原文链接: go-zero 的自适应熔断器
上篇文章我们介绍了微服务的限流,详细分析了计数器限流和令牌桶限流算法,这篇文章来说说熔断。
熔断和限流还不太一样,限流是控制请求速率,只要还能承受,那么都会处理,但熔断不是。
在一条调用链上,如果发现某个服务异常,比如响应超时。那么调用者为了避免过多请求导致资源消耗过大,最终引发系统雪崩,会直接返回错误,而不是疯狂调用这个服务。
本篇文章会介绍主流熔断器的工作原理,并且会借助 go-zero 源码,分析 googleBreaker 是如何通过滑动窗口来统计流量,并且最终执行熔断的。
工作原理
这部分主要介绍两种熔断器的工作原理,分别是 Netflix 开源的 Hystrix,其也是 Spring Cloud 默认的熔断组件,和 Google 的自适应的熔断器。
Hystrix is no longer in active development, and is currently in maintenance mode.
注意,Hystrix 官方已经宣布不再积极开发了,目前处在维护模式。
Hystrix 官方推荐替代的开源组件:Resilience4j,还有阿里开源的 Sentinel 也是不错的替代品。
hystrixBreaker
Hystrix 采用了熔断器模式,相当于电路中的保险丝,系统出现紧急问题,立刻禁止所有请求,已达到保护系统的作用。
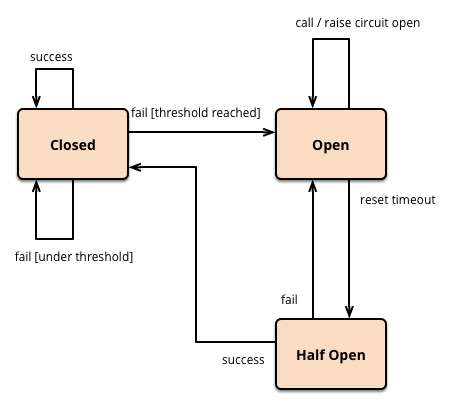
系统需要维护三种状态,分别是:
- 关闭: 默认状态,所有请求全部能够通过。当请求失败数量增加,失败率超过阈值时,会进入到断开状态。
- 断开: 此状态下,所有请求都会被拦截。当经过一段超时时间后,会进入到半断开状态。
- 半断开: 此状态下会允许一部分请求通过,并统计成功数量,当请求成功时,恢复到关闭状态,否则继续断开。
通过状态的变更,可以有效防止系统雪崩的问题。同时,在半断开状态下,又可以让系统进行自我修复。
googleBreaker
googleBreaker 实现了一种自适应的熔断模式,来看一下算法的计算公式,客户端请求被拒绝的概率。
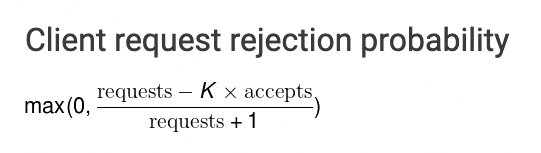
参数很少,也比较好理解:
- requests:请求数量
- accepts:后端接收的请求数量
- K:敏感度,一般推荐 1.5-2 之间
通过分析公式,我们可以得到下面几个结论,也就是产生熔断的实际原理:
- 正常情况下,requests 和 accepts 是相等的,拒绝的概率就是 0,没有产生熔断
- 当正常请求量,也就是 accepts 减少时,概率会逐渐增加,当概率大于 0 时,就会产生熔断。如果 accepts 等于 0 了,则完全熔断。
- 当服务恢复后,requests 和 accepts 的数量会同时增加,但由于 K * accepts 增长的更快,所以概率又会很快变回到 0,相当于关闭了熔断。
总的来说,googleBreaker 的实现方案更加优雅,而且参数也少,不用维护那么多的状态。
go-zero 就是采用了 googleBreaker 的方案,下面就来分析代码,看看到底是怎么实现的。
接口设计
接口定义这部分我个人感觉还是挺不好理解的,看了好多遍才理清了它们之间的关系。
其实看代码和看书是一样的,书越看越薄,代码会越看越短。刚开始看感觉代码很长,随着看懂的地方越来越多,明显感觉代码变短了。所以遇到不懂的代码不要怕,反复看,总会看懂的。

首先来看一下 breaker 部分的 UML 图,有了这张图,很多地方看起来还是相对清晰的,下面来详细分析。
这里用到了静态代理模式,也可以说是接口装饰器,接下来就看看到底是怎么定义的:
// core/breaker/breaker.go
internalThrottle interface {allow() (internalPromise, error)doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
}// core/breaker/googlebreaker.go
type googleBreaker struct {k float64stat *collection.RollingWindowproba *mathx.Proba
}
这个接口是最终实现熔断方法的接口,由 googleBreaker 结构体实现。
// core/breaker/breaker.go
throttle interface {allow() (Promise, error)doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
}type loggedThrottle struct {name stringinternalThrottleerrWin *errorWindow
}func newLoggedThrottle(name string, t internalThrottle) loggedThrottle {return loggedThrottle{name: name,internalThrottle: t,errWin: new(errorWindow),}
}
这个是实现了日志收集的结构体,首先它实现了 throttle 接口,然后它包含了一个字段 internalThrottle,相当于具体的熔断方法是代理给 internalThrottle 来做的。
// core/breaker/breaker.go
func (lt loggedThrottle) allow() (Promise, error) {promise, err := lt.internalThrottle.allow()return promiseWithReason{promise: promise,errWin: lt.errWin,}, lt.logError(err)
}func (lt loggedThrottle) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {return lt.logError(lt.internalThrottle.doReq(req, fallback, func(err error) bool {accept := acceptable(err)if !accept && err != nil {lt.errWin.add(err.Error())}return accept}))
}
所以当它执行相应方法时,都是直接调用 internalThrottle 接口的方法,然后再加上自己的逻辑。
这也就是代理所起到的作用,在不改变原方法的基础上,扩展原方法的功能。
// core/breaker/breaker.go
circuitBreaker struct {name stringthrottle
}// NewBreaker returns a Breaker object.
// opts can be used to customize the Breaker.
func NewBreaker(opts ...Option) Breaker {var b circuitBreakerfor _, opt := range opts {opt(&b)}if len(b.name) == 0 {b.name = stringx.Rand()}b.throttle = newLoggedThrottle(b.name, newGoogleBreaker())return &b
}
最终的熔断器又将功能代理给了 throttle。
这就是它们之间的关系,如果感觉有点乱的话,就反复看,看的次数多了,就清晰了。
日志收集
上文介绍过了,loggedThrottle 是为了记录日志而设计的代理层,这部分内容来分析一下是如何记录日志的。
// core/breaker/breaker.go
type errorWindow struct {// 记录日志的数组reasons [numHistoryReasons]string// 索引index int// 数组元素数量,小于等于 numHistoryReasonscount intlock sync.Mutex
}func (ew *errorWindow) add(reason string) {ew.lock.Lock()// 记录错误日志内容ew.reasons[ew.index] = fmt.Sprintf("%s %s", time.Now().Format(timeFormat), reason)// 对 numHistoryReasons 进行取余来得到数组索引ew.index = (ew.index + 1) % numHistoryReasonsew.count = mathx.MinInt(ew.count+1, numHistoryReasons)ew.lock.Unlock()
}func (ew *errorWindow) String() string {var reasons []stringew.lock.Lock()// reverse orderfor i := ew.index - 1; i >= ew.index-ew.count; i-- {reasons = append(reasons, ew.reasons[(i+numHistoryReasons)%numHistoryReasons])}ew.lock.Unlock()return strings.Join(reasons, "\n")
}
核心就是这里采用了一个环形数组,通过维护两个字段来实现,分别是 index 和 count。
count 表示数组中元素的个数,最大值是数组的长度;index 是索引,每次 +1,然后对数组长度取余得到新索引。
我之前有一次面试就让我设计一个环形数组,当时答的还不是很好,这次算是学会了。
滑动窗口
一般来说,想要判断是否需要触发熔断,那么首先要知道一段时间的请求数量,一段时间内的数量统计可以使用滑动窗口来实现。
首先看一下滑动窗口的定义:
// core/collection/rollingwindow.gotype RollingWindow struct {lock sync.RWMutex// 窗口大小size int// 窗口数据容器win *window// 时间间隔interval time.Duration// 游标,用于定位当前应该写入哪个 bucketoffset int// 汇总数据时,是否忽略当前正在写入桶的数据// 某些场景下因为当前正在写入的桶数据并没有经过完整的窗口时间间隔// 可能导致当前桶的统计并不准确ignoreCurrent bool// 最后写入桶的时间// 用于计算下一次写入数据间隔最后一次写入数据的之间// 经过了多少个时间间隔lastTime time.Duration // start time of the last bucket
}
再来看一下 window 的结构:
type Bucket struct {// 桶内值的和Sum float64// 桶内 add 次数Count int64
}func (b *Bucket) add(v float64) {b.Sum += vb.Count++
}func (b *Bucket) reset() {b.Sum = 0b.Count = 0
}type window struct {// 桶,一个桶就是一个时间间隔buckets []*Bucket// 窗口大小,也就是桶的数量size int
}
有了这两个结构之后,我们就可以画出这个滑动窗口了,如图所示。
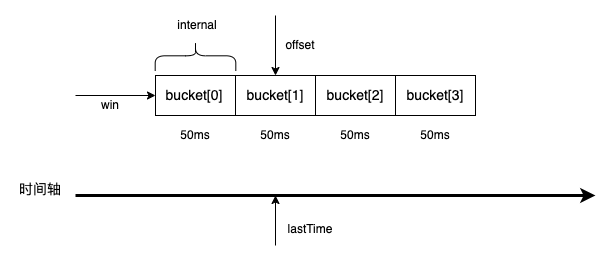
现在来看一下向窗口中添加数据,是怎样一个过程。
func (rw *RollingWindow) Add(v float64) {rw.lock.Lock()defer rw.lock.Unlock()// 获取当前写入下标rw.updateOffset()// 向 bucket 中写入数据rw.win.add(rw.offset, v)
}func (rw *RollingWindow) span() int {// 计算距离 lastTime 经过了多少个时间间隔,也就是多少个桶offset := int(timex.Since(rw.lastTime) / rw.interval)// 如果在窗口范围内,返回实际值,否则返回窗口大小if 0 <= offset && offset < rw.size {return offset}return rw.size
}func (rw *RollingWindow) updateOffset() {// 经过了多少个时间间隔,也就是多少个桶span := rw.span()// 还在同一单元时间内不需要更新if span <= 0 {return}offset := rw.offset// reset expired buckets// 这里是清除过期桶的数据// 也是对数组大小进行取余的方式,类似上文介绍的环形数组for i := 0; i < span; i++ {rw.win.resetBucket((offset + i + 1) % rw.size)}// 更新游标rw.offset = (offset + span) % rw.sizenow := timex.Now()// align to interval time boundary// 这里应该是一个时间的对齐,保持在桶内指向位置是一致的rw.lastTime = now - (now-rw.lastTime)%rw.interval
}// 向桶内添加数据
func (w *window) add(offset int, v float64) {// 根据 offset 对数组大小取余得到索引,然后添加数据w.buckets[offset%w.size].add(v)
}// 重置桶数据
func (w *window) resetBucket(offset int) {w.buckets[offset%w.size].reset()
}
我画了一张图,来模拟整个滑动过程:
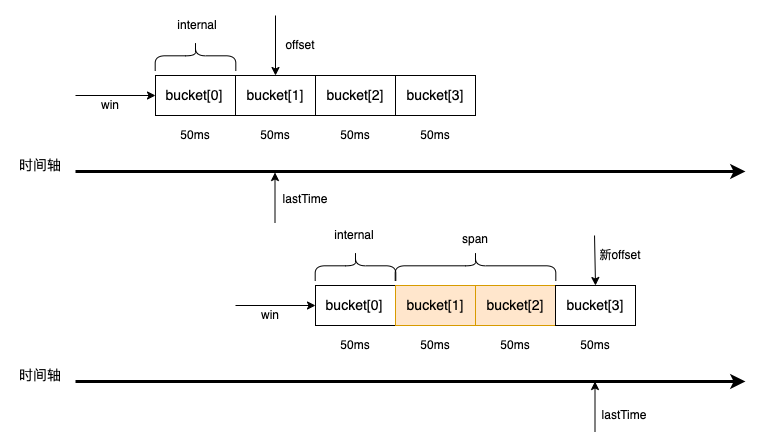
主要经历 4 个步骤:
- 计算当前时间距离上次添加时间经过了多少个时间间隔,也就是多少个 bucket
- 清理过期桶数据
- 更新 offset,更新 offset 的过程实际就是模拟窗口滑动的过程
- 添加数据
比如上图,刚开始 offset 指向了 bucket[1],经过了两个 span 之后,bucket[2] 和 bucket[3] 会被清空,同时,新的 offset 会指向 bucket[3],新添加的数据会写入到 bucket[3]。
再来看看数据统计,也就是窗口内的有效数据量是多少。
// Reduce runs fn on all buckets, ignore current bucket if ignoreCurrent was set.
func (rw *RollingWindow) Reduce(fn func(b *Bucket)) {rw.lock.RLock()defer rw.lock.RUnlock()var diff intspan := rw.span()// ignore current bucket, because of partial dataif span == 0 && rw.ignoreCurrent {diff = rw.size - 1} else {diff = rw.size - span}// 需要统计的 bucket 数量,窗口大小减去 span 数量if diff > 0 {// 获取统计的起始位置,span 是已经被重置的 bucketoffset := (rw.offset + span + 1) % rw.sizerw.win.reduce(offset, diff, fn)}
}func (w *window) reduce(start, count int, fn func(b *Bucket)) {for i := 0; i < count; i++ {// 自定义统计函数fn(w.buckets[(start+i)%w.size])}
}
统计出窗口数据之后,就可以判断是否需要熔断了。
执行熔断
接下来就是执行熔断了,主要就是看看自适应熔断是如何实现的。
// core/breaker/googlebreaker.goconst (// 250ms for bucket durationwindow = time.Second * 10buckets = 40k = 1.5protection = 5
)
窗口的定义部分,整个窗口是 10s,然后分成 40 个 bucket,每个 bucket 就是 250ms。
// googleBreaker is a netflixBreaker pattern from google.
// see Client-Side Throttling section in https://landing.google.com/sre/sre-book/chapters/handling-overload/
type googleBreaker struct {k float64stat *collection.RollingWindowproba *mathx.Proba
}func (b *googleBreaker) accept() error {// 获取最近一段时间的统计数据accepts, total := b.history()// 根据上文提到的算法来计算一个概率weightedAccepts := b.k * float64(accepts)// https://landing.google.com/sre/sre-book/chapters/handling-overload/#eq2101dropRatio := math.Max(0, (float64(total-protection)-weightedAccepts)/float64(total+1))// 如果小于等于 0 直接通过,不熔断if dropRatio <= 0 {return nil}// 随机产生 0.0-1.0 之间的随机数与上面计算出来的熔断概率相比较// 如果随机数比熔断概率小则进行熔断if b.proba.TrueOnProba(dropRatio) {return ErrServiceUnavailable}return nil
}func (b *googleBreaker) history() (accepts, total int64) {b.stat.Reduce(func(b *collection.Bucket) {accepts += int64(b.Sum)total += b.Count})return
}
以上就是自适应熔断的逻辑,通过概率的比较来随机淘汰掉部分请求,然后随着服务恢复,淘汰的请求会逐渐变少,直至不淘汰。
func (b *googleBreaker) allow() (internalPromise, error) {if err := b.accept(); err != nil {return nil, err}// 返回一个 promise 异步回调对象,可由开发者自行决定是否上报结果到熔断器return googlePromise{b: b,}, nil
}// req - 熔断对象方法
// fallback - 自定义快速失败函数,可对熔断产生的err进行包装后返回
// acceptable - 对本次未熔断时执行请求的结果进行自定义的判定,比如可以针对http.code,rpc.code,body.code
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {if err := b.accept(); err != nil {// 熔断中,如果有自定义的fallback则执行if fallback != nil {return fallback(err)}return err}defer func() {// 如果执行req()过程发生了panic,依然判定本次执行失败上报至熔断器if e := recover(); e != nil {b.markFailure()panic(e)}}()err := req()// 上报结果if acceptable(err) {b.markSuccess()} else {b.markFailure()}return err
}
熔断器对外暴露两种类型的方法:
1、简单场景直接判断对象是否被熔断,执行请求后必须需手动上报执行结果至熔断器。
func (b *googleBreaker) allow() (internalPromise, error)
2、复杂场景下支持自定义快速失败,自定义判定请求是否成功的熔断方法,自动上报执行结果至熔断器。
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
个人感觉,熔断这部分代码,相较于前几篇文章,理解起来是更困难的。但其中的一些设计思想,和底层的实现原理也是非常值得学习的,希望这篇文章能够对大家有帮助。
以上就是本文的全部内容,如果觉得还不错的话欢迎点赞,转发和关注,感谢支持。
参考文章:
- https://juejin.cn/post/7030997067560386590
- https://go-zero.dev/docs/tutorials/service/governance/breaker
- https://sre.google/sre-book/handling-overload/
- https://martinfowler.com/bliki/CircuitBreaker.html
推荐阅读:
- go-zero 是如何实现令牌桶限流的?
- go-zero 是如何实现计数器限流的?
- go-zero 是如何做路由管理的?