一、说明
在上一篇文章中,我们彻底介绍并检查了 LSTM 单元的各个方面。有人可能会争辩说,RNN方法已经过时了,研究它们是没有意义的。的确,最近一类称为变形金刚[5]的方法已经完全确定了自然语言处理领域。然而,深度学习从未停止让我感到惊讶,包括RNN。也许有一天,我们会看到一个巨大的卷土重来。
二、RNN VS 变压器
请记住,在以下情况下,与变形金刚相比,RNN 仍然是最好的选择:
- 序列长度太长。
- 该任务需要实时控制(机器人),否则下一个时间步长无法先验地获得。
- 没有一个巨大的数据集来利用变压器的迁移学习能力。
- 计算机视觉问题是弱监督(动作识别)。是的。混合CNN-RNN方法,以及连接主义时间分类(CTC)损失[6]仍然非常有效。
了解更多关于RNN的其他原因包括混合模型。例如,我最近遇到了一个模型[4],它产生了真实的实值多维医疗数据系列,它结合了递归神经网络和GAN。所以你永远不知道它们在哪里会派上用场。
无论如何,基本原理是要掌握的。这一次,我们将审查并构建门控循环单元(GRU),作为LSTM的自然紧凑变体。最后,我们将根据问题提供有关使用哪个单元格的多个比较见解。
此处提供了随附的笔记本代码。
三、GRU:简化 LSTM 单元
我们已经看到了LSTM如何能够预测顺序数据。最初引入 LSTM 时出现的问题是参数数量过多。让我们首先说,提出的称为 GRU 的 LSTM 变体的动机是简化参数数量和执行的操作。
在我们进入方程之前,让我们澄清一个重要的事实:LSTM和GRU细胞的原理在长期序列建模方面是常见的。首先,我们可以处理任意数量的时间步长,此外,我们试图洗去多余的信息,并合并存储在权重中的内存组件。存储器由隐藏状态向量引入网络,该向量对于每个输入序列都是唯一的,每次从\(t=0\)的零元素向量开始。
现在,让我们看看略有不同的数学!同样,我们将逐步分析它们。我在这里只是将它们作为一个参考点。为:
![]()
其中 N 是每个时间步的特征长度,而:
![]()
其中 H 是隐藏状态维度,GRU 方程如下:
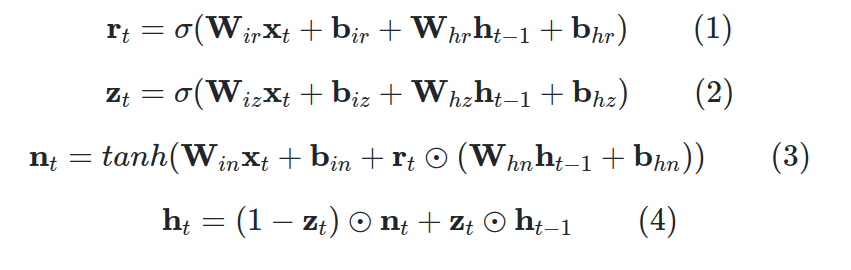
四、公式1:复位门
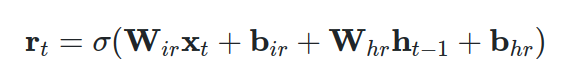
该门与 LSTM 单元的遗忘门非常相似。生成的重置向量 r 表示将确定将从先前隐藏的时间步中删除哪些内容的信息。与遗忘门一样,我们通过逐元素乘法应用遗忘运算,由 Hadamard 乘积运算符表示。我们将重置向量计算为当前时间步的输入向量以及先前隐藏状态的线性组合。
这两种运算都是用矩阵乘法 (nn.PyTorch 中的线性)。请注意,对于第一个时间步,隐藏状态通常是用零填充的向量。这意味着没有关于过去的信息。最后,应用非线性激活(即Sigmoid)。此外,通过使用激活函数(sigmoid),结果位于(0,1)范围内,这说明了训练稳定性。
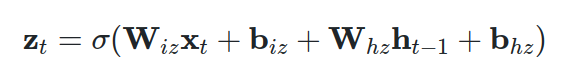
GRU 的输入和输出门在所谓的更新门中的合并就在这里发生。我们计算输入向量 x 和先前隐藏状态的另一种表示,但这次使用不同的可训练矩阵和偏差。向量 z 将表示更新向量。
五、等式3:几乎输出分量
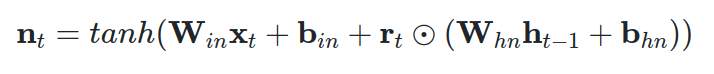
向量 n 由两部分组成;第一个是应用于输入的线性层,类似于 LSTM 中的输入门。第二部分由复位向量 r 组成,应用于先前的隐藏状态。请注意,此处的遗忘/重置向量直接应用于隐藏状态,而不是将其应用于 LSTM 单元的细胞向量 c 的中间表示。
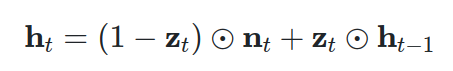
首先,在所描述的方程中,请注意 1 基本上是 0 的向量。由于 z 的值位于 (1,1) 范围内,因此 1-z 也属于同一范围。但是,向量 z 的元素具有互补值。很明显,元素级操作应用于 z 和 (<>-z)。
有时我们通过分析极端情况来理解事物。在极端情况下,假设 z 是 1 的向量。那是什么意思?
简单地说,这意味着输入将被忽略,因此下一个隐藏状态将是前一个状态!在相反的情况下,z 将是零元素向量,这意味着之前的隐藏状态几乎被忽略。重要的是,我使用这个词几乎是因为更新向量 n 在应用重置向量后受到先前隐藏状态的影响。尽管如此,复发几乎就消失了!
直观地,共享向量 z 平衡了先前隐藏状态和更新输入向量 n 的影响。
现在,我为什么选择使用共享的世界作为z变得深刻。以上所有内容都可以在维基百科的下图中说明:
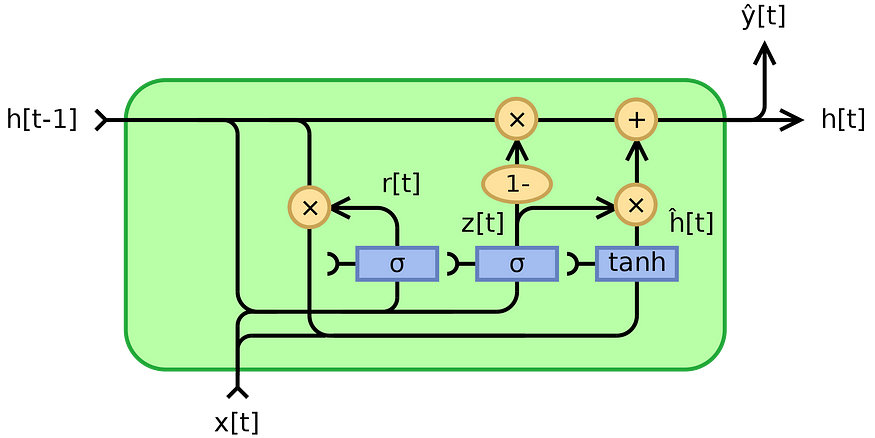
我不是这些图表的忠实粉丝的原因是因为它们可以用标量输入x和h来解释,这至少是误导性的。
第二,不清楚可训练矩阵在哪里。基本上,当你在RNN旅程中考虑这些图表时,试着认为x和h每次使用时都会乘以权重矩阵。
就个人而言,我更喜欢深入研究方程式。幸运的是,数学从不说谎!
简而言之,复位门(r 矢量)确定如何将新输入与以前的存储器融合,而更新门定义剩余多少先前存储器。
这就是您需要知道的全部内容,以便深入了解GRU细胞的工作原理。它们的连接方式(在空间和时间上)与 LSTM 完全相同:
隐藏的输出向量将是下一个 GRU 单元/层的输入向量。
可以通过同时以反向方式处理序列并连接隐藏向量来定义双向。
六、LSTM 与 GRU 细胞:使用哪一个?
GRU单元于2014年引入,而LSTM单元于1997年引入,因此GRU的权衡尚未得到如此彻底的探索。在许多任务中,这两种架构都能产生相当的性能 [1]。通常情况下,超参数的调整可能比选择合适的单元格更重要。但是,最好将它们并排比较。
以下是基本的 5 个讨论点:
- 值得一提的是,这两种架构都是为了解决梯度消失问题而提出的。这两种方法都利用不同的方式将以前的时间步长信息与门融合,以防止梯度消失。然而,LSTM 中的梯度流来自三条不同的路径(门),因此直观地,与 GRU 相比,您会观察到梯度下降的可变性更大。
- 如果您想要更快、更紧凑的模型,GRU 可能是您的选择,因为它们的参数更少。因此,在许多应用程序中,它们可以更快地训练。在序列不太大的小规模数据集中,通常选择GRU细胞,因为数据较少,LSTM的表达能力可能不会暴露出来。从这个角度来看,GRU被认为在更简单的结构方面更有效。
- 另一方面,如果您必须处理大型数据集,LSTM 的更大表达能力可能会带来更好的结果。理论上,LSTM细胞应该记住比GRU更长的序列,并在需要建模长程相关性的任务中优于它们。
- 根据方程,可以观察到GRU单元比LSTM少一个门。准确地说,只是一个复位和更新门,而不是 LSTM 的忘记、输入和输出门。
- 基本上,GRU 单元控制信息流,而不必使用单元存储单元(在 LSTM 方程中表示为 c)。它公开整个内存(与 LSTM 不同),没有任何控制。因此,如果这是有益的,则基于手头的任务。
总而言之,答案在于数据。没有明确的赢家可以说哪一个更好。确定哪一个最适合您的问题的唯一方法是训练两者并分析它们的性能。为此,以灵活的方式构建深度学习项目非常重要。
七、结论
在本文中,我们提供了对 GRU 单元的回顾。我们观察到它的独特特征,我们甚至建立了自己的细胞,用于预测正弦序列。后来,我们比较了LSTM和GRU的侧面。这一次,我们将建议进一步阅读一篇有趣的论文,该论文在自然语言处理的背景下分析GRU和LSTMs[3],由Yin et al. 2017撰写。
我们专注于理解RNN,而不是在更花哨的应用程序中部署它们的实现层。
八、引用
[1] Greff, K., Srivastava, R. K., Koutník, J., Steunebrink, B. R., & Schmidhuber, J. (2016).LSTM:搜索空间之旅。 IEEE Transactions on neural Network and Learning Systems, 28(10), 2222–2232.
[2] Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014).门控递归神经网络在序列建模上的实证评估。arXiv预印本arXiv:1412.3555。
[3] Yin, W., Kann, K., Yu, M., & Schütze, H. (2017).用于自然语言处理的CNN和RNN的比较研究。arXiv预印本arXiv:1702.01923。
[4] Esteban, C., Hyland, S. L., & Rätsch, G. (2017).具有递归条件 GAN 的实值(医学)时间序列生成。arXiv预印本arXiv:1706.02633。
[5] 瓦斯瓦尼, 沙泽尔, 帕尔马, 乌什科雷特, J., 琼斯, L., 戈麦斯, A. N., ...&Polosukhin,I.(2017)。注意力就是你所需要的。神经信息处理系统进展(第5998-6008页)。尼古拉斯·阿达洛格鲁