系列文章目录
【跟小嘉学 Rust 编程】一、Rust 编程基础
【跟小嘉学 Rust 编程】二、Rust 包管理工具使用
【跟小嘉学 Rust 编程】三、Rust 的基本程序概念
【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念
【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据
【跟小嘉学 Rust 编程】六、枚举和模式匹配
【跟小嘉学 Rust 编程】七、使用包(Packages)、单元包(Crates)和模块(Module)来管理项目
【跟小嘉学 Rust 编程】八、常见的集合
【跟小嘉学 Rust 编程】九、错误处理(Error Handling)
【跟小嘉学 Rust 编程】十一、编写自动化测试
【跟小嘉学 Rust 编程】十二、构建一个命令行程序
【跟小嘉学 Rust 编程】十三、函数式语言特性:迭代器和闭包
【跟小嘉学 Rust 编程】十四、关于 Cargo 和 Crates.io
【跟小嘉学 Rust 编程】十五、智能指针(Smart Point)
【跟小嘉学 Rust 编程】十六、无畏并发(Fearless Concurrency)
【跟小嘉学 Rust 编程】十七、面向对象语言特性
【跟小嘉学 Rust 编程】十八、模式匹配(Patterns and Matching)
【跟小嘉学 Rust 编程】十九、高级特性
【跟小嘉学 Rust 编程】二十、进阶扩展
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 一、 指针概述
- 1.1、什么是指针
- 1.2、Rust 的引用
- 1.3、示例
- 1.4、示例代码
- 1.5、Rust 智能指针
- 二、内存
- 2.1、值
- 2.2、变量
- 2.3、指针
- 2.4、内存区域
- 2.4.1、栈
- 2.4.2、堆
- 2.4.3、`'static`
- 2.5、动态内存分配(dynamic allocation)
- 2.6、虚拟内存
- 三、数据布局
- 3.1、对齐(Alignment)
- 3.1.1、对齐
- 3.1.2、复合类型
- 3.1.2.1、结构体
- 3.1.2.2、枚举类型
- 3.1.2.3、动态尺寸类型(DST, Dynamically Sized type)
- 3.1.2.4、零尺寸类型(ZST, Zero Sized type)
- 3.1.2.5、空类型
- 3.2、布局(Layout)
- 3.2.1、布局(Layout)
- 3.2.2、`repr(C)`
- 3.2.3、`repr(u)` 和`repr(i)`
- 3.2.4、repr(packed)
- 四、所有权
- 4.1、所有权和生命周期
- 4.2、引用
- 4.2.1、引用
- 4.2.2、别名
- 4.3、生命周期
- 4.3.1、生命周期
- 4.3.2、生命周期的局限
- 4.3.3、省略生命周期
- 4.3.4、无界生命周期
- 4.4、高阶 trait 边界 (higher-Rank Trait Bounds, HRTBs)
- 4.5、子类型和变性
- 4.5.1、子类型
- 4.5.2、变性
- 4.6、Drop 检查(Drop Check)
- 4.7、幽灵数据(PhantomData)
- 4.7.1、幽灵数据(PhantomData)
- 4.7.2、`Unique<T>`
- 4.7.3、幽灵数据模式表
- 4.8、分解借用(Splitting Borrows)
- 五、类型转换(Type Conversions)
- 5.1、强制转换(Conversion)
- 5.2、点操作符
- 5.3、显示转换(Cast)
- 5.4、变形(Transmutes)
- 六、未初始化内存
- 6.1、未初始化内存
- 6.2、安全方式
- 6.3、Drop 标志
- 6.4、非安全方式
- 六、基于所有权的资源管理(OBRM)
- 6.1、构造函数(Constructors)
- 6.2、析构函数(Destructors)
- 6.3、泄漏(Leaking)
- 6.3.1、泄漏(Leaking)
- 6.3.2、 vec::Drain
- 6.3.2、 Rc
- 6.3.4、thread::scoped::JoinGuard
- 七、展开(Unwinding)
- 7.1、展开(Unwinding)
- 7.2、异常安全性(Exception Safety)
- 7.3、污染(Poisoning)
- 八、并发
- 8.1、数据竞争和竞争条件
- 8.2、Sync 和 Send
- 8.3、原子(Atomics)
- 8.3.1、编译器重排(Compiler Reordering)
- 8.3.2、硬件重排(Hardware Reordering)
- 8.3.3、数据访问(Data Accesses)
- 8.3.4、顺序一致性(Sequentially Consistent)
- 8.3.5、获取释放(Acquire-Release)
- 8.3.6、Relaxed
- 九、不使用标准库
- 总结
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 前言
- 一、 指针概述
- 1.1、什么是指针
- 1.2、Rust 的引用
- 1.3、示例
- 1.4、示例代码
- 1.5、Rust 智能指针
- 二、内存
- 2.1、值
- 2.2、变量
- 2.3、指针
- 2.4、内存区域
- 2.4.1、栈
- 2.4.2、堆
- 2.4.3、`'static`
- 2.5、动态内存分配(dynamic allocation)
- 2.6、虚拟内存
- 三、数据布局
- 3.1、对齐(Alignment)
- 3.1.1、对齐
- 3.1.2、复合类型
- 3.1.2.1、结构体
- 3.1.2.2、枚举类型
- 3.1.2.3、动态尺寸类型(DST, Dynamically Sized type)
- 3.1.2.4、零尺寸类型(ZST, Zero Sized type)
- 3.1.2.5、空类型
- 3.2、布局(Layout)
- 3.2.1、布局(Layout)
- 3.2.2、`repr(C)`
- 3.2.3、`repr(u)` 和`repr(i)`
- 3.2.4、repr(packed)
- 四、所有权
- 4.1、所有权和生命周期
- 4.2、引用
- 4.2.1、引用
- 4.2.2、别名
- 4.3、生命周期
- 4.3.1、生命周期
- 4.3.2、生命周期的局限
- 4.3.3、省略生命周期
- 4.3.4、无界生命周期
- 4.4、高阶 trait 边界 (higher-Rank Trait Bounds, HRTBs)
- 4.5、子类型和变性
- 4.5.1、子类型
- 4.5.2、变性
- 4.6、Drop 检查(Drop Check)
- 4.7、幽灵数据(PhantomData)
- 4.7.1、幽灵数据(PhantomData)
- 4.7.2、`Unique<T>`
- 4.7.3、幽灵数据模式表
- 4.8、分解借用(Splitting Borrows)
- 五、类型转换(Type Conversions)
- 5.1、强制转换(Conversion)
- 5.2、点操作符
- 5.3、显示转换(Cast)
- 5.4、变形(Transmutes)
- 六、未初始化内存
- 6.1、未初始化内存
- 6.2、安全方式
- 6.3、Drop 标志
- 6.4、非安全方式
- 六、基于所有权的资源管理(OBRM)
- 6.1、构造函数(Constructors)
- 6.2、析构函数(Destructors)
- 6.3、泄漏(Leaking)
- 6.3.1、泄漏(Leaking)
- 6.3.2、 vec::Drain
- 6.3.2、 Rc
- 6.3.4、thread::scoped::JoinGuard
- 七、展开(Unwinding)
- 7.1、展开(Unwinding)
- 7.2、异常安全性(Exception Safety)
- 7.3、污染(Poisoning)
- 八、并发
- 8.1、数据竞争和竞争条件
- 8.2、Sync 和 Send
- 8.3、原子(Atomics)
- 8.3.1、编译器重排(Compiler Reordering)
- 8.3.2、硬件重排(Hardware Reordering)
- 8.3.3、数据访问(Data Accesses)
- 8.3.4、顺序一致性(Sequentially Consistent)
- 8.3.5、获取释放(Acquire-Release)
- 8.3.6、Relaxed
- 九、不使用标准库
- 总结
前言
本章节内容属于提高篇,主要详细讲解指针、数据布局(内存布局、内存对齐)、所有权、类型转换、未初始化内存、资源管理、展开、并发、重排序等内容。
主要教材参考 《The Rust Programming Language》
主要教材参考 《Rust For Rustaceans》
主要教材参考 《The Rustonomicon》
主要教材参考 《Rust 高级编程》
一、 指针概述
1.1、什么是指针
数据在物理内存(RAM)中时分散到存储着,地址空间是检索系统,指针就被编码为内存地址,使用 usize 类型的证书表示,一个地址就会指向地址空间内的某个地方。
地址空间的范围时 OS 和 CPU 提供的外官界面,程序只知道有序的字节序列,不会考虑系统中实际 RAM 的数量。
内存地址 是汇编语言的抽象,是指代内存中单个字节的一个数。
指针(原始指针) 就是指向某种类型的一个内存地址,指针是高级语言提供的抽象。
引用 就是指针,如果是动态大小的类型,就是指针和具有外保证的一个整数。
1.2、Rust 的引用
- 引用始终引用的是有效数据
- 引用与 usize 的倍数对齐
- 引用可以为动态大小的类型提供上述保障
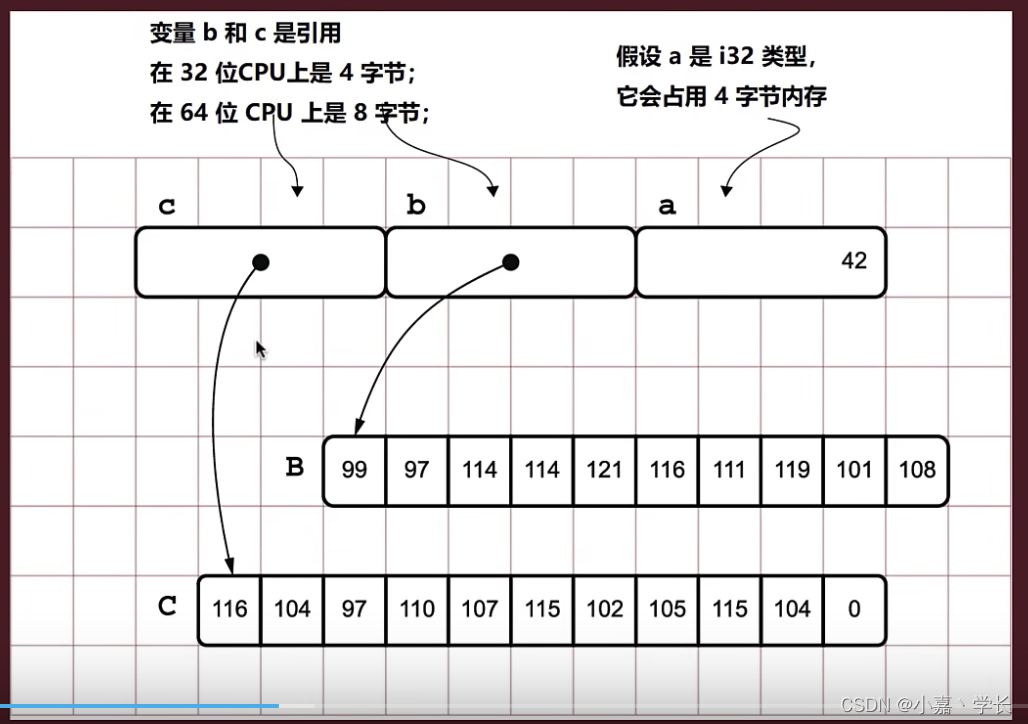
示例:代码
static B: [u8;10] = [99,97,114,114,121,116,111,119,101,108];
static C: [u8;11] = [116,104,97,110,107,115,102,105,115, 104,0];fn main() {let a:i32=42;let b: &[u8;10]=&B;let c: &[u8;11]=&C;println!("a:{}, b:{:p}, c:{:p}", a, b, c);
}
1.3、示例
use std::mem::size_of;
static B: [u8;10] = [99,97,114,114,121,116,111,119,101,108];
static C: [u8;11] = [116,104,97,110,107,115,102,105,115, 104,0];fn main() {let a:usize = 42;let b:Box<[u8]> = Box::new(B);let c: &[u8;11] = &C;println!("a (unsigned 整数)");println!("地址: {:p}", &a);println!("大小: {:?} bytes", size_of::<usize>());println!("值: {:?}", a);println!();println!("b (Box)");println!("地址: {:p}", &b);println!("大小: {:?} bytes", size_of::<Box<[u8]>>());println!("指向: {:p}", b);println!();println!("c (C的引用)");println!("地址: {:p}", &c);println!("大小: {:?} bytes", size_of::<[u8;11]>());println!("指向: {:p}", c);println!();println!("B (10 bytes 数组)");println!("地址: {:p}", &B);println!("大小: {:?} bytes", size_of::<[u8;10]>());println!("值: {:?}", B);println!();println!("C (11 bytes 数组)");println!("地址: {:p}", &c);println!("大小: {:?} bytes", size_of::<[u8;11]>());println!("值: {:?}", C);println!();
}
执行结果
a (unsigned 整数)
地址: 0x7ff7b7bed418
大小: 8 bytes
值: 42b (Box)
地址: 0x7ff7b7bed420
大小: 16 bytes
指向: 0x7fadd5f05d10c (C的引用)
地址: 0x7ff7b7bed440
大小: 11 bytes
指向: 0x108350dd6B (10 bytes 数组)
地址: 0x108350dcc
大小: 10 bytes
值: [99, 97, 114, 114, 121, 116, 111, 119, 101, 108]C (11 bytes 数组)
地址: 0x7ff7b7bed440
大小: 11 bytes
值: [116, 104, 97, 110, 107, 115, 102, 105, 115, 104, 0]
1.4、示例代码
use std::borrow::Cow;
use std::ffi::CStr;
use std::os::raw::c_char;static B: [u8;10] = [99,97,114,114,121,116,111,119,101,108];
static C: [u8;11] = [116,104,97,110,107,115,102,105,115, 104,0];fn main() {let a:i32 = 42;let b: String;let c: Cow<str>;unsafe{let b_ptr: *mut u8 = &B as *const u8 as *mut u8;b = String::from_raw_parts(b_ptr, 10, 10);let c_ptr: *const i8 = &C as *const u8 as *const c_char;c = CStr::from_ptr(c_ptr).to_string_lossy();}println!("a :{}, b:{} ,c:{}", a, b, c);
}
执行结果
a :42, b:carrytowel ,c:thanksfish
hello(55278,0x7ff847c62700) malloc: *** error for object 0x1047d0e8c: pointer being freed was not allocated
hello(55278,0x7ff847c62700) malloc: *** set a breakpoint in malloc_error_break to debug
zsh: abort cargo run
原始指针是没有 Rust 标准保障的内存地址。
Rust 引用(&mut T 和 &T) 会编译为原始指针,这意味着无需冒险进入 unsafe 就可以获得原始指针的性能。
1.5、Rust 智能指针
| 名称 | 简介 | 强项 | 弱项 |
|---|---|---|---|
| Raw Pointer | *mut T和 * const 自由基,闪电般快,极其unsafe | 速度、与外界交互 | unsafe |
Box<T> | 可以把任何东西都放在Box里面,可以接受几乎任何类型的长期存储,新的安全编程时代的主力军 | 将值集中存储在Heap | 大小增加 |
Rc<T> | 是Rust的能干而吝啬的薄记员,它知道谁借了什么,何时借了 | 对值的共享访问 | 大小增加;运行时成本;线程不安全 |
Arc<T> | 是Rust的大使,可以跨线程共享值,保证这些值不会互相干扰 | 对值的共享访问;线程安全 ;动态按需增长 | 大小增加;运行时成本;过度分配内存大小 |
| Cell` | 变态专家,具有改变不可变值的能力 | 内部可变性 | 大小增加;性能 |
| RefCell` | 对不可变引用执行改变,但有代价 | 内部可变性;可与仅接受不可变引用的Rc、Arc | 嵌套使用 大小增加;运行时成本;缺乏编译时保障 |
Cow<T> | 封闭并提供对借用数据的不可变访问,并在需要修改或所有权时延迟克隆数据 | 当只是只读访问时避免写入 | 大小可能会增加 |
| String | 可处理可变长度的文本,展示了如何构建安全的抽象 | 动态按需增长;在运行时保证正确编码 | 过度分配内存大小 |
RawVec<T> | 是Vec和其他动态大小类型的基石 | 动态按需增长;与内存分配器一起配合寻找空间 | 不直接适用您的代码 |
Unique<T> | 作为值的唯一所有者,可保证拥有完全控制权 | 需要独占值的类型(String)的基础 | 不适合直接用于应用程序代码 |
Share<T> | 共享所有权 | 共享所有权;可以将内存与T的宽度对齐,即使是空的时候 | 不适合直接用于应用程序代码 |
二、内存
2.1、值
- 值:类型 + 类型值域中的一个元素
- 通过它的类型表示,可以转化为字节序列
值的含义就是独立于存储它字节的位置
2.2、变量
变量是存储值的地方,它可以是栈、堆、或寄存器;变量就是给值的一个名称;
2.3、指针
- 指针是一个值,值里面存放的是一块内存的地址,指针指向某个地址;
- 指针可以被解引用来访问指向内存里面存放的值
2.4、内存区域
有很多内存区域,并不是都在DRAM上,三个比较重要的区域:Stack,heap、static 内存。
- 栈(stack):快,编译器必须知道类型的大小(实现了Sized 类型)
- 堆(heap):慢,编译器不知道类型的大小
2.4.1、栈
栈帧(stack Frame):每次函数调用,在stack 的顶部会分配一个连续的内存块。接近栈的底部附近是 main 函数的 Frame,随着函数调用,其余的 Frame 都推到了stack上面。
每个栈帧都包含了函数里面所有的变量以及函数所带的参数,当函数返回的时候,她的栈帧就会被回收。
每个栈帧的大小是不同的;栈指针(stack pointer):CPU有一个游标会随着程序执行而更新;
2.4.2、堆
Heap 是一个内存池,没有绑定到当前程序的调用栈,是为在编译时没有已知大小的类型准备的。
heap 允许你显式的分配连续的内存块,当你这么做的时候,你会得到一个指针,他执行内存块的开始地方。
堆内存中的值会一直有效,直到你对它显式的释放;
2.4.3、'static
'static 是特殊的生命周期,他的名字来自于 static 内存区,它将引用标记为之遥 static内存还存在,那么引用就合法;
static 变量的内存在程序开始运行时就分配了,到static 内存中的变量引用,按定义来说就是'static的,因为程序关闭前就不会被释放;
2.5、动态内存分配(dynamic allocation)
任何时刻,运行中的程序都需要一定数量的内存,当程序需要更多的内存时就会从 OS 请求,这就是动态内存分配(dynamic allocation)。
动态分配内存分配步骤
1、通过系统调用 从 OS 申请内存
- Unix: alloc
- windows:HeapAlloc
2、使用分配的内存
3、将不再需要的内存释放给OS - unix:free
- windows:HeapFree
2.6、虚拟内存
程序的内存视图,程序可访问的所有数据都是由操作系统在其他地址空间中提供。直觉上程序的内存就是一系列的字节,从开始位置0到结束为止。
segmentation fault:当CPU或OS检测到程序试图请求非法(无权访问)内存地址时,所产生的错误
segment:虚拟内存的块。虚拟内存被划分为块,以最小虚拟和物理地址之间转换所需要的空间;
- 页(page): 实际内存中固定大小的字块, 64位系统通常是 4k
- 字(word): 指针大小的任何类型,对应CPU寄存器的宽度
三、数据布局
3.1、对齐(Alignment)
3.1.1、对齐
对齐(Alignment)决定了字节可以被存在哪里,实际上硬件对给定类型可以存放的位置是有约束的,所有的值都必须开始byte的边界,必须至少是字节对齐(byte-aligned) ,存放的地址必须是 8bits 的倍数。
每种类型都有一个数字对齐属性。在x86平台,u64 和f 32 都是 32位对齐的。一种类型的大小都是它对齐属性的整数倍,这保证了这种类型的值在数组中的偏移量都是其类型尺寸的整数倍,可以按照偏移量进行索引。
动态大小类型的大小和对齐可能无法静态获取
3.1.2、复合类型
在Rust中有如下几种复合类型:
- 结构体(带命名的复合类型 named product types)
- 元组(匿名的复合类型 anonymous product types)
- 数组(同类型数据集合 homogeneous product types)
- 枚举(带命名的标签联合体 named sum types – tagged unions)
如果枚举类型的变量没有关联数据,它被称之为无成员枚举。
3.1.2.1、结构体
结构体的对齐属性等于他所有成员的对齐属性中最大的那个。Rust 会在必要的位置填充空白数据以保证每一个都正确地对齐,同时整个类型的尺寸都是对齐属性的整数倍。
use std::mem;#[warn(dead_code)]
struct A {a: u8, // 1 byteb: u32, // 4 bytec: u16, // 2 byte
}fn main() {println!("A sieof is {}", mem::size_of::<A>()); // 8
}
结构体 A 有两种对齐方案
// 方案一:12 byte
#[warn(dead_code)]
struct A {a: u8, // 1 byte// padding 3byteb: u32, // 4 bytec: u16, // 2 byte// padding 2byte
}// 方案一:8 byte
#[warn(dead_code)]
struct A {b: u32, // 4 bytea: u8, // 1 bytec: u16, // 2 byte// padding 1 byte
}
3.1.2.2、枚举类型
enum Foo {A(u32),B(u64),C(u8),
}// 布局
struct FooRepr {data: u64, // 根据tag的不同,这一项可以为u64,u32,或者u8tag: u8, // 0 = A, 1 = B, 2 = C
}
一般情况下,枚举的布局方式是这样的,但是很多情况下这种表达式并不是效率最高的。
3.1.2.3、动态尺寸类型(DST, Dynamically Sized type)
Rust 支持动态尺寸类型,即不能静态获取尺寸或者对齐属性的类型。Rust 语言提供了两种主要的 DST :Trait 和 切片(slice)。
trait 对象表示实现了某种指定 trait 的 类型,具体的类型被擦除了,取而代之的是运行时的一个虚函数表,表中包含了使用这种类型所有的必要信息,这就是 trait 对象的额外信息:一个指向虚函数表的指针。
3.1.2.4、零尺寸类型(ZST, Zero Sized type)
Rust 实际允许一种类型不占用内存空间;
use std::mem;struct Foo; // 没有成员 = 没有尺寸// 所有成员都没有尺寸 = 没有尺寸
struct Baz {foo: Foo,qux: (), // 空元组没有尺寸baz: [u8; 0], // 空数组没有尺寸
}fn main() {println!("Foo sieof is {}", mem::size_of::<Foo>());println!("Baz sieof is {}", mem::size_of::<Baz>());
}
Rust 认为所有产生和存储 ZST 的操作都被认为无操作(no-op)。 ZST 最极端的例子就是 Set 和 Map。安全代码不用关注 ZST,但是非安全代码必须考虑零尺寸类型带来的影响,计算指针的偏移量是no-op,标准的内存分配器(Rust默认使用jemalloc)在需要分配空间大小为0时,可能返回 nullptr,很难区分究竟是这种情况还是内存不足。
3.1.2.5、空类型
Rust 也支持不能被实例化的类型,这种类型只能有类型,而没有对应的值,空类型可以通过指定没有变量的枚举来声明。
enum Void {} // 没有变量 = 空类型
空类型比 ZST 更加少见,一个主要的应用场景就是在类型层面声明不可到达性(unreachability)。比如说一个 API 一般需要返回 Result。但是某些场景它是绝对不会出错的,这种情况类型层面的处理方法就是将返回值设置为 Result<T,Void>。
创建指向空类型的裸指针实际上是合法的,但是对他解引用是一个未定义行为,因为这么做没有任何意义。
3.2、布局(Layout)
3.2.1、布局(Layout)
类型的布局(Layout) :编译器如何决定类型的内存中的表示,Rust编译器对类型如何布局,并没给出多少保证。
Rust 提供了 repr 属性,可以添加到你类型的定义来请求特定的内存表示。
3.2.2、repr(C)
布局方式与c、cpp编译器对同类型的布局兼容,这对于FFI与其他语言交互的是很有用的,因为C布局可预测、不易改变。
注意:
- ZST的尺寸是0,但是它与C++的空类型不同,C++空类型需要占用一个字节的空间;
- DST的指针,元组、和带有成员的枚举都是C没有的,因此也不是FFI安全的;
- 如果 T 是一个 FFI 安全的非空指针,那么
Option<T>可以保证和 T 拥有相同的布局和 ABI,当然它也会是 FFI 安全的。这一规则适用于 &, &mut 和函数指针等所有非空的指针。 - 元组结构体和结构体基本相同,唯一不同是成员未命名;
- 对于枚举的处理和 repr(u*) 相同,选择的类型尺寸等于目标平台上C的应用二进制接口(ABI)默认枚举尺寸。
repr(C)和repr(u*)中无成员的枚举不能被赋值为一个没有对应变量的整数,尽管在 C\C++ 中这是一种合法的行为。构建一个没有对应变量的枚举类型实例属于未定义行为。(对于存在准确匹配的值是允许正常编写和编译的)
use std::mem;#[warn(dead_code)]
#[repr(C)]
struct A {a: u8, // 1 byte// padding 3 byteb: u32, // 4 bytec: u16, // 2 byte// padding 2 byte
}fn main() {println!("A sieof is {}", mem::size_of::<A>()); // 12
}
3.2.3、repr(u) 和repr(i)
这两个可以指定无成员枚举的大小,如果枚举变量对应的整数值对于设定的大小越界了,将产生一个编译期错误。你可以手工设置越界的元素为 0 以避免编译错误,不过 Rust 是不允许一个枚举中的两个变量拥有相同的值。
无成员枚举的意思就是枚举的每一个变量里面都不关联数据。不指定 repr(u*) 或 repr(i*) 的无成员枚举依然是一个 Rust 的合法原生类型,它们都没有固定的 ABI 表示方法。给它们指定 repr 使其有了固定的类型大小,方便在 ABI 中使用。
Rust中的所有有成员的枚举都没有确定的 ABI 表示方式(即使关联的数据只是 PhantomData 或 零尺寸类型的数据)。
为枚举显式指定 repr 后空指针优化将不再起作用。这些 repr 对于结构体无效。
3.2.4、repr(packed)
强制 Rust 不填充空数据,各个类型的数据紧密排列,这样有助于提升内存的使用效率,但很有可能导致其他的副作用。
尤其是大部分平台都强烈建议数据对齐。这意味着加载未对齐的数据会很低效(x86),甚至可能是错误的(一些ARM芯片)。像直接加载或存储打包的(packed)成员变量这种简单场景,编译器可能可以用 shift 和 mask 等方式隐藏对齐问题,但是如果使用一个打包的变量的引用,编译器很可能没办法避免未对齐加载问题。
在 Rust 中这会导致未定义行为。
四、所有权
4.1、所有权和生命周期
所有权是 Rust 的一个突破性功能,它让 Rust 彻底告别垃圾回收,同时做到内存安全和高效率。
可以避免 悬垂指针(野指针),指针逃逸;
4.2、引用
4.2.1、引用
在 Rust 之中有两种引用类型:共享指针(&) 和可变指针(&mut)。他们遵守如下两个规则
- 1、引用的生命周期不能超过被引用内容;
- 2、可变引用不能存在别名(alias);
很不幸 Rust 实际上没有定义别名模型。
4.2.2、别名
当变量和指针表示的内存区域有重叠的时候,他们就互为对方的别名。
fn compute(input: &u32, output: &mut u32) {if *input > 10 {*output = 1;}if *input > 5 {*output *= 2;}
}
编译器可能会对上述代码进行 优化,优化为如下形式。
fn compute(input: &u32, output: &mut u32) {let cached_input = *input; // 将*input放入缓存if cached_input > 10 {*output = 2; // x > 10 则必然 x > 5,所以直接加倍并立即退出} else if cached_input > 5 {*output *= 2;}
}
在 Rust 中这种优化是正确的,但对于其他几乎所有的语言都是错误的(除非编译器进行全局分析)。因为这种优化方案成立的前提是不存在别名,而绝大数语言并不会限制这一点。
4.3、生命周期
4.3.1、生命周期
Rust 在整个生命周期里面强制执行生命周期的规则,说白了就是作用域的名字,每一个引用以及包含引用的数据结构都要有一个生命周期来指定它保持有效的作用域。
在函数体内,Rust 通常不需要你显式地给生命周期起名字。因为在本地上下文里,一般没有必要关注生命周期。Rust 知道程序的全部信息,从而可以完美执行各种操作。它可能会引入许多匿名或临时的作用域让程序顺利执行。
但是如果你要跨出函数的边界,就需要关注生命周期了。生命周期用这样的符号表示:'a、'static。
4.3.2、生命周期的局限
#[derive(Debug)]
struct Foo;impl Foo {fn mutate_and_share(&mut self) -> &Self {&*self}fn share(&self) {}
}fn main() {let mut foo = Foo;let loan = foo.mutate_and_share();foo.share();println!("{:?}", loan);
}
上述代码可能会编译错误
error[E0502]: cannot borrow `foo` as immutable because it is also borrowed as mutable--> src/main.rs:12:5|
11 | let loan = foo.mutate_and_share();| ---------------------- mutable borrow occurs here
12 | foo.share();| ^^^^^^^^^^^ immutable borrow occurs here
13 | println!("{:?}", loan);| ---- mutable borrow later used here4.3.3、省略生命周期
Rust 为了让语言表达方式更加人性化,允许函数的签名中省略生命周期。
&'a T
&'a mut T
T<'a>
省略规则
- 每一个在输入位置省略的生命周期都对应一个唯一的生命周期参数。
- 如果只有一个输入的生命周期位置(无论省略还是没省略),那个生命周期会赋给所有省略了的输出生命周期。
- 如果有多个输入生命周期位置,而其中一个是 &self 或者 &mut self,那么 self 的生命周期会赋给所有省略了的输出生命周期。
- 除了上述两种情况,其他省略生命周期的情况都是错误的。
fn print(s: &str); // 省略的
fn print<'a>(s: &'a str); // 完整的fn debug(lvl: usize, s: &str); // 省略的
fn debug<'a>(lvl: usize, s: &'a str); // 完整的fn substr(s: &str, until: usize) -> &str; // 省略的
fn substr<'a>(s: &'a str, until: usize) -> &'a str; // 完整的fn get_str() -> &str; // 错误fn frob(s: &str, t: &str) -> &str; // 错误fn get_mut(&mut self) -> &mut T; // 省略的
fn get_mut<'a>(&'a mut self) -> &'a mut T; // 完整的fn args<T: ToCStr>(&mut self, args: &[T]) -> &mut Command // 省略的
fn args<'a, 'b, T: ToCStr>(&'a mut self, args: &'b [T]) -> &'a mut Command // 完整的fn new(buf: &mut [u8]) -> BufWriter; // 省略的
fn new<'a>(buf: &'a mut [u8]) -> BufWriter<'a> // 完整的
4.3.4、无界生命周期
非安全代码经常会凭空编出来一些引用和生命周期,这些生命周期都是无界的。
最常见的场景是解引用一个裸指针,然后产生一个拥有无界生命周期的引用。这些生命周期根据上下文的要求,想要多大就可以有多大。这其实比简单的设为'static 更加强大。比如 &'static &'a T 是无法通过类型检查的,但是无界生命周期可以完美适配 &'a &'a T。不过大多数情况下,这种的无界生命周期会被视为 'static。
4.4、高阶 trait 边界 (higher-Rank Trait Bounds, HRTBs)
Rust 的 Fn trait 是一个神奇的存在。比如说,我们可以编写如下的代码
struct Closure<F> {data: (u8, u16),func: F,
}impl<F> Closure<F>where F: Fn(&(u8, u16)) -> &u8,
{fn call(&self) -> &u8 {(self.func)(&self.data)}
}fn do_it(data: &(u8, u16)) -> &u8 { &data.0 }fn main() {let clo = Closure { data: (0, 1), func: do_it };println!("{}", clo.call());
}
这里我们进入 call 函数之前我们都不知道生命周期的名字! &self 和 call 要在同一个生命周期。
4.5、子类型和变性
4.5.1、子类型
子类型是类型之间的关系,可以让静态语言更加地灵活自由。尽管 Rust 没有结构体继承的概念,它却有子类型机制。在Rust 中子类型是针对生命周期存在的。生命周期是代码的作用域,我们可以根据他们相互包含的关系判断他们的继承关系。
4.5.2、变性
变性是类型构造函数与它的参数相关的一个属性。Rust 中的类型构造函数是一个带有无界参数的通用类型。比如,Vec 是一个构造函数,它的参数是 T,返回值是 vec<T>。& 和 &mut 也是构造函数,它们有两个类型:一个生命周期,和一个引用指向的类型。
Rust中有三种变性:
- 如果当 T 是 U 的子类型时,
F<T>也是F<U>的子类型,则 F 对于 T 是协变的 - 如果当 T 是 U 的子类型时,
F<U>是F<T>的子类型,则 F 对于 T 是逆变的 - 其他情况(即子类型之间没有关系),则 F 对于 T 是不变的
变性的基本原则:如果生命周期较短的内容有可能存储在生命周期更长的变量里,这时必须要求变性是不变的。
4.6、Drop 检查(Drop Check)
我们如下代码
let x;
let y;let (a,b) = (vec![],vec![]);
我们可以清晰的知道 x 的生命周期比 y是生命周期要长;但是 a 和 b 肯定有一个比另一个先销毁,但是销毁的顺序是不确定的,并非只有元组这样,复合结构从 Rust 1.0 开始就不会保证它们的销毁顺序。
Vec 必须通过标准库代码手动销毁它的元素,所以实现了 Drop 的类型在临死前都有一次回光返照的机会。
struct Inspector<'a>(&'a u8);struct World<'a> {inspector: Option<Inspector<'a>>,days: Box<u8>,
}impl<'a> Drop for Inspector<'a> {fn drop(&mut self) {println!("I was only {} days from retirement!", self.0);}
}fn main() {let mut world = World {inspector: None,days: Box::new(1),};world.inspector = Some(Inspector(&world.days));
}
此时代码存在编译错误
error[E0597]: `world.days` does not live long enough--> src/main.rs:19:38|
15 | let mut world = World {| --------- binding `world` declared here
...
19 | world.inspector = Some(Inspector(&world.days));| ^^^^^^^^^^^ borrowed value does not live long enough
20 | }| -| || `world.days` dropped here while still borrowed| borrow might be used here, when `world` is dropped and runs the destructor for type `World<'_>`
如果使用 Drop ,要哦求 days 的生命周期一定要比 inspector 要长(严格要求);如果不是泛型,则要求是'static。
关于 Dorp check 我们可以看
我们有一个不稳定属性可以用来不安全地断言泛型类型的析构函数保证不会访问任何过期的数据,该类型为 may_dangle 在RFC1372 例外规则。
#![feature(dropck_eyepatch)]struct Inspector<'a>(&'a u8, &'static str);unsafe impl<#[may_dangle] 'a> Drop for Inspector<'a> {fn drop(&mut self) {println!("Inspector(_, {}) knows when *not* to inspect.", self.1);}
}struct World<'a> {days: Box<u8>,inspector: Option<Inspector<'a>>,
}fn main() {let mut world = World {inspector: None,days: Box::new(1),};world.inspector = Some(Inspector(&world.days, "gadget"));
}
需要注意:dropck_eyepatch 这是一个不稳定特性在稳定版本不能使用。
4.7、幽灵数据(PhantomData)
4.7.1、幽灵数据(PhantomData)
在编写非安全代码时,我们常常遇见:类型或生命周期逻辑上与一个结构体关联起来,但是却不属于结构体的任何一个成员,这种情况对于生命周期尤为常见。
struct Iter<'a, T: 'a> {ptr: *const T,end: *const T,
}
上述会报如下错误:
error[E0392]: parameter `'a` is never used--> src/main.rs:5:13|
5 | struct Iter<'a, T: 'a> {| ^^ unused parameter|= help: consider removing `'a`, referring to it in a field, or using a marker such as `PhantomData`
因为 ’a 没有在结构体内使用,它是无界的。由于一些历史原因,无界生命周期和类型禁止出现在结构体定义中。所以我们必须想办法在结构体内使用到这个类型,这也是正确的变性检查和 Drop 检查的必要条件。
我们可以使用一个特殊的标志类型 PhantomData 做到这一点。PhantomData 不消耗存储克难攻坚,它只是模拟了某种类型的数据,以方便静态分析。
use std::marker;
struct Inspector<'a>(&'a u8, &'static str);struct Iter<'a, T: 'a> {ptr: *const T,end: *const T,_marker: marker::PhantomData<&'a T>,
}
4.7.2、Unique<T>
由于让裸指针拥有数据是一个很普遍的设计,以至于标准库为它自己创建了一个叫做unique<T> 的智能指针
- 它可以封装一个 * const T 处理变性
- 包含了一个 PhantomData
- 自动实现 Send / Sync,模拟和包含 T 时一样的行为
- 将指针标记为了 NonNull 以便控制很优化
4.7.3、幽灵数据模式表
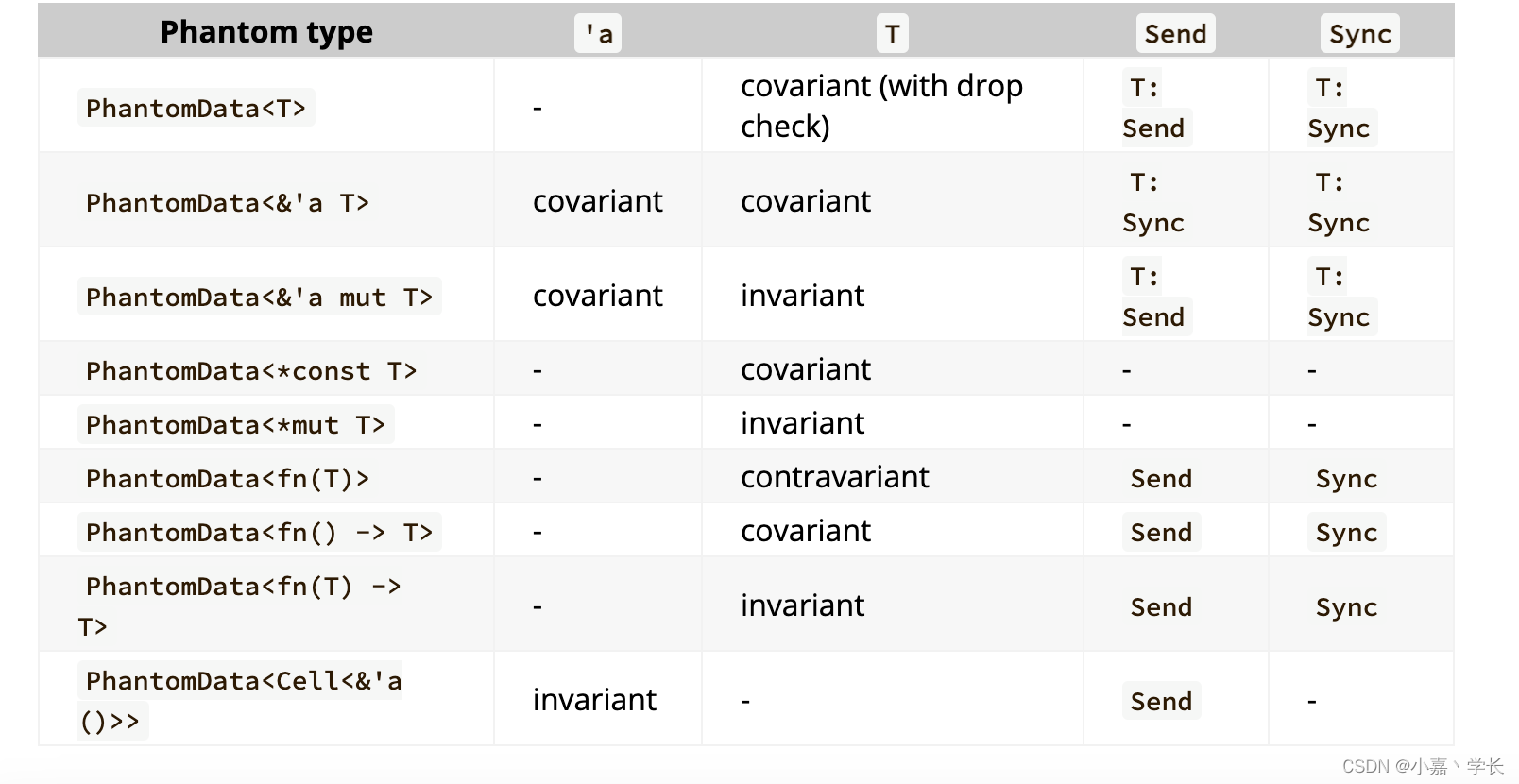
4.8、分解借用(Splitting Borrows)
可变引用的 Mutex 属性在处理复合类型的能力有限,借用检查器只能理解一些简单的东西,而且极易失败,他对结构体还算是充分了解,知道结构体的成员可能被分别借用。
struct Foo {a: i32,b: i32,c: i32,
}let mut x = Foo {a: 0, b: 0, c: 0};
let a = &mut x.a;
let b = &mut x.b;
let c = &x.c;
*b += 1;
let c2 = &x.c;
*a += 10;
println!("{} {} {} {}", a, b, c, c2);
let mut x = [1, 2, 3];
let a = &mut x[0];
let b = &mut x[1];
println!("{} {}", a, b);
但是对于数组和切片,就无法通过检查,为了能够让借用检查器理解我们所作所为是正确的。我们还是要使用非安全的代码。
use std::slice::from_raw_parts_mut;fn main() {let mut x = [1, 2, 3];unsafe{let a = from_raw_parts_mut(x.as_mut_ptr(), 1);(*a)[0]=2;println!("{:?}",a);}println!("{:?}",x);
}
五、类型转换(Type Conversions)
5.1、强制转换(Conversion)
在一些特定场景,类型会被隐式地强制转换。这种转换通常导致类型被弱化。主要针对指针和生命周期。
- 传递性:当 T_1 可以强制转换为 T_2 且 T_2 可以强制转换为 T_3 时,T_1 就可以强制转换为 T_3;
- 指针弱化
&mut T转换为&T*mut T转换为*const T&T转换为*const T&mut T转换为*mut T
- Unsize: 如果 T 实现了
CoerceUnsized<U>那么 T 可以强制转换为U - 类型解引用;如果 T 可以解引用为 U(比如
T: Deref<Target=U>),那么 &T 类型的表达式 &x 可以强制转换为 &U 类型的&*x
所有的指针类型(包括 Box 和 Rc 这些智能指针)都实现了 CoerceUnsized<Pointer<U>> for Pointer<T> where T: Unsize<U>
#[derive(Debug)]
struct Foo {x: u32,y: u16,
}
#[derive(Debug)]
struct Bar {a: u32,b: u16,
}fn main() {// 方式一let f:Foo = Foo { x: 1, y: 2 };let b:Bar = Bar { a: f.x, b: f.y };println!("f = {:#?}", f);println!("b = {:#?}", b);// 方式2let Foo { x, y } = f;let b:Bar = Bar { a: x, b: y };println!("f = {:#?}", f);println!("b = {:#?}", b);// 方式3let b: &Bar = unsafe {&*(&f as *const Foo as * const Bar)};println!("b = {:#?}", b);
}
5.2、点操作符
5.3、显示转换(Cast)
显式类型转换是强制类型转换的超集:所有的强制类型转换都可以通过显式转换的方式主动触发。但有一些场景只适用于显式转换。强制类型转换很普遍而且通常无害,但是显式类型转换是一种 “真正的转换 “,它的应用就很稀少了,而且有潜在的危险。因此,显式转换必须通过关键字 as 主动地触发。
expr as Type
真正的转换一般是针对裸指针和基本数字类型。显示类型转换不属于非安全行为。因为仅凭转换操作是不会违背内存安全性。
对于数字类型的转换
- 相同大小的整型互相转换(比如 i32->u32)是一个 no-op
- 大尺寸的整型转换为小尺寸的整型(比如 u32->u8)会被截断
- 小尺寸的整型转换为大尺寸的整型(比如 u8->u32)
- 如果源类型是无符号的,将会补0
- 如果源类型是有符号的,将会有符号补0
- 浮点类型转换为整型会舍去浮点部分
- 整型转换为浮点类型会产生这个整型的浮点型表示,
- f32 转换为 f64 可以无损失地完美转换,必要的时候做舍入(舍入到最近的可能取值,距离相同的取偶数)
- f64 转换为 f32 会生成最近可能值(舍入到最近的可能取值,距离相同的取偶数
5.4、变形(Transmutes)
mem::transmute<T, U> 接受一个 T 类型的值,然后将它重新解析为类型 U。唯一的限制是 T 和 U 必须有同样的大小。
- 创建任一类型的处于不合法状态的示例都将产生不可预知的混乱
- transmutes 有一个重载的返回类型。如果没有明确指定返回类型,它会返回一个满足类型推断的奇怪类型
- 使用不合法的值构建基本类型是未定义行为
- 非
repr(C)的类型之间相互变形是未定义行为 - & 变形为 &mut 永远是未定义行为
- 变形为一个未指定生命周期的引用会产生无界生命周期
六、未初始化内存
6.1、未初始化内存
所有运行期分配的内存开始都是“未初始化”状态,这种状态下内存的值是一组不确定的字节,甚至有可能不是使用这块内存的类型的合法值。将这段内存的值解析为任何类型都是未定义行为。
在 Rust 提供了处理未初始化内存的方式,既有安全的方式也有非安全的方式。
6.2、安全方式
Rust 禁止你在初始化之前读区它们
fn main() {let x: i32;println!("{}", x);
}
报错信息
error[E0381]: used binding `x` isn't initialized--> src/main.rs:3:20|
2 | let x: i32;| - binding declared here but left uninitialized
3 | println!("{}", x);| ^ `x` used here but it isn't initialized|= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider assigning a value|
2 | let x: i32 = 0;| +++如果一个值从变量中移出且变量类型不是Copy,那么变量逻辑上处于未初始化状态。
fn main() {let x = 0;let y = Box::new(0);let z1 = x; // x仍然是合法的,因为i32是Copylet z2 = y; // y现在逻辑上未初始化,因为Box不是Copy
}
6.3、Drop 标志
变量每次被赋值或离开作用域的时候, Rust 都需要判断是否调用析构函数。通过解引用赋值是一定会触发析构函数。
let mut x = Box::new(0); // let创建一个全新的变量,所以一定不会调用drop
let y = &mut x;
*y = Box::new(1); // 解引用假设被引用变量是初始化过的,所以一定会调用drop
有分支的代码所有分支的初始化行为一致的时候,也可以有静态的 drop 语义。drop 标准存储在栈中,并不在实现 Drop 的类型里面。
6.4、非安全方式
一个特殊情况是数组,安全 Rust 不允许部分初始化数组,初始化一个数组的时候,你可以通过 let x [val; N] 为每个位置赋予相同的值,或单独制定每个成员的值。很多时候我们需要用增量或动态的方式初始化数组,不幸的是,这个要求太严苛了。
非安全 Rust 为我们提供了:mem::uninitialized 函数。我们可以使用这个 函数来欺骗 Rust 我们已经初始化一个变量了。
在 Rust 之中对于已初始化和未初始化的变量赋值是有不同含义的。
- Rust 如果认为变量未初始化,它会将字节拷贝到未初始化的内存区域,别的就说嘛都不可以做了;
- 如果判断变量已初始化,它会销毁原有的值!因为我们欺骗 Rust 值已初始化,我们不能安全的赋值了。
系统分配器返回一个指向未初始化的指针。我们还必须使用 ptr 模块,特别是它提供的 三个函数,允许我们将字节写入一块内容而不会销毁原有的变量,这些函数为write、copy、copy_nonoverlapping,
use std::mem;
use std::ptr;// 数组的大小是硬编码的但是可以很方便地修改
// 不过这表示我们不能用[a, b, c]这种方式初始化数组
const SIZE: usize = 10;fn main() {let mut x: [Box<u32>; SIZE];unsafe {// 欺骗Rust说x已经被初始化x = mem::uninitialized::<_>();for i in 0..SIZE {// 十分小心地覆盖每一个索引值而不读取它// 注意:异常安全性不需要考虑;Box不会panicptr::write(&mut x[i], Box::new(i as u32));}}println!("{:?}", x);
}
我们需要注意。uninitialized 的方式已经被认为是过时的操作, Rust 提供了 MaybeUninit 替代。
use std::mem::{self, MaybeUninit};// 数组的大小是硬编码的但是可以很方便地修改
// 不过这表示我们不能用[a, b, c]这种方式初始化数组
const SIZE: usize = 10;fn main() {let x = {// Create an uninitialized array of `MaybeUninit`. The `assume_init` is// safe because the type we are claiming to have initialized here is a// bunch of `MaybeUninit`s, which do not require initialization.let mut x: [MaybeUninit<Box<u32>>; SIZE] = unsafe {MaybeUninit::uninit().assume_init()};// Dropping a `MaybeUninit` does nothing. Thus using raw pointer// assignment instead of `ptr::write` does not cause the old// uninitialized value to be dropped.// Exception safety is not a concern because Box can't panicfor i in 0..SIZE {x[i] = MaybeUninit::new(Box::new(i as u32));}// Everything is initialized. Transmute the array to the// initialized type.unsafe { mem::transmute::<_, [Box<u32>; SIZE]>(x) }};dbg!(x);
}
六、基于所有权的资源管理(OBRM)
基于所有权的资源管理(OBRM),又被称为 RALL(Resoruce Acquisition is Initialization,资源获取即初始化)。
如果要获取资源,你只要创建一个管理它的对象。如果要释放资源,你只要销毁这个对象,由对象负责为你回收资源。而所谓资源通常指的就是内存。资源是所有的系统资源,比如文件、线程、socket等;
6.1、构造函数(Constructors)
创建一个自定义类型的实例化的方法只有一种:先命名,然后一次性初始化所有成员。
因为 Rust 中的类型有且只有移动语义。
6.2、析构函数(Destructors)
Rust 通过 Drop trait 提供了一个成熟的自动析构函数。
fn drop(&mut self);
drop 执行之后,Rust 会递归销毁 self 的所有成员。我们需要注意。&mut self 意味着你可以阻止递归销毁, Rust 也不允许你将子成员的所有权移除。
6.3、泄漏(Leaking)
6.3.1、泄漏(Leaking)
基于所有权的资源管理能帮我们创建对象的时候获取资源,销毁对象的时候释放资源。
我们考虑一种更严格的泄漏形式:未能删除不可访问的值。 Rust 也不能防止这种情况。实际上 Rust 之中提供了一个函数来做这件事 mem::forget 这个函数使用传递给它的值,然后不运行析构函数。
对于代理类型,我们要小心它的析构函数。
6.3.2、 vec::Drain
Drain 是一个集合 API ,它将容器内的数据所有权移出,却不占有容器本身。
use std::mem;
fn main() {let mut vec = vec![Box::new(0); 4];{// start draining, vec can no longer be accessedlet mut drainer = vec.drain(..);// pull out two elements and immediately drop themdrainer.next();drainer.next();// get rid of drainer, but don't call its destructormem::forget(drainer);}// Oops, vec[0] was dropped, we're reading a pointer into free'd memory!println!("{}", vec[0]);
}
我们把造成更多泄漏的泄漏叫做泄漏扩大化(leak amplification)。
6.3.2、 Rc
struct Rc<T> {ptr: *mut RcBox<T>,
}struct RcBox<T> {data: T,ref_count: usize,
}impl<T> Rc<T> {fn new(data: T) -> Self {unsafe {// Wouldn't it be nice if heap::allocate worked like this?let ptr = heap::allocate::<RcBox<T>>();ptr::write(ptr, RcBox {data: data,ref_count: 1,});Rc { ptr: ptr }}}fn clone(&self) -> Self {unsafe {(*self.ptr).ref_count += 1;}Rc { ptr: self.ptr }}
}impl<T> Drop for Rc<T> {fn drop(&mut self) {unsafe {(*self.ptr).ref_count -= 1;if (*self.ptr).ref_count == 0 {// drop the data and then free itptr::read(self.ptr);heap::deallocate(self.ptr);}}}
}
6.3.4、thread::scoped::JoinGuard
该 API已经从 std 删除,详细参考 Issue #24292
七、展开(Unwinding)
7.1、展开(Unwinding)
Rust 有一个分层的错误处理体系:
- 如果有些值可以为空,就用 Option
- 如果发生了错误,而错误可以被正常处理,就用 Result
- 如果发生了错误,但是没办法正常处理,就让线程 panic
- 如果发生了更严重的问题,中止 (abort) 程序
Option 和 Result 在大多数情况下都是默认的优先选择,因为 API 的用户可以根据自己的考虑将它们变为 panic 或 中止 。 panic 会导致线程停止正常的执行流程、展开栈(Unwind stack)、调用析构函数。
我们可以使用 std::panic:catch_unwind api ,可以在不启动一个线程的情况下捕获 panic。
从其他语言展开 Rust 的栈,或者从 Rust 展开其他语言的栈,全都属于未定义行为。你必须在进入 FFI 调用之前捕获所有的 Panic!
7.2、异常安全性(Exception Safety)
在 Rust 里面还是有很多许多地方会 panic。例如 对 None 调用 unwrap、使用超出范围的索引值、或者 0 做除数,你的程序就要panic。
在 debug 模式下,所有的计算操作在溢出的时候也都会 panic。除非你十分小心并且严格控制着每一条代码的行为,否则所有的东西都有展开的可能,你需要时刻准备迎接它。
在更广大的程序设计世界里面,应对展开这件事通常被称之异常安全。在 Rust 中,我们需要考虑两个层次的异常安全性
- 在非安全代码中,异常安全的下限是要保证不能违背内存安全性。我们称之为最小异常安全性。
- 在安全代码中,异常安全性要保证程序时刻在做正确的事情。我们称之为最大异常安全性。
7.3、污染(Poisoning)
所有非安全的代码都必须保证最小异常安全性,但是并不是所有的类型都能保证最大异常安全性。
污染没有生命特别的含义:通常只是值禁止其他成俗正常地使用它。 污染是一种守护机制。
八、并发
8.1、数据竞争和竞争条件
安全 Rust 保证了不存在数据竞争。数据竞争指的是两个或两个以上的线程并发地访问同一块内存,其中一个线程写操作哦,其中一个线程是非同步的。
数据竞争导致未定义行为,所以不可能在安全 Rust 中存在。大多数情况下,Rust 的所有权系统就可以避免数据竞争:不可能有可变引用的别名,因此也就不可能有数据竞争。
但是内部可变性就复杂了,我们要用 Send 和Sync 实现。
竞争条件指多个线程或进程在读写一个共享数据时结果依赖于它们执行的相对时间的情形。
但是 Rust 并不会避免一般的竞争条件。
use std::thread;
use std::sync::atomic::{AtomicUsize, Ordering};
use std::sync::Arc;
use std::time;fn main() {let data = vec![1, 2, 3, 4];let idx = Arc::new(AtomicUsize::new(0));let other_idx = idx.clone();// `move` captures other_idx by-value, moving it into this threadthread::spawn(move || {other_idx.fetch_add(10, Ordering::SeqCst);});thread::sleep(time::Duration::from_millis(100));println!("{}", data[idx.load(Ordering::SeqCst)]);
}
如果没有进行线程休眠,idx =0 打印出1,但是如果休眠了100毫秒了,idx = 10 就会产生 panic。
8.2、Sync 和 Send
不是所有人都遵守可变性原则,有一些类型允许你拥有同一块内存的别名,同时还改变内存的值。除非这些类使用同步来控制访问,否则它们就不是线程安全的。 Rust 根据 Send 和 Sync 这两个 trait 获取相关信息。
- 如果一个类型可以安全地传递给另一个线程,这个类型是 Send
- 如果一个类型可以安全地被多个线程共享 (也就是 &T 是 Send),这个类型是 Sync
Send 和 Sync 是 Rust 并发机制的基础。 它们是非安全的 trait ,不正确地实现 Send 和 Sync 会导致未定义行为。
Send 和 Sync 还是自动推导的 trait。和其他的 trait 不同,如果一个类型完全由 Send 或 Sync 组成,那么这个类型本身也是 Send 或 Sync。几乎所有的基本类型都是 Send 和 Sync,因此你能见到的很多类型也就都是 Send 和 Sync。
主要例外
- 原始指针不是Send 、也不是Sync
- UnsafeCell 、Cell、RefCell 不是 Sync ;
- Rc 不是 Send 或 Sync ,因为引用计数是共享且非同步的。
一个类型会被自动推导为 Send 或 Sync,但是它其实不满足二者的要求。这时我们可以去掉 Send 和 Sync 实现
#![feature(option_builtin_traits)]// 我对于同步的基础类型有着神奇的语义
struct SpecialThreadToken(u8);impl !send for SpecialThreadToken {}
impl !Sync for SpecialThreadToken {}
8.3、原子(Atomics)
Rust 继承了 C++20 种原子的内存模型,C11 的内存模型试图同时满足开发者对语义的要求、编译器对优化的要求、还有硬件对混乱状态的要求。
8.3.1、编译器重排(Compiler Reordering)
编译器努力地通过各种复杂的变换,尽可能减少数据依赖和消除死代码。特别是,它可能会彻底改变事件的顺序,或者干脆让某些事件永远不会发生。
例如
x = 1;
y = 3;
x = 2;
可能被优化为
x = 2;
y = 3;
8.3.2、硬件重排(Hardware Reordering)
即使编译器玩去明白我们的意图,在内存分层模式下的CPU,你的硬件系统里面确实有一些全局共享的内存空间,但是在各个CPU 核心来看,这些内存都离得太远,速度太慢。CPU希望在本地 cache 里面操作数据,只有在 cache 里面没有需要内存的时候才委屈和共享内存打交道。
硬件不能保证相同的事件在两个不同的线程里面有一定相同的执行顺序,如果要确保这一点,我们需要有一些特殊的方法告诉CPU 稍微变笨一点。
initial state: x = 0, y = 1THREAD 1 THREAD2
y = 3; if x == 1 {
x = 1; y *= 2;}不同的 CPU 提供了不同的保证机制,但是详细区分它们没什么意义。一般来说只需要把硬件分为两类:强顺序的和弱顺序的。最明显的,x86/64 平台提供了强顺序保证,而 ARM 提供弱顺序保证。对于并发编程来说,它们也会导致不同的结果:
- 在强顺序硬件上要求强顺序保证的开销很小,甚至可能为零,因为硬件本身已经无条件提供了强保证。而弱保证可能只能在弱顺序硬件上获得性能优势。
- 在强顺序硬件上要求过于弱的顺序保证有可能也会碰巧成功,即使你的程序是错误的。如果可能的话,在弱保证硬件上测试并发算法。
8.3.3、数据访问(Data Accesses)
C11 内存模型允许我们接触到程序的因果关系。我们通过数据访问和原子访问来控制这种关系。编译器认为数据访问是单线程的,所以可以对它随意重排。硬件也可以把数据访问的重排结果移植到其他的线程上,无论结果多么的滞后和不一致都可以,数据访问最严重的问题就是它会导致数据竞争。
数据访问对硬件和编译器很友好,但是我们已经看到了编写和它相关的同步程序是十分可怕的。事实上,它的同步语义太弱了。
只依靠数据访问是不可能写出正确的同步代码。
Rust 暴露的排序方式
- 顺序一致性(Sequentially Consistent,SeqCst)
- 释放(Release)
- 获取(Acquire)
- Relaxed
8.3.4、顺序一致性(Sequentially Consistent)
顺序一致性 是所有排序方式中最强大的,包含了其他所有排序方式的约束条件。在同一个线程中,SeqCst 之前的访问永远在它之前,之后的访问永远在它之后。只使用顺序一致性原子操作和数据访问就可以构建一个无数据竞争的程序,这种程序的好处是它的命令在所有线程上都有着唯一的执行流程。而且这个执行流程又很容易推导:它就是每个线程各自执行流程的交叉。如果你使用更弱的原子排序方式的话,这一点并不一定继续有效。
顺序一致性给开发者的便利并不是免费的。即使是在强顺序平台上,顺序一致性也会产生内存屏障 (memory fence)。
事实上,顺序一致性很少是程序正确性的必要条件。但是,如果你对其他内存排序方式模棱两可的话,顺序一致性绝对是你正确的选择。程序执行得稍微慢一点总比执行出错要好!将它变为具有更弱一致性的原子操作也很容易,只要把 SeqCst 变成 Relaxed 就完工了!当然,证明这种变化的正确性就是另外一个问题了。
8.3.5、获取释放(Acquire-Release)
获取和释放成对出现,它们适用于获取和释放锁,确保临界区不会重叠。直观来看,Acquire 保证在它之后的访问永远在它之后,可在它之前的操作却有可能被重排序它的后面;Release 保证它之前的操作永远在它之前,但是它后面的操作可能被重排到它前面。
当线程 A 释放了一块内存空间,紧接着线程 B 获取了同一块内存,这时因果关系就确定了。在 A 释放之前的所有写操作的结果,B 在获取之后都能看到。但是,它们和其他线程之间没有确定因果关系。同理,如果 A 和 B 访问的是不同的内存,它们也没有因果关系。
范例:一个简单的自旋锁可能这样实现
use std::sync::Arc;
use std::sync::atomic::{AtomicBool, Ordering};
use std::thread;fn main() {let lock = Arc::new(AtomicBool::new(false)); // value answers "am I locked?"// ... distribute lock to threads somehow ...// Try to acquire the lock by setting it to truewhile lock.compare_and_swap(false, true, Ordering::Acquire) { }// broke out of the loop, so we successfully acquired the lock!// ... scary data accesses ...// ok we're done, release the locklock.store(false, Ordering::Release);
}
在强顺序平台上,大多数的访问都有释放和获取的语义,释放和获取通常是无开销的。不过在弱顺序平台上不是这样。
8.3.6、Relaxed
Relaxed 访问是最弱的,他们可以被随意重排,也没有先后关系,但是 Relaxed 操作依然是原子的。它并不算是数据访问,所有对它的读 - 修改 - 写操作都是原子的。Relaxed 操作适用于那些你希望发生但又并不特别在意的事情。比如,多线程可以使用 Relaxed 的 fetch_add 来增加计数器,如果你不使用计数器的值去同步其他的访问,这个操作就是安全的。
在强顺序平台上使用 Relaxed 没什么好处,因为它们通常都有释放 - 获取语义。不过,在弱顺序平台上,Relaxed 可以获取更小的开销。
九、不使用标准库
我们可以使用 #![no_std] 属性 告诉 Rust 不使用标准库,类似的属性还有如下
- #[lang = “eh_personality”]:被编译器的错误机制使用,不过对于不会触发panic的包装箱可以去定这个函数不会被调用
- #[lang = “start”] : 不使用标准库编写可执行,使用该属性#[start]可以控制程序入口,被标记的函数传递的参数和C一致
- #[lang = “termination”]
- #[panic_implementation]
- #![no_main] 禁用它通过正确 APBI 和正确的名字来创建合适函数;
使用 #[panic_handler] 实现 panic 处理函数
use core::panic::PanicInfo;/// 这个函数将在panic时被调用
#[panic_handler]
fn panic(_info: &PanicInfo) -> ! {loop {}
}
总结
以上就是今天要讲的内容