机器学习算法详解1:基础知识合集
前言
本系列主要对机器学习上算法的原理进行解读,给大家分享一下我的观点和总结。
本篇前言
开一个新系列,另外现在开学了,忙起来了,所以更新会很慢。
目录结构
文章目录
- 机器学习算法详解1:基础知识合集
- 1. 分类与回归
- 1.1 分类
- 1.2 回归
- 2. 损失函数
- 2.1 含义
- 2.2 常用损失函数
- 3. 距离度量
- 3.1 欧式距离
- 3.2 曼哈顿距离
- 3.3 切比雪夫距离
- 4. 归一化
- 4.1 作用
- 4.2 最大最小值归一化
- 4.3 z-score归一化
- 5. 拟合
- 5.1 含义
- 5.2 分类
- 6. 正则化
- 7. 优化器/梯度下降算法
- 8. 数据划分方法
- 8.1 训练集、验证集与测试集:
- 8.2 留出法
- 8.3 交叉验证
- 9. 编程语言
- 10. 类别不平衡问题
- 10.1 含义
- 10.2 处理方法
- 11. 评价指标
- 11.1 回归任务评价指标
- 11.2 混肴矩阵
- 12. 多分类任务
- 12.1 One vs One
- 12.2 One vs Rest
- 12.3 Many vs Many
- 13. 总结
1. 分类与回归
机器学习两大经典任务分类与回归。
1.1 分类
即我们所认知的对某个东西进行分类。
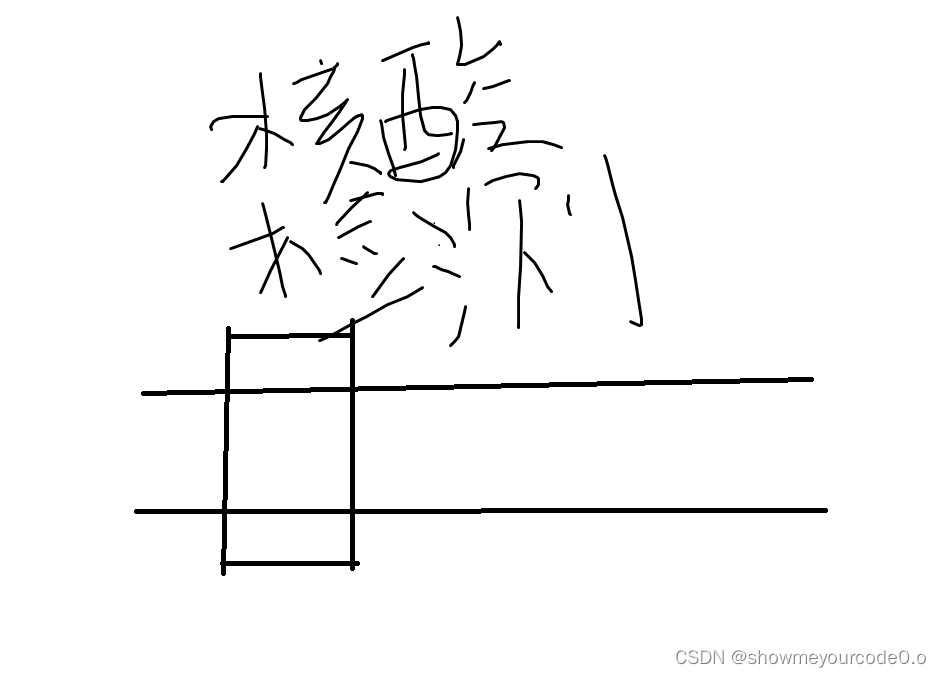
1.2 回归
用线性回归来解释,就是如下图:

即直线会趋于各个点的中间值。
2. 损失函数
2.1 含义
损失函数,也可以称之为目标函数、优化目标等等,是机器学习中的一个重要概念。
简单来说,我们有一个任务,对它进行分析后,得到一个最终的函数f(x),我们的目标就是求f(x)的最小值。那么对于我们来说,f(x)就是损失函数/目标函数(其实不太严谨,不过大概就是这意思)。
2.2 常用损失函数
回归任务常用的损失函数就是MAE、MSE损失,即我们熟悉的均值误差和均方差误差,公式如下:

而对于分类任务而言,常用的是交叉熵损失函数,二分类形式为:(其中y^ 为概率值,y为真实值,取值{0/1})

另外,上式其实可以使用KL散度进行推导,这里先不说,后面讲解逻辑回归的时候进行说明。
3. 距离度量
这里我先介绍三个最为常用的距离度量,至于KL"距离"后面讲。
3.1 欧式距离
两点的直线距离,公式:

3.2 曼哈顿距离
又称城市街区距离,即只允许走水平/垂直的路线:

公式如下:

3.3 切比雪夫距离
又称棋盘距离,即它可以向国际象棋里面的棋子一样可以走最大差值距离,公式如下:

4. 归一化
归一化/标准化,其实差不多,都是让某个变量符合你选定的分布,这里介绍机器学习里常用的min-max归一化、z-score归一化。(深度学习中常用的是批量归一化等)
4.1 作用
- 让数据的不同特征处于同一数量级
- 避免激活函数饱和而使梯度消失
- 加速收敛
前两个作用好理解,但是为什么可以加速收敛呢?
假设损失函数受两个参数w1\w2影响,并且假设w1为主参数,权重大,w2为次参数,权重小,那么损失值图是三维的图,我们投影到二维就是等高线图,如下:

那么,我们开始优化损失函数,假设起点在五角星位置,由于w1参数比w2参数重要,这意味着优化的时候w1方向走得快,w2走得慢,那么优化过程便如下图:

但是,归一化后,两个参数一样重要,那么等高线图和优化过程如下:

可以明显看出,收敛速度加快。
4.2 最大最小值归一化
公式如下:

特点:
- 不会改变数据原始分布,只是将值缩放到[0,1]之间
- 值都大于等于0(对于神经网络来说容易导致值偏置)
- 对异常值敏感(比如一个非常大的最大值,但是其他数值都比较小,会导致归一化异常)
4.3 z-score归一化
公式如下:

特点:
- 改变数据原始分布,让数据符合均值为u、标准差σ的分布。
- 值有正有负
5. 拟合
5.1 含义
拟合这个概念本身是对于回归问题来说的。比如只有几个点:

让你去用条线满足这三个点,你肯定能想到一条二次曲线,如下图:

这就是拟合。但是在实际中,拟合并不局限于回归问题,还可以用于分类任务。
5.2 分类
- 欠拟合
- 拟合得不到位,相当于还没有学习完
- 过拟合
- 拟合得过好,相当于考试只会刚刚学习过的题目,变一点就不会了
- 正常拟合
- 正常状况,不仅会刚刚考试的题目,变一点点也是会做的(但是不一定作对而已)
6. 正则化
看我这篇文章,说得很详细——深入机器学习1:详解正则表达式。
7. 优化器/梯度下降算法
我们都知道,机器学习/深度学习是来解决数据问题的,特别是大数据问题。而对于大数据问题,有一个很难的点就是很难求出解析解。针对这种情况,就提出了各种各样的优化器,这里我们来说说其中最典型的梯度下降算法。
对于一段山势图:

假设,你在四角星的位置,那么问:如何你才能最快的下山?这个答案显而易见,就是走梯度方向。
那么将上述这段话体现为数学公式,如下:

其中θ是我们的待优化参数,α是我们下山步长,称之为学习率,J(θ)就是损失函数,对其求导就是梯度方向。
其可以分为三类:
- 批量梯度下降算法
- 每次对全部数据进行梯度下降算法
- 随机梯度下降算法
- 每次对单个数据进行梯度下降算法
- 小批量梯度下降算法
- 每次对一批次的数据进行梯度下降算法
不难看出,其具有一定的缺点:
- 易震荡
- 即容易出现在波谷的位置左右横跳,找不到最佳值
- 可能只能找到局部最优解
- 参数不易设置并且参数单一,不能变化
8. 数据划分方法
这里说说数据集的划分。
8.1 训练集、验证集与测试集:
训练集,即用于机器学习模型训练的数据集合。这里补充一下,训练有时候不仅仅训练一次,有时候可以对数据进行多次训练。
验证集,每次训练完毕后用于验证训练效果如何。
测试集,所有训练完后用于检测模型效果如何,这是模拟真实使用情景。
补充说明:验证集一般在深度学习中常用,机器学习还是用得比较少。
8.2 留出法
直接将数据集划分为两个互斥的集合,一个作为训练集,一个作为测试机,常用的比例为7/3、8/2。
8.3 交叉验证
随机将训练样本拆分成K个互不相交大小相同的子集,然后用K-1个子集作为训练集训练模型,用剩余的子集验证模型,对K中选择重复进行,最终选出K次测评中的平均测试误差最小的模型。常用的k值有 5、10、20等。
比如,5折交叉验证如下图所示:

9. 编程语言
想要实现机器学习其实有很多编程语言都可以,不过现在主流的还是python,因此推荐大家使用python进行编程。而在python中主要实现机器学习的库是sklearn,这个库集成了大部分的常见机器学习算法,使用起来非常简单,想要了解的可以看我这篇文章。
10. 类别不平衡问题
10.1 含义
有时候我们拿到的数据,A类别有400条,B类别只有100条,这样的数据,我直接定义一个学习器只输出A类别,它的准确率都有80%。因此,针对这样类别不平衡的数据(分类数据),我们需要进行数据的平衡处理。
10.2 处理方法
降采样
有一个最简单的思路:把数据多的类别降采样到和类别少的一样的数据量即可。比如上面我们直接从400个A数据中抽样100个A数据,这样A和B的数据量就相同了。
它的优缺点非常明显:
- 优点
- 计算开销小,思路简单
- 缺点
- 丢弃了很多数据,导致训练样本集合比初始小很多
- 另外,有时候数据量本身就少,你还降采样,不合适
过采样
好的,不能降采样,那么我们直接对数据量少的类别过采样总行吧。
但是,如何过采样呢?最简单的思路就是重复一些样本,但是这样非常容易导致过拟合,比如你100条B类别,现在你重复采样,变为了400条B类别,最低的比例都是每条数据重复4次。
因此,这样的思路不可取,而常用的过采样思路是SMOTE算法,它通过对训练集的少样本对象进行差值计算来产生新的样例。
基于学习的策略
第三种思路是基于学习的策略来调整。
一个思路如下:
我们知道在分类的时候,实际上是把模型输出值y与一个阈值进行比较(比如0.5),大于这个阈值则为正例,小于则为负例。那么,几率y/1-y就是正例概率与负例概率的比值,原先针对y阈值为0.5,那么这里变为了1(0.5 / (1-0.5) = 1)。
而由于正反例数据量不同,我们可以设置一个观测几率,其值为m+ / m-,其中m+表示正例数量,m-表示负例数量。
那么,可以认为:(下式是关注了数量关系)
y/1-y > m+/1- ,认为是正例
但是,实际上却是:(下式只是符合客观印象)
y/1-y > 1 ,认为是正例
因此,可以做出一定的修整:

基于上述原理,我们可以先让模型直接学习不平衡的数据,但是在进行决策的时候按照上述公式进行决策,这样相当于对数据进行了一定程度的缩放,实现了解决类别不平衡的目的。
11. 评价指标
11.1 回归任务评价指标
即我们前面讲解过的MAE、MSE等都是它的评价指标,主要衡量真实值与预测值之间的差距。
除此之外,还有一个评价指标,衡量拟合程度好坏的指标,称之为相关系数/决定系数,或者R2,公式如下:

11.2 混肴矩阵
分类任务常用评价指标。
矩阵形式如下:

可以得出以下几个指标:
- 精确度/查准率

- 召回率/查全率

两者是一对矛盾的量,一者大另外一者就偏小。
将两者的值画作曲线,称之为P-R曲线:

上图中一个曲线被另外一个曲线包住,说明了前者性能低于后者(从查全率和查准率的值可以看出来),而所谓的平衡点就是查全率等于查准率的点而已。
12. 多分类任务
我们算法讲解的时候,为了方便起见,一般都是以二分类任务为例子进行讲解的,那么二分类任务如何拓展到多分类任务呢?
12.1 One vs One
简称为OvO(看起来就像表情包<_<),中文称为一对一。
假设有N个类别,我们可以将这N个类别随机抽取两个组成一个二分类任务,那么一共有N*(N-1)/2个分类任务,也可以得到N*(N-1)/2个分类结果,那么最终的结果就是有投票表决,即哪一个类别出现的次数最多,说明就是哪个类别。
12.2 One vs Rest
简称OvR,中文称为一对剩余。
即N个类别,每次抽取1个类别,并将其他类别作为一个整体,分类器就判断是否属于这个类别就行。那么,一共产生N个分类器,那么最终结果就是分类器输出该类别的类别(分类器输出Yes表示为该类别,No表示为其他类别)。
12.3 Many vs Many
简称MvM,中文称为多对多。
即,每次抽取诺干为正例,诺干为负例,当然,抽取是根据一定规则抽取的,不过具体的规则有很多,这里就不细说了,有兴趣的可以看看西瓜书等资料。
13. 总结
本篇主要讲解了一些机器学习的基础前置知识,当然上面的内容肯定没有包含全,后期我想起来了也会继续补充的。
下一篇,讲解线性回归的原理。