一、Redisson分布式锁存在问题
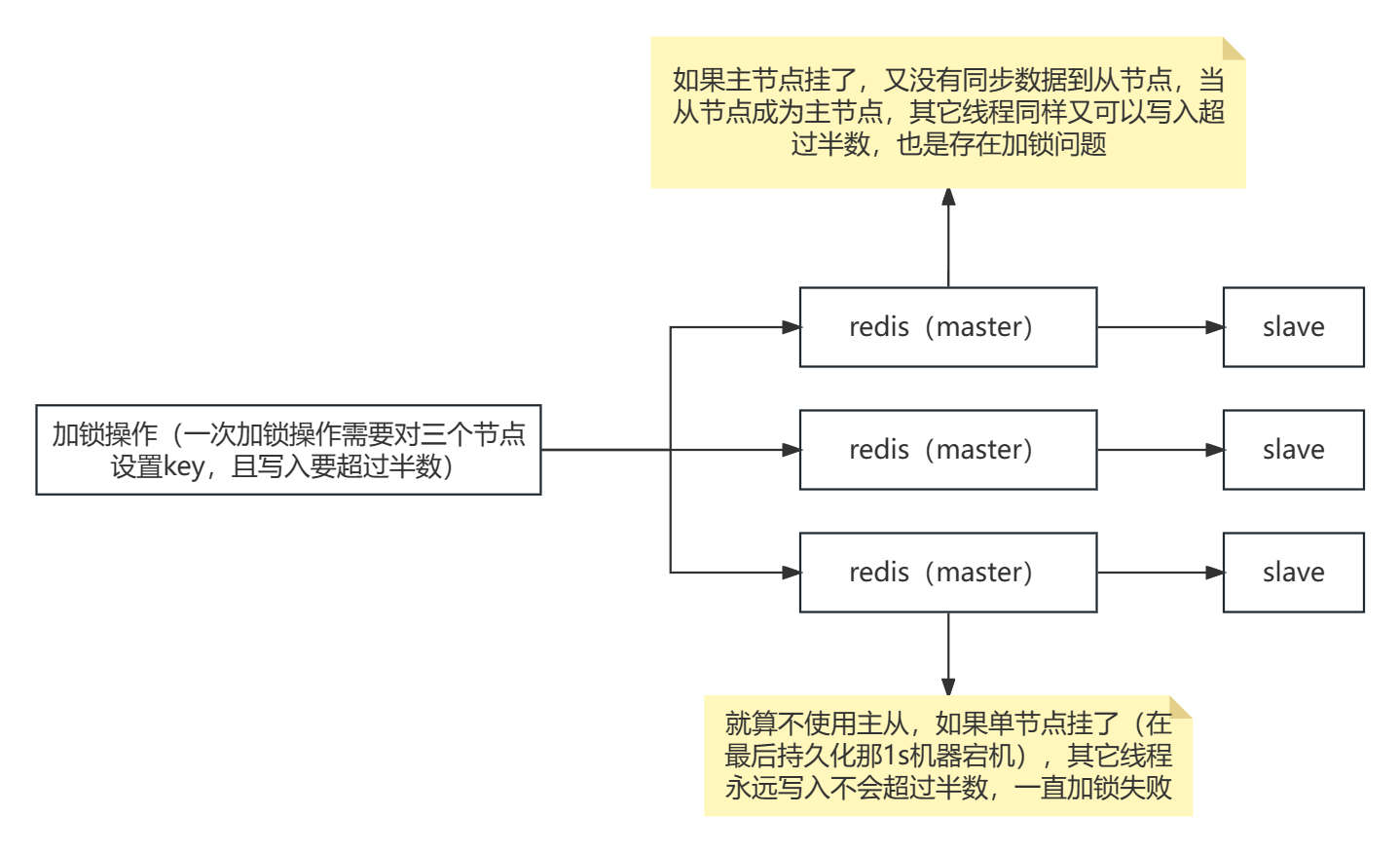
1、基于redis实现的分布式锁,如果redis集群出现master宕机,而从节点没有接收到锁对应的key,被选举成新的master就可能存在被其它线程加锁成功则存在加锁问题
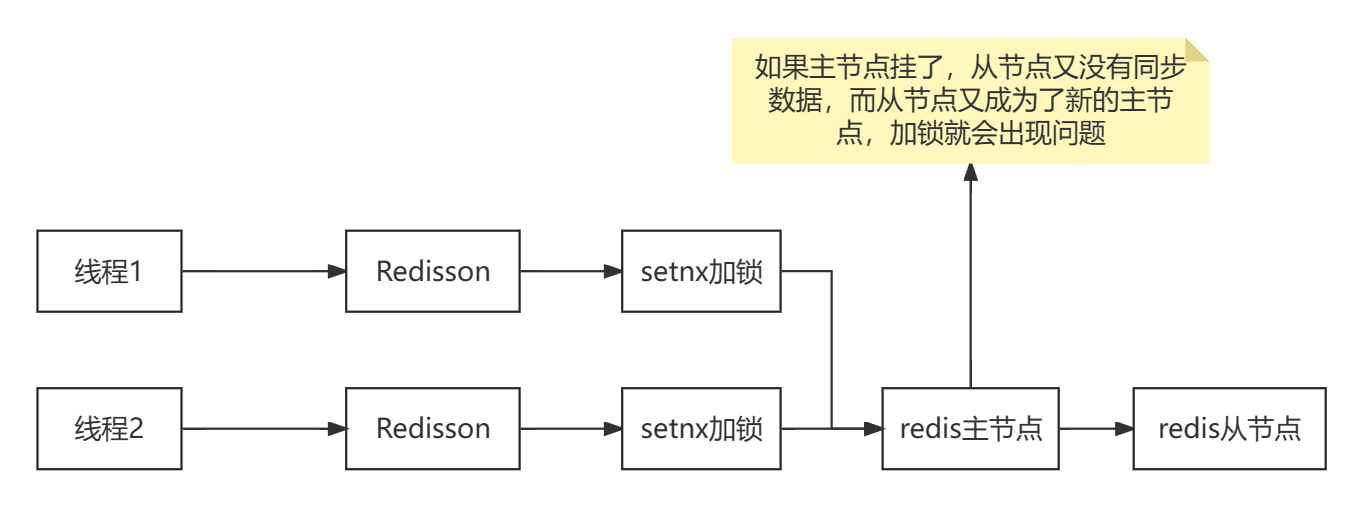
2、 基于上面的问题,可以把redis分为多个节点写入,如果写入超过半数,则加锁成功,否则失败,Redisson的RedLock(红锁)就是这么实现的,需要注意的是如果节点过多,那么加锁的效率就会变慢,如果这样建议用zookeeper
使用
public String reduceStock() {String lockKey = "lock:product_001";//不同的Redis连接同时针对同一个key获取锁RLock lock1 = redissonClient1.getLock(lockKey);RLock lock2 = redissonClient2.getLock(lockKey);RLock lock3 = redissonClient3.getLock(lockKey);// 创建红锁RedissonRedLock redissonRedLock = new RedissonRedLock(lock1, lock2, lock3);//加分布式锁redissonRedLock.lock(); // .setIfAbsent(lockKey, clientId, 30, TimeUnit.SECONDS);try {int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); // jedis.get("stock")if (stock > 0) {int realStock = stock - 1;stringRedisTemplate.opsForValue().set("stock", realStock + ""); // jedis.set(key,value)System.out.println("扣减成功,剩余库存:" + realStock);} else {System.out.println("扣减失败,库存不足");}} finally {//解锁redissonRedLock.unlock();}return "end";}红锁存在问题:
3、如果在高并发场景下想提升性能还可以使用分段锁,比如一个key可以分成多个key存储,再比如一个商品的库存key是product_id,分成100个key,也就是product_id_001...product_id_100,让线程相对并行执行,比如当中有key减完了给个标记 ,这样就可以减轻并发量
4、缓存数据冷热分离:大部分数据其实都没必要一直在缓存中,我们可以用户读redis数据时,重新给对应key设置一个超时时间,当有不同的线程来读这个redis的key就会刷新,这样经常访问的数据就会常驻redis内存
二、缓存穿透
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
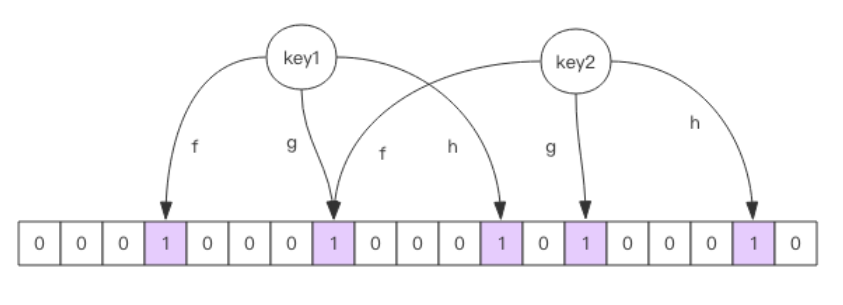
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组长度比较大,存在概率就会很大,如果这个位数组长度比较小,存在概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
可以用redisson实现布隆过滤器,引入依赖:
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.6.5</version>
</dependency>示例伪代码:
package com.redisson;import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;public class RedissonBloomFilter {public static void main(String[] args) {Config config = new Config();config.useSingleServer().setAddress("redis://localhost:6379");//构造RedissonRedissonClient redisson = Redisson.create(config);RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小bloomFilter.tryInit(100000000L,0.03);//将zhuge插入到布隆过滤器中bloomFilter.add("zhuge");//判断下面号码是否在布隆过滤器中System.out.println(bloomFilter.contains("gao"));//falseSystem.out.println(bloomFilter.contains("wang"));//falseSystem.out.println(bloomFilter.contains("wu"));//true}
}使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,布隆过滤器缓存过滤伪代码:
//初始化布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);//把所有数据存入布隆过滤器
void init(){for (String key: keys) {bloomFilter.put(key);}
}String get(String key) {// 从布隆过滤器这一级缓存判断下key是否存在Boolean exist = bloomFilter.contains(key);if(!exist){return "";}// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空, 需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}
}注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据。
三、缓存击穿
有时候数据是批量导入的,redis在记录这些数据的同时,过期时间也是一样的,如果并发量大情况下,大量数据缓存失效,就会直接到数据库,而数据库是无法承受的,可以在批量导入方法中redis设置key的部分代码中加一个随机的过期时间
还有一种情况就是冷门的数据,因为某些原因突然并发量剧增,由于redis之前是没有进行缓存的,大量请求会直接请求数据库,正常的代理逻辑是:1、先从redis中取数据 2、redis中没有对应数据才从数据库中取数据;所以处理的办法就是DCL,进行加分布式锁,加锁范围覆盖逻辑2,在加锁之后数据库查询前再进行一次redis查询,这样第一个线程通过数据库查询出数据,后面线程依次进入加锁逻辑就可以先进行redis查询到数据
public Product get(Long productId) throws InterruptedException {Product product = null;String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;// 进行一次redis查询product = getProductFromCache(productCacheKey);if (product != null) {return product;}//DCLRLock hotCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_PREFIX + productId);hotCacheLock.lock();//boolean result = hotCacheLock.tryLock(3, TimeUnit.SECONDS);try {// 再进行一次redis查询product = getProductFromCache(productCacheKey);if (product != null) {return product;}product = productDao.get(productId);if (product != null) {redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS);productMap.put(productCacheKey, product);} else {redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);}} finally {hotCacheLock.unlock();}return product;}四、缓存雪崩
缓存雪崩指的是缓存层支撑不住或宕掉后, 流量会像奔逃的野牛一样, 打向后端存储层。
由于缓存层承载着大量请求, 有效地保护了存储层, 但是如果缓存层由于某些原因不能提供服务(比如超大并发过来,缓存层支撑不住,或者由于缓存设计不好,类似大量请求访问bigkey,导致缓存能支撑的并发急剧下降), 于是大量请求都会打到存储层, 存储层的调用量会暴增, 造成存储层也会级联宕机的情况。
预防和解决缓存雪崩问题, 可以从以下三个方面进行着手。
1) 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster。
2) 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。
比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
3) 提前演练。 在项目上线前, 演练缓存层宕掉后, 应用以及后端的负载情况以及可能出现的问题, 在此基础上做一些预案设定。
可以使用多级缓存,在redis之前再加一级缓存,jvm内存级别的缓存(为了防止内存泄漏使用Ehcache),只存放热数据,这样就可以减轻redis的压力,但是分布式场景下web服务器是多台的,可能其它web服务器不存在查询的数据,这时候可以维护一个单独的系统计算热搜数据,实时发送给web服务器去更新web服务器jvm级别的缓存
五、热点缓存key重建优化
开发人员使用“缓存+过期时间”的策略既可以加速数据读写, 又保证数据的定期更新, 这种模式基本能够满足绝大部分需求。 但是有两个问题如果同时出现, 可能就会对应用造成致命的危害:
- 当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
- 重建缓存不能在短时间完成, 可能是一个复杂计算, 例如复杂的SQL、 多次IO、 多个依赖等。
在缓存失效的瞬间, 有大量线程来重建缓存, 造成后端负载加大, 甚至可能会让应用崩溃。
要解决这个问题主要就是要避免大量线程同时重建缓存。
我们可以利用互斥锁来解决,此方法只允许一个线程重建缓存, 其他线程等待重建缓存的线程执行完, 重新从缓存获取数据即可。
示例伪代码
String get(String key) {// 从Redis中获取数据String value = redis.get(key);// 如果value为空, 则开始重构缓存if (value == null) {// 只允许一个线程重建缓存, 使用nx, 并设置过期时间exString mutexKey = "mutext:key:" + key;if (redis.set(mutexKey, "1", "ex 180", "nx")) {// 从数据源获取数据value = db.get(key);// 回写Redis, 并设置过期时间redis.setex(key, timeout, value);// 删除key_mutexredis.delete(mutexKey);}// 其他线程休息50毫秒后重试else {Thread.sleep(50);get(key);}}return value;
}六、缓存与数据库双写不一致
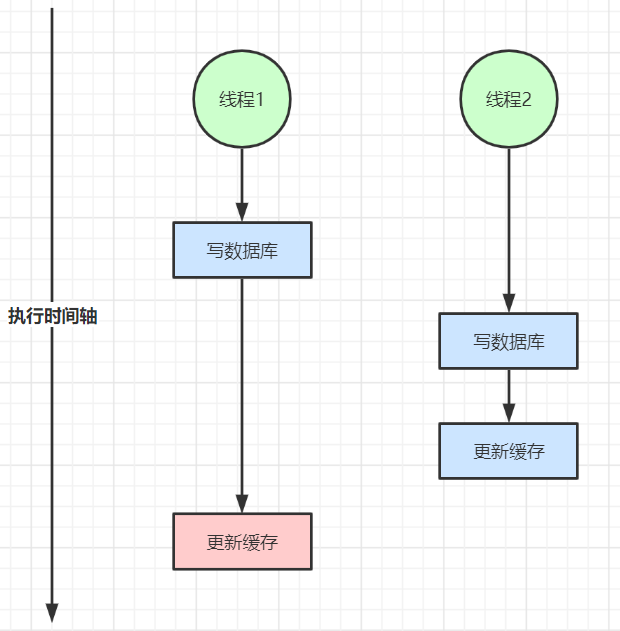
在大并发下,同时操作数据库与缓存会存在数据不一致性问题
1、双写不一致情况
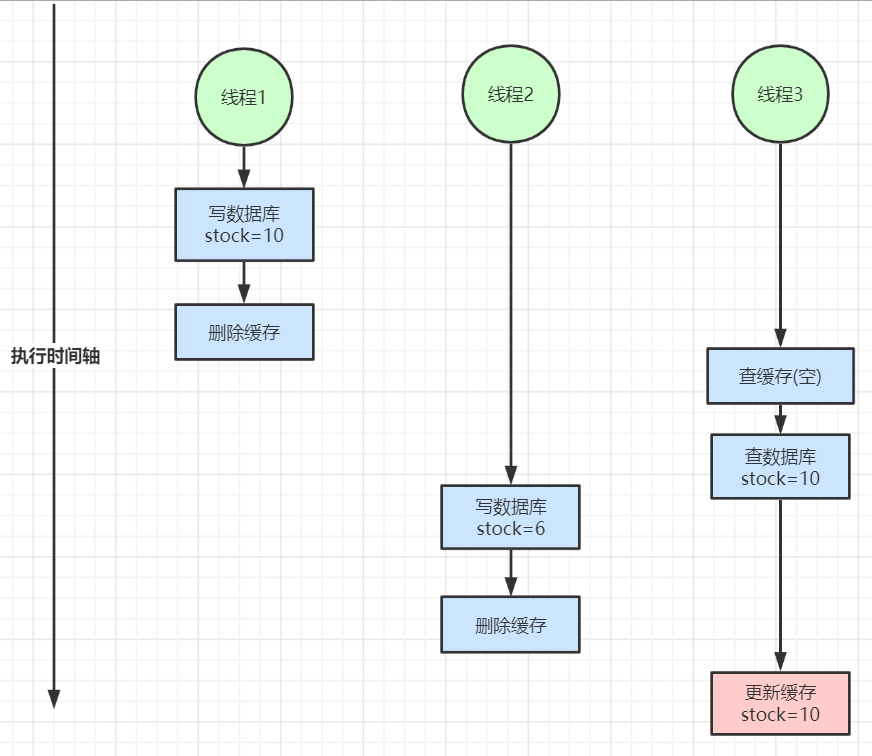
2、读写并发不一致
解决方案:
1、对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
2、就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
3、如果不能容忍缓存数据不一致,可以通过加分布式读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁(Redisson有提供读写锁的实现)。
4、也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。
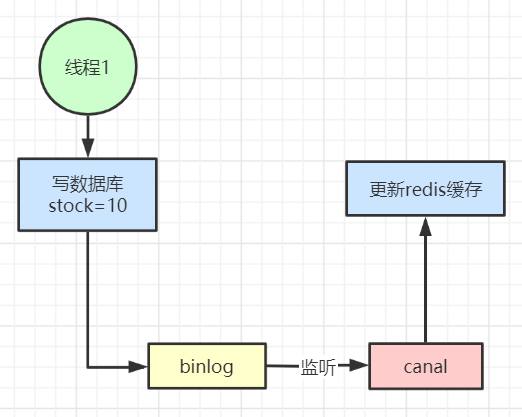
总结:
以上我们针对的都是读多写少的情况加入缓存提高性能,如果写多读多的情况又不能容忍缓存数据不一致,那就没必要加缓存了,可以直接操作数据库。当然,如果数据库抗不住压力,还可以把缓存作为数据读写的主存储,异步将数据同步到数据库,数据库只是作为数据的备份。
放入缓存的数据应该是对实时性、一致性要求不是很高的数据。切记不要为了用缓存,同时又要保证绝对的一致性做大量的过度设计和控制,增加系统复杂性!