Spark 环境安装
一、准备工作
1、hadoop成功安装
2、防火墙关闭
二、解压安装
1、上传 spark 安装包到/tools 目录,进入 tools 下,执行如下命令:
tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C /training/
由于 Spark 的脚本命令和 Hadoop 有冲突,只需在.bash_profile 中设置一个即可(不能同时设置),所以有hadoop的就不设置spark的这个文件。
2、进入training,进入spark安装路径,配置文件spark-env.sh
1,
cd /training/spark-2.1.0-binhadoop2.7/conf/
可以看到并没有spark-env.sh

2.
复制备份一份
cp spark-env.sh.template spark-env.sh
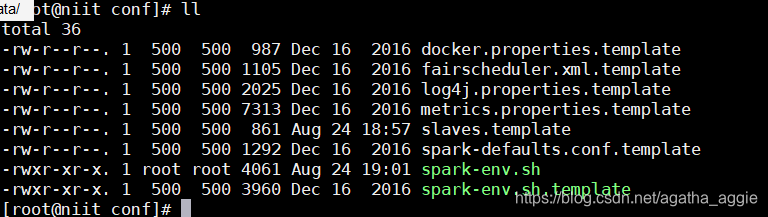
3.配置文件spark-env.sh
vi spark-env.sh
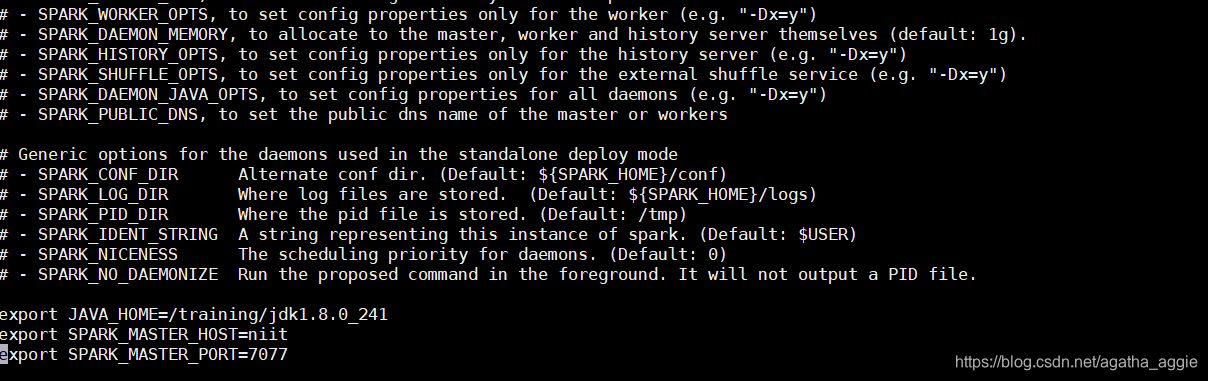
在底部输入配置(根据自己配置的路径、版本、主机名调整配置)
export JAVA_HOME=/training/jdk1.8.0_241
export SPARK_MASTER_HOST=niit
export SPARK_MASTER_PORT=7077
4。配置文件slaves
首先复制一遍slaves.template

cp slaves.template slaves

配置slaves,将localhost改自己的主机名
vi slaves
niit

三、启动spark
1、启动hadoop
start-all.sh
2.启动spark
cd /training/spark-2.1.0-binhadoop2.7/sbin/
start-all.sh

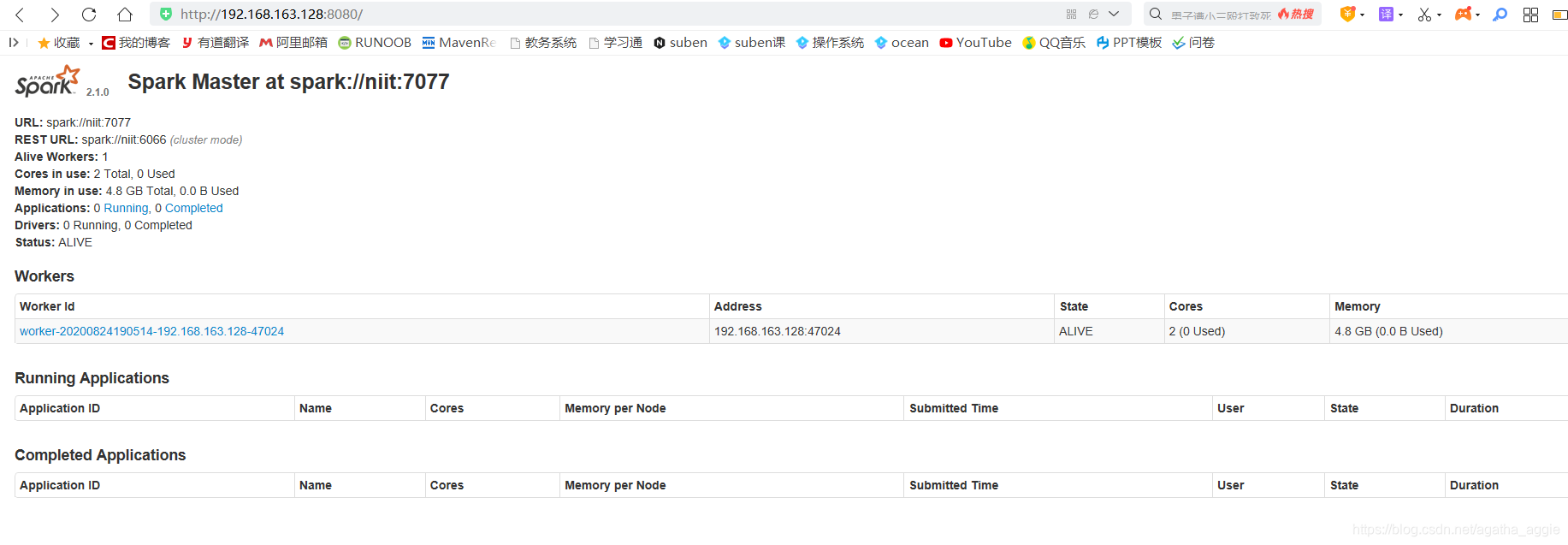
查看spark网址
http://niit(主机名):8080
Spark 案例演示
一、查询pi的值
1.进入spark安装目录,进入bin,使用spark-submit函数
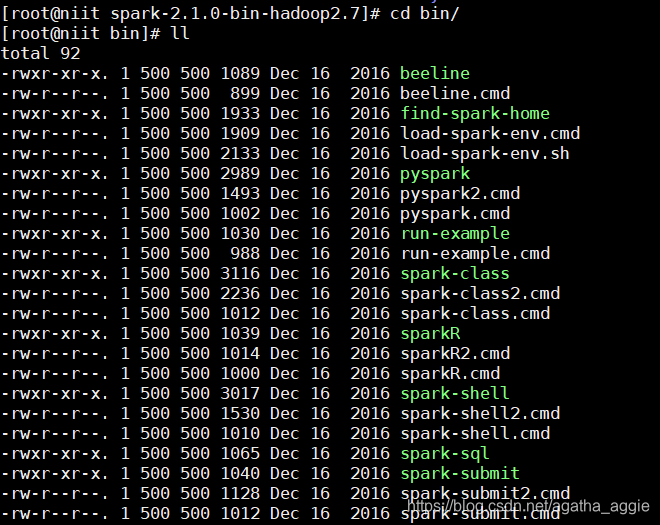
2.查看spark example的路径,找到之后使用pwd将路径存在记事本中
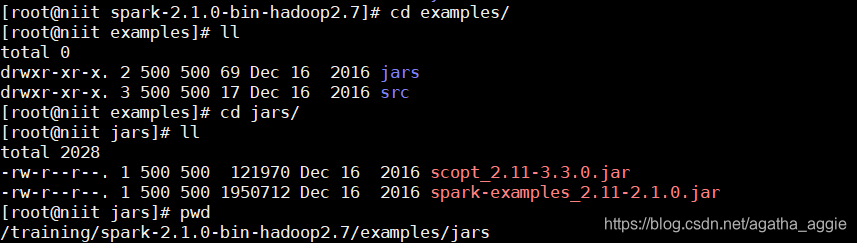
3.查看spark pi的路径
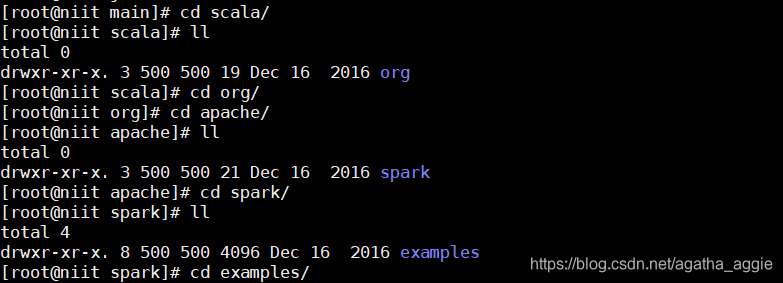
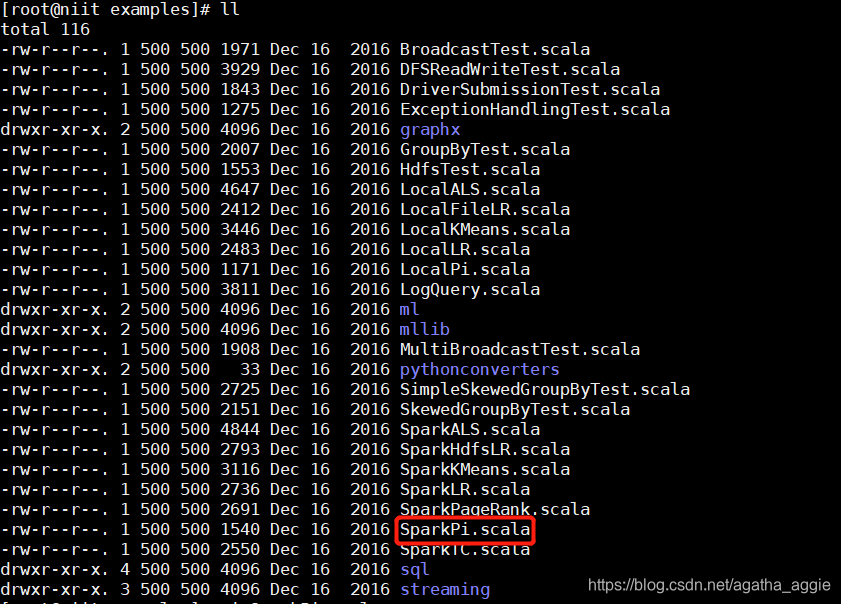

输入执行总代码:
./spark-submit --master spark://niit:7077 --class org.apache.spark.examples.SparkPi /training/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jar 100
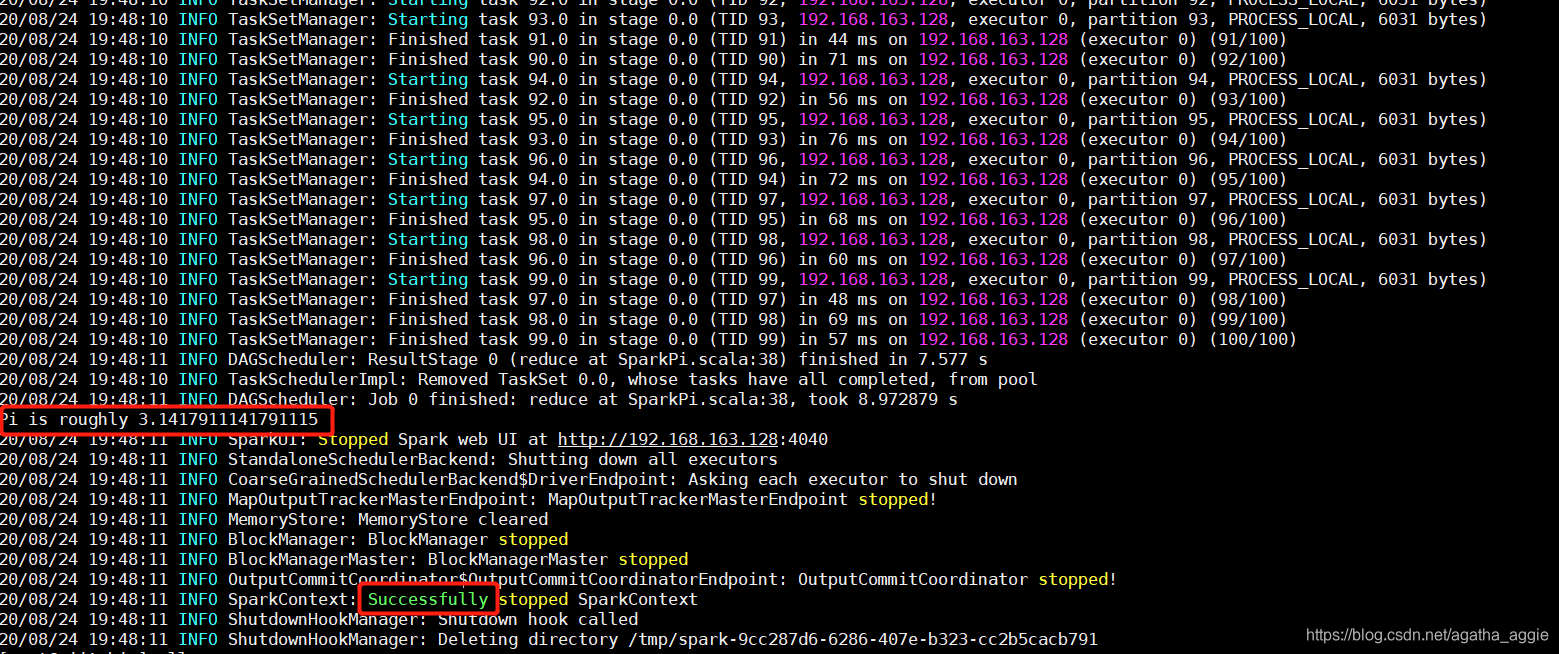
二、实现wordcount程序
1.进入spark安装目录,进入bin,使用spark-shell函数
- spark-shell是 Spark 自带的交互式 Shell 程序,方便用户进行交互式编程,用户可以在该命令行下用 scala 编写 spark 程序。
2.进入shell
spark-shell
也可以使用以下参数:
参数说明:
–master spark://niit110:7077 指定 Master 的地址
–executor-memory 2g 指定每个 worker 可用内存为 2G
–total-executor-cores 2 指定整个集群使用的 cup 核数为 2 个
例如:
spark-shell --master spark://niit:7077
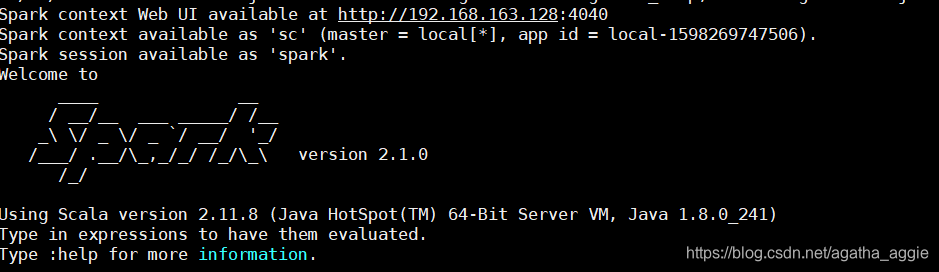
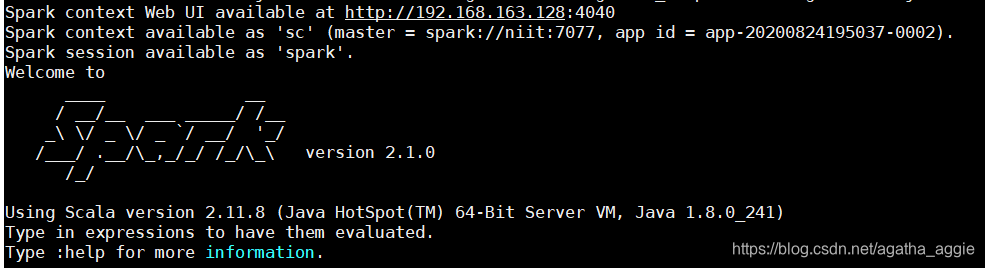
如果启动 spark shell 时没有指定 master 地址,但是也可以正常启动 spark shell 和执行sparkshell 中的程序,其实是启动了spark 的 local 模式,该模式仅在本机启动一个进程,没有与集群建立联系。请注意 local 模式和集群模式的日志区别:
local:
集群:
3.在 Spark Shell 中编写 WordCount 程序
首先将文件传输到hdfs中路径自己传输时设置,可以通过50070端口查看
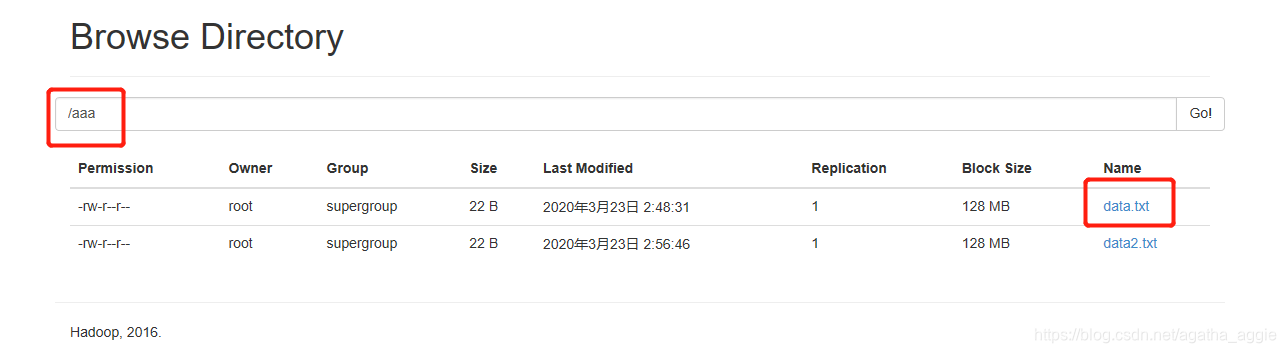
将此代码写入shell中,ip地址以及文件、输入输出路径、文件名自行更换

sc.textFile("hdfs://192.168.163.128:9000/aaa/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://192.168.163.128:9000/output/spark/wc")


![MyBatis-Plus实现普通查询/分页查询[MyBatis-Plus系列] - 第484篇](https://img-blog.csdnimg.cn/img_convert/e58de28fe465fdafd3a923ce24b1ba7c.png)