目录
1. 广播
2 文件输入和输出
3 随机数生成
4 线性代数操作
5 进阶操作
6 数据分析示例
1. 广播
广播是NumPy中的一种机制,用于在不同形状的数组之间执行元素级操作,使它们具有兼容的形状。广播允许你在不显式复制数据的情况下,对不同形状的数组进行运算。当你尝试对形状不同的数组进行操作时,NumPy会自动调整这些数组的形状,使它们具有兼容的形状,以便进行元素级运算。
广播规则和示例: 广播的规则如下:
- 如果两个数组的维度不同,将维度较小的数组的形状在其前面补1,直到两个数组的维度相同。
- 如果两个数组的形状在某个维度上不一致,但其中一个数组的维度大小为1,那么这个维度的大小将被扩展为与另一个数组相同。
- 如果两个数组在任何维度上的大小都不匹配且没有一个维度的大小为1,则广播操作将失败,引发异常。

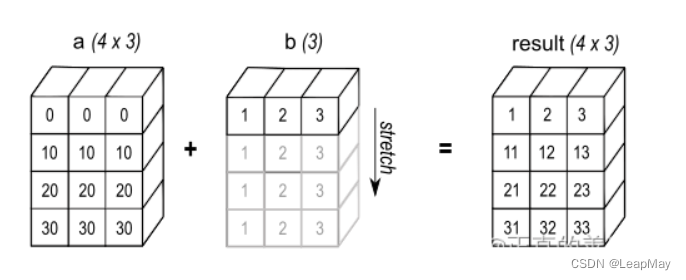
示例:
- 广播规则和示例
import numpy as np# 广播示例1:将标量与数组相乘
scalar = 2
array = np.array([1, 2, 3])
result = scalar * array
print("广播示例1结果:", result) # 输出:[2 4 6]# 广播示例2:将一维数组与二维数组相加
a = np.array([1, 2, 3])
b = np.array([[10, 20, 30], [40, 50, 60]])
result = a + b
print("广播示例2结果:\n", result)
# 输出:
# [[11 22 33]
# [41 52 63]]# 广播示例3:形状不兼容的情况
a = np.array([1, 2, 3])
b = np.array([10, 20])
try:result = a + b
except ValueError as e:print("广播示例3结果(异常):", e)
# 输出:广播示例3结果(异常):operands could not be broadcast together with shapes (3,) (2,)
2 文件输入和输出
读取文本文件:
np.loadtxt():用于从文本文件中读取数据并返回一个NumPy数组。np.genfromtxt():用于从文本文件中读取数据,并根据需要自动处理缺失值和数据类型。
写入文本文件:
np.savetxt():用于将NumPy数组写入文本文件。
读取和写入二进制文件:
np.save():将NumPy数组以二进制格式保存到磁盘文件中。np.load():从磁盘文件中加载保存的NumPy数组。
示例:
import numpy as np# 读取文本文件
data = np.loadtxt('data.txt') # 从文本文件中读取数据# 写入文本文件
np.savetxt('output.txt', data, delimiter=',') # 将数据写入文本文件,使用逗号作为分隔符# 读取和写入二进制文件
arr = np.array([1, 2, 3])
np.save('array_data.npy', arr) # 保存数组到二进制文件
loaded_arr = np.load('array_data.npy') # 从二进制文件中加载数组
3 随机数生成
生成随机数:
np.random.rand():生成均匀分布的随机数数组。np.random.randn():生成标准正态分布(平均值为0,标准差为1)的随机数数组。np.random.randint():生成指定范围内的随机整数。
随机种子:
np.random.seed():用于设置随机数生成器的种子,以确保生成的随机数可重复。
示例:
import numpy as np# 生成随机数
random_numbers = np.random.rand(3, 3) # 生成3x3的均匀分布的随机数数组
standard_normal = np.random.randn(2, 2) # 生成2x2的标准正态分布的随机数数组
random_integers = np.random.randint(1, 10, size=(2, 3)) # 生成2x3的随机整数数组,范围在1到10之间# 设置随机种子以可重复生成相同的随机数
np.random.seed(42)
random_a = np.random.rand(3)
np.random.seed(42) # 使用相同的种子
random_b = np.random.rand(3)
当你使用相同的随机种子值(在上述示例中是42)时,
np.random模块将生成相同的随机数序列。这对于研究、实验和调试非常有用,因为它确保了随机性的可复制性。例如:
import numpy as npnp.random.seed(42)
random_a = np.random.rand(3)# 使用相同的种子值生成相同的随机数序列
np.random.seed(42)
random_b = np.random.rand(3)# random_a 和 random_b 应该是相同的
print(random_a)
print(random_b)
这将产生相同的随机数序列,使得
random_a和random_b的值相等。请注意,如果你在不同地方使用相同的种子值,你将在这些地方生成相同的随机数序列。但是,如果你更改种子值,将生成不同的随机数序列。
随机数生成和随机种子在模拟、机器学习实验以及需要可重复性的应用中非常重要。使用随机种子可以确保你的实验结果是可复制的,而不受随机性的影响。
4 线性代数操作
线性代数在科学计算中起着关键作用,NumPy提供了许多用于处理矩阵和向量的线性代数操作。
- 矩阵乘法:
np.dot()、@运算符- 逆矩阵和伪逆矩阵:
np.linalg.inv()、np.linalg.pinv()- 特征值和特征向量:
np.linalg.eig()- 奇异值分解(SVD):
np.linalg.svd()
矩阵乘法:可以使用 np.dot() 函数或 @ 运算符进行矩阵乘法。
示例:
import numpy as npA = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])result = np.dot(A, B) # 或者使用 result = A @ B
逆矩阵和伪逆矩阵:可以使用 np.linalg.inv() 计算逆矩阵,以及 np.linalg.pinv() 计算伪逆矩阵(当矩阵不可逆时使用伪逆矩阵)。
示例:
import numpy as npA = np.array([[1, 2], [3, 4]])
inverse_A = np.linalg.inv(A)
pseudo_inverse_A = np.linalg.pinv(A)
特征值和特征向量:可以使用 np.linalg.eig() 计算矩阵的特征值和特征向量。
示例:
import numpy as npA = np.array([[1, 2], [2, 3]])
eigenvalues, eigenvectors = np.linalg.eig(A)
奇异值分解(SVD):可以使用 np.linalg.svd() 进行奇异值分解,将矩阵分解为三个矩阵的乘积。
示例:
import numpy as npA = np.array([[1, 2], [3, 4], [5, 6]])
U, S, VT = np.linalg.svd(A)
5 进阶操作
5.1 索引和切片技巧:
NumPy允许使用布尔掩码、整数数组索引等高级索引技巧来访问和修改数组的元素。
基本切片(Basic Slicing):
- 基本切片通过指定开始索引、结束索引和步长来提取数组的子数组。
- 示例:
arr[2:5]提取索引2到4的元素,arr[1:5:2]使用步长提取元素。布尔掩码(Boolean Masking):
- 布尔掩码允许你根据某些条件来选择数组中的元素,条件通常是布尔表达式。
- 示例:
arr[arr > 2]选择大于2的元素。整数数组索引(Integer Array Indexing):
- 使用整数数组作为索引,可以选择或重排数组中的元素。
- 示例:
arr[indices]使用整数数组indices选择指定索引的元素。多维数组切片:
- 对多维数组进行切片时,可以分别指定不同维度的切片条件。
- 示例:
arr2[1:3, 0:2]选择第2和第3行的前2列。
代码示例:
import numpy as np# 基本切片示例
arr = np.array([0, 1, 2, 3, 4, 5])
sub_array1 = arr[2:5] # 提取子数组,结果为 [2, 3, 4]
sub_array2 = arr[1:5:2] # 使用步长,结果为 [1, 3]# 布尔掩码示例
mask = arr > 2
result = arr[mask] # 选择大于2的元素,结果为 [3, 4, 5]# 整数数组索引示例
indices = np.array([0, 2, 4])
result2 = arr[indices] # 使用整数数组索引,结果为 [0, 2, 4]# 多维数组切片示例
arr2 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
sub_array3 = arr2[1:3, 0:2] # 选择第2和第3行的前2列
# 结果为
# [[4, 5],
# [7, 8]]# 输出结果
print("基本切片示例1:", sub_array1)
print("基本切片示例2:", sub_array2)
print("布尔掩码示例:", result)
print("整数数组索引示例:", result2)
print("多维数组切片示例:\n", sub_array3)
5.2 数组排序
NumPy提供了 np.sort() 和 np.argsort() 用于对数组进行排序和返回排序后的索引。
示例:
import numpy as nparr = np.array([3, 1, 2, 4, 5])
sorted_arr = np.sort(arr) # 对数组进行排序
sorted_indices = np.argsort(arr) # 返回排序后的索引
示例1:按值排序
import numpy as nparr = np.array([3, 1, 2, 4, 5])
sorted_arr = np.sort(arr) # 按值升序排序,结果为[1, 2, 3, 4, 5]
示例2:按索引排序
import numpy as nparr = np.array([3, 1, 2, 4, 5])
indices = np.argsort(arr) # 获取按值排序后的索引,结果为[1, 2, 0, 3, 4]
sorted_arr = arr[indices] # 按索引排序,结果为[1, 2, 3, 4, 5]
5.3 结构化数组:
结构化数组允许存储和操作不同数据类型的数据,类似于数据库的表格。
示例:
import numpy as npdata = np.array([(1, 'Alice', 25), (2, 'Bob', 30)],dtype=[('ID', 'i4'), ('Name', 'U10'), ('Age', 'i4')])# 访问结构化数组的元素
print(data['Name']) # 输出['Alice', 'Bob']
6 数据分析示例
我们将加载一个包含学生考试成绩的CSV文件,计算平均分、分数分布和绘制直方图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 加载CSV文件数据
data = pd.read_csv('student_scores.csv')# 提取分数列作为NumPy数组
scores = data['Score'].values# 计算统计信息
mean_score = np.mean(scores)
median_score = np.median(scores)
std_deviation = np.std(scores)# 绘制直方图
plt.hist(scores, bins=10, edgecolor='k', alpha=0.7)
plt.title('Score Distribution')
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.show()# 打印统计信息
print(f"Mean Score: {mean_score}")
print(f"Median Score: {median_score}")
print(f"Standard Deviation: {std_deviation}")
在这个示例中,我们首先使用Pandas库加载CSV文件,然后提取其中的分数列并将其转换为NumPy数组。接下来,我们使用NumPy计算平均分、中位数和标准差。最后,我们使用Matplotlib库绘制了分数的直方图。
这个示例展示了如何使用NumPy与其他库一起进行更复杂的数据分析任务,包括数据加载、计算统计信息和可视化数据。



![[杂谈]-2023年实现M2M的技术有哪些?](https://img-blog.csdnimg.cn/aba543cbcd674f5a86a4f8003b474fa6.webp#pic_center)

