01 对大型语言模型(LLM)的
主客观评估
在评估大型语言模型时,我们可以进行客观评估和主观评估。
主观评估的方法是用户亲自尝试不同的模型,提出一些问题,然后根据自己的感受来判断哪个模型好,哪个模型不好。这种评价方法简单直接,但是它很难达到客观、可解释和可量化的程度。
如果需要进行更深入的测试,或者在技术选型和产品开发的前提下选择大型语言模型,那么仅依靠主观评估是不够的,我们还需要一些相对客观的方法。例如通过数据集进行自动化测试,从而获得一个可量化的评估结果。这就需要数据集和相应的验证指标来作为客观依据。
02 评估数据集与评估方法
目前已有一些可用于评估大规模预训练模型的数据集,有英文、中文等多种语言语料,尤其是英文数据集,相当丰富。其中很大一部分数据来源于考试题目,例如小学生数学考试题,中学英语测试题,物理常识等。
这些数据集可以用于评估模型在简单常识和基础知识方面的表现。但当我们需要针对某个垂直领域进行深度评估时,这些数据就不够用了。尤其是对于一些较为冷门或需要精深专业知识的领域,公开的数据集往往难以满足需求。
在这种情况下,评估者就需要自己动手创建专业数据集。至于构建方法,最直接的:领域专家可以根据自己的知识和经验,人工创建问题,并自己给出对应答案,然后将这个问题和答案写出来,形成一个问题-答案对(QA pair)。通过创建若干个问题-答案对,就可以得到一份满足特定领域需求的问答数据集。
接下来,评估者可以使用这些QA pair的问题作为提示(prompt),分别输入给待测试的LLM。然后将它们的回应与预设的答案进行比较,以判断回答是否正确。这样就可以对模型的正确性进行评估。在正确性评估的基础上,还可以对语言模型带给用户的体验进行主观评分。
03 利用知识图谱构建评估数据集
然而,领域专家人工出题存在一定的随机性,而且,即使出题者本人也可能在几天后都无法回想起为什么会提出这样一个问题。此外,数据集中的问题是否具有足够的覆盖面、基础性或深度也是值得考虑的因素。
如何才能以尽量小的人工投入获得一份覆盖全面,既具备基础性又具备专业性的评估数据集呢?我们可以尝试基于专业知识图谱来创建专业评估数据集,也就是专业知识问答对。
首先当然需要构建一个专业知识图谱。这个知识图谱不需要过于庞大,几百个节点就可以达到良好的效果。
然后,基于这个知识图谱来创建问答对。这使得问答的知识覆盖面,以及问答难度都变得非常明显,且具有可追溯性。
我们一起来看一个例子,比如下图这个春秋战国知识图谱:

从这个知识图谱中,我们可以看到春秋战国时期的人物、国家、事件和著作等实体,以及它们之间的关系。
这个图谱本身是人工生成的,我们的实习生用了大概2周的时间创建了整个图谱的逻辑结构,并利用开源的SmartKG(https://github.com/microsoft/smartkg)进行了存储管理与可视化。
图谱的规模并不大,总共包含300多个节点,即300多个实体。从可视化效果也不难看出,实体之间的关系并不非常稠密,而是相对联通的。
基于这一图谱内蕴含的知识,我们首先生成了一个非常小的数据集,总共只包含20个问题。并用这个微小数据评估了文心一言、讯飞星火、GPT4和GPT3.5,具体过程和结果前面的文章已经有所阐述。
需要注意的是,这个微小数据集并不适合作为一个真正的评估数据来使用。它只是为了让大家了解,在这个非常小的数据集上,我们也可以得出一些有趣的结论。然而,它的规模实在是太小了。
那么我们有没有可能基于同一个知识图谱,来构建更多的问题答案对呢?当然是可以的。不仅可以,而且这个构建过程可以自动化完成。
04 自动化构建评估数据集
实际上,自动构建问题答案对一个并不复杂的过程。这样做的关键在于利用知识图谱的结构。
在知识图谱中,一个实体和一个源自该实体的关系可以组合成一个问题。这个关系所对应的目标实体就是这个问题的答案。
以春秋战国图谱中的一个小片段为例
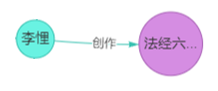
我们看实体为“李悝”,源自它的关系是“创作”,这一关系的目标实体是“法经六篇”。因此,我们可以构造出一个问题:“李悝创作了什么著作?”答案便是“法经六篇”。
图谱中,有许多这类一级关系,因此可以构成许多问题和答案。
除了一级关系,还有二级、三级甚至四五六七八级的关系。通过这些关系,我们同样可以构成新的问题。
来看一个图谱中的二级关系
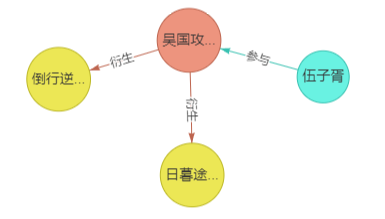
据此,我们可以提一个问题——“与伍子胥有关的成语都有什么?” 答案是:“道行逆师和日暮途穷。”
实际上,“伍子胥”并不能直接连接到某个成语,但是通过他参与的事件——“吴国攻打楚国”——我们可以找到两条衍生出的成语:“道行逆师”和“日暮途穷”。这样的问题同样可以构成一个问答对,只不过它不再是一步到位,而是进行了一个一级的推理。
类似的例子还有很多,通过这种方式,我们可以构建出更多的问题和答案。
依据知识图谱的内在结构,我们仅需一些简单的程序,便能自动生成这些问题和答案。
05 自动化评估LLM
同样,我们可以自动地将这些提示抛给LLM,收集其响应。对于这些响应,最简单的方法是在对其和正确答案都进行嵌入(embedding)后,比较它们的相似度,从而判断LLM的响应是否正确回答了问题。
此外,如果我们有更多的资金,我们可以将响应和答案同时提交给已知质量较高的LLM,让这个LLM判断它们的含义是否近似,是否陈述了相同的事实……通过这种方式,我们可以判断答案的对错。
然后通过将主观评价的规则输入给LLM,来对收集到的相应进行主观评分。这些都是我们可以自动化执行的方法和手段。
加入社群

我们聚焦科技创新和行业发展,欢迎加入我们的社群,你将与优秀的人士共同探讨行业趋势、分享经验和思考未来的发展方向。
Step1|添加小助理微信(DTPfuneng),留言:“加入社群”+关注方向;
Step2|说明姓名+工作单位/学校,并发送名片(需提供名片验证)
加入Public100

如果您有与AIGC相关的故事,欢迎来到Public 100,与我们一起畅聊.
ATP Public100是一项公益活动,聚焦科技行业,专注垂直领域的知识、观点和行业剖析,并将其传达给全球的伙伴们,欢迎你加入我们!
欢迎关注微软 ATP 官方账号
微软 ATP 一手资讯抢先了解




点击“阅读原文” | 了解更多 AI 赋能案例





![算法:经典贪心算法--跳一跳[2]](https://img-blog.csdnimg.cn/664c03a879484bd1b922f33044384e14.png#pic_center)
