诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Improving Language Understanding by Generative Pre-Training
论文下载地址:https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
本文是2018年OpenAI的工作,是初代GPT的原始论文。
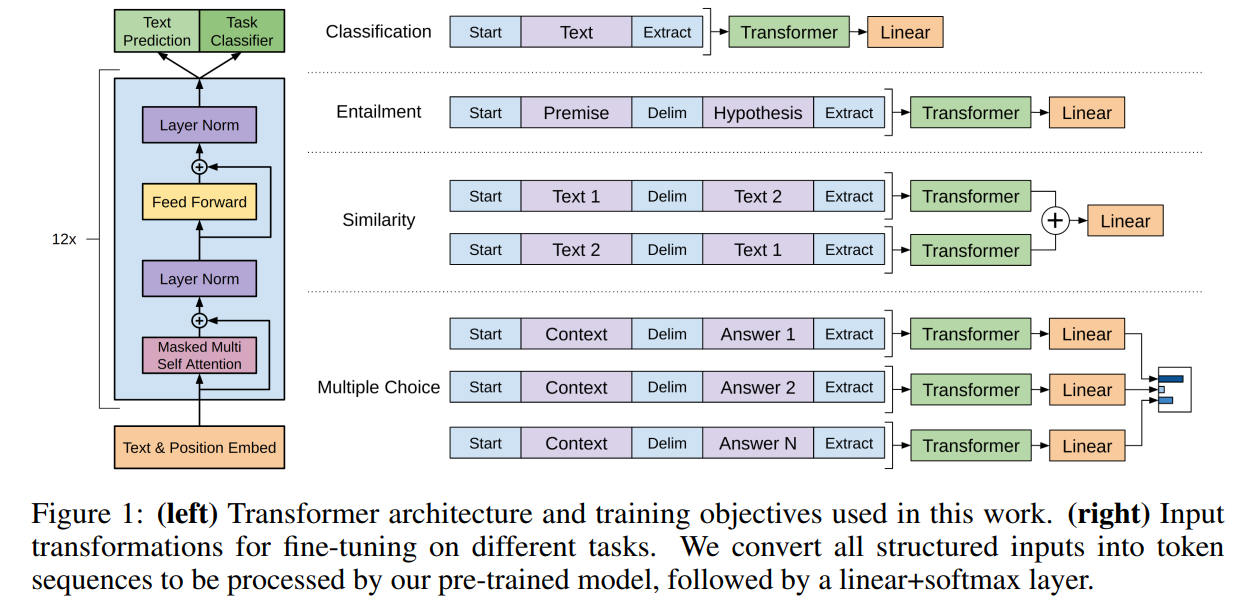
先用无监督数据预训练语言模型(Transformer decoder),再在有监督数据上微调(加一层prediction head,同时优化语言模型和有监督任务的损失函数)
文章目录
- 1. 简介
- 2. GPT-1
- 1. 无监督预训练语言模型
- 2. 微调
- 3. 实验
- 1. 数据集
- 2. 下游任务指标
- 3. 模型分析
1. 简介
NLU任务包括textual entailment, question answering, semantic similarity assessment, and document classification等子任务,本文测试了NLI、QA、语义相似度和文本分类4个任务。
有监督数据稀少,本文的解决方案是在语言模型上用海量无标签数据上进行generative pre-training,然后再在特定子任务上discriminative fine-tuning。
(算半监督学习)
普遍的使用无监督方法来学习语言学知识的方法,是构建预训练词嵌入来提升NLP任务的效果,这种做法有两个问题:1. 在学习文本表征中使用什么优化目标对迁移最有效,不知道。至今没有绝对优秀的方法。2. 如何利用文本表征最有效,不知道。
2. GPT-1
1. 无监督预训练语言模型
标准语言模型目标,最大化文本的似然:
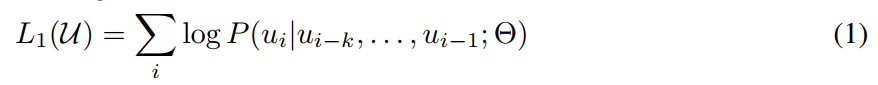
( k k k是上下文窗口尺寸,条件概率 P P P,神经网络的参数 Θ \Theta Θ)
本文用多层Transofmer decoder1(多头自注意力机制+position-wise前馈神经网络生成target token上的输出分布):
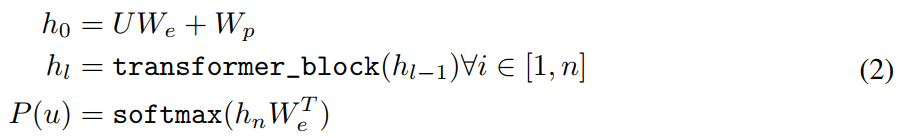
U U U是token, n n n是层数, W e W_e We是token嵌入矩阵, W p W_p Wp是position embedding矩阵
Transformer相比LSTM的优势体验在对长文本的处理上
2. 微调
通过输入(每个任务被转变成不同形式的输入,见figure 1)得到表征,喂进线性输出层来预测 y y y:
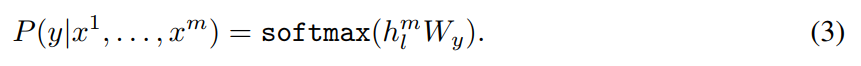
新的优化目标:
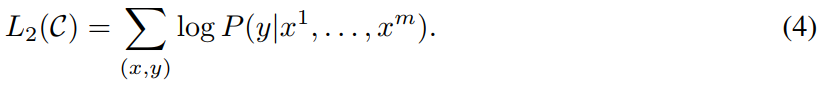
事实上是将两个优化目标加起来:

3. 实验
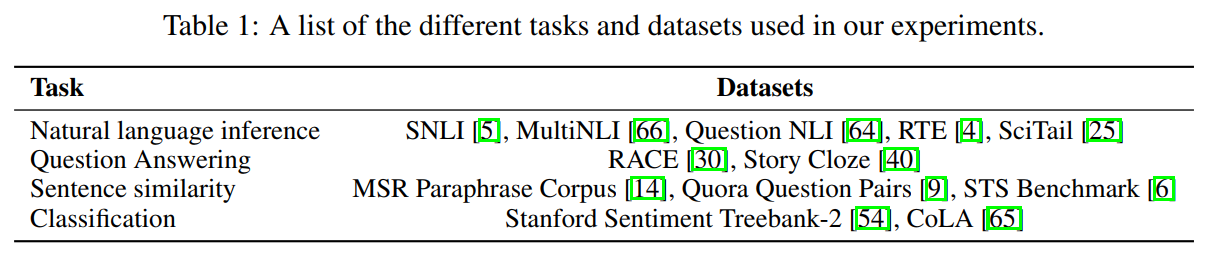
1. 数据集
- 上游预训练数据:BooksCorpus和1B Word Benchmark
- 下游微调数据
2. 下游任务指标
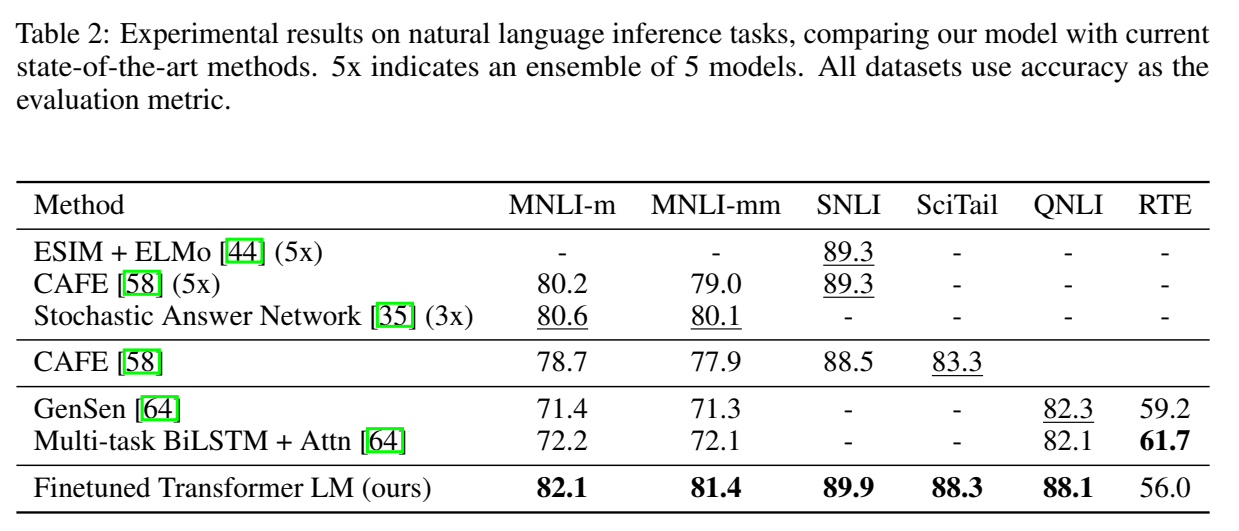
- NLI任务的实验结果
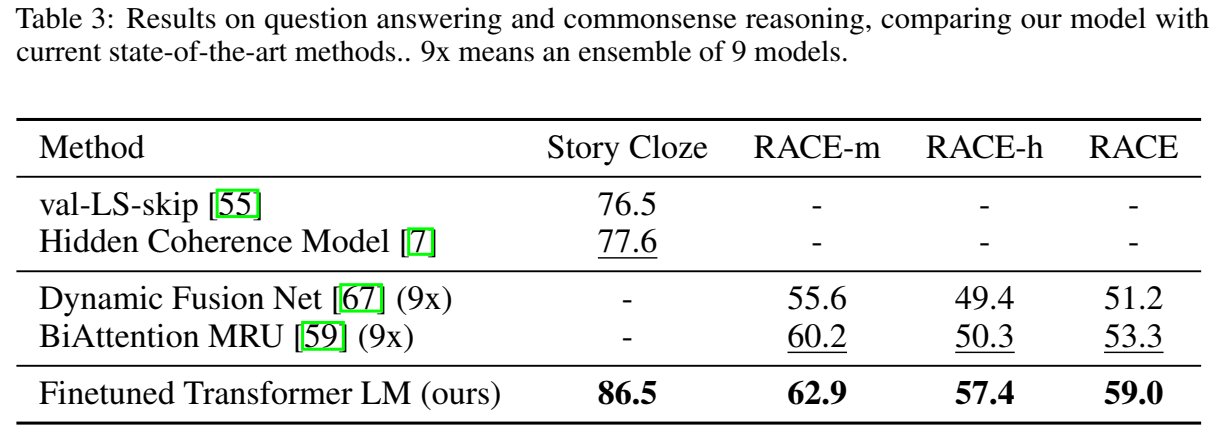
- QA和常识推理的实验结果
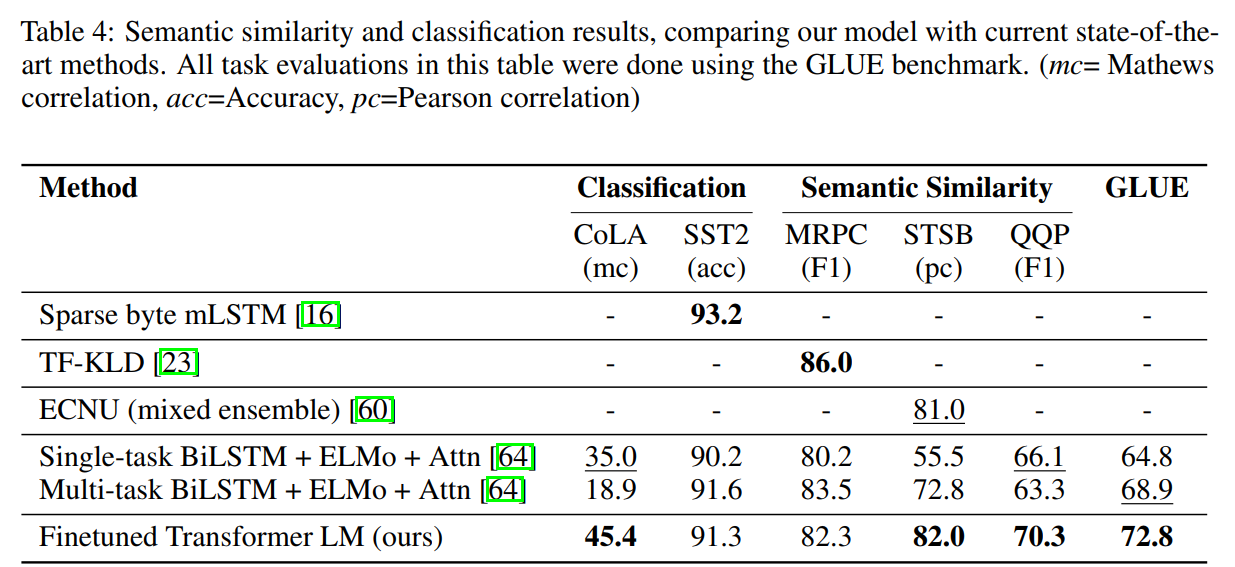
- 语义相似度和文本分类的实验结果
3. 模型分析
- 层数对微调结果的影响(答案是越多越好)和预训练更新次数对zero-shot表现的影响
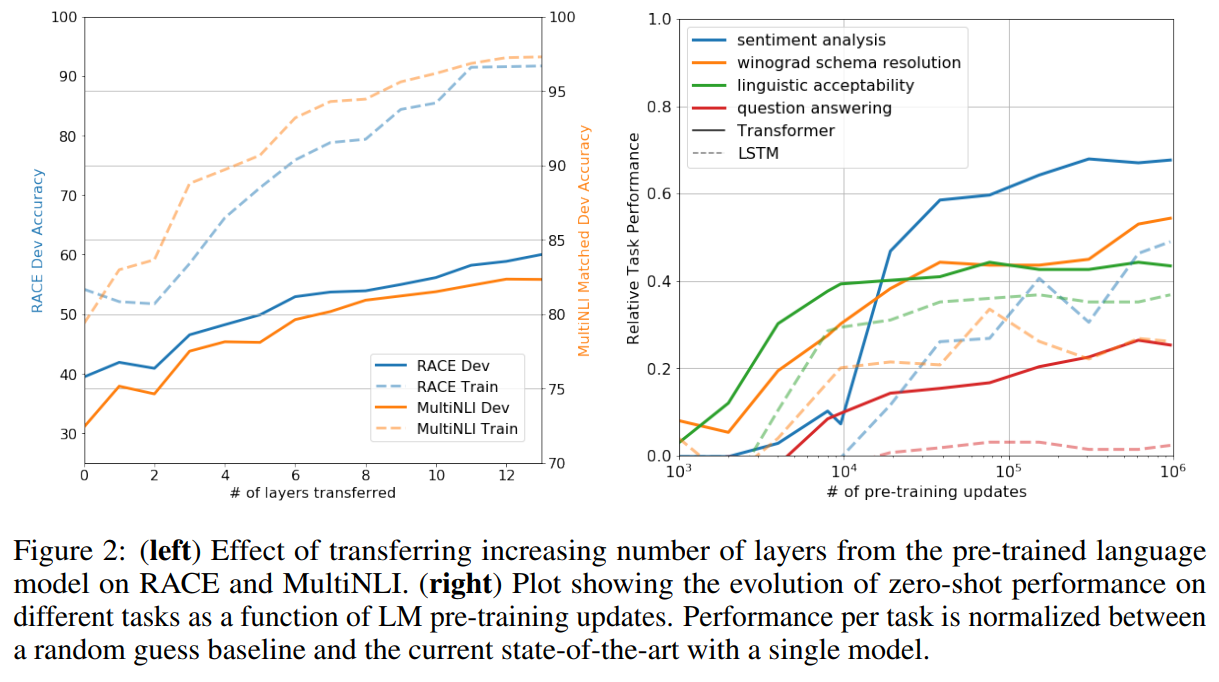
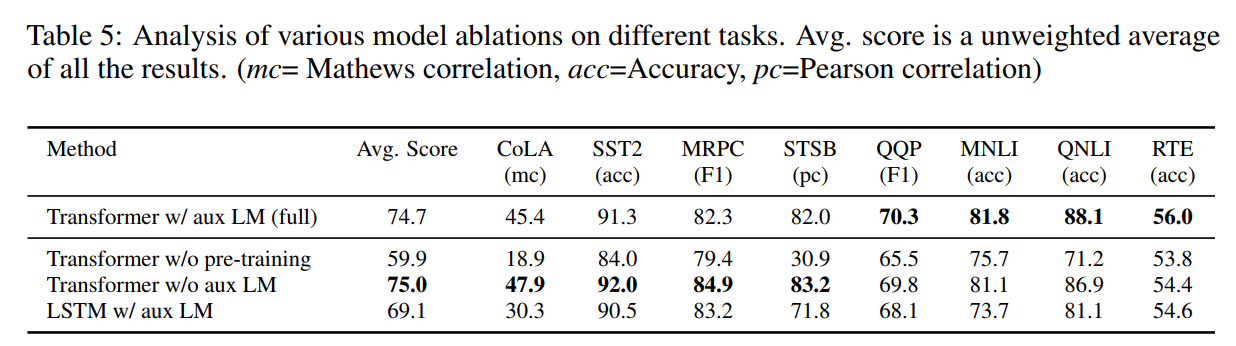
(数值是经规范化后得到的) - ablation study
Generating Wikipedia by Summarizing Long Sequences ↩︎


![java八股文面试[多线程]——CompletableFuture](https://img-blog.csdnimg.cn/img_convert/d039c7beedf24de3dd72bf4118b4fc9f.png)