6. 分析查询语句:EXPLAIN(重点)
6.1 概述
定位了查询慢的sQL之后,我们就可以使用EXPLAIN或DESCRIBE 工具做针对性的分析查询语句。DESCRIBE语句的使用方法与EXPLAIN语句是一样的,并且分析结果也是一样的。
MySQL中有专门负责优化SELECT语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的Query提供它认为最优的执行计划(他认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)。
这个执行计划展示了接下来具体执行查询的方式,比如多表连接的顺序是什么,对于每个表采用什么访问方法来具体执行查询等等。MySQL为我们提供了EXPLAIN语句来帮助我们查看某个查询语句的具体执行计划,大家看懂EXPLAIN语句的各个输出项,可以有针对性的提升我们查询语句的性能。
1.能做什么?
●表的读取顺序
●数据读取操作的操作类型
●哪些索引可以使用
●哪些索引被实际使用
●表之间的引用
●每张表有多少行被优化器查询
2. 版本情况
1. MySQL 5.6.3以前只能 EXPLAIN SELECT ;MYSQL 5.6.3以后就可以 EXPLAIN SELECT,UPDATE,DELETE
2. 在5.7以前的版本中,想要显示 partitions 需要使用 explain partitions 命令;想要显示
filtered 需要使用 explain extended 命令。在5.7版本后,默认explain直接显示partitions和
filtered中的信息。
6.2 基本语法
如果我们想看看某个查询的执行计划的话,可以在具体的查询语句前边加一个 EXPLAIN ,就像这样:
mysql> EXPLAIN SELECT 1;
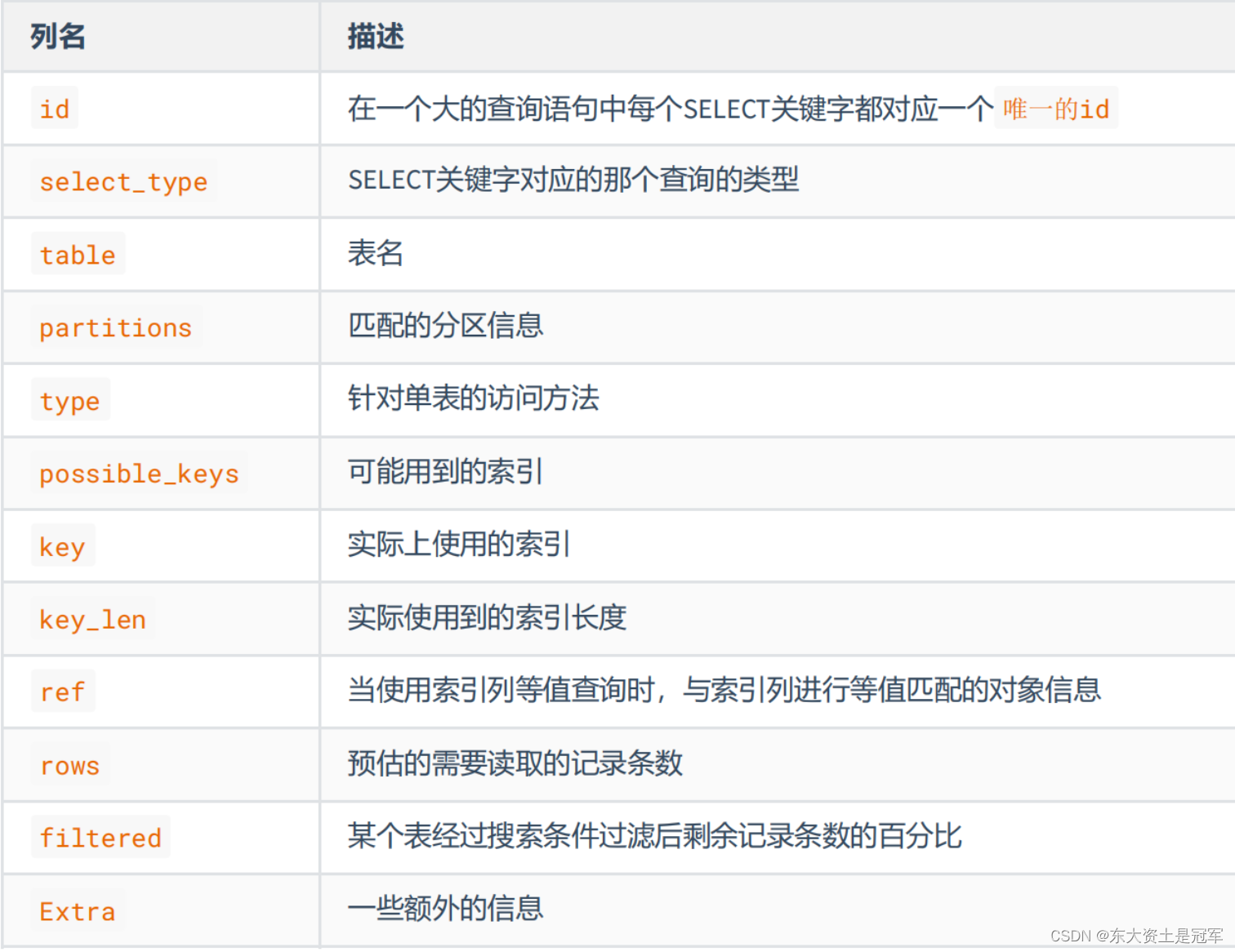
EXPLAIN 语句输出的各个列的作用如下:
6.3 数据准备
1. 建表
表s1首先将id设为主键, 对key1 , key3 建立普通索引, 对key2建立唯一索引, 对key_part1, key_part2, key_part3按顺序建立联合索引
普通字段 common_field
CREATE TABLE s1 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;CREATE TABLE s2 (
id INT AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
INDEX idx_key1 (key1),
UNIQUE INDEX idx_key2 (key2),
INDEX idx_key3 (key3),
INDEX idx_key_part(key_part1, key_part2, key_part3)
) ENGINE=INNODB CHARSET=utf8;2. 设置参数 log_bin_trust_function_creators
创建函数,假如报错,需开启如下命令:允许创建函数设置:
set global log_bin_trust_function_creators=1; # 不加global只是当前窗口有效。
3. 创建函数
DELIMITER //
CREATE FUNCTION rand_string1(n INT)RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGINDECLARE chars_str VARCHAR(100) DEFAULT
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';DECLARE return_str VARCHAR(255) DEFAULT '';DECLARE i INT DEFAULT 0;WHILE i < n DOSET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));SET i = i + 1;END WHILE;RETURN return_str;
END //
DELIMITER ;4. 创建存储过程
创建往s1表中插入数据的存储过程:
DELIMITER //
CREATE PROCEDURE insert_s1 (IN min_num INT (10),IN max_num INT (10))
BEGINDECLARE i INT DEFAULT 0;SET autocommit = 0;REPEATSET i = i + 1;INSERT INTO s1 VALUES((min_num + i),rand_string1(6),(min_num + 30 * i + 5),rand_string1(6),rand_string1(10),rand_string1(5),rand_string1(10),rand_string1(10));UNTIL i = max_numEND REPEAT;COMMIT;
END //
DELIMITER ;创建往s2表中插入数据的存储过程:
DELIMITER //
CREATE PROCEDURE insert_s2 (IN min_num INT (10),IN max_num INT (10))
BEGINDECLARE i INT DEFAULT 0;SET autocommit = 0;REPEATSET i = i + 1;INSERT INTO s2 VALUES((min_num + i),rand_string1(6),(min_num + 30 * i + 5),rand_string1(6),rand_string1(10),rand_string1(5),rand_string1(10),rand_string1(10));UNTIL i = max_numEND REPEAT;COMMIT;
END //
DELIMITER ;5. 调用存储过程
s1表数据的添加:加入1万条记录:
CALL insert_s1(10001,10000);s2表数据的添加:加入1万条记录:
CALL insert_s2(10001,10000);6.4 EXPLAIN各列作用
为了让大家有比较好的体验,我们调整了下 EXPLAIN 输出列的顺序。
1. table
不论我们的查询语句有多复杂,里边儿 包含了多少个表 ,到最后也是需要对每个表进行 单表访问 的,所 以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
2. id
我们写的查询语句一般都以 SELECT 关键字开头,比较简单的查询语句里只有一个 SELECT 关键字 (大多数情况下:出现几个select就有几个id)
特殊情况:
1. 查询优化器可能对涉及子查询的查询语句进行重写, 转变为多表查询的操作:
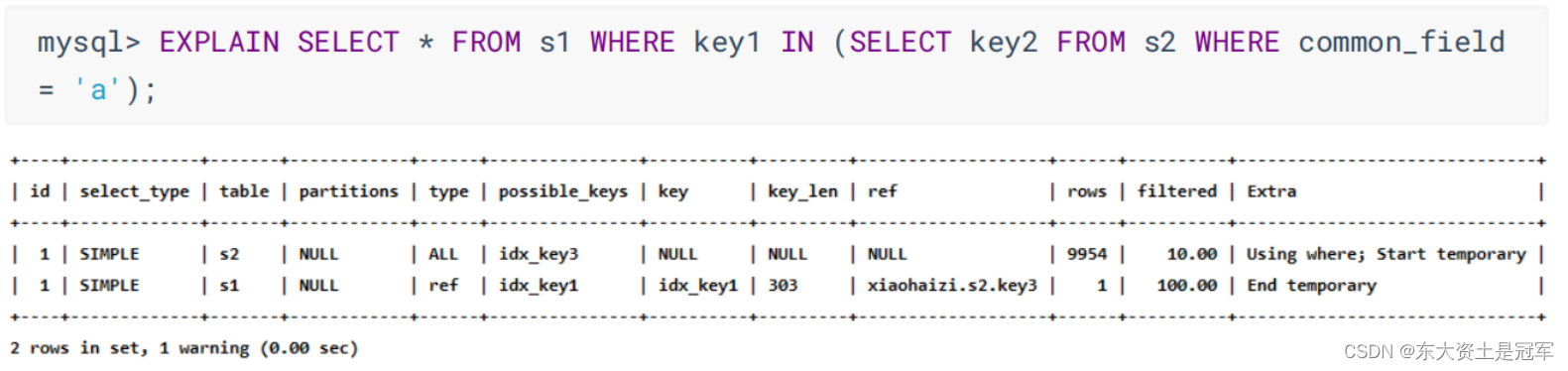
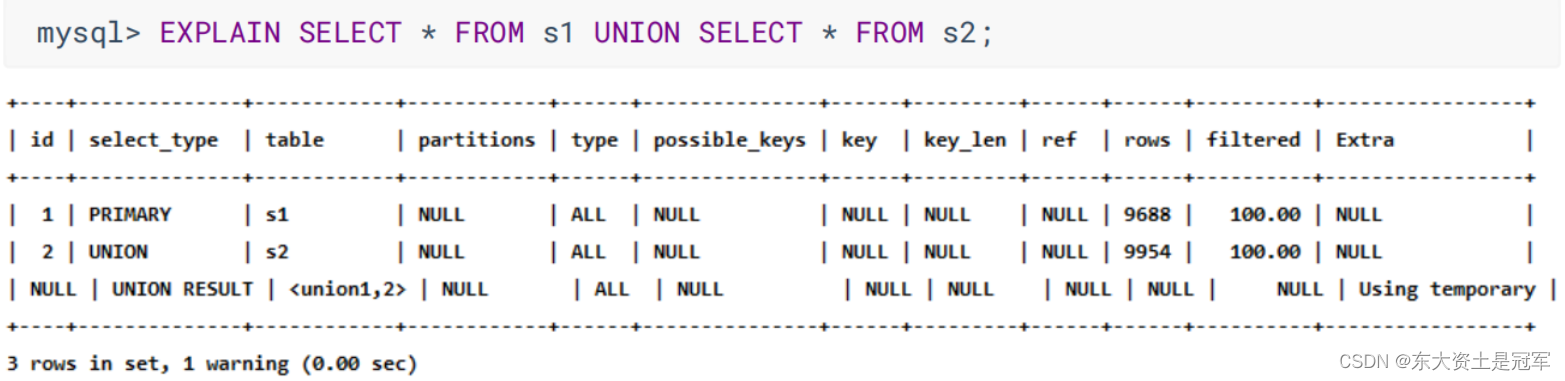
2. Union 去重, 需要创建临时表(第3行), 再在其中去重
Union All 不需要去重 所以不创建临时表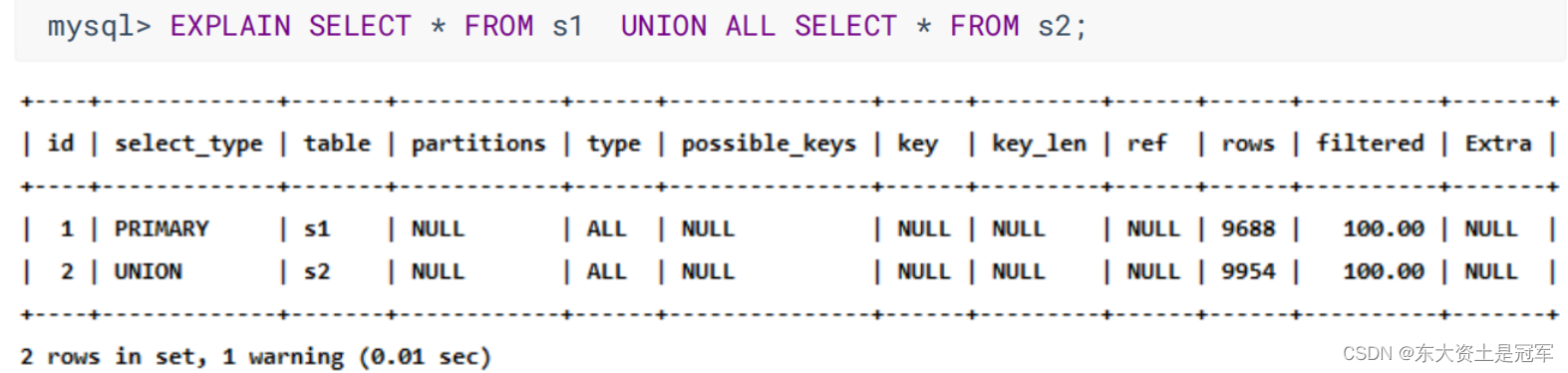
小结:
id如果相同,可以认为是一组,从上往下顺序执行
在所有组中,id值越大,优先级越高,越先执行
关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好
3. select_type
一条大的查询语句里边可以包含若干个SELECT关键字,每个SELECT关键字代表着一个小的查询语句,而每个SELECT关键字的FROM子句中都可以包含若干张表(这些表用来做连接查询),每一张表都对应着执行计划输出中的一条记录,对于在同一个SELECT关键字中的表来说,它们的id值是相同的。
MySQL为每一个SELECT关键字代表的小查询都定义了一个称之为select_type的属性,意思是我们只要知道了某个小查询的select_type属性,就知道了这个小查询在整个大查询中扮演了一个什么角色,我们看一下select_type都能取哪些值,请看官方文档:
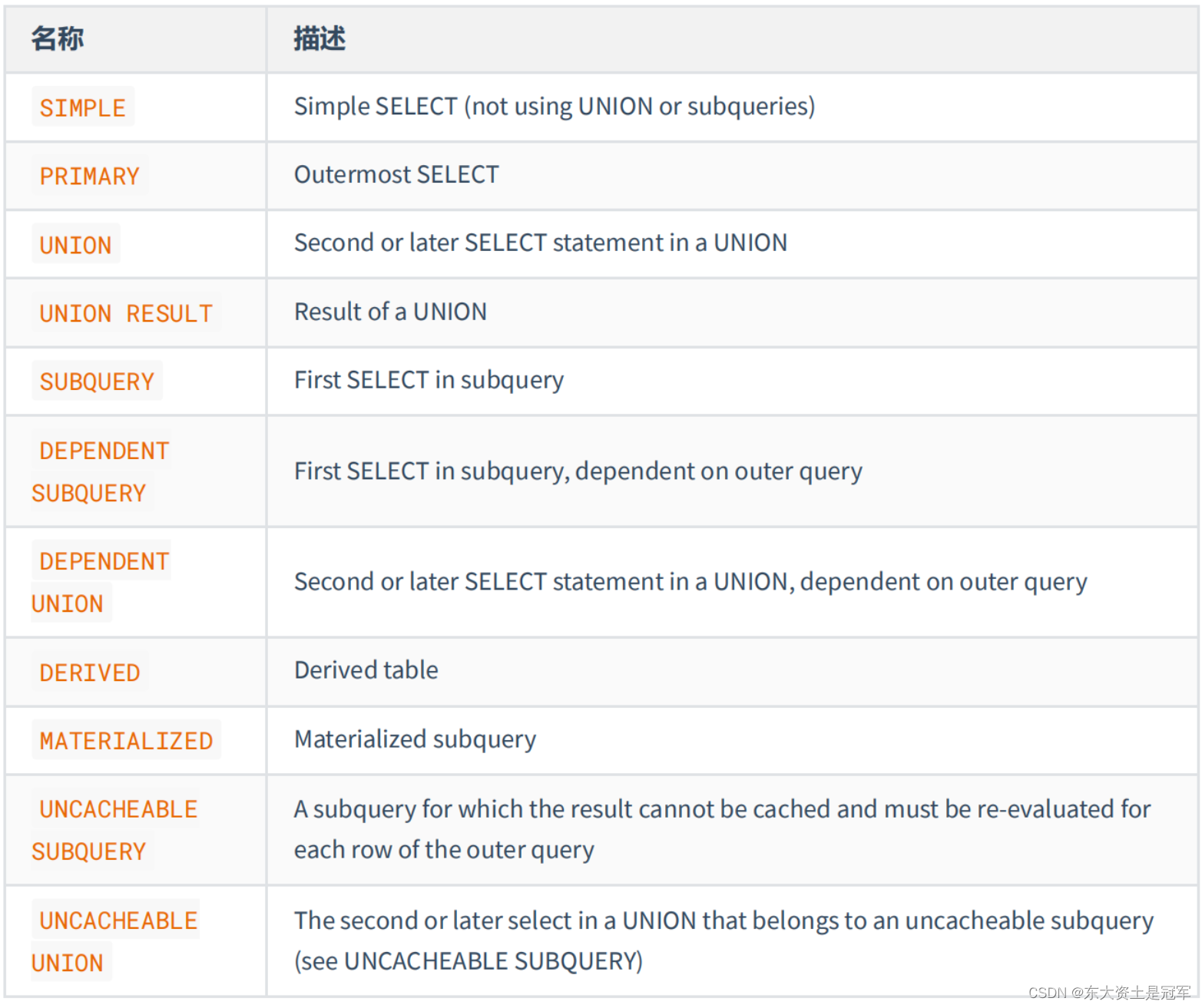
SIMPLE:
查询语句不包含'UNION'或者子查询的查询都算是'SIMPLE'类型

PRIMARY:
对于包含'UNION'或者'UNION ALL' 的大查询来说,, 他是有几个小查询组成的, 其中最左边select_typee'值就是'PRIMARY'
UNION
对于包含'UNION' 或者'UNION ALL'的大查询来说, 除了最左边的查询外, 其余的小查询的'select_type' 值就是'UNION'
UNION RESULT
MysQL 选择使用临时表来完成'UNION'查询的去重工作, 针对该临时表的查询的select_type就是UNION RESULT
mysql> EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2; SUBQUERY
SUBQUERY
包含子查询的查询语句不能转为对应的semi-join 形式, 并且该子查询是不相关子查询,则该子查询的第一个select关键字代表的那个查询select_type 就是SUBQUERY
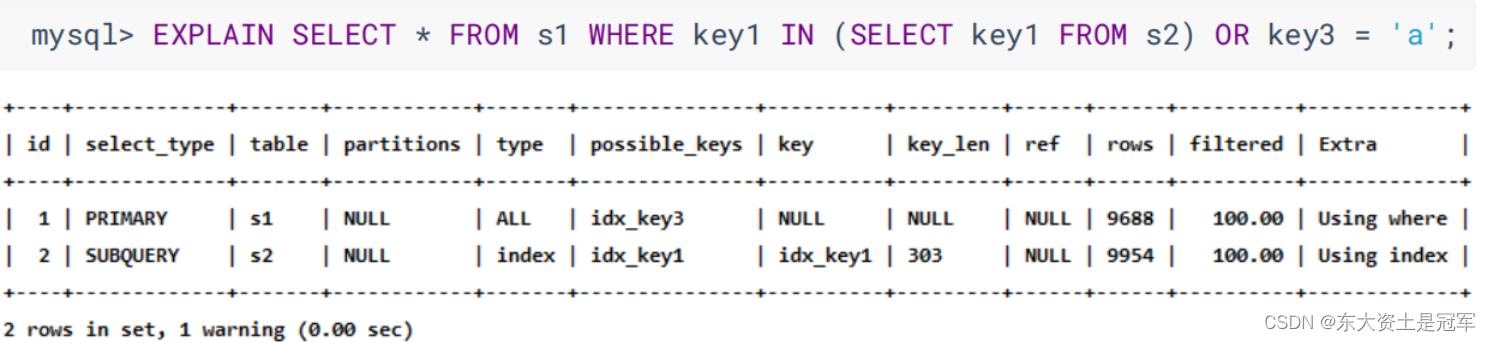
包含子查询的查询语句不能转为对应的semi-join 形式, 并且该子查询是相关子查询,则该子查询的第一个select关键字代表的那个查询select_type 就是DEPENDENT SUBQUERY
 DEPENDENT UNION
DEPENDENT UNION
在包含UINON或者UNION ALL的大查询中, 如果各个小查询都是依赖外层查询的话, 那除了最左边的那个小查询外, 其余的小查询select_type 都是 DEPENDENT UNION

DERIVED
派生表
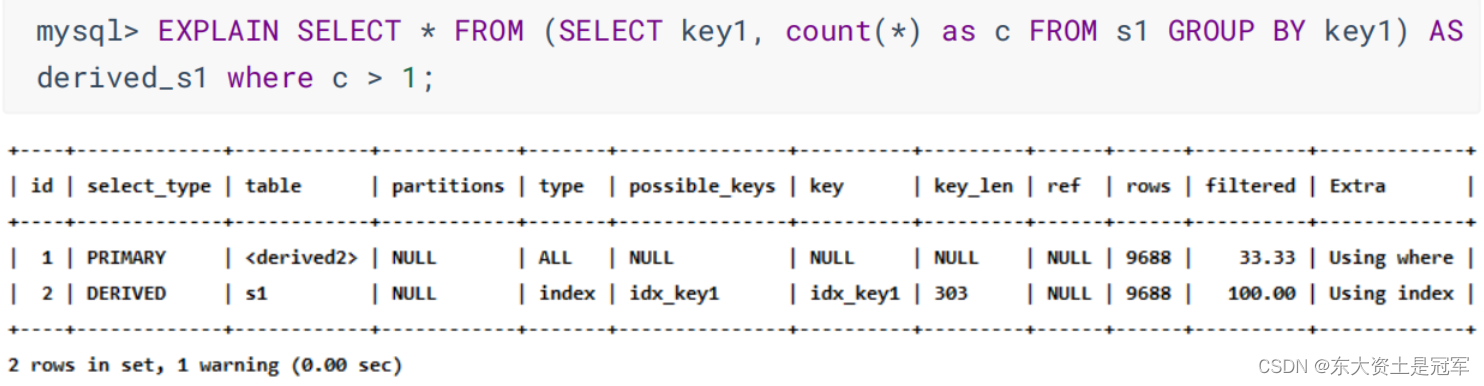
MATERIALIZED
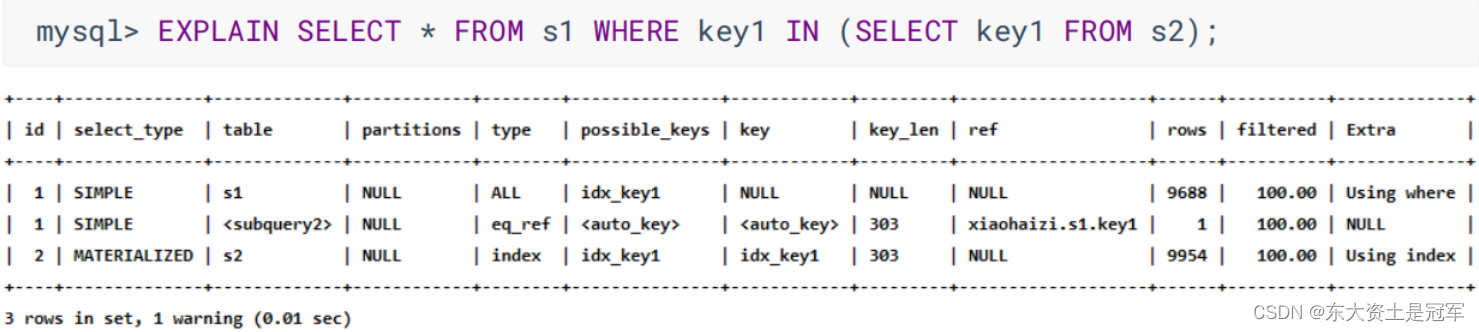
4. type ☆
mysql> CREATE TABLE t(i int) Engine=MyISAM;
Query OK, 0 rows affected (0.05 sec)
mysql> INSERT INTO t VALUES(1);
Query OK, 1 row affected (0.01 sec)mysql> EXPLAIN SELECT * FROM t;
mysql> EXPLAIN SELECT * FROM s1 WHERE id = 10005 ;
 eq_ref
eq_ref
在连接查询时, 如果被驱动表是通过主键或者唯一二级索引等值匹配的方式进行访问的
(如果该主键或者唯一二级索引是联合索引的话, 所有的索引列都必须进行等值比较), 则对该被驱动表的访问方法就是eq_ref
mysql> EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1 .id = s2 .id ;
 从执行计划的结果中可以看出,MySQL打算将s2作为驱动表,s1作为被驱动表,重点关注s1的访问方法是 eq_ref ,表明在访问s1表的时候可以 通过主键的等值匹配 来进行访问。
从执行计划的结果中可以看出,MySQL打算将s2作为驱动表,s1作为被驱动表,重点关注s1的访问方法是 eq_ref ,表明在访问s1表的时候可以 通过主键的等值匹配 来进行访问。
mysql> EXPLAIN SELECT * FROM s1 WHERE key1 = 'a' ;

range
使用索引获取某些范围区间的记录 
index
mysql> EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a' ;
当我们可以使用索引覆盖
mysql> EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3 = 'a';

5. possible_keys和key
可能用到的索引和 实际上使用的索引
6. key_len ☆
实际使用到的索引长度(即:字节数)
![]()

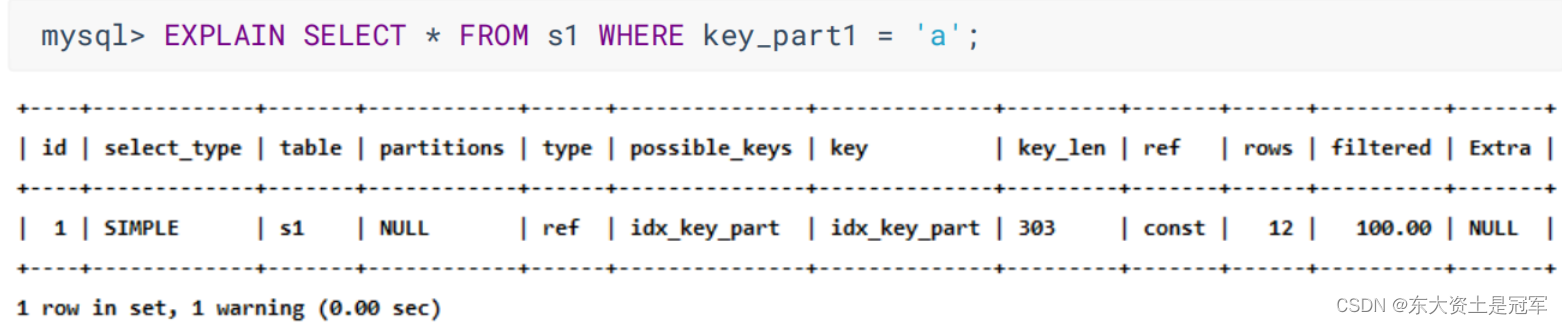
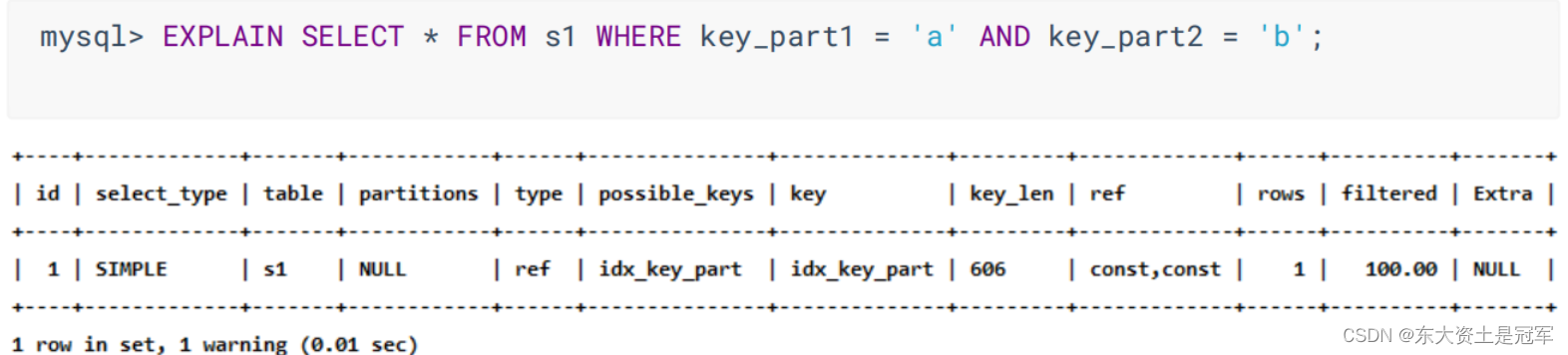
可以看到606 会比303 更好
utf8一个字符占3个字节
303 = 允许长度100 * 3 + 一个字节(null) + 两个字节变长字段
 7. Extra ☆
7. Extra ☆
太多了 不抄了 见书260