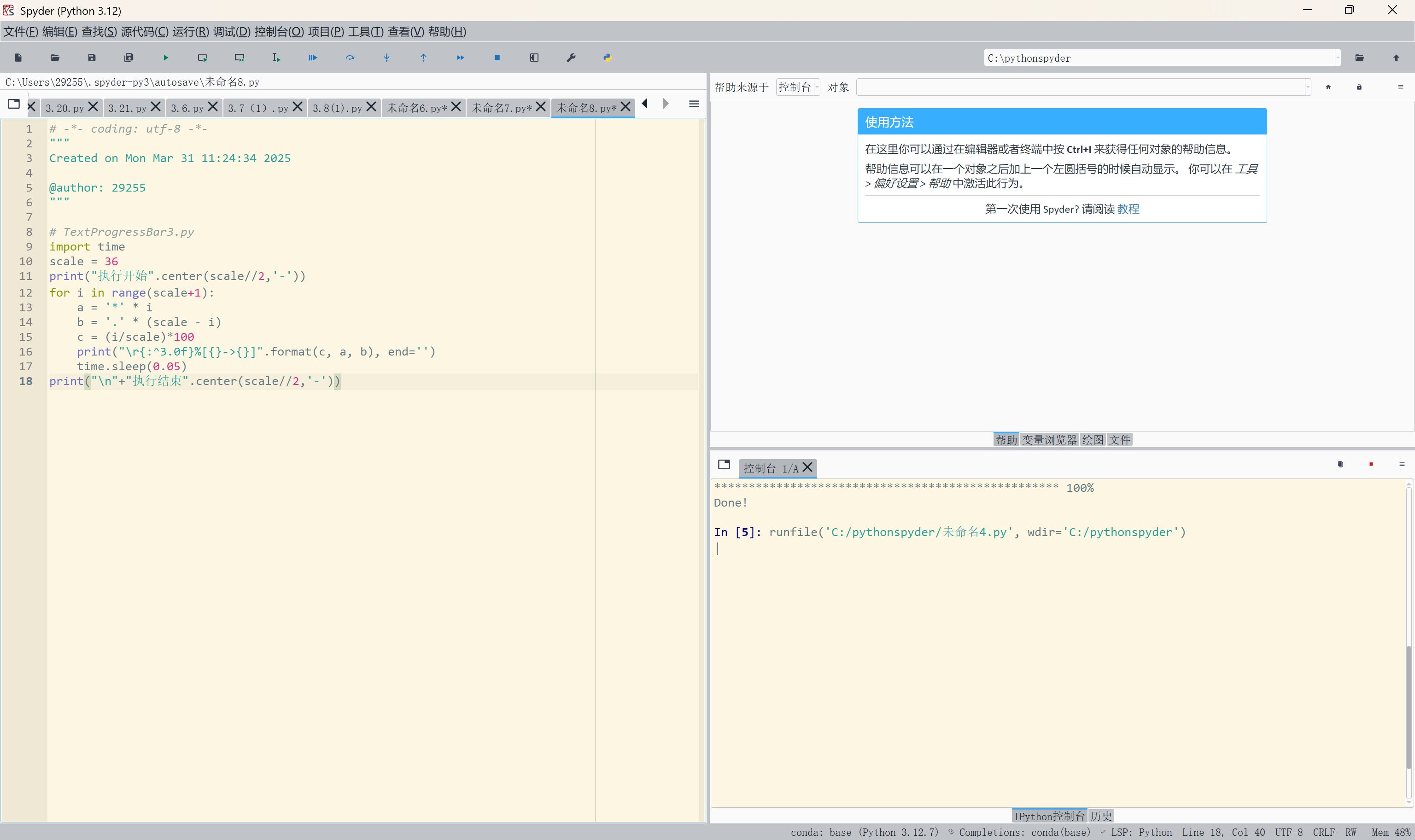
一、简介
验证码识别是自动化测试和数据提取中常见的挑战。Ruby 作为一门灵活高效的脚本语言,结合 Tesseract OCR,可以快速完成验证码识别任务。本文将介绍如何使用 Ruby 实现验证码识别,并进行一些图像预处理操作来提升识别率。
二、环境准备
2.1 安装 Ruby
大多数系统自带 Ruby,可以通过以下命令检查:
ruby -v
如果未安装,可以通过 rbenv 或 RVM 进行安装。
2.2 安装 Tesseract OCR
Linux (Ubuntu):
sudo apt update
sudo apt install tesseract-ocr libtesseract-dev
macOS:
更多内容访问ttocr.com或联系1436423940
brew install tesseract
Windows: 前往 GitHub 下载并安装 Tesseract。
2.3 安装依赖库
我们需要使用以下 Ruby 库:
mini_magick:进行图像处理
rtesseract:Ruby 版 Tesseract 接口
安装这些库:
gem install mini_magick
gem install rtesseract
三、代码实现
3.1 代码结构
图像预处理
验证码识别
识别结果输出
3.2 Ruby 代码示例
创建文件 captcha_ocr.rb:
require 'mini_magick'
require 'rtesseract'
def preprocess_image(input_path, output_path)
image = MiniMagick::Image.open(input_path)
转换为灰度图像
image.colorspace 'Gray'
调整对比度和亮度
image.level '20%,80%'
二值化处理
image.threshold '50%'
调整图像大小
image.resize '300x100'
保存预处理后的图像
image.write(output_path)
end
def recognize_captcha(image_path)
processed_path = 'processed_captcha.png'
preprocess_image(image_path, processed_path)
ocr = RTesseract.new(processed_path, lang: 'eng', psm: 6)
text = ocr.to_s.strip
puts "识别出的验证码: #{text}"
end
主程序
captcha_path = 'captcha.png'
if File.exist?(captcha_path)
recognize_captcha(captcha_path)
else
puts "验证码文件不存在: #{captcha_path}"
end
四、运行程序
将验证码图片放在脚本同一目录下,并命名为 captcha.png。
运行程序:
ruby captcha_ocr.rb
示例输出:
识别出的验证码: 3F9KX
五、效果优化
5.1 调整 PSM 模式
Tesseract 支持不同的页面分割模式(PSM),在某些验证码中,单行文本模式效果更好:
ocr = RTesseract.new(processed_path, lang: 'eng', psm: 6)
5.2 使用特定语言包
如果验证码主要是数字,可以指定为数字模式:
ocr = RTesseract.new(processed_path, lang: 'eng+osd', tessedit_char_whitelist: '0123456789')
5.3 进一步图像增强
在图像预处理中,尝试去噪和边缘检测来提高字符清晰度。
六、性能和效果分析
处理速度快:Ruby 的脚本特性使其非常适合小型快速处理任务。
代码简洁:结合 Tesseract 和 MiniMagick,代码清晰易读。
识别率高:通过图像增强和 PSM 模式调整,可以显著提升识别效果。


![B3916 [语言月赛 202401] 区间函数最大值](https://img2024.cnblogs.com/blog/3619440/202503/3619440-20250331121007583-1146033787.png)