本系列文章主要是我在学习《数值优化》过程中的一些笔记和相关思考,主要的学习资料是深蓝学院的课程《机器人中的数值优化》和高立编著的《数值最优化方法》等,本系列文章篇数较多,不定期更新,上半部分介绍无约束优化,下半部分介绍带约束的优化,中间会穿插一些路径规划方面的应用实例
九、修正阻尼牛顿法
1、基本牛顿方法
(1)基本牛顿方法介绍
Newton方法是Newton型方法的基础.本文主要讨论基本Newton方法、阻尼Newton方法及修正Newton方法的构造与性质.这类方法适宜于解决中小型最优化问题.
设f(x)具有连续的二阶偏导数,当前迭代点是 x k x_k xk,f(x)在 x k x_k xk处的Taylor展式为
f ( x k + d ) = f k + ∇ f ( x k ) T d + 1 2 d T ∇ 2 f ( x k ) d + o ( ∥ d ∥ 2 ) . f(x_k+d)=f_k+\nabla f\left(x_{k}\right)^\mathrm{T}d+\dfrac12d^{\mathrm T}\nabla^2 f(x_k) d+o(\|d\|^2). f(xk+d)=fk+∇f(xk)Td+21dT∇2f(xk)d+o(∥d∥2).
其中 d = x − x k d= x - x_k d=x−xk ,在点 x k x_k xk的邻域内,用如下二次函数来近似 f ( x k + d ) f(x_k + d) f(xk+d),求解问题
q k ( d ) ≜ f k + ∇ f ( x k ) T d + 1 2 d T ∇ 2 f ( x k ) d q_k(d)\triangleq f_k+ \nabla f\left(x_{k}\right)^\mathrm{T}d+\dfrac12d^{\mathrm T}\nabla^2 f(x_k)d qk(d)≜fk+∇f(xk)Td+21dT∇2f(xk)d
上式中的d也就是 x − x k x-x_k x−xk,所以上式也可写为如下的形式:
q k ( d ) ≜ f ( x k ) + ∇ f ( x k ) T ( x − x k ) + 1 2 ( x − x k ) T ∇ 2 f ( x k ) ( x − x k ) q_k(d)\triangleq f(\boldsymbol{x}_{k})+\nabla f(\boldsymbol{x}_{k})^{T}(\boldsymbol{x}-\boldsymbol{x}_{k})+{\frac{1}{2}}(\boldsymbol{x}-\boldsymbol{x}_{k})^{T}\nabla^{2}f(\boldsymbol{x}_{k})(\boldsymbol{x}-\boldsymbol{x}_{k}) qk(d)≜f(xk)+∇f(xk)T(x−xk)+21(x−xk)T∇2f(xk)(x−xk)

只要上式中的 ∇ 2 f ( x k ) \nabla^2f(x_k) ∇2f(xk)在 x k x_k xk处是正定的,就可以对上式求导,即求梯度等于0的点,得到以下方程组:
∇ 2 f ( x k ) ( x − x k ) + ∇ f ( x k ) = 0 \nabla^2f(\boldsymbol{x}_k)(\boldsymbol{x}-\boldsymbol{x}_k)+\nabla f(\boldsymbol{x}_k)=\boldsymbol{0} ∇2f(xk)(x−xk)+∇f(xk)=0
即:
∇ 2 f ( x k ) d = − ∇ f ( x k ) \nabla^2 f(x_k) d=-\nabla f\left(x_{k}\right) ∇2f(xk)d=−∇f(xk)
若 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)正定,则方程组的解 d k = − ∇ 2 f ( x k ) − 1 ∇ f ( x k ) d_k=-\nabla^2 f(x_k)^{-1}\nabla f\left(x_{k}\right) dk=−∇2f(xk)−1∇f(xk)为上述问题的唯一解,因为基本牛顿法步长取1,因此其迭代式为: x k + 1 = x k − [ ∇ 2 f ( x k ) ] − 1 ∇ f ( x k ) \boldsymbol{x}_{k+1}=\boldsymbol{x}_{k}-\left[\nabla^{2}\boldsymbol{f}(\boldsymbol{x}_{k})\right]^{-1}\nabla f(\boldsymbol{x}_{k}) xk+1=xk−[∇2f(xk)]−1∇f(xk)。

–
由上图可以看出通过不断迭代,可以很快收敛到局部最优解,此外,若目标函数 f ( x ) f(x) f(x)本来就是一个二次函数,其泰勒展开式 q k ( d ) q_k(d) qk(d)近似于它自己,此时,采用牛顿方向,就可以从任何地方经过一次迭代就能到达局部最优解。
所以,对于严格正定的二次函数,采用牛顿方向(步长),可以一步收敛到精确解。
我们称方程组 ∇ 2 f ( x k ) d = − ∇ f ( x k ) \nabla^2 f(x_k) d=-\nabla f\left(x_{k}\right) ∇2f(xk)d=−∇f(xk)为Newton方程,由该方程组得到的方向 d p d_p dp为Newton方向.用Newton方向作为迭代方向的最优化方法称为Newton方法.用Newton方法迭代的意义如下图所示,其中粗虚线表目标函数 f ( x ) f(x) f(x)的等高线,细虚线表 q k ( d ) q_k(d) qk(d)的等高线。
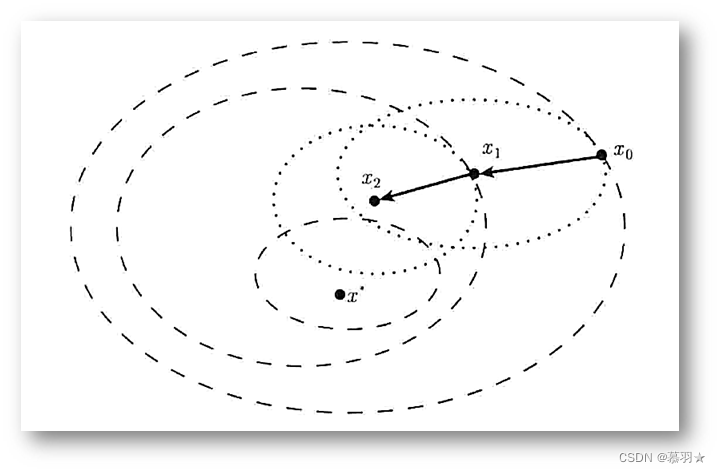
再例如下图中的例子,其中品红色曲线为 x 0 x_0 x0处的二次逼近的等值线,棕色曲线为 x 1 x_1 x1处的二次逼近的等值线

–
(2)基本牛顿方法算法流程
基本Newton方法指取全步长 a k = 1 a_k=1 ak=1的Newton方法, 下面给出基本Newton方法的迭代步骤:

此外,只要 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)正定,Newton方向 d k d_k dk就是下降方向,只要在 x k x_k xk(k=0,1,2,3,…)处 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)均正定,迭代就能不停的进行下去
附:判断一个矩阵是否是正定的方法
一个矩阵是正定的,当且仅当它是对称的(即等于它的转置矩阵)且所有特征值都是正数。特别地,一个正定矩阵是一个非奇异(可逆)矩阵。
判断一个矩阵是否是正定的方法有多种,以下是其中两种常用的方法:
方法① 判断所有特征值是否为正数:设矩阵 A A A 的特征值为 λ 1 , λ 2 , ⋯ , λ n \lambda_1,\lambda_2,\cdots,\lambda_n λ1,λ2,⋯,λn,则 A A A 是正定的当且仅当 λ i > 0 \lambda_i>0 λi>0 对于所有 i = 1 , 2 , ⋯ , n i=1,2,\cdots,n i=1,2,⋯,n。
方法②判断所有主子矩阵的行列式是否为正数:设矩阵 A A A 的 k k k 阶主子矩阵为 A k A_k Ak,即 A k A_k Ak 由 A A A 的前 k k k 行和前 k k k 列组成,则 A A A 是正定的当且仅当 A k A_k Ak 的行列式 det ( A k ) > 0 \det(A_k)>0 det(Ak)>0 对于所有 k = 1 , 2 , ⋯ , n k=1,2,\cdots,n k=1,2,⋯,n。
需要注意的是,这些方法只适用于实对称矩阵,而对于复数矩阵,需要使用其他定义和方法来判断是否是正定的。
一个简单的牛顿法例子如下(拖动或者双击可查看大图):

下面给出了其迭代过程,并与采用恒定步长0.1的梯度下降法进行了对比,从收敛速度来看,牛顿法更优,从稳定性和占用计算资源来看,牛顿法不占优,如果该凸函数的Hesse矩阵是严格正定的就可以满足稳定性,如果有高效的求解Hesse矩阵的方法,就可以减少计算资源的占用。

一般从以下三个方面评价一种数值优化方法:
①、收敛速度:一般认为在对数精度曲线上随着迭代次数的增加,呈直线下降,一般认为收敛较快,如果是朝下的二次曲线,则认为收敛速度更快,如果是朝上的曲线,则认为收敛速度不佳。
②、适用于不同函数时的稳定性:有的要求是强凸的或者凸的,有的可以适应于非凸的函数,甚至是非光滑的函数,甚至是不连续的函数。
③、每次迭代的计算量:每次迭代需要计算多大的计算量,一般跟维度和约束个数有关,一般可用收敛速度和计算量(计算耗时)的乘积来衡量
(3)基本牛顿方法收敛性
Newton方法的收敛性依赖于初始点的选择.当初始点接近极小点时,迭代序列收敛于极小点,并且收敛很快; 否则就会出现迭代序列收敛到鞍点或极大点的情形,或者在迭代过程中出现矩阵奇异或病态的情形,使线性方程组不能求解或不能很好地求解,导致迭代失败.
由基本Newton方法的收敛性定理可知,只有当迭代点充分接近a*时,基本Newton方法的收敛性才能保证。
(4)基本牛顿方法的优缺点
优点:
(1)当 x 0 x_0 x0充分接近问题的极小点x * 时,方法以二阶收敛速度收敛;
(2)方法具有二次终止性.
缺点:
(1)当 x 0 x_0 x0没有充分接近问题的极小点x * 时, ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)会出现不正定或奇异的情形,使{ x k x_k xk}不能收敛到x * ,或使迭代无法进行; 即使 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)正定也不能保证{ f k f_k fk}单调下降。
(2)每步迭代需要计算Hesse矩阵,即计算n(n +1)/2个二阶偏导数.
(3)每步迭代需要解一个线性方程组,计算量为O( n 3 n^3 n3) 。
(4)在很多非凸的函数中曲率可能不是正向的曲率,即使Hesse矩阵是半正定的也会出现奇异值是0的情况,不能对Hesse矩阵求逆也就完成不了一次迭代,因此需要规避Hesse矩阵奇异或者不定的情况,才能快速收敛。
(5)只有当Hesse是正定的时候,它的逆才是正定的,此时乘以一个负梯度方向才能保证牛顿方向与负梯度方向夹角是小于90度的,若Hesse是不定的,则夹角可能是钝角,此时,不能保证牛顿方向是下降方向。即我们要保证牛顿方向与最速下降方向夹角小于90度

2、阻尼牛顿方法
为改善Newton方法的局部收敛性质,我们可以采用带一维搜索的Newton方法,即
x k + 1 = x k + α k d k x_{k+1}=x_{k}+\alpha_k d_k xk+1=xk+αkdk
其中 a k a_k ak 是一维搜索的结果.该方法称为阻尼Newton方法.此方法能够保证对正定的 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk),{ f k f_k fk}单调下降;即使 x k x_k xk离 x ∗ x^* x∗稍远,该方法产生的点列{ x k x_k xk}仍可能收敛至 x ∗ x^* x∗
对严格凸函数,采用Wolfe 准则的阻尼Newton方法具有全局收敛性,且采用Wolfe准则的阻尼Newton方法产生的{ x k x_k xk}满足下列二者之一:
① { x k x_k xk}为有穷点列,即存在N,使得 ∇ f ( x N ) \nabla f\left(x_{N}\right) ∇f(xN)= 0;
② { x k x_k xk}为无穷点列, { x k x_k xk}收敛到 f f f的唯一极小值点 x ∗ x^* x∗
此外,采用精确线搜索、Goldstein 准则等线搜索准则,阻尼Newton方法对严格凸函数的全局收敛性亦存在.
3、修正阻尼牛顿方法(混合方法)
Newton方法在迭代的过程中会出现 Hesse矩阵奇异、不正定的情形,Newton方向会出现与梯度 ∇ f ( x k ) \nabla f\left(x_{k}\right) ∇f(xk)几乎正交的情形.为解决这些问题,人们提出了许多修正Newton方法.这些方法或采用与其他方法混合的方式,或采用隐式地、显式地对Hesse矩阵进行修正的方式对Newton方法进行修正.
笼统来说,修正阻尼牛顿法满足以下框架,其中M是对Hessian矩阵的近似,根据不同的情况,可以选择不同的近似方法,得到不同的M,多种方法组合在一起也就成了混合方法

–
(1)
最简单的修正 Newton方法是针对 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)可逆但不正定情形的.即当 ∇ f ( x k ) \nabla f\left(x_{k}\right) ∇f(xk) ∇ 2 f − 1 ( x k ) \nabla^2 f^{-1}(x_k) ∇2f−1(xk) ∇ f ( x k ) \nabla f\left(x_{k}\right) ∇f(xk) <0时,我们可以简单地取
d k = ∇ 2 f − 1 ( x k ) ∇ f ( x k ) d_k=\nabla^2 f^{-1}(x_k)\nabla f\left(x_{k}\right) dk=∇2f−1(xk)∇f(xk)
使 d k d_k dk是下降方向.然而这样的修正不能处理Newton方法可能遇到的各种情形,如下的混合方法可以处理Newton方法可能遇到的各种情形。
(2)一种混合方法
所谓的混合方法就是一种方法与另外一种或多种方法混合使用的方法.混合的方式有多种,混合的目的是取各方法所长,或者是在一种方法无法继续迭代下去时,采用另一种方法.使迭代得以继续进行.下面我们要考虑的方法是Newton方法与负梯度方法的混合.该方法采用Newton方向,但在 Hesse矩阵 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)奇异或 ∇ f ( x k ) \nabla f\left(x_{k}\right) ∇f(xk)与 d k d_k dk几乎正交时,采用负梯度方向;在 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)负定,但 ∇ 2 f − 1 ( x k ) \nabla^2 f^{-1}(x_k) ∇2f−1(xk)存在时,取 d k d_k dk= ∇ 2 f − 1 ( x k ) \nabla^2 f^{-1}(x_k) ∇2f−1(xk) ∇ f ( x k ) \nabla f\left(x_{k}\right) ∇f(xk).考虑到Newton方法在迭代过程中可能出现的各种情形,我们有如下算法:

该方法的缺点在于,若迭代过程中连续多步使用负梯度方向,收敛速度会趋于负梯度方法的收敛速度.虽然该方法不是非常有效的方法,然而为了让迭代进行下去,它所采用的混合方式还是有代表意义的。
(3)LM方法
LM (Levenberg-Marquardt)方法是处理 ∇ 2 f ( x k ) \nabla^2 f(x_k) ∇2f(xk)奇异、不正定等情形的一个最简单且有效的方法,它是指求解
( ∇ 2 f ( x k ) + ν k I ) d = − ∇ f ( x k ) (\nabla^2 f(x_k)+\nu_kI)d=-\nabla f\left(x_{k}\right) (∇2f(xk)+νkI)d=−∇f(xk)
来确定迭代方向的Newton型方法,这里 v k v_k vk >0,Ⅰ是单位阵.显然,若 v k v_k vk足够大,可以保证 ∇ 2 f ( x k ) + ν k I \nabla^2 f(x_k)+\nu_kI ∇2f(xk)+νkI正定,当 v k v_k vk很小时,上述方程的的解偏向于Newton方向,此时能够保证正定性,随着 v k v_k vk的增大,上述方程的解向负梯度方向偏移.这种修正Newton方法的思想来自解最小二乘问题的LM方法,在后续的文章中讨论关于修正 v k v_k vk的方法.这里当 ∇ 2 f ( x k ) + ν k I \nabla^2 f(x_k)+\nu_kI ∇2f(xk)+νkI不正定时,我们可以简单地取 v k v_k vk=2 v k v_k vk
当 ( ∇ 2 f ( x k ) + ν k I ) (\nabla^2 f(x_k)+\nu_kI) (∇2f(xk)+νkI)正定时可以对其进行Cholesky分解,分解成一个下三角阵乘一个上三角阵的形式,即 ( ∇ 2 f ( x k ) + ν k I ) (\nabla^2 f(x_k)+\nu_kI) (∇2f(xk)+νkI)= L L T LL^T LLT,其中L为下三角阵,通过Cholesky分解可以快速求出以上方程。
LM方法比 Newton方法有效,它能够处理Newton方法所不能处理的情况.
(4)
对于一般的非凸函数,它的Hessian矩阵是不定的,我们可以将Hessian矩阵进行Bunch-Kaufman因式分解,分解成 L B L T LBL^T LBLT,L为下三角阵,B为分块对角阵, L T L^T LT为上三角阵。假设B由1个1x1的对角块,和1个2x2的对角块组成。对于1x1的块,要求其为正数,对于2x2的块的两个特征值必然为1正1负,所以在将Hessian矩阵分解成 L B L T LBL^T LBLT后,将其中的B阵的2x2的块更改为与其最接近的正定阵,即2x2的块的两个特征值均为正,然后再利用修改后的方程求出迭代方向。

参考资料:
1、数值最优化方法(高立 编著)
2、机器人中的数值优化