1.概念
NIO(New Input/Output)和BIO(Blocking Input/Output)是Java中用于处理输入输出的两种不同的模型。
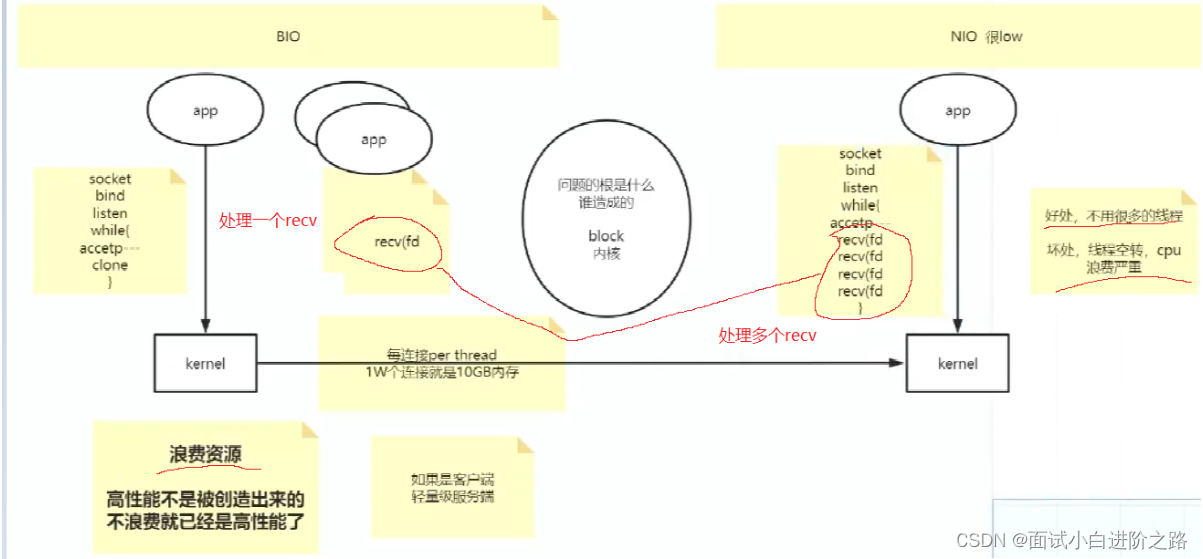
BIO 会阻塞,等有了消息,立刻返回,一个线程处理一个recv(需要很多线程)。
NIO 有没有消息,都返回(但程序要自己判断,返回空就循环重复);一个线程可以处理多个recv(好处:不用很多线程;坏处:线程空转,cpu浪费严重)。

Java中新的NIO包可以通过上述形式设置是否开启阻塞,从而设置NIO或BIO,两者都支持;
IO多路复用
IO多路复用(IO Multiplexing)是一种通过单线程处理多个I/O操作的机制。它允许一个进程同时监听多个文件描述符(如Socket),并在有数据可读或可写时进行相应的处理,从而提高系统的并发性能。
在传统的阻塞I/O模型中,每个I/O操作都需要一个独立的线程来处理,当并发量增加时,线程数量会急剧增加,导致系统资源消耗过大。而使用IO多路复用,只需要一个线程就可以同时处理多个I/O操作,大大减少了线程的数量和系统开销。
常见的IO多路复用机制包括:
-
select:select是Unix系统最早引入的IO多路复用机制。它通过select函数来监听多个文件描述符,当其中任意一个文件描述符准备就绪时,select函数会返回,然后可以通过遍历文件描述符集合来确定哪些文件描述符可读或可写。
-
poll:poll是select的一种改进版本。它使用一个pollfd结构体数组来管理文件描述符,并通过poll函数来监听多个文件描述符的状态。与select相比,poll没有最大文件描述符数量的限制。
-
epoll:epoll是Linux系统引入的一种高效的IO多路复用机制。它使用一个事件表来管理文件描述符,并通过epoll_ctl函数来注册和删除事件,通过epoll_wait函数来等待事件的发生。epoll提供了三种工作模式:边沿触发(EPOLLET)、水平触发(EPOLLIN、EPOLLOUT)和一次性触发(EPOLLONESHOT),可以根据具体需求选择适合的模式。(epoll可以理解为多了个记事本,)
IO多路复用适用于处理大量的并发连接,如服务器端的网络编程。它可以有效地减少线程的数量,提高系统的并发性能和资源利用率。
可以说:
select内核无状态,每次从零开始
eqoll内核维护一个状态,可以异步做很多事情,调用的时候能够立刻给出结果集
额外拓展
1.epoll机制详解
epoll是Linux系统引入的一种高效的IO多路复用机制,它提供了一种事件驱动的方式来处理多个文件描述符的I/O操作。相比于传统的select和poll机制,epoll在处理大量并发连接时具有更高的性能。
epoll的核心概念包括以下几个部分:
-
epoll实例(epoll instance):epoll实例是一个内核数据结构,用于管理文件描述符和事件。通过epoll_create函数来创建一个epoll实例。
-
文件描述符(file descriptor):文件描述符是操作系统对文件或I/O设备的引用。在epoll中,需要将需要监听的文件描述符添加到epoll实例中。
-
事件(event):事件是对文件描述符的一种状态变化的表示,如可读、可写等。在epoll中,通过epoll_event结构体来表示事件。
-
事件表(event table):事件表是epoll实例中用来存储事件的数据结构,可以通过epoll_ctl函数来注册和删除事件。
epoll的工作流程如下:
-
创建epoll实例:通过epoll_create函数创建一个epoll实例,并返回一个文件描述符,用于后续的操作。
-
添加文件描述符:通过epoll_ctl函数将需要监听的文件描述符添加到epoll实例中,并指定需要监听的事件类型。
-
等待事件:通过epoll_wait函数等待事件的发生。当有文件描述符的事件发生时,epoll_wait函数会返回,并将事件信息填充到一个epoll_event数组中。
-
处理事件:遍历epoll_event数组,根据事件类型进行相应的处理。
-
循环操作:重复执行等待事件和处理事件的过程,实现持续的事件驱动。
epoll提供了三种工作模式:
-
边沿触发(EPOLLET):只有在文件描述符状态发生变化时才触发事件,适用于高效处理大量的并发连接。
-
水平触发(EPOLLIN、EPOLLOUT):只要文件描述符处于可读或可写状态,就会触发事件,适用于普通的网络编程。
-
一次性触发(EPOLLONESHOT):只触发一次事件,需要在处理完事件后重新注册。
epoll的优势在于可以处理大量的并发连接,具有更高的性能和资源利用率。它避免了传统select和poll机制中遍历文件描述符集合的开销,同时提供了更灵活的事件触发方式。因此,epoll被广泛应用于高性能的网络服务器编程。
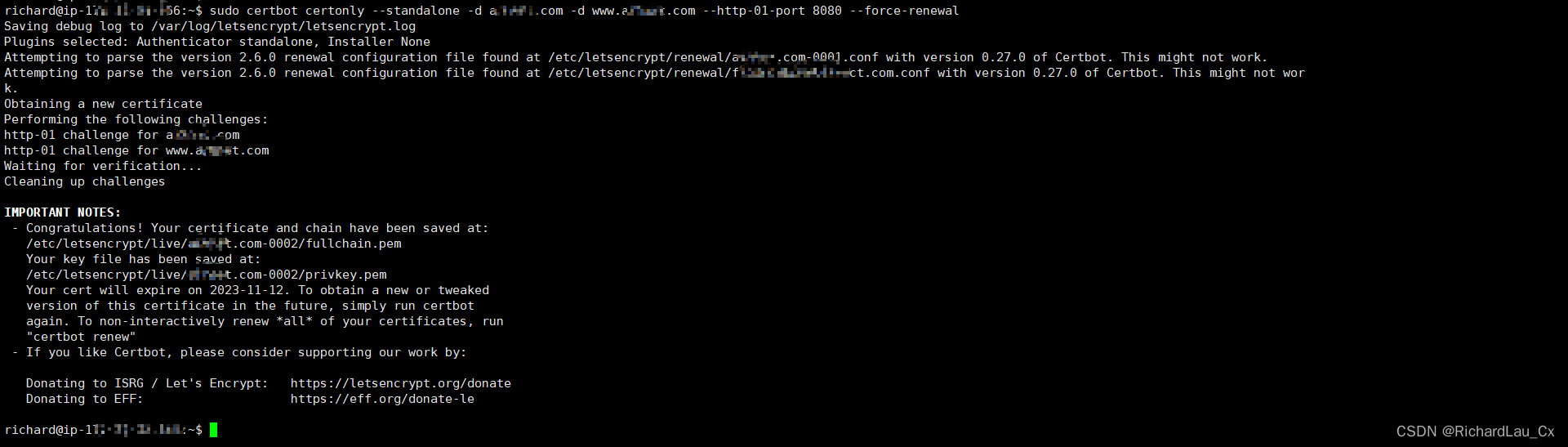
2.BIO什么时候会阻塞?
BIO(Blocking I/O,阻塞I/O)是一种同步的I/O模型,在进行I/O操作时会阻塞当前线程,直到操作完成或出现错误。以下情况下,BIO会发生阻塞:
-
读取阻塞:当从输入流(如Socket的InputStream)读取数据时,如果没有可读取的数据,读取操作将会阻塞,直到有数据可读或者发生超时或错误。
-
写入阻塞:当向输出流(如Socket的OutputStream)写入数据时,如果输出缓冲区已满,写入操作将会阻塞,直到有空间可写或者发生超时或错误。
-
连接阻塞:在使用ServerSocket等待客户端连接时,accept()方法会阻塞当前线程,直到有客户端连接成功或发生超时或错误。
BIO的阻塞特性意味着在进行I/O操作时,线程会一直等待,不能处理其他任务。这可能导致资源浪费和性能下降。因此,对于高并发的网络应用,通常使用NIO(Non-blocking I/O,非阻塞I/O)或AIO(Asynchronous I/O,异步I/O)模型来避免阻塞。
3.上文提到的缓冲区(详解)
概念和作用:缓冲区(Buffer)是在进行I/O操作时用于临时存储数据的一块内存区域。它提供了一种缓冲数据的机制,可以减少实际的I/O操作次数,提高数据读写的效率。
在Java中,缓冲区是通过Buffer类的实例来表示的。Java NIO(New I/O)库提供了一组缓冲区类,如ByteBuffer、CharBuffer、ShortBuffer等,用于处理不同类型的数据。
缓冲区有以下几个重要的属性:
-
容量(Capacity):缓冲区的容量表示它可以存储的最大数据量。一旦创建,缓冲区的容量就是固定的,不能改变。
-
位置(Position):缓冲区的位置表示当前读写操作的位置。初始时,位置为0,随着读写操作进行,位置会自动更新。
-
上界(Limit):缓冲区的上界表示有效数据的末尾位置。读写操作不能超过上界。
-
标记(Mark):缓冲区的标记是一个备忘位置,可以通过mark()方法设置,并通过reset()方法恢复到标记位置。
缓冲区的基本操作包括:
-
写入数据:通过put()方法将数据写入缓冲区,同时位置会自动向后移动。
-
读取数据:通过get()方法从缓冲区读取数据,同时位置会自动向后移动。
-
翻转缓冲区:通过flip()方法将上界设置为当前位置,位置重置为0,用于将缓冲区从写模式切换到读模式。
-
清空缓冲区:通过clear()方法将位置设置为0,上界设置为容量,用于将缓冲区从读模式切换到写模式。
缓冲区的使用可以提高I/O操作的效率,特别是在处理大量数据时。它可以减少系统的调用次数,提高数据读写的速度。