目录
1. MyBatis 的缓存机制
2. 为什么不默认开启 MyBatis 的二级缓存
3. MyBatis 如何开启二级缓存
4. MyBatis 有哪些缓存清除策略
1. MyBatis 的缓存机制
MyBayis 中包含两级缓存:一级缓存和二级缓存
1. 一级缓存是 SqlSession 级别的,是 MyBatis 自带的缓存功能,默认是开启的,并且无法关闭,所以当有两个 SqlSession 执行相同的 SQL 时,就没有用到一级缓存,而是查询了两次数据库。
2. 二级缓存是 Mapper 级别的,只要是同一个 Mapper,无论使用多少个 SqlSession 进行操作,数据都是共享的,所以多个 SqlSession 可以共享二级缓存。但是 MyBatis 的二级缓存默认是关闭的,需要时可以手动开启。此外,二级缓存还可以使用第三方的缓存,例如:Ehcache。
2. 为什么不默认开启 MyBatis 的二级缓存
为什么不默认开启二级缓存呢 ? 缓存不是可以加速程序的查询性能吗 ?
MyBatis 不默认开启二级缓存的原因有以下几点:
1. 缓存粒度过大:因为二级缓存是一个全局缓存,可以缓存多个不同的查询结果集。默认情况下,MyBatis 是不知道哪些查询结果需要缓存,哪些查询结果不需要缓存。当开启二级缓存后,所有的查询结果都尝试使用缓存,这就可能会导致缓存的数据不准确或者不一致性。

例如上图,三次查询操作查询到的结果可能不一致,此时 MyBatis 默认不知道缓存哪个查询结果,这样就存在缓存不准确的风险。
2. 并发性问题:在多线程情况下,开启二级缓存,如果没有及时清空或刷新缓存,就可能会导致缓存和数据库数据不一致性问题。
此处的并发性问题可以类比到 Redis 和 MySQL 数据不一致性问题 :
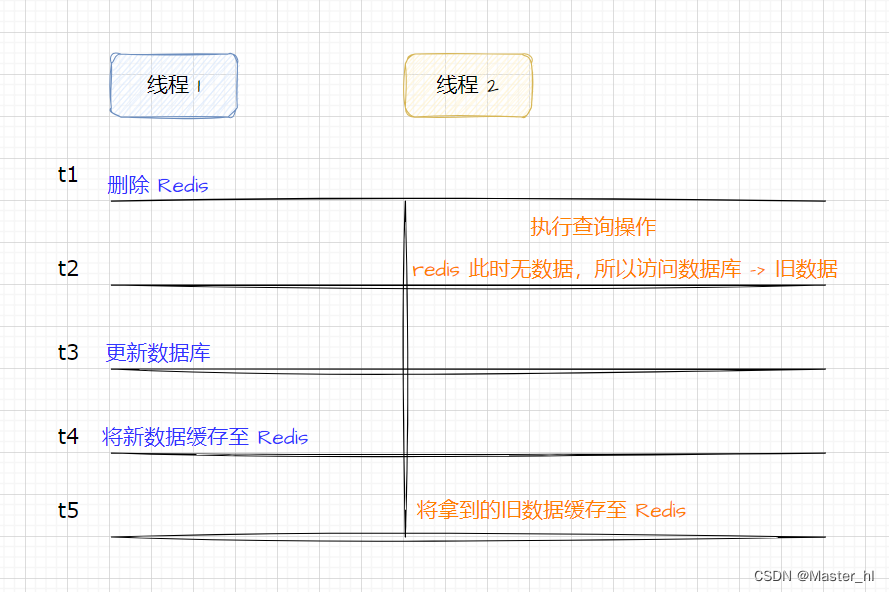
关于多线程情况下的缓存和数据库不一致性问题以及解决方案,可以看我的这篇博客:https://blog.csdn.net/xaiobit_hl/article/details/132453064
3. 内存占用问题:开启二级缓存之后,缓存的数据需要占用大量的内存空间,如果没有合适的策略来管理缓存,可能就会导致内存占用过多的问题。
4. 复杂性问题:二级缓存的配置需要考虑诸多因素,例如:缓存的刷新以及缓存的清理,这都需要较好的缓存策略来处理,这就加大了开发的复杂性,并且有可能引入新的问题。
基于以上问题,MyBatis 选择默认关闭二级缓存,当开发人员确认某些查询可以受益于缓存时,再手动开启二级缓存来使用即可(把主动权交给了开发人员)。
3. MyBatis 如何开启二级缓存
MyBatis 中开启二级缓存需要两步操作:
- 在 mapper 对应的 xml 中添加 <cache> 标签;
- 在 xml 中给需要缓存的标签设置 useCache="true"。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper"><cache/><select id="getAll" resultType="UserInfo" useCache="true">select count(*) from userinfo;</select>
</mapper>进行单元测试:
@SpringBootTest
class UserMapperTest {@Resourceprivate UserMapper userMapper;@Testvoid getAll() {int ret1 = userMapper.getAll();System.out.println("查询结果:" + ret1);int ret2 = userMapper.getAll();System.out.println("查询结果:" + ret2);}
}【说明】
此处在外部方法,调用两次 getAll() 方法,它一定会使用两个 SqlSession,只有在一个 getAll() 方法里面执行两条相同的 SQL 时,才会使用同一个 SqlSession。
如何判断是否走缓存?(properties 文件中配置执行打印 SQL)
- 如果两次查询都打印了 SQL 语句,说明没有走缓存,
- 如果第一次查询打印了 SQL 语句,第二次没有打印,说明第二次查询走的是缓存。
【执行结果】
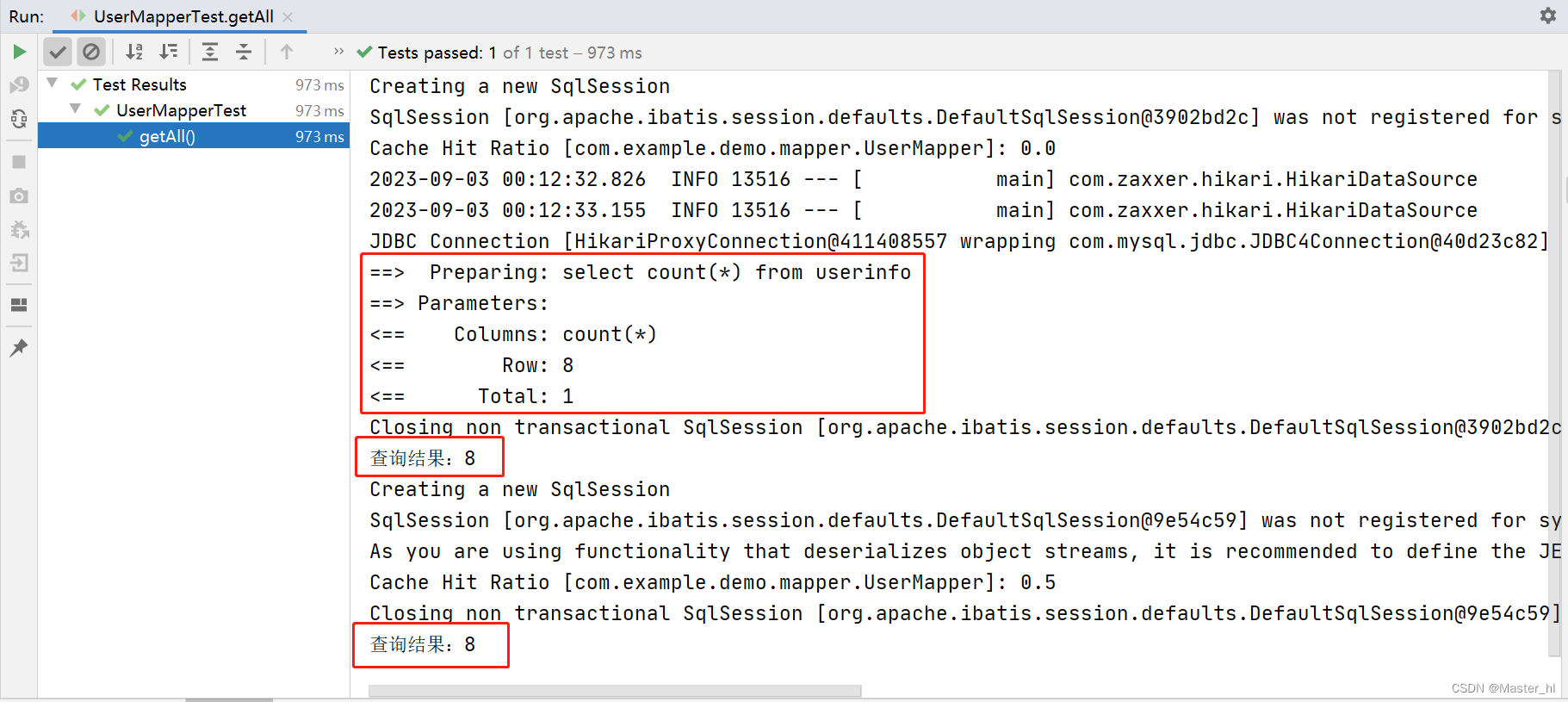
【结果分析】
执行结果很显然,第二次查询走了缓存。虽然调用了两次 getAll() 方法,使用了两个 SqlSession,但是因为我前面开启了二级缓存,二级缓存的作用域是整个 mapper,所以不管是用了几个 SqlSession,第二次查询肯定会走缓存。
如果关闭二级缓存,那么两次查询都会查询数据库(创建了两个 SqlSession,都打印了 SQL),执行结果如下:
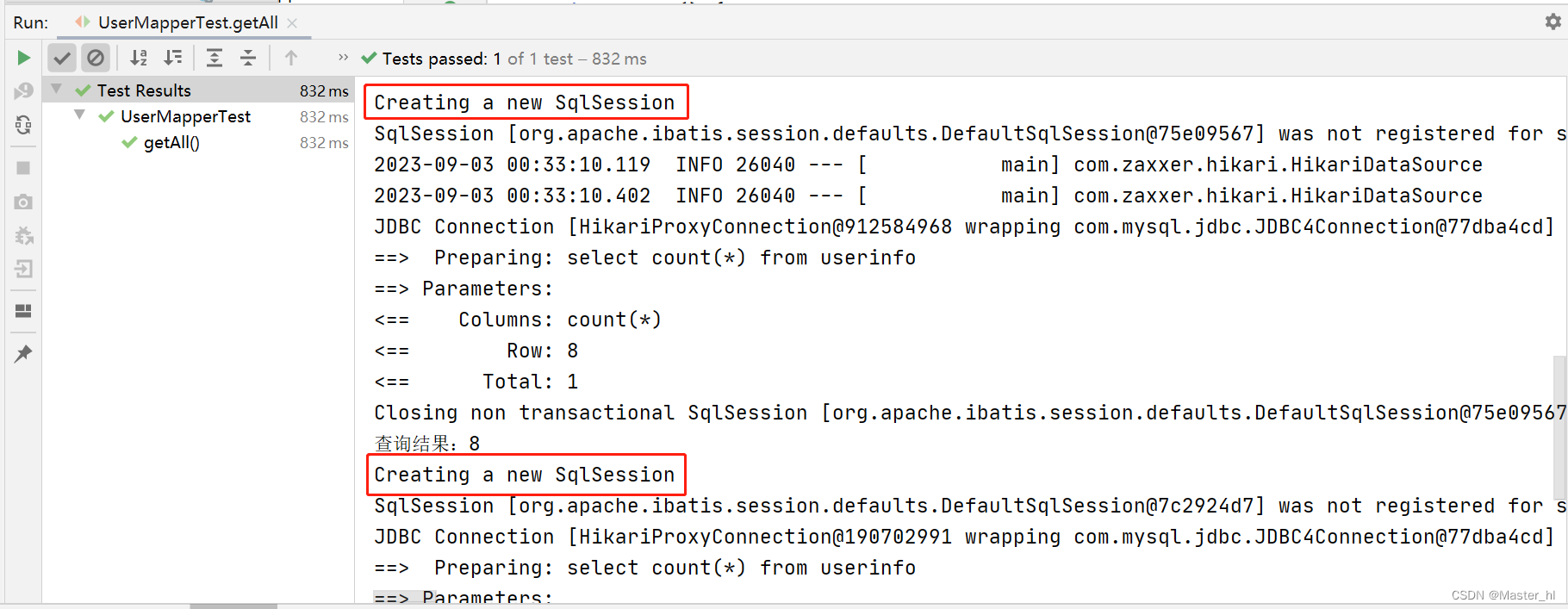
【一级缓存示例】
在关闭二级缓存的情况下,还想使得第二次查询走缓存,可以通过在方法上加一个 @Transactional 注解就可以做到。
当我们在方法上加上 @Transactional 注解的时候,事物里面的所有方法就会使用一个 SqlSession 来进行操作,那么第二次查询也就自然而然会走缓存了。
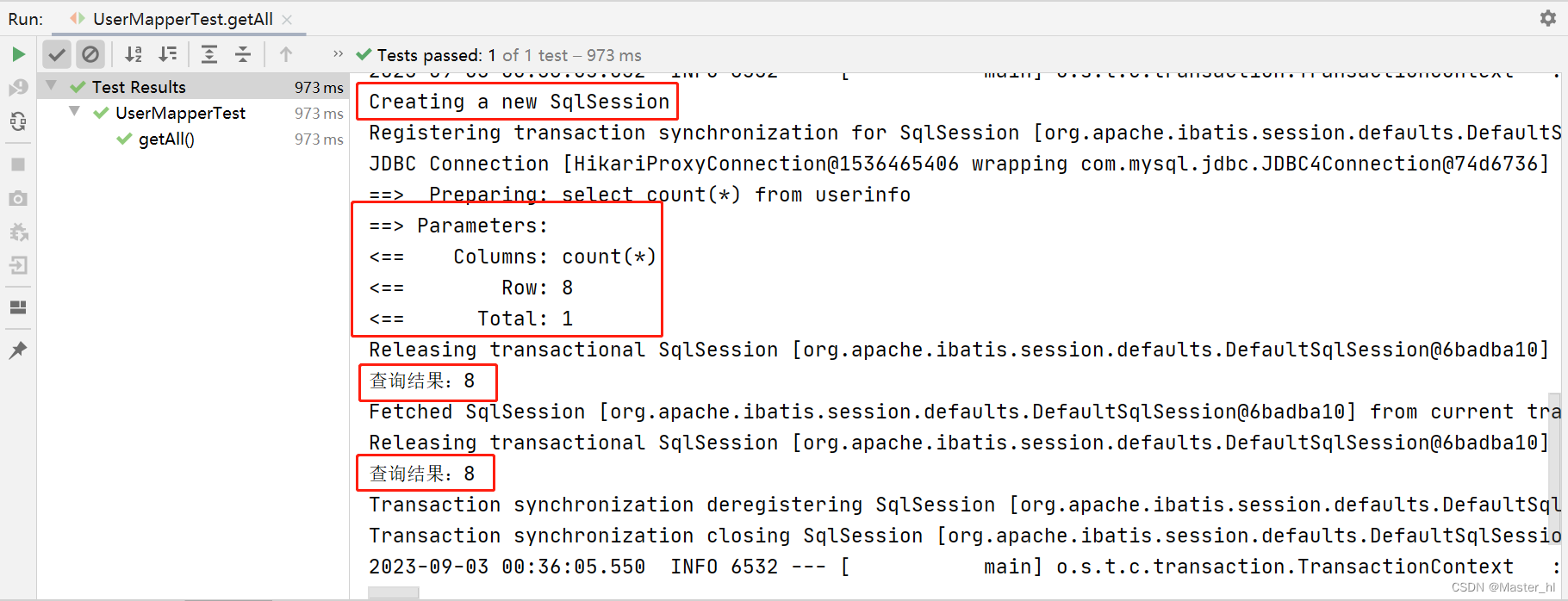
但是这种做法是不推荐的,使用 @Transactional 注解相当于用了新方法解决旧问题,然后又引入了新的问题。@Transactional 底层是基于动态代理来实现的,操作代理对象肯定不如操作原对象的性能好,所以又引入了性能问题。
4. MyBatis 有哪些缓存清除策略
关于 MyBatis 二级缓存的一个补充:
- 使用二级缓存时,所有的 select 语句的结果将会被缓存;
- 所有的 update,insert,delete 语句将会刷新缓存;
- 缓存默认使用 LRU 最近最少使用算法来清除不需要的缓存; -- eviction
- 缓存不会定时刷新,没有刷新间隔; -- flushInterval
- 缓存默认最多保存 1024 个引用; -- size
- 缓存默认被视为读写缓存(prototype),对象不共享,更安全。 -- readOnly
上述这些特性都可以在 <cache/> 标签里进行设置:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>这行设置的意思是缓存使用 FIFO 的清除策略,刷新间隔为 60s,缓存能保存的最大引用数为 512,并且设置只读缓存(单例)。
MyBatis 缓存的清除策略有 4 种可以设置:
- LRU:最近最少使用;
- FIFO:先进先出,按照对象的缓存顺序来清除缓存;
- SOFT:软引用,普通 GC 不回收,触发 Full GC 才回收。
- WEAK:弱引用,触发任何 GC 都会回收,例如:Young GC,Full GC。
对于 LRU 不太理解的,可以看我的这篇博客:https://blog.csdn.net/xaiobit_hl/article/details/132418631
虽然 MyBatis 的缓存看起来非常牛皮,但是它只能在单机架构中花拳绣腿,分布式架构还得看 Redis。