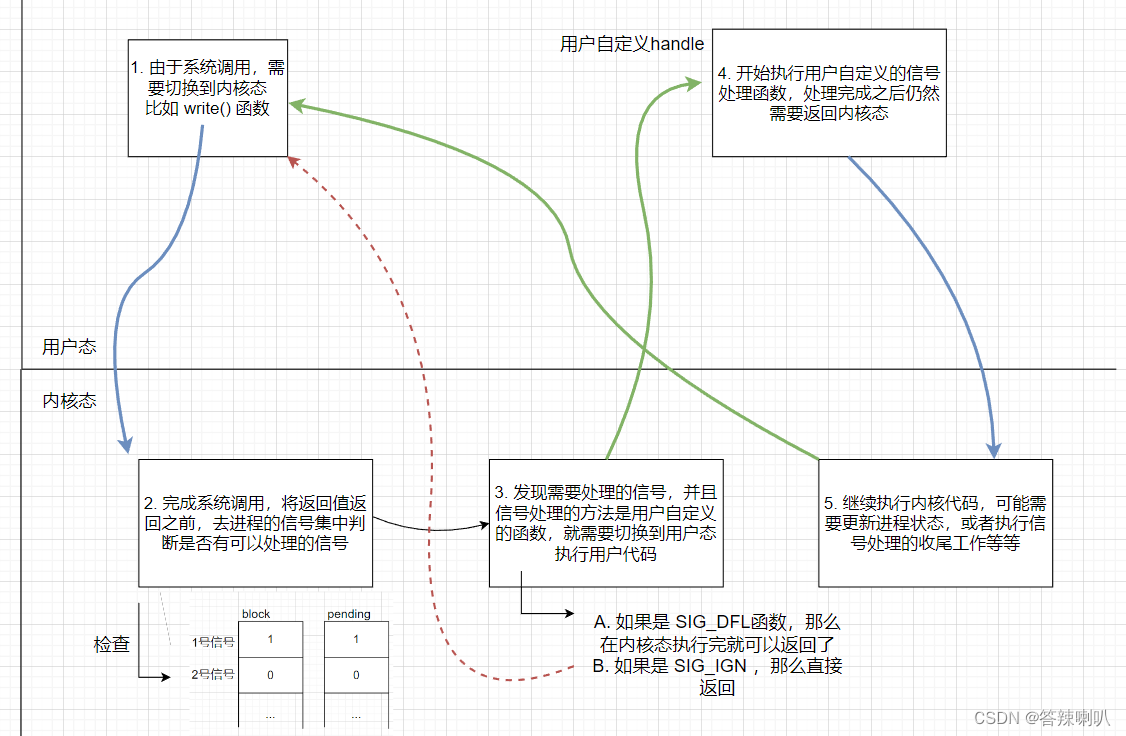
1、前言
存储引擎是数据库的组成部分,负责管理数据存储。
MongoDB支持的以下存储引擎:
| 存储引擎 | 描述 |
|---|---|
| WiredTiger存储引擎 | 从MongoDB 3.2开始默认的存储引擎,新的版本MongoDB推荐使用WiredTiger存储引擎。 |
| MMAPv1存储引擎 | MMAPv1是MongoDB 3.2之前版本默认的存储引擎。 |
| In-Memory存储引擎 | MongoDB企业版支持In-Memory存储引擎。 |
表
2、WiredTiger存储引擎
从MongoDB 3.2开始,MongoDB默认的存储引擎为WiredTiger存储引擎。WiredTiger存储引擎提供文档级的并发模型,检查点、压缩、加密等多项功能。基于这些功能,WiredTiger存储引擎提供最全面的性能和存储效率。
存储引擎可以通过--storageEngine启动项或在配置文件中storage.engine中设置。
2.1 WiredTiger存储引擎的优势:
·最大化可用缓存
WiredTiger最大限度地使用可用的内存作为缓存来减少I/O瓶颈。有两个缓存被使用:WiredTiger缓存和文件系统缓存。WiredTiger缓存存储未压缩的数据和提供的内存性能。操作系统的文件系统缓存存储压缩数据。当数据不在WiredTiger缓存中找到时,WiredTiger将在文件系统缓存查找数据。

·WiredTiger缓存大小默认为50%RAM
没有了文件系统缓存,最小的可用内存为20%,这对于任何较低的操作系统来说都可能受到资源的限制。而WiredTiger缓存大小默认为50%的RAM,将缓解资源限制的问题。
·高吞吐量
WiredTiger使用“写时复制”,在文件更新时,WiredTiger将创建一个新的文档副本,确定返回给用户的是最新版本。这种方法允许多个客户端同时修改集合中的不同文档,从而提高并发和吞吐量。当使用多核服务器,多个线程正在写入不同的文档时,就实现了最佳的写入性能。
·降低存储空间和提高磁盘IOPS
WiredTiger使用压缩算法来减少存储在磁盘上的数据空间。不仅降低存储压力,而且提高磁盘读写效率。文本文件是高度可压缩的,而二进制数据可能不可压缩,因为它可能已经被编码和压缩。WiredTiger在压缩时会消耗额外的CPU,但用户可以配置压缩方案优化CPU的开销与压缩比。Snappy是默认的压缩引擎,提供了较低的CPU开销高压缩比之间的良好平衡。Zlib压缩引擎可以实现更高的压缩比,但会增加额外的CPU。
·压缩索引和日志
索引可以在内存中压缩,也可以在磁盘上压缩。WiredTiger利用前缀压缩索引,节约内存的使用以及释放存储的IOPS。日志是默认Snappy压缩。
·多核的可扩展性
WiredTiger在多核架构提供的可扩展性下,利用风险指针、无锁算法、快速锁存等技术减少了线程间的争用。线程可以在不阻塞彼此的情况下执行操作,从而减少线程争用、提供更好的并发性和更高的吞吐量。
·文档级并发
WiredTiger使用文档级并发控制写操作。使多个客户端可以同时修改集合的不同的文档。
对于大多数的读写操作,WiredTiger只使用数据库和集合级的意向锁。
一些全局操作,通常是涉及多个数据库的短时间操作,仍然需要全局锁(即实例范围)。某些其他操作,如删除集合,则需要独占数据库锁。
2.2 WiredTiger存储引擎的配置
WiredTiger存储引擎可以通过--storageEngine启动项或在配置文件中storage.engine中设置。
例如:
mongod--storageEngine wiredTiger --dbpath <WiredTigerDBPath>
或,在配置文件设置如下:
storage:
wiredTiger:engineConfig:cacheSizeGB:<number>journalCompressor: <string>directoryForIndexes:<boolean>collectionConfig:blockCompressor: <string>indexConfig:prefixCompression: <boolean>复制
cacheSizeGB:从MongoDB 3.4开始,值取值范围为256MB至10TB,默认情况下,cacheSizeGB值为50%的RAM减去1GB或是256MB。
journalCompressor:WiredTiger采用预写事务日志联合检查站,保证数据的持久性。日志压缩算法默认为snappy。其他可选值有none或zlib。
directoryForIndexes:默认为false。当为true时,mongod会分别单独以索引命名的子目录存储索引和以集合命令的子目录存储集合数据。
blockCompressor:默认值为snappy,用于压缩集合数据的压缩的默认类型。其他可选值为none或zlib。
prefixCompression:默认为true,即使用前缀压缩索引数据。
3、In-Memory存储引擎
在MongoDB企业版3.2.6开始,In-Memory存储引擎作为通用性部分。除了一些元数据和诊断数据外,In-Memory存储引擎只在内存中维护数据,包括配置数据、索引、用户凭据等。
由于通过避免磁盘I/O,In-Memory存储引擎的数据库操作延迟更低。
3.1 In-Memory存储引擎优势
·低延迟
·应用可以将单独的缓存和数据库层合并成——所有的访问和管理都使用相同的API、操作工具和安全控件。
3.2 In-Memory存储引擎配置
mongod--storageEngine inMemory --dbpath <path> --inMemorySizeGB <newSize>
或,在配置文件中如下:
storage:
engine: inMemorydbPath: <path>
inMemory:engineConfig:inMemorySizeGB:<newSize>复制
inMemorySizeGB: 类型float,表示In-Memory存储引擎使用内存大小,默认是50%的物理RAM减去1GB,在3.4版本中,值范围在256MB到10TB内。
4、MMAPv1存储引擎
MMAPv1存储引擎是3.2版本之前的默认存储引擎。它利用集合级并发性和内存映射文件访问底层数据存储。内存管理委托给操作系统。MMAPv1不支持大端架构如s390x(IBM System z系列大型机硬件平台)。
4.1 MMAPv1存储引擎优势
·大容量插入、读取和更新
4.2 MMAPv1存储引擎配置
mongod--storageEngine mmapv1 --dbpath <path>
或,在配置文件做如下配置:
storage:
mmapv1:preallocDataFiles: <boolean>nsSize: <int>quota:enforced: <boolean>maxFilesPerDB: <int>smallFiles: <boolean>journal:debugFlags: <int>commitIntervalMs: <num>复制
preallocDataFiles:默认为True,表示预分配数据文件。
nsSize:默认为16,命名空间文件的默认大小,这些文件是以ns结尾的文件。每个集合和索引都算作名称空间。此设置控制新创建的命名空间文件的大小。此项对现有文件没有影响。命名空间文件的最大大小为2047MB。默认值为16MB,提供大约24000个名称空间。
enforced: 默认为false,表示禁止对每个数据库拥有的数据文件的最大限制。MongoDB每个数据库最多有8个数据文件,可以通过maxFilesPerDB调整配额。
maxFilesPerDB: 默认为8,表示每个数据库的数据文件数量的限制。需要设置enforced选项。
smallFiles: 默认为false,如果为true,MongoDB使用一个较小的默认文件大小。
debugFlags: 作用是提供功能性测试,在系统发生异常关闭时,影响的数据文件的完整性。
commitIntervalMs: 默认值100,表示MongoDB写入日志文件时间,单位毫秒。
5、MongoDB存储引擎性能对比
| WiredTIger存储引擎 | In-Memory存储引擎 | MMAPv1存储引擎 | |
|---|---|---|---|
| 写性能 | 高 | 高 | 中 |
| 文档级并发控制 | 文档级并发控制 | 集合级并发控制 | |
| 读性能 | 高 | 高 | 中 |
| 低延迟 | 中 | 高 | 中 |
| 支持磁盘压缩 | 是 | 否 | 否 |
| MongoDB查询语言支持 | 是 | 是 | 是 |
| 二级索引支持 | 是 | 是 | 是 |
| 副本集支持 | 是 | 是 | 是 |
| 分片支持 | 是 | 是 | 是 |
| 安全控制 | 是 | 是 | 是 |
| 大数据集的RAM | 是 | 否 | 是 |