文章目录
- 一、题目
- 二、解法
- 三、完整代码
所有的LeetCode题解索引,可以看这篇文章——【算法和数据结构】LeetCode题解。
一、题目
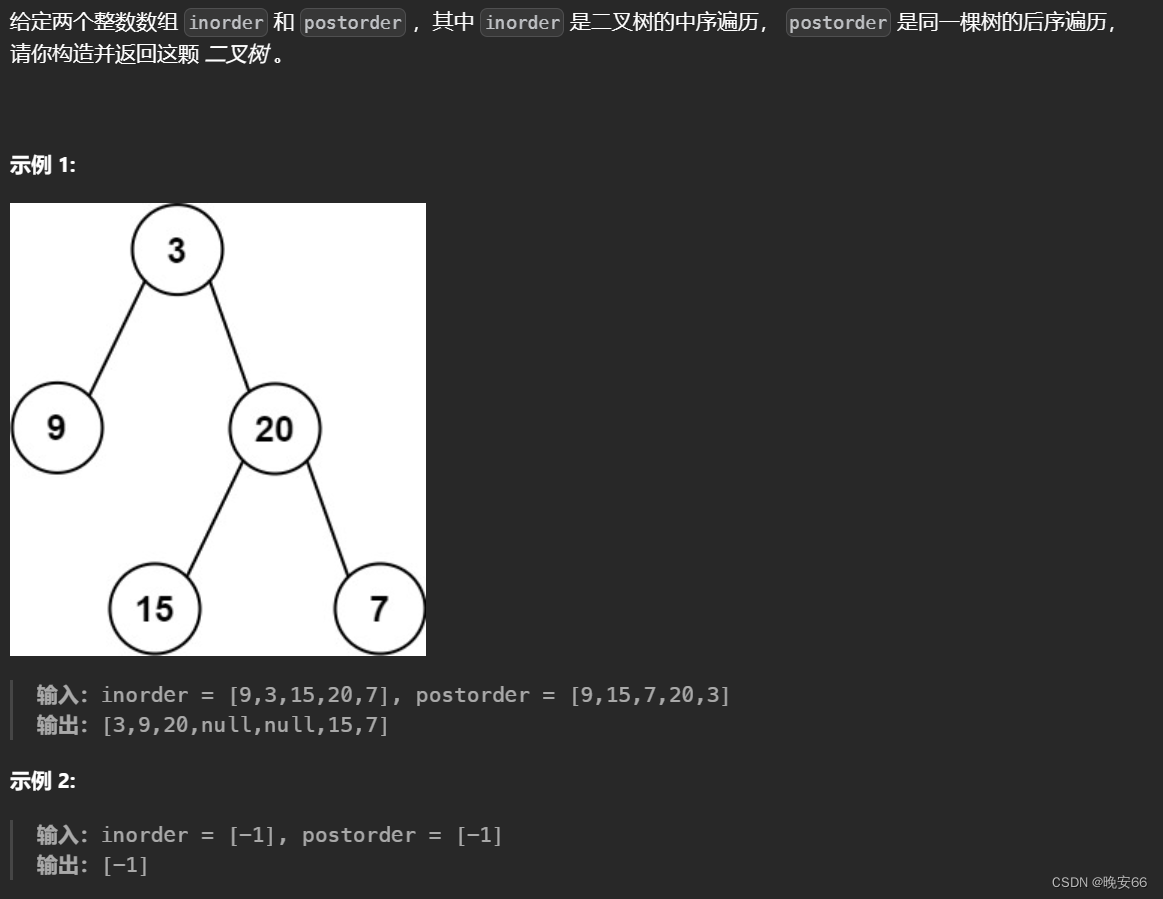
二、解法
思路分析:首先我们要知道后序遍历数组的最后一个元素必然是根节点,然后根据根节点在中序遍历数组中的位置进行划分,得到根节点的左右子树遍历数组,以此递归。当然这里有一个前提,遍历数组的元素不得重复,否则构造的二叉树不唯一。因此我们根据根节点的值找到中序遍历数组中的根节点索引,以此划分出左右区间,然后进行递归。
程序如下:
class Solution {
public:TreeNode* traversal(const vector<int>& inorder, int inorderBegin, int inorderEnd, const vector<int>& postorder, int postorderBegin, int postorderEnd) { // 1、判断是否为空数组,直接返回if (inorderBegin == inorderEnd || postorderBegin == postorderEnd) return NULL;// 2、后序遍历数组最后一个元素,就是当前的中间节点int rootValue = postorder[postorderEnd - 1]; TreeNode* root = new TreeNode(rootValue);// 3、叶子节点,后序数组只剩下一个元素,树构造完毕,返回if (postorderBegin - postorderEnd == 1) return root;// 4、找切割点int delimiterIndex;for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {if (inorder[delimiterIndex] == rootValue) break; // 这里注意二叉树遍历数组的值不能重复,否则二叉树不唯一,这里默认是唯一二叉树,值不重复。}// 5、切割中序数组,得到 中序左数组和中序右数组int leftinorderBegin = inorderBegin;int leftinorderEnd = delimiterIndex;int rightinorderBegin = delimiterIndex + 1;int rightinorderEnd = inorder.size();// 6、切割后序数组,得到 后序左数组和后序右数组int leftpostorderBegin = postorderBegin;int leftpostorderEnd = postorderBegin + delimiterIndex - inorderBegin;// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);int rightPostorderEnd = postorderEnd - 1; // 排除最后一个元素,已经作为节点了// 7、递归root->left = traversal(inorder, leftinorderBegin, leftinorderEnd, postorder, leftpostorderBegin, leftpostorderEnd);root->right = traversal(inorder, rightinorderBegin, rightinorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());}
};
三、完整代码
# include <iostream>
# include <vector>
# include <queue>
# include <string>
# include <algorithm>
# include <stack>
using namespace std;// 树节点定义
struct TreeNode {int val;TreeNode* left;TreeNode* right;TreeNode() : val(0), left(nullptr), right(nullptr) {}TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}TreeNode(int x, TreeNode* left, TreeNode* right) : val(x), left(left), right(right) {}
};class Solution {
public:TreeNode* traversal(const vector<int>& inorder, int inorderBegin, int inorderEnd, const vector<int>& postorder, int postorderBegin, int postorderEnd) { // 1、判断是否为空数组,直接返回if (inorderBegin == inorderEnd || postorderBegin == postorderEnd) return NULL;// 2、后序遍历数组最后一个元素,就是当前的中间节点int rootValue = postorder[postorderEnd - 1]; TreeNode* root = new TreeNode(rootValue);// 3、叶子节点,后序数组只剩下一个元素,树构造完毕,返回if (postorderBegin - postorderEnd == 1) return root;// 4、找切割点int delimiterIndex;for (delimiterIndex = inorderBegin; delimiterIndex < inorderEnd; delimiterIndex++) {if (inorder[delimiterIndex] == rootValue) break; // 这里注意二叉树遍历数组的值不能重复,否则二叉树不唯一,这里默认是唯一二叉树,值不重复。}// 5、切割中序数组,得到 中序左数组和中序右数组int leftinorderBegin = inorderBegin;int leftinorderEnd = delimiterIndex;int rightinorderBegin = delimiterIndex + 1;int rightinorderEnd = inorder.size();// 6、切割后序数组,得到 后序左数组和后序右数组int leftpostorderBegin = postorderBegin;int leftpostorderEnd = postorderBegin + delimiterIndex - inorderBegin;// 右后序区间,左闭右开[rightPostorderBegin, rightPostorderEnd)int rightPostorderBegin = postorderBegin + (delimiterIndex - inorderBegin);int rightPostorderEnd = postorderEnd - 1; // 排除最后一个元素,已经作为节点了// 7、递归root->left = traversal(inorder, leftinorderBegin, leftinorderEnd, postorder, leftpostorderBegin, leftpostorderEnd);root->right = traversal(inorder, rightinorderBegin, rightinorderEnd, postorder, rightPostorderBegin, rightPostorderEnd);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { return traversal(inorder, 0, inorder.size(), postorder, 0, postorder.size());}
};template<class T1, class T2>
void my_print2(T1& v, const string str) {cout << str << endl;for (class T1::iterator vit = v.begin(); vit < v.end(); ++vit) {for (class T2::iterator it = (*vit).begin(); it < (*vit).end(); ++it) {cout << *it << ' ';}cout << endl;}
}// 层序遍历
vector<vector<int>> levelOrder(TreeNode* root) {queue<TreeNode*> que;if (root != NULL) que.push(root);vector<vector<int>> result;while (!que.empty()) {int size = que.size(); // size必须固定, que.size()是不断变化的vector<int> vec;for (int i = 0; i < size; ++i) {TreeNode* node = que.front();que.pop();vec.push_back(node->val);if (node->left) que.push(node->left);if (node->right) que.push(node->right);}result.push_back(vec);}return result;
}int main()
{//vector<int> inorder = {9, 3, 15, 20, 7};//vector<int> postorder = { 9, 15, 7, 20, 3 };vector<int> inorder = { 1, 2, 3};vector<int> postorder = { 3, 2, 1};Solution s;TreeNode* root = s.buildTree(inorder, postorder);vector<vector<int>> tree = levelOrder(root);my_print2<vector<vector<int>>, vector<int>>(tree, "目标树:");system("pause");return 0;
}
end