前几天,一个朋友问我:“大模型中的 Token 究竟是什么?”
这确实是一个很有代表性的问题。许多人听说过 Token 这个概念,但未必真正理解它的作用和意义。思考之后,我决定写篇文章,详细解释这个话题。

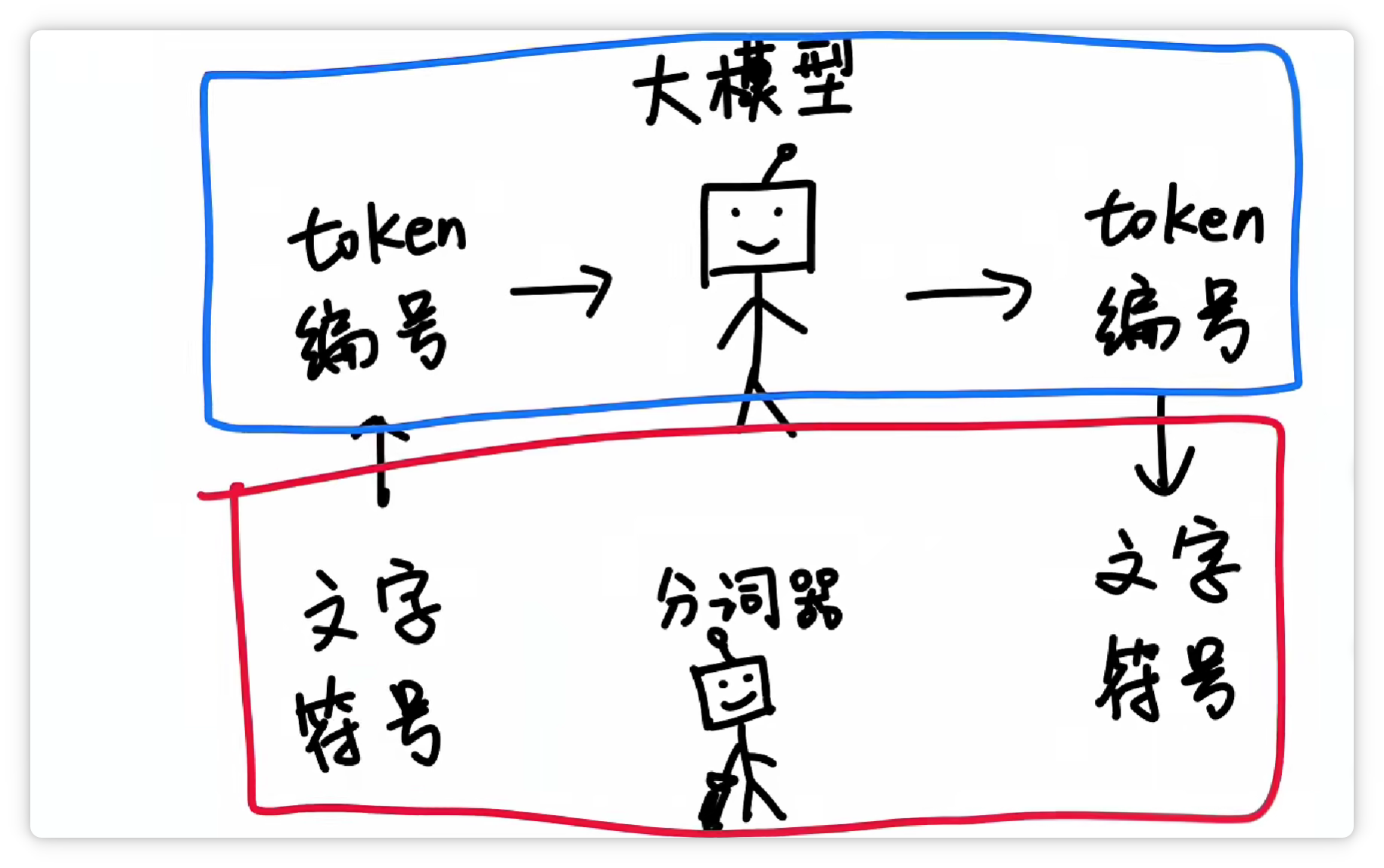
我说:像 DeepSeek 和 ChatGPT 这样的超大语言模型,都有一个“刀法精湛”的小弟——分词器(Tokenizer)。

当大模型接收到一段文字。
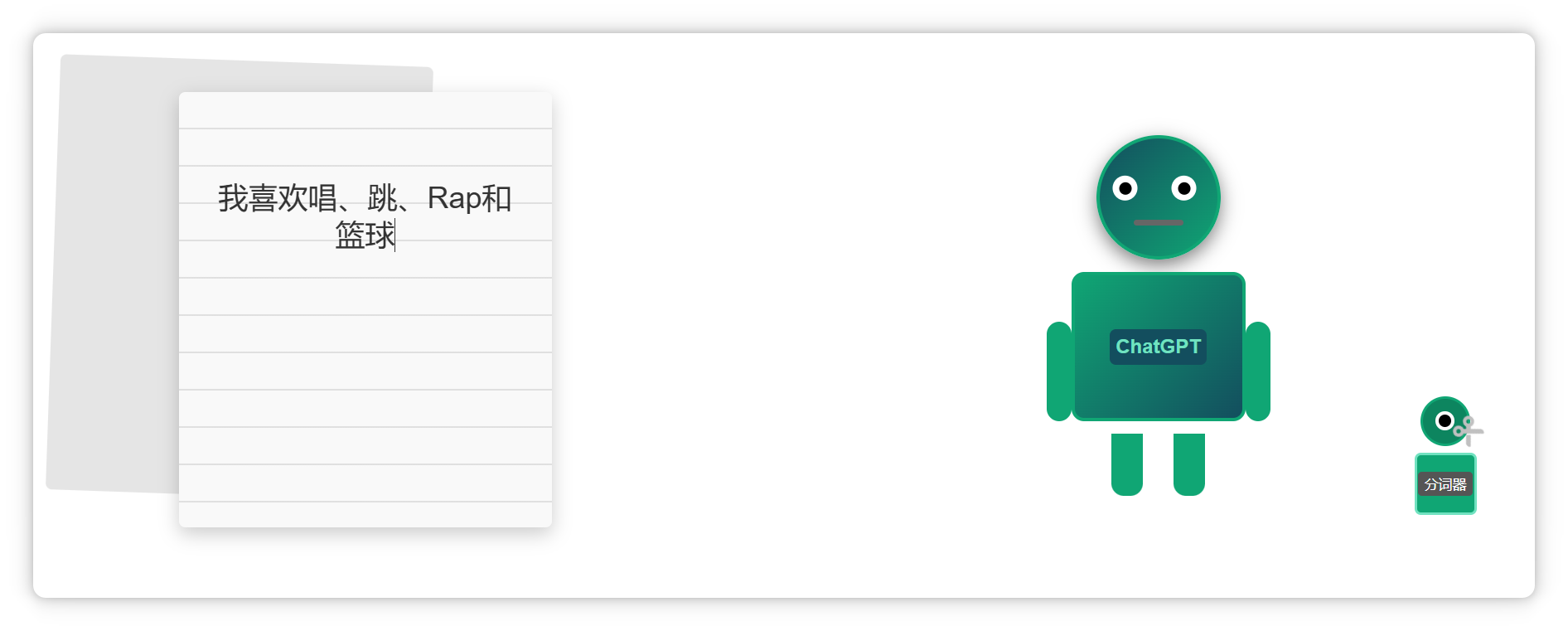
会让分词器把它切成很多个小块。
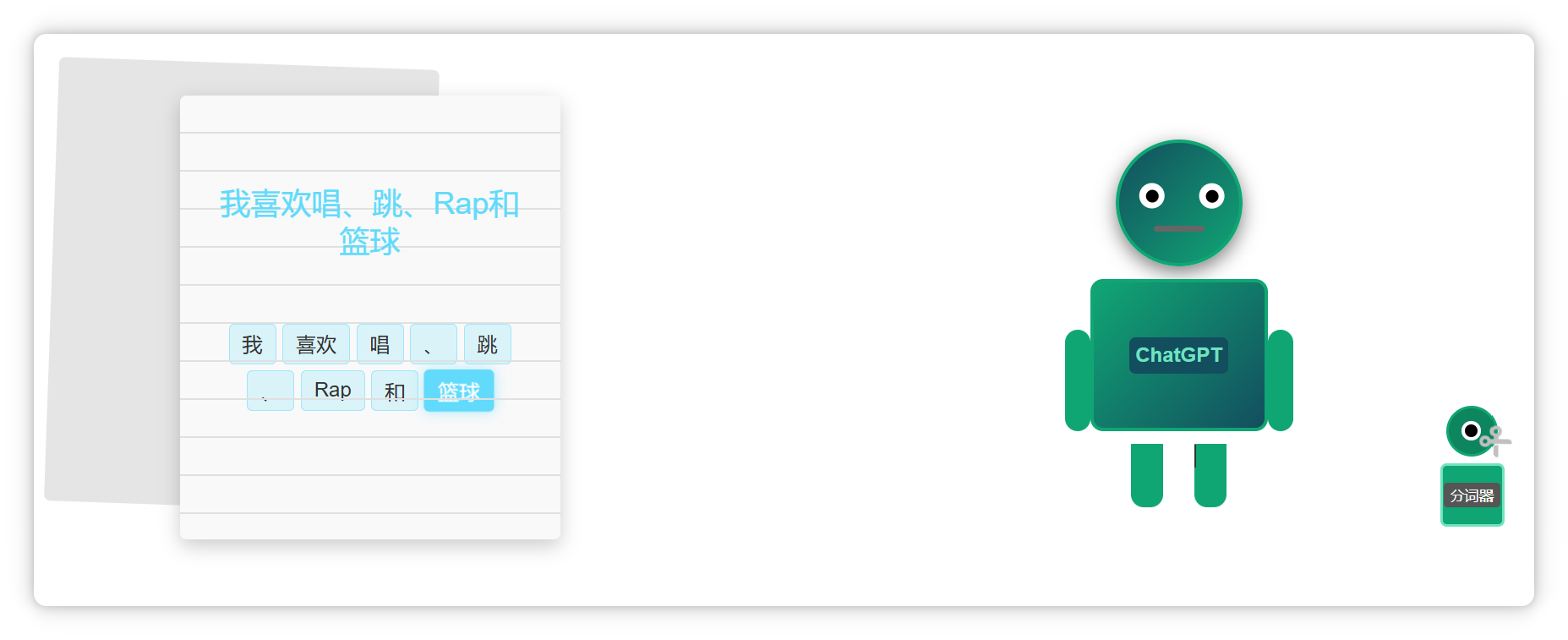
这切出来的每一个小块就叫做一个 Token。

比如这段话(我喜欢唱、跳、Rap和篮球),在大模型里可能会被切成这个样子。

像单个汉字,可能是一个 Token。
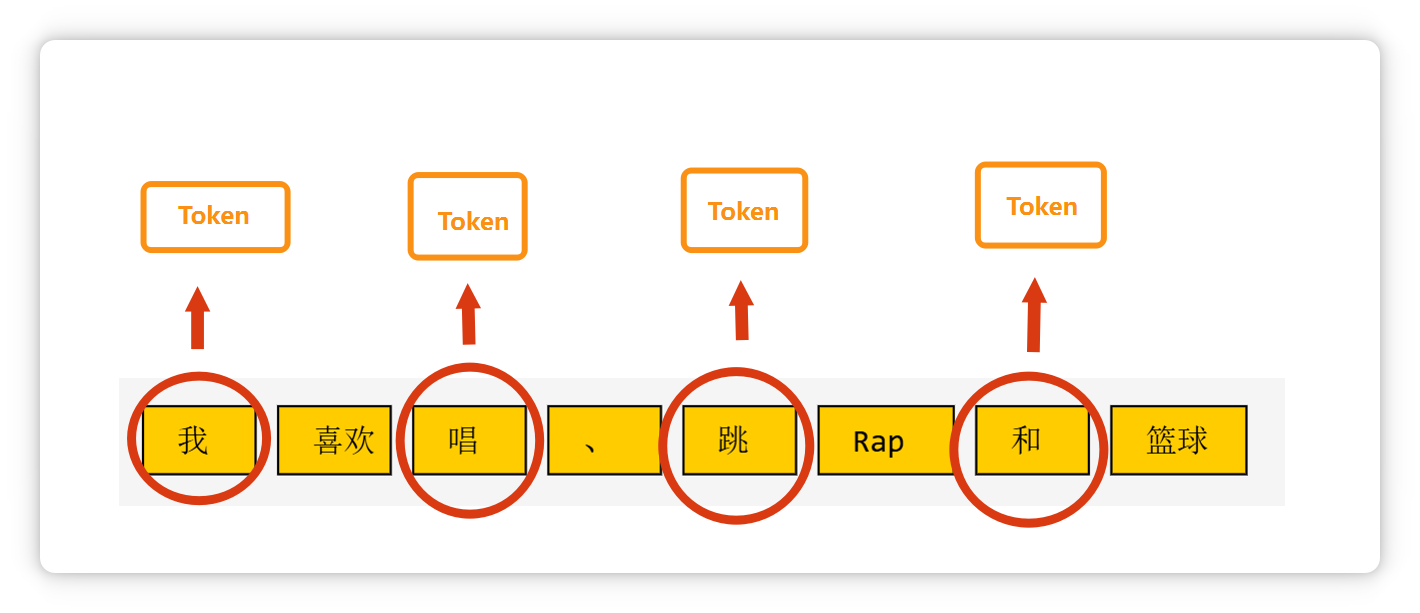
两个汉字构成的词语,也可能是一个 Token。
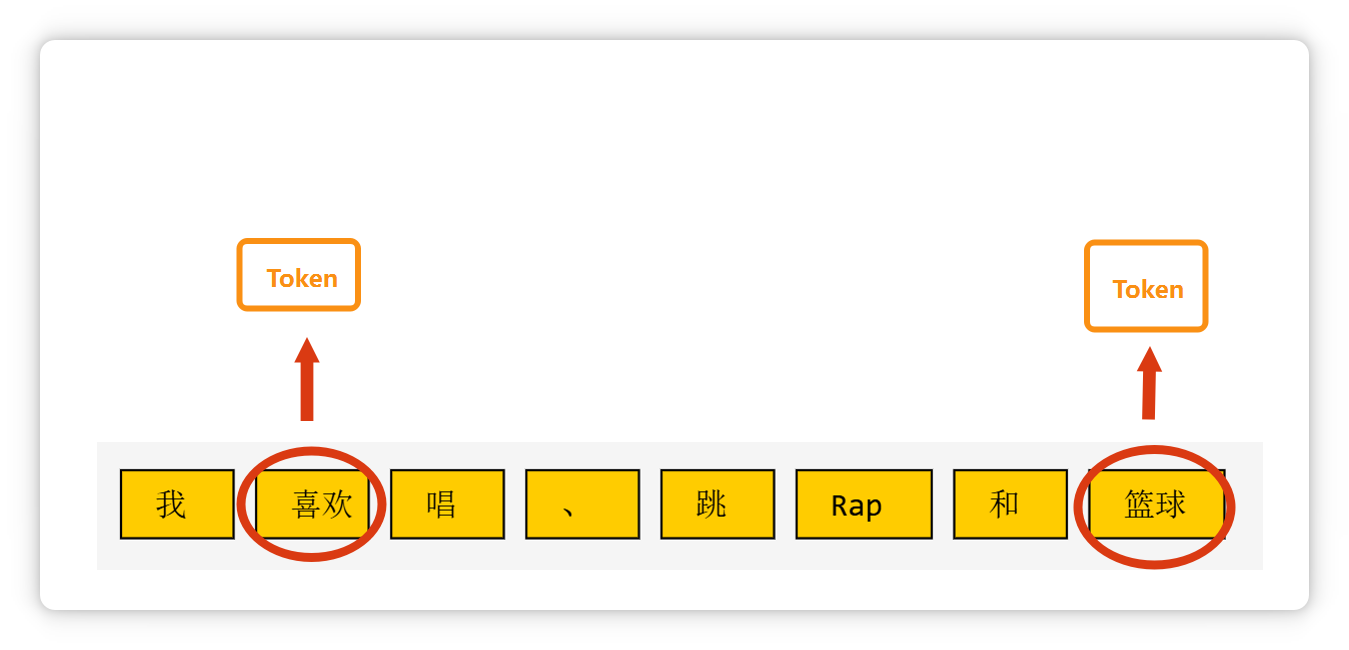
三个字构成的常见短语,也可能是一个 Token。
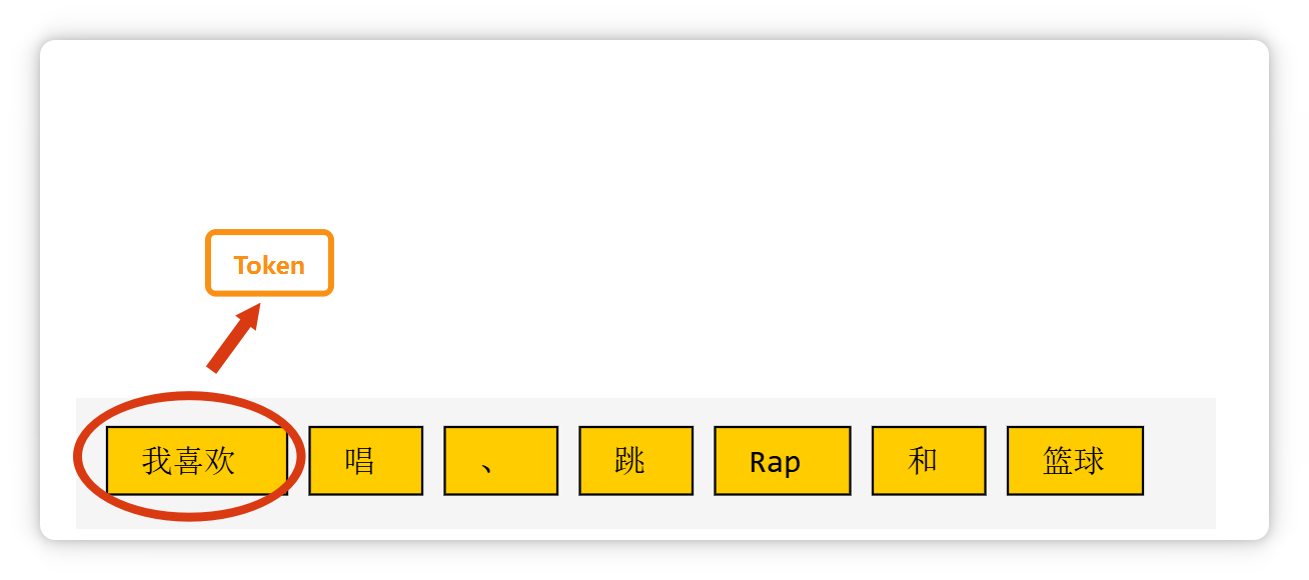
一个标点符号,也可能是一个 Token。
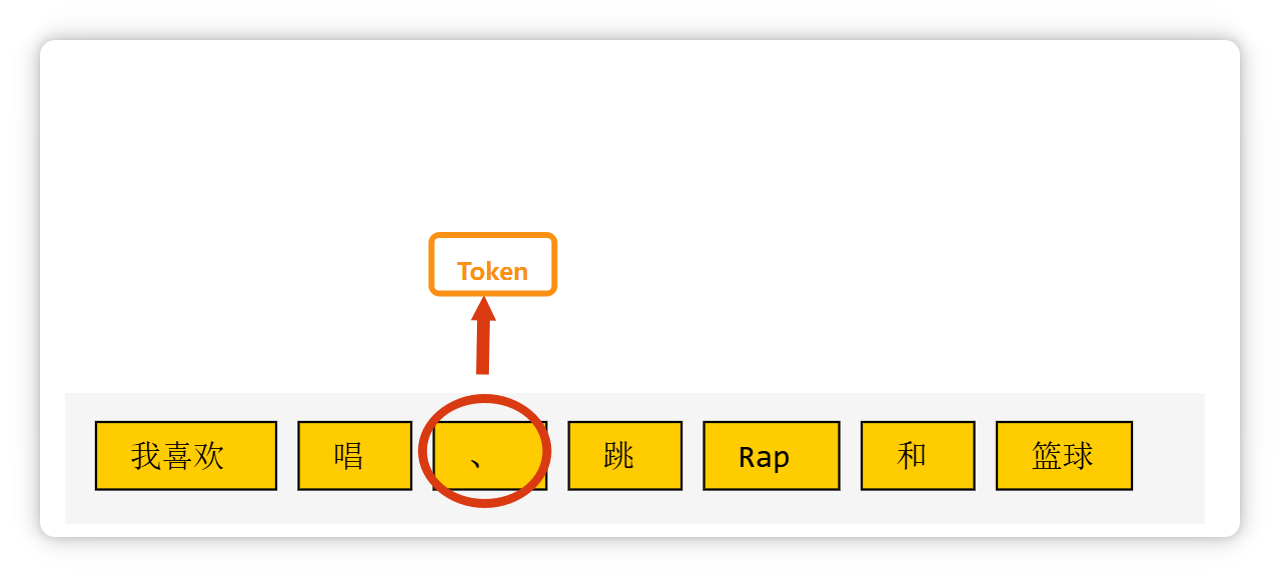
一个单词,或者是几个字母组成的一个词缀,也可能是一个 Token。

大模型在输出文字的时候,也是一个 Token 一个 Token 的往外蹦,所以看起来可能有点像在打字一样。

朋友听完以后,好像更疑惑了:

于是,我决定换一个方式,给他通俗解释一下。
大模型的Token究竟是啥,以及为什么会是这样。
首先,请大家快速读一下这几个字:

是不是有点没有认出来,或者是需要愣两秒才可以认出来?
但是如果这些字出现在词语或者成语里,你瞬间就可以念出来。

那之所以会这样,是因为我们的大脑在日常生活中,喜欢把这些有含义的词语或者短语,优先作为一个整体来对待。

不到万不得已,不会去一个字一个字的抠。

这就导致我们对这些词语还挺熟悉,单看这些字(旯妁圳侈邯)的时候,反而会觉得有点陌生。
而大脑🧠之所以要这么做,是因为这样可以节省脑力,咱们的大脑还是非常懂得偷懒的。

比如 “今天天气不错” 这句话,如果一个字一个字的去处理,一共需要有6个部分。

但是如果划分成3个、常见且有意义的词。

就只需要处理3个部分之间的关系,从而提高效率,节省脑力。
既然人脑可以这么做,那人工智能也可以这么做。

所以就有了分词器,专门帮大模型把大段的文字,拆解成大小合适的一个个 Token。

不同的分词器,它的分词方法和结果不一样。
分得越合理,大模型就越轻松。这就好比餐厅里负责切菜的切配工,它的刀功越好,主厨做起菜来当然就越省事。

分词器究竟是怎么分的词呢?
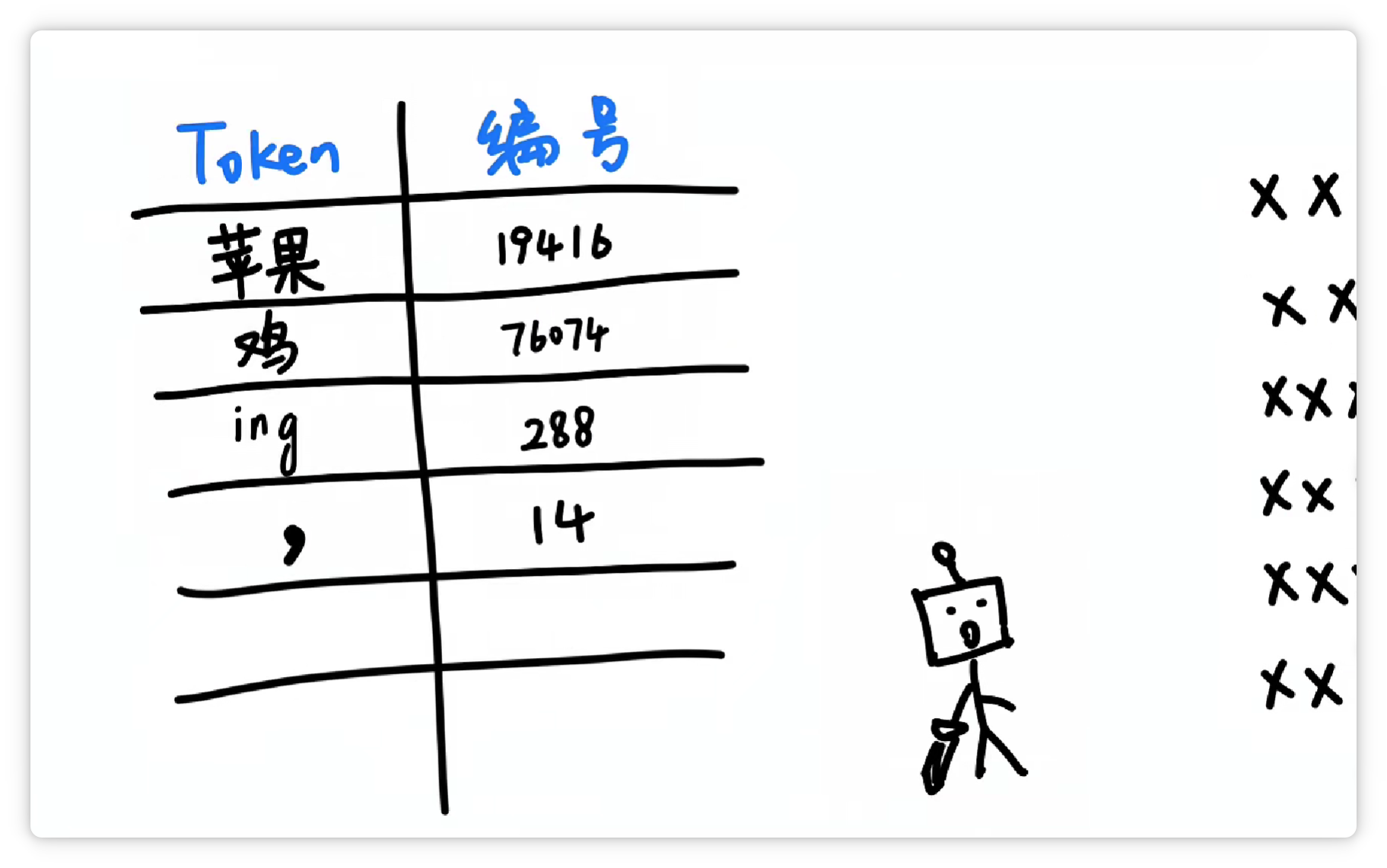
其中一种方法大概是这样,分词器统计了大量文字以后,发现 “苹果” 这两个字,经常一起出现。
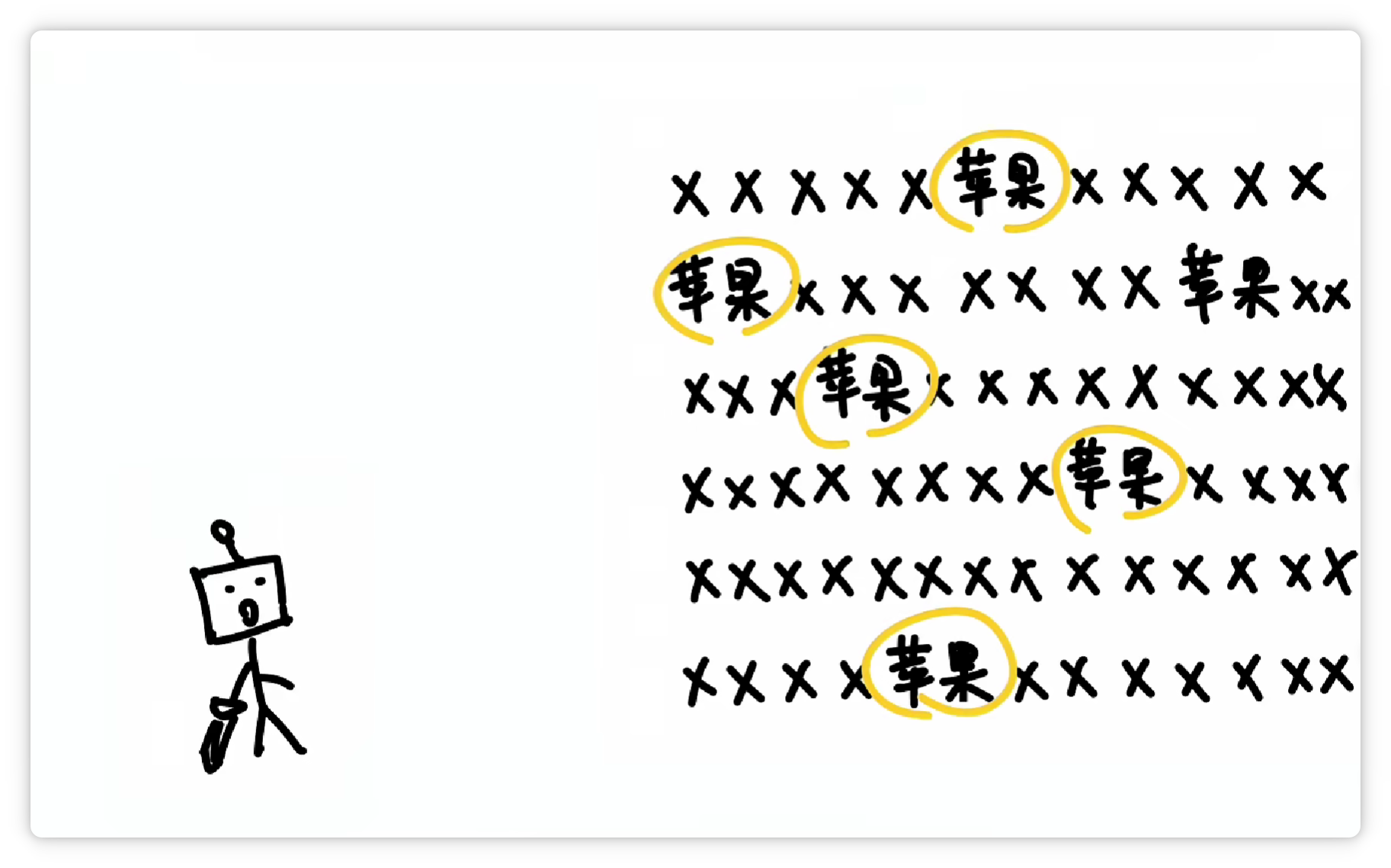
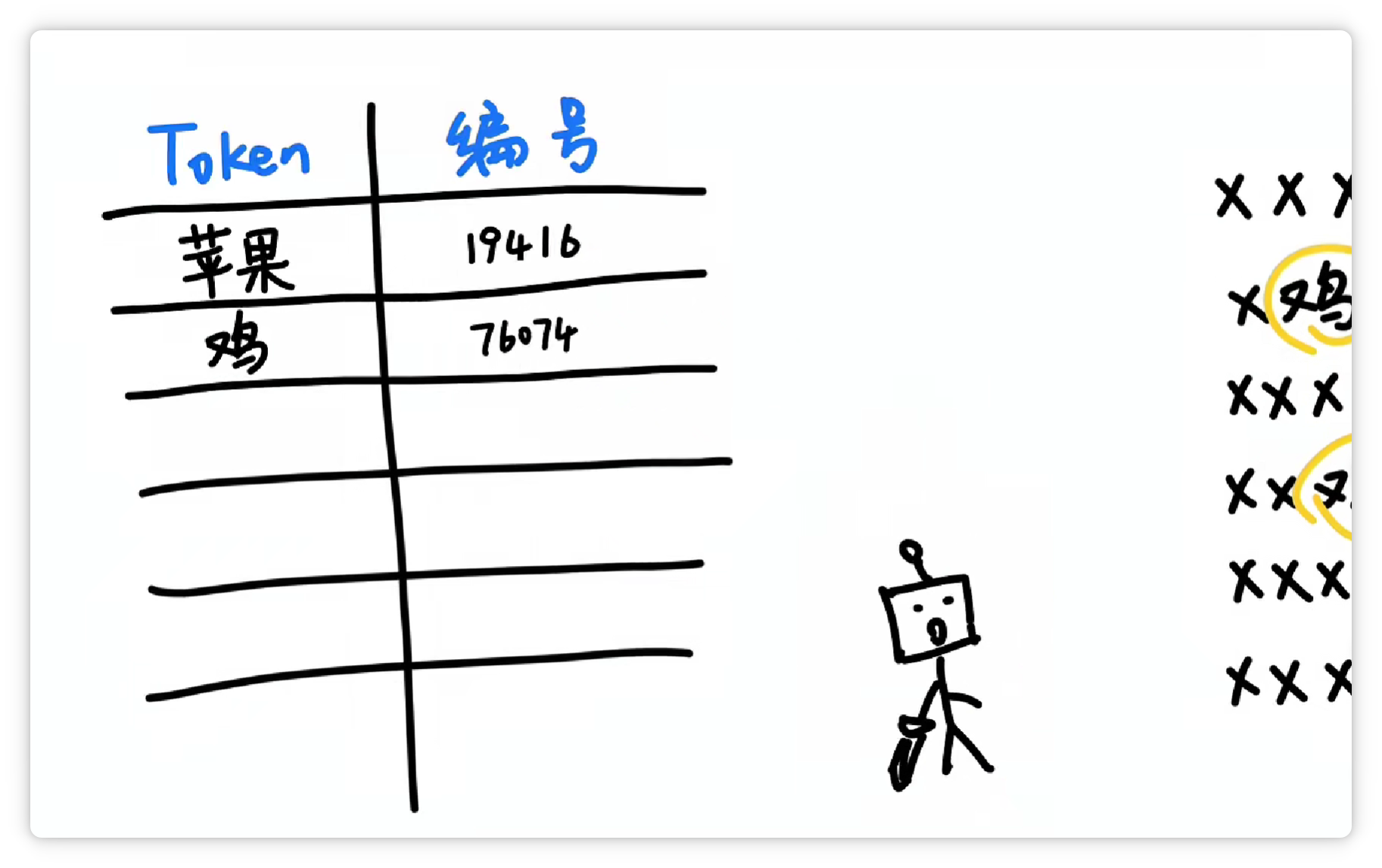
就把它们打包成一个 Token,给它一个数字编号,比如 19416。

然后丢到一个大的词汇表里。

这样下次再看到 “苹果” 这两个字的时候,就可以直接认出这个组合就可以了。
然后它可能又发现 “鸡” 这个字经常出现,并且可以搭配不同的其他字。

于是它就把 “鸡” 这个字,打包成一个 Token,给它配一个数字编号,比如 76074。

并且丢到词汇表里。
它又发现 “ing” 这三个字母经常一起出现。
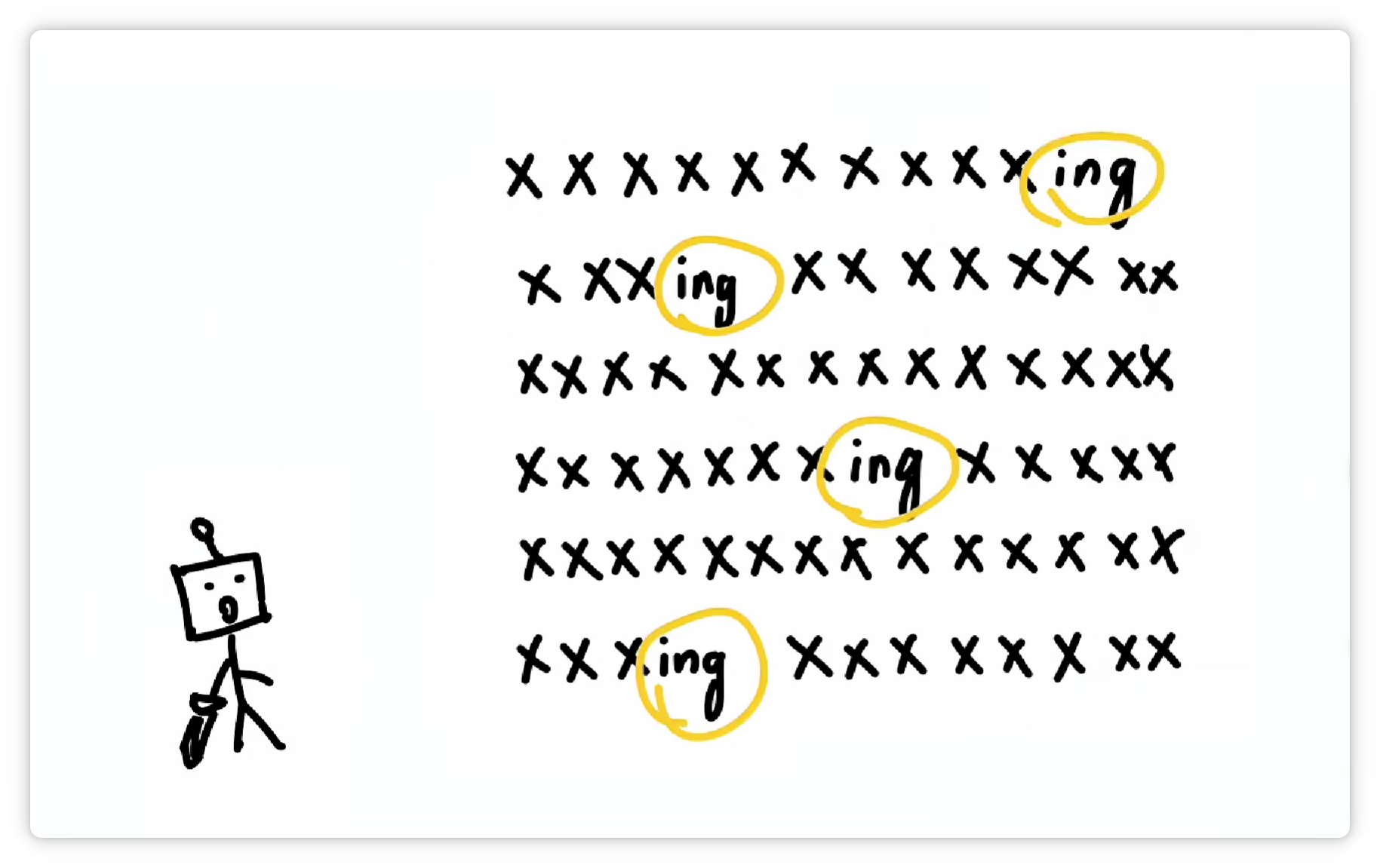
于是又把 “ing” 这三个字母打包成一个 Token,给它配一个数字编号,比如 288。
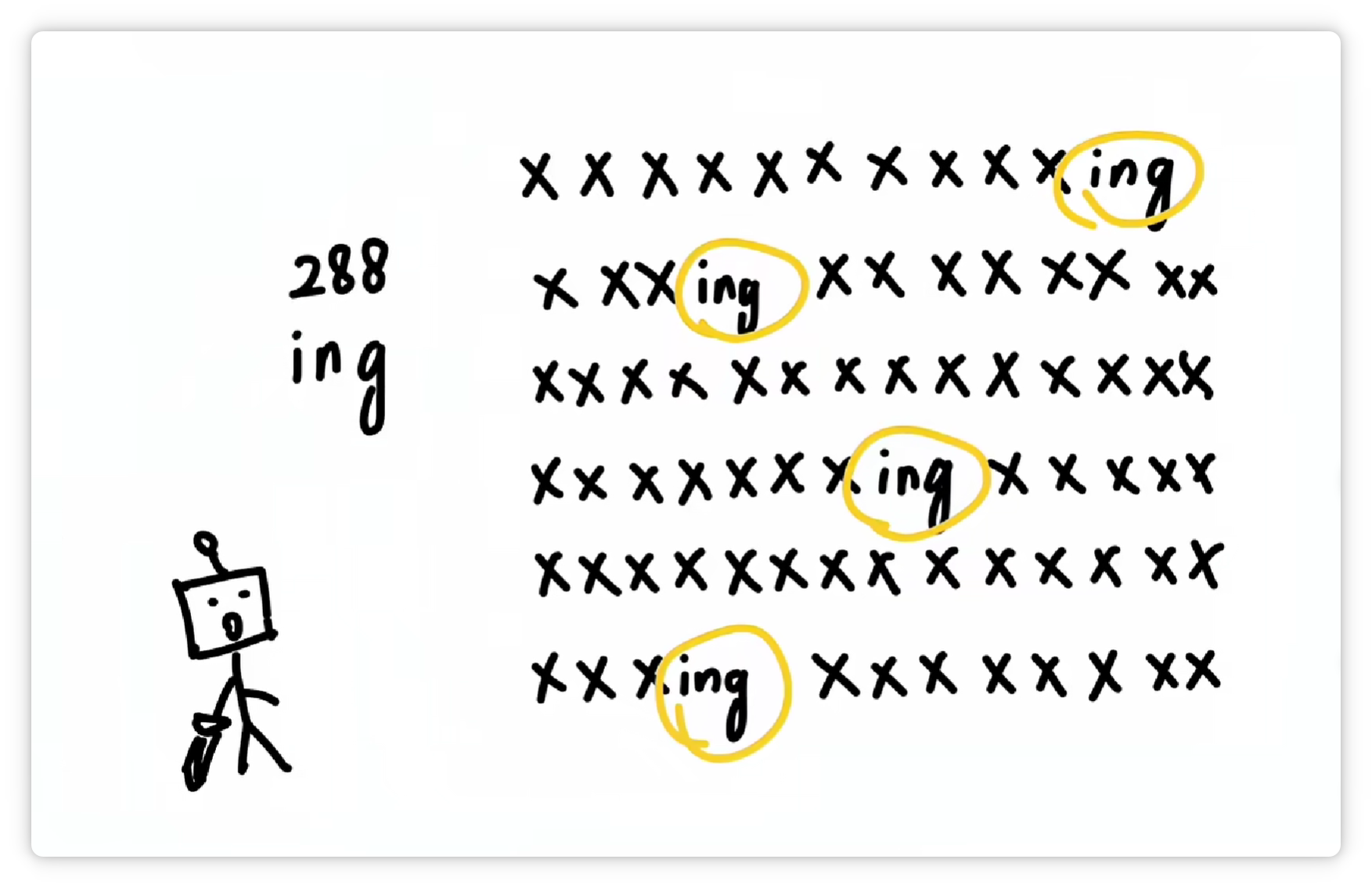
并且收录到词汇表里。

它又发现 “逗号” 经常出现。

于是又把 “逗号” 也打包作为一个 Token,给它配一个数字编号,比如 14。

收录到词汇表里。
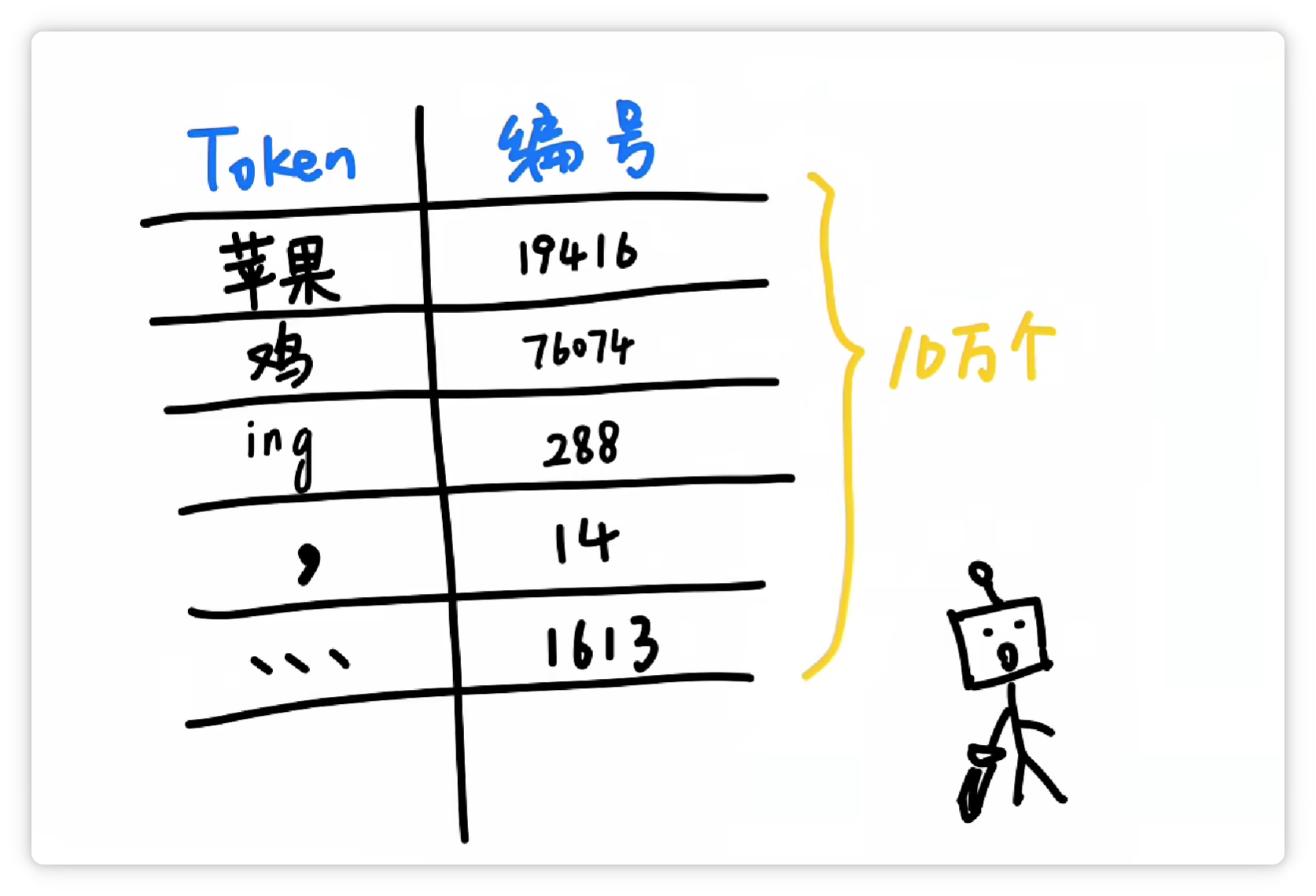
经过大量统计和收集,分词器就可以得到一个庞大的Token表。

可能有5万个、10万个,甚至更多Token,可以囊括我们日常见到的各种字、词、符号等等。
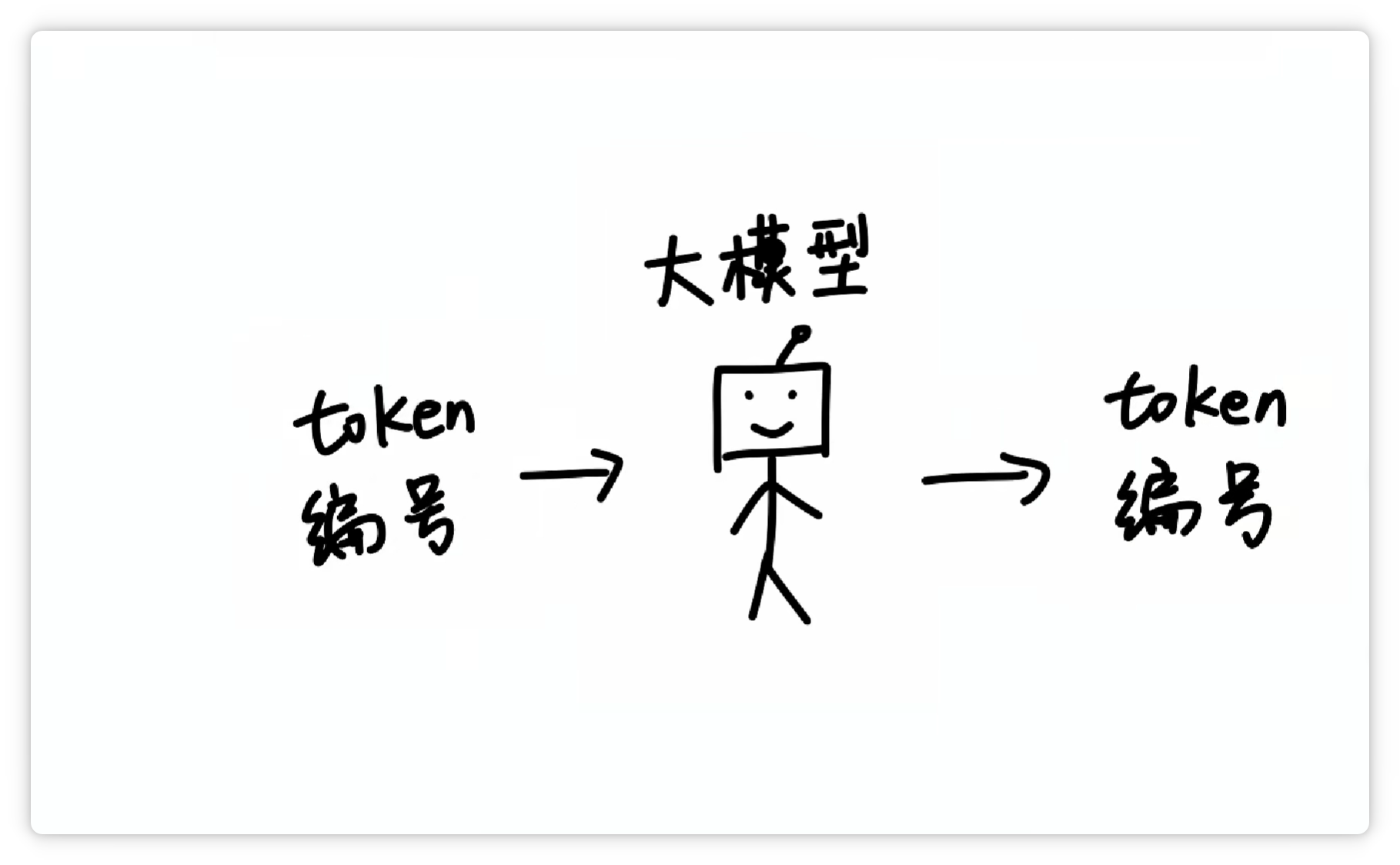
这样一来,大模型在输入和输出的时候,都只需要面对一堆数字编号就可以了。
再由分词器按照Token表,转换成人类可以看懂的文字和符号。
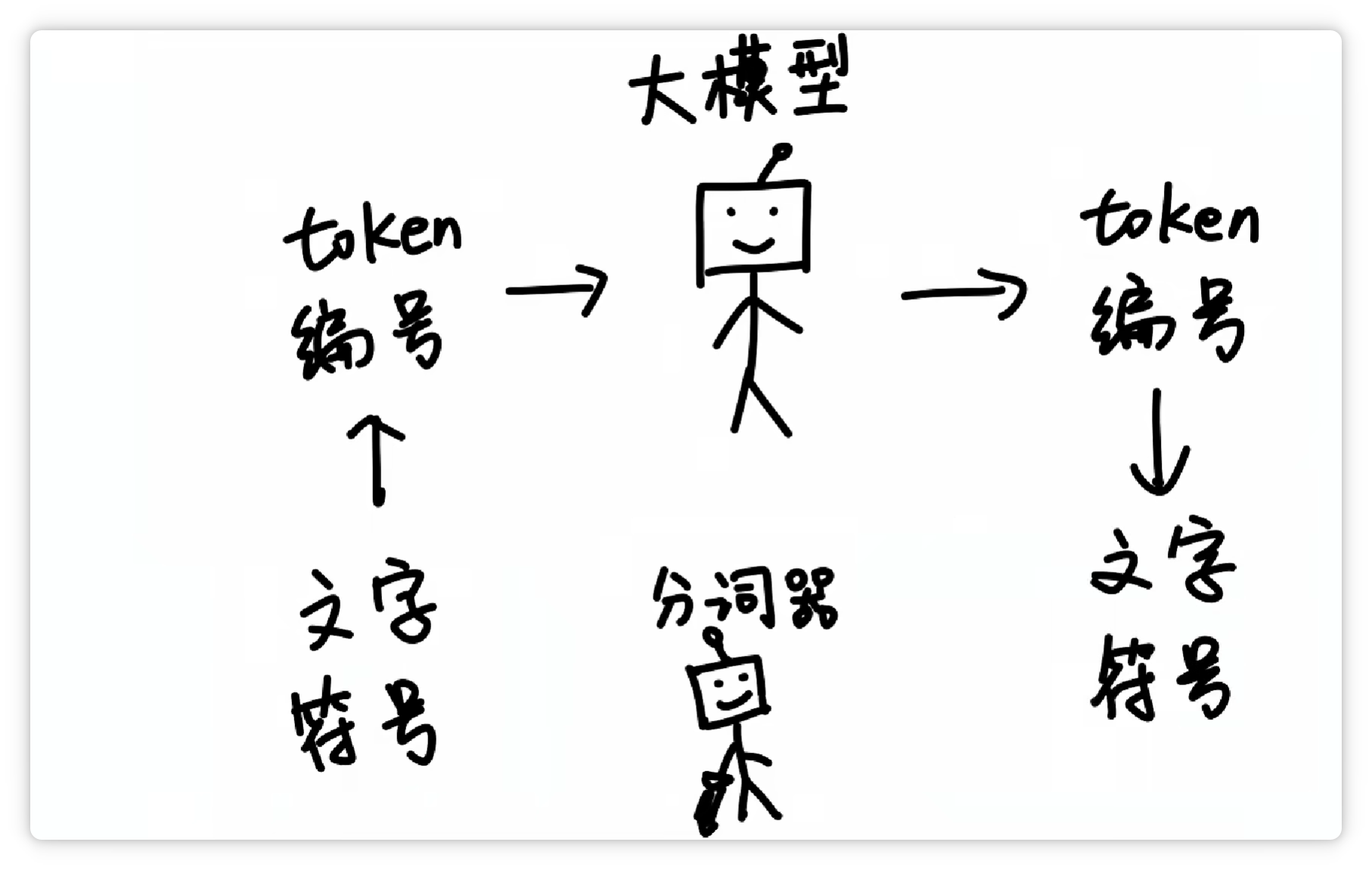
这样一分工,工作效率就非常高。
有这么一个网站 Tiktokenizer:https://tiktokenizer.vercel.app
输入一段话,它就可以告诉你,这段话是由几个Token构成的,分别是什么,以及这几个Token的编号分别是多少。
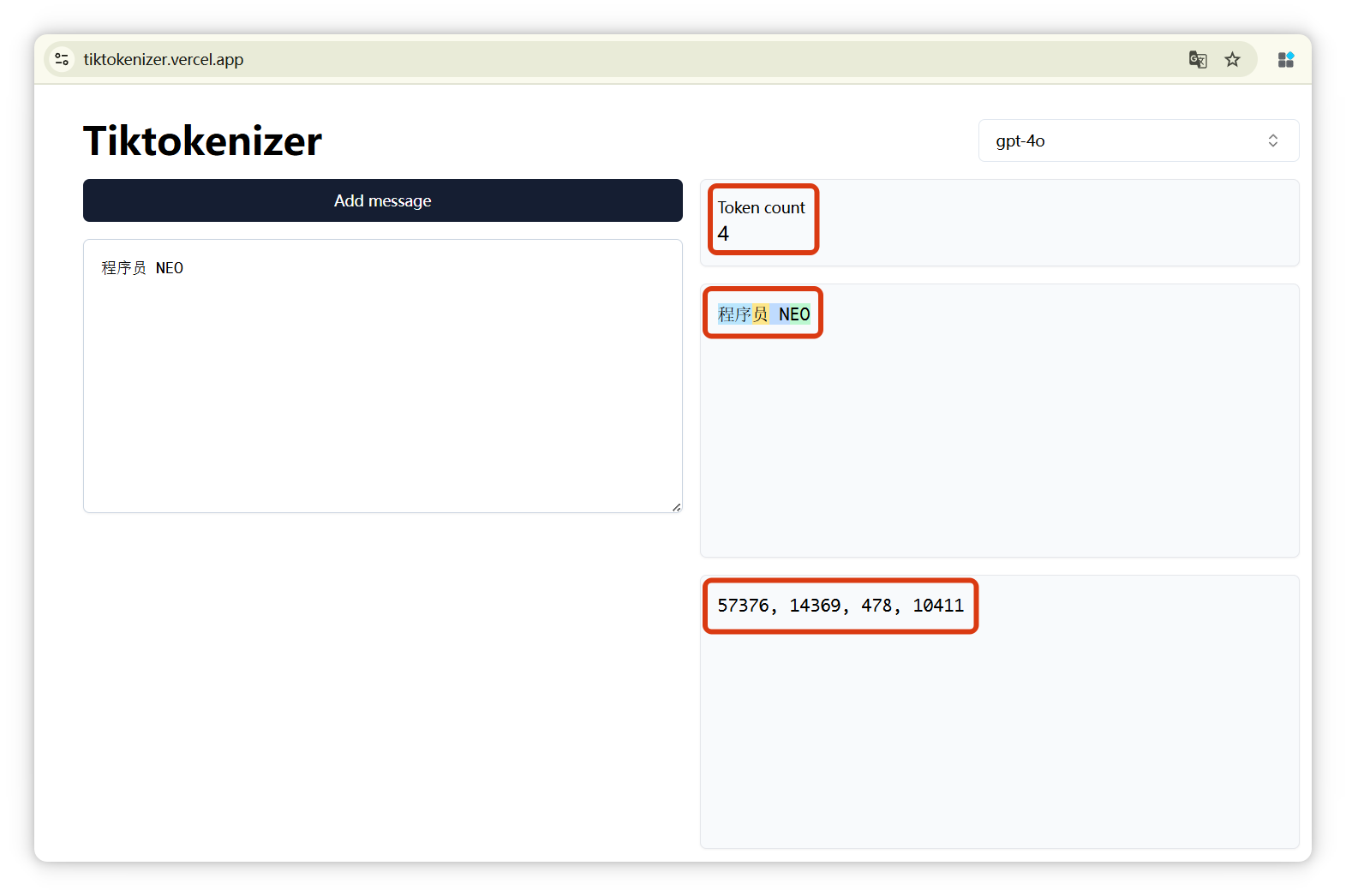
我来演示一下,这个网站有很多模型可以选择,像 GPT-4o、DeepSeek、LLaMA 等等。

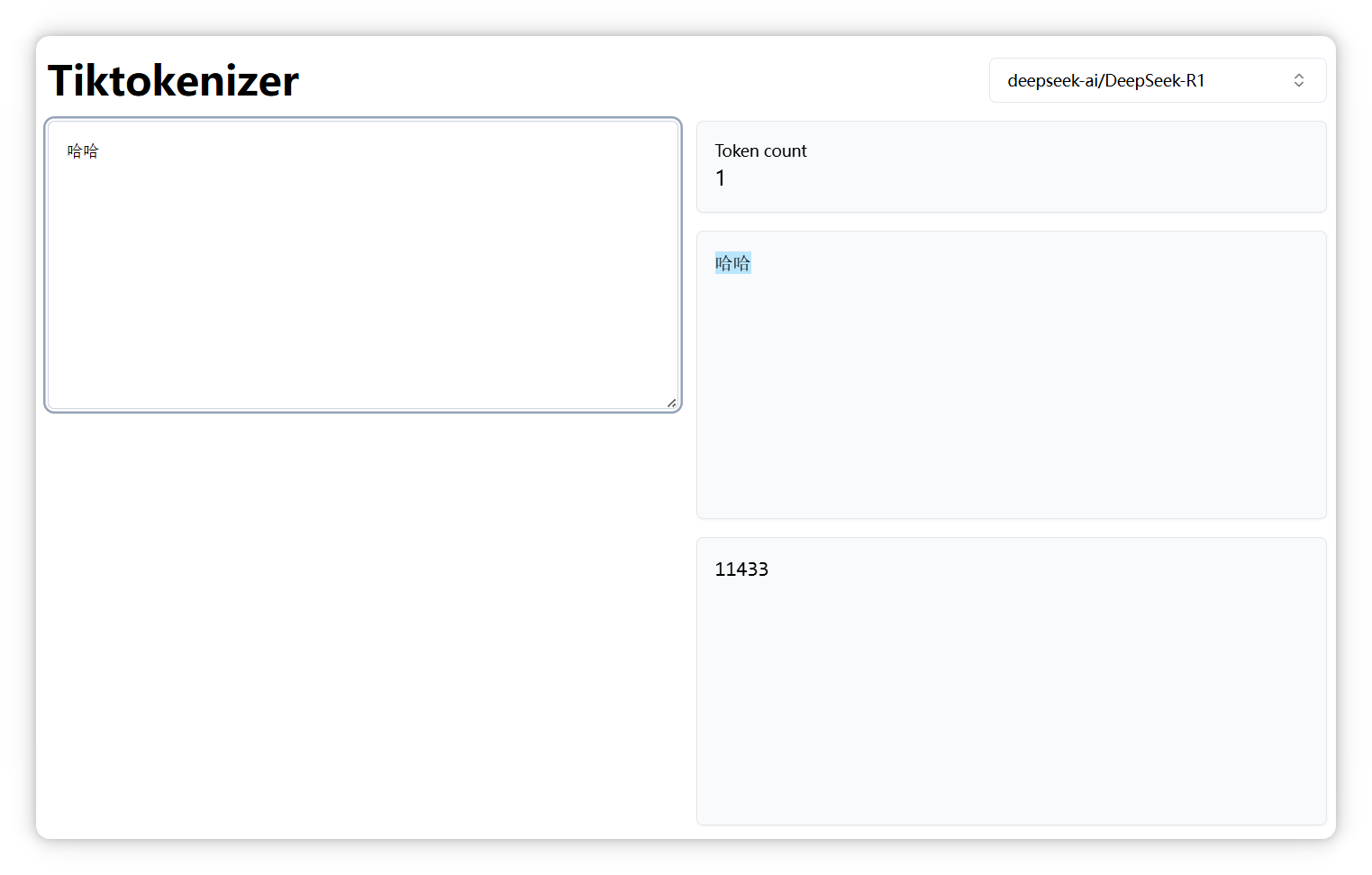
我选的是 DeepSeek,我输入 “哈哈”,显示是一个 Token,编号是 11433:
“哈哈哈”,也是一个 Token,编号是 40886:

4个 “哈”,还是一个 Token,编号是 59327:
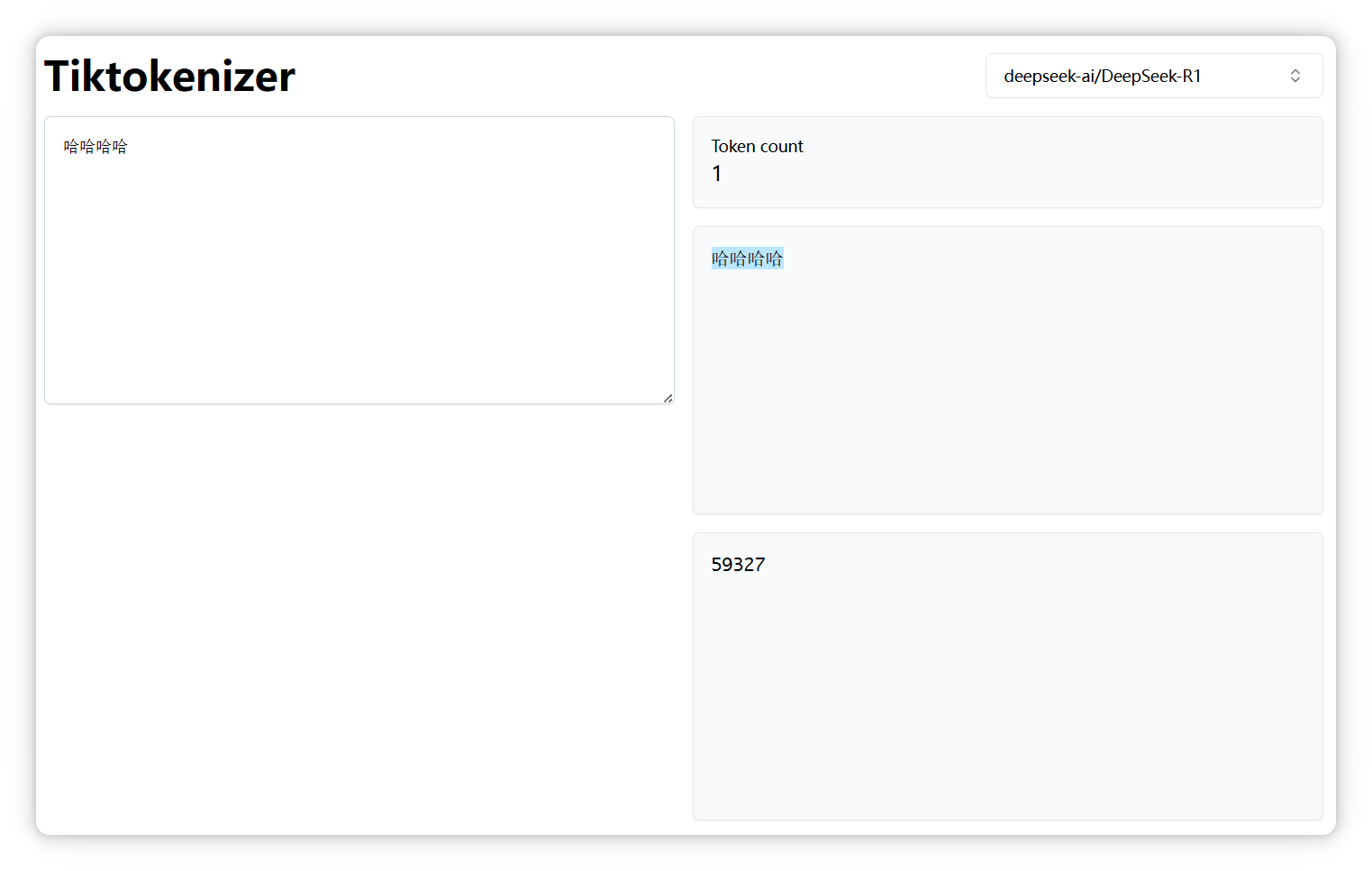
但是5个 “哈”,就变成了两个Token,编号分别是 11433, 40886:

说明大家平常用两个 “哈” 或者三个的更多。
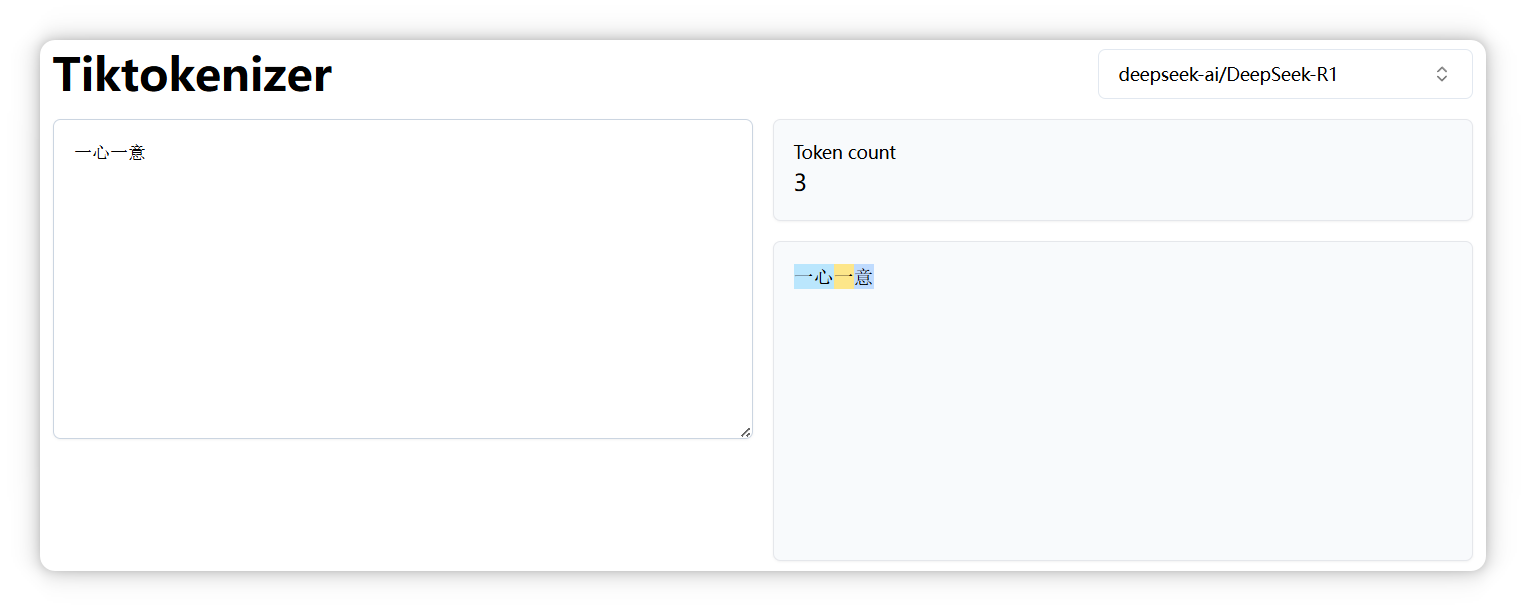
再来,“一心一意” 是三个 Token。
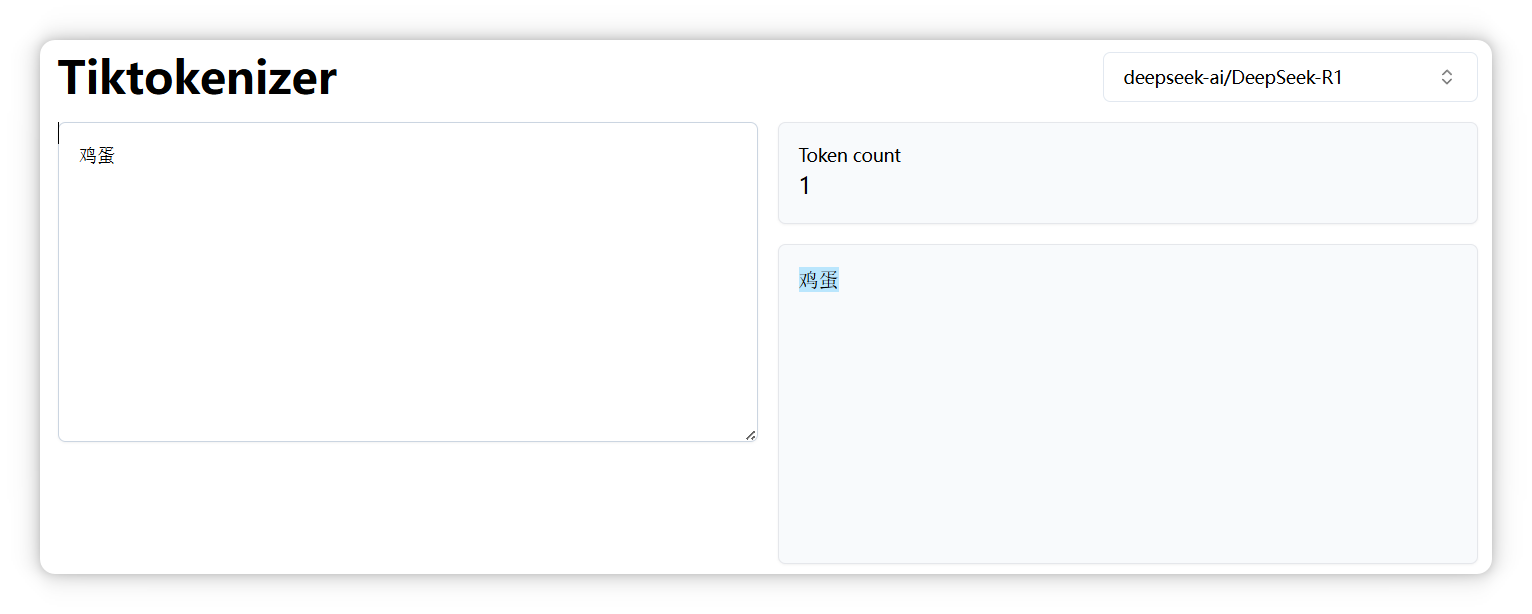
“鸡蛋” 是一个 Token。
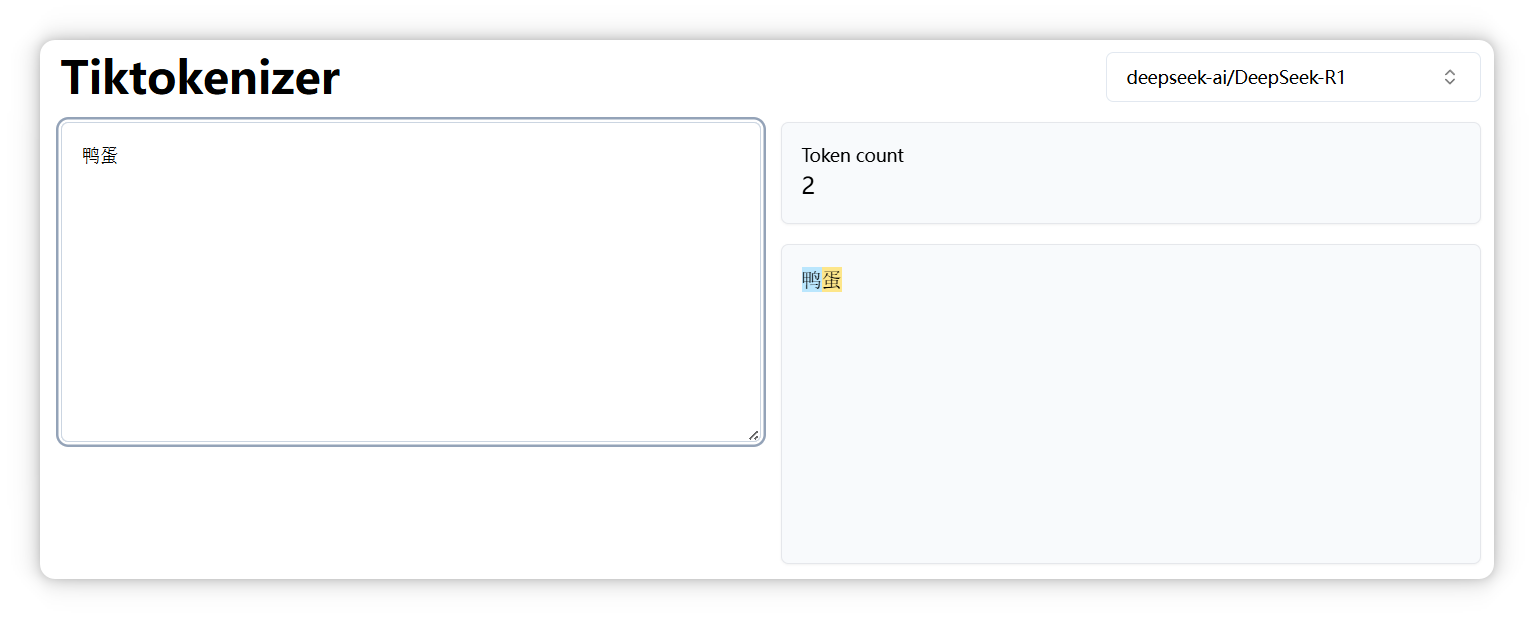
但是 “鸭蛋” 是两个 Token。
“关羽” 是一个 Token。
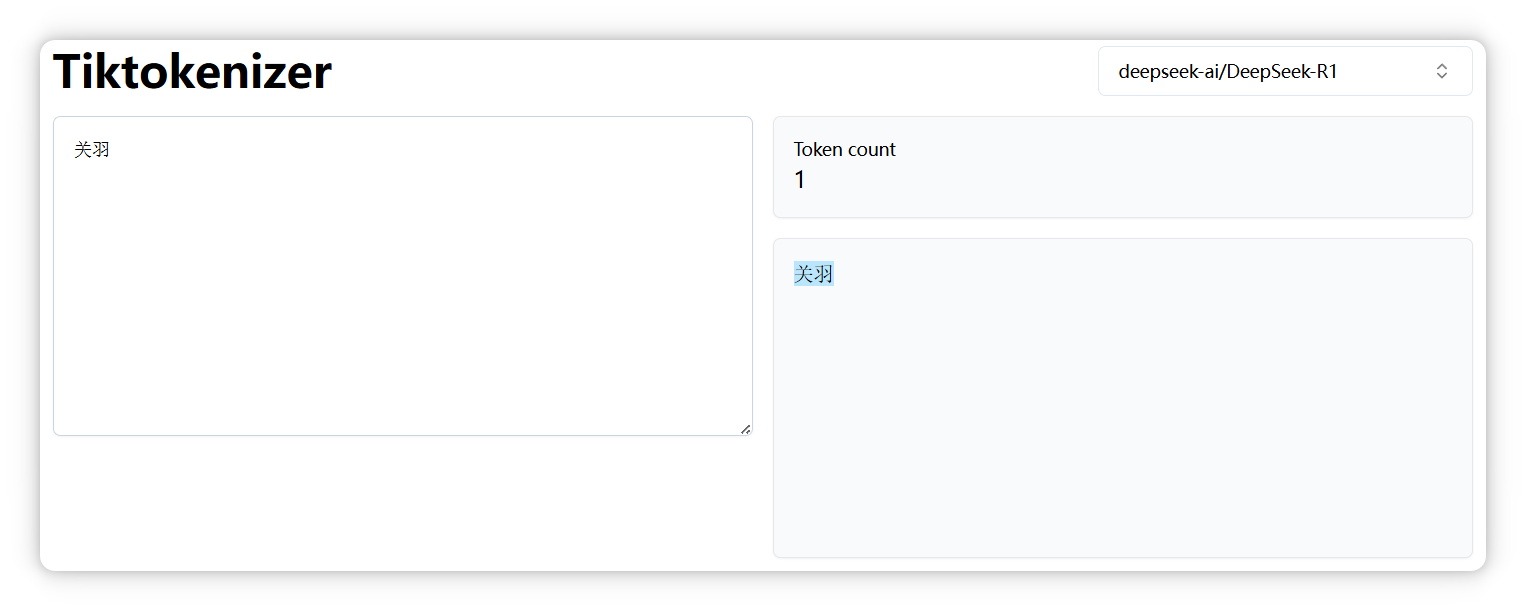
“张飞” 是两个 Token。
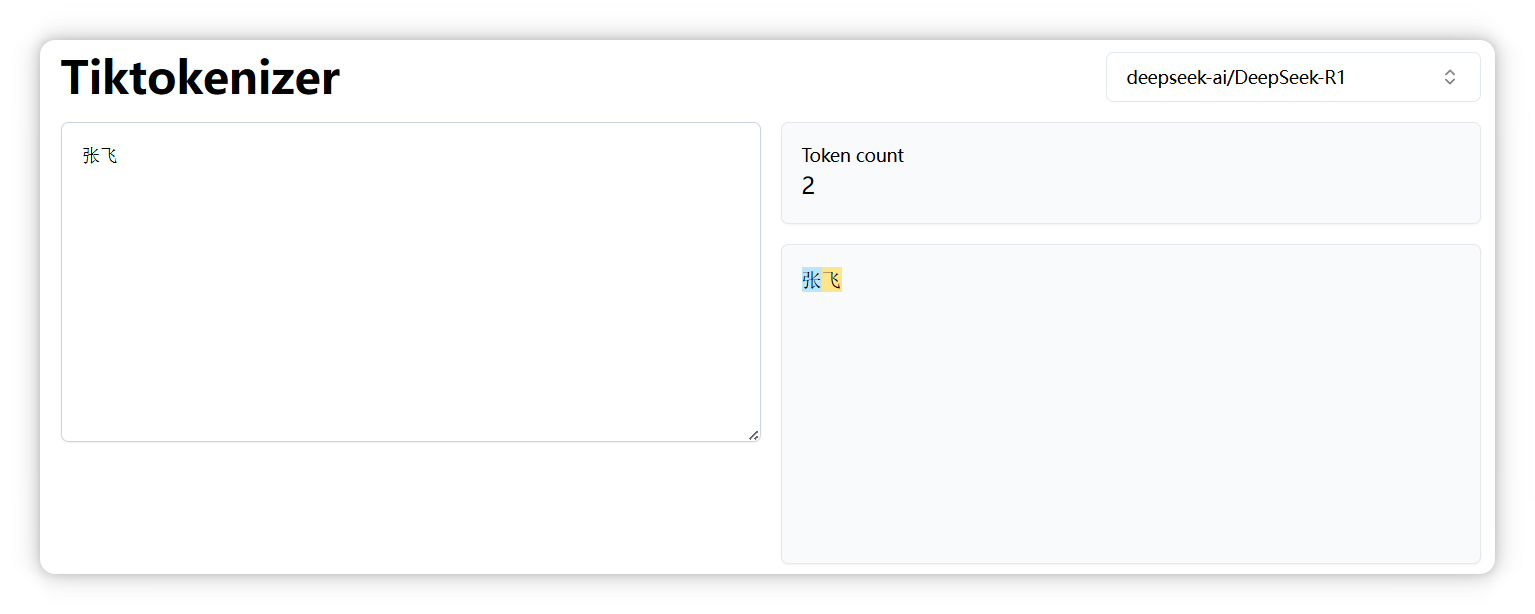
“孙悟空” 是一个 Token。
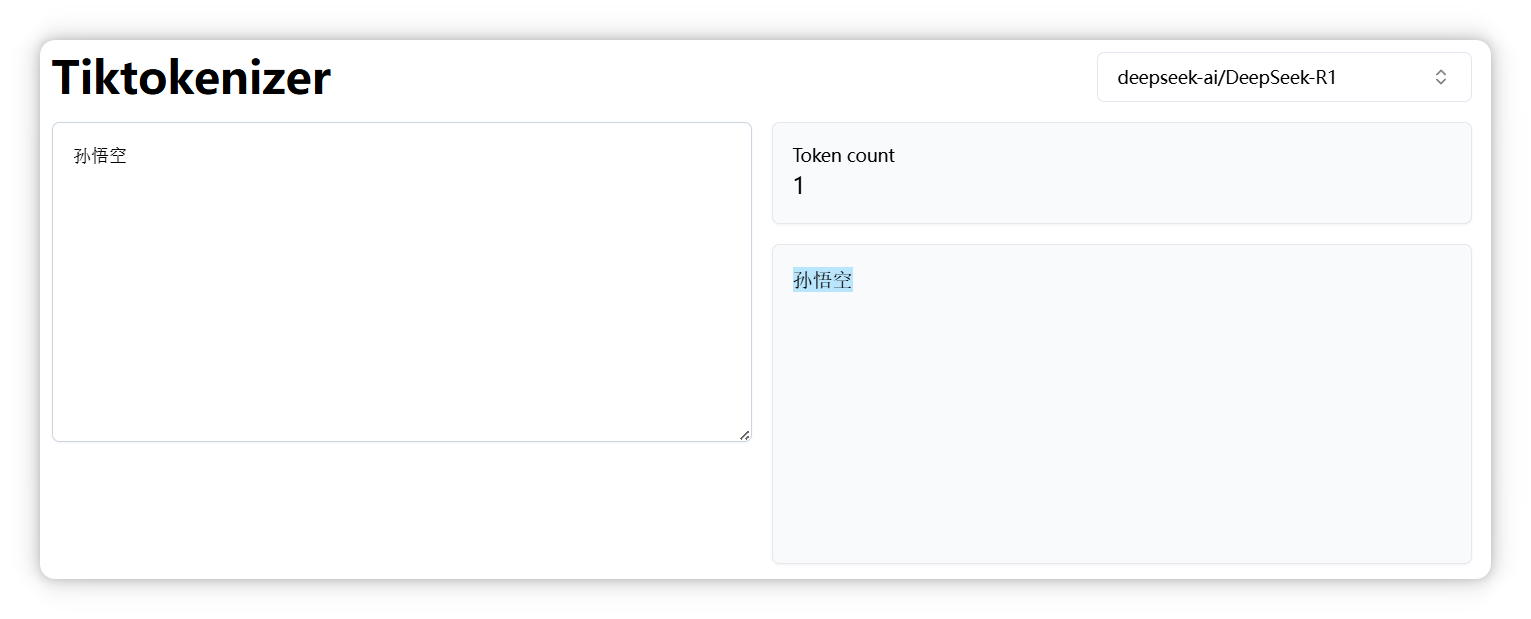
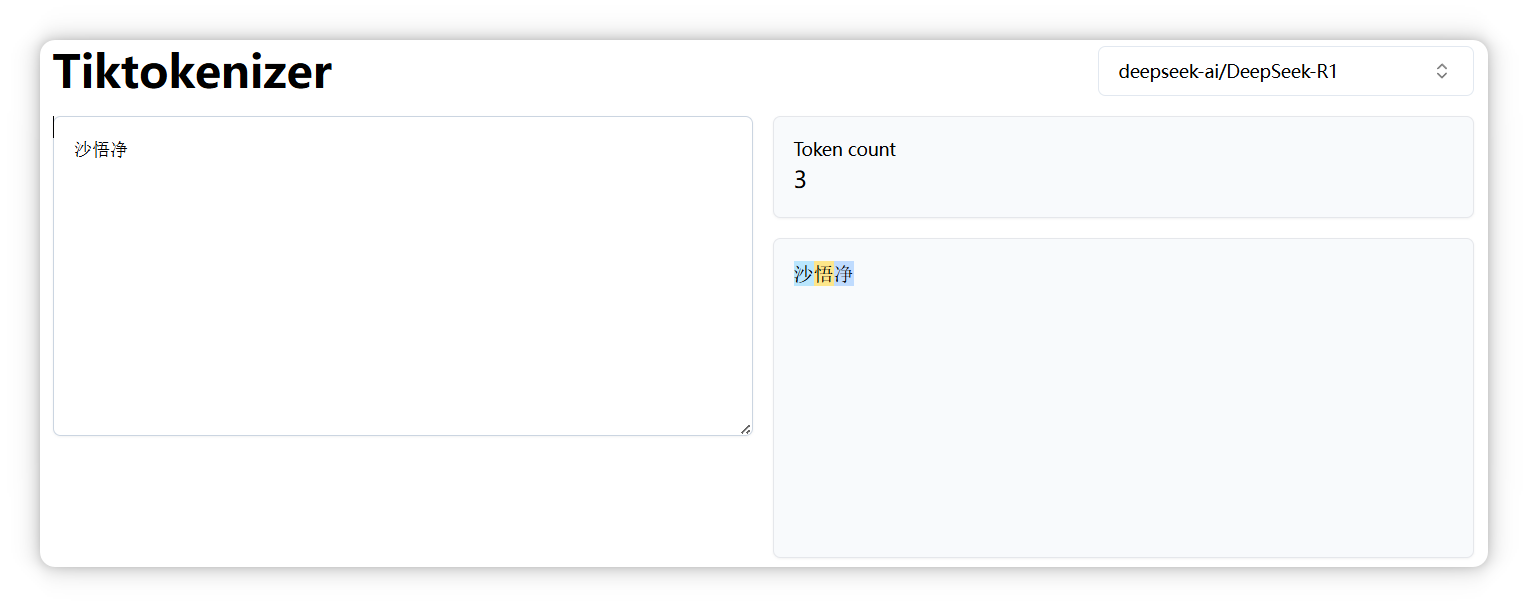
“沙悟净” 是三个 Token。
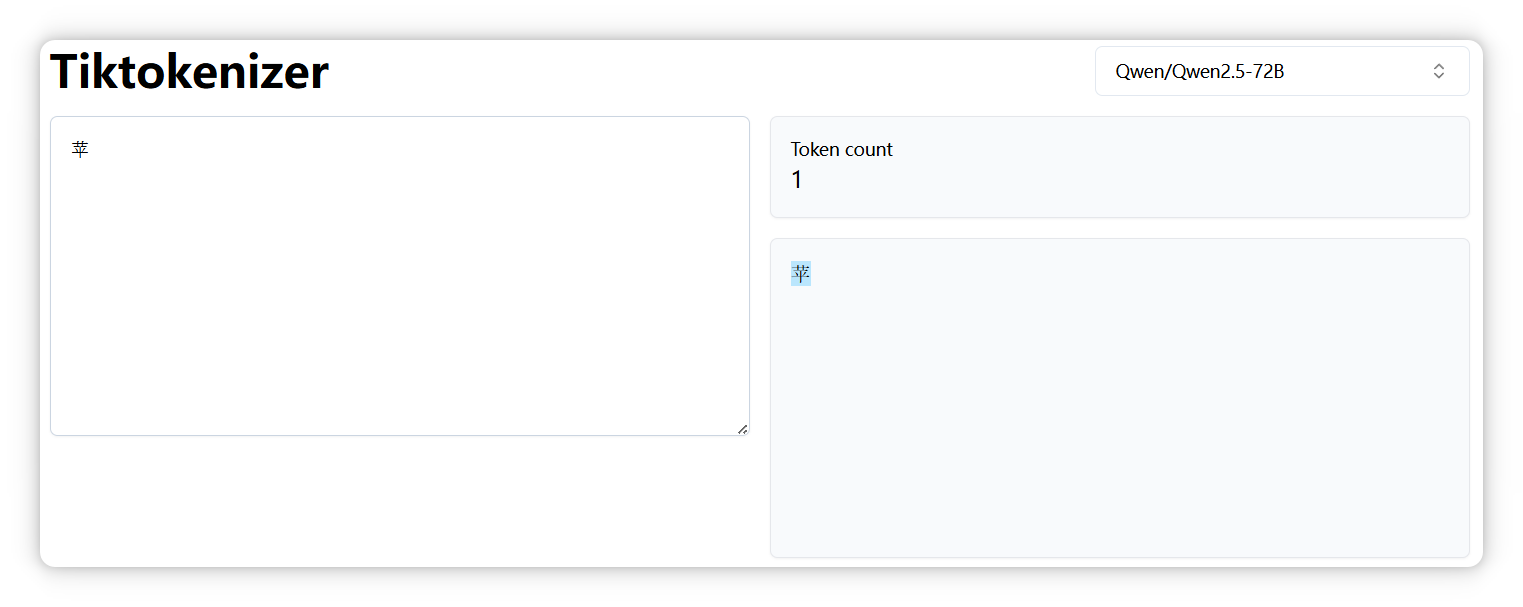
另外,正如前面提到的,不同模型的分词器可能会有不同的切分结果。比如,“苹果” 中的 “苹” 字,在 DeepSeek 中被拆分成两个 Token。
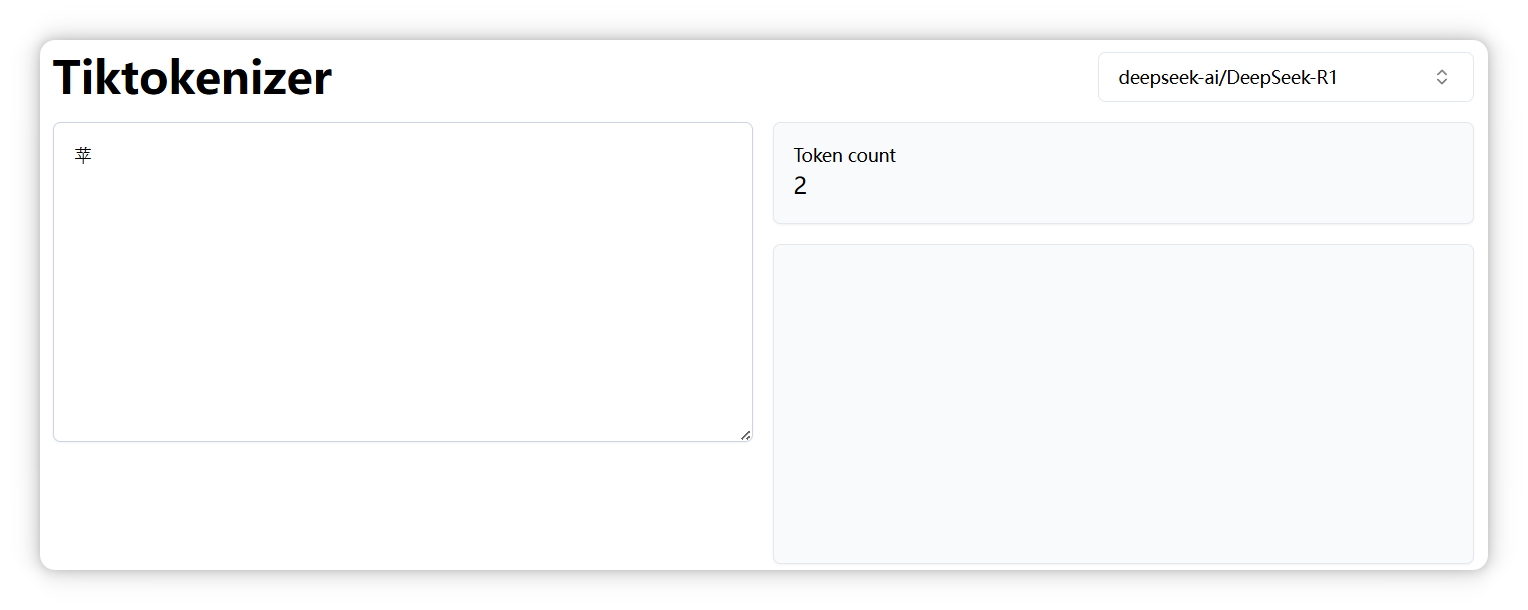
但是在 Qwen 模型里却是一个 Token。
所以回过头来看,Token 到底是什么?
它就是构建大模型世界的一块块积木。
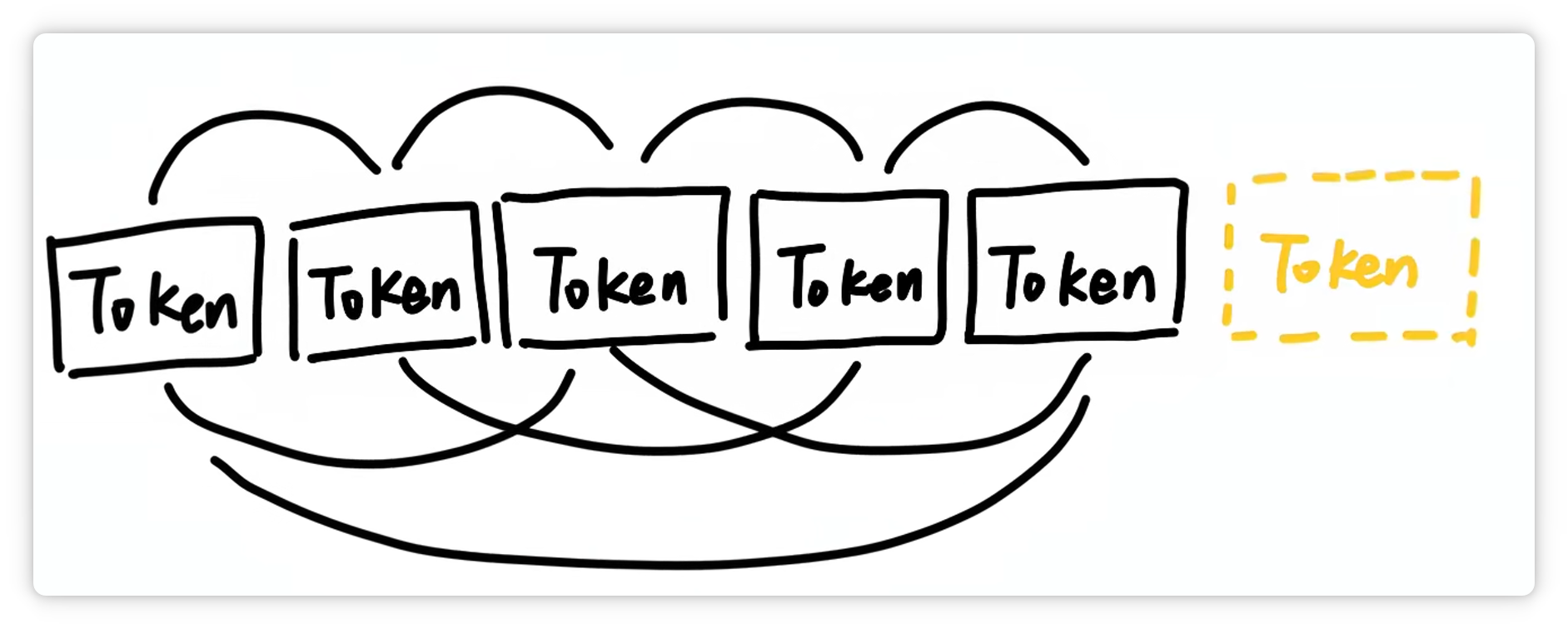
大模型之所以能理解和生成文本,就是通过计算这些 Token 之间的关系,来预测下一个最可能出现的 Token。
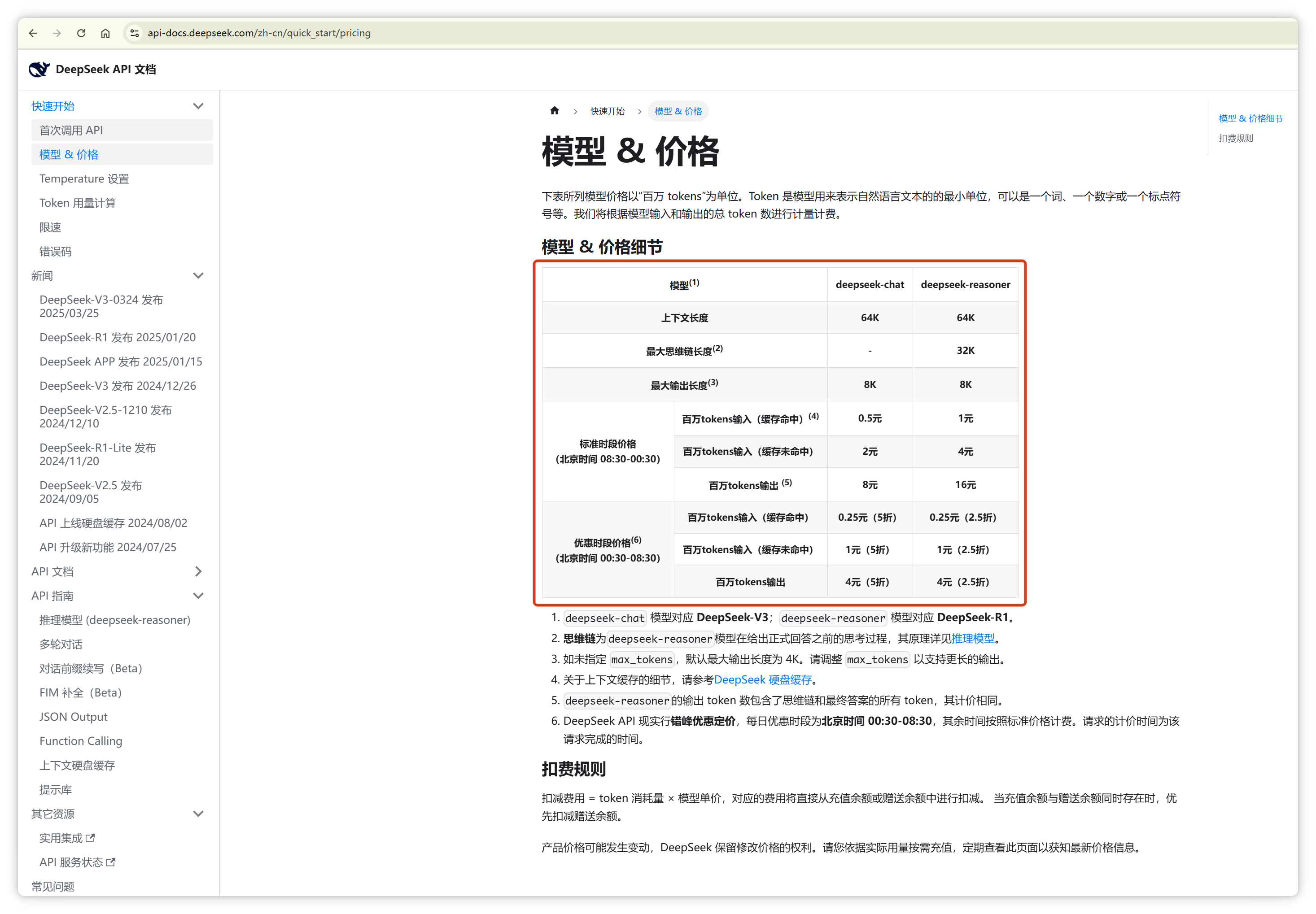
这就是为什么几乎所有大模型公司都按照 Token 数量计费,因为 Token 数量直接对应背后的计算成本。
“Token” 这个词不仅用于人工智能领域,在其他领域也经常出现。其实,它们只是恰好都叫这个名字而已。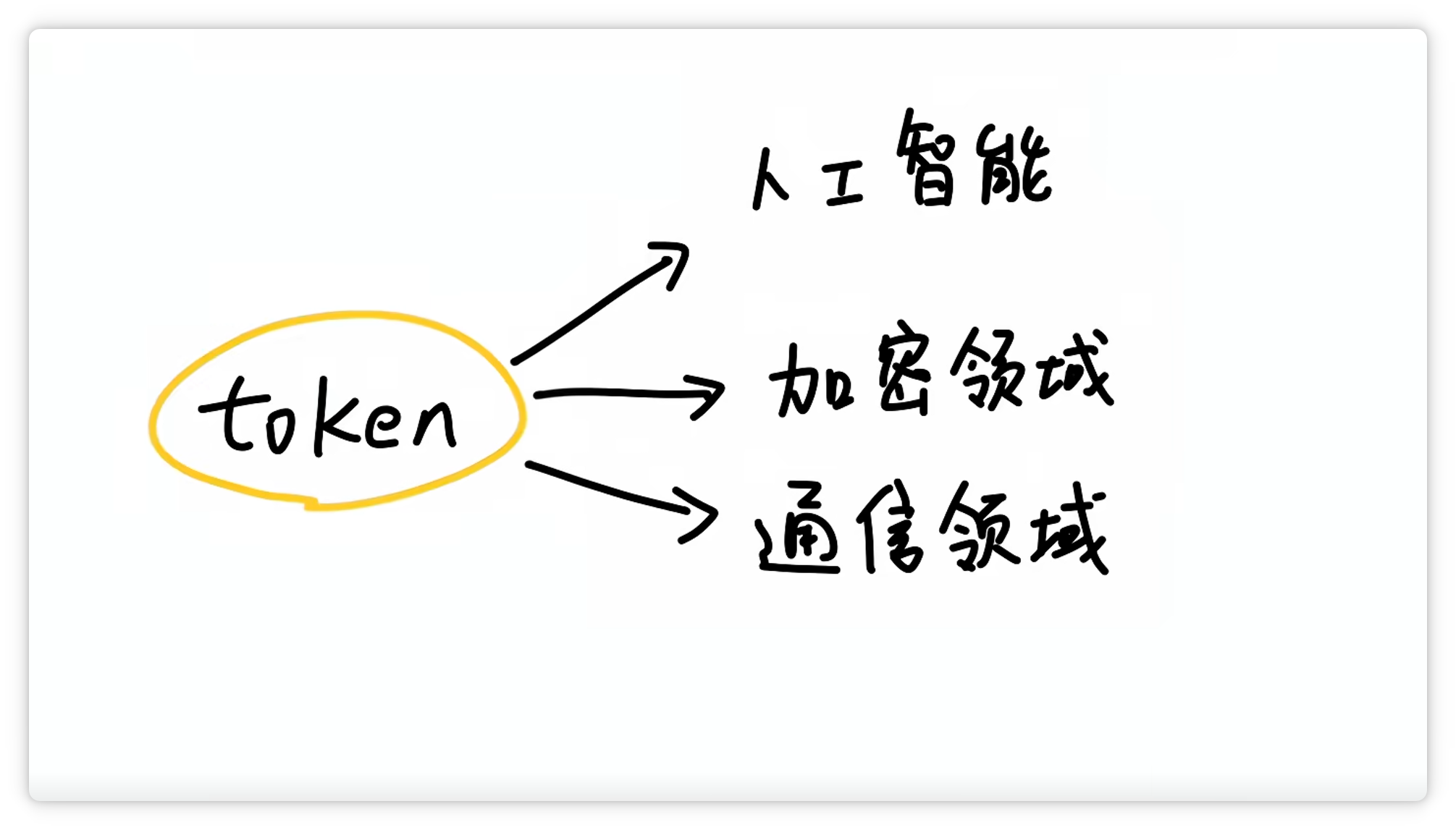
就像同样都是 “车模”,汽车模型和车展模特,虽然用词相同,但含义却截然不同。

FAQ
1. 苹为啥会是2个?
因为“苹” 字单独出现的概率太低,无法独立成为一个 Token。
2. 为什么张飞算两个 Token?
“张” 和 “飞” 一起出现的频率不够高,或者“ 张” 字和 “飞” 字的搭配不够稳定,经常与其他字组合,因此被拆分为两个 Token。
Token 在大模型方面最好的翻译是 '词元' 非常的信雅达。
欢迎关注我的微信公众号【程序员 NEO】!
这里有丰富的技术分享、实用的编程技巧、深度解析微服务架构,还有更多精彩内容等你探索!🚀