⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️
🐴作者:秋无之地🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。
🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、留言💬
上一篇文章已经跟大家介绍过《数据分析综述》,相信大家对数据分析都有一个清楚的认识。下面我讲一下数据分析中比较重要的一环:数据挖掘的学习路径。
一、数据挖掘的重要组成
一开始可能大家对数据挖掘还很陌生,有点无从下手的感觉。不用担心,接下来听我讲解就行。
想象一下,茫茫的大海上,孤零零地屹立着钻井,想要从大海中开采出宝贵的石油。对于普通人来说,大海是很难感知的,就更不用说找到宝藏了。但对于熟练的石油开采人员来说,大海是有坐标的。他们对地质做勘探,分析地质构造,从而发现哪些地方更可能有石油。然后用开采工具,进行深度挖掘,直到打到石油为止。
大海、地质信息、石油对开采人员来说就是数据源、地理位置、以及分析得到的结果。而我们要做的数据挖掘工作,就好像这个钻井一样,通过分析这些数据,从庞大的数据中发现规律,找到宝藏。

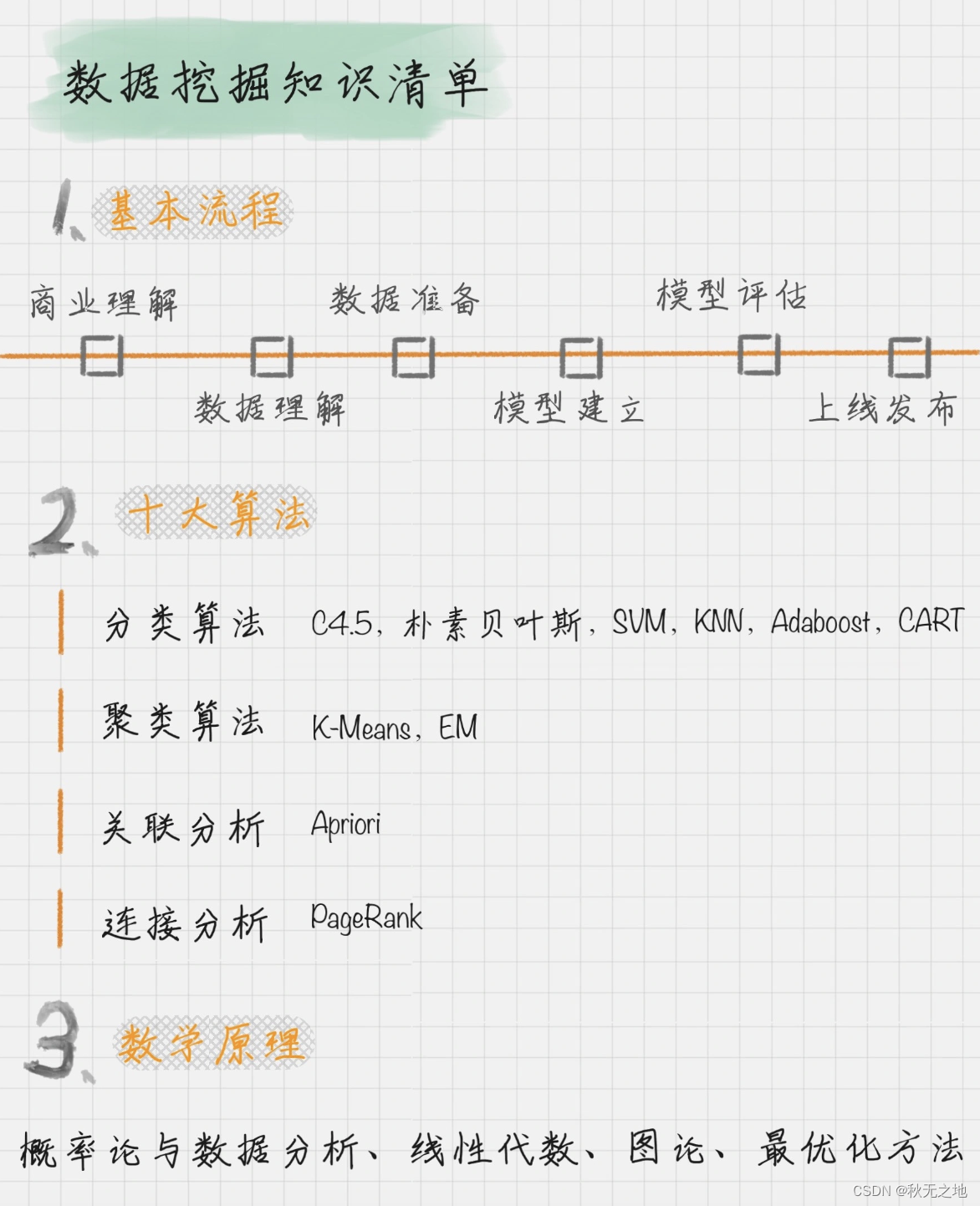
二、数据挖掘的基本流程
数据挖掘主要分为下面6个流程:
- 商业理解:数据挖掘不是我们的目的,我们的目的是更好地帮助业务,所以第一步我们要从商业的角度理解项目需求,在这个基础上,再对数据挖掘的目标进行定义。
- 数据理解:尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等。这有助于你对收集的数据有个初步的认知。
- 数据准备:开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作。
- 模型建立:选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。
- 模型评估:对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的商业目标。
- 上线发布:模型的作用是从数据中找到金矿,也就是我们所说的“知识”,获得的知识需要转化成用户可以使用的方式,呈现的形式可以是一份报告,也可以是实现一个比较复杂的、可重复的数据挖掘过程。数据挖掘结果如果是日常运营的一部分,那么后续的监控和维护就会变得重要。
三、数据挖掘的十大算法
在众多的数据挖掘模型中,国际权威的学术组织 ICDM (the IEEE International Conference on Data Mining)评选出了十大经典的算法。
1. C4.5
C4.5 算法是得票最高的算法,可以说是十大算法之首。C4.5 是决策树的算法,它创造性地在决策树构造过程中就进行了剪枝,并且可以处理连续的属性,也能对不完整的数据进行处理。它可以说是决策树分类中,具有里程碑式意义的算法。
2. 朴素贝叶斯(Naive Bayes)
朴素贝叶斯模型是基于概率论的原理,它的思想是这样的:对于给出的未知物体想要进行分类,就需要求解在这个未知物体出现的条件下各个类别出现的概率,哪个最大,就认为这个未知物体属于哪个分类。
3. SVM
SVM 的中文叫支持向量机,英文是 Support Vector Machine,简称 SVM。SVM 在训练中建立了一个超平面的分类模型。
4. KNN
KNN 也叫 K 最近邻算法,英文是 K-Nearest Neighbor。所谓 K 近邻,就是每个样本都可以用它最接近的 K 个邻居来代表。如果一个样本,它的 K 个最接近的邻居都属于分类 A,那么这个样本也属于分类 A。
5. AdaBoost
Adaboost 在训练中建立了一个联合的分类模型。boost 在英文中代表提升的意思,所以 Adaboost 是个构建分类器的提升算法。它可以让我们多个弱的分类器组成一个强的分类器,所以 Adaboost 也是一个常用的分类算法。
6. CART
CART 代表分类和回归树,英文是 Classification and Regression Trees。像英文一样,它构建了两棵树:一棵是分类树,另一个是回归树。和 C4.5 一样,它是一个决策树学习方法。
7. Apriori
Apriori 是一种挖掘关联规则(association rules)的算法,它通过挖掘频繁项集(frequent item sets)来揭示物品之间的关联关系,被广泛应用到商业挖掘和网络安全等领域中。频繁项集是指经常出现在一起的物品的集合,关联规则暗示着两种物品之间可能存在很强的关系。
8. K-Means
K-Means 算法是一个聚类算法。假设每个类别里面,都有个“中心点”,即意见领袖,它是这个类别的核心。现在我有一个新点要归类,这时候就只要计算这个新点与 K 个中心点的距离,距离哪个中心点近,就变成了哪个类别。
9. EM
EM 算法也叫最大期望算法,是求参数的最大似然估计的一种方法。原理是这样的:假设我们想要评估参数 A 和参数 B,在开始状态下二者都是未知的,并且知道了 A 的信息就可以得到 B 的信息,反过来知道了 B 也就得到了 A。可以考虑首先赋予 A 某个初值,以此得到 B 的估值,然后从 B 的估值出发,重新估计 A 的取值,这个过程一直持续到收敛为止。EM 算法经常用于聚类和机器学习领域中。
10. PageRank
PageRank 起源于论文影响力的计算方式,如果一篇文论被引入的次数越多,就代表这篇论文的影响力越强。同样 PageRank 被 Google 创造性地应用到了网页权重的计算中:当一个页面链出的页面越多,说明这个页面的“参考文献”越多,当这个页面被链入的频率越高,说明这个页面被引用的次数越高。基于这个原理,我们可以得到网站的权重划分。
算法可以说是数据挖掘的灵魂,也是最精华的部分。看完上面的介绍,相信大家对十大算法有一个初步的了解,具体内容不理解没有关系,后面我会详细给大家进行讲解。
四、数据挖掘的数学原理
之前已经提到过,学好数据分析,数据基础是必须的。那是因为数据挖掘中的经典算法,如果不了解概率论和数理统计,是很难掌握算法的本质;如果不懂线性代数,就很难理解矩阵和向量运作在数据挖掘中的价值;如果没有最优化方法的概念,就对迭代收敛理解不深。所以说,想要更深刻地理解数据挖掘的方法,就非常有必要了解它后背的数学原理。
1. 概率论与数理统计
概率论在我们上大学的时候,基本上都学过,不过大学里老师教的内容,偏概率的多一些,统计部分讲得比较少。在数据挖掘里使用到概率论的地方就比较多了。比如条件概率、独立性的概念,以及随机变量、多维随机变量的概念。
2. 线性代数
向量和矩阵是线性代数中的重要知识点,它被广泛应用到数据挖掘中,比如我们经常会把对象抽象为矩阵的表示,一幅图像就可以抽象出来是一个矩阵,我们也经常计算特征值和特征向量,用特征向量来近似代表物体的特征。这个是大数据降维的基本思路。
3. 图论
社交网络的兴起,让图论的应用也越来越广。人与人的关系,可以用图论上的两个节点来进行连接,节点的度可以理解为一个人的朋友数。我们都听说过人脉的六度理论,在 Facebook 上被证明平均一个人与另一个人的连接,只需要 3.57 个人。当然图论对于网络结构的分析非常有效,同时图论也在关系挖掘和图像分割中有重要的作用。
4. 最优化方法
最优化方法相当于机器学习中自我学习的过程,当机器知道了目标,训练后与结果存在偏差就需要迭代调整,那么最优化就是这个调整的过程。一般来说,这个学习和迭代的过程是漫长、随机的。最优化方法的提出就是用更短的时间得到收敛,取得更好的效果
五、总结
版权声明
本文章版权归作者所有,未经作者允许禁止任何转载、采集,作者保留一切追究的权利。