AMD GPU上对比语言图像预训练(CLIP)模型的交互
3.1.1 介绍
对比语言图像预训练(CLIP)是一种连接视觉和自然语言的多模态深度学习模型。它是在OpenAI的论文从自然语言监督中学习可转移的视觉模型(2021)中介绍的,并在大量(4亿)图像字幕对的网络抓取数据上进行了对比训练(这是最早做到这一点的模型之一)。
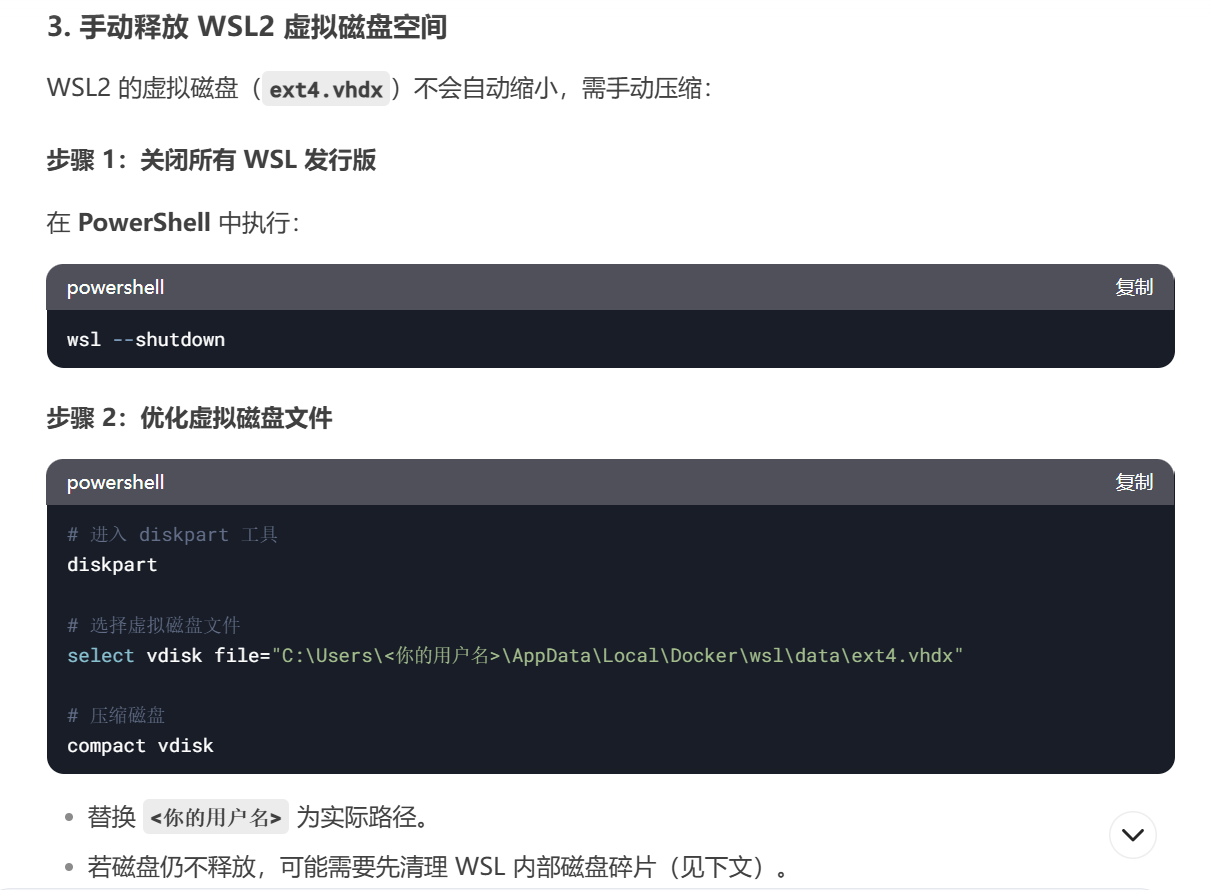
在预训练阶段,CLIP被训练来预测批处理中图像和文本之间的语义关联。这涉及确定哪些图像文本对彼此关系最密切或最相关。该过程涉及图像编码器和文本编码器的同时训练。目标是最大化批处理中图像和文本对嵌入之间的余弦相似性,同时最小化不正确对嵌入的相似性。该模型通过学习多模态嵌入空间来实现这一点。对称交叉熵损失在这些相似性得分上得到了优化。标准图像模型联合训练图像特征,提取器和线性分类器预测标签,如图3-1所示。
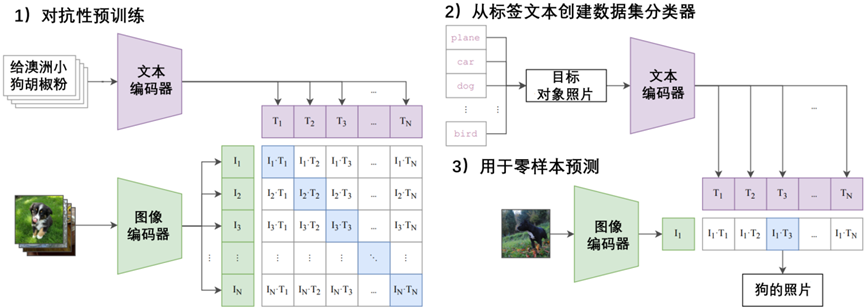
图3-1 标准图像模型联合训练图像特征,提取器和线性分类器预测标签
标准图像模型联合训练图像特征提取器和线性分类器来预测一些标签,而CLIP联合训练图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对。在测试时,学习的文本编码器通过嵌入目标数据集的类的名称或描述来合成零样本线性分类器。
图片来源:从自然语言监督中学习可转移的视觉模型。
在的后续部分,将利用PyTorch框架和ROCm来运行CLIP模型,以计算任意图像和文本输入之间的相似性。
3.1.2 安装程序
此演示是使用以下设置创建的。
1)硬件和操作系统:
①AMD Instinct GPU
②Ubuntu 22.04.3 LTS
2)软件:
①ROCm 5.7.0+
②Pytorch 2.0+
3.1.3 任意图像和文本输入之间的相似性计算
1. 第一步:开始
首先,确认GPU的可用性。
!rocm-smi –显示产品名称
ROCm系统管理界面
产品信息
GPU[0]:板卡系列:AMD INSTINCT MI250(MCM)OAM AC MBA
GPU[0]:卡型号:0x0b0c
GPU[0]:卡供应商:Advanced Micro Devices,股份有限公司[AMD/ATI]
GPU[0]:卡SKU:D65209
ROCm SMI日志结束
接下来,安装CLIP和所需的库。
! pip install git+https://github.com/openai/CLIP.git ftfy regex tqdm matplotlib
2. 步骤2:加载模型
import torch
import clip
import numpy as np
# 将加载ViT-L/14@336px剪辑模型
model, preprocess = clip.load("ViT-L/14@336px")
model.cuda().eval()
# 检查模型架构
print(model)
# 检查预处理器
print(preprocess)
输出:
CLIP(
(visual): VisionTransformer(
(conv1): Conv2d(3, 1024, kernel_size=(14, 14), stride=(14, 14), bias=False)
(ln_pre): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1024, out_features=1024, bias=True)
)
(ln_1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=1024, out_features=4096, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=4096, out_features=1024, bias=True)
)
(ln_2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(1): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1024, out_features=1024, bias=True)
)
(ln_1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=1024, out_features=4096, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=4096, out_features=1024, bias=True)
)
(ln_2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
...
(23): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1024, out_features=1024, bias=True)
)
(ln_1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=1024, out_features=4096, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=4096, out_features=1024, bias=True)
)
(ln_2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
)
(ln_post): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(1): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
...
(11): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
(token_embedding): Embedding(49408, 768)
(ln_final): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
Compose(
Resize(size=336, interpolation=bicubic, max_size=None, antialias=warn)
CenterCrop(size=(336, 336))
<function _convert_image_to_rgb at 0x7f8616295630>
ToTensor()
Normalize(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711))
)