一、简介
GreenPlum 的数据导入功能作为对数据源的一种扩充,数据导入的方式有:
- 1、insert 该方式通过 sql 语句,把数据一条一条插入至表中。这种方式,不仅读取数据慢(一条一条读取),且数据需要经过 master 节点后再分发给所有 segment,所以 master 制约着导入性能。
- 2、copy 该方式实现了数据的批量读取,但数据依然需要通过 master 节点,所以 master 制约着导入性能,无法实现并行、高效的数据加载。
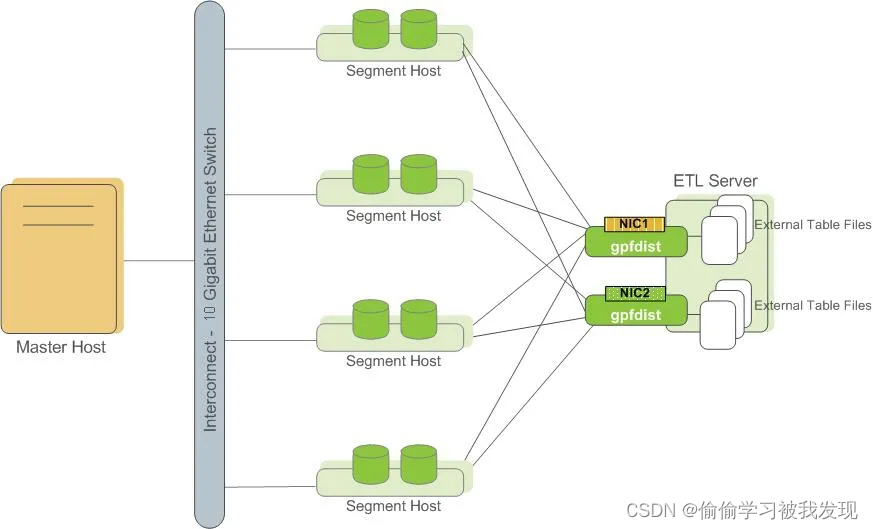
- 3、gpfdist 该方式使用 gpfdist 协议,segment 与 数据源直连,数据读取后直接发送给每个 segment。这种方式,数据不再通过 master,真正实现了数据加载的并行、高效。
gpfdist 是 Greenplum 数据库并行文件分发程序。
它可以被外部表和 gpload 用来并行地将外部表文件提供给所有的 Greenplum 数据库 Segment。
它也可以被可写外部表使用,并行接受来自 Greenplum 数据库 Segment 的输出流,并将它们写出到文件中。
总的来说,可以并行读文件数据,通过 segment 将数据读取至 master 中, 可以并行写文件数据,通过 segment 将数据写入文件中。 gpfdist 本身是单进程单线程程序,所以如果需要实现服务端的并行,需要启动多个 gpfdist 服务。
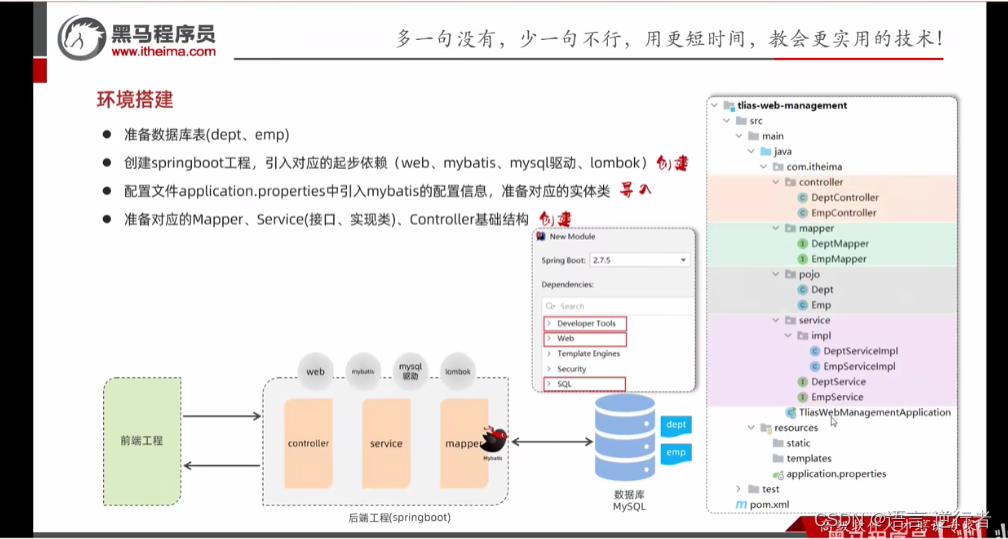
二、架构部署

三、配置与使用
命令格式:
gpfdist [-d <directory>] [-p <http_port>] [-l <log_file>] [-t <timeout>]
[-S] [-w <time>] [-v | -V] [-m <max_length>] [--ssl <certificate_path>]gpfdist [-? | help] | --version
例如:gpfdist -p 9000
参数:
-d <directory> 可以指定工作目录,如果没指定,则为当前目录
-l <log_file> 指定 log 文件,如果没指定,则直接输出到屏幕中
-p <http_port> 指定服务端口,默认是 8080
-m <max_length> 指定最大一行数据的大小,单位是 byte,默认是 32768, 即 32K,可配范围是 32K ~ 256M
-S <use O_SYNC> 写入文件的时候,同步等待数据写入至存盘后再返回
-v 显示详细信息
-V 显示更详细信息,当使用这个 V 时,上面的 v 也会被显示出来
-s 不显示头信息 (这个在 --help 中没有显示,但代码里面是支持的,可以用)
-c 指定一个配置文件,用来执行数据转换的 (这个在 --help 中没有显示,但代码是支持的)
--ssl <certificate_path> 指定 ssl 加密
使用示例
示例中主要使用的是 gpfdist 协议,使用的文件格式主要是 csv。
1、创建只读外部表基本语法
只读外部表
CREATE [READABLE] EXTERNAL [TEMPORARY | TEMP] TABLE table_name ( column_name data_type [, ...] | LIKE other_table )LOCATION ('file://seghost[:port]/path/file' [, ...])| ('gpfdist://filehost[:port]/file_pattern[#transform=trans_name]'[, ...]| ('gpfdists://filehost[:port]/file_pattern[#transform=trans_name]'[, ...])| ('pxf://path-to-data?PROFILE=profile_name[&SERVER=server_name][&custom-option=value[...]]'))| ('s3://S3_endpoint[:port]/bucket_name/[S3_prefix] [region=S3-region] [config=config_file]')[ON MASTER]FORMAT 'TEXT' [( [HEADER][DELIMITER [AS] 'delimiter' | 'OFF'][NULL [AS] 'null string'][ESCAPE [AS] 'escape' | 'OFF'][NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'][FILL MISSING FIELDS] )]| 'CSV'[( [HEADER][QUOTE [AS] 'quote'] [DELIMITER [AS] 'delimiter'][NULL [AS] 'null string'][FORCE NOT NULL column [, ...]][ESCAPE [AS] 'escape'][NEWLINE [ AS ] 'LF' | 'CR' | 'CRLF'][FILL MISSING FIELDS] )]| 'CUSTOM' (Formatter=<formatter_specifications>)[ ENCODING 'encoding' ][ [LOG ERRORS [PERSISTENTLY]] SEGMENT REJECT LIMIT count[ROWS | PERCENT] ]
1.1、 使用csv 文件创建只读外部表示例
只读外部表
指定了csv格式的时候,默认的 分隔符(DELIMITER)为 ‘,’ ,默认的引号值(QUOTE)为 ‘"’,默认的换行符(NEWLINE)为\n。
create external table ext (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv') format 'csv';insert into a select * from ext;create external table ext2 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9000/data2.csv') format 'csv';create external table ext6 (id int, name char(20)) location ('gpfdist://gp_init:9000/data*.csv') format 'csv';create external table ext7 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9001/data2.csv') format 'csv';
查看数据文件与外部表
数据文件的内容
[root@gp_init gpfdist]# cat data.csv
0, asdfghjkl;
1, asdfghjkl;
[root@gp_init gpfdist]# cat data2.csv
0, asdfghjkl;
1, asdfghjkl;
查询外部表
postgres=# select * from ext;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl;
(2 rows)postgres=# select * from ext2;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl; 0 | asdfghjkl; 1 | asdfghjkl;
(4 rows)postgres=# select * from ext6;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl; 0 | asdfghjkl; 1 | asdfghjkl;
(4 rows)postgres=# select * from ext7;id | name
----+----------------------0 | asdfghjkl; 1 | asdfghjkl; 0 | asdfghjkl; 1 | asdfghjkl;
(4 rows)
1.2、使用 pipe管道创建只读外部表示例
只读外部表
gpfdist 支持从管道中读取数据流。
创建一个管道
[root@gp_init gpfdist]# mkfifo gpfdist_pipe
往管道里填写数据
cat data.csv > gpfdist_pipe
创建外部表
create external table ext_pipe(id int, name varchar(30))
location ('gpfdist://gp_init:9000/gpfdist_pipe')
format 'csv';
查询外部表
postgres=# select * from ext_pipe ;id | name
----+-------------0 | asdfghjkl;1 | asdfghjkl;
2、创建可写外部表
2.1、使用csv 文件创建可写外部表示例
目前可写的外部表只支持 gpfdist 协议。
CREATE WRITABLE EXTERNAL [TEMPORARY | TEMP] TABLE table_name( column_name data_type [, ...] | LIKE other_table )LOCATION('gpfdist://outputhost[:port]/filename[#transform=trans_name]'[, ...])| ('gpfdists://outputhost[:port]/file_pattern[#transform=trans_name]'[, ...])FORMAT 'TEXT' [( [DELIMITER [AS] 'delimiter'][NULL [AS] 'null string'][ESCAPE [AS] 'escape' | 'OFF'] )]| 'CSV'[([QUOTE [AS] 'quote'] [DELIMITER [AS] 'delimiter'][NULL [AS] 'null string'][FORCE QUOTE column [, ...]] | * ][ESCAPE [AS] 'escape'] )]| 'CUSTOM' (Formatter=<formatter specifications>)[ ENCODING 'write_encoding' ][ DISTRIBUTED BY ({column [opclass]}, [ ... ] ) | DISTRIBUTED RANDOMLY ]
创建可写外部表
create writable external table extw (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv')format 'csv';create writable external table extw2 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9000/data2.csv') format 'csv';create writable external table extw3 (id int, name char(20)) location ('gpfdist://gp_init:9000/data.csv', 'gpfdist://gp_init:9001/data2.csv') format 'csv';
插入数据
postgres=# create table abc(id int, name char(20));
postgres=# insert INTO abc select * from ext;
postgres=# select count(*) from abc;count
--------100000
(1 row)-- 写入文件
-- 基本上是会把数据平局分给各个文件里。
postgres=# insert INTO extw select * from abc ;
INSERT 0 100000
[root@gp_init gpfdist]# wc -l data.csv
100000 data.csvpostgres=# insert INTO extw2 select * from abc ;
INSERT 0 100000
[root@gp_init gpfdist]# wc -l data.csv data2.csv 50171 data.csv49829 data2.csv100000 totalpostgres=# insert INTO extw3 select * from abc ;
INSERT 0 100000
[root@gp_init gpfdist]# wc -l data.csv data2.csv 50135 data.csv49865 data2.csv100000 total
2.2、使用 pipe管道创建可写外部表示例
创建可写外部表
create writable external table extw4 (id int, name char(20)) location ('gpfdist://gp_init:9000/gpfdist_pipe') format 'csv';
-- 执行写入操作
postgres=# insert INTO extw4 select * from abc;
[root@gp_init opt]# bash read.sh gpfdist_pipe
100000
主要函数代码解析
1、main
- gpfdist_init :所有的处理都是在 gpfdist_init 函数中。
- gpfdist_run:只有一个 event_dispatch。
2、gpfdist_init
- 命令行输入参数解析:parse_command_line。
- 注册信号处理signal_register:对信号的处理。捕获 SIGTERM 信号,设置最高优先级,注册 process_term_signal 回调函数,在回调函数中,关闭所有 socket 后,退出。
- http服务配置http_setup:
- 先根据配置的端口,获取地址信息,然后对地址进行端口绑定。这里获取的地址信息包含两个:ipv4 地址 和 ipv6 地址。gpfdist 优先使用ipv6进行绑定,因为IPv6的监听套接字能够同时监听v4客户端和v6客户端。
- 遍历所有可用的套接字,设置监听事件:EV_READ | EV_PERSIST(持久属性),设置优先级,并绑定回调函数:do_accept。可用套接字个数保存在 gcb.listen_sock_count 中,可用的 socket 保存在 gcb.listen_socks 数组中。
- do_accept:对请求进行 accept,记录了自己 accept 产生的 socket(r->sock),client 的 port(r->port),并对socket设置一些属性,例如:keepalive、reuseaeddr 等。
- 并调用 setup_read 设置read事件。
- setup_read设置可读事件的回调函数:do_read_request,并判断该请求中是否带 timeout 参数:
- 如果没带 timeout 参数,则是普通请求,不需要设置 timeout。
- 如果带 timeout 参数,则是超时事件,需要重新设置超时参数。
- setup_read设置可读事件的回调函数:do_read_request,并判断该请求中是否带 timeout 参数:
- 看门狗初始化:watchdog_thread。
3、do_read_request
如果是超时事件,则直接发送http_end,后续会关闭连接。
读取socket,如果是返回0,发送 http_end。
- gnet_parse_request :解析出请求的方法,以及后面跟的参数
- request_validate :检测请求参数是否正确:必须是GET或POST,且使用协议必须是 HTTP/1.xx。
- percent_encoding_to_char :检测path中的字符是否存在 %XX 的格式,如果有,则转化为 char 类型的字符。
如果 path 为 “/gpfdist/status”,则直接返回 send_gpfdist_status。(该请求作为 debug 使用) - request_set_path: 将 path 相对路径转换为绝对路径。
- request_parse_gp_headers:解析 header 中的信息,比如 xid / cid / sn / segcount / csvopt 等。
- request_set_transform : 执行 transform 转换。
- session_attach:根据文件名和 TID (由 xid/cid/sn 生成) 创建一个会话,对文件的处理都在会话中处理。根据 tid 和 path 组成 key,从 hash 表中获取该 session,如果没有则进行创建。如果 session 中没获取到 fstream,则直接返回错误。
如果是 GET,则通过 handle_get_request 函数增加写事件监听(被监听的 fd 是在 do_accept 函数中 accept的 fd),如果是 POST,则调用 handle_post_request 函数。 - do_write:
- 1、如果上次读取的数据,都已经发送完成了(通过 block_t 里面的 bot == top 来判断),则再通过 session_get_block 读取一个 block。
- 2、如果 gp_proto 的协议号为 1,则调用 local_send:发送头部数据,即 blockhdr_t 中的 hbyte
- 3、调用 local_send:再发送真正的数据,即 block_t 中的 data
- 4、通过 setup_write,再次添加当前 fd 的写事件
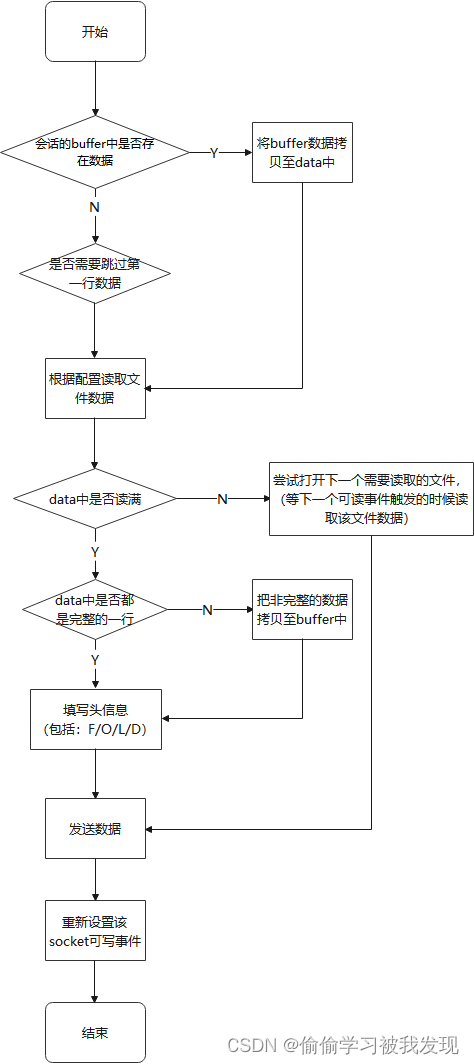
数据读取示意图
学习记录,原文

![[git]分支操作](https://img-blog.csdnimg.cn/e657096b5ae5490396a54cb60e213701.png)