读高性能MySQL(第4版)笔记06_优化数据类型(上)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/106601.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Redis原理:IntSet
(笔记总结自b站黑马程序员课程)
一、结构
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。 结构如下:
typedef struct intset {uint32_t encoding; //编码方式uint32_t l…
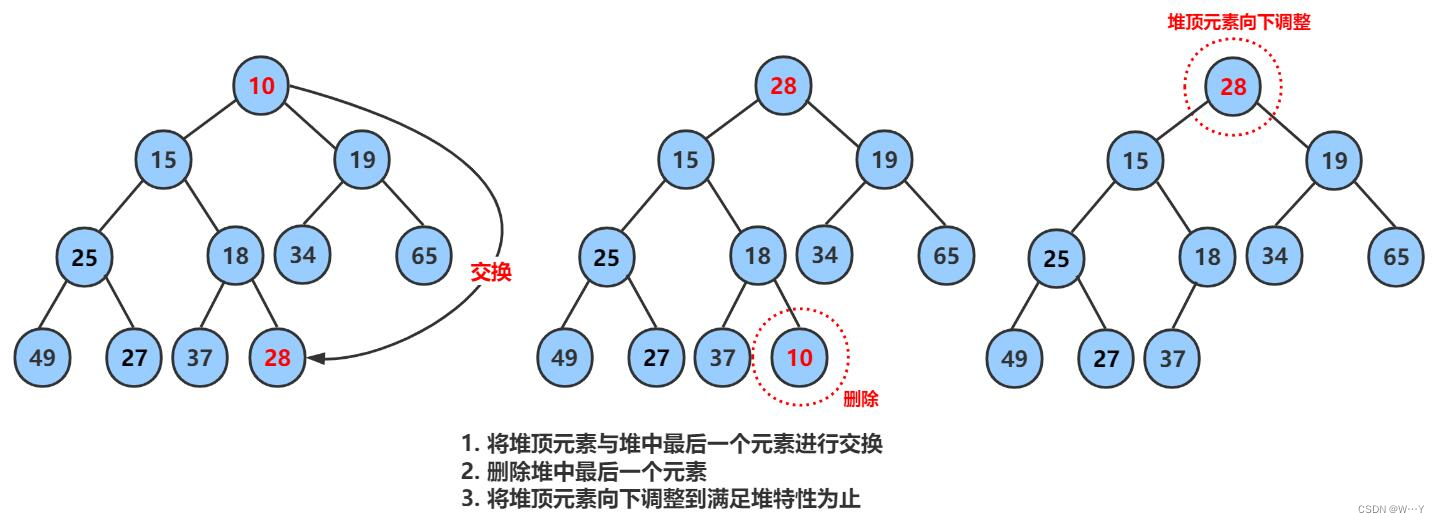
二叉树的顺序结构以及堆的实现——【数据结构】
W...Y的主页 😊
代码仓库分享 💕 上篇文章,我们认识了什么是树以及二叉树的基本内容、表示方法……接下来我们继续来深入二叉树,感受其中的魅力。
目录 二叉树的顺序结构
堆的概念及结构
堆的实现
堆的创建
堆的初始化与…
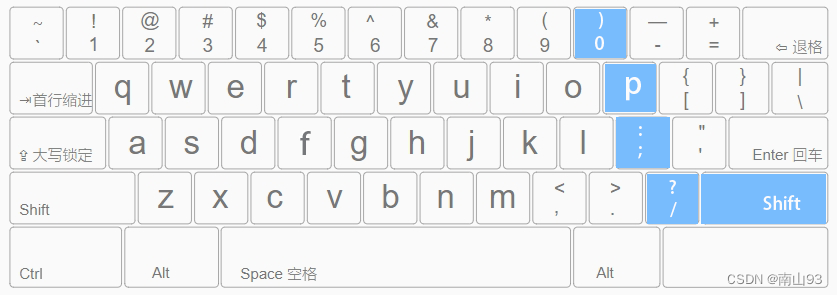
盲打键盘的正确指法指南
简介
很多打字初学者,并不了解打字的正确指法规范,很容易出现只用两根手指交替按压键盘的“二指禅”情况。虽然这样也能实现打字,但是效率极低。本文将简单介绍盲打键盘的正确指法,以便大家在后续的学习和工作中能够提高工作效率…

LINUX 用户和组操作
目录
一、用户和组的分类
1、用户分类
2、组的分类
3、用户和组的配置文件
二、用户管理
1、添加用户
2、修改用户信息
3、修改用户密码
4、用户间切换
5、删除用户账号
6、sudo命令提高普通用户权限
三、用户组管理
1、创建用户组
2、修改用户组的属性
3、添加…
智慧安防/视频分析云平台EasyCVR不显示告警图片该如何解决?
安防视频监控平台EasyCVR可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安防视频监控的能力,也…
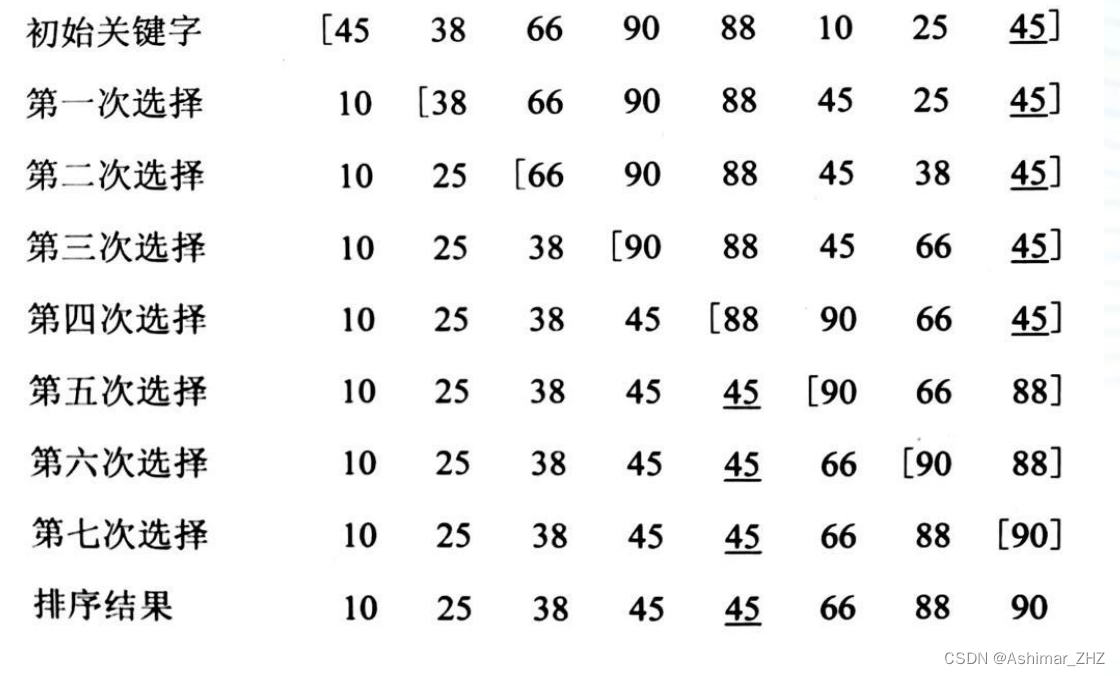
选择排序——直接选择排序
直接选择排序:(以重复选择的思想为基础进行排序)
1、简述
顾名思义就是选出一个数,再去抉择放哪里去。
设记录R1,R2…,Rn,对i1,2,…,n-1,重复下…

【docker快速部署微服务若依管理系统(RuoYi-Cloud)】
工作原因,需要一个比较完整的开源项目测试本公司产品。偶然发现RuoYi-Cloud非常适合,它有足够多的中间件,而且官方提供docker安装,但我本人在安装过程中遇到了很多坑,在这里记录一下防止下次会再次遇到。 项目地址
ht…
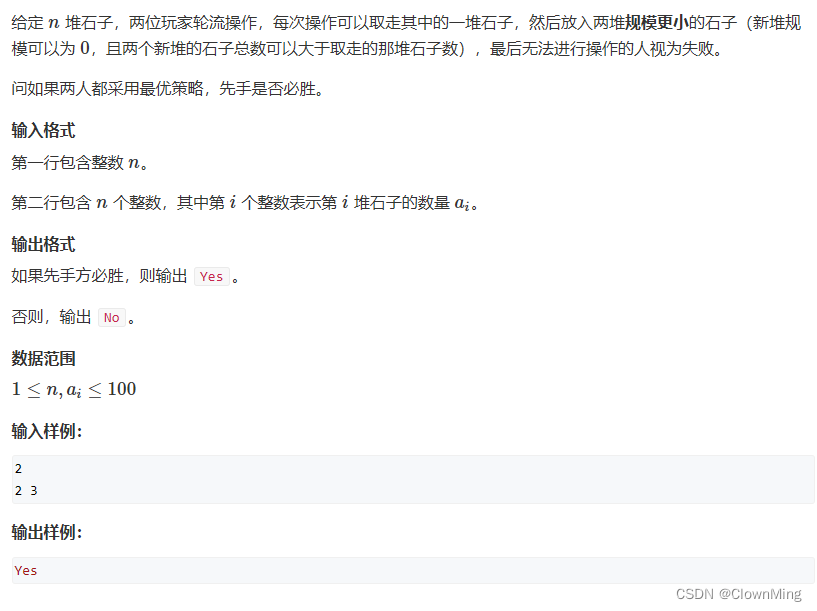
2023-9-11 拆分-Nim游戏
题目链接:拆分-Nim游戏 #include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_set>using namespace std;const int N 110;int f[N];int sg(int x)
{if(f[x] ! -1) return f[x];unordered_set<int> S;f…

从零开发一款ChatGPT VSCode插件
本文作者是360奇舞团开发工程师 引言 OpenAI发布了ChatGPT,就像是给平静许久的互联网湖面上扔了一颗重磅炸弹,刹那间所有人都在追捧学习它。究其原因,它其实是一款真正意义上的人工智能对话机器人。它使用了深度学习技术,通过大…
比较Visual Studio Code中的文件
目录
一、比较两个文件
1.1VS code中的文件大致分为两类: 1.2如何比较VS code中的两个文件? 二、并排差异模式:VS code中的一种差异模式
三、内联差异模式:VS code中的另一种差异模式
四、VS code忽略在行首或者行尾添加或删除…
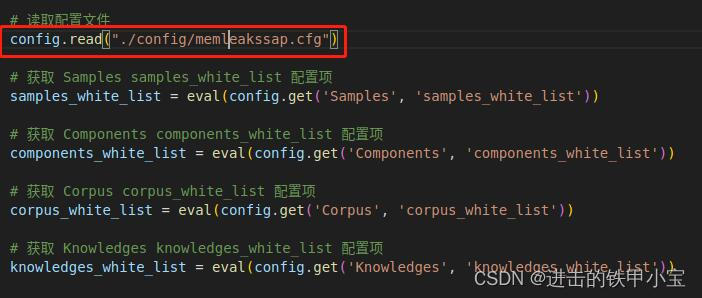
django configparser.NoSectionError: No section: ‘Samples
django configparser.NoSectionError: No section: Samples 背景:Windows下的Django项目,重新部署至Linux ubuntu20中。 samples_white_list eval(config.get(‘Samples’, ‘samples_white_list’)) File “/home/hhl/anaconda3/envs/django/lib/pytho…