一、介绍
普罗米修斯提供了一种称为PromQL(普罗米修斯查询语言)的函数式查询语言,允许用户实时选择和聚合时间序列数据。
表达式的结果可以显示为图形,在 Prometheus 的表达式浏览器中显示为表格数据,也可以通过 HTTP API 由外部系统使用。
通常初学者可以在浏览器总,通过 Prometheus 的查询框输入查询语句,从而获取到查询结果。
二、PromQL 数据类型
在普罗米修斯的表达语言中,表达式或子表达式计算结果可以是如下四种类型之:
-
Instant vector即时矢量 一组按照当前时间戳获取的监控指标时间序列数据样本,例如当前服务器内存可以大小,当前服务器的CPU使用率等。
示例:
假设目前监控了 3 台服务器,现在我希望获取 3 台服务器此刻每台服务器的内存剩余可用容量。可以输入语句:node_memory_MemAvailable_bytes应该返回如下样式的数据:
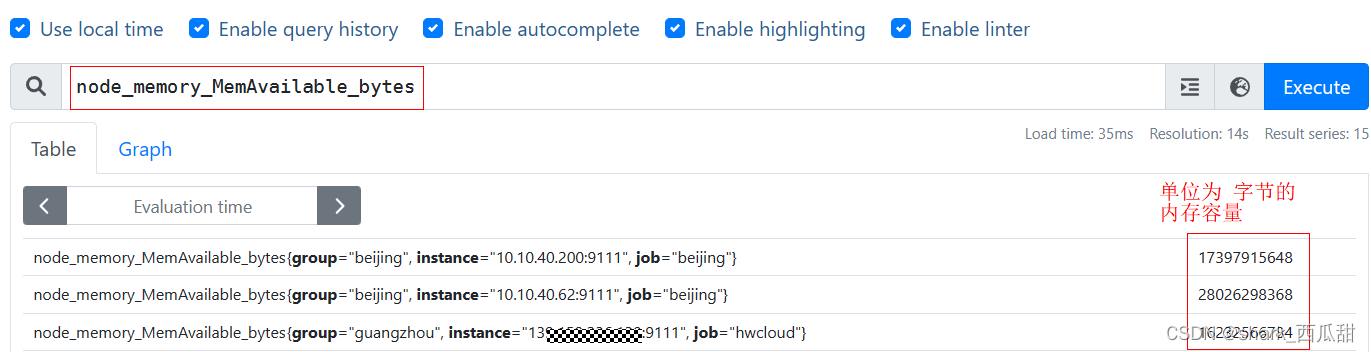
上图中每一行都是一个服务器的数据样本,后面是具体的数据,单位: 字节。
- Range vector 范围矢量 一组按照指定时间范围获取到的监控指标时间序列数据,包含了在这个时间范围内,随着时间变化而变化的数据样本,例如最近 15 秒内的内存剩余可用数据。
可以输出查询语句:node_memory_MemAvailable_bytes[15s]
获取到如下结果
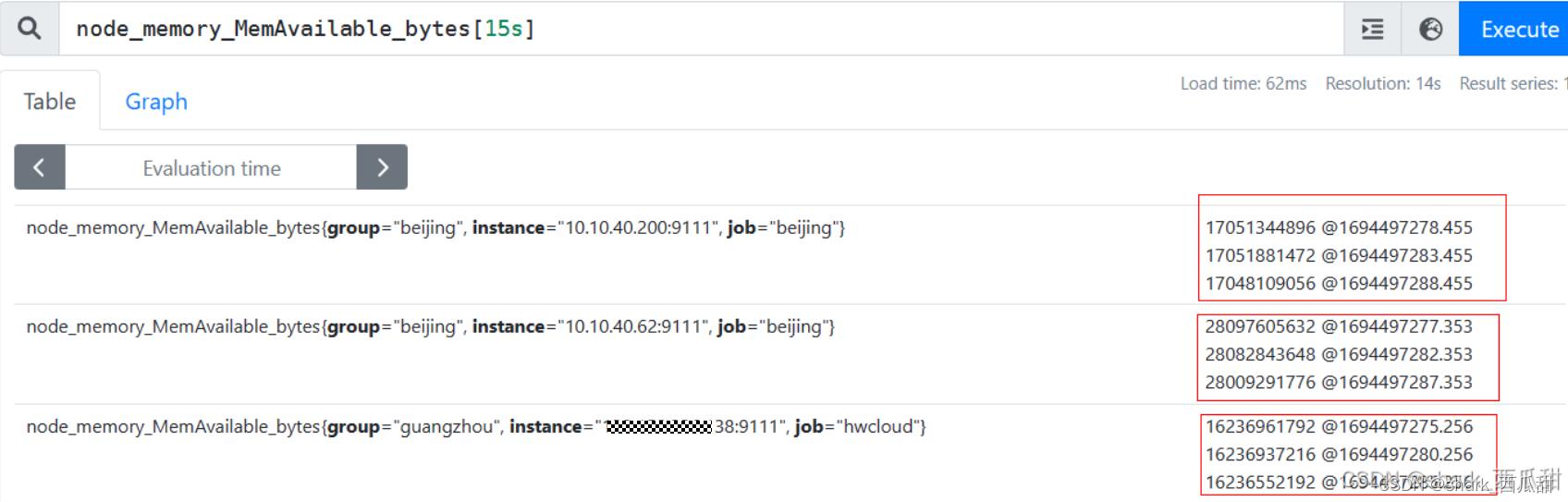
从上图可以看到,每个服务器都有 3 组数据,这是因为在 prometheus.yml 配置中的 scrape_interval 的值是 5s, 表示每 5 秒中 Prometheus会查询一次数据并保存到自己的数据库中。所以这里查询最近 15 秒的数据,就会返回 3 组数据。
17051344896 @1694497278.455 中 17051344896 是具体的数值,@1694497278.455 表示一个时间戳,这个时间戳就是从Unix 元年开始到现在的秒数。
- Scalar 标量 - 一个简单的数字浮点值;通常是通过查询表达式计算出来的结果。例如,内存使用率=内存可用容量 / 内存总容量=0.23
- String 字符串 - 一个简单的字符串值;当前未使用
三、常量
1 字符串
字符串可以指定为单引号、双引号或反引号中的字面。
PromQL遵循与Go相同的转义规则。在单引号或双引号中,反斜杠开始一个转义序列,后面可能有a、b、f、n、r、t、v或\。可以使用八进制(\nnn)或十六进制(\xnn、\unnnn和\Unnnnnnnn)提供特定字符。
在反引号中不会处理转义符号
"this is a string"
'these are unescaped: \n \\ \t'
`these are not unescaped: \n ' " \t`
2 浮点
标量(Scalar)浮点值可以写成该格式中的文字整数或浮点数(只包括空白以提高可读性)
[-+]?([0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?| 0[xX][0-9a-fA-F]+| [nN][aA][nN]| [iI][nN][fF]
)
示例:
23
-2.43
3.4e-9
0x8f
-Inf
NaN
四、时间序列选择器 Time series Selectors
1 即时矢量(Instant vector)选择器
Instant vector 选择器允许在给定的时间戳(即时)为每个时间序列选择一组时间戳和一个样本值:在最简单的形式中,只指定一个度量名称。这将产生一个Instant vector,其中包含具有此度量名称的所有时间序列的元素。
此示例选择具有 up 指标名称的所有时间序列:
up
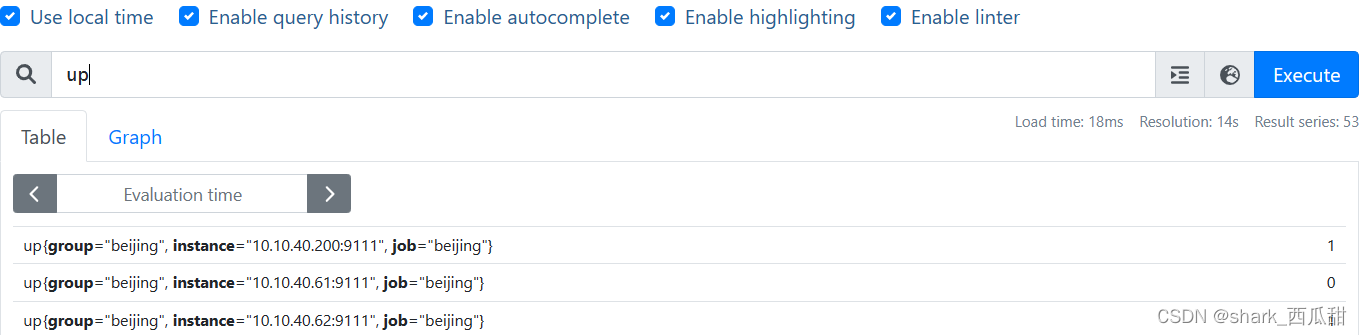
在一个简单的指标名称后面添加大括号({}),并在大括号中附件用逗号分隔的标签匹配器,可以实现对查询结果的过滤,这有点像是 SQL 中的 where 条件语句。
PromQL:
up{instance="10.10.40.200:9111"}
转化成 SQL:
select * from up where instance="10.10.40.200:9111"
此示例表示查询标签 instance 的值是 10.10.40.200:9111 的 up 指标数据
存在以下标签匹配运算符:
=选择与提供的字符串完全相等的标签。!=选择不等于提供的字符串的标签。=~选择与正则表达式匹配的标签。!~选择与正则表达式不匹配的标签。
注意:正则表达式匹配完全锚定。env=~"foo" 的匹配被视为 env=~"^foo$"
如下示例:返回标签 instance 的值以 10.10.40 开头,后面跟着 2 个任意组合的数字,以及标签 job的值以是 beijing 的。
up{instance=~"10.10.40.[0-9]{2}:9111", job="beijing"}
与空标签值匹配的标签匹配器还将包含所有没有设置此指定标签的时间序列。
同一标签名称可能有多个匹配器。
矢量选择器必须指定一个名称或至少含有一个非空字符串的标签匹配器。以下表达方式是非法的:
{job=~".*"} # 错误!
错误的原因: 这个可以匹配到一个空字符串(注意这里空字符串并不是空格)的标签,比如 {job=~""}, 这种情况下,它还没有指定一个具体的指标名称
相比之下,这些表达式是有效的,因为它们都至少有一个非空的标签的选择器。
{job=~".+"} # Good!, 这个正测表示一个以及一个以上的字符(包含空格,虽然实际上并没有任何意义))。
{job=~".*",method="get"} # Good!
以上两个表达式,虽然都没有指定一个具体的指标名称,但是他们都不会匹配到一个空标签。空标签就是 {job=""}
通过与内部__name__标签进行匹配,标签匹配器也可以应用于指标名称。例如,表达式http_requests_total 等效于{__name__="http_requists_toltal"}。也可以使用除=之外的匹配项(!=,=~,!~)。以下表达式选择名称以 job 开头的所有度量:
{__name__=~"job:.*"}
指标名称不得是关键字 bool、on、ignoring、group_left 和 group_right 之一。以下表达方式是非法的:
on{} # Bad!
此限制的变通办法是使用__name__标签:
{__name__="on"} # Good!
2 范围矢量选择器
范围矢量的工作原理与即时矢量一样,只是它们从当前实例中选择指定时间范围内的一系列样本。
从语法上讲,时间长度附加在方括号([])中,在矢量选择器的末尾,以指定每个结果范围向量元素应获取多远的时间值。
在本例中,我们选择过去5分钟内为所有时间序列记录的所有值,这些值的指标名称为 node_filesystem_avail_bytes ,且标签 mountpoing 是 / , 标签 fstype 是 ext 开头或者是 xfs的:
node_filesystem_avail_bytes{fstype=~"ext.*|xfs",mountpoint ="/"}[5m]
2.1 时间长度
时间长度指定为数字,紧接着是以下单位之一:
ms毫秒s秒m分钟h小时d天 - 假设一天总是24小时w周 - 假设一周总是7dy年 - 假设一年总是365d
时间长度可以通过串联来组合。单位必须从最长到最短给定。给定的单位在一段时间内只能出现一次。
以下是一些有效时间长度的示例:
5h
1h30m
5m
10s
2.2 偏移修饰符
不常用
offset修饰符允许更改查询中单个即时矢量和范围矢量的时间偏移量。
例如,以下表达式返回 5 分钟之前 node_memory_MemAvailable_bytes 即时矢量的值:
node_memory_MemAvailable_bytes offset 5m
请注意,offset修饰符总是需要立即跟随选择器,即以下内容是正确的:
sum(node_memory_MemAvailable_bytes offset 5m) // GOOD.
sum 是一个计算总和的函数,后续会介绍
显然以下情况不正确:
sum(node_memory_MemAvailable_bytes) offset 5m // INVALID.
范围向量也是如此。这返回了node_memory_MemAvailable_bytes 一周前的5分钟数据:
node_memory_MemAvailable_bytes[5m] offset 1w
2.3 @ 修饰符
不常用
@ 修饰符允许对单个即时和范围矢量的具体时间进行指定。提供给@修饰符的时间是unix时间戳,并用 Float 文字描述。
说白了就是可以指定某个时间点
例如,以下表达式在 2023-09-12 12:30 返回 node_memory_MemAvailable_bytes 的值:
node_memory_MemAvailable_bytes @1694493000
时间转换: date -d “2023-09-12 12:30” +%s
请注意,同样 @修饰符总是需要立即跟随选择器。
范围向量也是如此。
@ 修饰符支持上述在int64范围内的所有浮点文字表示。它也可以与 offset 修饰符一起使用,其中 offset 相对于@修饰符时间应用,无论先写入哪个修饰符,这2个查询将产生相同的结果。
指定时间 1694493000 的 5 m之前 的数据
# offset after @
node_memory_MemAvailable_bytes @1694493000 offset 5m
# offset before @
node_memory_MemAvailable_bytes offset 5m @1694493000
3 避免慢速查询和过载
如果查询需要对大量数据进行操作,则绘制查询可能会超时或使服务器或浏览器过载。
因此,在对未知数据构建查询时,请始终在普罗米修斯表达式浏览器的表格视图中开始构建查询,直到结果集看起来合理(最多是数百个,而不是数千个时间序列)。
只有在充分筛选或汇总数据后,才能切换到图形模式。如果表达式仍然需要很长时间来进行特别绘图,请通过记录规则 (recording rules ) 对其进行预记录。
这与普罗米修斯的查询语言尤其相关,在普罗米修斯中,像 api_http_requests_total 这样的裸度量名称选择器可以扩展到数千个具有不同标签的时间序列。还要记住,即使输出只是少量的时间序列,在许多时间序列上聚合的表达式也会在服务器上产生负载。这类似于对关系数据库中一列的所有值求和的速度很慢,即使输出值只有一个数字。
五、子查询
子查询允许您针对给定的范围和分辨率进行即时查询(instant query)。
子查询的结果是一个范围向量。
语法:<instant_query> '[' <range> ':' [<resolution>] ']' [ @ <float_literal> ] [ offset <duration> ]
<resolution>是可选的。默认值是全局评估间隔。
返回过去30分钟 promhttp_metric_handler_requests_total 指标的5分钟速率,分辨率为1分钟。
rate(promhttp_metric_handler_requests_total[5m])[30m:1m]
prometheus_http_requests_total[5m]) 返回了每5分钟
六、操作符 Operators
Prometheus支持许多二进制和聚合运算符。
1 二进制运算符
普罗米修斯的查询语言支持基本的逻辑和算术运算符。对于两个即时矢量之间的操作,可以修改主题匹配行为。
算术运算符
普罗米修斯中存在以下二进制算术运算符:
+加法-减法*乘法/除法%取模运算^幂运算
2 比较运算符:
==等于!=不等于>大于<小于>=大于等于<=小于等于
3 集合运算符
and 逻辑与
unless 排除某个
or 逻辑或
vector1 unless vector2
从 vector1 返回的结果中排除 vector2 返回的结果。
示例:
up{instance=~"10.10.40.*:9111"} unless up{instance="10.10.40.61:9111"}
从查询的结果集中排除 instance 的值为 10.10.40.61:9111 的数据
排除之前:

排除之后:

3 矢量匹配 Vector matching
矢量之间的运算试图在右侧矢量中为左侧的每个条目找到匹配元素。有两种基本类型的匹配行为:
- 一对一
- 多对一 或 一对多
3.1 矢量匹配关键字
这些矢量匹配关键字允许在具有不同标签集的系列之间进行匹配。
可以使用:
onignoring
提供给匹配关键字的标签列表将决定向量的组合方式。
具体用法见下面章节 3.3 一对一 矢量匹配 One-to-one vector matches
3.2 组修饰符
这些组修饰符可以实现 多对一/一对多 矢量匹配:
group_leftgroup_right
标签列表可以提供给组修饰符,其中包含要包含在结果度量中的“one”侧的标签。
多对一和一对多匹配是高级用例,应该仔细考虑。通常,正确使用 ignoring(<labels>) 可以提供所需的结果。
分组修饰符只能用于比较运算符和算术运算符。操作为 and, unless 和 or 操作默认情况下与右向量中的所有可能条目匹配。
具体用法见下面章节3.4 多对一 和 一对多 矢量匹配 Many-to-one and one-to-many vector matches
3.3 一对一 矢量匹配 One-to-one vector matches
一对一从操作的每一侧查找一对唯一的条目。
在默认情况下,这是一个遵循 vector1<operator>vector2格式的操作。
如果两个条目具有完全相同的标签集和相应的值,则它们匹配。
ignoring关键字允许在匹配时忽略某些标签,就是在匹配的时候不需要考虑的标签on关键字允许将所需要匹配的标签集限定在所提供的列表中,就是在匹配的时候仅限于on所指定的这些标签。
语法:
<vector expr> <bin-op> ignoring(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) <vector expr>
<vector expr>是 PromQL 查询表达式
<bin-op>就是二进制操作符
<label list>就是 标签列表
假设有如下数据
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
查询示例:
method_code:http_errors:rate5m{code="500"} / ignoring(code) method:http_requests:rate5m这将返回一个结果向量,其中包含在过去5分钟内测量到的每个 HTTP 请求方法的响应状态代码为500的HTTP请求占对应的HTTP请求方法的多少。
如果不忽略(code),就不会有匹配,因为度量不共享同一组标签。方法为put和del的条目不匹配,不会显示在结果中:
{method="get"} 0.04 // 24 / 600
{method="post"} 0.05 // 6 / 120
3.4 多对一 和 一对多 矢量匹配 Many-to-one and one-to-many vector matches
多对一和一对多匹配指的是“一”侧的每个表达式查询到的每条数据可以与“多”侧的多条数据匹配的情况。这必须使用group_left 或 group_right 修饰符来明确请求,其中 left/right 决定哪个矢量为多的一侧。
语法:
<vector expr> <bin-op> ignoring(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> ignoring(<label list>) group_right(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_left(<label list>) <vector expr>
<vector expr> <bin-op> on(<label list>) group_right(<label list>) <vector expr>
示例数据:
method_code:http_errors:rate5m{method="get", code="500"} 24
method_code:http_errors:rate5m{method="get", code="404"} 30
method_code:http_errors:rate5m{method="put", code="501"} 3
method_code:http_errors:rate5m{method="post", code="500"} 6
method_code:http_errors:rate5m{method="post", code="404"} 21method:http_requests:rate5m{method="get"} 600
method:http_requests:rate5m{method="del"} 34
method:http_requests:rate5m{method="post"} 120
查询目的:
当前希望查询 每个请求方法(get,post,put)的响应码(500,404,501)在每个请求方法总数中的占比。
例如, get 方法中响应码为 500 的数据占 get 请求总数的占比, 手工计算: 24 / 600
可使用查询示例:
method_code:http_errors:rate5m / ignoring(code) group_left method:http_requests:rate5m
在这种情况下,左侧表达式中每个 method 标签值包含了多个条目(比如 get 就有 2 条)。因此,我们使用 group_left 来表示这一点,可以认为是以左侧表达式进行分组。右侧表达式中的元素现在与左侧表达式具有相同 method 标签的多个元素匹配:
{method="get", code="500"} 0.04 // 24 / 600
{method="get", code="404"} 0.05 // 30 / 600
{method="post", code="500"} 0.05 // 6 / 120
{method="post", code="404"} 0.175 // 21 / 120
put 和 del 没有同时在两侧出现,所以无法匹配成功,结果中不包含 put 和 del 方法的条目。
4 聚合运算
Prometheus支持以下内置聚合运算符,这些运算符可用于聚合单个即时向量的数据,从而产生具有聚合值的更少数据的新矢量:
-
sum(计算总和) -
min(选择最小值) -
max(选择最大值) -
avg(计算平均值) -
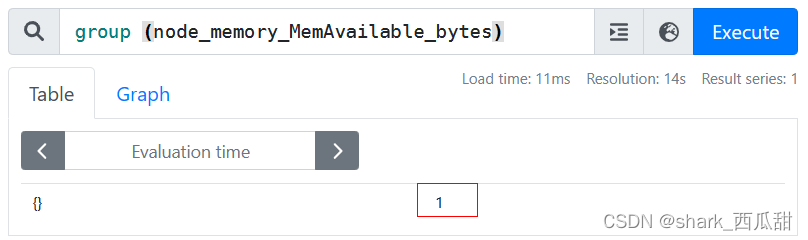
group(将结果集中的值都设置为 1)
-
stddev(计算维度上的总体标准偏差) -
stdvar(计算维度上的总体标准方差) -
count(计算向量中的元素数量,就是有多少条数据)
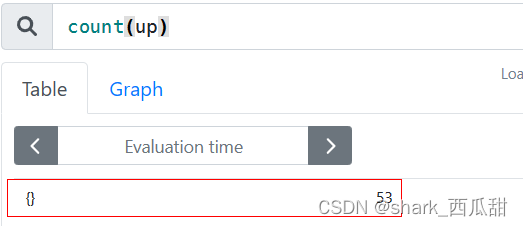
统计目前监控了多少台服务器count(up) -
count_values(计算具有相同值的元素数量,并需要传递一个字符串的参数,这个参数会作为一个新的 key 给返回值使用,这个有点像 SQL 语句中的group by)
分别统计当前在线和非在线服务器的数量,并且打上新的标签 countcount_values("server_st", up)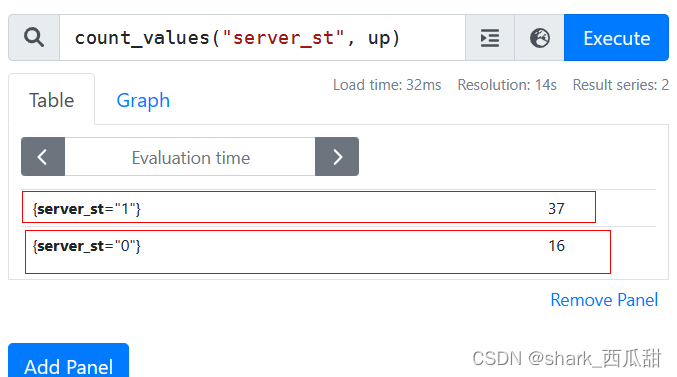
-
bottomk(按样本值划分的最小k元素,就是找到所有数据的值最小的前几个) -
topk(按样本值划分的最大的k种元素,就是找到所有数据的值最大的前几个)topk(5,node_memory_MemAvailable_bytes) -
quantile(计算φ-quantile(0 ≤ φ ≤ 1) 取当前数据的中位数,取值范围0-1quantile(0.5, http_request_total)
这些运算符可用于聚合所有标签维度,也可以通过包含一个 without 或 by 子句来保留不同的维度。
without 或 by 可以在表达式之前或之后使用, 放在之前和之后两者起到的做优。
语法:
<aggr-op> [without|by (<label list>)] ([parameter,] <vector expression>)
或
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
标签列表是未引用标签的列表,其可以包括尾随逗号,即 (label1, label2)和 (label1, label2,) 都是有效语法。
without 从聚合结果向量中删除列出的标签,而所有其他标签都保留在输出中。
by 执行相反的操作,并删除未在 by 子句中列出的标签,即使它们的标签值在所有表达式的所有数据之间相同。
parameter 参数仅对 count_values, quantile, topk and bottomk 是必须的。
示例1 从返回的数据中添加 group 标签
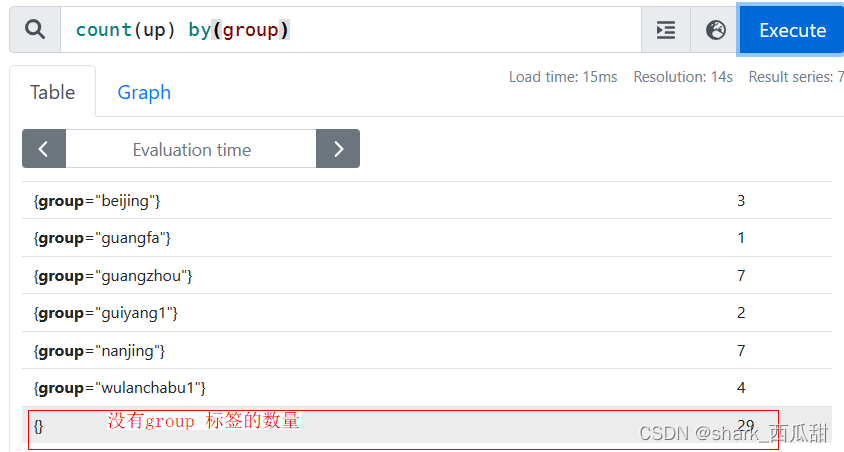
使用 by 之前,统计所有被监控的服务器总数:
使用 by 之后,以 group 标签的值进行分组统计:
七、函数
八、Comments
支持以 # 开头作为注释