一、ElasticSearch 向量存储及相似性搜索
在当今大数据时代,快速有效地搜索和分析海量数据成为了许多企业和组织的重要需求。Elasticsearch 作为一款功能强大的分布式搜索和分析引擎,为我们提供了一种优秀的解决方案。除了传统的文本搜索,Elasticsearch 还引入了向量存储的概念,以实现更精确、更高效的相似性搜索。
在 Elasticsearch 中,我们可以将文档或数据转换为数值化向量的方法存入。每个文档被表示为一个向量,其中每个维度对应于文档中的一个特征或属性。这种向量化的表示使得文档之间的相似性计算变得可能。
使用场景:
-
相似文档搜索:通过将文档转换为向量,并使用向量相似性函数,如
dot product或cosine similarity,可以快速找到与查询文档最相似的文档,从而实现精确且高效的相似文档搜索。 -
推荐系统:将用户和商品等表示为向量,可以根据用户的喜好和行为,推荐与其兴趣相似的商品。
-
图像搜索:将图像转换为向量表示,并使用相似性度量,可以在图像库中快速找到与查询图像相似的图像。
下面基于上篇文章使用到的 Chinese-medical-dialogue-data 中文医疗对话数据作为知识内容进行实验。
本篇实验使用 ES 版本为:7.14.0
二、Chinese-medical-dialogue-data 数据集
GitHub 地址如下:
https://github.com/Toyhom/Chinese-medical-dialogue-data
数据分了 6 个科目类型:
数据格式如下所示:

其中 ask 为病症的问题描述,answer 为病症的回答。
由于数据较多,本次实验仅使用 IM_内科 数据的前 5000 条数据进行测试。
三、Embedding 模型
Embedding 模型使用开源的 chinese-roberta-wwm-ext-large ,该模型输出为 1024 维。
huggingface 地址:
https://huggingface.co/hfl/chinese-roberta-wwm-ext-large
基本使用如下:
from transformers import BertTokenizer, BertModel
import torch# 模型下载的地址
model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'def embeddings(docs, max_length=300):tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# 对文本进行分词、编码和填充input_ids = []attention_masks = []for doc in docs:encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_ids.append(encoded_dict['input_ids'])attention_masks.append(encoded_dict['attention_mask'])input_ids = torch.cat(input_ids, dim=0)attention_masks = torch.cat(attention_masks, dim=0)# 前向传播with torch.no_grad():outputs = model(input_ids, attention_mask=attention_masks)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddingsif __name__ == '__main__':res = embeddings(["你好,你叫什么名字"])print(res)print(len(res))print(len(res[0]))
运行后可以看到如下日志:

四、ElasticSearch 存储向量
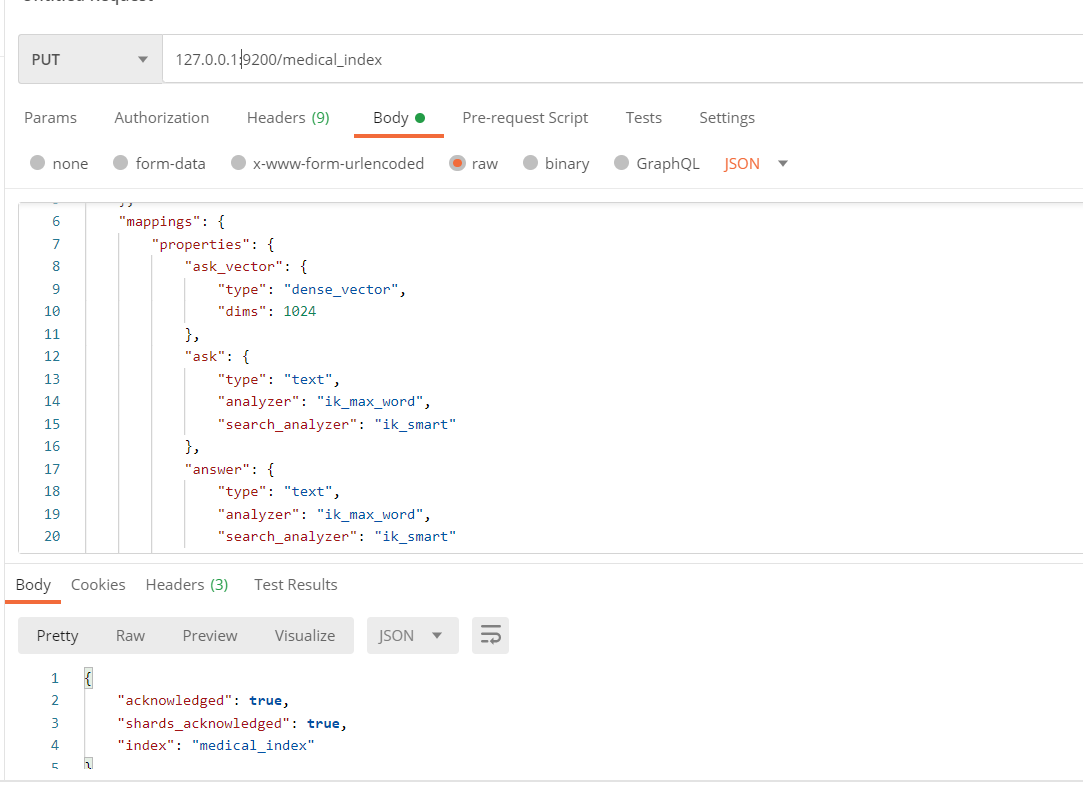
创建向量索引
PUT http://127.0.0.1:9200/medical_index
{"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {"properties": {"ask_vector": { "type": "dense_vector", "dims": 1024 },"ask": { "type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"answer": { "type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"}}}
}
其中 dims 为向量的长度。
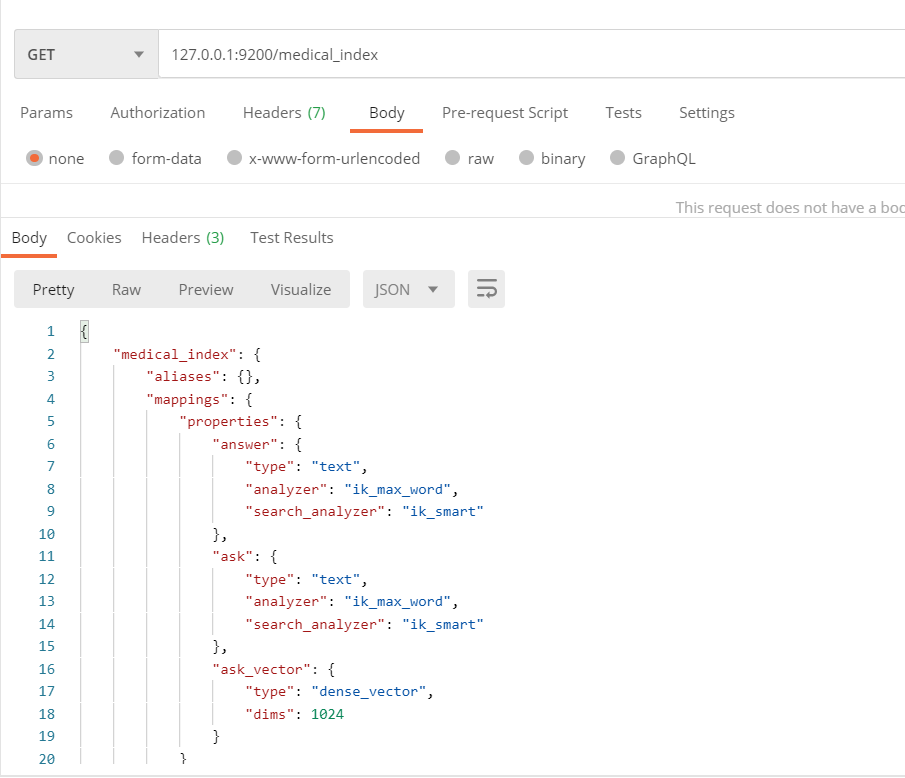
查看创建的索引:
GET http://127.0.0.1:9200/medical_index
数据存入 ElasticSearch
引入 ElasticSearch 依赖库:
pip install elasticsearch -i https://pypi.tuna.tsinghua.edu.cn/simple
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torch
import pandas as pddef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def add_doc(index_name, id, embedding_ask, ask, answer, es):body = {"ask_vector": embedding_ask.tolist(),"ask": ask,"answer": answer}result = es.create(index=index_name, id=id, doc_type="_doc", body=body)return resultdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 数据地址path = "D:\\AIGC\\dataset\\Chinese-medical-dialogue-data\\Chinese-medical-dialogue-data\\Data_数据\\IM_内科\\内科5000-33000.csv"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))# 读取数据写入ESdata = pd.read_csv(path, encoding='ANSI')for index, row in data.iterrows():# 写入前 5000 条进行测试if index >= 500:breakask = row["ask"]answer = row["answer"]# 文本转向量embedding_ask = embeddings_doc(ask, tokenizer, model)result = add_doc(index_name, index, embedding_ask, ask, answer, es)print(result)if __name__ == '__main__':main()
五、相似性搜索
1. 余弦相似度算法:cosineSimilarity
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "cosineSimilarity(params.queryVector, 'ask_vector') + 1.0","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()打印日志如下:

================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。
2. 点积算法:dotProduct
计算给定查询向量和文档向量之间的点积度量。
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "dotProduct(params.queryVector, 'ask_vector')+1.0","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()
================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。
3. L1曼哈顿距离:l1norm
计算给定查询向量和文档向量之间的L1距离。
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "1 / (1 + l1norm(params.queryVector, doc['ask_vector']))","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()
================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。
4. l2 欧几里得距离:l2norm
计算给定查询向量和文档向量之间的欧几里德距离。
from elasticsearch import Elasticsearch
from transformers import BertTokenizer, BertModel
import torchdef embeddings_doc(doc, tokenizer, model, max_length=300):encoded_dict = tokenizer.encode_plus(doc,add_special_tokens=True,max_length=max_length,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')input_id = encoded_dict['input_ids']attention_mask = encoded_dict['attention_mask']# 前向传播with torch.no_grad():outputs = model(input_id, attention_mask=attention_mask)# 提取最后一层的CLS向量作为文本表示last_hidden_state = outputs.last_hidden_statecls_embeddings = last_hidden_state[:, 0, :]return cls_embeddings[0]def search_similar(index_name, query_text, tokenizer, model, es, top_k=3):query_embedding = embeddings_doc(query_text, tokenizer, model)print(query_embedding.tolist())query = {"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "1 / (1 + l2norm(params.queryVector, doc['ask_vector']))","lang": "painless","params": {"queryVector": query_embedding.tolist()}}}},"size": top_k}res = es.search(index=index_name, body=query)hits = res['hits']['hits']similar_documents = []for hit in hits:similar_documents.append(hit['_source'])return similar_documentsdef main():# 模型下载的地址model_name = 'D:\\AIGC\\model\\chinese-roberta-wwm-ext-large'# ES 信息es_host = "http://127.0.0.1"es_port = 9200es_user = "elastic"es_password = "elastic"index_name = "medical_index"# 分词器和模型tokenizer = BertTokenizer.from_pretrained(model_name)model = BertModel.from_pretrained(model_name)# ES 连接es = Elasticsearch([es_host],port=es_port,http_auth=(es_user, es_password))query_text = "我有高血压可以拿党参泡水喝吗"similar_documents = search_similar(index_name, query_text, tokenizer, model, es)for item in similar_documents:print("================================")print('ask:', item['ask'])print('answer:', item['answer'])if __name__ == '__main__':main()
================================
ask: 我有高血压这两天女婿来的时候给我拿了些党参泡水喝,您好高血压可以吃党参吗?
answer: 高血压病人可以口服党参的。党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。感谢您的进行咨询,期望我的解释对你有所帮助。
================================
ask: 我准备过两天去看我叔叔,顺便带些人参,但是他有高血压,您好人参高血压可以吃吗?
answer: 人参有一定的调压作用,主要用来气虚体虚的患者,如果有气血不足,气短乏力,神经衰弱,神经衰弱健忘等不适症状的话,可以适当口服人参调养身体,但是对于高血压的病人,如果长期食用人参的话,可能会对血压引发一定影响,所以,比较好到医院中医科实施辨证论治调治,看如何适合食用人参。
================================
ask: 我妈妈有点高血压,比较近我朋友送了我一些丹参片,我想知道高血压能吃丹参片吗?
answer: 丹参片具备活血化瘀打通血管的作用可以致使血液粘稠度减低,所以就容易致使血管内血液供应便好防止出现血液粘稠,致使血压下降,所以对降血压是有一定帮助的,高血压患者是经常使用丹参片实施治疗的。可以预防,因为血液粘稠引来的冠心病心绞痛以及外周血管脑水肿症状。