}10、序列化ID(seriaVersionUID)的作用是什么?(高频plus & 高xinplus)
在Java中,serialVersionUID 是一个静态的、最终的长整型变量,用于唯一标识一个可序列化的类。它的主要作用是在序列化和反序列化过程中确保类的版本一致性。当类的结构发生变化时(例如添加、删除或修改字段),serialVersionUID 可以帮助确保旧版本的序列化数据能够与新版本的类兼容。
相关的面试题:
问1:序列化ID(seriaVersionUID)的格式是怎样的?
答:private static final long serialVersionUID = 值;
问2:序列化ID(seriaVersionUID)一定要显式声明吗?
答:如果类没有显式声明 serialVersionUID,Java 运行时环境会根据类的结构(包括类名、接口名、成员方法和属性等)自动生成一个 serialVersionUID。自动生成的 serialVersionUID 是基于类的结构计算出来的哈希值。如果类的结构发生变化(例如添加、删除或修改字段),生成的 serialVersionUID 也会变化。如果序列化数据的 serialVersionUID 与类的 serialVersionUID 不匹配,Java 运行时环境会抛出 InvalidClassException 异常。
所以,显式声明 serialVersionUID 可以确保类的版本一致性。即使类的结构发生变化,只要 serialVersionUID 保持不变,旧版本的序列化数据仍然可以被新版本的类正确反序列化。
问3:序列化ID(seriaVersionUID)默认生成的有什么特点?(见上一题)
问4:序列化ID(seriaVersionUID)一定是唯一的吗?
答:serialVersionUID 并不一定需要是全局唯一的,但它必须在同一个类的不同版本之间保持一致,以确保序列化和反序列化过程的兼容性。不同类之间的 serialVersionUID 可以相同,因为 serialVersionUID 是类级别的标识符,而不是全局唯一的标识符。
问5:同一个类的不同对象可以有不同的序列化ID(seriaVersionUID)吗?
答:不可以。serialVersionUID 是一个静态的、最终的长整型变量(static final long),它属于类级别,而不是实例级别。这意味着 serialVersionUID 是在整个类的所有对象之间共享的,同一个类的所有对象都具有相同的 serialVersionUID。
问6:序列化ID(seriaVersionUID)可以修改吗?什么情况下可以修改?
答:serialVersionUID 是一个静态的、最终的长整型变量(static final long),不能在运行时修改,但在开发过程中,你可以根据需要修改其值。当你对类的结构进行了重大修改,例如添加、删除或修改字段,这些修改可能会影响序列化数据的兼容性。在这种情况下,修改 serialVersionUID 可以确保旧版本的序列化数据无法被新版本的类反序列化,从而避免潜在的数据损坏或错误。
10、静态变量能不能被序列化?
在 Java 中,静态变量(static 变量)不会被序列化。这是因为序列化的主要目的是保存和恢复对象的状态,而静态变量属于类级别,不是对象的一部分。因此,序列化机制不会保存静态变量的值。
番外篇:正常来说,不会也不应该序列化静态变量,但是如果你非要这么做,只能通过writeObject方法手动定义序列化规则。

11、transient关键字有什么用?
在 Java 中,transient 关键字用于标记类的成员变量,使其在序列化过程中被忽略。具体来说,transient 关键字有以下几个主要用途:
- 排除敏感数据:某些数据可能是敏感的,例如密码、密钥等,这些数据不应该被序列化并存储在文件或传输到网络上。使用 transient 关键字可以确保这些数据不会被序列化。通过排除敏感数据,可以提高应用程序的安全性,防止敏感信息泄露。
- 优化序列化性能:某些数据量较大的字段,例如大对象、大数组等,如果不需要在序列化过程中保存,可以使用 transient 关键字来排除这些字段,从而减少序列化数据的大小,提高性能。减少不必要的数据序列化可以节省磁盘空间和网络带宽。
- 动态计算的字段:某些字段可能是在运行时动态计算的,这些字段的值可以在需要时重新计算,不需要保存在序列化数据中。使用 transient 关键字可以避免保存这些临时数据。在反序列化时,可以重新初始化这些字段的值。
问:ArrayList集合中elementData数组为什么加transient修饰?
答:elementData数组中可能有很多null值,size < elementData.length,因此序列化时,只需要序列化size个对象即可,而不是整个数组。
因此ArrayList类中手动实现 writeObject 和 readObject 方法定制了特殊的序列化过程。
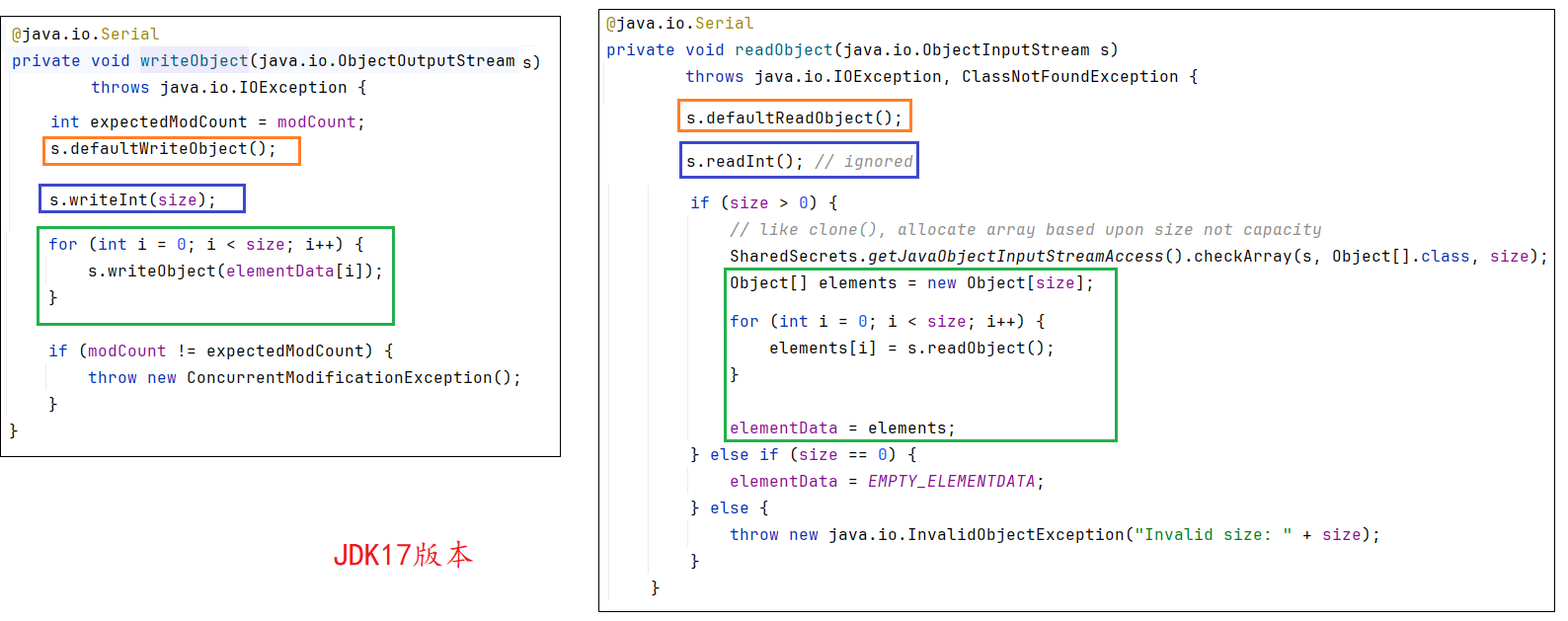
新旧对应关系的分析:
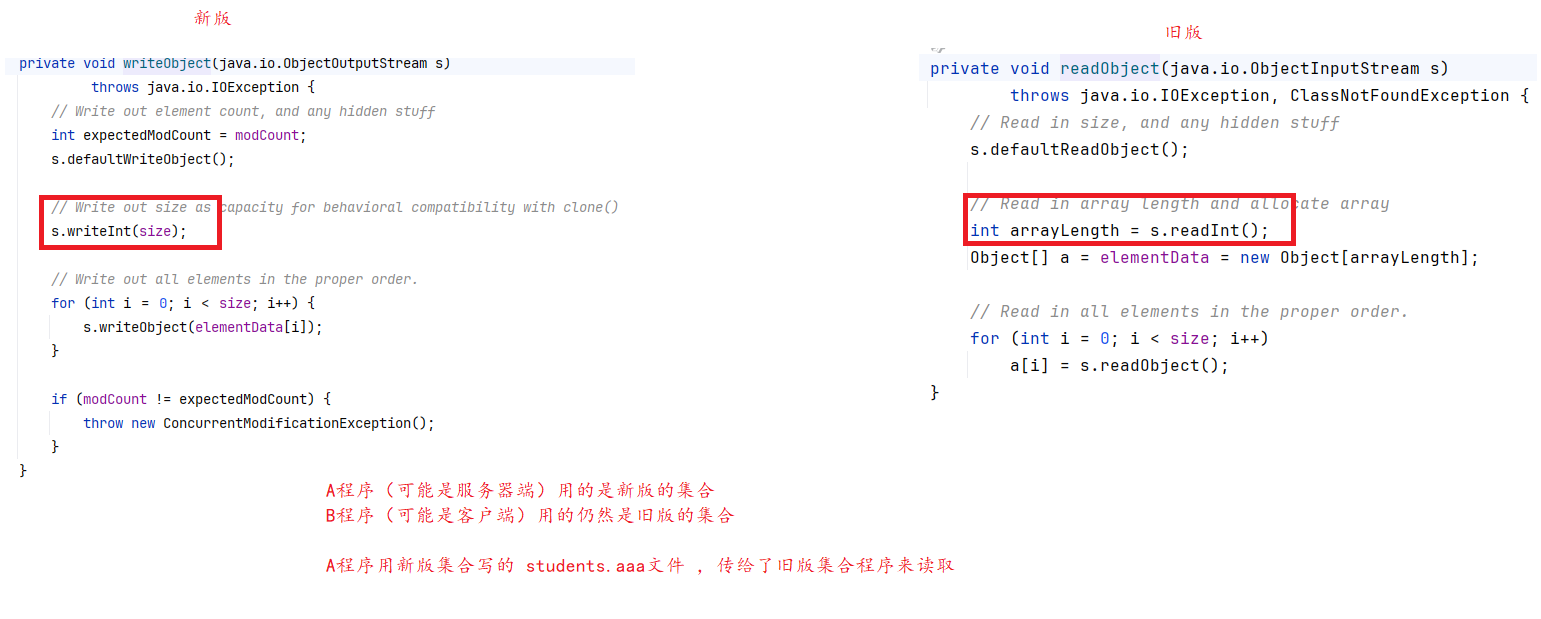
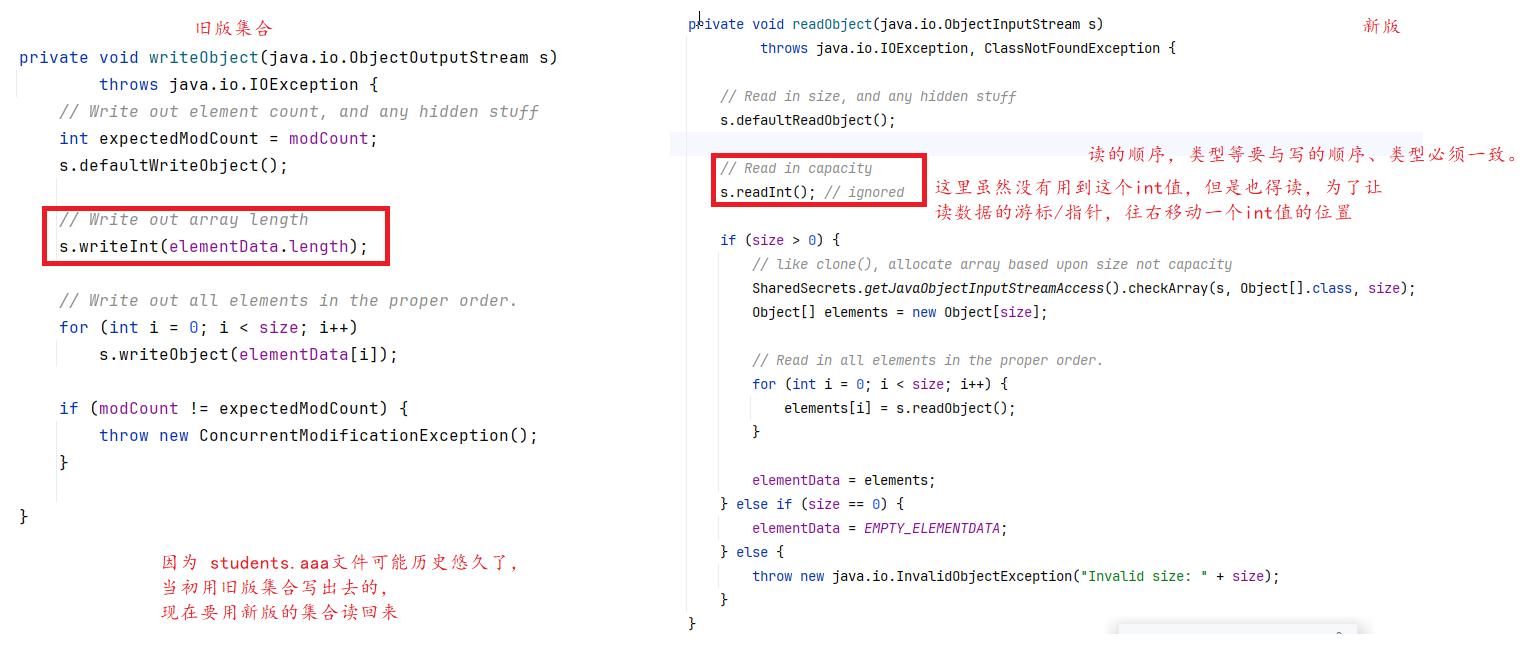
12、序列化一个对象时,有哪些要注意的?(高频plus & 高xinplus)
在进行序列化和反序列化时,需要注意以下几个方面:
- 要使一个类的对象可以被序列化,该类必须
实现 Serializable 接口。 - 建议
显式定义 serialVersionUID,以避免因编译器自动生成的 serialVersionUID 不一致而导致的问题。 - 明确哪些变量不序列化:
static和transient标识变量不会被序列化。 - 尽量避免复杂的对象图,或者使用 transient 关键字来排除不必要的引用。如果对象图中有循环引用(即对象 A 引用对象 B,对象 B 又引用对象 A),序列化机制会自动处理这种情况,但可能会导致性能问题。
- 如果需要对序列化和反序列化过程进行更细粒度的控制,可以在类中实现 writeObject 和 readObject 方法。
13、Java有哪两种序列化方式?
- 实现Serializable接口。该接口不包含任何抽象方法。如果需要更细粒度的控制,可以在类中手动实现 writeObject 和 readObject 方法。
- 实现Externalizable接口。该接口包含writeExternal和readExternal方法。
14、序列化中@Serial注解的作用?
在 Java 16 及更高版本中,引入了一个新的注解 @Serial,用于在序列化相关的代码中提供更好的文档化和维护性。@Serial 注解主要用于标记那些与序列化相关的特殊方法和字段,使得这些方法和字段在代码审查和维护时更加清晰。具体来说,@Serial 注解可以用于以下几种情况:
- 标记 serialVersionUID 字段:确保 serialVersionUID 字段的定义清晰可见。
- 标记 writeObject 和 readObject 方法:确保这些方法的实现清晰可见。
- 标记 readResolve 和 writeReplace 方法:确保这些方法的实现清晰可见。
15、什么是BIO?什么是NIO?什么是AIO?(高频plus & 高xinplus)
| BIO | NIO | AIO | |
|---|---|---|---|
| 概念 | Blocking I/O(即同步阻塞式 I/O),它就是传统的IO |
Non-blocking I/O(即同步非阻塞式 I/O),也称为 New I/O |
Asynchronous I/O(异步 I/O) |
| 技术 | 基于流模型 |
基于缓冲区和通道 |
基于事件回调机制 |
| 应用场景 | 适用于连接数较少且每个连接的数据量较大的场景 |
适用于连接数较多且每个连接的数据量较小的场景 |
适用于高并发、低延迟的场景,如高性能服务器 |
| 特点 | 当客户端发起一个 I/O 操作请求时,服务器端会阻塞,直到 I/O 操作完成。 仅支持从输入流中读取数据,将数据写入输出流 每个连接都需要一个独立的线程来处理。 |
客户端发起 I/O 操作请求后,服务器端不会阻塞,可以继续处理其他任务。 使用通道(Channel)和缓冲区(Buffer)进行数据读写。 支持选择器(Selector),可以监听多个通道的事件。 |
客户端发起 I/O 操作请求后,服务器端立即返回,继续处理其他任务。 I/O 操作完成后,操作系统会通知服务器端程序。 AIO的工作机制基于事件和回调机制,这种机制使得线程可以在I/O操作完成时通过回调机制继续执行其他任务,不需要轮询检查 I/O 操作的状态。 |
16、Java如何高效率读写大文件?(高频plus & 高xinplus)
方式一:使用缓冲流和文件流
方式二:使用Files工具类的方法
方式三:使用NIO的FileChannel和Buffer
import org.junit.Test;import java.io.*;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;public class TestBigFile {@Testpublic void test1(){//方式一:使用缓冲流和文件流String inputFilePath = "D:\\large_input.txt";String outputFilePath = "D:\\large_output.txt";try (FileInputStream fis = new FileInputStream(inputFilePath);BufferedInputStream bis = new BufferedInputStream(fis);FileOutputStream fos = new FileOutputStream(outputFilePath);BufferedOutputStream bos = new BufferedOutputStream(fos)) {byte[] buffer = new byte[8192];int bytesRead;while ((bytesRead = bis.read(buffer)) != -1) {bos.write(buffer, 0, bytesRead);}} catch (IOException e) {e.printStackTrace();}}@Testpublic void test2(){//方式二:使用Files工具类的方法Path inputPath = Paths.get("D:\\large_input.txt");Path outputPath = Paths.get("D:\\large_output.txt");try {// 读取文件内容byte[] fileContent = Files.readAllBytes(inputPath);// 写入文件内容Files.write(outputPath, fileContent);} catch (IOException e) {e.printStackTrace();}}@Testpublic void test3(){//方式三:使用NIO的FileChannel和BufferString inputFilePath = "D:\\large_input.txt";String outputFilePath = "D:\\large_output.txt";try (RandomAccessFile inputFile = new RandomAccessFile(inputFilePath, "r");FileChannel inputChannel = inputFile.getChannel();RandomAccessFile outputFile = new RandomAccessFile(outputFilePath, "rw");FileChannel outputChannel = outputFile.getChannel()) {long fileSize = inputChannel.size();MappedByteBuffer inputBuffer = inputChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileSize);MappedByteBuffer outputBuffer = outputChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileSize);for (int i = 0; i < fileSize; i++) {outputBuffer.put(i, inputBuffer.get(i));}} catch (IOException e) {e.printStackTrace();}}
}
17、如何比较两文件的内容是否相等?
选择哪种方法取决于文件的大小和类型。
第一步:查看两个路径是不是指向同一个文件
- 使用 Files 类的 isSameFile 方法:检查两个路径是否指向同一个文件,不适用于内容相同但路径不同的文件。
第二步:查看两个文件大小是不是一致
- 获取两个文件大小,然后比较文件大小
第三步:
-
如果文件不大:使用 Files 类的 readAllBytes 方法一次性读取文件的所有字节,然后用Arrays.equals(byte[] a, byte[] b)方法对字节数组进行比较 ,适用于较小的文件。
-
对于较大的文件,建议使用逐行比较或逐字节比较,以避免内存溢出。
-
任意类型文件:使用字节流一次读取多个字节,然后用Arrays.equals(byte[] a, byte[] b)方法对字节数组进行比较 。
-
纯文本文件:使用 BufferedReader 或Scanner逐行读取,然后用Objects.equals(Object s1, Object s2)方法比较行文本。
-
package com.atguigu.compare;import org.junit.Test;import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Arrays;public class TestCompareFile {@Testpublic void test1()throws Exception{Path p1 = Path.of("d:\\1.txt");Path p2 = Path.of("/1.txt");System.out.println(smallFile(p1, p2)?"相同":"不相同");}@Testpublic void test2()throws Exception{Path p1 = Path.of("d:\\1.txt");Path p2 = Path.of("d:\\2.txt");System.out.println(smallFile(p1, p2)?"相同":"不相同");}public boolean smallFile(Path p1, Path p2) throws IOException {if(Files.isSameFile(p1,p2)){return true;}byte[] b1 = Files.readAllBytes(p1);byte[] b2 = Files.readAllBytes(p2);return Arrays.equals(b1,b2);}@Testpublic void test3()throws Exception{Path p1 = Path.of("d:\\1.txt");Path p2 = Path.of("d:\\2.txt");System.out.println(TxtFile(p1, p2)?"相同":"不相同");}public boolean TxtFile(Path p1, Path p2) throws IOException {if(Files.isSameFile(p1,p2)){return true;}try(FileReader f1 = new FileReader(p1.toFile());BufferedReader b1 = new BufferedReader(f1);FileReader f2 = new FileReader(p2.toFile());BufferedReader b2 = new BufferedReader(f2);){while(true){String s1 = b1.readLine();String s2 = b2.readLine();if(s1 == null && s2 == null){return true;}if(s1 == null || s2 == null){return false;}if(!s1.equals(s2)){return false;}}}catch (IOException e){throw new IOException(e);}}@Testpublic void test4()throws Exception{Path p1 = Path.of("d:\\1.jpg");Path p2 = Path.of("d:\\2.jpg");System.out.println(bigFile(p1, p2)?"相同":"不相同");}public boolean bigFile(Path p1, Path p2) throws IOException {if(Files.isSameFile(p1,p2)){return true;}try( FileInputStream f1 = new FileInputStream(p1.toFile());FileInputStream f2 = new FileInputStream(p1.toFile());) {byte[] b1 = new byte[1024];byte[] b2 = new byte[1024];while (true) {int length1 = f1.read(b1);int length2 = f2.read(b2);if (length1 == -1 && length2 == -1) {return true;}if (length1 == -1 || length2 == -1) {return false;}if (!Arrays.equals(b1, b2)) {return false;}}}catch (IOException e){throw new IOException(e);}}
}4.8 多线程(8题)
1、为什么要使用多线程?
多线程编程是一种常见的并发编程技术,它允许多个任务在同一时间(或看起来是同一时间)执行。使用多线程的主要原因包括:
- 提高程序响应性:确保用户界面和实时系统保持响应。
- 利用多核处理器:充分利用多核处理器,提高程序的执行效率。
- 提高吞吐量:同时处理多个任务,提高系统的吞吐量。
- 简化复杂任务:将复杂任务分解成多个子任务,使代码更简洁、更易于维护。
- 提高资源利用率:共享内存和其他资源,减少资源的冗余和浪费。
- 提高用户体验:确保应用程序在执行耗时操作时仍然保持流畅,提供即时反馈。
- 解决I/O瓶颈:处理I/O密集型任务,避免I/O操作阻塞主线程。
通过合理使用多线程,可以显著提升应用程序的性能和用户体验。
2、串行、并行和并发有什么区别?
- 串行(Serial):串行是指多个任务按顺序依次完成。此时反而使用单线程效果更好,避免了线程的切换。
- 并行(Parallelism):并行是指多个任务在同一时刻真正同时执行的能力。这通常需要多核处理器或多台计算机来实现。在多核处理器上,每个核心可以同时执行不同的任务,从而实现真正的并行计算。主要目标是提高计算性能,通过同时执行多个任务来加速计算密集型任务。适用于计算密集型任务,如矩阵运算、图像处理等。
- 并发(Concurrency):并发是指多个任务在同一时间段内
交替执行的能力。这些任务可能共享资源,但不一定同时执行。在单核处理器上,操作系统通过时间片轮转等方式让多个任务看起来像是同时执行的。主要目标是提高系统的响应性和吞吐量,使多个任务能够在同一时间段内高效地执行。适用于 I/O 密集型任务,如网络请求、文件读写等。
3、创建线程有哪几种方式?(高频plus & 高xinplus)
创建线程通常有四种方式:
- 继承 Thread 类:简单直接,但只能继承 Thread 类。
- 实现 Runnable 接口:更灵活,可以与其他接口或类组合使用。
- 实现 Callable 接口:可以返回结果并抛出异常,通常与 FutureTask 结合使用。
- 使用线程池:通过 ExecutorService 管理线程池,提高线程的复用率和程序性能。
选择哪种方式取决于具体的应用场景和需求。对于简单的任务,继承 Thread 类或实现 Runnable 接口即可;对于需要返回结果的任务,可以使用 Callable 接口;对于需要高效管理和复用线程的任务,推荐使用线程池
4、启动一个线程用start还是run?(高频plus)
正确的做法是使用 start 方法来启动线程,而不是直接调用 run 方法。
- 调用 start 方法后,会创建一个新的线程,并在新线程中执行 run 方法中的代码。这样可以实现真正的并发执行。
- 直接调用 run 方法并不会启动新线程,而是在当前线程中执行 run 方法中的代码。这与普通方法调用没有区别,不会实现并发执行。
相关的面试题:
问:一个线程可以多次start吗?不能
答:一个线程对象只能调用一次 start 方法,再次调用会抛出 IllegalThreadStateException 异常。如果需要多次执行相同的任务,可以创建新的线程对象或使用线程池来管理线程。
5、怎么理解线程分组?编程实现一个线程分组的例子?
线程组(Thread Group)是一种将多个线程组织在一起的机制。每个线程在创建时都会被分配到一个线程组,默认情况下,主线程会被分配到一个名为 "main" 的线程组。
public class TestThreadGroup1 {public static void main(String[] args) {Thread t1 = Thread.currentThread();System.out.println("主线程:" + t1);Thread t2 = new Thread(()-> System.out.println("尚硅谷:" + Thread.currentThread()));Thread t3 = new Thread(()-> System.out.println("atguigu:" + Thread.currentThread()));t2.start();t3.start();}
}
通过 ThreadGroup 类创建线程组,并在创建线程时指定所属的线程组。线程组的主要用途:
- 批量操作:可以对整个线程组中的所有线程进行批量操作,如中断等。
- 资源管理:可以更好地管理线程资源,例如限制线程组中的最大线程数。
- 异常处理:可以为线程组设置未捕获异常处理器,统一处理线程组中所有线程的未捕获异常。
public class TestThreadGroup2 {public static void main(String[] args) {// 获取当前线程组ThreadGroup currentGroup = Thread.currentThread().getThreadGroup();System.out.println("主线程的线程组: " + currentGroup.getName());ThreadGroup group = new ThreadGroup("Java组");Thread t1 = new Thread(group,()->{System.out.println("尚硅谷:" + Thread.currentThread());try {Thread.sleep(50000);} catch (InterruptedException e) {e.printStackTrace();}});Thread t2 = new Thread(group,()->{System.out.println("atguigu:" + Thread.currentThread());try {Thread.sleep(50000);} catch (InterruptedException e) {e.printStackTrace();}});t1.start();t2.start();// 枚举线程组中的所有线程Thread[] threads = new Thread[group.activeCount()];group.enumerate(threads);for (Thread t : threads) {System.out.println(group.getName() + "组的线程: " + t.getName());}// 中断Java线程组中的所有线程try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}group.interrupt();}
}
6、线程的优先级有什么用?
在 Java 中,线程的优先级是一个整数值,用于指示线程的相对重要性。线程调度器会根据优先级来决定哪些线程应该优先获得 CPU 时间。虽然线程优先级不能保证绝对的执行顺序,但它可以影响线程的调度行为,从而优化程序的性能和响应性。线程优先级的范围(Thread类):
- 最小优先级MIN_PRIORITY:1
- 默认优先级NORM_PRIORITY:5
- 最大优先级MAX_PRIORITY:10
7、什么是守护线程?
守护线程(Daemon Thread)是一种在后台运行的线程,它的主要作用是为其他线程提供服务。与普通线程(用户线程)不同,守护线程不会阻止 JVM 的退出。当 JVM 中所有的非守护线程都结束时,JVM 会自动退出,而不会等待守护线程的完成。
public class TestDaemonThread {public static void main(String[] args) {MyDaemon m = new MyDaemon();m.setDaemon(true);m.start();for (int i = 1; i <= 100; i++) {System.out.println("main:" + i);}}
}class MyDaemon extends Thread {public void run() {while (true) {System.out.println("我一直守护者你...");try {Thread.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}}}
}
8、线程的状态有哪几种?

9、怎么让3个线程按顺序执行?(高频plus & 高xinplus)
方式一:使用Thread类的join方法
方式二:使用 CountDownLatch
方式三:使用 CyclicBarrier
相关面试题:
编程:实现让3个线程按顺序进行
方式一:使用join方法的示例代码:
public class OrderedExecutionDemo1 {public static void main(String[] args) {Thread t1 = new Thread(() -> {System.out.println("Thread 1 is running");});Thread t2 = new Thread(() -> {try {t1.join(); // 等待t1执行完毕} catch (InterruptedException e) {e.printStackTrace();}System.out.println("Thread 2 is running");});Thread t3 = new Thread(() -> {try {t2.join(); // 等待t2执行完毕} catch (InterruptedException e) {e.printStackTrace();}System.out.println("Thread 3 is running");});t1.start();t2.start();t3.start();}
}方式二:使用CountDownLatch的示例代码:
import java.util.concurrent.CountDownLatch;public class OrderedExecutionDemo2 {public static void main(String[] args) {CountDownLatch latch1 = new CountDownLatch(1);CountDownLatch latch2 = new CountDownLatch(1);Thread t1 = new Thread(() -> {System.out.println("Thread 1 is running");latch1.countDown(); // 通知t2可以开始});Thread t2 = new Thread(() -> {try {latch1.await(); // 等待t1完成,直到latch1的计数器为0为止} catch (InterruptedException e) {e.printStackTrace();}System.out.println("Thread 2 is running");latch2.countDown(); // 通知t3可以开始});Thread t3 = new Thread(() -> {try {latch2.await(); // 等待t2完成,直到latch2的计数器为0为止} catch (InterruptedException e) {e.printStackTrace();}System.out.println("Thread 3 is running");});t1.start();t2.start();t3.start();}
}
方式三:使用 CyclicBarrier的示例代码
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;public class OrderedExecutionDemo3 {public static void main(String[] args) {CyclicBarrier barrier1 = new CyclicBarrier(2);CyclicBarrier barrier2 = new CyclicBarrier(2);Thread t1 = new Thread(() -> {System.out.println("Thread 1 is running");try {barrier1.await(); // 等待t2到达屏障} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}});Thread t2 = new Thread(() -> {try {barrier1.await(); // 等待t1到达屏障} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}System.out.println("Thread 2 is running");try {barrier2.await(); // 等待t3到达屏障} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}});Thread t3 = new Thread(() -> {try {barrier2.await(); // 等待t2到达屏障} catch (InterruptedException | BrokenBarrierException e) {e.printStackTrace();}System.out.println("Thread 3 is running");});t1.start();t2.start();t3.start();}
}
10、join方法有什么用?什么原理?
join 方法是 Thread 类中的一个重要方法,用于控制线程的执行顺序。
join 方法的原理是通过调用 wait 方法来实现的。当一个线程调用另一个线程的 join 方法时,当前线程会被阻塞,直到被调用的线程执行完毕。具体步骤如下:
调用 join 方法:当前线程调用目标线程的 join 方法。
进入等待状态:当前线程进入等待状态,释放 CPU 资源。
目标线程执行:目标线程继续执行,直到运行完毕。
唤醒当前线程:目标线程执行完毕后,当前线程被唤醒,继续执行。
相关面试题:
题目:编程实现一个线程join的例子。
public class OrderedExecutionDemo1 {public static void main(String[] args) {Thread t1 = new Thread(() -> {System.out.println("Thread 1 is running");});Thread t2 = new Thread(() -> {try {t1.join(); // 等待t1执行完毕} catch (InterruptedException e) {e.printStackTrace();}System.out.println("Thread 2 is running");});Thread t3 = new Thread(() -> {try {t2.join(); // 等待t2执行完毕} catch (InterruptedException e) {e.printStackTrace();}System.out.println("Thread 3 is running");});t1.start();t2.start();t3.start();}
}
11、sleep、wait、yield方法有什么区别?(高频plus & 高xinplus)
-
sleep是Thread类的静态方法,用于让当前线程休眠,进入阻塞状态,让出CPU给其他线程。但是如果当前线程占用同步锁的话,休眠期间不释放同步锁,这会使得其他线程即使抢到CPU也会因为抢不到锁而阻塞。
-
wait是Object类的非静态方法,必须由同步锁对象调用,用于让当前线程等待,进入阻塞状态,让出CPU给其他线程。并且如果当前线程占用同步锁的话,同时还会释放同步锁给其他线程。
-
yield是Thread类的静态方法,用于让当前暂停执行,进入就绪状态,让出CPU之后,与其他线程同时抢夺CPU执行权,所以下次执行权有可能依然被当前线程抢到。
12、怎么理解Java中的线程中断?
Java 中的线程中断是一种协作机制,用于请求线程停止其所执行的任务。线程中断并不强制终止线程,而是通过设置线程的中断标志来通知线程应该停止当前的操作。线程可以选择如何响应这个中断请求,通常是在合适的时机优雅地终止任务。需要注意:以下阻塞方法(如 Thread.sleep()、Object.wait()、BlockingQueue.take() 等)会在检测到中断标志时抛出 InterruptedException 异常。
编程:实现让一个线程中断的例子
public class InterruptExample {public static void main(String[] args) throws InterruptedException {Thread worker = new Thread(() -> {while (!Thread.currentThread().isInterrupted()) {// 模拟耗时操作try {Thread.sleep(1000);System.out.println("Worker thread is running");} catch (InterruptedException e) {System.out.println("Worker thread is interrupted");break;}}System.out.println("Worker thread is exiting");});worker.start();// 主线程等待一段时间后中断工作线程Thread.sleep(5000);worker.interrupt();}
}
13、线程interrupt和stop有什么区别?
- interrupt是用于让线程中断,这是一种协作机制,线程可以选择如何响应中断请求,通常在合适的时机优雅地终止任务。
- 优点:安全性高,不会导致资源泄漏或数据不一致,因为线程可以在中断时进行必要的清理工作。
- 缺点:需要线程主动检查中断标志并作出响应,不能强制终止线程。
- 以下阻塞方法(如 Thread.sleep()、Object.wait()、BlockingQueue.take() 等)会在检测到中断标志时抛出 InterruptedException 异常。
- stop是用于强制终止线程。已经被标记为废弃(deprecated)。
- 优点:立即终止线程,无需等待线程完成当前任务。
- 缺点:安全性低,可能导致资源泄漏、数据不一致等问题,因为线程在被终止时可能没有机会进行必要的清理工作。
public class InterruptExample1 {public static void main(String[] args) throws InterruptedException {Thread worker = new Thread(() -> {while (true) {System.out.println("Worker thread is running");}});worker.start();// 主线程等待一段时间后中断工作线程Thread.sleep(1);worker.interrupt();}
}public class InterruptExample2 {public static void main(String[] args) throws InterruptedException {Thread worker = new Thread(() -> {while (true) {if(!Thread.currentThread().isInterrupted()) {System.out.println("Worker thread is running");}else{System.out.println("Worker clear...");break;}}System.out.println("Worker thread is exiting");});worker.start();// 主线程等待一段时间后中断工作线程Thread.sleep(1);worker.interrupt();}
}public class StopExample {public static void main(String[] args) throws InterruptedException {Thread worker = new Thread(() -> {while (true) {System.out.println("Worker thread is running");}});worker.start();// 主线程等待一段时间后停止工作线程Thread.sleep(1);worker.stop(); // 不推荐使用}
}14、如何优雅的终止一个线程?(高频plus)
- 通常情况下使用线程中断机制。此时线程需要定期检查中断标志,并根据需要采取相应的行动。
- 除了使用中断标志外,还可以使用一个标志变量来控制线程的生命周期。这种方法在某些情况下更加灵活。
public class SafeStopExample {private static volatile boolean isRunning = true;public static void main(String[] args) throws InterruptedException {Thread worker = new Thread(){@Overridepublic void run() {while (isRunning) {try {// 模拟耗时操作Thread.sleep(1000);System.out.println("Worker thread is running");} catch (InterruptedException e) {System.out.println("Worker thread is interrupted");break;}}// 进行必要的清理工作System.out.println("Cleaning up resources...");//结束线程System.out.println("Worker thread is exiting");}};worker.start();// 主线程等待一段时间后请求终止工作线程Thread.sleep(5000);isRunning = false;}
}15、如何判断代码是不是有线程安全问题?如何解决?
- 是不是有多个线程
- 多个线程是不是有共享数据
- 对共享数据是不是有读有写操作
满足上述3个条件,就会有线程安全问题。
有线程安全问题时,给操作共享数据的代码加锁,基础阶段就是加同步锁,高级JUC部分还可以加其他Lock锁。
16、synchronized同步锁有哪几种用法?(高频plus)
synchronized同步锁有2种用法:
-
同步方法:这是最简单的用法,通过在方法声明中使用 synchronized 关键字,可以确保同一时间只有一个线程可以执行该方法。静态同步方法的同步锁对象是当前类的Class对象,非静态同步方法的同步锁对象是this。
-
其他修饰符 synchronized 返回值类型 方法名(形参列表){..... }
-
-
同步代码块:它提供了更细粒度的控制,只对特定的代码块进行同步,而不是整个方法。这可以减少锁的竞争,提高程序的性能。
-
修饰符 返回值类型 方法名(形参列表){....synchronized(同步锁对象){.....}.... }
-
相关面试题:
问:synchronized锁的是什么?
答:用synchronized锁的方法或代码块,可以确保同一时间只有一个线程可以执行这段代码。
17、如何选择同步锁对象?如何设定同步代码范围?
同步锁对象的选择必须保证具有竞争关系的多个线程,使用同一个同步锁对象。
同步方法的同步锁对象是固定的,静态方法的同步锁对象是当前类的Class对象,非静态方法的同步锁对象是当前对象this。
同步代码块中同步锁对象是可以由程序员手动指定的。
同步代码块不是越大越好,否则会导致性能低下,或者其他线程没有机会。也不是越小越好,否则安全问题无法彻底解决。以单次原子性任务代码为准。
错误案例:同步锁对象不是同一个
public class TicketThreadDemo1 extends Thread{private static int total = 100;//成员变量之静态变量@Overridepublic void run() {while(total>0) {saleOneTicket();}}/*方法是非静态的,那么它的默认锁对象/监视器对象 是 this,*/public synchronized void saleOneTicket(){ //有问题,锁对象不是同一个if(total>0){try {Thread.sleep(10);//加入这个休眠, 只是为了让问题暴露明显} catch (InterruptedException e) {e.printStackTrace();}total--;System.out.println(getName() + "卖出1张票,剩余" + total);}}
}
public class TestTicketThreadDemo1 {public static void main(String[] args) {TicketThreadDemo1 t1 = new TicketThreadDemo1();TicketThreadDemo1 t2 = new TicketThreadDemo1();TicketThreadDemo1 t3 = new TicketThreadDemo1();t1.start();t2.start();t3.start();}
}错误示例代码2:同步代码范围太大
public class TicketThreadDemo2 extends Thread {private static int total = 100;//成员变量之静态变量@Overridepublic void run() {saleOneTicket();}/*方法是静态的,那么它的默认锁对象/监视器对象 是 当前类的Class对象*/public synchronized static void saleOneTicket(){ //有问题,范围太大while(total>0){try {Thread.sleep(10);//加入这个休眠, 只是为了让问题暴露明显} catch (InterruptedException e) {e.printStackTrace();}total--;System.out.println(Thread.currentThread().getName() + "卖出1张票,剩余" + total);}}
}public class TestTicketThreadDemo2 {public static void main(String[] args) {TicketThreadDemo2 t1 = new TicketThreadDemo2();TicketThreadDemo2 t2 = new TicketThreadDemo2();TicketThreadDemo2 t3 = new TicketThreadDemo2();t1.start();t2.start();t3.start();}
}
正确示例代码1:
public class TicketThreadDemo4 extends Thread{private static int total = 100;//成员变量之静态变量@Overridepublic void run() {while(total>0) {saleOneTicket();}}/*方法是静态的,那么它的默认锁对象/监视器对象 是 当前类的Class对象*/public static synchronized void saleOneTicket(){//没问题if(total>0){try {Thread.sleep(10);//加入这个休眠, 只是为了让问题暴露明显} catch (InterruptedException e) {e.printStackTrace();}total--;System.out.println(Thread.currentThread().getName() + "卖出1张票,剩余" + total);}}
}public class TestTicketThreadDemo4 {public static void main(String[] args) {TicketThreadDemo4 t1 = new TicketThreadDemo4();TicketThreadDemo4 t2 = new TicketThreadDemo4();TicketThreadDemo4 t3 = new TicketThreadDemo4();t1.start();t2.start();t3.start();}
}正确示例代码2:
public class TicketThreadDemo3 implements Runnable{private int total = 1000;@Overridepublic void run() {while(total>0) {saleOneTicket();}}/*方法是非静态的,那么它的默认锁对象/监视器对象 是 this,*/public synchronized void saleOneTicket(){//问题和范围都合适if(total>0){try {Thread.sleep(10);//加入这个休眠, 只是为了让问题暴露明显} catch (InterruptedException e) {e.printStackTrace();}total--;System.out.println(Thread.currentThread().getName() + "卖出1张票,剩余" + total);}}
}public class TestTicketThreadDemo3 {public static void main(String[] args) {TicketThreadDemo3 t = new TicketThreadDemo3();Thread t1 = new Thread(t);Thread t2 = new Thread(t);Thread t3 = new Thread(t);t1.start();t2.start();t3.start();}
}正确示例代码3:
public class TicketThreadDemo5 extends Thread{private static int total = 100;private static Object object = new Object();@Overridepublic void run() {while(total>0) {
// synchronized (this) {//??
// synchronized (TicketThreadDemo5.class) {
// synchronized ("尚硅谷") {synchronized (object) {if (total > 0) {try {Thread.sleep(10);//加入这个休眠, 只是为了让问题暴露明显} catch (InterruptedException e) {e.printStackTrace();}total--;System.out.println(Thread.currentThread().getName() + "卖出1张票,剩余" + total);}}}}
}
public class TestTicketThreadDemo5 {public static void main(String[] args) {TicketThreadDemo5 t1 = new TicketThreadDemo5();TicketThreadDemo5 t2 = new TicketThreadDemo5();TicketThreadDemo5 t3 = new TicketThreadDemo5();t1.start();t2.start();t3.start();}
}18、synchronized关键字的底层实现原理是什么?(高频plus & 高xinplus)
synchronized 关键字的实现基于监视器锁(Monitor)。监视器锁是一个互斥锁,确保同一时间只有一个线程可以持有锁并执行同步代码块或方法。每个 Java 对象都有一个对象头,其中包含对象的元数据信息,包括锁信息。对象头中的锁状态可以是无锁状态、偏向锁、轻量级锁和重量级锁。在 Java 中,synchronized 关键字的锁状态会根据竞争情况动态转换,主要包括以下几种状态:
- 无锁状态:没有线程竞争锁。
- 偏向锁:当一个线程访问同步块时,JVM 会将锁偏向该线程,减少锁的开销。
- 轻量级锁:当多个线程竞争锁时,JVM 会尝试使用自旋锁,避免线程上下文切换的开销。
- 重量级锁:当自旋锁失败时,JVM 会将锁升级为重量级锁,使用操作系统提供的互斥锁。
19、怎么理解wait,notify,notifyAll方法?(高频plus)
wait、notify 和 notifyAll 是 Java 中用于线程间通信的重要方法,它们都定义在 Object 类中。这些方法主要用于协调多个线程对共享资源的访问,确保线程之间的正确同步,主要用于解决生产者与消费者问题,它们的搭配使用我们也称为等待与唤醒机制。
-
wait 方法使当前线程进入
等待状态,并释放当前持有的锁。当其他线程调用 notify 或 notifyAll 方法时,等待的线程会被唤醒,重新竞争锁。 -
notify 方法
唤醒一个正在等待当前对象锁的线程。如果有多个线程在等待,JVM 会选择其中一个线程唤醒。 -
notifyAll 方法
唤醒所有正在等待当前对象锁的线程。被唤醒的线程会重新竞争锁,最终只有一个线程能够获得锁并继续执行。
所谓生产者与消费者问题,就是
- 一个或一些线程负责往共享的数据缓冲区填充数据,我们称为生产者线程,当缓冲区满的时候,生产者线程等待,
- 另一个或一些线程负责从共享的数据缓冲区消耗数据,我们称为消费者线程,当缓冲区空的时候,消费者线程等待。
生产者与消费者线程对共享缓冲区的操作,有线程安全问题,所以必须加锁(例如:同步锁),然后由同步锁对象来调用wait和notify/notifyAll方法来协调这些线程的执行。
相关面试题:
问:wait、notify、notifyAll它们是Thread类中的方法吗?
答:不是,它们都定义在 Object 类中。
问:使用wait,notify,notifyAll有什么要注意的吗?
答:它们必须在同步方法或同步代码块中使用,而且必须由同步锁对象调用。
问:编程:实现让一个线程wait的例子
案例1:一个生产者与一个消费者线程
public class TestCommunicate {public static void main(String[] args) {// 1、创建资源类对象Workbench workbench = new Workbench();// 2、创建和启动厨师线程new Thread("厨师") {public void run() {while (true) {workbench.make();}}}.start();// 3、创建和启动服务员线程new Thread("服务员") {public void run() {while (true) {workbench.eat();}}}.start();}}// 1、定义资源类
class Workbench {private static final int MAX_VALUE = 10;private int total;public synchronized void make() {if (total >= MAX_VALUE) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}total++;System.out.println(Thread.currentThread().getName() + "制作了一份快餐,现在工作台上有:" + total + "份快餐");this.notify();}public synchronized void eat() {if (total <= 0) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}total--;System.out.println(Thread.currentThread().getName() + "取走了一份快餐,现在工作台上有:" + total + "份快餐");this.notify();}
}
案例2:多个生产者与多个消费者线程
public class TestCommunicate2 {public static void main(String[] args) {// 1、创建资源类对象Workbench workbench = new Workbench();class Cook implements Runnable {public void run() {while (true) {workbench.make();}}}class Waiter implements Runnable{public void run() {while (true) {workbench.eat();}}}// 2、创建和启动厨师线程Cook cook = new Cook();Thread t1 = new Thread( cook,"厨师1号");Thread t2 = new Thread( cook,"厨师2号");t1.start();t2.start();// 3、创建和启动服务员线程Waiter waiter = new Waiter();Thread t3 = new Thread( waiter,"服务员1号");Thread t4 = new Thread( waiter,"服务员3号");t3.start();t4.start();}}// 1、定义资源类
class Workbench {private static final int MAX_VALUE = 1;private int total;public synchronized void make() {while (total >= MAX_VALUE) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}total++;System.out.println(Thread.currentThread().getName() + "制作了一份快餐,现在工作台上有:" + total + "份快餐");this.notifyAll();}public synchronized void eat() {while (total <= 0) {try {this.wait();} catch (InterruptedException e) {e.printStackTrace();}}total--;System.out.println(Thread.currentThread().getName() + "取走了一份快餐,现在工作台上有:" + total + "份快餐");this.notifyAll();}
}
4.9 网络编程(1题)
1、IP地址和端口号的作用什么?
每个连接到互联网的设备都需要一个唯一的IP地址,以便在网络中被识别和定位。
每个端口号在一台主机上是唯一的,用于区分不同的服务或应用程序。
端口号与IP地址结合使用,共同确定网络通信的目标。
2、TCP/IP参考模型
TCP/IP参考模型(Transmission Control Protocol/Internet Protocol Model)是互联网的核心协议模型,它通过四层结构确保数据在网络中的可靠传输。每一层都有明确的职责,从应用层的用户接口到链路层的物理传输,各层协同工作,实现了复杂而高效的网络通信。
以下是TCP/IP参考模型的详细说明:
- 应用层(Application Layer)提供应用程序间的接口,将数据格式化为应用程序可以处理的形式。代表协议有:HTTP、HTTPS、FTP、SMTP、DNS、Telnet、SSH等。
- 传输层(Transport Layer)负责端到端的通信。代表协议有:TCP(传输控制协议)、UDP(用户数据报协议)。
- 网络层(Internet Layer)负责数据包的路由选择,将数据包从一个网络节点转发到另一个网络节点,确保数据包能够从源主机到达目的主机。代表协议有:IP(互联网协议)、ICMP(互联网控制消息协议)、ARP(地址解析协议)、RARP(逆向地址解析协议)。
- 网络接口层(Link Layer)负责将网际层的数据包封装成数据帧,并在同一网络内的主机之间传输数据帧。代表协议有:以太网、Wi-Fi、PPP(点对点协议)。
3、TCP和UDP协议有什么区别?(高频plus)
TCP(传输控制协议,Transmission Control Protocol)和 UDP(用户数据报协议User Datagram Protocol)是两种常用的传输层协议,它们在功能和特性上有显著的区别。以下是TCP和UDP的主要区别:
- 连接方式
TCP:面向连接的协议。在数据传输之前,需要先建立连接(三次握手),数据传输完成后需要断开连接(四次挥手)。
UDP:无连接的协议。数据传输前不需要建立连接,直接发送数据报文。 - 可靠性
TCP:提供可靠的数据传输服务。通过确认应答、重传机制、拥塞控制等手段确保数据的完整性和顺序性。
UDP:不保证数据的可靠传输。数据报文可能丢失、重复或乱序,但不会进行重传或排序。 - 数据传输方式
TCP:基于字节流的传输方式。数据被分割成多个段(segments),每个段都有序列号,接收端根据序列号重新组装数据。
UDP:基于数据报的传输方式。数据被封装成一个个独立的数据报文(datagrams),每个数据报文独立传输,没有顺序保证。 - 速度和效率
TCP:由于可靠性高,需要进行多次握手、确认应答等操作,因此传输速度相对较慢。
UDP:由于没有连接建立和确认应答等操作,传输速度快,效率高。 - 流量控制和拥塞控制
TCP:提供流量控制和拥塞控制机制。通过滑动窗口机制调节发送速率,避免网络拥塞。
UDP:不提供流量控制和拥塞控制机制。发送方可以以最大速率发送数据,可能导致网络拥塞。 - 报头大小
TCP:报头较大,标准TCP报头至少20字节。
UDP:报头较小,标准UDP报头只有8字节。 - 适用场景
TCP:适用于需要可靠传输的场景,如文件传输、电子邮件、网页浏览等。
UDP:适用于对实时性要求高、对数据丢失容忍度高的场景,如视频直播、语音通话、在线游戏等。

4.10 反射(2题)
1、什么是Java的反射机制?
Java的反射(Reflection)机制提供了强大的灵活性,使得程序可以在运行时动态地获取类的信息,并且可以操作类的内部成员,如字段、构造器、成员方法等。通过反射,可以在运行时创建对象、调用方法、访问和修改字段值等。
反射适用于框架开发、插件系统、动态代理等场景,但在普通业务逻辑中应谨慎使用。
2、Java反射机制如何获取Class类的对象,以及Class类有哪些常用方法?
获取Class对象的四种方式:
- 类型名.class
- Java对象.getClass()
- Class.forName("类型全名称")
- ClassLoader类加载对象.loadClass("类型全名称")
Java反射机制中,Class 类提供了许多方法,这些方法使得在运行时动态地获取和操作类的信息成为可能,增强了程序的灵活性和可扩展性。以下是一些常用的 Class 类方法:
(1)获取类信息
- getName():返回类的全限定名。
- getSimpleName():返回类的简单名称。
- getPackage():返回类的包信息。
- isInterface():判断该类是否是一个接口。
- isEnum():判断该类是否是一个枚举。
- isAnnotation():判断该类是否是一个注解。
(2)获取构造器
- getConstructor(Class<?>... parameterTypes):返回一个带有指定参数类型的公共构造器。
- getConstructors():返回所有公共构造器。
- getDeclaredConstructor(Class<?>... parameterTypes):返回一个带有指定参数类型的构造器(包括私有的)。
- getDeclaredConstructors():返回所有构造器(包括私有的)。
(3)获取方法
- getMethod(String name, Class<?>... parameterTypes):返回一个带有指定名称和参数类型的公共方法。
- getMethods():返回所有公共方法(包括继承的方法)。
- getDeclaredMethod(String name, Class<?>... parameterTypes):返回一个带有指定名称和参数类型的方法(包括私有的)。
- getDeclaredMethods():返回所有方法(包括私有的)。
(4)获取字段
- getField(String name):返回一个带有指定名称的公共字段。
- getFields():返回所有公共字段(包括继承的字段)。
- getDeclaredField(String name):返回一个带有指定名称的字段(包括私有的)。
- getDeclaredFields():返回所有字段(包括私有的)。
(5)创建实例
- newInstance():创建一个该类的新实例(已弃用,推荐使用 Constructor 的 newInstance 方法)。
- Constructor
.newInstance(Object... initargs):使用指定的构造器创建一个新实例。
(6)获取父类和接口
- getSuperclass():返回该类的父类。
- getInterfaces():返回该类实现的所有接口。
(7)获取注解
-
getAnnotation(Class
annotationClass):返回该类上的指定注解。 -
getAnnotations():返回该类上的所有注解。
-
getDeclaredAnnotation(Class
annotationClass):返回该类上的指定注解(包括私有的)。 -
getDeclaredAnnotations():返回该类上的所有注解(包括私有的)。
3、Java反射可以访问父类的私有方法吗?(高频plus)
Java反射机制可以用来访问父类的私有方法,但需要进行一些额外的操作来绕过Java的访问控制限制。具体步骤如下:
- 获取父类的 Class 对象。
- 使用 getDeclaredMethod 方法获取私有方法。
- 调用 setAccessible(true) 方法使私有方法可访问。
- 使用 invoke 方法调用私有方法。
相关面试题:
问:Java反射可以访问私有方法吗?
答:可以,使用 getDeclaredMethod 方法获取私有方法。
问:Java反射可以访问私有变量吗?
答:可以,使用 getDeclaredField 方法获取私有变量。
问:Java反射可以访问父类的成员吗?
答:可以,关于父类的公共的成员,通过子类Class对象通过调用getMethod、getField方法即可获取,如果是父类的私有成员,必须先获取父类的Class对象,然后通过getDeclaredMethod、getDeclaredField方法才能获取。
4、Java反射有没有性能影响?(高频plus)
Java反射确实会对性能产生影响,主要体现在以下几个方面:
- 初始化开销
类加载:使用反射时,如果类还没有被加载到JVM中,反射会触发类的加载过程。类加载本身是一个相对耗时的操作,因为它涉及到类文件的读取、解析和验证。
对象创建:通过反射创建对象时,需要查找和解析类的构造器,这比直接使用 new 关键字创建对象要慢。 - 方法调用开销
动态绑定:反射调用方法时,需要在运行时动态查找和绑定方法,这比编译时静态绑定的方法调用要慢得多。每次调用反射方法时,都需要进行方法查找和权限检查。
缓存机制:虽然现代JVM对反射方法调用进行了优化,例如缓存方法查找结果,但仍然无法完全消除性能差距。 - 安全检查
访问控制:使用 setAccessible(true) 来访问私有成员时,JVM需要进行额外的安全检查,以确保这种操作是允许的。这些安全检查会增加额外的开销。 - 字符串操作
方法和字段名称:反射通常需要使用字符串来指定方法和字段的名称,这会导致额外的字符串处理和比较操作。 - 内存开销
元数据:反射操作需要维护大量的元数据信息,这些信息会占用额外的内存。
相关面试题:
问:Java反射到底慢在哪里?
5、Java为什么要引入模块化?
Java模块化是指在Java 9及更高版本中引入的一种新的组织和管理代码的方式,旨在解决传统Java应用中的类路径问题和依赖管理问题。模块化的好处:
- 更好的封装:模块化系统提供了强封装机制,只有显式导出的包才能被其他模块访问,提高了代码的安全性和可维护性。
- 清晰的依赖管理:模块描述符(module-info.java)明确声明了模块的依赖关系,避免了类路径污染和依赖冲突问题。
- 更好的性能:模块化系统可以优化类加载过程,减少不必要的类加载,提高应用的启动速度和运行效率。
- 更好的可维护性:模块化系统鼓励将代码组织成独立的模块,每个模块负责一个特定的功能,提高了代码的可维护性和可测试性。
相关面试题:
问:你怎么理解Java模块化?
4.11 设计模式(4题)
1、简要说明一下你了解哪些设计模式?
JavaSE的核心类库中就用到好几个设计模式:
- 单例设计模式 (Singleton):Runtime类
- 工厂方法模式 (Factory Method):Calendar.getInstance()方法,返回Calendar子类对象
- 抽象工厂模式 (Abstract Factory):通过 Connection 对象创建 Statement 对象。
- 建造者模式 (Builder):StringBuilder 和StringBuffer用于构建字符串。
- 原型模式 (Prototype):Object提供了clone()克隆对象的方法。
- 适配器模式 (Adapter):InputStreamReader 和OutputStreamWriter将字节流转换为字符流,Arrays.asList()将数组转换为列表。
- 桥接模式 (Bridge):Reader 和 Writer将字符流与底层字节流分离。List 和 ArrayList将列表接口与具体实现分离。
- 装饰模式 (Decorator):BufferedInputStream 和 BufferedOutputStream为输入输出流增加缓冲功能。
- 享元模式 (Flyweight):Integer.valueOf(int i)缓存常用的小整数对象。String.intern():缓存常用的字符串对象。
- 代理模式 (Proxy):Proxy动态生成代理类
- 策略模式 (Strategy):Comparator定义了比较策略,List.sort(Comparator c)根据比较器排序列表。
- 命令模式 (Command):Executor 和 Callable封装了线程任务执行的命令。
- 迭代器模式 (Iterator):集合的迭代器
- 模板方法模式 (Template Method):AbstractList、AbstractSet 和AbstractMap提供了集合类的基本实现。InputStream 和OutputStream提供了输入输出流的基本实现。
拓展:23种经典的设计模式简要信息
设计模式是在软件设计中常见问题的解决方案模板,以下是23种经典的设计模式简要信息:

(1)创建型模式(5种):
- 单例模式 (Singleton):确保一个类只有一个实例,并提供一个全局访问点。
- 工厂方法模式 (Factory Method):定义一个用于创建对象的接口,让子类决定实例化哪一个类。
- 抽象工厂模式 (Abstract Factory):提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
- 建造者模式 (Builder):将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
- 原型模式 (Prototype):用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象。
(2)结构型模式(7种):
- 适配器模式 (Adapter):将一个类的接口转换成客户希望的另一个接口。
- 桥接模式 (Bridge):将抽象部分与实现部分分离,使它们都可以独立变化。
- 组合模式 (Composite):将对象组合成树形结构以表示“部分-整体”的层次结构。
- 装饰模式 (Decorator):动态地给一个对象添加一些额外的职责。
- 外观模式 (Facade):为子系统中的一组接口提供一个一致的界面。
- 享元模式 (Flyweight):运用共享技术有效地支持大量细粒度的对象。
- 代理模式 (Proxy):为其他对象提供一种代理以控制对这个对象的访问。
(3)行为型模式(11种):
- 策略模式 (Strategy):定义一系列算法,把它们一个个封装起来,并且使它们可互相替换。
- 观察者模式 (Observer):定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
- 命令模式 (Command):将请求封装成对象,从而使你可用不同的请求对客户进行参数化。
- 责任链模式 (Chain of Responsibility):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。
- 状态模式 (State):允许一个对象在其内部状态改变时改变它的行为。
- 访问者模式 (Visitor):表示一个作用于某对象结构中的各元素的操作。
- 中介者模式 (Mediator):用一个中介对象来封装一系列的对象交互。
- 迭代器模式 (Iterator):提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。
- 备忘录模式 (Memento):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
- 解释器模式 (Interpreter):给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
- 模板方法模式 (Template Method):定义一个操作中的算法骨架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
这些设计模式可以帮助解决软件开发过程中遇到的常见问题,提高代码的复用性和可维护性。
2、编程:设计并实现一个单例类(高频plus & 高xinplus)
饿汉式:在类初始化时就创建对象,无论你现在是不是需要这个对象。
懒汉式:在你调用可以获取这个类的对象的方法时,才创建这个对象,即延迟创建对象。
案例1:饿汉式(静态常量)
public class Singleton {public static final Singleton INSTANCE = new Singleton();private Singleton() {}
}
案例2:饿汉式(静态方法)
public class Singleton {private static final Singleton INSTANCE = new Singleton();private Singleton() {}public static Singleton getInstance() {return INSTANCE;}
}
案例3:饿汉式(枚举式)
public enum Singleton{INSTANCE
}
案例4:懒汉式(同步方法)
public class Singleton {private static Singleton instance;private Singleton(){}public static synchronized Singleton getInstance(){if(instance == null){instance = new Singleton();}return instance;}
}
案例5:懒汉式(同步代码块+双重条件)
public class Singleton {private static Singleton instance;private Singleton(){}public static Singleton getInstance(){if(instance == null){synchronized(Singleton.class){if(instance == null){instance = new Singleton();}}}return instance;}
}
案例6:懒汉式(静态内部类)
public class Singleton {private Singleton(){}private static class Inner{static final Singleton INSTANCE = new Singleton();}public static Singleton getInstance(){return Inner.INSTANCE;}
}
3、请简述一下工厂设计模式?(高频plus)
工厂设计模式是一种创建型设计模式。工厂设计模式优点有很多,例如:
- 封装对象创建过程:工厂模式将对象的创建过程封装在工厂类中,而不是直接在客户端代码中进行实例化。这样可以隐藏具体的实现细节,降低客户端代码与具体产品类的耦合度。
- 提高代码的可扩展性:当需要添加新的产品类型时,只需增加相应的具体产品类和对应的工厂方法或工厂类,而不需要修改现有的客户端代码。这符合开闭原则(Open/Closed Principle),即对扩展开放,对修改关闭。
- 集中管理对象的创建逻辑:将对象的创建逻辑集中在工厂类中,便于管理和维护。如果创建逻辑比较复杂,例如需要依赖注入、配置文件读取等,工厂模式可以使这些逻辑更易于组织和管理。
- 简化客户端代码:客户端代码只需要调用工厂方法来获取对象,而不必关心具体的创建过程。这使得客户端代码更加简洁和易于理解。
- 支持多态:通过工厂方法或简单工厂返回的产品对象是抽象产品的接口或基类,可以在运行时动态决定具体的产品类型,从而利用多态特性,增强代码的灵活性。
例如:
JavaSE的核心类库中的:
- Calendar类的静态工厂方法创建日历对象:Calendar.getInstance();
- DateTimeFormatter 类使用了静态工厂方法来创建日期时间格式化对象:DateTimeFormatter.ofPattern("yyyy-MM-dd");
- DriverManager 类使用了工厂方法来创建数据库连接:DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "user", "password");
- Executors 类的静态工厂方法:创建不同类型的线程池
- Executors.newFixedThreadPool(10);
- Executors.newScheduledThreadPool(5);
Spring 框架通过多种方式实现了工厂模式,包括 BeanFactory、ApplicationContext、FactoryBean等。
(1)简单工厂模式
public abstract class Vehicle {//产品的抽象父类public abstract void drive();
}
public class Bike extends Vehicle{//具体产品子类@Overridepublic void drive() {System.out.println("骑自行车锻炼身体");}
}
public class Electromobile extends Vehicle{//具体产品子类@Overridepublic void drive() {System.out.println("骑电动车送外卖!");}
}public class Car extends Vehicle{//具体产品子类@Overridepublic void drive() {System.out.println("开车去加班!");}
}
public class VehicleFactory {//简单工厂类public static Vehicle getVehicle(String type){switch (type){case "Bike": return new Bike();case "Electromobile": return new Electromobile();case "Car": return new Car();}return null;}
}
public class TestVehicle {public static void main(String[] args) {Vehicle v1 = VehicleFactory.getVehicle("Bike");v1.drive();Vehicle v2 = VehicleFactory.getVehicle("Electromobile");v2.drive();Vehicle v3 = VehicleFactory.getVehicle("Car");v3.drive();}}(2)工厂方法模式
抽象产品父类Vehicle及其子类Bike、Electromobile、Car与上面一致。
public interface VehicleFactory {//工厂类接口Vehicle getVehicle();
}public class BikeFactory implements VehicleFactory{//具体的产品子类的工厂类@Overridepublic Bike getVehicle() {return new Bike();}
}
public class CarFactory implements VehicleFactory{//具体的产品子类的工厂类@Overridepublic Car getVehicle() {return new Car();}
}public class TestVehicle {public static void main(String[] args) {BikeFactory bf = new BikeFactory();Bike bike = bf.getVehicle();bike.drive();System.out.println("=====================");CarFactory cf = new CarFactory();Car car = cf.getVehicle();car.drive();}}4、请简述一下代理模式?(高频plus & 高xinplus)
代理模式(Proxy Pattern)是一种结构型设计模式。代理模式通过引入一个代理对象来间接访问目标对象,从而在不改变目标对象的前提下,增加了额外的功能或控制目标对象的访问。
适用场景:
- 访问控制:如保护代理,用于控制对象的访问权限。
- 日志记录:在调用方法前后记录日志。
- 事务管理:在调用方法前后管理事务。
- 远程代理:用于远程对象的访问,如 RMI。
框架中也都有代理模式的应用,例如Spring框架的AOP(面向切面编程)等。
代理模式主要有以下几种类型:
(1)静态代理
静态代理是指在编译时就已经确定了代理类和被代理类的关系。
缺点是:每一个代理工作,每一个主题接口都需要单独代理类。代理类与被代理类需要实现共同的主题接口。
优点是:直观
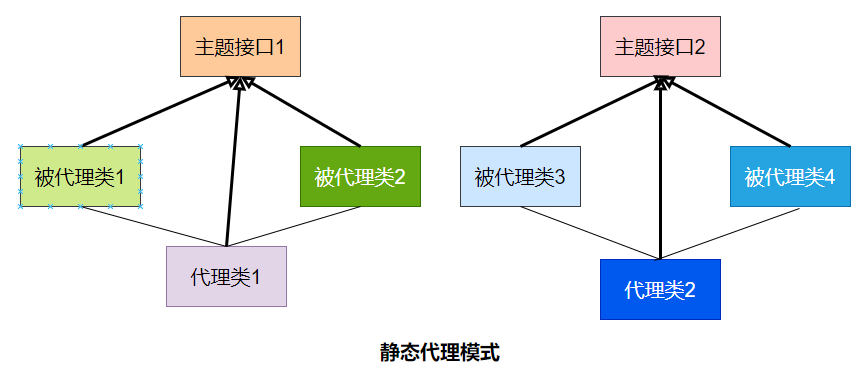
public interface AdminServiceOne {//主题接口1void adminOperationOne();
}
public interface AdminServiceTwo {//主题接口2void adminOperationTwo();
}
public class RealAdminServiceOne implements AdminServiceOne {//被代理类1@Overridepublic void adminOperationOne() {System.out.println("执行具体业务操作1");}
}
public class RealAdminServiceTwo implements AdminServiceTwo {//被代理类2@Overridepublic void adminOperationTwo() {System.out.println("执行具体业务操作2");}
}
import java.util.Random;public class Session {//模拟当前系统登录的人员列表private static String[] roles = {"admin","user"};public static String getUser(){return roles[new Random().nextInt(0,2)];}
}public class AdminServiceProxyOne implements AdminServiceOne {//代理类1private final AdminServiceOne target;public AdminServiceProxyOne(AdminServiceOne realAdminServiceOne) {this.target = realAdminServiceOne;}@Overridepublic void adminOperationOne() {// 前置处理System.out.println("前置处理操作(例如:事务开启)");//权限校验,执行被代理类的方法String user = Session.getUser();if ("admin".equals(user)) {System.out.println(user + "请求的操作被允许");target.adminOperationOne();} else {System.out.println(user + "请求的操作被拒绝");}// 后置处理System.out.println("后置处理操作(例如:事务提交等)");}
}
public class AdminServiceProxyTwo implements AdminServiceTwo {//代理类2private final AdminServiceTwo target;public AdminServiceProxyTwo(AdminServiceTwo realAdminServiceTwo) {this.target = realAdminServiceTwo;}@Overridepublic void adminOperationTwo() {// 前置处理System.out.println("前置处理操作(例如:事务开启)");//权限校验,执行被代理类的方法String user = Session.getUser();if ("admin".equals(user)) {System.out.println(user + "请求的操作被允许");target.adminOperationTwo();} else {System.out.println(user + "请求的操作被拒绝");}// 后置处理System.out.println("后置处理操作(例如:事务提交等)");}
}
public class StaticProxyDemo {public static void main(String[] args) {RealAdminServiceOne one = new RealAdminServiceOne();//被代理类对象AdminServiceOne proxyOne = new AdminServiceProxyOne(one);//代理类对象proxyOne.adminOperationOne();System.out.println("========================");RealAdminServiceTwo two = new RealAdminServiceTwo();//被代理类对象AdminServiceTwo proxyTwo = new AdminServiceProxyTwo(two);//代理类对象proxyTwo.adminOperationTwo();}
}(2)动态代理
动态代理是指在运行时才确定了代理类和被代理类的关系,而且代理类往往是通过调用Proxy.getProxyClass或Proxy.newProxyInstance方法根据InvocationHandler接口实现类的invoke方法的模板代码动态生成的,不用单独定义.java文件。
缺点是:不够直观
优点是:只要代理工作一样,多个主题接口只需要定义一个InvocationHandler接口的实现类。
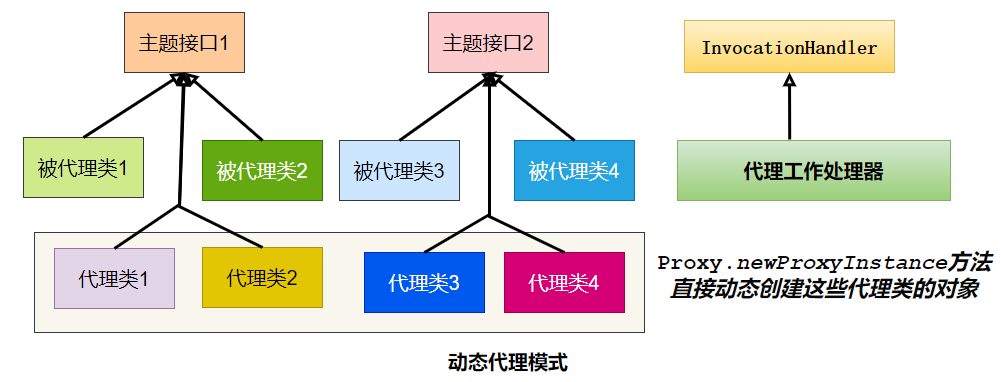
主题与被代理类与上面相同,代理类代码如下:
public class DynamicProxyTemplate implements InvocationHandler {private Object target;public DynamicProxyTemplate(Object target) {this.target = target;}@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 前置处理System.out.println("前置处理操作(例如:事务开启)");Object result = null;String user = Session.getUser();if ("admin".equals(user)) {System.out.println(user + "请求的操作被允许");// 调用被代理类的方法result = method.invoke(target, args);} else {System.out.println(user + "请求的操作被拒绝");}// 后置处理System.out.println("后置处理操作(例如:事务提交等)");return result;}public static <T> T createProxy(T target) {return (T) Proxy.newProxyInstance(target.getClass().getClassLoader(),target.getClass().getInterfaces(),new DynamicProxyTemplate(target));}
}public class DynamicProxyDemo {public static void main(String[] args) {RealAdminServiceOne one = new RealAdminServiceOne();//被代理类对象AdminServiceOne proxyOne = DynamicProxyTemplate.createProxy(one);//代理类对象proxyOne.adminOperationOne();System.out.println("========================");RealAdminServiceTwo two = new RealAdminServiceTwo();//被代理类对象AdminServiceTwo proxyTwo = DynamicProxyTemplate.createProxy(two);//代理类对象proxyTwo.adminOperationTwo();}
}5、请简述一下装饰者设计模式?
装饰者设计模式(Decorator Pattern)是一种结构型设计模式,它允许你通过将对象放入包含行为的特殊封装对象中来为原对象绑定新的行为。

装饰者模式(Decorator Pattern)和代理模式(Proxy Pattern)都是结构型设计模式,但它们的用途和实现方式有所不同。
- 装饰者模式:
- 意图:动态地给一个对象添加一些额外的职责。就增加功能来说,装饰者模式相比生成子类更为灵活。
- 应用场景:当你需要在运行时为对象动态添加功能或行为时使用。例如,给奶茶添加不同的调料(如珍珠、椰果等),每次添加调料都相当于给奶茶对象增加了新的特性。
- 代理模式:
- 意图:代理对象为目标对象提供一种代理,以控制对这个目标对象的访问方式。
- 应用场景:当你需要控制对某个对象的访问或者需要在访问前后执行某些操作时使用。例如,权限检查、事务管理、日志记录、远程服务调用等。
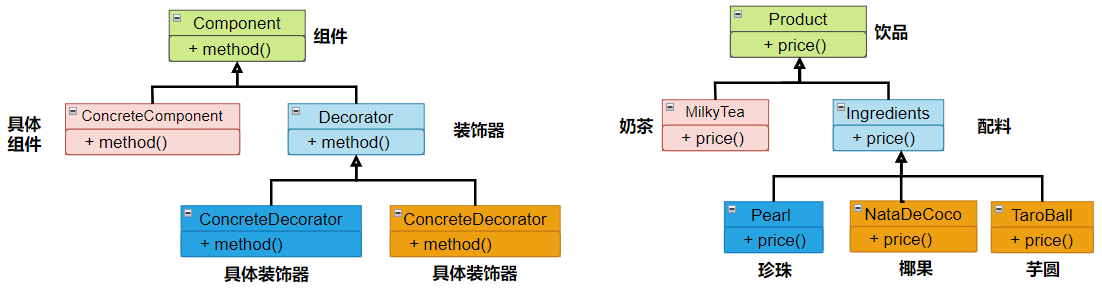
public abstract class Product {// 抽象产品类public abstract double totalPrice();public abstract String showMaterials();
}
public class MilkyTea extends Product{//奶茶@Overridepublic double totalPrice() {return 8;}@Overridepublic String showMaterials() {return "牛奶,红茶";}
}
public abstract class Ingredients extends Product{//小料,配料protected Product product;public Ingredients(Product product) {this.product = product;}@Overridepublic double totalPrice() {return product.totalPrice();}@Overridepublic String showMaterials() {return product.showMaterials();}
}
public class Pearl extends Ingredients{//珍珠配料public Pearl(Product product) {super(product);}@Overridepublic double totalPrice() {return super.totalPrice() + 2;}@Overridepublic String showMaterials() {return super.showMaterials() + ",黑珍珠";}
}
public class NataDeCoco extends Ingredients{//椰果配料public NataDeCoco(Product product) {super(product);}public double totalPrice() {return super.totalPrice() + 3;}@Overridepublic String showMaterials() {return super.showMaterials() + ",椰果";}
}
public class TaroBall extends Ingredients{//芋圆配料public TaroBall(Product product) {super(product);}@Overridepublic double totalPrice() {return super.totalPrice() + 1;}@Overridepublic String showMaterials() {return super.showMaterials()+",芋圆";}
}
public class TestProducts {public static void main(String[] args) {//测试类Product milkyTea = new MilkyTea();System.out.println("普通奶茶价格:" + milkyTea.totalPrice());System.out.println("普通奶茶材料:" + milkyTea.showMaterials());System.out.println("==================");Product pearl = new Pearl(new MilkyTea());System.out.println("珍珠奶茶价格:" + pearl.totalPrice());System.out.println("珍珠奶茶材料:" + pearl.showMaterials());System.out.println("==================");Product nataDeCoco = new NataDeCoco(new MilkyTea());System.out.println("椰果奶茶价格:" + nataDeCoco.totalPrice());System.out.println("椰果奶茶材料:" + nataDeCoco.showMaterials());System.out.println("===============");Product nataDeCocoPearl = new NataDeCoco(new Pearl(new MilkyTea()));System.out.println("椰果珍珠奶茶价格:" + nataDeCocoPearl.totalPrice());System.out.println("椰果珍珠奶茶材料:" + nataDeCocoPearl.showMaterials());System.out.println("===============");Product nataDeCoco2Pearl = new NataDeCoco(new Pearl(new NataDeCoco(new MilkyTea())));System.out.println("椰果双倍珍珠奶茶价格:" + nataDeCoco2Pearl.totalPrice());System.out.println("椰果双倍珍珠奶茶材料:" + nataDeCoco2Pearl.showMaterials());System.out.println("===============");Product all = new NataDeCoco(new Pearl(new TaroBall(new MilkyTea())));System.out.println("椰果珍珠芋圆奶茶价格:" + all.totalPrice());System.out.println("椰果珍珠芋圆奶茶材料:" + all.showMaterials());}
}
6、模板方法设计模式(高频plus)
模板方法设计模式是一种行为设计模式。模板方法设计模式在模板父类的模板方法中定义了一个操作的算法骨架,而将一些步骤延迟到子类中实现。这样,子类可以不改变算法结构的情况下重定义某些特定步骤。
主要特点:
- 定义算法框架:模板方法在抽象类中定义了一个算法的骨架,但将某些步骤的具体实现延迟到子类中。
- 防止子类修改:模板方法通常是 final 的,防止子类修改算法的结构。
- 钩子方法:模板方法可以包含一些“钩子”方法,这些方法在模板方法中调用,但默认实现为空,子类可以选择性地实现这些方法。或者设计为抽象方法,完全由子类来实现。
Java SE 核心类库中通过 InputStream、OutputStream、AbstractList、AbstractSet、Thread 和 TimerTask 等类广泛使用了模板方法设计模式。这些类定义了算法的骨架,但将某些步骤的具体实现延迟到子类中,从而提供了高度的灵活性和可扩展性。
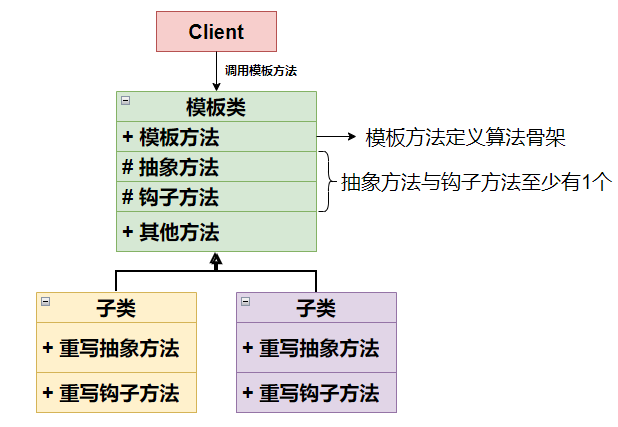
public abstract class Game { //模板类// 模板方法,定义了游戏的基本流程public final void play() {initialize();startPlay();endPlay();}// 抽象方法,由子类实现protected abstract void initialize();protected abstract void startPlay();protected abstract void endPlay();
}
public class BasketBallGame extends Game {//具体子类@Overrideprotected void initialize() {System.out.println("篮球游戏初始化");}@Overrideprotected void startPlay() {System.out.println("篮球游戏开始");}@Overrideprotected void endPlay() {System.out.println("篮球游戏结束存盘");}
}public class FootballGame extends Game {@Overrideprotected void initialize() {System.out.println("足球游戏初始化");}@Overrideprotected void startPlay() {System.out.println("足球游戏开始");}@Overrideprotected void endPlay() {System.out.println("足球游戏结束存盘");}
}
public class TemplateMethodDemo {public static void main(String[] args) {Game game = new BasketBallGame();game.play();//调用模板方法game = new FootballGame();game.play();//调用模板方法}
}
7、观察者设计模式
观察者设计模式(Observer Pattern)是一种行为设计模式,它定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。当主题对象的状态发生变化时,它会通知所有观察者对象,使它们能够自动更新。
public interface Subject {//主题接口void registerObserver(Observer o);void removeObserver(Observer o);void notifyObservers();
}
public interface Observer {//观察者接口void update(String message);
}
import java.util.ArrayList;
import java.util.List;public class ParentHealth implements Subject { //具体被观察的主题类:例如,父母老人的健康主题private List<Observer> observers = new ArrayList<>();private String message;@Overridepublic void registerObserver(Observer o) {observers.add(o);}@Overridepublic void removeObserver(Observer o) {observers.remove(o);}@Overridepublic void notifyObservers() {for (Observer observer : observers) {observer.update(message);}}public void setMessage(String message) {this.message = message;System.out.println("父母健康状态发生变化:");notifyObservers();}
}import java.util.ArrayList;
import java.util.List;public class Weather implements Subject{private List<Observer> observers = new ArrayList<>();private String message;@Overridepublic void registerObserver(Observer o) {observers.add(o);}@Overridepublic void removeObserver(Observer o) {observers.remove(o);}@Overridepublic void notifyObservers() {for (Observer observer : observers) {observer.update(message);}}public void setMessage(String message) {this.message = message;System.out.println("天气发生变化:");notifyObservers();}
}public class Children implements Observer{//具体观察者,例如:儿女@Overridepublic void update(String message) {System.out.println("儿女们接收新信息:" + message +",请假回家");}
}public class CommunityCareWorker implements Observer{//具体观察者,例如:社区工作者@Overridepublic void update(String message) {System.out.println("社区护工接收新消息:" + message + ",上门查看");}
}public class Doctor implements Observer{//具体观察者,例如:医生@Overridepublic void update(String message) {System.out.println("家庭医生接收新消息:" + message + ",分析健康状态");}
}public class TestObservers {public static void main(String[] args) {ParentHealth p = new ParentHealth();Weather w = new Weather();Children s = new Children();CommunityCareWorker c = new CommunityCareWorker();Doctor d = new Doctor();//订阅健康主题消息p.registerObserver(s);p.registerObserver(c);p.registerObserver(d);//订阅天气主题消息w.registerObserver(s);w.registerObserver(c);System.out.println("健康主题变化演示:");p.setMessage("发烧");System.out.println("===================");p.setMessage("摔跤");System.out.println("====================");p.removeObserver(d);//取消订阅p.setMessage("感冒");System.out.println("====================");System.out.println("天气主题变化演示:");w.setMessage("下雪");}
}