全文链接:https://tecdat.cn/?p=33566
生成对抗网络(GAN)是一种神经网络,可以生成类似于人类产生的材料,如图像、音乐、语音或文本(点击文末“阅读原文”获取完整代码数据)。
相关视频
最近我们被客户要求撰写关于GAN生成对抗性神经网络的研究报告,包括一些图形和统计输出。
近年来,GAN一直是研究的热门话题。Facebook的AI研究总监Yann LeCun称对抗训练是“过去10年中最有趣的机器学习领域的想法”。
本文将介绍以下内容:
什么是生成模型以及它与判别模型的区别
GAN的结构和训练方式
如何使用PyTorch构建GAN
如何使用GPU和PyTorch训练GAN以实现实际应用
什么是生成对抗网络?
生成对抗网络是一种可以学习模仿给定数据分布的机器学习系统。它们最早是由深度学习专家Ian Goodfellow及其同事在2014年的一篇NeurIPS论文中提出的。
GAN由两个神经网络组成,一个网络用于生成数据,另一个网络用于区分真实数据和假数据(因此模型具有"对抗"的性质)。虽然生成数据的结构并不新鲜,但在图像和视频生成方面,GAN取得了令人印象深刻的成果,例如:
使用CycleGAN进行风格转换,可以对图像进行多种令人信服的风格转换
利用StyleGAN生成人脸,如网站This Person Does Not Exist上所示
判别模型与生成模型
如果您学习过神经网络,那么您接触到的大多数应用很可能是使用判别模型实现的。而生成对抗网络属于一类不同的模型,被称为生成模型。
在训练过程中,您会使用一个算法来调整模型的参数。目标是通过最小化损失函数使模型学习到给定输入的输出的概率分布。在训练阶段之后,您可以使用该模型通过估计输入最可能对应的数字来对新的手写数字图像进行分类,如下图所示:
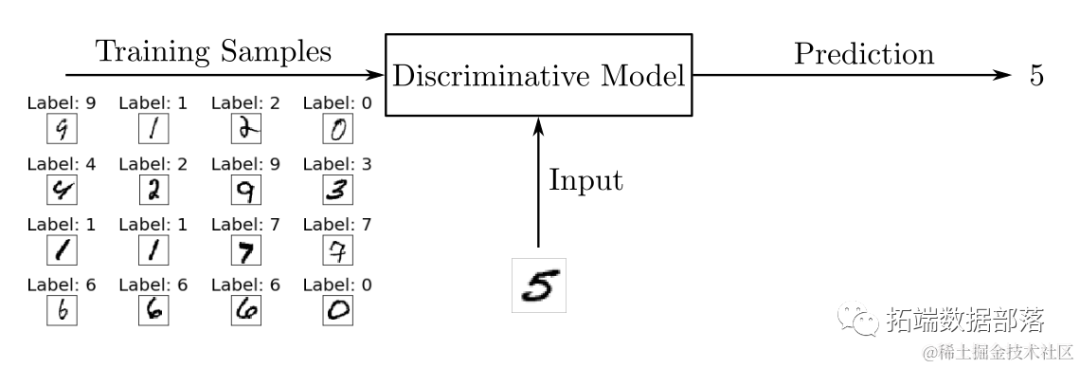
您可以将用于分类问题的判别模型想象成使用训练数据来学习类别之间边界的区块。然后,它们使用这些边界来区分输入并预测其类别。数学上来说,判别模型学习输出y给定输入x的条件概率P(y|x)。
除了神经网络,其他结构也可以用作判别模型,例如逻辑回归模型和支持向量机(SVM)。
然而,生成模型(如GAN)被训练为描述数据集的生成方式,以概率模型的形式进行。通过从生成模型中采样,您可以生成新的数据。虽然判别模型常用于有监督学习,但生成模型通常与无标签的数据集一起使用,并可被视为一种无监督学习的形式。
使用手写数字数据集,您可以训练一个生成模型来生成新的数字。在训练阶段,您会使用某种算法来调整模型的参数,以最小化损失函数并学习训练集的概率分布。然后,通过训练好的模型,您可以生成新的样本,如下图所示:
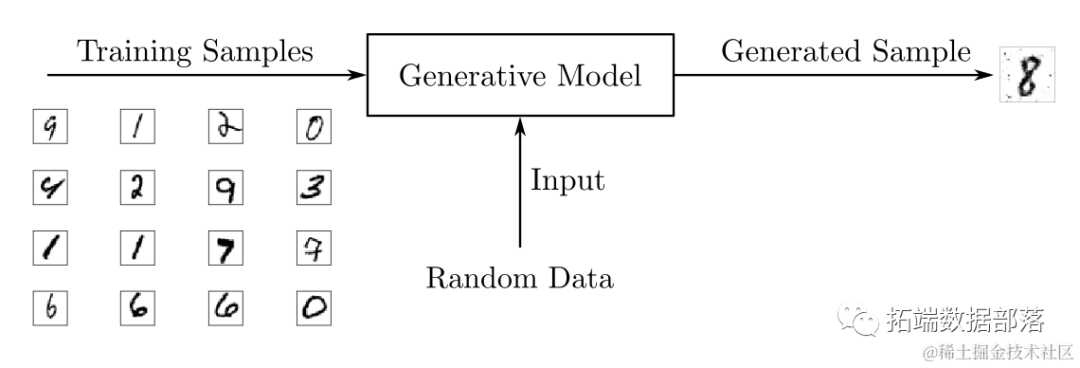
为了输出新的样本,生成模型通常考虑到一个随机元素,该随机元素影响模型生成的样本。用于驱动生成器的随机样本是从"潜在空间"中获得的,在该空间中,向量表示一种压缩形式的生成样本。
与判别模型不同,生成模型学习输入数据x的概率P(x),通过具有输入数据分布,它们能够生成新的数据实例。
尽管GAN近年来受到了广泛关注,但它们并不是唯一可用作生成模型的架构。除了GAN,还有其他各种生成模型架构,例如:
伯劳兹曼机(Boltzmann machines)
变分自编码器(Variational autoencoders)
隐马尔可夫模型(Hidden Markov models)
预测序列中的下一个词的模型,如GPT-2
然而,由于其在图像和视频生成方面取得的令人兴奋的结果,GAN最近引起了公众的最大关注。
现在您已了解生成模型的基础知识,接下来将介绍GAN的工作原理和训练方法。
生成对抗网络(GAN)的架构
生成对抗网络由两个神经网络组成,一个称为"生成器"(generator),另一个称为"判别器"(discriminator)。
生成器的作用是估计真实样本的概率分布,以提供类似真实数据的生成样本。而判别器则被训练来估计给定样本来自真实数据的概率,而不是由生成器提供的。
这些结构被称为生成对抗网络,因为生成器和判别器被训练以相互竞争:生成器试图在愚弄判别器方面变得更好,而判别器试图在识别生成样本方面变得更好。
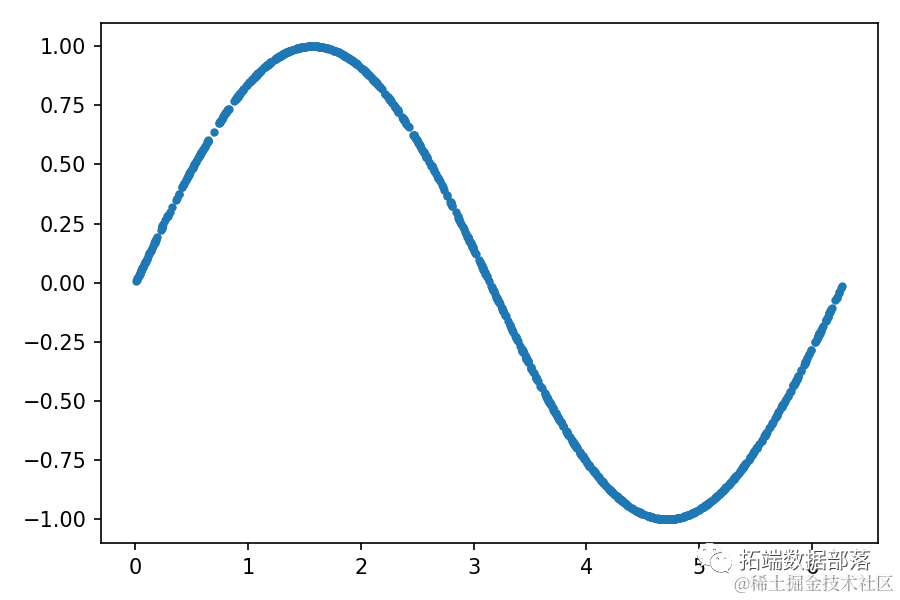
为了理解GAN的训练过程,考虑一个示例,包含一个由二维样本(x₁, x₂)组成的数据集,其中 x₁ 在 0 到 2π 的区间内,x₂ = sin(x₁),如下图所示:
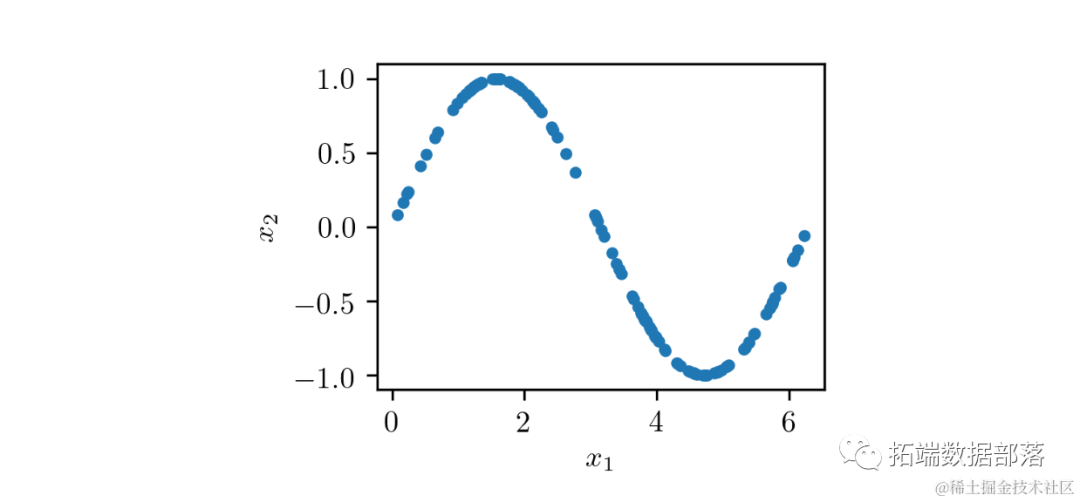
可以看到,这个数据集由位于正弦曲线上的点(x₁, x₂)组成,具有非常特殊的分布。GAN的整体结构用于生成类似数据集样本的(x̃₁, x̃₂)对,如下图所示:
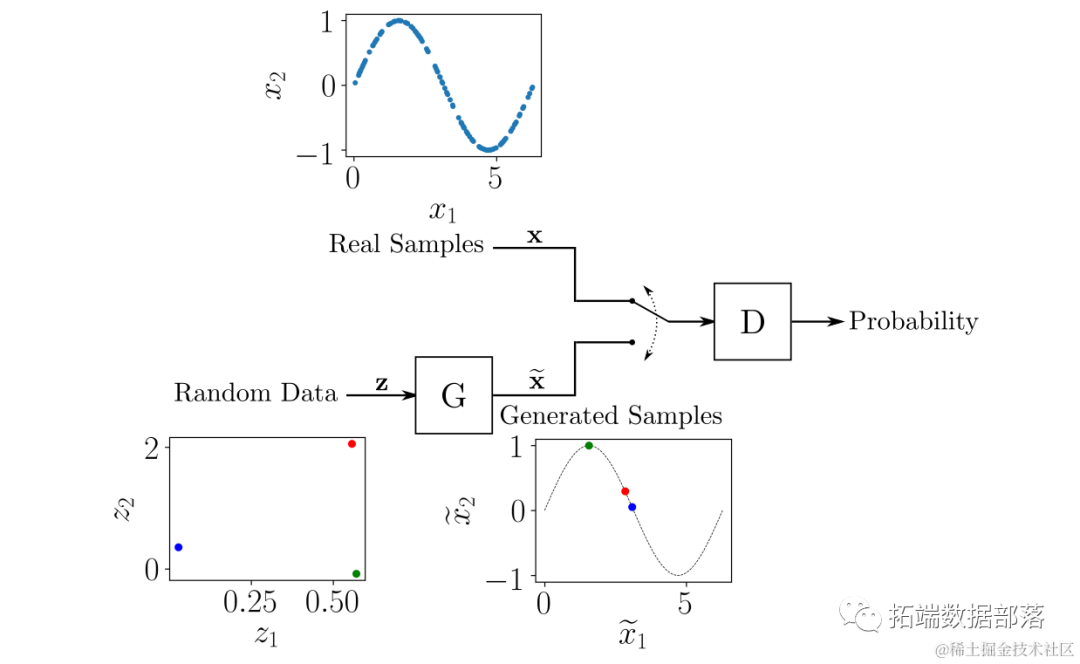
生成器G接收来自潜在空间的随机数据,并且其作用是生成类似真实样本的数据。在这个示例中,我们有一个二维的潜在空间,因此生成器接收随机的(z₁, z₂)对,并要求将它们转化为类似真实样本的形式。
生成对抗网络(GAN)
作为生成对抗网络的初次实验,你将实现前面一节中描述的示例。
要运行这个示例,你需要使用PyTorch库,可以通过Anaconda Python发行版和conda软件包和环境管理系统来安装。
首先,创建一个conda环境并激活它:
$ conda create --name gan
$ conda activate gan当你激活conda环境后,你的命令提示符会显示环境的名称,即gan。然后你可以在该环境中安装必要的包:
$ conda install -c pytorch pytorch=1.4.0
$ conda install matplotlib jupyter由于PyTorch是一个非常活跃的开发框架,其API可能会在新版本中发生变化。为了确保示例代码能够运行,你需要安装特定的版本1.4.0。
除了PyTorch,你还将使用Matplotlib进行绘图,并在Jupyter Notebook中运行交互式代码。这并不是强制性的,但它有助于进行机器学习项目的工作。
在打开Jupyter Notebook之前,你需要注册conda环境gan,以便可以将其作为内核来创建Notebook。要做到这一点,在激活gan环境后,运行以下命令:
$ python -m ipykernel install --user --name gan现在你可以通过运行jupyter notebook来打开Jupyter Notebook。通过点击“新建”然后选择“gan”来创建一个新的Notebook。
在Notebook中,首先导入必要的库:
import torch
from torch import nnimport math
import matplotlib.pyplot as plt在这里,你使用torch导入了PyTorch库。你还导入nn,为了能够以更简洁的方式设置神经网络。然后你导入math来获取pi常数的值,并按照惯例导入Matplotlib绘图工具为plt。
为了使实验在任何机器上都能完全复现,最好设置一个随机生成器种子。在PyTorch中,可以通过运行以下代码来实现:
torch.manual_seed(111)数字111代表用于初始化随机数生成器的随机种子,它用于初始化神经网络的权重。尽管实验具有随机性,但只要使用相同的种子,它应该产生相同的结果。
现在环境已经设置好,可以准备训练数据了。
准备训练数据
训练数据由一对(x₁,x₂)组成,其中x₂是x₁在区间从0到2π上的正弦值。你可以按照以下方式实现它:
train_data_length = 1024train_set = [(train_data[i], train_labels[i]) for i in range(train_data_length)
]在这里,你创建了一个包含1024对(x₁,x₂)的训练集。在第2行,你初始化了train_data,它是一个具有1024行和2列的张量,所有元素都为零。张量是一个类似于NumPy数组的多维数组。
在第3行,你使用train_data的第一列来存储在0到2π区间内的随机值。然后,在第4行,你计算了张量的第二列,即第一列的正弦值。
接下来,你需要一个标签张量,PyTorch的数据加载器需要使用它。由于GAN使用无监督学习技术,标签可以是任何值。毕竟,它们不会被使用。
在第5行,你创建了一个填充了零的train_labels张量。最后,在第6到8行,你将train_set创建为元组列表,其中每个元组代表train_data和train_labels的每一行,正如PyTorch的数据加载器所期望的那样。
你可以通过绘制每个点(x₁,x₂)来查看训练数据:
plt.plot(train_data[:, 0], train_data[:, 1], ".")输出应该类似于以下图形:
使用train_set,您可以创建一个PyTorch数据加载器:
batch_size = 32)在这里,您创建了一个名为train_loader的数据加载器,它将对train_set中的数据进行洗牌,并返回大小为32的样本批次,您将使用这些批次来训练神经网络。
设置训练数据后,您需要为判别器和生成器创建神经网络,它们将组成GAN。在下一节中,您将实现判别器。
实现判别器
在PyTorch中,神经网络模型由继承自nn.Module的类表示,因此您需要定义一个类来创建判别器。
判别别器是一个具有二维输入和一维输出的模型。它将接收来自真实数据或生成器的样本,并提供样本属于真实训练数据的概率。下面的代码展示了如何创建判别器:
class Discriminator(nn.Module):def __init__(self):nn.Linear(64, 1),nn.Sigmoid(),)def forward(self, x):output = self.model(x)return output您使用. __init __()来构建模型。首先,您需要调用super().__init __()来运行nn.Module中的.__init __()。您使用的判别器是在nn.Sequential()中以顺序方式定义的MLP神经网络。它具有以下特点:
第5和第6行:输入为二维,第一个隐藏层由256个神经元组成,并使用ReLU激活函数。
第8、9、11和12行:第二个和第三个隐藏层分别由128个和64个神经元组成,并使用ReLU激活函数。
第14和第15行:输出由一个神经元组成,并使用sigmoidal激活函数表示概率。
第7、10和13行:在第一个、第二个和第三个隐藏层之后,您使用dropout来避免过拟合。
最后,您使用.forward()来描述如何计算模型的输出。这里,x表示模型的输入,它是一个二维张量。在此实现中,通过将输入x馈送到您定义的模型中而不进行任何其他处理来获得输出。
声明判别器类后,您应该实例化一个Discriminator对象:
discriminator = Discriminator()discriminator代表您定义的神经网络的一个实例,准备好进行训练。但是,在实现训练循环之前,您的GAN还需要一个生成器。您将在下一节中实现一个生成器。
实现生成器
在生成对抗网络中,生成器是一个以潜在空间中的样本作为输入,并生成类似于训练集中数据的模型。在这种情况下,它是一个具有二维输入的模型,将接收随机点(z₁,z₂),并提供类似于训练数据中的(x̃₁,x̃₂)点的二维输出。
实现类似于您为判别器所做的操作。首先,您必须创建一个从nn.Module继承并定义神经网络架构的Generator类,然后需要实例化一个Generator对象:
class Generator(nn.Module):def __init__(self):super().__init__()generator = Generator()在这里,generator代表生成器神经网络。它由两个具有16个和32个神经元的隐藏层组成,两者都使用ReLU激活函数,以及一个具有2个神经元的线性激活层作为输出。这样,输出将由一个包含两个元素的向量组成,可以是从负无穷大到正无穷大的任何值,这些值将表示(x̃₁,x̃₂)。
现在,您已定义了判别器和生成器的模型,可以开始进行训练了!
训练模型
在训练模型之前,您需要设置一些参数来在训练过程中使用:
lr = 0.001
num_epochs = 300在这里,您设置了以下参数:
第1行设置学习率(
lr),您将使用它来调整网络权重。第2行设置了周期数(
num_epochs),定义了对整个训练集进行训练的重复次数。第3行将变量
loss_function赋值为二进制交叉熵函数BCELoss(),这是您将用于训练模型的损失函数。
二进制交叉熵函数是训练判别器的适用损失函数,因为它考虑了二元分类任务。它也适用于训练生成器,因为它将其输出馈送给判别器,后者提供一个二进制的可观测输出。
PyTorch在torch.optim中实现了各种权重更新规则用于模型训练。您将使用Adam算法来训练判别器和生成器模型。要使用torch.optim创建优化器,请运行以下代码:
optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)最后,你需要实现一个训练循环,在该循环中,将训练样本输入模型,并更新其权重以最小化损失函数:
for epoch in range(num_epochs):for n, (real_samples, _) in enumerate(train_loader):# 训练判别器的数据real_samples_labels = torch.ones((batch_size, 1))# 训练判别器discriminator.zero_grad()# 训练生成器的数据latent_space_samples = torch.randn((batch_size, 2))# 训练生成器generator.zero_grad()# 显示损失if epoch % 10 == 0 and n == batch_size - 1:对于生成对抗网络(GANs),您需要在每个训练迭代中更新判别器和生成器的参数。与所有神经网络一样,训练过程包括两个循环,一个用于训练周期,另一个用于每个周期的批处理。在内部循环中,您开始准备用于训练判别器的数据:
第2行: 从数据加载器中获取当前批次的真实样本,并将其赋值给
real_samples。请注意,张量的第一个维度具有与batch_size相等的元素数量。这是在PyTorch中组织数据的标准方式,张量的每一行表示批次中的一个样本。第4行: 使用
torch.ones()为真实样本创建标签,并将标签赋给real_samples_labels。第5和第6行: 通过在
latent_space_samples中存储随机数据,创建生成的样本,然后将其输入生成器以获得generated_samples。第7行: 使用
torch.zeros()将标签值0分配给生成的样本的标签,然后将标签存储在generated_samples_labels中。第8到11行: 将真实样本和生成的样本以及标签连接起来,并将其存储在
all_samples和all_samples_labels中,您将使用它们来训练判别器。
接下来,在第14到19行,您训练了判别器:
第14行: 在PyTorch中,每个训练步骤都需要清除梯度,以避免积累。您可以使用
.zero_grad()来实现这一点。第15行: 您使用训练数据
all_samples计算判别器的输出。第16和17行: 您使用模型的输出
output_discriminator和标签all_samples_labels来计算损失函数。第18行: 您使用
loss_discriminator.backward()计算梯度以更新权重。第19行: 您通过调用
optimizer_discriminator.step()来更新判别器的权重。
接下来,在第22行,您准备用于训练生成器的数据。您将随机数据存储在latent_space_samples中,行数与batch_size相等。由于您将二维数据作为输入提供给生成器,因此使用了两列。
然后,在第25到32行,您训练了生成器:
第25行: 使用
.zero_grad()清除梯度。第26行: 将
latent_space_samples提供给生成器,并将其输出存储在generated_samples中。第27行: 将生成器的输出输入判别器,并将其输出存储在
output_discriminator_generated中,您将使用其作为整个模型的输出。第28到30行: 使用分类系统的输出
output_discriminator_generated和标签real_samples_labels计算损失函数,这些标签都等于1。第31和32行: 计算梯度并更新生成器的权重。请记住,当训练生成器时,保持判别器权重冻结,因为您创建了
optimizer_generator,其第一个参数等于generator.parameters()。
最后,在第35到37行,您显示了每十个周期结束时判别器和生成器损失函数的值。
由于此示例中使用的模型参数较少,训练将在几分钟内完成。在接下来的部分中,您将使用训练的GAN生成一些样本。
检查GAN生成的样本
生成对抗网络被设计用于生成数据。因此,在训练过程结束后,您可以从潜在空间中获取一些随机样本,并将它们提供给生成器以获得一些生成的样本:
latent_space_samples = torch.randn(100, 2)然后,您可以绘制生成的样本,并检查它们是否类似于训练数据。在绘制generated_samples数据之前,您需要使用.detach()从PyTorch计算图中返回一个张量,然后使用它来计算梯度:
generated_samples = generated_samples.detach()输出应类似于以下图像:
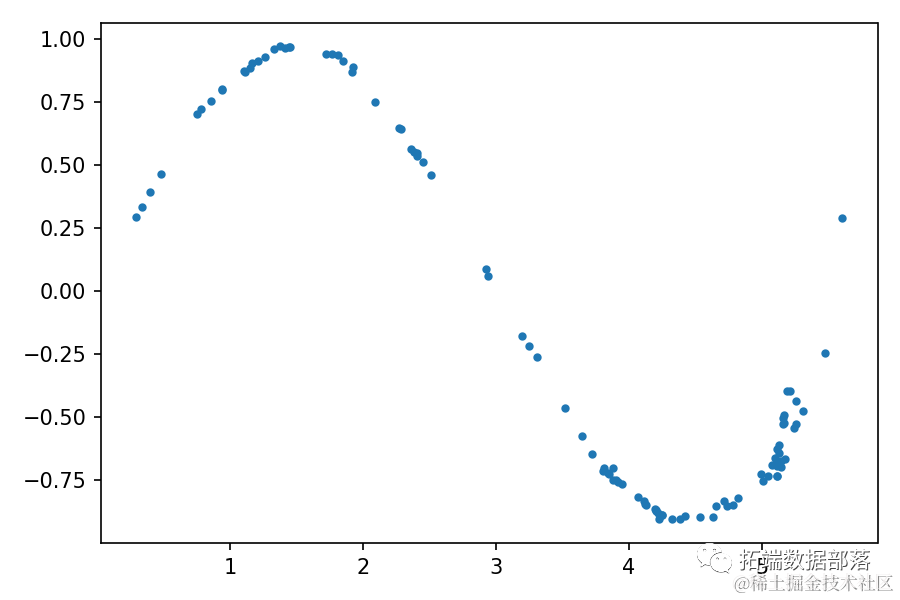
您可以看到,生成的数据分布类似于真实数据。通过使用固定的潜在空间样本张量,并在训练过程的每个周期结束时将其提供给生成器,您可以可视化训练的演变。
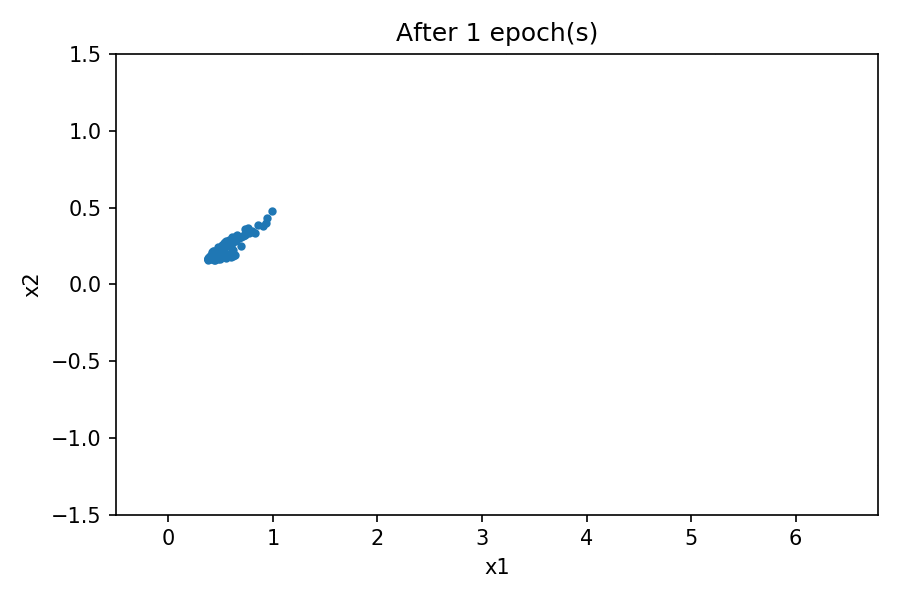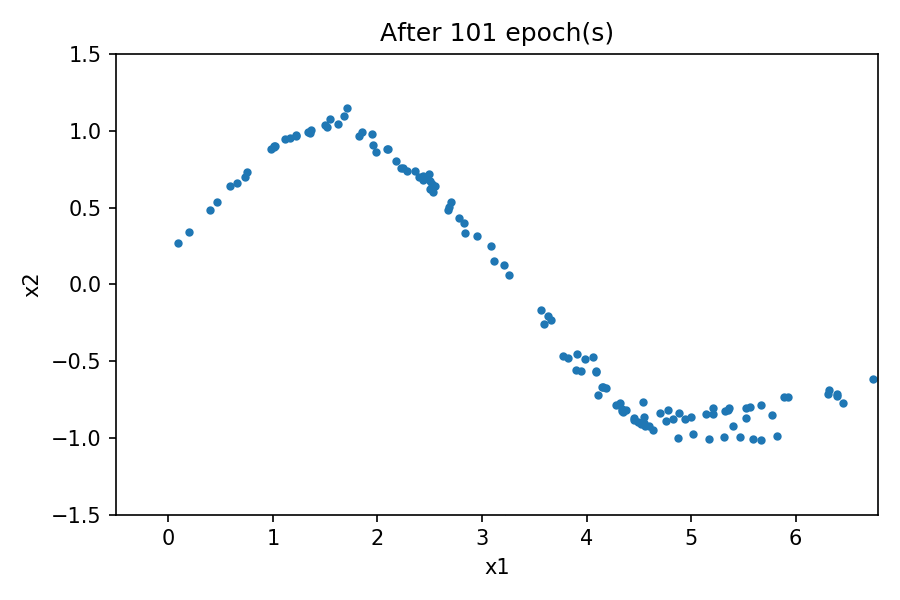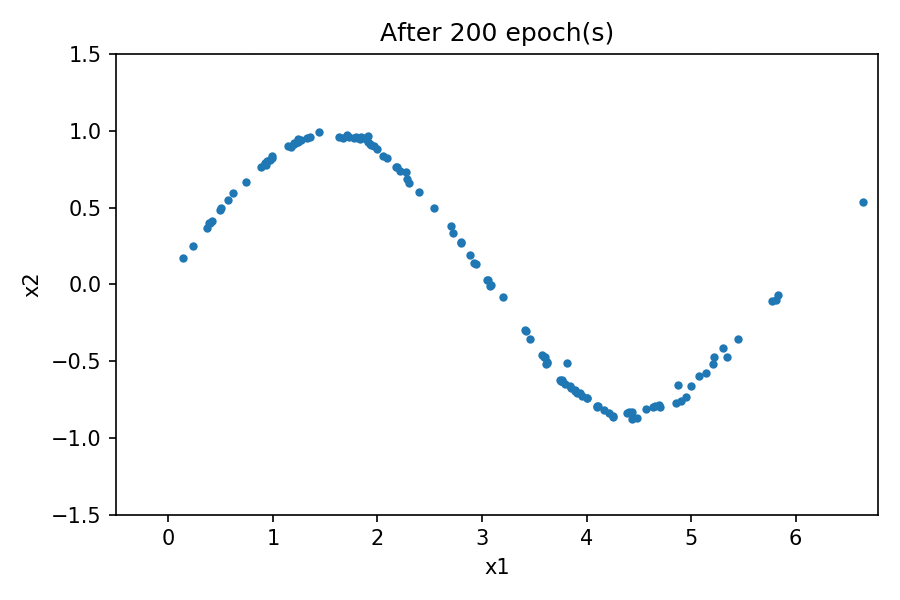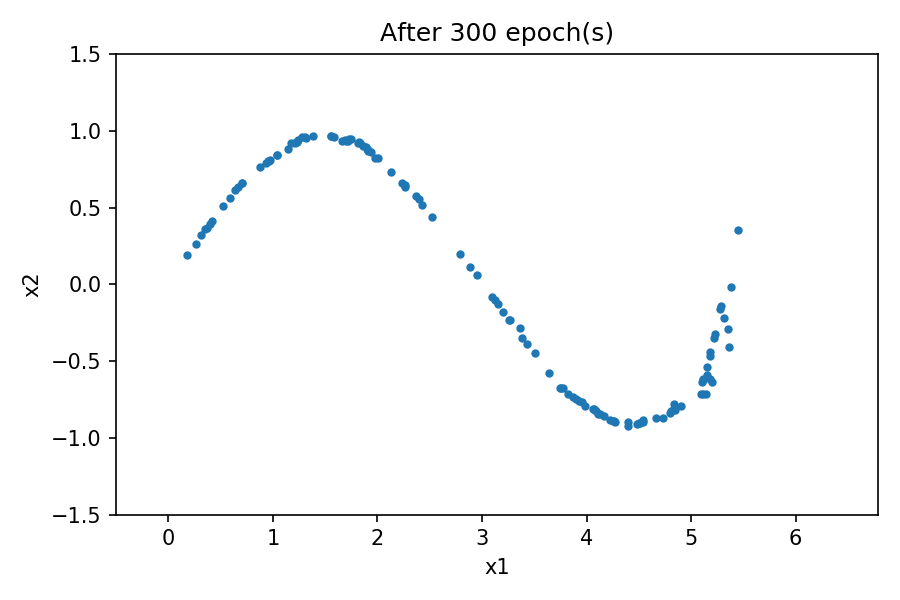
点击标题查阅往期内容

【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析|数据分享

左右滑动查看更多
01
02
03
04
手写数字图像与GAN
生成对抗网络可以生成高维样本,例如图像。在此示例中,您将使用GAN生成手写数字图像。为此,您将使用包含手写数字的MNIST数据集,该数据集已包含在torchvision包中。
首先,您需要在已激活的gan conda环境中安装torchvision:
$ conda install -c pytorch torchvision=0.5.0与前面一样,您使用特定版本的torchvision来确保示例代码可以运行,就像您在pytorch上所做的一样。设置好环境后,您可以在Jupyter Notebook中开始实现模型。
与之前的示例一样,首先导入必要的库:
import torch
from torch import nn除了之前导入的库外,您还将需要torchvision和transforms来获取训练数据并执行图像转换。
同样,设置随机生成器种子以便能够复制实验:
torch.manual_seed(111)由于此示例在训练集中使用图像,所以模型需要更复杂,并且具有更多的参数。这使得训练过程变慢,当在CPU上运行时,每个周期需要大约两分钟。您需要大约50个周期才能获得相关结果,因此在使用CPU时的总训练时间约为100分钟。
为了减少训练时间,如果您有可用的GPU,可以使用它来训练模型。但是,您需要手动将张量和模型移动到GPU上,以便在训练过程中使用它们。
您可以通过创建一个指向CPU或(如果有)GPU的device对象来确保您的代码将在任何一种设置上运行:
device = ""device = torch.device("cpu")稍后,您将使用此device在可用的情况下使用GPU来设置张量和模型的创建位置。
现在基本环境已经设置好了,您可以准备训练数据。
准备训练数据
MNIST数据集由28×28像素的灰度手写数字图像组成,范围从0到9。为了在PyTorch中使用它们,您需要进行一些转换。为此,您定义了一个名为transform的函数来加载数据时使用:
transform = transforms.Compose()该函数分为两个部分:
transforms.ToTensor()将数据转换为PyTorch张量。transforms.Normalize()转换张量系数的范围。
由transforms.ToTensor()产生的原始系数范围从0到1,而且由于图像背景是黑色,当使用此范围表示时,大多数系数都等于0。
transforms.Normalize()通过从原始系数中减去0.5并将结果除以0.5,将系数的范围更改为-1到1。通过这种转换,输入样本中为0的元素数量大大减少,有助于训练模型。
transforms.Normalize()的参数是两个元组(M₁, ..., Mₙ)和(S₁, ..., Sₙ),其中n表示图像的通道数量。MNIST数据集中的灰度图像只有一个通道,因此元组只有一个值。因此,对于图像的每个通道i,transforms.Normalize()从系数中减去Mᵢ并将结果除以Sᵢ。
现在,您可以使用torchvision.datasets.MNIST加载训练数据,并使用transform进行转换:
train_set = torchvision.datasets.MNIST()参数download=True确保您第一次运行上述代码时,MNIST数据集将会被下载并存储在当前目录中,如参数root所指示的位置。
现在您已经创建了train_set,可以像之前一样创建数据加载器:
batch_size = 32
train_loader = torch.utils.data.DataLoader()您可以使用Matplotlib绘制一些训练数据的样本。为了改善可视化效果,您可以使用cmap=gray_r来反转颜色映射,并以黑色数字在白色背景上绘制:
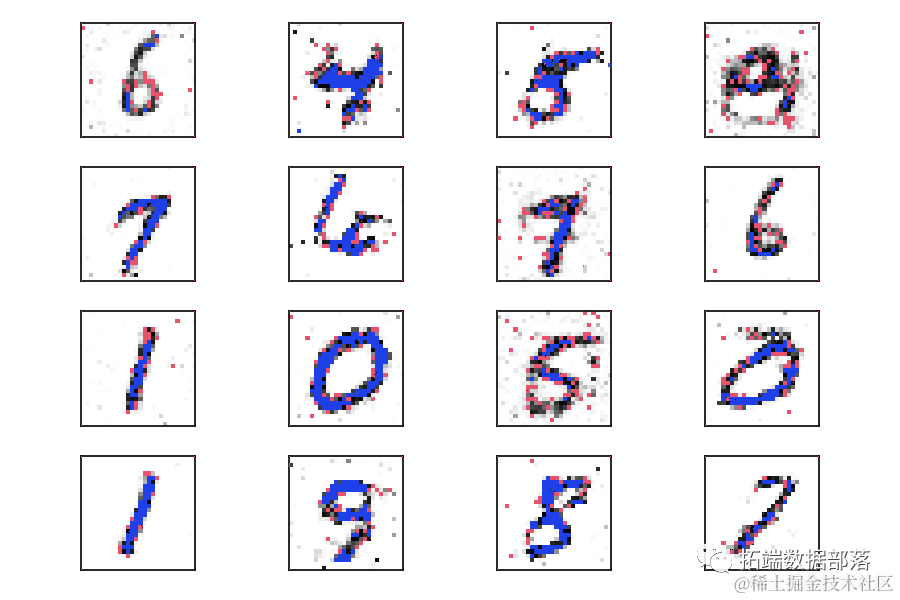
real_samples, mnist_labels = next(iter(train_loader))
for i in range(16):输出应该类似于以下内容:

如您所见,有不同的手写风格的数字。随着GAN学习数据的分布,它还会生成具有不同手写风格的数字。
现在您已经准备好了训练数据,可以实现判别器和生成器模型。
实现判别器和生成器
本例中判别器是一个MLP神经网络,它接收一个28 × 28像素的图像,并提供图像属于真实训练数据的概率。
您可以使用以下代码定义模型:
class Discriminator(nn.Module):def __init__(self):def forward(self, x):return output为了将图像系数输入到MLP神经网络中,可以将它们进行向量化,使得神经网络接收具有784个系数的向量。
矢量化发生在.forward()的第一行,因为调用x.view()可以转换输入张量的形状。在这种情况下,输入x的原始形状是32×1×28×28,其中32是您设置的批量大小。转换后,x的形状变为32×784,每行表示训练集中图像的系数。
要使用GPU运行判别器模型,您必须实例化它并使用.to()将其发送到GPU。要在有可用GPU时使用GPU,可以将模型发送到先前创建的device对象:
discriminator = Discriminator().to(device=device)由于生成器将生成更复杂的数据,因此需要增加来自潜在空间的输入维数。在这种情况下,生成器将接收一个100维的输入,并提供一个由784个系数组成的输出,这些系数将以28×28的张量表示为图像。
下面是完整的生成器模型代码:
class Generator(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(在第12行,使用双曲正切函数Tanh()作为输出层的激活函数,因为输出系数应该在-1到1的区间内。在第20行,实例化生成器并将其发送到device以使用可用的GPU。
现在您已经定义了模型,可以使用训练数据对它们进行训练。
训练模型
要训练模型,需要定义训练参数和优化器,就像在之前的示例中所做的那样:
lr = 0.0001
num_epochs = 50
loss_function = nn.BCELoss()optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)为了获得更好的结果,将学习率从先前的示例中降低。还将将epoch数设置为50,以减少训练时间。
训练循环与之前的示例非常相似。在突出显示的行中,将训练数据发送到device以在有GPU可用时使用:
for epoch in range(num_epochs):for n, (real_samples, mnist_labels) in enumerate(train_loader):e, 100)).to(device=device)loss_generator = loss_function(output_discriminator_generated, real_samples_labels)loss_generator.backward()optimizer_generator.step().: {loss_generator}")某些张量不需要使用device显式地发送到GPU。这适用于第11行中的generated_samples,它将已经被发送到可用GPU,因为latent_space_samples和generator先前已被发送到GPU。
由于此示例具有更复杂的模型,训练可能需要更长时间。训练完成后,您可以通过生成一些手写数字样本来检查结果。
检查GAN生成的样本
要生成手写数字,您需要从潜在空间中随机采样一些样本并将其提供给生成器:
latent_space_samples = torch.randn(batch_size, 100).to(device=device)要绘制generated_samples,您需要将数据移回GPU上运行时,以便在使用Matplotlib绘制数据之前,可以简单地调用.cpu()。与之前一样,还需要在使用Matplotlib绘制数据之前调用.detach():
generated_samples = generated_samples.cpu().detach()
for i in range(16):输出应该是类似训练数据的数字,如以下图片所示:
 经过50个epoch的训练后,生成了一些类似真实数字的生成数字。通过增加训练epoch次数,可以改善结果。
经过50个epoch的训练后,生成了一些类似真实数字的生成数字。通过增加训练epoch次数,可以改善结果。
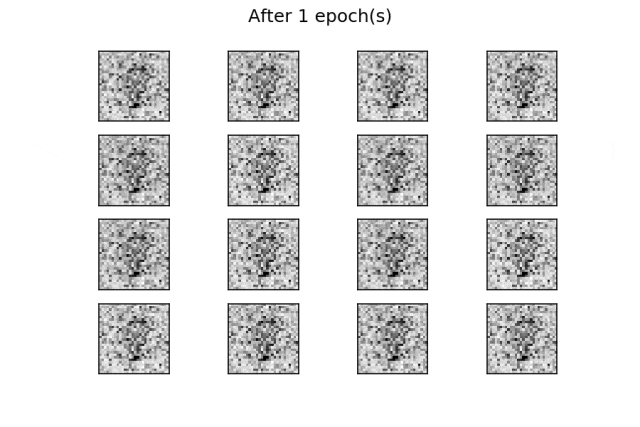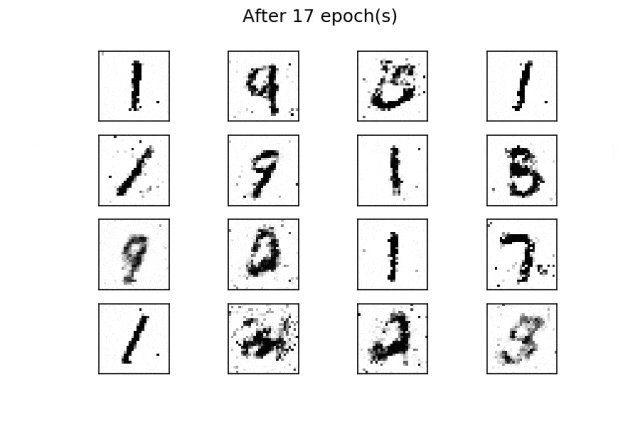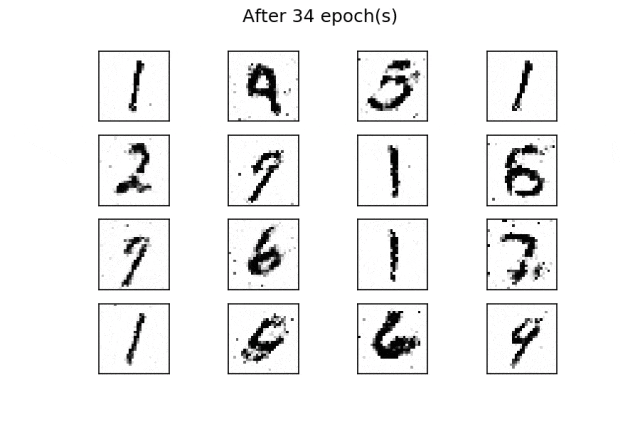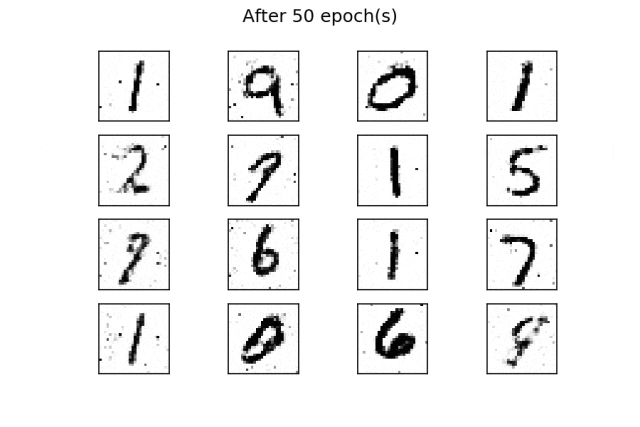
与之前的示例一样,通过在训练过程的每个周期结束时使用固定的潜在空间样本张量并将其提供给生成器,可以可视化训练的演变。
总结
您已经学会了如何实现自己的生成对抗网络。在深入探讨生成手写数字图像的实际应用之前,您首先通过一个简单的示例了解了GAN的结构。
您看到,尽管GAN的复杂性很高,但像PyTorch这样的机器学习框架通过提供自动微分和简便的GPU设置,使其实现更加简单直观。
在本文中,您学到了:
判别模型和生成模型的区别
如何结构化和训练生成对抗网络
如何使用PyTorch等工具和GPU来实现和训练GAN模型
GAN是一个非常活跃的研究课题,近年来提出了几个令人兴奋的应用。如果您对此主题感兴趣,请密切关注技术和科学文献,以获取新的应用想法。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python用GAN生成对抗性神经网络判别模型拟合多维数组、分类识别手写数字图像可视化》。


点击标题查阅往期内容
PYTHON TENSORFLOW 2二维卷积神经网络CNN对图像物体识别混淆矩阵评估|数据分享
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类

![]()