1.HBase的特点
HBase是一个数据库,与RDMS相比,有以下特点:
① 它不支持SQL
② 不支持事务
③ 没有表关系,不支持JOIN
④ 有列族,列族下可以有上百个列
⑤ 单元格,即列值,可以存储多个版本的值,每个版本都有对应时间戳
⑥ 行键按照字典序升序排列
⑦ 元数据 和 数据 分开存储
- 元数据存储在zookeeper
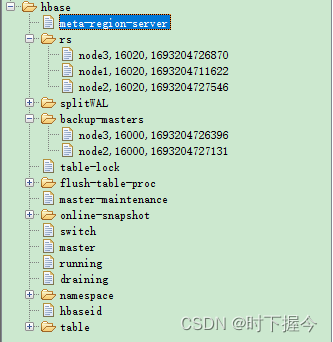
- 数据存储在HDFS,具体路径在hbase-site.xml指定

⑧ HBase的吞吐量不如HDFS,但具备HDFS不具备的随机读写,HDFS只支持顺序读写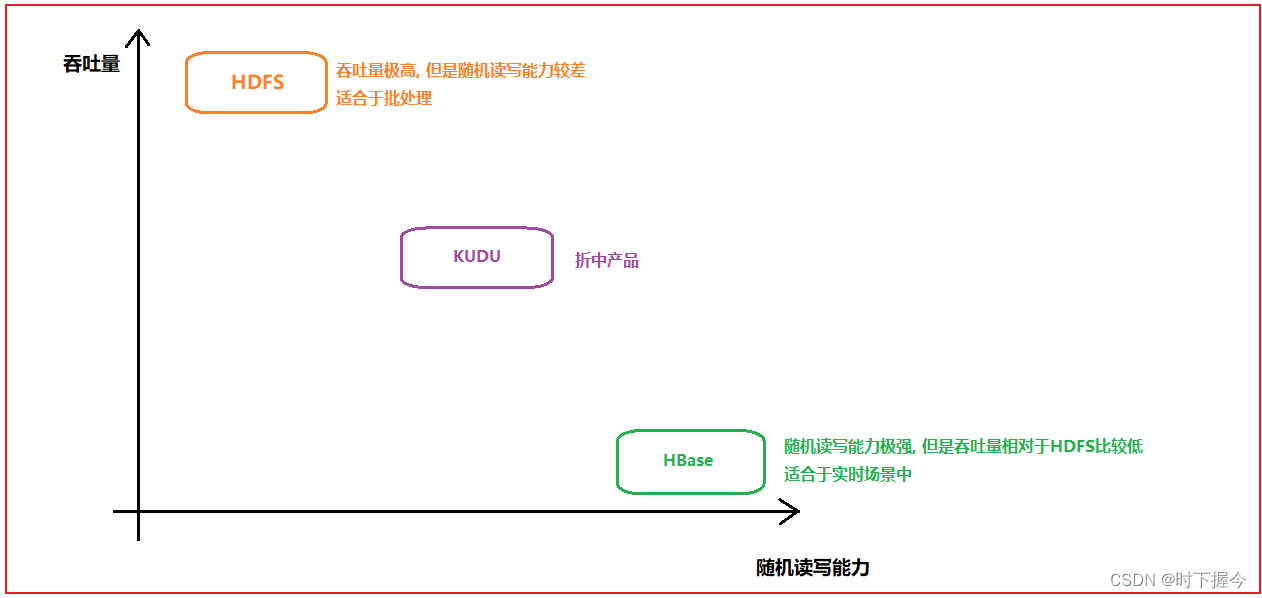
⑨ HBase以字节的形式存储数据,Null值不占用存储空间,支持稀疏存储
2.HBase表模型
表创建好之后,默认有一个分区,能存储10G大小的数据,随着数据量的不断增加,分区会按照rowkey分离,一个数据范围内的行数据分配到不同Region
不过,在创建表时,可以预先设置几个分区(预分区),每个分区指定rowkey范围,这样数据写入时,会写到不同Region
2.1 rowkey的设计原则
rowkey按照字典序升序在表中存储,若rowkey具有相同前缀,则数据可能在同一个rowkey范围内,会将数据存储在同一个Region,造成其它Region空闲。rowkey的设计主要是打乱rowkey的顺序,使rowkey分布在不同Region。
建议rowkey设计时:
①加盐:每个rowkey的前缀加上一个随机数
②反转:手机号、身份证号、时间戳反转
③HASH:MD5Hash方案生成rowkey
①和②能保证数据落在不同Region,但数据的相关性不能保证。③能保证相关性数据放到一起,相关性数据比较多的时候,依然导致数据分配到同一个分区
2.2 列族的设计原则
一个表有多个列族的话,一行数据会写入多处memstore、多处storefile。增加了IO写入次数和读取次数。一行数据的一个memstore触发溢写,该行数据的其它menstore也会同时触发溢写,增加了小文件的数量。
建议列族越少越好。
① 热点数据 和 冷备数据分两个列族存储
② 对接不同业务,建立对应业务的列族
2.3 名称空间的设计原则
名称空间类似于RDMS中的库,便于管理维护工作,使业务划分更加明确,权限管理能够细致
default:默认的名称空间, 在创建表的时候, 如果不指定名称空间, 默认就会将表创建在这个default名称空间下,类似于在HIVE中有一个default库
hbase:hbase专门用于放置hbase系统表,meta 表就是存储在这个名称空间下
3. 架构模型
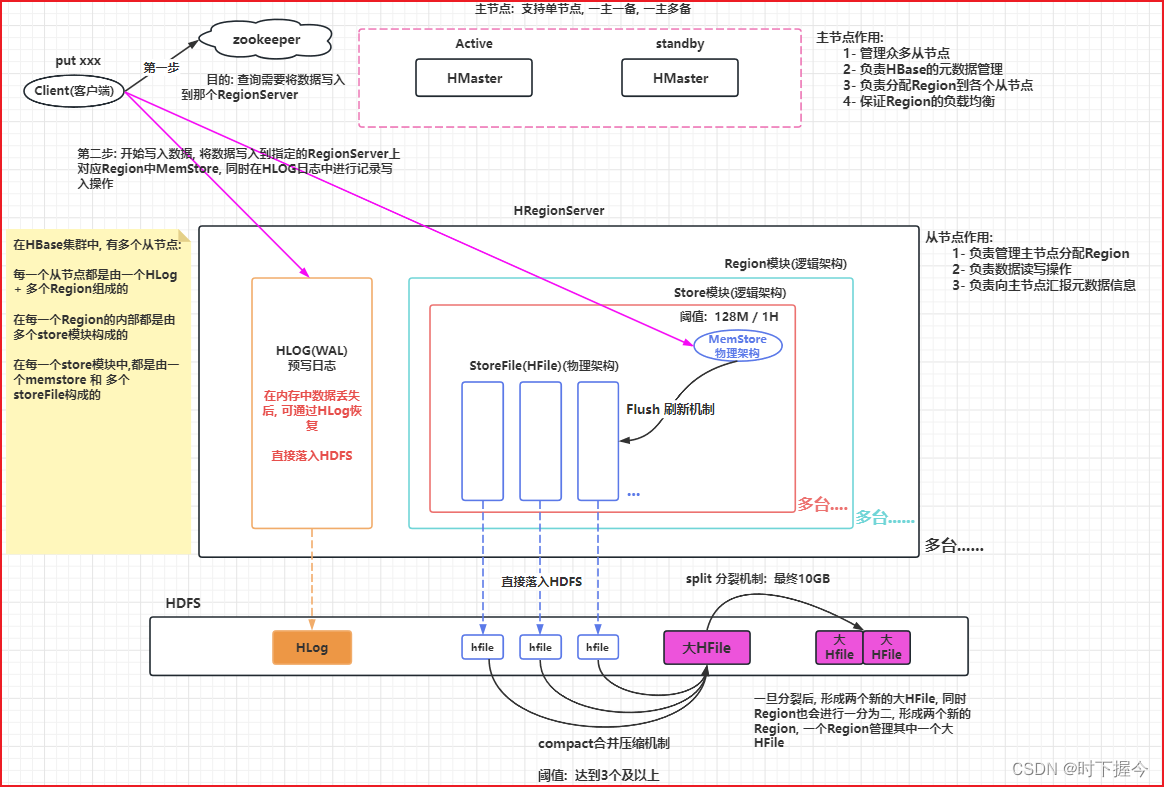
① HMaster
主节点,支持单节点、主从、主备主从架构、HMaster的高可用需要zookeeper参与。
② HRegionServer
从节点,负责管理主节点分配的Region,一个HRegionServer可以管理多个Region,但一个Region只能被一个HRegionServer管理
③ Region
逻辑上,HBase基于rowkey将一个表水平划分成多个Region,默认一个表只有一个Region,随着写入数据的增多,Region会分裂
④ Store
逻辑上,一个列族就是一个Store模块,一个Store模块由一个memStore和多个StoreFile构成
3.1 读数据流程
① 客户端发起读取数据的请求,首先连接zk集群,从zk中查询hbase:meta表,得到管理hbase元数据的Master结点地址
② 客户端连接Master结点,检索habse:meta表,得到客户端端要读的表的Region及管理Region的HRegionServer结点
说明: hbase:meta 是HBase专门用于存储元数据的表, 此表只会有一个Region, 也就说这个表只会被一个Region所管理, 一个Region也只能被一个RegionServer所管理
③ 客户端根据rowkey确定Region,连接管理该Region的HRegionServer,从Region中读取数据
如果执行scan, 返回这个表所有Region对应的RegionServer的地址
如果执行get, 返回查询rowkey所对应Region所在RegionServer的地址
读取顺序: 先内存 --> blockCache(块缓存) —> storeFile —> 大HFile
3.2 写数据流程
① 由客户端发起写入数据的请求, 首先 先连接zookeeper集群
② 从zookeeper集群中获取hbase:meta 表被那个RegionServer所管理
③ 连接对应RegionServer, 从meta表获取要写入数据的表的Region, 然后根据Region的startRow和endRow, 判断要写入数据的Region, 并确定管理该Region的HRegionServer
④连接对应RegionServer,开始进行数据写入操作, 写入时需要将数据写入到对应的Store模块下的MemStore中(可能写入多个MemStore),同时也会将本次写入操作记录在对应RegionServer的HLog中, 这个两个位置都写入完成后, 客户端写入完成
⑤ 随着客户端不断的写入操作, MemStore中数据会越来越多, 当MemStore的数据达到一定的阈值(128M/1H)后,就会启动Flush 刷新线程, 将内存中数据 “最终” 刷新到HDFS上,形成一个StoreFile文件
⑥ 随着不断地Flush的刷新, 在HDFS上StoreFile文件会越来越多, 当StoreFile文件达到一定的阈值(3个及以上)后, 就会启动compact合并压缩机制, 将多个StoreFile “最终” 合并为一个大的HFile
⑦ 随着不断的合并, HFile文件会越来越大,当这个大的HFile文件达到一定的阈值( “最终” 10GB)后,就会触发Split的分裂机制, 将大的HFile进行一分为二操作, 形成两个新的大HFile文件, 此时Region也会进行一分为二操作, 形成两个新的Region, 一个Region管理一个新的大HFile, 旧的大HFile和对应Region就会下线删除
4.写数据流程中的核心工作机制
4.1 刷新机制
memstore溢写storeFile的触发条件:
hbase.hregion.memstore.flush.size: 134217728 (128M)
hbase.regionserver.optionallogflushinterval : 3600000 (1h)
128M(Region级别) / 1H(RegionServer级别) 满足其一,即可触发Flush刷新机制
① 客户端不断向MemStore中写入数据, 当MemStore中数据达到阈值后, 就会启动Flush刷新操作
② 首先HBase会先关闭当前这个已经达到阈值的内存空间, 然后开启一个新的MemStore的空间, 继续写入
③ 将这个达到阈值的内存空间数据放入到内存队列中, 此队列的特性是只读的, 在HBase的2.x版本中, 可以设置此队列尽可能晚的刷新到HDFS中,当这个队列中数据达到某个阈值后(内存不足),这个时候触发Flush刷新操作(希望队列中尽可能多的memstore的数据, 让更多的数据存储在内存中)
④ Flush线程会将队列中所有的数据 全部都读取 出来, 然后对数据进行 排序合并 操作, 将合并后数据存储到HDFS中, 形成一个StoreFile的文件
HBase的2.x版本支持了推迟刷新, 合并刷新策略
hbase.systemtables.compacting.memstore.type:
NONE | BASIC | EAGER
basic(基础型): 直接将多个MemStore数据合并为一个StoreFile. 写入到HDFS上, 如果数据中存在过期的数据,或者已经标记为删除的数据, 基础型不做任何处理
eager(饥渴型): 在将多个memstore合并的过程中, 积极判断数据是否存在过期, 或者是否已经被标记删除了, 如果有, 直接过滤掉这些标记删除或者已经过期的数据
adaptive(适应性): 检测数据是否有过期的内容, 如果过期数据比较多的时候, 就会自动选择饥渴型,否则就是基础型
4.2 合并机制
storefile触发compact合并压缩机制,合并成一个HFile的条件:
整个Compact合并压缩机制分为二大阶段:
minor阶段
hbase.hstore.compaction.min: 3 (3个及以上)
将多个StoreFile合并为一个较大的HFile文件, 对数据进行排序操作, 如果此时有过期或者有标记删除的数据, 此时不做任何处理的(类似于: 内存合并中基础型合并方案)
major阶段
hbase.hregion.majorcompaction: 604800000 (7天)
将较大的HFile 和 之前的大HFile进行合并, 形成一个更大的HFile文件 (全局合并)。
合并过程中, 会将那些过期的数据或者已经标记删除的数据删除掉
4.3 分裂机制
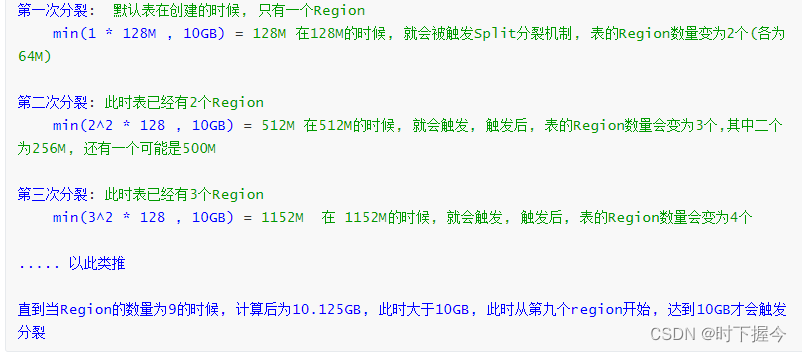
HFile达到一定阈值, 触发Split分裂机制的条件:
hbase.hregion.max.filesize: 10737418240 (10G)
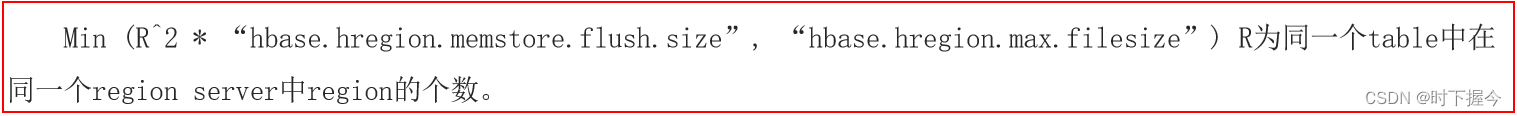
上述公式, 其实就是HBase用于计算在何时进行分裂
相关的变量说明:
R:表对应的Region的数量
hbase.hregion.memstore.flush.size : 默认为128M
hbase.hregion.max.filesize: 默认 10GB
 由于表一开始默认只有一个Region, 被一个HRegionServer管理, 如果此时这个表有大量的数据写入和数据读取操作, 这些请求全部负载到同一个HRegionServer, 这个HRegionServer可能负载过重 直接宕机。
由于表一开始默认只有一个Region, 被一个HRegionServer管理, 如果此时这个表有大量的数据写入和数据读取操作, 这些请求全部负载到同一个HRegionServer, 这个HRegionServer可能负载过重 直接宕机。
一旦宕机, 对应的Region就会被HMaster分配给其他的HRegionServer, 然后其他的RegionServer也会跟着一起宕机, 最终导致整个HBase集群从节点全部宕机(雪崩问题)
通过Region分离或预分区策略, HMaster就可以将Region分布给不同的HRegionServer, 大量的并发, 由多个HRegionServer共同负载