Packet(MBuf)库概述:
这个库提供了分配和释放缓冲区(mbuf)的能力,DPDK 应用可以使用这些缓冲区来存储各种类型的数据,比如:
- 网络数据包(最常见)
- 控制信息(control data)
- 事件(events)
- 或其他需要临时存储的数据
这些 mbuf 缓冲区的底层是通过 Mempool 管理的,即使用 Memory Pool Library 来进行对象池化分配。
rte_mbuf 是什么?
rte_mbuf 是 DPDK 中用来表示一个 消息缓冲区(Message Buffer) 的结构体。
最常用于:承载一个网络数据包(packet)或其中的一部分(比如一帧、一段 TCP payload)
结构设计特点:
rte_mbuf的结构体设计目标是:尽可能小、尽可能 cache 友好- 它被划分为两个 cache line,常用字段尽量放在第一个 cache line
- 这样可以减少 CPU 访问开销,提高包处理性能
主要字段包括:
- 指向真正数据的指针
data - 数据长度
data_len - 数据偏移
data_off - 指向原始 mempool 的指针
pool - 一些 metadata(如端口号、RSS hash、标志位)
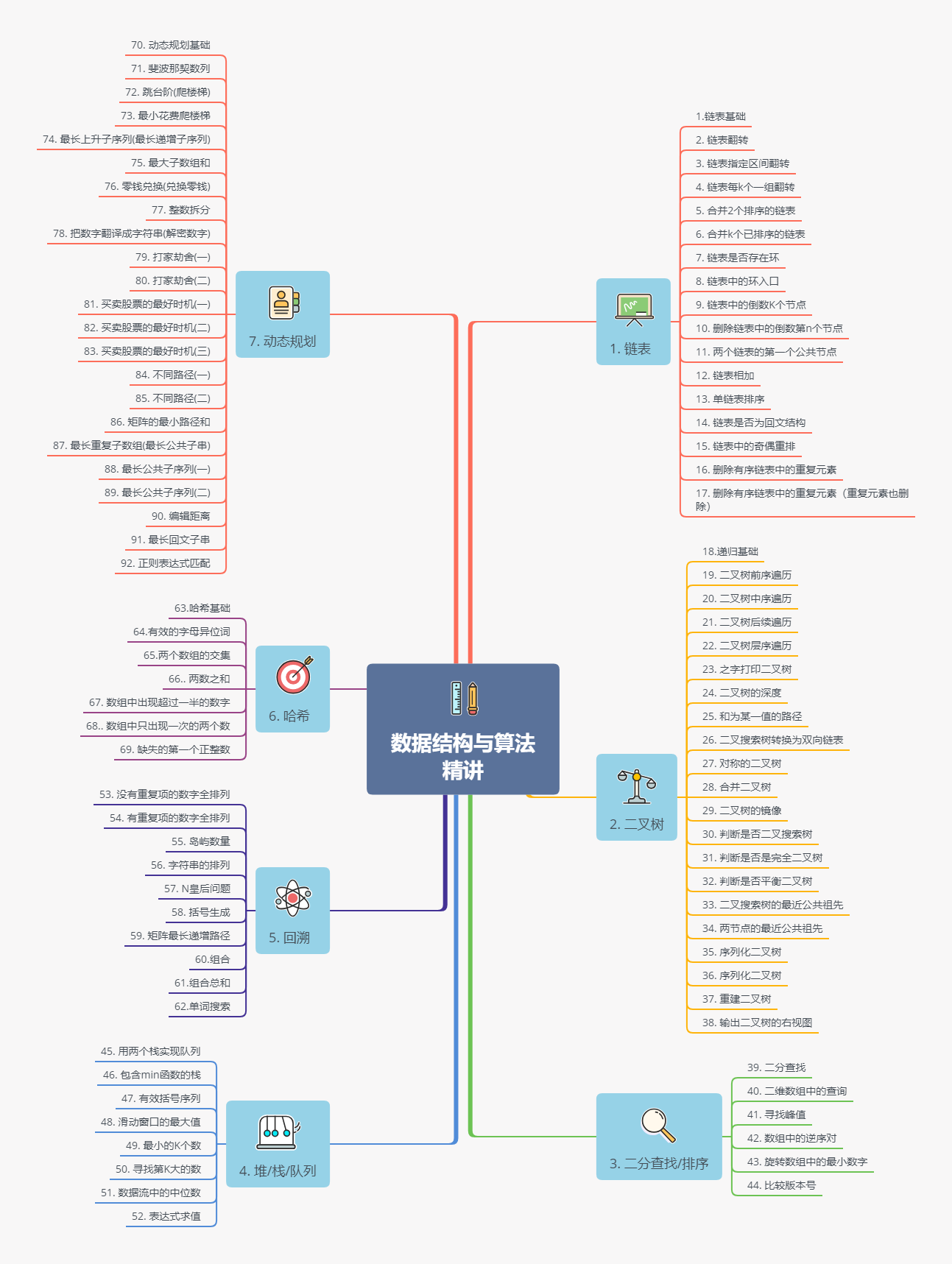
rte_mbuf
+-----------------------------+ ← 第一 cache line(常用)
| buf_addr |
| data_off |
| data_len |
| pkt_len |
| next |
| port, ol_flags, hash |
+-----------------------------+ ← 第二 cache line(不常访问)
| vlan info, timestamp, etc |
| user metadata |
+-----------------------------+通俗总结:
| 点 | 内容 |
|---|---|
| mbuf 是什么? | DPDK 中的基本数据包单元,既可以是网络包,也可以是任意数据 |
| 谁来分配 mbuf? | Mempool(对象池)负责分配、缓存、回收 mbuf |
| 为什么结构要小? | 减少 CPU 缓存 miss,提升包处理效率 |
| 能不能自定义? | rte_mbuf 支持用户元数据区,可挂自定义字段 |
数据包缓冲区设计:
在设计用于存储数据包数据(包括协议头部)的结构时,DPDK 考虑了两种方案:
方法一:将元数据和数据区合并在一个内存块中
也就是:先是 rte_mbuf 结构体 → 紧接着是一段固定大小的数据区,都位于同一个内存块中。
这种方式的好处是:
- 只需要一次分配 / 一次释放操作
- 结构紧凑、访问高效、减少内存碎片
- DPDK 选择了这种方式
方法二:将元数据和数据区分开存储
- 一块内存保存
rte_mbuf元数据 - 另一块内存保存真正的数据包内容
这种方法虽然更灵活(元信息和数据可以独立分配),但会带来额外复杂性:
- 两次分配和释放
- 缓存命中率低
- 管理复杂,不利于性能优化
DPDK 采用了第一种设计方案(合并结构)
在这种结构中,rte_mbuf 中包含:
- 消息类型(message type)
- 数据长度(data_len、pkt_len)
- 数据起始偏移(data_off)
next指针(用于多个 mbuf 链接成一个长包)
缓冲区链(Buffer Chaining)
有些大型数据包(如 jumbo frame)单个 mbuf 放不下,这时:
会使用多个
rte_mbuf,通过它们的next字段组成链表(mbuf chain)
每个 mbuf 承载数据包的一部分。
[mbuf1] --> [mbuf2] --> [mbuf3] ...
这种方式称为 scatter-gather 模式,在处理大包或硬件分段时非常重要。
数据偏移说明(RTE_PKTMBUF_HEADROOM)
每个新分配的 rte_mbuf 的数据区不是从 buffer 开头开始,而是:
data_start = buf_addr + RTE_PKTMBUF_HEADROOM
这个 预留空间(headroom) 用于:
- 在数据包前插入额外头部(如封装、tunneling)
- 保证数据对齐(cache aligned)
- 避免每次移动数据造成性能开销
默认 headroom 是 128 字节(可配置)


3.6 元信息(Meta Information)
DPDK 中的网络驱动在接收(RX)或发送(TX)数据包时,会把一些辅助信息存入 mbuf,以便后续快速处理或 offload 给硬件。
示例信息包括:
| 元信息 | 说明 |
|---|---|
| VLAN 标签信息 | 用于 VLAN 识别与打标 |
| RSS hash 值 | 用于多核负载均衡 |
| 校验和状态标志(checksum offload) | 表明硬件是否已经完成 L3/L4 校验 |
数据包来源端口 mb->port
该数据包链表的段数 nb_segs(mbuf 链)
如果是链式 mbuf,只有链首的 mbuf 保存这些元信息(包括 csum、RSS、port 等)
RX 方向(接收)
比如:
- IEEE1588 时间戳
- VLAN tag
- L3 校验和状态
都由网卡写入 mbuf 对应字段 → 上层代码无需重复解析,提高效率。
TX 方向(发送)
你也可以主动设置 mbuf 的标志位,告诉驱动让硬件去计算某些字段(offload),比如:
| 标志位 | 含义 |
|---|---|
RTE_MBUF_F_TX_IP_CKSUM |
要求硬件计算 IPv4 校验和 |
RTE_MBUF_F_TX_TCP_CKSUM |
要求硬件计算 TCP 校验和 |
RTE_MBUF_F_TX_UDP_CKSUM |
要求硬件计算 UDP 校验和 |
RTE_MBUF_F_TX_TCP_SEG |
要求硬件做 TCP 分段(TSO) |
RTE_MBUF_F_TX_OUTER_IP_CKSUM |
要求硬件计算外层 IPv4 封装的校验和(VXLAN 场景) |
VXLAN 封装 TCP 包的 Offload 配置示例:
下面这些例子展示如何设置 mbuf->ol_flags 与 mbuf->l2_len, l3_len, outer_l2_len 等字段来控制 offload 行为:
动态字段与标志位(Dynamic Fields and Flags)
由于 rte_mbuf 的结构大小是有限的(只有两个 cache line),但现实中协议场景非常多,无法为所有协议预留字段,因此 DPDK 提供了一种机制:动态扩展空间。
动态字段(Dynamic Field):
- 是 mbuf 结构中一个注册的 命名字段区域
- 你可以使用
rte_mbuf_dynfield_register()来分配 - 用于保存一些自定义的信息,如:
- Q-in-Q metadata
- PTP 时间戳
- 模块扩展标记
动态标志位(Dynamic Flag):
- 是
ol_flags字段中的 某一位 - 你可以用
rte_mbuf_dynflag_register()注册一个新的功能标志 - 之后可以在
ol_flags中设置或检查这个 flag
限制:
- 一旦注册后,动态字段/标志不能取消注册
- 每次注册都要求你指定大小、对齐方式(最小 1 字节)
- 多个库/模块可以独立使用,不冲突
通俗总结
| 点 | 说明 |
|---|---|
mbuf 支持哪些元信息? |
VLAN、hash、校验和状态、端口号、段数 |
| 硬件可以帮你做什么? | 计算 IP/TCP/UDP 校验和、TSO 分段、VXLAN 封装校验等 |
| 你需要设置什么? | ol_flags + l2_len / l3_len / outer_l2_len 等 |
| 动态扩展怎么办? | 用 rte_mbuf_dynfield_register() / dynflag_register() 添加自定义字段和标志 |
rte_mbuf 是高性能、硬件友好、可扩展的数据结构,既能记录丰富的协议信息,也支持灵活 offload 配置,且可通过动态字段实现模块间扩展与解耦。
直接与间接缓冲区(Direct and Indirect Buffers)
什么是 直接缓冲区(Direct Buffer)?
- 一个 独立完整 的
rte_mbuf,其buf_addr和数据完全属于它自己。 - 正常分配的
rte_mbuf都是 Direct 的。
什么是 间接缓冲区(Indirect Buffer)?
- 表面上是个
rte_mbuf,但它的数据指针(buf_addr和data_off)指向另一个 Direct mbuf 的数据区域。 - 自己不持有数据,只是引用别人的数据。
间接缓冲区非常适合以下场景:
| 场景 | 问题 | 使用间接缓冲区的优势 |
|---|---|---|
| 数据包复制 | 多个模块需要访问同一份数据 | 零拷贝复用数据,节省内存 |
| 数据包分片(如 GSO) | 一个包分成多个段 | 每个间接 mbuf 指向 Direct 的不同片段 |
| 转发分支 | 同一个包要发给多个目的地 | 创建多个 indirect clone,无需拷贝 |
//创建间接缓冲区
rte_pktmbuf_attach(indirect_mbuf, direct_mbuf);
//解除引用
rte_pktmbuf_detach(indirect_mbuf);
//推荐使用
struct rte_mbuf *clone = rte_pktmbuf_clone(original, clone_pool);
注意事项:
| 限制 | 说明 |
|---|---|
| 不能 attach 到另一个 indirect buffer | 会自动 attach 到其 direct buffer(跳过中间层) |
要 attach 的 direct buffer refcnt 必须为 1 |
表示它是“尚未被引用”的 |
| 不能重复 attach | 你必须先 detach 再 attach |