简介
awk是一种强大的文本处理工具,用于在命令行环境下对文件或数据流进行逐行处理和分析。它是由 Alfred Aho、Peter Weinberger 和 Brian Kernighan 在 1977 年开发的,并以他们三人的姓氏命名。awk在 Unix/Linux 系统中非常常见,也有 Windows 版本可用。
awk基于一种脚本语言,语法类似于 C 语言,因此熟悉 C 或类似语言的开发者能够轻松上手。它的主要功能是对于输入数据的逐行处理和分析,可以通过灵活的模式匹配、操作符和函数对数据进行处理和转换。awk的工作方式是逐行读取输入数据,然后根据用户指定的模式和动作对数据进行处理。
目录
1. 语法
1.1. 参数选项
1.2. 内置变量
1.3. 转义符
1.4. 正则表达式
1.5. 操作符
1.6. 控制语句
1.7. 内置函数
2. 数据过滤
2.1. 基础用法
2.2. 过滤行方法
2.3. 过滤列方法
2.4. 组合过滤行、列
2.5. 输出行号
2.6. 输出列号
2.7. 忽略大小写
2.8. 指定分隔符
3. 正则表达式
3.1. 模糊匹配
3.2. 精确匹配
3.3. 逻辑匹配
3.4. 范围匹配
4. 控制语句
4.1. 条件判断语句
4.2. 循环控制语句
5. 内置函数方法
5.1. 字符串转换
5.2. 构造随机数
5.3. 生成大数据文件
5.4. 数学运算
5.5. BEGIN用法
5.6. END用法
1. 语法
1.1. 参数选项
-F:指定分隔符
-v:定义变量
-f:指定文件读取awk代码
-o:优化Awk程序以提高性能
-W:兼容旧版本
-r:启用扩展正则表达式中的重复操作符
1.2. 内置变量
FS :指定字段之间的分隔符。默认为连续的空白字符(空格和制表符)。
OFS:输出字段分隔符。默认为连续的空白字符(空格和制表符)。
RS :记录分隔符,默认为换行符。
ORS:输出记录分隔符,默认为换行符。
NF :字段数量,表示当前记录中字段的数量。
NR :记录数量,表示已读取的记录的总数。
$0 :所有的列。
$n :指定n列。$1表示第1列,$2表示第2列...
FILENAME:当前正在处理的文件的名称。
ARGV:包含命令行中的所有参数。
1.3. 转义符
\n:换行符
\t:制表符(Tab)
\b:退格符
\r:回车符
\f:换页符
\\:反斜杠本身
\":双引号
\':单引号
1.4. 正则表达式
.:匹配除了换行符之外的任意字符。
*:匹配前面字符的零个或多个重复。
+:匹配前面字符的一个或多个重复。
?:匹配前面字符的零个或一个重复。
^:匹配行的开头。
$:匹配行的结尾。
[ ]:字符类,匹配方括号内的任意一个字符。
[^ ]:否定字符类,匹配除了方括号内字符之外的任意一个字符。
( ):分组,将括号内的表达式作为一个整体。
|:或操作符,匹配两个或多个表达式中的任意一个。
1.5. 操作符
算术操作符
+:加法
-:减法
*:乘法
/:除法
%:取余数
^:幂运算关系操作符
> :大于
< :小于
==:等于
!=:不等于
>=:大于等于
<=:小于等于逻辑操作符
&&:逻辑与(and)
||:逻辑或(or)
! :逻辑非(not)赋值操作符
= :直接赋值
+=:加法赋值
-=:减法赋值
*=:乘法赋值
/=:除法赋值
%=:取模赋值字符串操作符
"":双引号用于拼接字符串
~ :匹配字符串
!~:不匹配字符串增减操作符
++:自增
--:自减
1.6. 控制语句
条件控制
if (条件) {代码块} else {代码块}循环控制
# 迭代循环
for (i=1; i<=10; i+=1) {代码块}# 只有条件为真,才能循环
while (条件为真) {代码块}# 至少打印1次代码
do {代码块} while (条件为真)控制流语句
continue:跳出当前循环
break:跳出整个循环
exit:终止整个Awk程序
1.7. 内置函数
字符串函数
length(str)'返回字符串 str 的长度。'
index(str, search)'返回字符串 str 中第一次出现 search 的位置。'
substr(str, start, length)'返回字符串 str 中从 start 开始长度为 length 的子字符串。'
split(str, arr, sep)'将字符串 str 按照分隔符 sep 分割,并将结果存储到数组 arr 中。'
tolower(str)'将字符串 str 转换为小写。'
toupper(str)'将字符串 str 转换为大写。'数值函数
int(n) :返回 n 的整数部分。
sqrt(n):返回 n 的平方根。
sin(n) :返回 n 的正弦值。
cos(n) :返回 n 的余弦值。
rand() :返回一个 0 到 1 之间的随机数。文件和输入函数
getline:读取下一行输入并赋值给特定变量。
NF:当前行的字段数。
NR:当前行的行号。
FNR:当前文件的行号。
2. 数据过滤
2.1. 基础用法
用法:[ ] 表示可选,<> 表示必选
awk [参数] <条件> [文件]1、查看文件内容
# 查看文件全部内容
awk // tmp.txt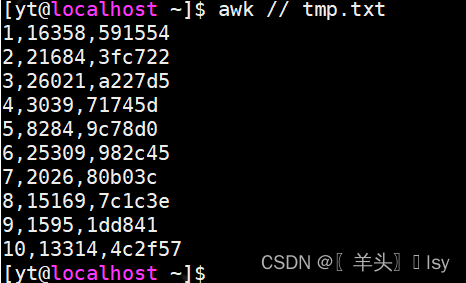
# 匹配包含c的行
awk /c/ tmp.txt 
# 指定分隔符为逗号,匹配包含c的行,只输出第1列和第3列
awk -F , '/c/{print $1, $3}' tmp.txt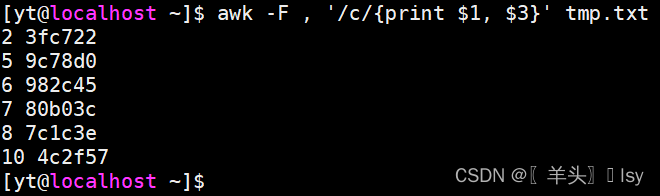
2、直接输出内容(使用BEGIN)
# 使用print直接打印内容
awk 'BEGIN{print 1, "abc"}'
# 使用变量赋值
awk -v num=100 'BEGIN{print "number is", num}'
3、管道符过滤
# 条件判断第1列的值
seq 10 |awk '$1 > 5 && $1 < 9'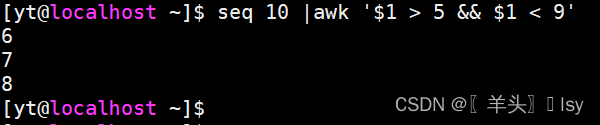
2.2. 过滤行方法
1、输出第1行
awk 'NR==1{print}' file.txt
2、输出最后1行
# 倒数第2行(先获取最后一行数据,再获取它的上一行),处理大数据文件较快
awk '{ line[NR] = $0 } END { print line[NR-1] }' file.txt# 最后1行使用END
awk 'END{print}' file.txt
3、输出第3~6行
# 通过判断的方式获取3~6行
awk 'NR>=3 && NR<=6' file.txt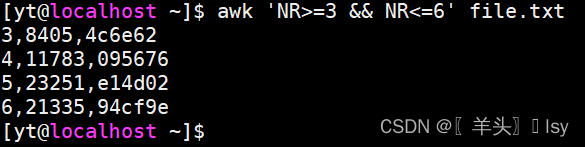
4、输出第2、6、8行数据
awk 'NR==2 || NR==6 || NR==8' file.txt
5、每隔3行输出一次
awk 'NR % 3 == 0' file.txt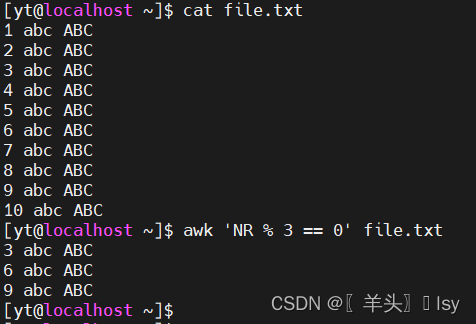
6、过滤n行后面/前面的全部行
# 输出5行以后的全部行
awk 'NR > 5' file.txt# 输出3行以前的全部行
awk 'NR < 3' file.txt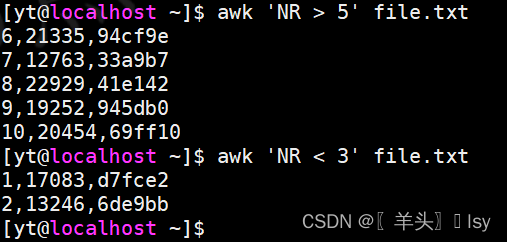
7、不输出空行
awk 'NF' file.txt
8、输出包含关键字的行
# 输出包含c的行
awk /c/ file.txt# 输出包含c和f的行
awk '/c/ && /f/' file.txt# 输出包含a或c的行
awk '/a/ || /c/' file.txt
9、输出匹配到的行的下1行
# 输出包含5的下一行
awk '/5/ {getline; print}'# 输出包含5的行和它的下一行
awk '/5/ {print; getline; print}'
10、匹配开始行和结束行
# 指定开始行:以2开头,结束行:以4开头。输出这中间的行
awk '/^2/, /^4/' file.txt
2.3. 过滤列方法
文件内容
1,17083,d7fce2,zhangsan,boy,18
2,13246,6de9bb,lisi,boy,39
3,8405,4c6e62,xiaomei,girl,28
4,11783,095676,wangwu,boy,20
5,23251,e14d02,zhangjie,girl,211、输出第1、3、5列
awk -F , '{print $1, $3, $5}' file.txt
2、过滤比较多的列(例如3~20列)不建议使用awk,使用cut
# 指定分隔符为逗号,过滤第3~20列
cut -d , -f 3-20 file.txt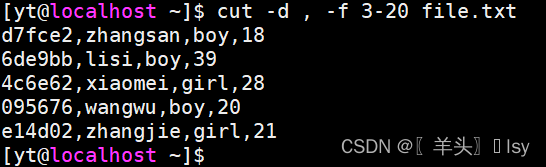
3、输出第列1为2,第2列小于50000的行
awk -F , '$1==2 && $2<50000{print}' file.txt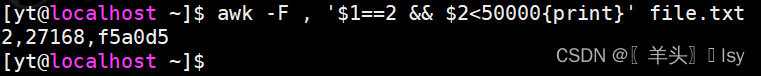
4、模糊匹配第2列以1开头的行
# 使用 ~ 模糊匹配,^1正则匹配以1开头
awk -F , '$2 ~ /^1/' file.txt
5、输出倒数第2列、最后1列
# $NF表示最后1列,倒数第2列-1,倒数第2列-2...
awk -F , '{print $(NF-1), $NF}' file.txt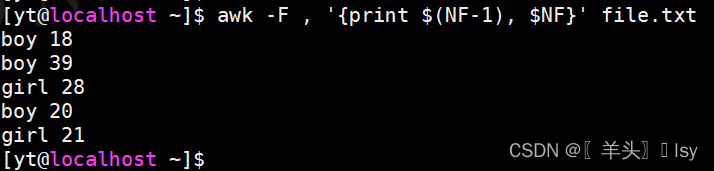
6、不输出第3列和最后1列
# 将第3列和最后1列替换为空
awk -F , '{$3=""; $NF=""; print}' file.txt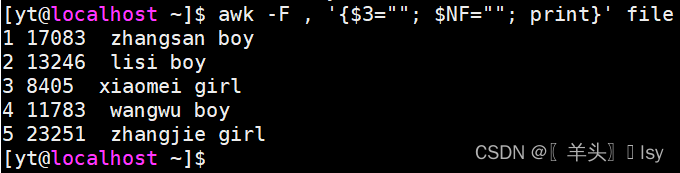
7、每列顺序随意控制
awk '{print $3, $1, $2}' file.txt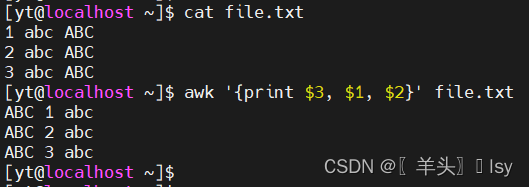
8、在最后添加一列字符串($0可以换成其他列)
awk '{print $0, "ooo"}' file.txt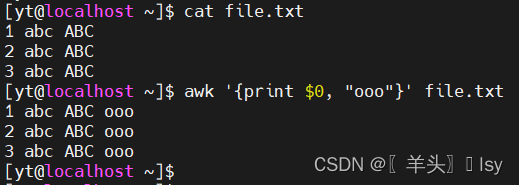
2.4. 组合过滤行、列
1、输出2~3行的第1列
awk -F , 'NR>1 && NR<4{print $1}' file.txt
2、输出第4行的第1列和最后1列
awk -F , 'NR==4{print $1, $NF}' file.txt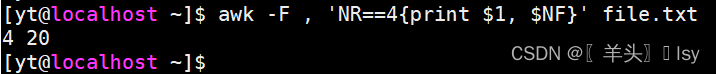
3、输出前3行,不包含最后1列
awk -F , 'NR<4{$NF=""; print}' file.txt
4、输出第1列等于5的第3列的值
awk -F , '$1==5{print $3}' file.txt
2.5. 输出行号
1、输出每行的行号
# NR输出行号,$0输出全部内容
awk '{print NR, $0}' file.txt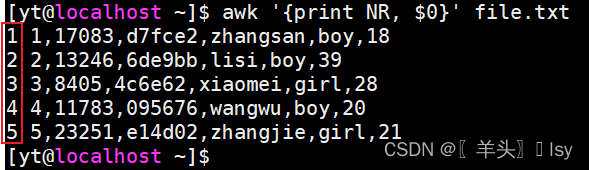
2、输出过滤关键字行的行号
# 过滤包含e的行,输出行号和内容
awk '/e/{print NR, $0}' file.txt
3、输出包含关键字的总行数
# 过滤包含e的行,每匹配到一次n+1,最后打印n
awk '/e/ {n++} END{print n}' file.txt
4、输出总行数
# 输出文件总行数
awk 'END{print NR}' file.txt# 输出文件总行数,不包含空行
awk 'NF!=0 {n++} END{print n}' file.txt
2.6. 输出列号
1、遍历所有列
awk -F , '{ for (i=1; i<=NF; i++) print "第" NR "行," "第" i "列: " $i }' file.txt
2、获取每行的列数
# 只输出列数
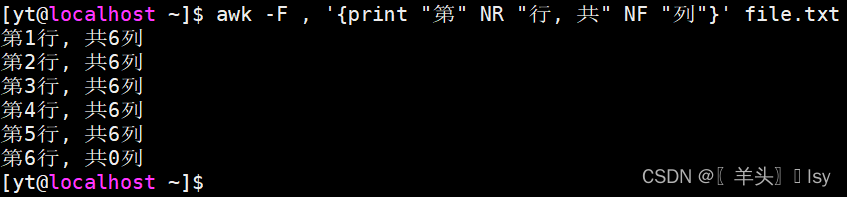
awk -F , '{print NF}' file.txt# 输出内容
awk -F , '{print "第" NR "行, 共" NF "列: ", $0}' file.txt# 不输出内容
awk -F , '{print "第" NR "行, 共" NF "列"}' file.txt
2.7. 忽略大小写
- 忽略大小写(IGNORECASE=1)
awk 'BEGIN{IGNORECASE=1} /C/' file.txt
2.8. 指定分隔符
- awk 默认分割符为单个或多个空格、以及制表符。
1、使用默认匹配分隔符
awk '{print $1}' file.txt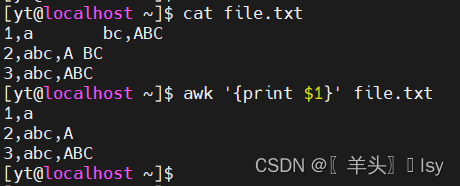
2、指定匹配分隔符
# 方法一:参数 -F
awk -F ',' '{print $1}' file.txt# 方法二:BEGIN
awk 'BEGIN{FS=","} {print $1}' file.txt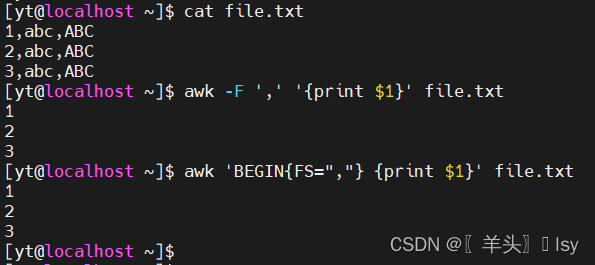
3、OFS 指定输出分隔符(默认是空格)
awk -F ',' '{OFS="|"; print $1, $2}' file.txt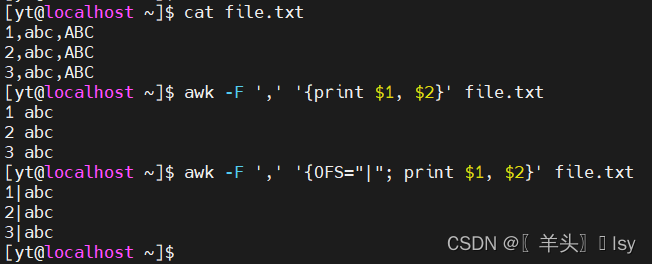
3. 正则表达式
3.1. 模糊匹配
1、匹配以 ab 开头的行
awk /^ab/ file.txt
2、匹配以 bc 结尾的行
awk /bc$/ file.txt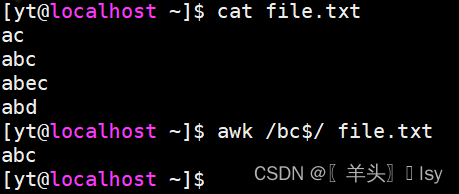
3.2. 精确匹配
1、只匹配a与c之间拥有一个字符的行
awk /a.c/ file.txt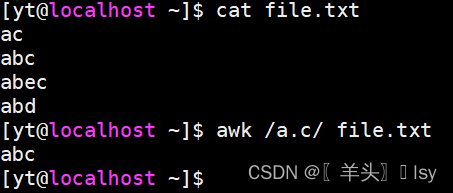
2、匹配a与c之间任意字符的行,不包含ac
awk /a.+c/ file.txt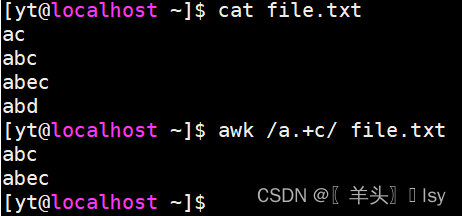
3、匹配a与c之间任意字符的行,包含ac
awk /a*c/ file.txt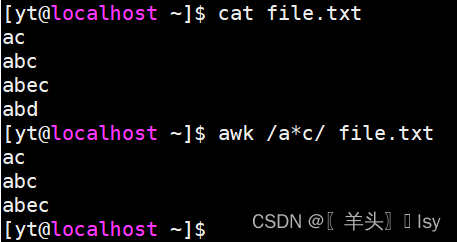
4、逻辑匹配单个字符,只匹配包含 abc 或 adc 的行
# b和d任取一个都可以
awk '/a(b|d)c/' file.txt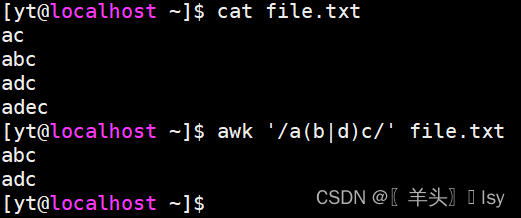
5、逻辑匹配多个字符,可匹配:abc、adc、abbc、addc、abbbc...
awk '/a(b|d)+c/' file.txt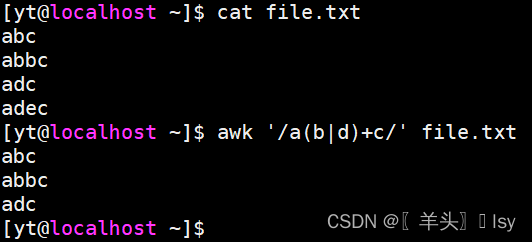
3.3. 逻辑匹配
or:匹配包含 bd 或 ac 的行
awk '/bd|ac/' file.txt 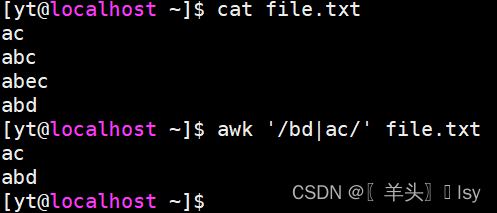
and:匹配包含ab且包含c的行
awk '/ab/ && /c/' file.txt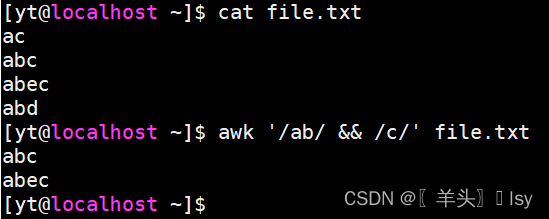
not:匹配不包含ab的行
awk '!/ab/' file.txt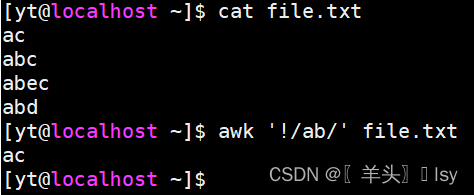
3.4. 范围匹配
1、匹配方括号中的任一字符
# 匹配任意包含d或e的行
awk /[de]/ file.txt# 匹配除了包含d或e的全部行
awk '!/[de]/' file.txt# 匹配除了abd以外的其他行
awk '/[^abd]/' file.txt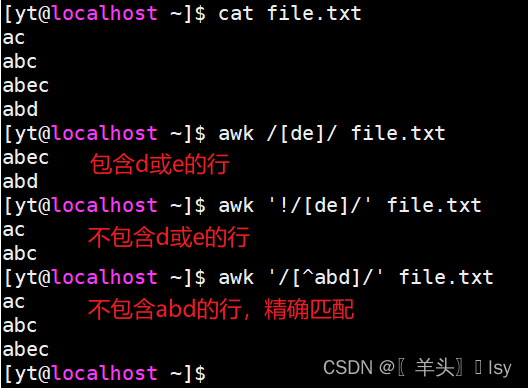
2、匹配数字
# 匹配包含数字的行
awk /[0-9]/ file.txt# 匹配不包含数字的行
awk '!/[0-9]/' file.txt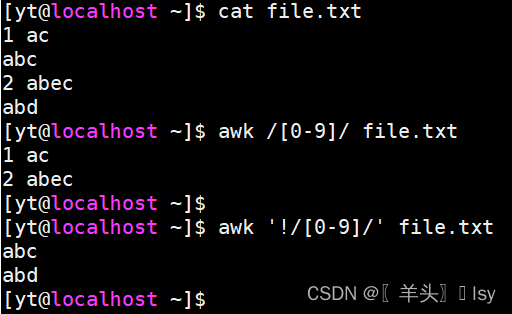
3、匹配小写字母
# 匹配包含小写字母的行
awk /[a-z]/ file.txt# 匹配不包含小写字母的行
awk '!/[a-z]/' file.txt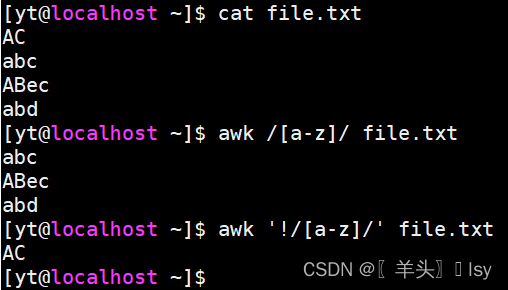
4、匹配大写字母
# 匹配包含大写字母的行
awk /[A-Z]/ file.txt# 匹配不包含大字母的行
awk '!/[A-Z]/' file.txt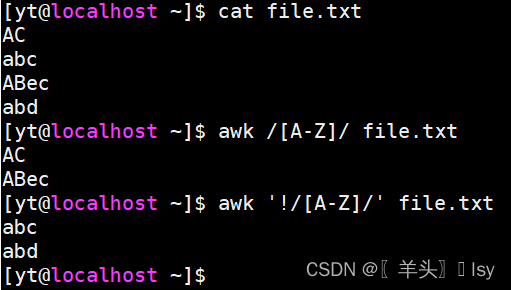
5、组合用法
# 匹配所有包含字母的行(不区分大小写)
awk /[A-Za-z]/ file.txt# 匹配所有包含字母、数字的行
awk /[A-Za-z0-9]/ file.txt 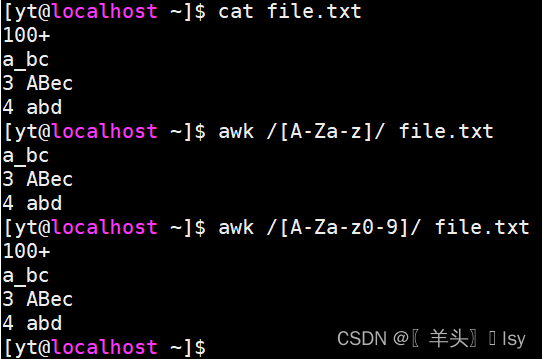
6、匹配多个相同字符
# 匹配ab,且ab连续的a为2个以上
awk /a{2}b/ file.txt# 匹配ab,且ab连续的b为2个以上
awk /ab{2}/ file.txt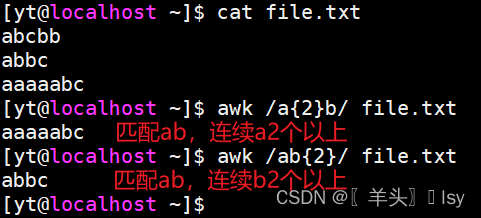
7、范围匹配数字、字母
# 匹配连续出现小写字母2次以上的行
awk /[a-z]{2}/ file.txt# 匹配连续出现数字2次以上的行
awk /[0-9]{2}/ file.txt 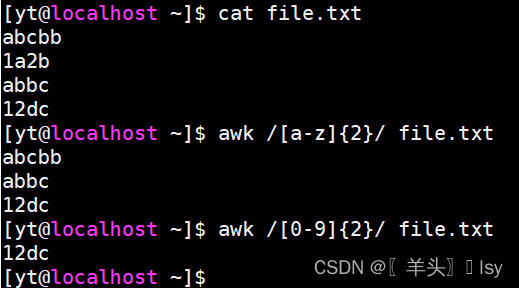
4. 控制语句
4.1. 条件判断语句
- awk '{if (条件判断) <为真> ;else <为假>}'
1、判断数字大小
awk '{if ($1 < 18) print $1 "岁,未成年" ;else print $1 "岁,已成年"}'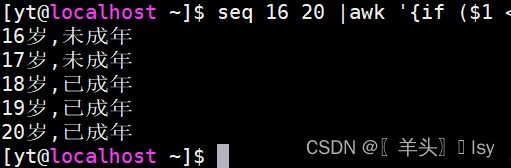
2、判断第1列的值小于4,或者最后1列等于5
awk '{if ($1 < 4 || $NF == 5) print $0}'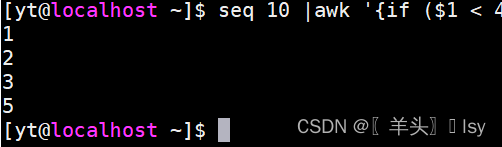
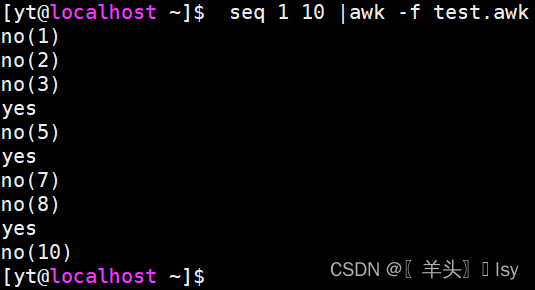
3、多分支判断,没有elif,通过else if构造(判断第1列的值为4、6、9)
# vim test.awk
{
if($1==4){print "yes"}
else if($1==6){print "yes"}
else if($1==9){print "yes"}
else{print "no(" $1 ")"}
} 
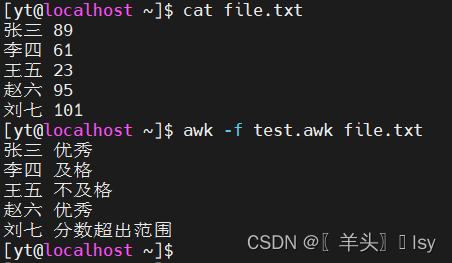
4、三元表达式
语法
awk '{result = (条件1) ? 结果1 :(条件2) ? 结果2 :(条件3) ? 结果3 :条件以外的结果print result
}' file.txt案例
# vim test.awk
{
label = ($2 < 60) ? "不及格":($2 < 71) ? "及格":($2 < 85) ? "良好":($2 < 101) ? "优秀":"分数超出范围"
print $1, label
}
4.2. 循环控制语句
1、for 循环
- awk 'BEGIN{for (条件) {循环体代码}}'
# 循环5次
awk 'BEGIN{for (i=1; i<=5; i+=1) {print "循环" i}}'
awk 'BEGIN{for (i=1; i<=5; i+=1) {print "循环" i} print "不在循环体中"}'
跳出循环
- awk 'BEGIN{for (条件) {if (条件) {跳出当前循环}; if (条件) {跳出整个循环}; 循环体代码块}}'
# 如果i=2,跳出当前循环;如果i=6,跳出整个循环
awk 'BEGIN{for (i=1; i<=10; i+=1) {if (i==2) {continue}; if (i==6) {break}; print "循环" i}}'
2、while 循环
- awk 'BEGIN{while (条件) {循环体代码}}'
# 循环5次
awk 'BEGIN{i=1; while (i<=5) {print "循环" i; i+=1}}'
awk 'BEGIN{i=1; while (i<=5) {print "循环" i; i+=1} print "不在循环体中"}'
跳出循环
- awk 'BEGIN{while (循环条件) {if (判断条件) {跳出当前循环}; if (判断条件) {跳出整个循环}; 循环体代码}}'
# 如果i=2,跳出当前循环;如果i=6,跳出整个循环
awk 'BEGIN{i=0; while (i<=10) {i+=1; if (i==2) {continue}; if (i==6) {break}; print "循环" i}}'
5. 内置函数方法
5.1. 字符串转换
1、全部转换为大写(toupper)
awk '{print toupper($0)}' file.txt
2、全部转换为小写(tolower)
awk '{print tolower($0)}' file.txt
3、单词首字母大写
awk '{for(i=1;i<=NF;i++){$i=toupper(substr($i,1,1))tolower(substr($i,2))}print}' file.txt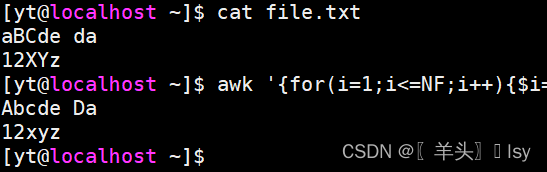
4、浮点数取整(int)
awk '{print int($1)}'
5.2. 构造随机数
1、生成0~1的随机数
awk 'BEGIN{srand(); print rand()}'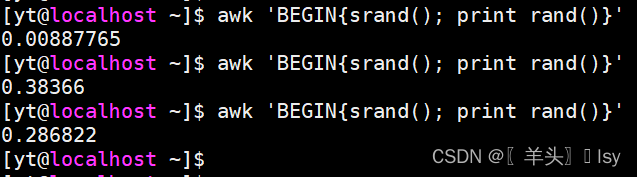
2、生成0~100的随机数
awk 'BEGIN{srand(); print int(rand()*101)}'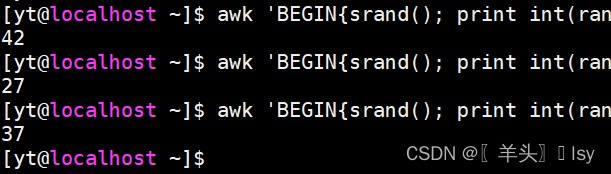
3、生成100~200的随机数
awk 'BEGIN{srand(); print int(rand()*101) + 100}'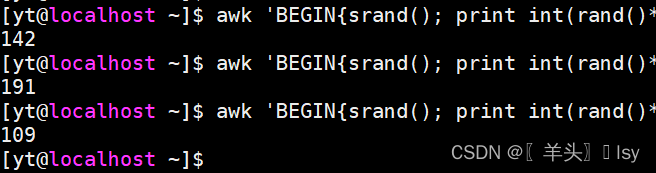
4、生成100次500~800的随机数
awk -v num=100 'BEGIN{srand(); for (i=1; i<=num; i+=1) {print int(rand()*301) + 500}}'
5、生成6位数随机数
awk 'BEGIN{srand(); printf "%06d\n", int(rand()*1000000)}'
6、生成6位随机字符串
awk 'BEGIN{srand(); print rand()}' |md5sum |cut -c 1-6
5.3. 生成大数据文件
1、生成1000w行简单数据
# 直接使用for循环1000w次,打印需要输出的内容
awk 'BEGIN { for (i=1; i<=10000000; i++) print "abc" }'
2、生成1GB简单数据
# 使用while无限循环,再利用head让其最大输出1GB大小
awk 'BEGIN{w=0; while (w<1) {print "abc"}}' |head -c 1G
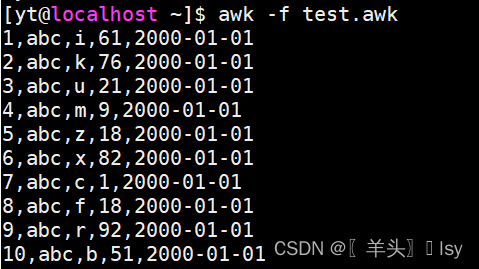
3、生成复杂数据
BEGIN{ OFS=","; srand(); for (i=1; i<=100; i+=1){col1 = icol2 = "abc"col3 = sprintf("%c", int(rand() * 26) + 97)col4 = int(rand() * 100)col5 = "2000-01-01"print col1, col2, col3, col4, col5}
}
- 第1列:从1开始叠加
- 第2列:固定字符"abc"
- 第3列:一个随机字母
- 第4列:0~100的随机数
- 第5列:固定字符"2000-01-01"
5.4. 数学运算
1、求和
awk '{sum += $1} END{print sum}'
2、求平均数
awk '{sum += $1} END{print sum/NR}'
3、求最大值
# NR==1 表示初始化变量max为第一个数值
awk 'NR==1 {max=$1} $1>max {max=$1} END{print max}'
4、求最小值
# NR==1 表示初始化变量min为第一个数值
awk 'NR==1 {min=$1} $1<min {min=$1} END {print min}'
5、数学运算
# 第1列的值 + 2(加法)
awk '{print $1 + 2}'# 第1列的值 - 2(减法)
awk '{print $1 - 2}'# 第1列的值 * 2(乘法)
awk '{print $1 * 2}'# 第1列的值 / 2(除法)
awk '{print $1 / 2}'# 第1列的值 ^ 2(幂运算)
awk '{print $1 ^ 2}'# 第1列的值 % 2(取余)
awk '{print $1 % 2}'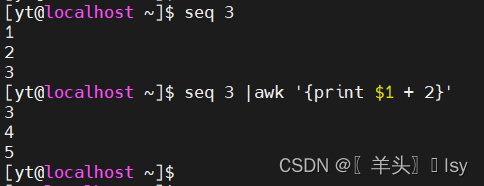
5.5. BEGIN用法
- BEGIN 是在处理输入之前执行一次。
1、初始化变量
awk 'BEGIN{OFS=","; a=1; b=2; print a, b}'
2、设置分隔符
awk 'BEGIN{FS=","} {print $2}'
3、输出表头信息
awk 'BEGIN{print "数字如下:"} {print $0}'
4、调用外部命令
awk 'BEGIN{system("echo $RANDOM |md5sum")}'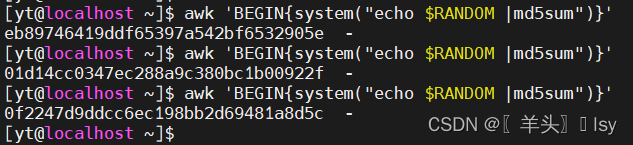
5.6. END用法
- END 是在处理完所有输入行之后执行一次。
1、输出结束后的字符串
awk '{print $0} END{print "结束后执行"}'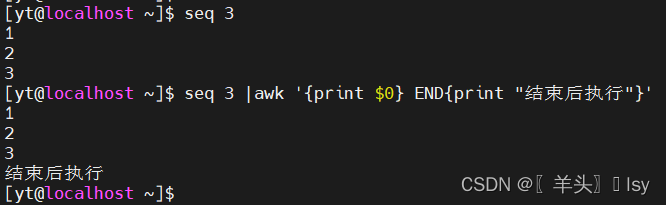
2、输出计算完成后的结果
# {sum += $1}是在持续进行,END后面的代码则是所有事情做完后最后执行
awk '{sum += $1} END{print sum}'