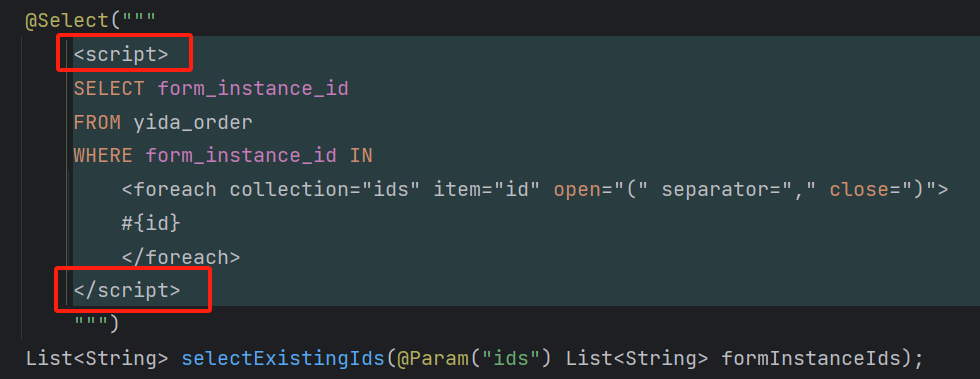
当线程遭遇海量的并发请求时...
等等,什么是并发?
[!NOTE] 并发(Concurrency)与并行(Parallelism)
并发代表应用程序能够同时(并发)处理多个任务。
尽管严格意义上在单核CPU中应用程序不可能真正“同时”取得进展,但对外看来其内部一次正在处理多个任务,并且在之前的任务完成之前能够继续接受并开始一个新的任务。并行代表应用程序能够真正同时在多个任务上取得进展。
从本质上讲,并行需要具有多个处理单元。在单核 CPU 中可能做到并发,但不可能做到并行。并发更加强调多个任务在重叠的时间段内交替推进,通过任务切换提高资源利用率。
并行更加强调多个任务在同一时间段内同时推进,利用多个处理单元缩短总时间。
并行是一种特殊的并发,其中任务实际上是同时执行的。--- displayMode: compact ---gantt title 并发 axisFormat %S秒 section 任务A CPU核心1 :a1, 00, 2s CPU核心1 :a2, after b1, 2s section 任务B CPU核心1 :b1, after a1, 2s CPU核心1 :b2, after a2, 2s--- displayMode: compact --- gantt title 并行 axisFormat %S秒section 任务ACPU核心1 :pa1, 00, 4ssection 任务BCPU核心2 :pb1, 00, 4s
在CPU还是单核的时代,操作系统就已经引入了线程的概念,用于实现并发。
在IO操作中,CPU往往需要等待某个事件的发生,例如等待数据从磁盘读取完成,或者等待网卡接受到远端的数据。
在这个等待的过程中,CPU是空闲的。为了充分利用CPU的资源,操作系统会将当前正在等待IO事件的线程挂起,并将CPU的控制权交给其他需要CPU进行计算的线程。当IO操作完成后,操作系统会唤醒挂起的线程,让其继续执行。
因此,一种常见的并发处理方式是使用 1:1 的线程模型,即每当收到一个新的用户请求时,就创建一个新的线程来处理这个请求。在处理请求的过程中如果需要等待IO事件,则使用阻塞式的系统调用挂起当前线程,在IO事件发生后由操作系统唤醒线程继续执行。
[!NOTE] 阻塞与非阻塞、同步与异步
在概念上,阻塞(blocking)与非阻塞(non-blocking)通常用于描述模块或API在等待事件时的行为。
阻塞意味着模块将会一直等待事件发生,等待时间内不会做其他事情。模块将会在事件发生后恢复执行。
非阻塞意味着模块并不会等待事件发生。无论当前是否有可处理的事件,模块都会继续执行。另一组常见的概念是同步(synchronous)与异步(asynchronous),通常用于描述两个模块之间的交互方式。
模块A与模块B是同步的意味着在B完成任务之前A会一直等待,在B完成任务后A才会继续执行。
而异步意味着A不会等待B完成,阻塞与非阻塞、同步与异步在概念上有着十分微妙的不同。
注意区分任务执行中的同步与并发编程中的同步(Synchronization)。
一个典型的代码如下:
class Server {
public:// 主线程void handle_connection() {while (!stop_) {Connection conn = accept_connection_blocking(); // 阻塞式调用,等待新的连接std::thread([worker = Worker{conn}] {worker.do_work();}).detach();}}
};class Worker {Connection conn_;
public:// 每个 worker 都在独立的线程中执行void do_work() {while (conn_->is_connected()) {std::string request = conn->receive_blocking(); // 阻塞式调用,从网络中读取请求std::string response = process_request(request);conn->send_blocking(response); // 阻塞式调用,将响应发送到网络}}
};
在操作系统中,线程是一个非常重量级的资源,创建和销毁线程都需要耗费大量的资源。因此为了提高性能,可以使用线程池来重用线程,避免频繁创建和销毁线程。但是线程和任务的关系仍然是 1:1 的,即每个任务都会分配一个线程来执行。
class ThreadPool {std::vector<std::thread> threads_;std::queue<std::function<void()>> tasks_;std::mutex mutex_;std::condition_variable condition_;int running_tasks = 0;public:void add_task(std::function<void()> task) {std::unique_lock<std::mutex> lock(mutex_);ensure_enough_threads(); // 确保线程池中有足够的线程,避免任务等待tasks_.push_back(task);condition_.notify_one();}// 由线程池中的线程调用void do_work() {while (true) {std::function<void()> task;{std::unique_lock<std::mutex> lock(mutex_);condition_.wait(lock, [this] { return !tasks_.empty(); });// 当线程长时间没有需要执行的任务时,也可以考虑销毁线程释放资源task = tasks_.front();tasks_.pop();}task();}}
};
线程池避免了频繁创建和销毁线程的开销,但是线程池中的线程仍然是 1:1 的关系。每当任务需要等待IO事件时,线程会被挂起,操作系统需要保存当前线程的上下文,将上下文切换到其他就绪线程的上下文。
而上下文的切换仍然是一个非常耗费资源的操作,通常情况下操作系统需要保存通用寄存器、浮点寄存器、向量寄存器等 CPU 的状态,同时切换内存映射表、页表等内存管理的状态并刷新 TLB。通常而言需要保存的状态有 100 KB,而切换的时间在 1-10 微秒。如果算上 TLB 刷新导致的后续 cache miss,这个时间可能会更长。
为了解决这个问题,出现了一种影响十分深远的设计模式:事件循环。在 1:1 线程模型中,我们使用阻塞式系统调用向操作系统发起 IO 请求,让操作系统等待事件的发生。而在事件循环中,我们将任务中“等待事件发生”这一部分抽象出来,在一个统一的调度器中使用少量的线程来监听大量的事件,并在事件发生时调用相应的处理函数执行任务的剩余部分。由于线程数量大大减少,线程平均的等待时间也大大减少,操作系统不再需要频繁地进行挂起线程执行上下文切换,从而提高了 CPU 的利用率。
事件循环的基本结构如下:
void event_loop() {while (true) {Event event = poll_event();dispatch_event(event);}
}
其中,poll_event 函数通过某些方式获取当前已经发生的事件,例如磁盘读取缓冲区已完成填充,网络接收缓冲区已经有数据等。
dispatch_event 函数根据事件的类型调用相应的处理函数。
针对 poll_event,操作系统提供了多种系统调用。最简单的一种实现方式是使用非阻塞的系统调用进行轮询。
例如在 Linux 中,使用 fcntl 函数设置文件描述符为非阻塞模式,然后调用 read 函数读取数据。如果没有数据可读,read 函数会立即返回,而不会阻塞线程。
例如基于轮询的 poll_event 的实现如下:
Event poll_event(std::vector<Connection> connections) {while (true) {for (auto& conn : connections) {if (conn->is_readable_non_blocking()) {return Event{conn, EventType::Readable};}if (conn->is_writable_non_blocking()) {return Event{conn, EventType::Writable};}}}
}
尽管非阻塞式的系统调用不再挂起线程,节省了线程上下文切换的开销,但是轮询每一个文件描述符的状态仍然需要发起大量系统调用,程序仍然会频繁地进入和退出内核态,导致 CPU 的资源浪费。
为了进一步节省时间,可以考虑使用操作系统提供的IO多路复用,在一次系统调用中监听多个文件描述符的状态。
select、poll、epoll 等系统调用都是操作系统提供的IO多路复用的方式,仅在 API 设计和执行效率上有些不同。epoll 是目前 Linux 中最高效的 IO 多路复用方式。
class EventLoop {std::map<int, EventSource*> event_sources_;int epoll_fd;
public:EventLoop() {epoll_fd = epoll_create1(0);}void add_event_source(EventSource *source) {event_sources_.emplace(source->get_fd(), source);epoll_event ev;ev.events = EPOLLIN | EPOLLOUT;ev.data.fd = source->get_fd();epoll_ctl(epoll_fd, EPOLL_CTL_ADD, source->get_fd(), &ev);}void remove_connection(EventSource *source) {event_sources_.erase(source->get_fd());epoll_ctl(epoll_fd, EPOLL_CTL_DEL, source->get_fd(), nullptr);}Event poll_event() {epoll_event events[1];int nfds = epoll_wait(epoll_fd, events, 1, -1); // 阻塞式调用,等待任意一个事件发生for (int i = 0; i < nfds; ++i) {if (events[i].events & EPOLLIN) {return Event{event_sources_[events[i].data.fd], EventType::Readable};}if (events[i].events & EPOLLOUT) {return Event{event_sources_[events[i].data.fd], EventType::Writable};}}}
};
在事件循环监听到事件发生后,需要调用 dispatch_event 派发事件,调用相应的处理函数。
一种常见的方式是向事件循环注册回调函数,每当任务需要等待事件发生时,便向事件循环注册针对该事件的处理函数,等待事件发生后由事件循环调用处理函数。
class EventLoop {// ...std::map<Event, std::vector<std::function<void()>>> event_handlers_; // 一次性的事件处理函数,当事件发生时调用并清空,需要重复注册std::mutex mutex_;public:// ...// 由 worker 调用,注册事件处理函数void register_event_handler(Event event, std::function<void()> handler) {std::unique_lock<std::mutex> lock(mutex_);event_handlers_[event].emplace_back(handler);}void dispatch_event(Event event) {std::vector<std::function<void()>> handlers;{std::unique_lock<std::mutex> lock(mutex_);if (event_handlers_.find(event) == event_handlers_.end()) {return;}swap(handlers, event_handlers_[event]); // 获取已注册的事件处理函数,并清空}for (auto& handler : handlers) {handler(); // 也可以使用线程池在独立的线程中执行,避免阻塞事件循环}}
}class Server {EventLoop& ev;ServerSocket server_socket_;
public:void start() {ev.register_event_handler(Event{server_socket_, EventType::Readable}, std::bind(&Server::on_connection, this));}void on_connection() {Connection conn = server_socket_.accept_connection_non_blocking(); // 非阻塞式调用,等待新的连接Worker worker{conn};worker.do_work(); // 调用后立即返回}
}class Worker {EventLoop& ev;Connection conn_;
public:void do_work() {ev.register_event_handler(Event{conn, EventType::Readable}, [this] {std::string request = conn_->receive_non_blocking(); // 非阻塞式调用,从网络中读取请求std::string response = process_request(request);ev.register_event_handler(Event{conn, EventType::Writable}, [this, response] {conn->send_non_blocking(response); // 非阻塞式调用,将响应发送到网络do_work(); // 递归调用,继续处理下一个请求});});}
};
[!NOTE] 回调函数的线程安全
需要注意回调函数是由事件循环执行的,其执行线程可能会与注册回调函数的线程不同。因此当任务的不同部分之间存在共享的状态时需要注意线程安全问题。
此外,由于IO是异步非阻塞的,函数返回后回调函数可能还未执行,因此需要注意回调函数及其变量的生命周期,避免出现垂悬指针。
基于异步的事件循环模型可以实现高效的并发处理,但需要将任务拆分为多个独立的回调函数。这在代码逻辑变得复杂的同时增大了编写和维护的难度。为了解决这个问题,可以使用协程来简化异步编程。
协程是一种轻量级的线程。与操作系统提供的线程不同,协程的调度在用户态完成,不需要执行操作系统的上下文切换。但是协程保留了线程的特性,允许用户使用阻塞式的API发起IO事件并挂起当前协程,等待事件发生后被唤醒并恢复执行。
协程与线程最大的不同是协程之间的切换是可预知和可控的。
对于线程而言,操作系统需要不定时中断当前线程的执行,将CPU转让给其他线程以保证不会有线程长时间未得到执行。此外操作系统在收到硬件中断时也需要临时中断当前线程的执行,切换到操作系统内核的中断处理程序。这些切换可能发生在任何一个时间点,程序完全无法预知线程切换并进行准备。同时操作系统无法感知线程上的程序究竟依赖于上下文中的哪些状态,因此为了保障正确性,操作系统只能完整地保存线程当前的上下文并在唤醒时恢复。
对于协程而言,协程之间的切换能且只能由程序显式地发起,这些可能会挂起协程的位置被称为挂起点(suspension point)。编译器和协程库知道程序中的挂起点,在挂起点前后保存和恢复程序依赖的上下文,并在挂起点直接生成相应的跳转代码。协程的上下文远小于线程的上下文,在一些场景下协程库还允许由编译器感知或程序员指定程序真正依赖的上下文,进一步减少协程切换时所需要保存的状态。
当协程被挂起时,协程的上下文会被保存在一个特殊的数据结构中。这个过程不需要操作系统的介入,也不需要保存和恢复线程的上下文,因此协程的切换速度远远快于线程的切换。
协程的实现方式有很多,大体上可以分为两种:有栈协程(Stackful Coroutine)和无栈协程(Stackless Coroutine)。
有栈协程的实现方式与操作系统的线程非常相似,每一个有栈协程都运行在独立的栈上。有栈协程在执行到挂起点时,其所有的状态都会被保存在协程栈上。因此切换协程只需要切换线程使用的运行时栈即可。挂起点前后的代码会自动地处理协程上下文的保存和恢复。
无栈协程则不需要独立的栈。无栈协程执行到挂起点时,栈中不再保存任何状态,其所有状态都会保存在堆中由编译器生成的数据结构中。因此不同的无栈协程可以直接共用执行线程栈,也允许调度到不同线程上基于不同的栈运行。不过这种设计在实现上更加复杂,会在后续的章节中介绍。
有栈协程由于符合已有的线程模型,因此在实现上更加简单,所使用的接口也会更加地符合现有的编程习惯。在经过封装后使用有栈协程编写的代码与使用阻塞式同步API的代码非常相似:
void do_work() {std::string request = co_receive(conn_); // 阻塞式调用,挂起当前协程但不会阻塞线程,请求到达后恢复执行std::string response = process_request(request);co_send(conn_, response); // 阻塞式调用,挂起当前协程但不会阻塞线程,响应发送完成后恢复执行
}
经过良好抽象的协程库可以隐藏协程的实现细节,并且能够和现有的异步库结合使用,提供更简洁的异步编程方式。例如 co_receive 可以使用上面的事件循环实现,使用协程库提供的API将协程挂起并在事件发生后恢复执行。
std::string co_receive(Connection conn) {std::string request;ev.register_event_handler( // 1. 注册回调函数(线程A)Event{conn, EventType::Readable},[&request, conn] {request = conn->receive_non_blocking();CO_RESUME(); // 3. 唤醒协程(线程B)});CO_SUSPEND(); // 2. 挂起当前协程,等待回调函数执行(线程A)// 4. 从 suspend 后恢复执行(线程C)return request;
}
协程在和异步IO库配合时由多种不同的调度策略。
例如在上面的例子中:
线程 A 在执行到 2 挂起当前协程后,线程 A 应该挂起、继续执行当前线程中的其他协程还是从其他线程的任务队列中偷取已就绪的协程执行?异步库的线程 B 在 3 处唤醒协程后,线程 B 应该立即返回还是直接执行被唤醒的协程?协程执行到 4 处时,底层的执行线程应该是进入函数时的线程 A、异步库中唤醒协程的线程 B、还是调度器线程池中的线程 C?
从理论上,这些行为都是合法的。Boost::fiber 库中就允许自定义协程的调度策略,既可以将协程的调度限制在启动协程的线程中(默认行为),也可以基于任务偷取在全局初始化一个线程池,允许协程在不同的线程中执行。
POSIX 提供了 ucontext.h 头文件用于抽象程序的执行上下文,可以用于实现有栈协程。一种可以在 Linux 和 macOS 上使用的协程库如下。
相对于侵入性较小的有栈协程,无栈协程需要编译器和运行时的支持,同时需要对函数的签名进行修改,因此在使用上会有一定的限制。C++20 引入了对无栈协程的支持,使用无栈协程实现的 worker 代码如下:
StacklessCoroutine<std::string> co_receive(Connection conn);
StacklessCoroutine<void> co_send(Connection conn, std::string response);StacklessCoroutine<> do_work_inner() {std::string request = co_await co_receive(conn_); // 阻塞式调用,挂起当前协程但不会阻塞线程,请求到达后恢复执行std::string response = process_request(request);co_await co_send(conn_, response); // 阻塞式调用,挂起当前协程但不会阻塞线程,响应发送完成后恢复执行
}void do_work() {do_work_inner().detach();
}
可以看到,无栈协程需要修改函数的签名,在原本返回值的基础上套了一层协程对象,用来保存协程的状态。同时使用 co_await 来显式地挂起协程。
StacklessCoroutine<std::string> co_receive(Connection conn) {auto awaitable = callback_awaitable([conn](auto resume_handle){ev.register_event_handler(Event{conn, EventType::Readable}, [resume_handle, conn] {resume(conn->receive_non_blocking()); // 恢复当前协程});})std::string request = co_await awaitable; // 挂起当前协程,等待回调函数执行co_return request;
}
相比于有栈协程,无栈协程的实现中额外引入了一个 awaitable 对象,用于显式恢复协程的执行。但整体的逻辑与有栈协程非常相似。
MyCoroutine myCoroutineFunction(Argument arg) {Trace::print("coroutine 1");co_await Awaiter{};Trace::print("coroutine 2");
}void caller() {Trace::print("before coroutine");MyCoroutine myCoroutine = myCoroutineFunction(Argument{});Trace::print("after coroutine");co_handle.resume();Trace::print("after resume");
}
实际上会被编译器转换为:
MyCoroutine myCoroutineFunction(void *state, Argument arg) {// 保存所有参数到 state// 构造 promise_type 对象// 调用 promise_type::get_return_object(),返回 MyCoroutine 对象。可在// get_return_object() 中调用// std::coroutine_handle<promise_type>::from_promise(*this) 在 MyCoroutine// 中保存 coroutine_handle await promise_type::initial_suspend()。 当// initial_suspend() 恢复执行时,执行函数体。Trace::print("coroutine 1");co_await Awaiter{};Trace::print("coroutine 2");co_return;
}void caller() {Trace::print("before coroutine");void *state = new myCoroutineFunction__CoroutineState();MyCoroutine myCoroutine = myCoroutineFunction(state, Argument{});Trace::print("after coroutine");co_handle = myCoroutineFunction__CoroutineState::get_handle(state);co_handle.resume();Trace::print("after resume");
}
#include <iostream>
#include <coroutine>struct Argument {Argument() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }~Argument() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }Argument(const Argument&) { std::cout<<__PRETTY_FUNCTION__<<std::endl; }Argument& operator=(const Argument&) { std::cout<<__PRETTY_FUNCTION__<<std::endl; return *this; }
};struct MyCoroutine {MyCoroutine() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }~MyCoroutine() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }// promise_type 为固定名称,更改会导致编译错误struct promise_type {promise_type() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }promise_type(int test) { std::cout<<__PRETTY_FUNCTION__<<std::endl; }~promise_type() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }promise_type(const promise_type&) = delete;promise_type& operator=(const promise_type&) = delete;MyCoroutine get_return_object() { std::cout<<__PRETTY_FUNCTION__<<std::endl; return {}; }std::suspend_never initial_suspend() { std::cout<<__PRETTY_FUNCTION__<<std::endl; return {}; }std::suspend_never final_suspend() noexcept { std::cout<<__PRETTY_FUNCTION__<<std::endl; return {}; }void return_void() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }void unhandled_exception() { std::cout<<__PRETTY_FUNCTION__<<std::endl; std::terminate(); }};
};std::coroutine_handle<> co_handle;struct Awaiter {Awaiter() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }~Awaiter() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }bool await_ready() { std::cout<<__PRETTY_FUNCTION__<<std::endl; return false; }void await_suspend(std::coroutine_handle<> handle) { std::cout<<__PRETTY_FUNCTION__<<std::endl; co_handle = handle; }void await_resume() { std::cout<<__PRETTY_FUNCTION__<<std::endl; }
};MyCoroutine myCoroutineFunction(Argument arg) {// state = new myCoroutineFunction__CoroutineState,CoroutineState 由编译器基于当前函数生成,用于保存当前函数的执行状态// 保存当前函数的所有参数到 state(可能造成垂悬指针)// 构造 promise_type 对象// 调用 promise_type::get_return_object(),返回 MyCoroutine 对象(与当前函数上下文对应的 Coroutine 一致)// await promise_type::initial_suspend()。// 当 initial_suspend() 恢复执行时,执行函数体。std::cout << "Start of coroutine\n";// 保存当前函数的执行状态到 state// 调用 Awaiter::await_ready(),若返回 true,则直接调用 Awaiter::await_resume(),否则调用 Awaiter::await_suspend(coroutine_handle) 注册回调函数,未来准备就绪时可以调用 coroutine_handle.resume() 恢复执行// return state,将控制流交给调用方,函数返回前会析构 Awaiter 对象co_await Awaiter{};// 恢复执行std::cout << "Resume of coroutine\n";// 隐式调用 co_return;// 调用 promise_type::return_void()// 调用 promise_type::final_suspend()// 析构 promise_type 对象// 析构 state
}int main() {std::cout << "Before calling coroutine function\n";MyCoroutine myCoroutine = myCoroutineFunction(Argument{});std::cout << "After calling coroutine function\n";std::cout << "Before resuming coroutine\n";// 实际应该使用一个 scheduler 来调度协程,读取co_handle.resume();std::cout << "After resuming coroutine\n";return 0;
}
在 C++ 中,一种实现异步的方式是使用 promise 和 future。promise 和 future 之间是一对一的关系,与管道非常相似。promise 代表一个将会在未来某个时间完成的异步操作,future 代表这个异步操作的结果。通常而言 promise 由被调用者持有,在执行结束时调用 promise 的 API 设置执行结果。future调用者使用 future 对象的方法获取执行结果。
在实现中,promise 和 future 之间通过共享一个对象来传递数据。一种非常简单的实现方式如下:
// R: result type, E: error type
template <typename R, typename E>
class Promise {std::shared_ptr<State<R, E>> state_;public:Promise() {state_ = new State<R, E>();}~Promise() {delete state_;}// Mark the promise as completed with a value// Should be called by the producer only oncevoid set_value(R value) {state_.value_ = value;state_.ready_.store(true, std::memory_order_release);}// Mark the promise as aborted with an error// Should be called by the producer only oncevoid set_error(E error) {state_->error_ = error;state_->ready_.store(true, std::memory_order_release);}Future get_future() {return Future(this);}
}template <typename R, typename E>
class Future {std::shared_ptr<State<R, E>> state_;public:int get() {while (!state_->ready_.load(std::memory_order_acquire)) {// pollingstd::this_thread::sleep_for(std::chrono::milliseconds(1));}if (state_->error_) {throw state_->error_;}return state_->value_;}
}template <typename R, typename E>
class State {R value_;E error_;std::atomic<bool> ready_ = false;
}
用户可以以一下方式使用 promise 和 future:
Promise<int, std::string> do_work() {Promise<int, std::string> promise;std::thread([promise] {try {int result = do_actual_work();promise.set_value(result);} catch (std::string error) {promise.set_error(error);}}).detach();return promise;
}int main() {Promise<int, std::string> promise = do_work();Future<int, std::string> future = promise.get_future();try {int result = future.get();std::cout << "Result: " << result << std::endl;} catch (std::string error) {std::cout << "Error: " << error << std::endl;}
}
promise 本身只表示一个将来完成的异步操作,并不关心异步操作的具体实现。在 C++ 中,async 对此进行了封装,可以更方便地实现异步操作。