点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者介绍

梁志烜
香港大学计算机系直博一年级学生,导师为罗平教授,研究兴趣是生成式机器学习,Embodied AI和Data-centric learning。
报告题目
作为自适应自进化规划器的扩散模型
内容简介
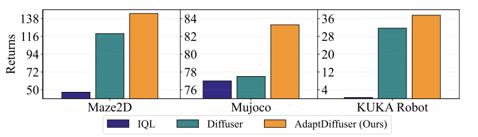
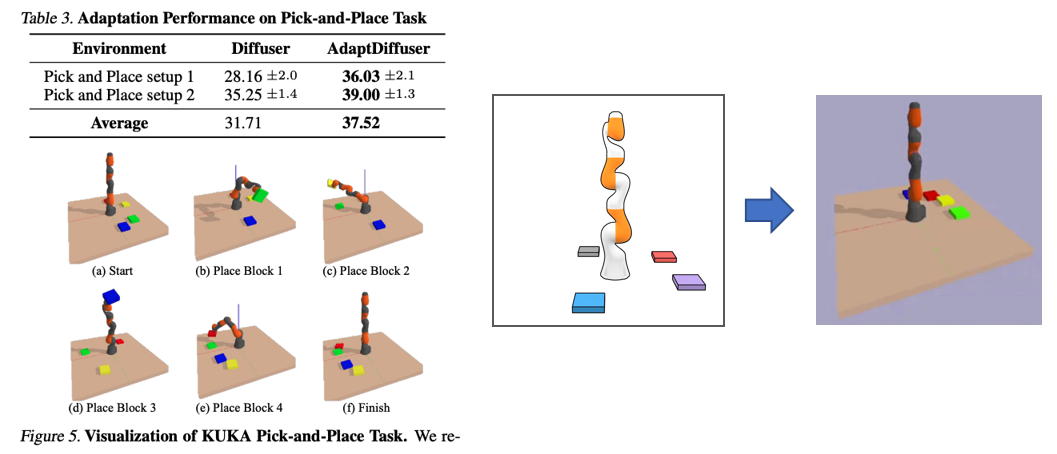
扩散模型已经在许多任务中展示了其作为生成模型的强大能力,进而具有作为离线强化学习范式的巨大潜力。然而,扩散模型的质量受到训练数据多样性不足的限制。这制约了扩散模型在规划任务上的性能,同时阻碍了其对新任务的泛化性。本文首次提出AdaptDiffuser,一种基于扩散模型的自进化规划方法,它可以自我进化以提升扩散模型的性能,从而使之成为更好的规划器,不仅适用于已见过的任务,而且还可以迁移到未见的任务。我们的方法AdaptDiffuser首先使用奖励(reward)的梯度作为指引,为目标条件任务生成丰富的综合专家数据。然后,它通过判别器选择高质量数据来微调扩散模型,从而提高扩散模型对未见过的任务的泛化能力。我们在KUKA工业机械臂和Maze2D两个基准环境中和两个精心设计的未见过的任务上进行了实证实验,证明了AdaptDiffuser的有效性。例如,在Maze2D上AdaptDiffuser比之前的Diffuser [1]性能高出20.8%,在MuJoCo上比之前的Diffuser性能高出7.5%,而且AdaptDiffuser能够更好地适应新任务,在KUKA拾取任务中,在没有额外专家数据的情况下AdaptDiffuser的性能相较于Diffuser提高了27.9%。
代码链接:https://adaptdiffuser.github.io/
论文链接:https://arxiv.org/pdf/2302.01877.pdf
01
Background
自DDPM在2021年底被提出用于建模图像生成过程之后,扩散模型一直是最强有力的生成模型,包括Midjourney在内的扩散模型表现出十分强大的性能。深度生成模型的难点在于如何去应对高维数据的联合概率分布,从而进行表征学习和判断。在扩散模型被提出之前,VAE、规整流、对抗生成网络等多项工作都对生成模型进行了探索。
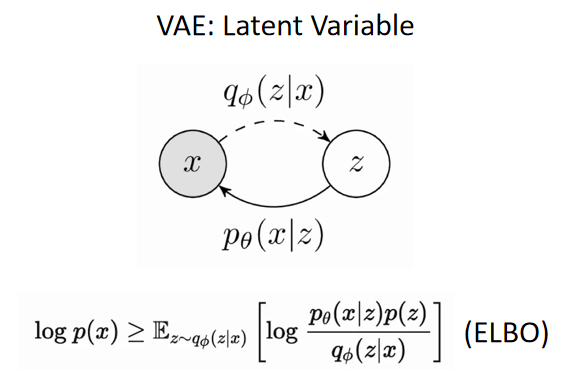
VAE通过学习一个编码器和解码器试图将实际的图像数据建模到潜变量的空间中,然后我们通过学习和采样潜变量恢复出原始图像。
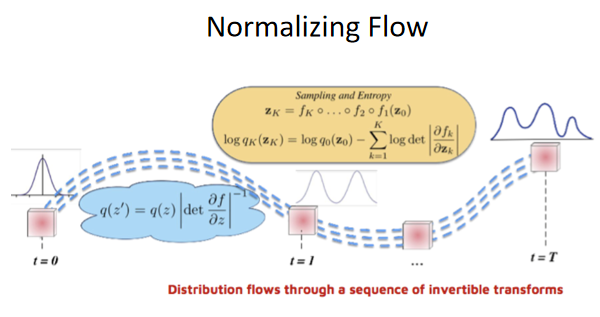
生成对抗网络(GAN)的主要思想是:通过生成器(generator)与判别器(discriminator)的不断对抗进行训练。最终使得判别器难以分辨生成器生成的数据(图片,音频等)和真实的数据。它通过对抗式训练的方法来提升生成模型的性能,但是存在训练过程不稳定、模式坍塌等问题。
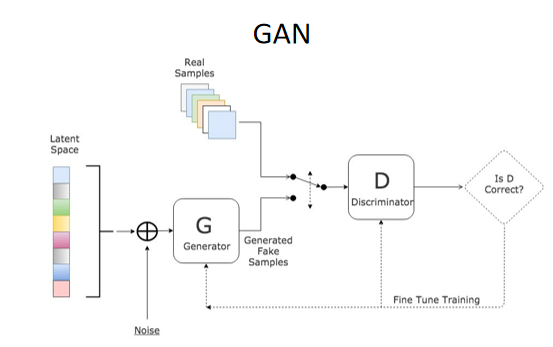
规整流(Normalizing Flow)则是通过学习一个可逆的函数将单峰分布逐渐拟合到原始图像的多峰分布,训练的过程是不断拟合以达到正常图像特征出现的最大概率,但是它的表达能力是有限的。
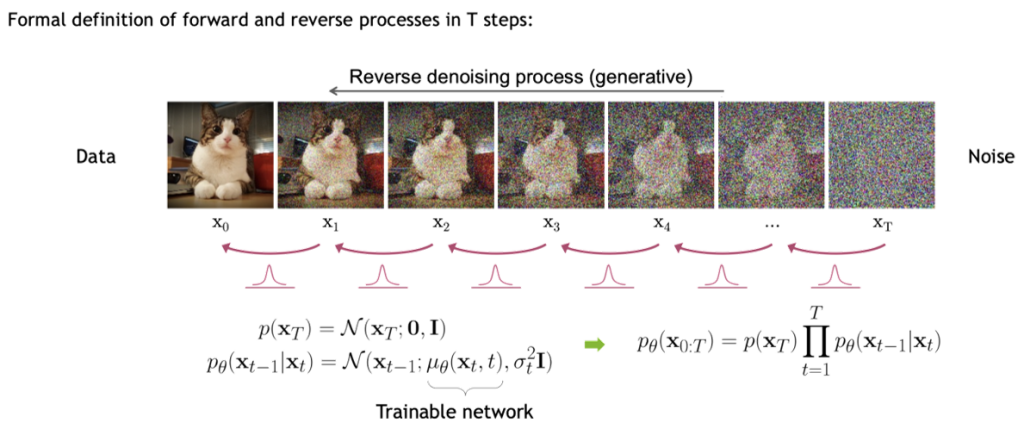
不同于VAE、GAN或规整流,扩散模型将图像生成过程建模成一个多步的在不同噪声级别上的去噪模型,借用物理学中扩散过程的概念,在理论上保证了只要在一定的条件下,前向的扩散过程对于任何的输入分布都是可逆的,同时这些逆过程的形式是保持不变的。此时我们只需要在前项的扩散过程中学习到添加的随机噪声的均值和方差,就能够用一个学到的网络在逆向过程中从高斯噪声中的采样逐步恢复到原始的图像。
在本篇工作中,我们还关注到如何将无条件的扩散模型转变为有条件的扩散模型。本文采用的做法是基于对贝叶斯公式取对数然后再求梯度,展开成如下图所示的形式:
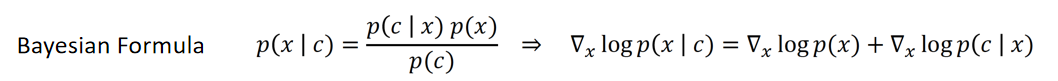
可以看到,一个有条件的生成模型等于一个无条件的生成模型加上一个预训练好的分类器,即对应下图中的形式:

02
Method
Previous Work:Planning as Generative Modeling
如下图所示,对于一个经典的基于模型的强化学习算法(Model-based RL),它一般会先学习一个状态转移模型,同时再学习一个世界模型(以预测轨迹的奖励),基于两个学好的模型,通过优化的方法找到最优策略。但是用生成模型解决强化学习任务时,只需将这两个过程集成到生成模型的生成过程中,同时生成它的状态转移以及它对当前步的奖励,就可以将整条轨迹一步地生成出来。

在2022年ICML的一篇文章中也首次提出将扩散模型用于规划任务。具体来讲,它将轨迹表征成单通道的图像,如下图所示,右侧图像中纵向是去噪过程,横向是规划过程,我们将其规划的整条轨迹看作是单通道的图像,就可以使用扩散模型逐步迭代地去噪生成出来。
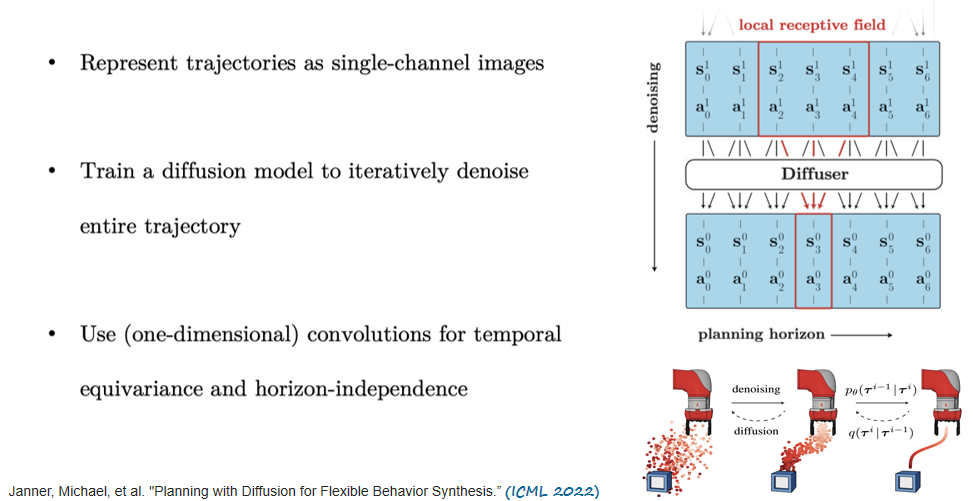
而关于将无条件的轨迹生成模型转化成有条件的轨迹生成模型,该篇文章也定义了一个行为模型,正比于一个无条件的扩散模型乘以一个引导函数。在ICML 2022中,它提供了两种引导函数,第一种是值函数的引导,第二种是目标位置的引导。将无条件的扩散模型和这两者之一相乘就可以获得满足所给条件的一条最优轨迹。
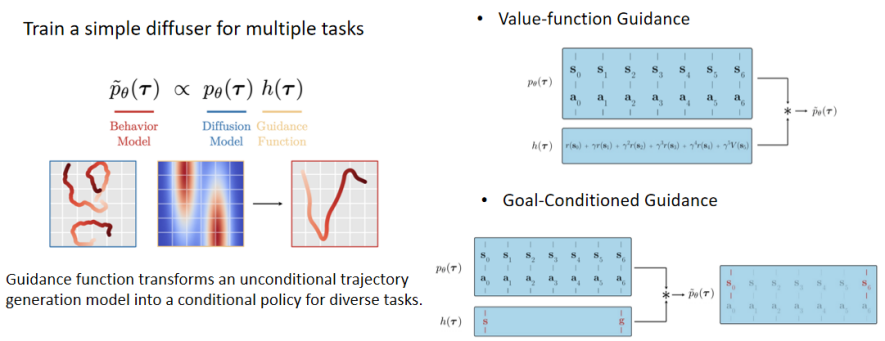
Our work: Self-evolved Planning with Diffusion
在离线强化学习中有一个共性的问题,离线强化学习模型的性能受限于离线训练数据的多样性和数量,尤其是将规划器迁移到一些新的任务或环境中是非常具有挑战性的。而扩散模型在图像中的优异表现给我们带来一定启发,一方面,扩散模型有能力生成完全不同于训练数据的异质图像;另一方面,我们发现只需对在采样阶段给予不同的引导函数就可以自动生成适应于不同任务的新数据,而无需重新训练一个扩散过程。因此,我们希望将扩散模型的特点应用到强化学习中,学习一个自进化的基于扩散模型的规划器,进而使得其能够用于多样化的任务和目标。
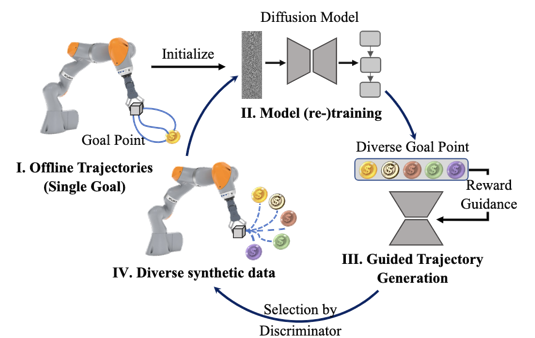
如下图所示,是本文提出的网络框架。我们首先初始化训练一个扩散模型,在模型预训练之后,采用多样化的目标指引生成崭新的数据,进而设计一个较简单的基于规则的判别器从生成的数据中挑选高质量的数据;在得到高质量的数据后,我们会利用这些数据对扩散模型进行微调。如此循环往复,实现类似于少样本多次联合训练的效果。
在多个数据集上的实验证明,AdaptDiffuser较其他模型有了明显的性能提高。并且AdaptDiffuser所使用的动力学引导的约束使用了一种基于传统机器人运动学的方法来获得它的实际可执行动作,进而判别是否与动力学约束一致。
下图是AdaptDiffuser具体的网络框架。左侧是经典的用于规划和轨迹生成的扩散模型,在生成大量数据后会通过判别器判断是否为高质量数据,如果是则将其加入数据池中更新扩散模型。在生成阶段,我们通过不同的指引函数指引多样化的异质数据生成,多样化的任务包括迷宫找路、拾取任务的不同设置等。
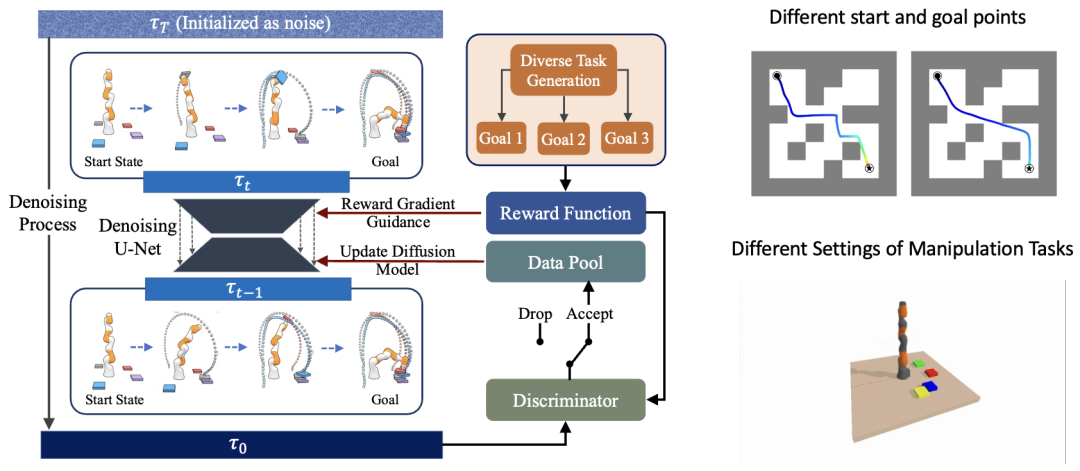
我们在前人的Reward-guided方法基础上提出了一种更泛化的引导方法,它使用了一种Product of Experts Model的方法将行为模型建模成一个扩散模型乘上置信函数的过程。在之前的工作中,我们可以发现,如果是一个连续的奖励函数,则可以通过贝叶斯建模判别当前的轨迹是否为最优轨迹;如果是稀疏的奖励函数,则可以将其建模成阶跃函数的形式,由于阶跃函数的导函数是冲激函数,有采样性质,因此在对应步进行状态的采样和赋值就可以实现要求的效果。进而,我们在此基础上提出了将二者结合的方式(Energy-function Guided),以一种能量函数指引的方式建模,只需要能量函数可微,不强制要求特定的奖励函数形式。
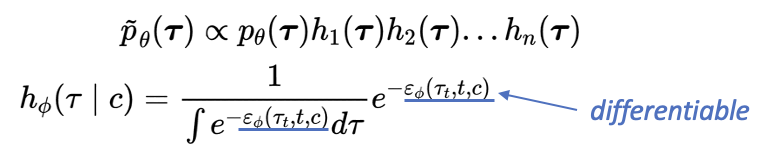
03
Experiment Results
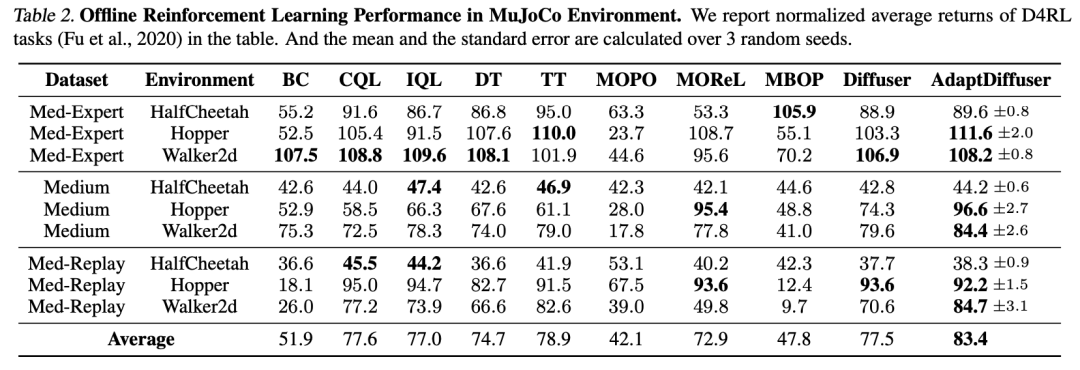
如下图所示是在MuJoCo数据集上的实验结果,AdaptDiffuser比其余的无论是基于Model-based RL的方法还是基于生成模型的方法都表现出更优异的性能。
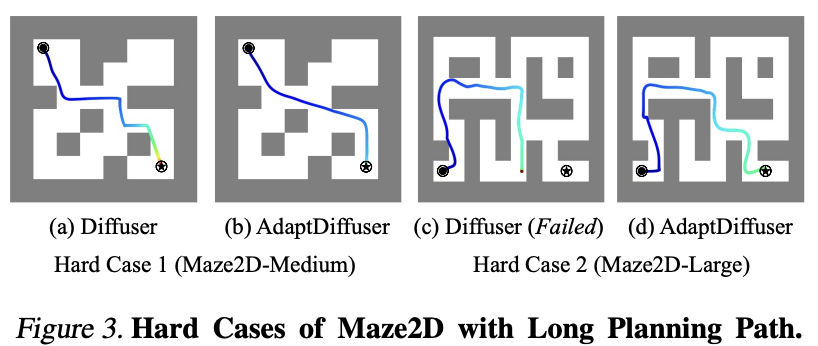
我们也展示了在迷宫找路任务中,AdaptDiffuser的性能更好。比如,在图(a)、(b)中,其余方法在碰到障碍物时会拐急弯,而AdaptDiffuser在更多优质数据的训练下,最后的生成轨迹更加平滑,也可以更快速地到达终点。在图(c)、(d)更加复杂的地图构型模块中,其余方法甚至是失败的,而AdaptDiffuser还是能够找到最终的一条路径。
此外,更重要的是模型在未见过(unseen)任务中的迁移能力。具体来讲,模型在训练的过程中只有将物块堆叠到一起的数据,但是在经过合成的数据生成过程和模型微调之后,它可以非常优质地完成将右侧物块整理到左侧,并排列成一定顺序的任务。
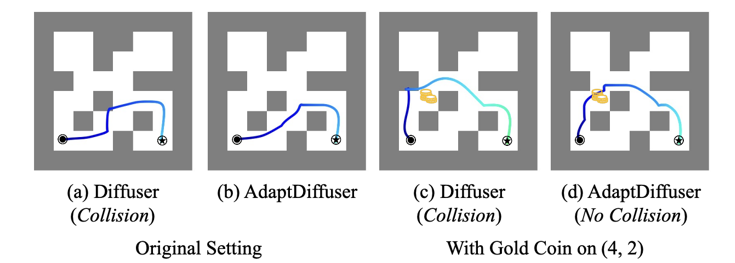
我们为了检验所提出的组合奖励函数的效果,还进行了一组对比实验。在迷宫找路任务中,图(a)、(b)的Diffuser以及AdaptDiffuser方法都会寻找一条尽可能短的路。当在迷宫中放置新的奖励(金币)并要求模型拾取时,AdaptDiffuser不仅可以拾取起金币,还可以走到最终目标,但是对比的基线方法Diffuser就会在迷宫中发生碰撞。
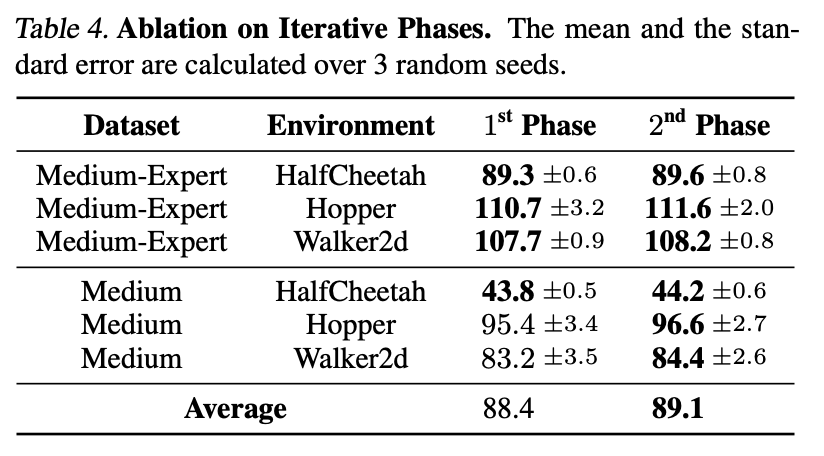
我们还进行了消融实验,验证了模型在多次循环的联合训练过程中,模型性能是可以得到进一步提升的。
04
Discussion
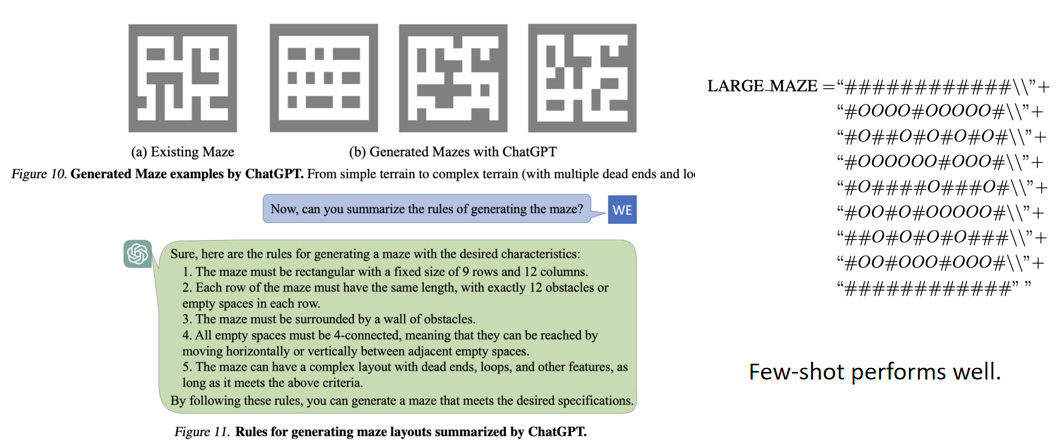
在本文的模型中,算法管线需要生成大量的多样化任务,如果直接人工设计迷宫任务需要耗费大量的时间成本。而在ChatGPT被提出以后,我们完全有可能将迷宫以语言的形式进行表征,然后利用ChatGPT少样本地生成多样化的迷宫布局,并通过提示语的多次引导去指引它生成地形更复杂的迷宫。
05
Conclusion
在本文中,我们提出了AdaptDiffuser,一种通过自进化提高基于扩散模型的规划器在离线强化学习中性能的方法。通过使用扩散模型生成合成专家数据,然后用一种奖励引导的判别器过滤出其中高质量的部分,AdaptDiffuser提高了扩散模型在现有决策任务中的性能,特别是目标条件任务。同时AdaptDiffuser进一步增强了该类规划器在没有任何专家数据情况下(在未见过的任务中)的适应性。我们在两个广泛使用的离线RL基准测试上的实验,以及我们在KUKA和Maze2d环境中精心设计的未见过的任务上的实验,均验证了AdaptDiffuser的有效性。
参考文献
[1] Janner, Michael, et al. "Planning with Diffusion for Flexible Behavior Synthesis.” (ICML 2022)
整理:陈研
审核:梁志烜
提
醒
点击“阅读原文”跳转至00:02:40
可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1300多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!