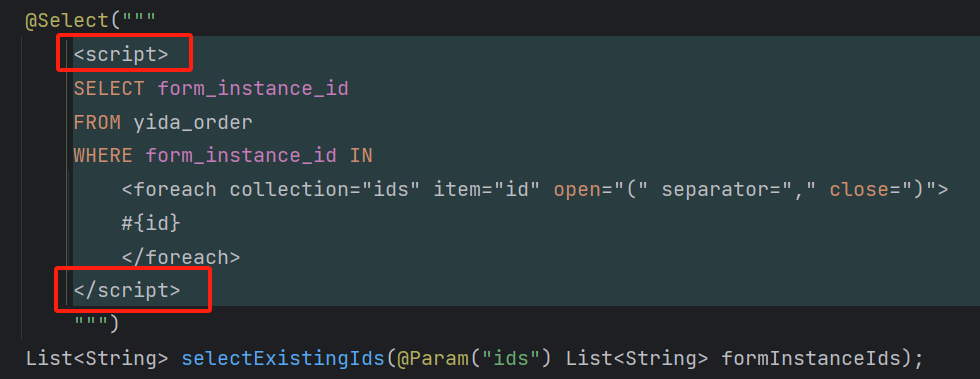
识别热点数据通常可通过以下几种方法:
基于访问频率统计:利用日志记录或专门的监控工具,统计一段时间内每个数据项的访问次数。设定一个阈值,当某个数据项的访问次数超过该阈值时,将其视为热点数据。例如,通过分析服务器的访问日志,统计不同数据请求的频率,对于访问频率较高的数据库记录、文件或缓存对象等,标记为热点数据。
基于时间窗口分析:以固定的时间窗口为单位,如每分钟、每小时等,统计每个数据项在该时间窗口内的访问频率。当数据项在多个连续的时间窗口内都保持较高的访问频率时,可判定为热点数据。这种方法能更好地适应数据访问模式的动态变化,及时捕捉到突发的热点数据。
基于 LRU(最近最少使用)算法的变体:维护一个缓存队列,按照数据最近被访问的时间进行排序。当缓存满时,优先淘汰最久未被访问的数据。通过观察缓存中数据的停留时间和访问顺序,可发现那些经常被访问、总是处于缓存队列头部的数据,将其识别为热点数据。
为保证热点数据的响应时间小于5ms,可采用以下策略:
多级缓存架构:构建包括浏览器缓存、CDN(内容分发网络)缓存、应用服务器本地缓存和分布式缓存等在内的多级缓存体系。浏览器缓存可以直接响应部分静态资源请求;CDN 缓存能根据用户的地理位置缓存数据,加速数据传输;应用服务器本地缓存用于快速响应本地请求;分布式缓存则负责存储热点数据,供多个服务器节点共享访问。通过这种多级缓存架构,大部分热点数据请求可以在缓存层得到快速响应,避免直接访问后端数据库或存储系统,从而大幅缩短响应时间。
缓存预热:在系统启动或业务高峰期来临前,提前将热点数据加载到缓存中。可以通过定时任务、数据预取等方式,将预计会成为热点的数据提前加载到各级缓存中。这样,当用户请求到达时,缓存中已经存在相应的数据,能够立即响应,无需等待数据从后端存储加载,有效减少了响应时间。
数据分片与复制:将热点数据进行分片,分散存储在多个服务器或节点上,以减轻单个节点的负载压力。同时,对热点数据进行适当的复制,将其存储在多个地理位置不同或性能较好的节点上,当某个节点出现故障或负载过高时,请求可以被路由到其他拥有该数据副本的节点上进行处理,保证热点数据的高可用性和快速响应。
优化数据库查询:对于需要从数据库获取热点数据的情况,优化数据库查询语句,创建合适的索引,以提高查询效率。例如,分析查询语句的执行计划,找出可能存在的性能瓶颈,如全表扫描等问题,并通过添加索引来优化查询。此外,还可以采用数据库连接池技术,减少数据库连接的创建和销毁开销,加快数据库访问速度。
采用高性能存储设备:对于存储热点数据的存储设备,选用性能更高的固态硬盘(SSD)甚至是内存数据库等。SSD 具有更快的读写速度,能够减少数据读取时间;内存数据库将数据存储在内存中,数据访问几乎可以达到内存访问速度,大大提高了数据的读取效率,从而保证热点数据的快速响应。