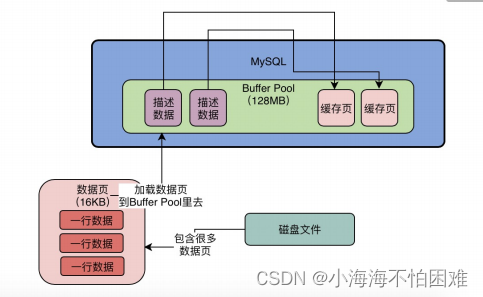
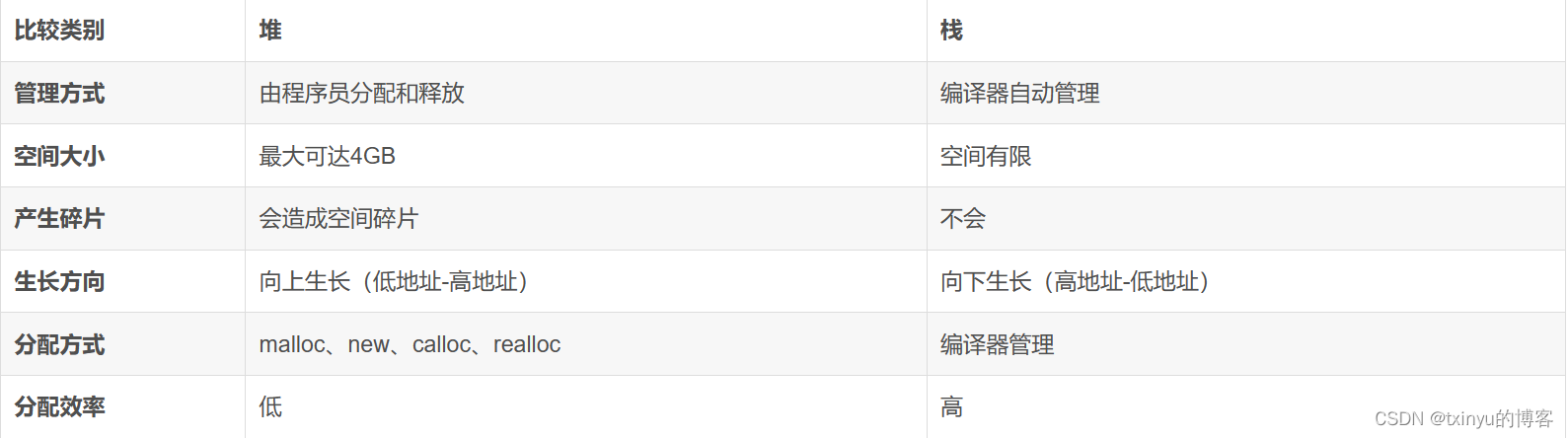
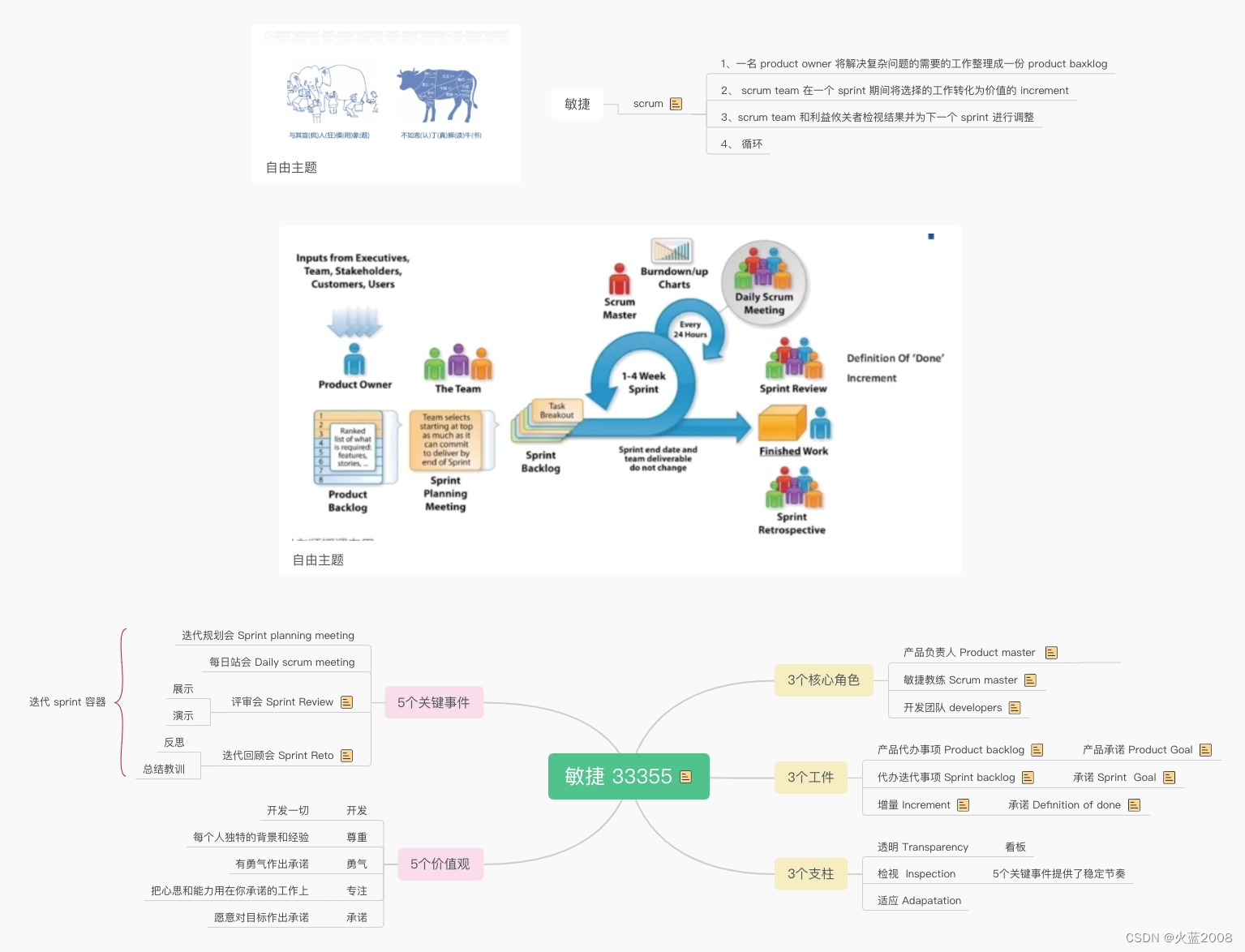
文章目录
- openGauss学习笔记-50 openGauss 高级特性-DB4AI
- 50.1 关键字解析
- 50.2 使用指导
openGauss学习笔记-50 openGauss 高级特性-DB4AI
openGauss当前版本支持了原生DB4AI能力,通过引入原生AI算子,简化操作流程,充分利用数据库优化器、执行器的优化与执行能力,获得高性能的数据库内模型训练能力。更简化的模型训练与预测流程、更高的性能表现,让开发者在更短时间内能更专注于模型的调优与数据分析上,而避免了碎片化的技术栈与冗余的代码实现。
当前版本的DB4AI支持基于SGD算子的逻辑回归(目前支持二分类任务)、线性回归和支持向量机算法(分类任务),以及基于K-Means算子的Kmeans聚类算法。
50.1 关键字解析
表 1 DB4AI语法及关键字
| 名称 | 描述 | |
|---|---|---|
| 语句 | CREATE MODEL | 创建模型并进行训练,同时保存模型。 |
| PREDICT BY | 利用已有模型进行推断。 | |
| 关键字 | TARGET | 训练/推断任务的目标列名。 |
| FEATURES | 训练/推断任务的数据特征列名。 | |
| MODEL | 训练任务的模型名称。 |
50.2 使用指导
-
使用“CREATE MODEL”语句可以进行模型的创建和训练。
模型训练SQL语句,现有一个数据集为kmeans_2d,该表的数据内容如下:
openGauss=# select * from kmeans_2d;id | position ----+-------------------------------------1 | {74.5268815685995,88.2141939294524}2 | {70.9565760521218,98.8114827475511}3 | {76.2756086327136,23.8387574302033}4 | {17.8495847294107,81.8449544720352}5 | {81.2175785354339,57.1677675866522}6 | {53.97752255667,49.3158342130482}7 | {93.2475341879763,86.934042100329}8 | {72.7659293473698,19.7020415100269}9 | {16.5800288529135,75.7475957670249}10 | {81.8520747194998,40.3476078575477}11 | {76.796671198681,86.3827232690528}12 | {59.9231450678781,90.9907738864422}13 | {70.161884885747,19.7427458665334}14 | {11.1269539105706,70.9988166182302}15 | {80.5005071521737,65.2822235273197}16 | {54.7030725912191,52.151339428965}17 | {103.059707058128,80.8419883321039}18 | {85.3574452036992,14.9910179991275}19 | {28.6501615960151,76.6922890325077}20 | {69.7285806713626,49.5416352967732} (20 rows)该表的字段position的数据类型为 double precision[].
从kmeans_2d训练集中指定position为特征列,使用kmeans算法,创建并保存模型point_kmeans。
openGauss=# CREATE MODEL point_kmeans USING kmeans FEATURES position FROM kmeans_2d WITH num_centroids=3; NOTICE: Hyperparameter max_iterations takes value DEFAULT (10) NOTICE: Hyperparameter num_centroids takes value 3 NOTICE: Hyperparameter tolerance takes value DEFAULT (0.000010) NOTICE: Hyperparameter batch_size takes value DEFAULT (10) NOTICE: Hyperparameter num_features takes value DEFAULT (2) NOTICE: Hyperparameter distance_function takes value DEFAULT (L2_Squared) NOTICE: Hyperparameter seeding_function takes value DEFAULT (Random++) NOTICE: Hyperparameter verbose takes value DEFAULT (0) NOTICE: Hyperparameter seed takes value DEFAULT (0) MODEL CREATED. PROCESSED 1上述命令中:
-
“CREATE MODEL”语句用于模型的训练和保存。
-
USING关键字指定算法名称。
-
FEATURES用于指定训练模模型的特征,需根据训练数据表的列名添加。
-
TARGET指定模型的训练目标,它可以是训练所需数据表的列名,也可以是一个表达式,例如: price > 10000。
-
WITH用于指定训练模型时的超参数。当超参未被用户进行设置的时候,框架会使用默认数值。
针对不同的算子,框架支持不同的超参组合,见表2。
表 2 算子支持的超参
算子 超参 GD(logistic_regression、linear_regression、svm_classification) optimizer(char*); verbose(bool); max_iterations(int); max_seconds(double); batch_size(int); learning_rate(double); decay(double); tolerance(double)其中,SVM限定超参lambda(double) Kmeans max_iterations(int); num_centroids(int); tolerance(double); batch_size(int); num_features(int); distance_function(char*); seeding_function(char*); verbose(int);seed(int) 当前各个超参数设置的默认值和取值范围,见表3。
表 3 超参的默认值以及取值范围
算子 超参(默认值) 取值范围 超参描述 GD (logistic_regression、linear_regression、svm_classification) optimizer = gd(梯度下降法) gd/ngd(自然梯度下降) 优化器 verbose = false T/F 日志显示 max_iterations = 100 (0, INT_MAX_VALUE] 最大迭代次数 max_seconds = 0 (不对运行时长设限制) [0,INT_MAX_VALUE] 运行时长 batch_size = 1000 (0, MAX_MEMORY_LIMIT] 一次训练所选取的样本数 learning_rate = 0.8 (0, DOUBLE_MAX_VALUE] 学习率 decay = 0.95 (0, DOUBLE_MAX_VALUE] 权值衰减率 tolerance = 0.0005 (0, DOUBLE_MAX_VALUE] 公差 seed = 0(对seed取随机值) [0, INT_MAX_VALUE] 种子 just for SVM:lambda = 0.01 (0, DOUBLE_MAX_VALUE) 正则化参数 Kmeans max_iterations = 10 [1, INT_MAX_VALUE] 最大迭代次数 num_centroids = 10 [1, MAX_MEMORY_LIMIT] 簇的数目 tolerance = 0.00001 (0,1) 中心点误差 batch_size = 10 [1, MAX_MEMORY_LIMIT] 一次训练所选取的样本数 num_features = 2 [1, GS_MAX_COLS] 输入样本特征数 distance_function = “L2_Squared” L1\L2\L2_Squared\Linf 正则化方法 seeding_function = “Random++” “Random++”“KMeans||” 初始化种子点方法 verbose = 0U { 0, 1, 2 } 冗长模式 seed = 0U [0, INT_MAX_VALUE] 种子 MAX_MEMORY_LIMIT = 最大内存加载的元组数量 GS_MAX_COLS = 数据库单表最大属性数量
模型保存成功,则返回创建成功信息如下。
MODEL CREATED. PROCESSED x -
-
查看模型信息。
当训练完成后模型会被存储到系统表gs_model_warehouse中。系统表gs_model_warehouse可以查看到关于模型本身和训练过程的相关信息。
用户可以通过查看系统表的方式查看模型,例如查看模型名为“point_kmeans”的SQL语句如下:
openGauss=# select * from gs_model_warehouse where modelname='point_kmeans'; -[ RECORD 1 ]---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- modelname | point_kmeans modelowner | 10 createtime | 2021-04-30 17:30:39.59044 processedtuples | 20 discardedtuples | 0 pre_process_time | 6.2001e-05 exec_time | .000185272 iterations | 5 outputtype | 23 modeltype | kmeans query | CREATE MODEL point_kmeans USING kmeans FEATURES position FROM kmeans_2d WITH num_centroids=3; modeldata | weight | hyperparametersnames | {max_iterations,num_centroids,tolerance,batch_size,num_features,distance_function,seeding_function,verbose,seed} hyperparametersvalues | {10,3,1e-05,10,2,L2_Squared,Random++,0,0} hyperparametersoids | {23,23,701,23,23,1043,1043,23,23} coefnames | {original_num_centroids,actual_num_centroids,dimension,distance_function_id,seed,coordinates} coefvalues | {3,3,2,2,572368998,"(77.282589,23.724434)(74.421616,73.239455)(18.551682,76.320914)"} coefoids | trainingscoresname | trainingscoresvalue | modeldescribe | {"id:1,objective_function:542.851169,avg_distance_to_centroid:108.570234,min_distance_to_centroid:1.027078,max_distance_to_centroid:297.210108,std_dev_distance_to_centroid:105.053257,cluster_size:5","id:2,objective_function:5825.982139,avg_distance_to_centroid:529.634740,min_distance_to_centroid:100.270449,max_distance_to_centroid:990.300588,std_dev_distance_to_centroid:285.915094,cluster_size:11","id:3,objective_function:220.792591,avg_distance_to_centroid:55.198148,min_distance_to_centroid:4.216111,max_distance_to_centroid:102.117204,std_dev_distance_to_centroid:39.319118,cluster_size:4"} -
利用已存在的模型做推断任务。
使用“SELECT”和“PREDICT BY”关键字利用已有模型完成推断任务。
查询语法:SELECT…PREDICT BY…(FEATURES…)…FROM…;
openGauss=# SELECT id, PREDICT BY point_kmeans (FEATURES position) as pos FROM (select * from kmeans_2d limit 10);id | pos ----+-----1 | 22 | 23 | 14 | 35 | 26 | 27 | 28 | 19 | 310 | 1 (10 rows)针对相同的推断任务,同一个模型的结果是稳定的。且基于相同的超参数和训练集训练的模型也具有稳定性,同时AI模型训练存在随机成分(每个batch的数据分布、随机梯度下降),所以不同的模型间的计算表现、结果允许存在小的差别。
-
查看执行计划。
使用explain语句可对“CREATE MODEL”和“PREDICT BY”的模型训练或预测过程中的执行计划进行分析。Explain关键字后可直接拼接CREATE MODEL/ PREDICT BY语句(子句),也可接可选的参数,支持的参数见表4。
表 4 EXPLAIN支持的参数
参数名 描述 ANALYZE 布尔型变量,追加运行时间、循环次数等描述信息 VERBOSE 布尔型变量,控制训练的运行信息是否输出到客户端 COSTS 布尔型变量 CPU 布尔型变量 DETAIL 布尔型变量,不可用。 NODES 布尔型变量,不可用 NUM_NODES 布尔型变量,不可用 BUFFERS 布尔型变量 TIMING 布尔型变量 PLAN 布尔型变量 FORMAT 可选格式类型:TEXT / XML / JSON / YAML 示例:
openGauss=# Explain CREATE MODEL patient_logisitic_regression USING logistic_regression FEATURES second_attack, treatment TARGET trait_anxiety > 50 FROM patients WITH batch_size=10, learning_rate = 0.05; NOTICE: Hyperparameter batch_size takes value 10 NOTICE: Hyperparameter decay takes value DEFAULT (0.950000) NOTICE: Hyperparameter learning_rate takes value 0.050000 NOTICE: Hyperparameter max_iterations takes value DEFAULT (100) NOTICE: Hyperparameter max_seconds takes value DEFAULT (0) NOTICE: Hyperparameter optimizer takes value DEFAULT (gd) NOTICE: Hyperparameter tolerance takes value DEFAULT (0.000500) NOTICE: Hyperparameter seed takes value DEFAULT (0) NOTICE: Hyperparameter verbose takes value DEFAULT (FALSE) NOTICE: GD shuffle cache size 212369QUERY PLAN -------------------------------------------------------------------Gradient Descent (cost=0.00..0.00 rows=0 width=0)-> Seq Scan on patients (cost=0.00..32.20 rows=1776 width=12) (2 rows) -
异常场景。
-
训练阶段。
-
场景一:当超参数的设置超出取值范围,模型训练失败,返回ERROR,并提示错误,例如:
openGauss=# CREATE MODEL patient_linear_regression USING linear_regression FEATURES second_attack,treatment TARGET trait_anxiety FROM patients WITH optimizer='aa'; NOTICE: Hyperparameter batch_size takes value DEFAULT (1000) NOTICE: Hyperparameter decay takes value DEFAULT (0.950000) NOTICE: Hyperparameter learning_rate takes value DEFAULT (0.800000) NOTICE: Hyperparameter max_iterations takes value DEFAULT (100) NOTICE: Hyperparameter max_seconds takes value DEFAULT (0) NOTICE: Hyperparameter optimizer takes value aa ERROR: Invalid hyperparameter value for optimizer. Valid values are: gd, ngd. (default is gd) -
场景二:当模型名称已存在,模型保存失败,返回ERROR,并提示错误原因:
openGauss=# CREATE MODEL patient_linear_regression USING linear_regression FEATURES second_attack,treatment TARGET trait_anxiety FROM patients; NOTICE: Hyperparameter batch_size takes value DEFAULT (1000) NOTICE: Hyperparameter decay takes value DEFAULT (0.950000) NOTICE: Hyperparameter learning_rate takes value DEFAULT (0.800000) NOTICE: Hyperparameter max_iterations takes value DEFAULT (100) NOTICE: Hyperparameter max_seconds takes value DEFAULT (0) NOTICE: Hyperparameter optimizer takes value DEFAULT (gd) NOTICE: Hyperparameter tolerance takes value DEFAULT (0.000500) NOTICE: Hyperparameter seed takes value DEFAULT (0) NOTICE: Hyperparameter verbose takes value DEFAULT (FALSE) NOTICE: GD shuffle cache size 5502 ERROR: The model name "patient_linear_regression" already exists in gs_model_warehouse. -
场景三:FEATURE或者TARGETS列是*,返回ERROR,并提示错误原因:
openGauss=# CREATE MODEL patient_linear_regression USING linear_regression FEATURES * TARGET trait_anxiety FROM patients; ERROR: FEATURES clause cannot be * -----------------------------------------------------------------------------------------------------------------------、 openGauss=# CREATE MODEL patient_linear_regression USING linear_regression FEATURES second_attack,treatment TARGET * FROM patients; ERROR: TARGET clause cannot be * -
场景四:对于无监督学习方法使用TARGET关键字,或者在监督学习方法中不适用TARGET关键字,均会返回ERROR,并提示错误原因:
openGauss=# CREATE MODEL patient_linear_regression USING linear_regression FEATURES second_attack,treatment FROM patients; ERROR: Supervised ML algorithms require TARGET clause ----------------------------------------------------------------------------------------------------------------------------- CREATE MODEL patient_linear_regression USING linear_regression TARGET trait_anxiety FROM patients; ERROR: Supervised ML algorithms require FEATURES clause -
场景五:当GUC参数statement_timeout设置了时长,训练超时执行的语句将被终止:执行CREATE MODEL语句。训练集的大小、训练轮数(iteration)、提前终止条件(tolerance、max_seconds)、并行线程数(nthread)等参数都会影响训练时长。当时长超过数据库限制,语句被终止模型训练失败。
-
-
推断阶段。
-
场景六:当模型名在系统表中查找不到,数据库会报ERROR:
openGauss=# select id, PREDICT BY patient_logistic_regression (FEATURES second_attack,treatment) FROM patients; ERROR: There is no model called "patient_logistic_regression". -
场景七:当做推断任务FEATURES的数据维度和数据类型与训练集存在不一致,将报ERROR,并提示错误原因,例如:
openGauss=# select id, PREDICT BY patient_linear_regression (FEATURES second_attack) FROM patients; ERROR: Invalid number of features for prediction, provided 1, expected 2 CONTEXT: referenced column: patient_linear_regression_pred ------------------------------------------------------------------------------------------------------------------------------------- openGauss=# select id, PREDICT BY patient_linear_regression (FEATURES 1,second_attack,treatment) FROM patients; ERROR: Invalid number of features for prediction, provided 3, expected 2 CONTEXT: referenced column: patient_linear_regression_pre
-
-
👍 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富!