目录
一、Spirng概括
1、什么是Spring
2、什么是容器
3、什么是IoC
4、模拟实现IoC
4.1、传统的对象创建开发
5、理解IoC容器
6、DI概括
二、创建Spring项目
1、创建spring项目
2、Bean对象
2.1、创建Bean对象
2.2、存储Bean对象(将Bean对象注册到容器中)
2.3、获取Bean对象
【1】使用ApplicationContext接口获取:
【2】使用BeanFactory获取Bean对象:
【3】(面试题)ApplicationContext 和 BeanFactory的区别
3、注解
3.1、五大类注解之间的关系
3.2、使用类注解简易地存储Bean对象
3.2.1、配置扫描路径(必备)
3.2.2、通过注解注册Bean对象及直接获取
3.3、五大类注解Bean对象的命名规则
3.4、使用方法注解@Bean
3.5、方法注解的Bean命名规则/Bean重命名
※特殊情况:方法注解@Bean不能修饰有参的方法
3.6、简易地获取Bean对象(对象装配/对象注入)
1)属性注入
2)Setter注入
3)构造方法注入
4)@Resource注解
3.7、多个同类型Bean对象的指定获取
三、Bean的作用域和生命周期
1、Bean作用域的理解
2、Bean的作用域
2.1、singleton作用域
2.2、prototype作用域
2.3、application作用域
2.4、request作用域
2.5、session作用域
2.6、websocket作用域
2.7、设置Bean对象作用域
3、Spring的执行流程
4、Bean的生命周期
一、Spirng概括
1、什么是Spring
🤔spring即spring Framework (spring框架),它作为一个开源的设计层面框架,解决的是业务逻辑层和其他各层的松耦合问题,因此它将面向接口的编程思想贯穿整个系统应用。
一句话概括,spring是包含了众多工具方法轻量级的 IoC容器(关键)和面向切面(AOP)的开源容器(框架)!
2、什么是容器
容器说到底,就是用于容纳存储数据的一个(基本)装置。
像前面学的javeSE中的list/Map/泛型,都是一个集合,而集合是用于存储数据的,也就是说集合是一个数据存储的容器。
以泛型为例,Listlist,这是一个只能存储和取出String类型数据的集合。
而Tomcat是Web容器.,存储Web项目和Servlet类的容器
3、什么是IoC
IoC(inversion of control)控制(权)反转,IoC是Spring中最核心的一个关键功能(词)。
控制反转,也就是把控制权交给其他方
例如:
本来程序是由一个A类来控制B类的生命周期,在A类中要想使用B类就得new一个B类出来;
但控制反转后,就能把B类的生命周期交给其他人【如spring】控制,此时使用B类就不用在
程序中实例化一个B类对象,而是直接交由spring控制创建即可。
4、模拟实现IoC
4.1、传统的对象创建开发
此处创建一个手机对象程序为例,创建一个逐级依赖的对象关系;
手机(Phone) 依赖于 芯片 (Chip) ,而芯片依赖于 电池 (Battery)
此处的程序,想要运行Phone,就得创建Chin,因为彼此是依赖关系,之后初始化Chin,而Chin依赖于Battery,就得在Chin类中创建一个Battery类,从而才能调用使用Battery类。
①手机类(Phone)
public class Phone {private Chin chin;public Phone() {chin = new Chin();}public void run() {System.out.println("Phone-init");chin.init();}public static void main(String []args){Phone phone = new Phone();phone.run();}
}
②芯片类(Chip)
public class Chin {private Battery battery;public Chin() {this.battery = new Battery();}public void init(){System.out.println("Chin-init");battery.init();}
}③电池类(Battery)
public class Battery {//默认电池的容量private int capacity = 100;public void init(){System.out.println("Battery-init; capacity:"+this.capacity);}
}对于上述传统的程序来说,彼此类逐级依赖导致耦合度过高,如果后续对该Phone类中的某个部件进行调整修改,就会导致整个调用链上的类都要更改。
比如此处要修改Battery类中的capacity容量,但是如果要从Phone类中直接传递参数,逐级传参到Battery类,就很麻烦。
代码如下:
①Phone类:
public class Phone {private Chin chin;public Phone(int capacity) {chin = new Chin(capacity);}public void run() {System.out.println("Phone-init");chin.init();}public static void main(String []args){Phone phone = new Phone(200);phone.run();}
}②Chin类
public class Chin {private Battery battery;public Chin(int capacity) {this.battery = new Battery(capacity);}public void init(){System.out.println("Chin-init");battery.init();}
}③Battery类
public class Battery {private int capacity = 100;public Battery(int capacity) {this.capacity = capacity;}public void init(){System.out.println("Battery-init; capacity:"+this.capacity);}
}上述的代码存在最致命的问题,就是底层代码增加或修改需求时,整个调用链上的所有代码都得发生改变。
而导致这种问题的原因,是我们在每一个类的构造方法中处理下一层类的依赖关系,都是自己手动new创建一个实例对象,是主动创建的。
由自己创建的下级类,当下级类发生修改时,此处的创建实例操作也得进行修改。
要解决这个问题,就可以采用控制(权)反转,使用注入的方式,将所需要的参数由本来的从上往下传递创建实例,转为从下往上传递;
原自己创建类,当下级类发生改变时,当前的类也要进行修改;改为注入的方式后,下级类发生改变,当前类就不需要再进行代码修改了。
这就能完成代码的解耦(降低耦合性,耦合性也可以换⼀种叫法叫程序相关性。好的程序代码的耦合性(代码之间的相关性)是很低的,也就是代码之间要实现解耦。)
此处也可以理解成,当客户要求产品进行参数修改时,不再又我们自己调整,而是外包出去交由第三方处理,因此我们就无需出力,照样按原来的流程进行传递即可。
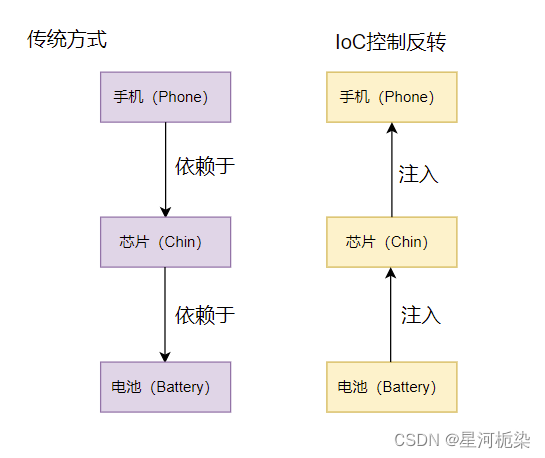
控制权反转后的代码:
①NewPhone类:
public class NewPhone {private NewChin newChin;public NewPhone(NewChin newChin) {this.newChin = newChin;}public void run(){System.out.println("NewPhone_init");newChin.init();}
}②NewChin类:
public class NewChin {private NewBattery newBattery;public NewChin(NewBattery newBattery) {this.newBattery = newBattery;}public void init(){System.out.println("NewChin_init");newBattery.init();}
}③NewBattery类:
public class NewBattery {private int capacity = 100;public NewBattery(int capacity) {this.capacity =capacity;}public void init(){System.out.println("NewBattery_init;capacity:"+capacity);}
}④启动类:
由原来自己手动在类中创建下级类,转为注入方式(控制权反转),把控制权转交其他类(此处以App类为例)处理,再由该类调用传参。
此处可以很明显地观察到反转的特性,由原来创建Phone类依次依赖往下控制创建Battery类,【反转】转为 根据参数()创建NewBattery类,再往后依次注入到上级对象。
通⽤程序的实现代码,类的创建顺序是反的,传统代码是 Phone 控制并创建了Chin,Chin 创建并创建了 Battery,依次往下,⽽改进之后的控制权发⽣的反转,不再是上级对象创建并控制下级对象了,⽽是下级对象把注⼊将当前对象中,下级的控制权不再由上级类控制了,这样即使下级类发⽣任何改变,当前类都是不受影响的,这就是典型的控制反转,也就是 IoC 的实现思想。
public class App {public static void main(String[] args) {int capacity = 200;NewBattery battery = new NewBattery(capacity);NewChin newChin = new NewChin(battery);NewPhone newPhone = new NewPhone(newChin);newPhone.run();}
}5、理解IoC容器
✔Spring是集合众多工具方法的开源Ioc容器,而IoC容器(又为:控制反转容器)。
容器,顾名思义就是用于存储数据和获取数据的一个东西。而作为Spring最核心的东西---IoC容器。
那么Spring最核心也是最基础的功能,就是如何将对象存储到Spring;且怎么从Spring中取出对象的过程。
将对象存储到Spring容器中,当要使用的时候,就从容器中获取即可,Spring使用的是“懒汉模式”,使用这种模式可以提高开发效率,也可以减少
每次创建销毁对象带来带来的内存开销,不然每次使用一个对象就new一个太过于浪费空间。
【懒汉模式会在第一次使用时才创建对象,而在之前则不会创建,从而避免了在系统启动或者初始化时就创建对象的过程。这种方式被称为“懒汉”,
是因为它在初始化阶段并不匆忙,而是等待真正需要时才会采取行动。】
优点:实现代码的解耦、节省系统的资源,提高了程序运行的效率
6、DI概括
DI(Dependency Injection)依赖注入,跟创建Servlet项目中引入依赖类似,要使用什么样的功能就从Maven中央仓库获取jar包引入进去。
DI和IoC其实是在不同维度上的同一实现方法,只是角度不同。所谓依赖注⼊,就是由 IoC 容器在运⾏期间,
动态地将某种依赖关系注⼊到对象之中。所以,依赖注⼊(DI)和控制反转(IoC)是从不同的度的描述的同⼀件事情,就是指通过引⼊IoC 容器,利⽤依赖关系注⼊的⽅式,实现对象之间的解耦。
说到底,IoC是一种思想(IoC 是“⽬标”也是⼀种思想,⽽⽬标和思想只是⼀种指导原则,最终还是要有可⾏的落地⽅案),而DI是实现该思想的具体方法。要想实现IoC控制反转,有很多的方法而DI只是其中一种。
二、创建Spring项目
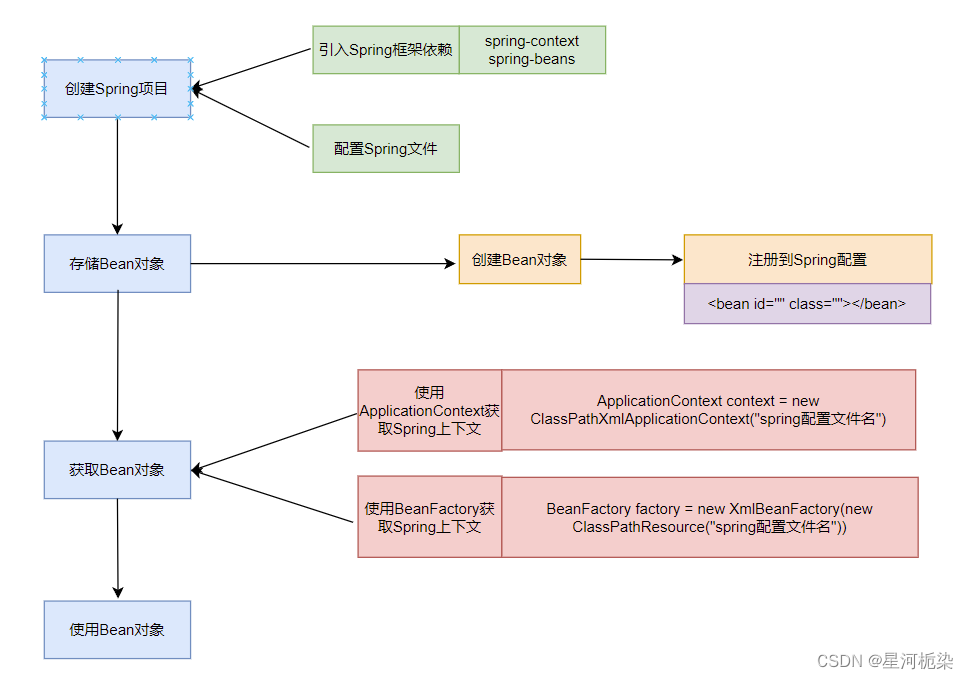
1、创建spring项目
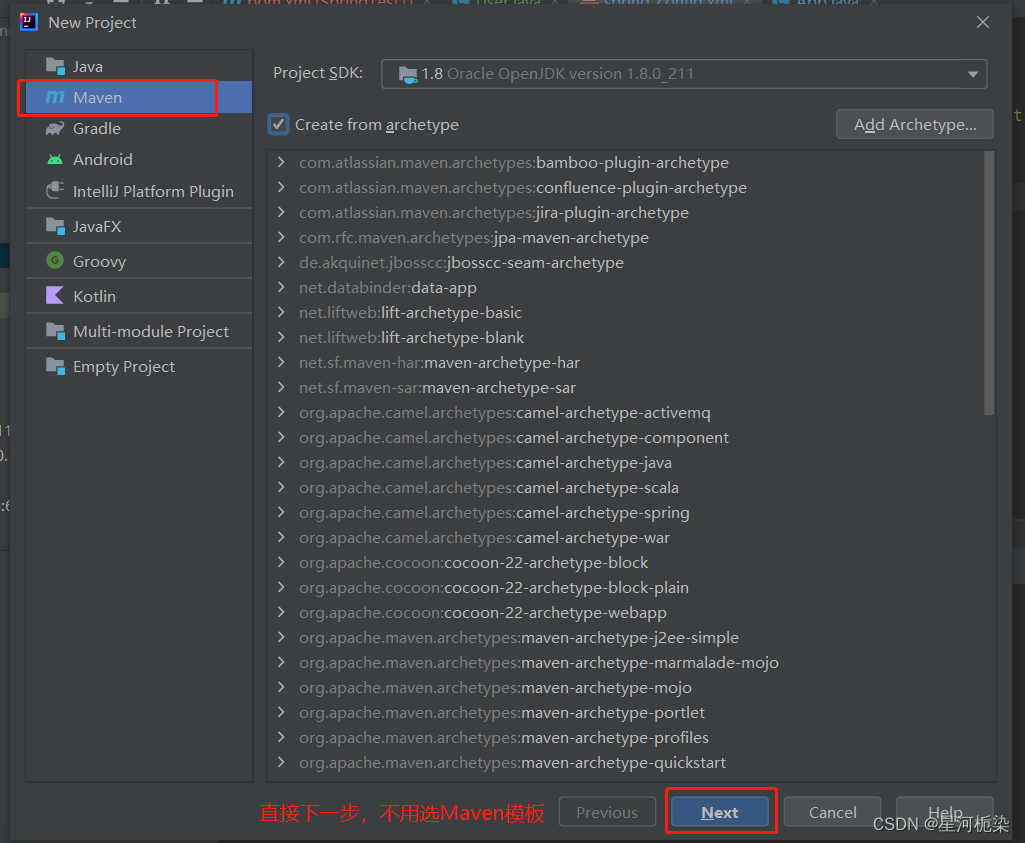
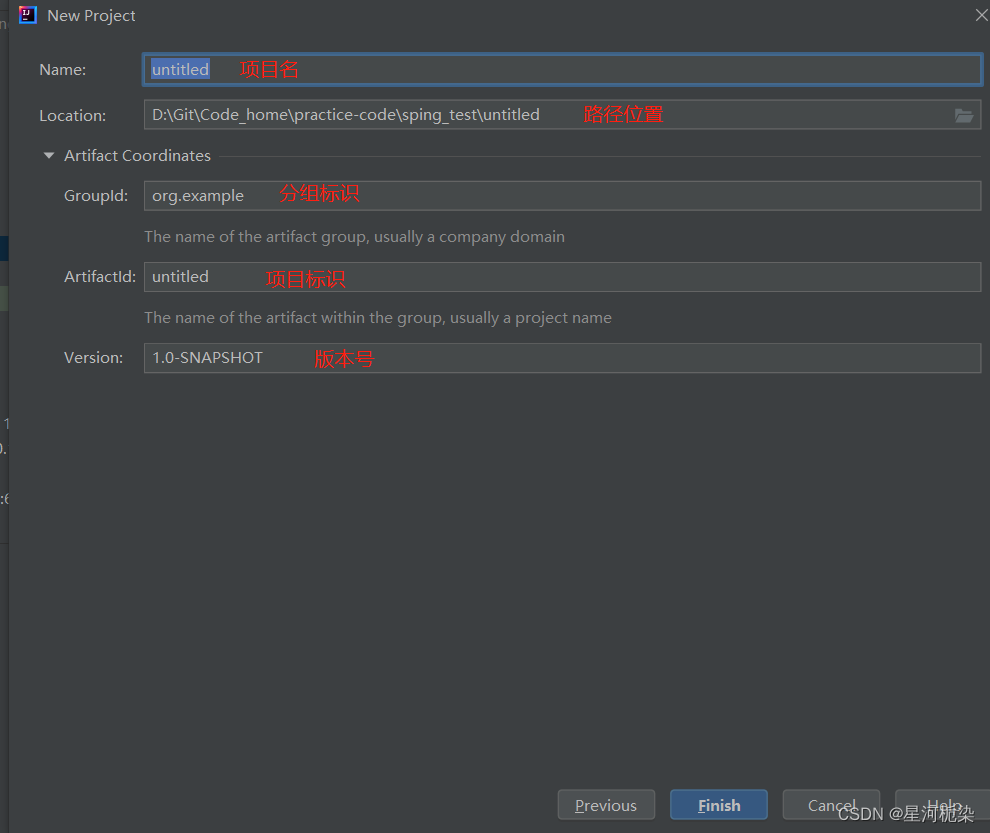
①创建Maven项目 【注意】:项目的存储路径不能有中文
②添加Spring的框架依赖
添加完Spring的依赖后,可以理解为该maven项目变为Spring Core项目
在项⽬的 pom.xml 中添加 Spring 框架的⽀持(需要spring context【spring上下文,也就是表示spring】及spring beans(管理对象的模块),可以从Maven中央仓库获取),xml 配置如下:
下述jar包版本号中的Release表示的是当前版本是稳定的,当前更新停止,可以用于发行的版本;如果是snapshot 版本则代表不稳定、尚处于开发中的版本,即快照版本
<dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.3.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-beans</artifactId><version>5.2.3.RELEASE</version></dependency>
</dependencies> 引入spring框架依赖后,左侧可以看到一些列jar包,除了jdk1.8、spring-beans和spring-context外其他是配套出现的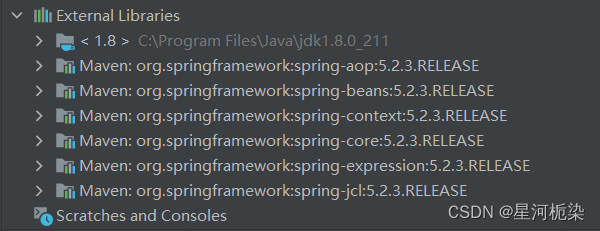
③添加一个启动类
最后在创建好的项⽬ java ⽂件夹下创建⼀个启动类,包含 main ⽅法(实现方法细节后续再补充)即可:
public class App {//创建启动类public static void main(String[] args) {}
}2、Bean对象
2.1、创建Bean对象
创建一个Bean对象,跟普通java程序中创建的对象一样,此处随便创建一个对象即可,要想增添方法、属性也可以.
public class User {//创建一个Bean对象public void functino(){System.out.println("Start!");}
}2.2、存储Bean对象(将Bean对象注册到容器中)
此处的创建Bean对象存入Spring中,此处的存储并不是真正执行存储的动作,而是告诉spring此时要把某些类存储/托管给spring。
(只是告诉spring要存储对象,什么时候存储是与我们没关系,我们只是使用方,要使用该对象的时候,再到spring取就行,不关注什么时候存,只在乎能不能拿到)
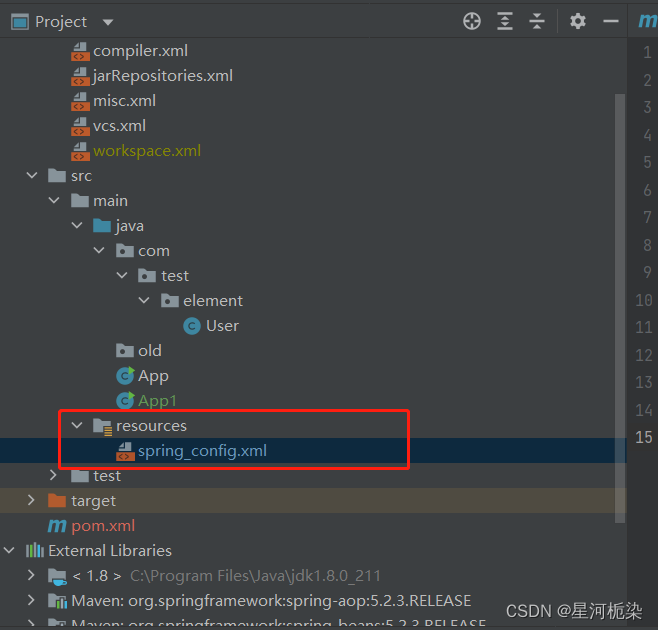
✔通过xml配置文件,告诉spring要存储的Bean对象
【注意】:在创建好的项目中添加配置文件,需要将其放到resources根目录下,新建一个自定义命名(非中文)的.xml文件,再将下述配置代码写入即可
此处的Bean对象(User类)是存放在包里的,因此在配置Bean时,bean的class类名也必须要包含包名(即完整路径名)
下述的Spring 配置⽂件的固定格式(此处只是声明要把对象存储到Spring当中)为以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"><bean id="user_bean" class="com.test.element.User"></bean>
</beans>2.3、获取Bean对象
根据前面在spring配置文件中注册进Bean对象后,要想获取该对象,就得先拿到Spring对象,才可以拿到里面存放的Bean对象。
【1】使用ApplicationContext接口获取:
ApplicationContext是Spring中的一个接口,通过该接口可以获取到Spring的上下文(得到 Spring 的上下⽂对象,创建的时候需要配置 Spring 配置信息).
它作为一个接口需要实现创建一个ClassPathXmlApplicationContext,通过传入spring配置文件的命名去调用其构造方法创建出来。
ApplicationContext context = new ClassPathXmlApplicationContext("配置文件名");之后通过调用该Spring上下文对象中的getBean()即可获取Bean对象。
而该getBean方法还有三种不同的参数的传递:
- getBean(String) --- 传入在spring配置文件中注册入的Bean对象id,该方法的返回类型是Object类,需要进行强转
public class App1 {public static void main(String[] args) {//1.ApplicationContext context = new ClassPathXmlApplicationContext("spring_config.xml");User user = (User)context.getBean("user_bean");user.function();}
}
- getBean(Class) --- 传入Bean对象的类型映射,由于已经传入了Bean对象的类型,自然无需像上一个进行类型强转
- getBean(String,Class) --- 同时传入Bean对象的id和类型
①此处对于getBean(String)和getBean(Class) 还是有区别的,当返回的Bean对象是null时,第一个方法依然会对null进行类型强转,而第二个方法无需强转。
②当Spring当中出现两个类型一样,id不一样的Bean对象时,如果使用的是getBean(Class) 方法获取,就会出现报错。通过此处的报错NoUniqueBeanDefinitionException,可以知道没有唯一的一个Bean对象,此处相同类型的Bean对象有两个,无法同时获取两个Bean对象,从而报错。【正确做法:就是使用id去获取,或者结合id和类型获取】
spring中的xml配置文件:
//错误的获取Bean方法 public class App1 {public static void main(String[] args) {//1.ApplicationContext context = new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean(User.class);User user1 = context.getBean(User.class);user.function();user1.function();} }

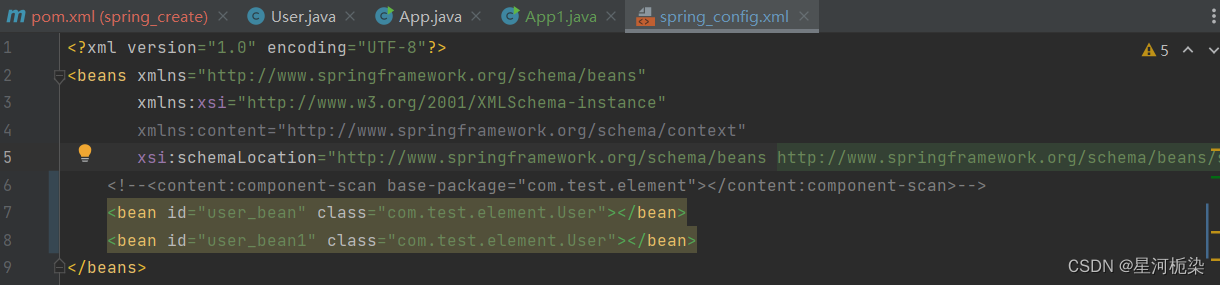
③spring配置文件中对于Bean对象的注册,其id标识不能重复使用,不然在根据id标识获取Bean对象,无法准确得知要获取具体哪一个Bean对象。此处的报错内容,明显的可以知道,命名为user_bean的id标识已经被使用过了!(正确做法:指定不重复的id)
//错误代码 public class App1 {public static void main(String[] args) {ApplicationContext context = new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean(User.class);user.function();} }
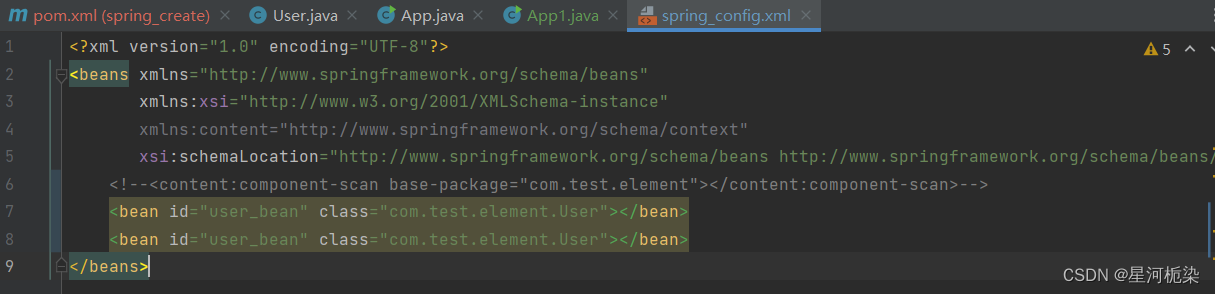

【2】使用BeanFactory获取Bean对象:
public class App1 {public static void main(String[] args) {BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("spring_config.xml"));User user = beanFactory.getBean(User.class);user.function();}
}【3】(面试题)ApplicationContext 和 BeanFactory的区别
ApplicationContext和BeanFactory效果其实是一样的,都是可以获取到Bean对象。
两者的区别在于:
- ApplicationContext是在初始化的时候就一次性加载获取spring中所有的Bean对象,而BeanFactory是要获取的时候才获取(懒汉),执行速度比较快 (相对轻量)但是ApplicationContext一次性获取后就一劳永逸,后续再想获取其他Bean对象,效率都会很高。
- ApplicationContext接口是BeanFactory接口的子类,java中的继承关系可知,子类继承父类会具有父类所有的属性和方法,而ApplicationContext作为子类,又有自己独特的方法和属性,所以相比于父类BeanFactory功能更多,其还添加了对国际化⽀持、资源访问⽀持、以及事件传播等⽅⾯的⽀持。
3、注解
🎈注解说到底就是一种功能声明.
通过多层类注解,可以让后续对代码的管理和维护更方便 ,使其他人更能直观地了解当前类的用途
Spring中的注解可以分为:1)类注解;2)方法注解
①类注解又可以分为:
- @Controller(控制器存储);实现前后端交互的时候,前端分发请求到后端的第一层入口【用途:验证前端传递的参数(安全检查)】
- @Service(服务层);经过安全检查才可以享受服务【此处为服务调用的编排和汇总】(编排:服务之间的优先级编排,哪个先完成;汇总:请求发送到后端后,服务层会实现两个接口的调用,服务当中会把后端需要更新的两张表的所有接口都在这个方法实现,这就是汇总)
- @Repository(仓库存储---数据仓库、数据持久层);直接操作数据库
- @Component(组件存储);通用化的工具类
- @Configuration(配置存储);存放项目中所有的配置;比如:拦截器、过滤器;
@Controller、@Service、@Repository是要满足用户请求的;
而@Component组件是通用化的工具类,例如定义了一个密码类(用于加密和解密功能的),该类就不用前面三大类注解,因为其是和业务没有关系的,而是使用Component组件注解
②方法注解:@Bean(也可以通过方法注解,将当前方法返回的Bean对象存储到Spring中)
3.1、五大类注解之间的关系
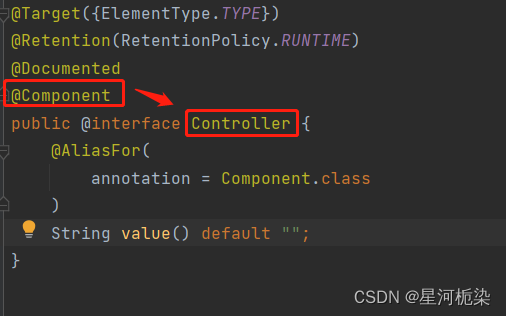
1)@Controller
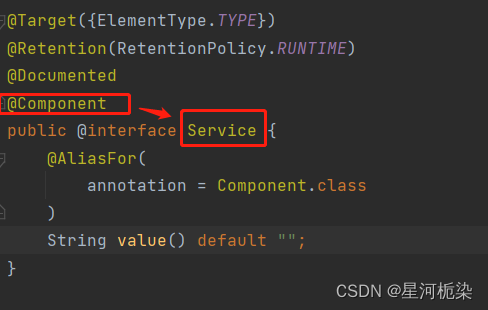
2)@Service
3)@Repository
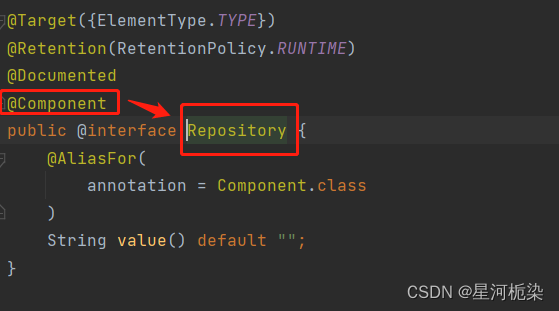
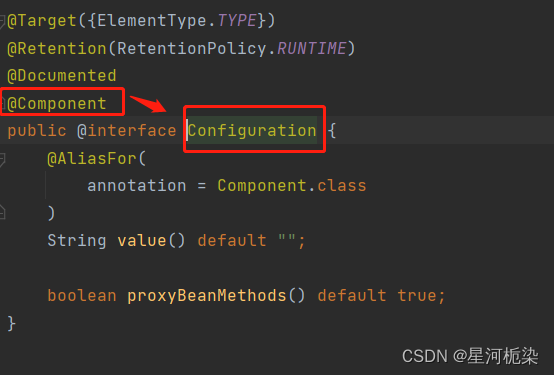
4)@Configuration
5)Component
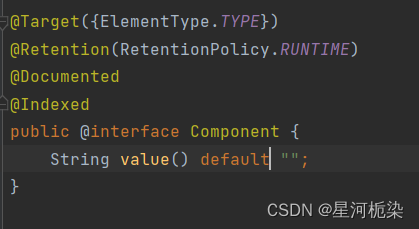
通过观察上述的五大类注解源码,可以清楚地知道@Controller、@Repository、@Configuration、@Service四大注解都是依靠@Component注解实现的,说到底这四个注解是针对组件注解的扩充和扩展。
3.2、使用类注解简易地存储Bean对象
3.2.1、配置扫描路径(必备)
为了不让spring一次性进行全盘扫描(耗时间、耗资源),可以在spring配置文件中配置存储一下存储对象的扫描路径即可。
那么spring就只会在这个包名下扫描,哪些类是有被注解修饰的,才可以判断知道哪些是存放到spring中的Bean对象
下述配置了com.test.element这个包:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:content="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"><content:component-scan base-package="com.test.element"></content:component-scan>
</beans>【注意】:如果不设置扫描路径,其不会扫描任何类。
3.2.2、通过注解注册Bean对象及直接获取
在想要注册进spirng的类前添加类注解即可
@Controller
public class User {public void function(){System.out.println("测试!");}
}public class App {public static void main(String[] args) {//从spring容器中获取Bean对象//1. 通过ApplicationContext来获取Spring上下文//==============================================//通过注解来将Bean对象注册到Spring中,不像原方法直接手动在配置文件中注册,没有指定Bean对象的Id标识//因此在获取Bean对象时,就不清楚要根据什么去获取。而注解默认提供了Bean对象的Id标识为类型小驼峰,如此处的“user”// 根据id和类名去找到对应根路径下的包名,扫描是否有被注解修饰的类给注册到Spring中,从而去获取对应的Bean对象ApplicationContext context = new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean("user",User.class);user.function();//2.通过BeanFactory来获取Spring上下文BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("spring_config.xml"));User user1 = (User)beanFactory.getBean("user");user1.function();}
}3.3、五大类注解Bean对象的命名规则
默认情况下,五大类注解的Bean名称是按类名首字母小写的规则来获取的。
创建一个Bean对象时,其类名为大驼峰形式,当要想获取Bean对象时,传递的id参数字符串是其类名的首字母小写形式。如:User -> user
@Controller
public class User {public void function(){System.out.println("测试!");}
}public class App {public static void main(String[] args) {ApplicationContext context = new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean("user",User.class);user.function();}
}🤔特殊情况:当创建的对象类名为前两个字母大写,而不是大驼峰形式,如:IException;
还是通过传入首字母小写的id标识去spring中获取Bean对象,是找不到的
下述演示的注册IException对象,就没办法通过首字母小写形式获取。
@Controller
public class IException {public void function(){System.out.println("成功!");}
}public class App2 {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");IException iException = context.getBean("iException",IException.class);iException.function();}
}
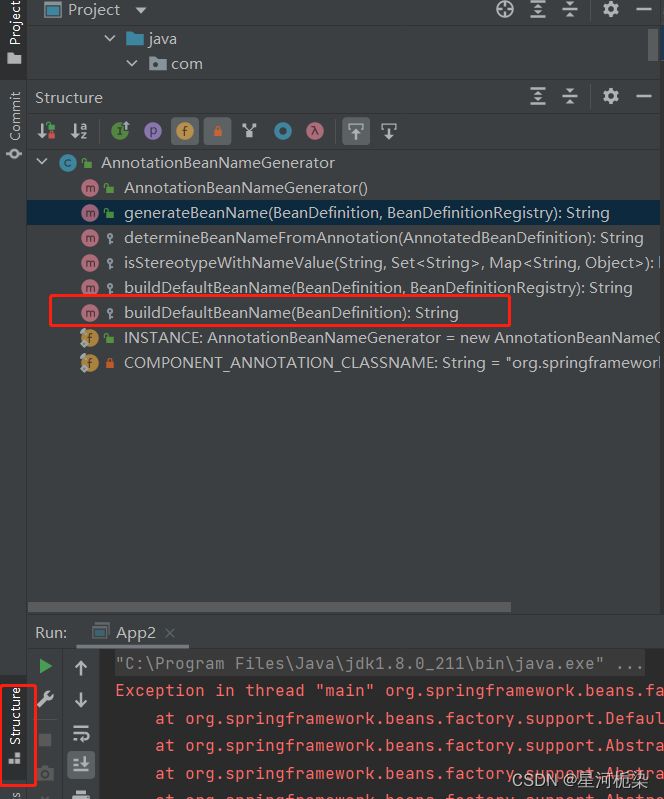
1)要想查清为什么spring根据该命名无法找到Bean对象,就只能进到spring的源代码中了解Spring关于Bean存储时的命名规则。
在IDEA中连续按两次Shift键,进入查询界面,因为要想知道Spring的命名规则,可以根据BeanName这一关键词去搜索。
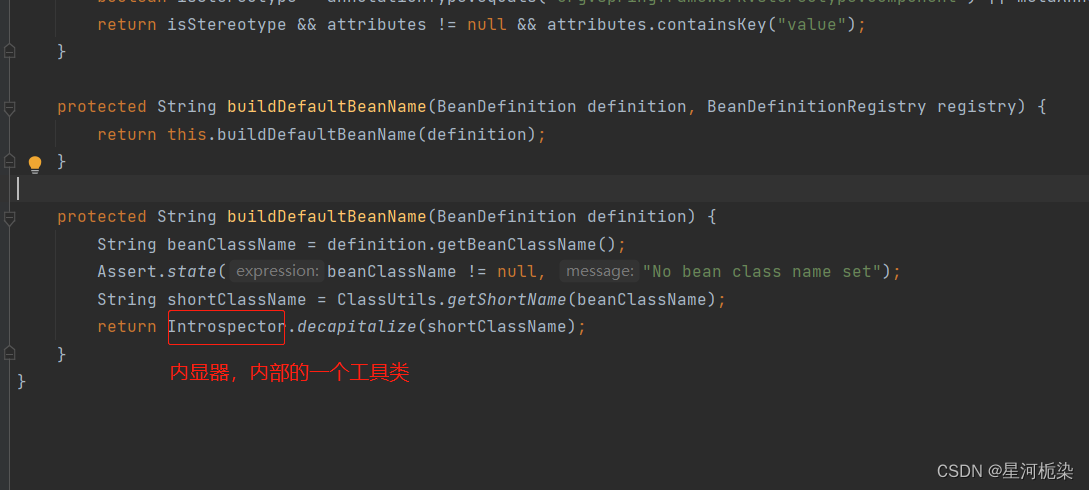
2)通过观察该类中的方法名,找到这个符合我们需求的一个方法bulidDefaultBeanName(创建默认Bean命名)
3)在该方法中,最关键的就是最后的这个调用了jdk中Introspector类的decapitalize(),【因此此处是spring调用jdk里面的命名规则】
该方法翻译过来是小写化的意思。此处将一个字符串(即Bena对象名字符串)传进去
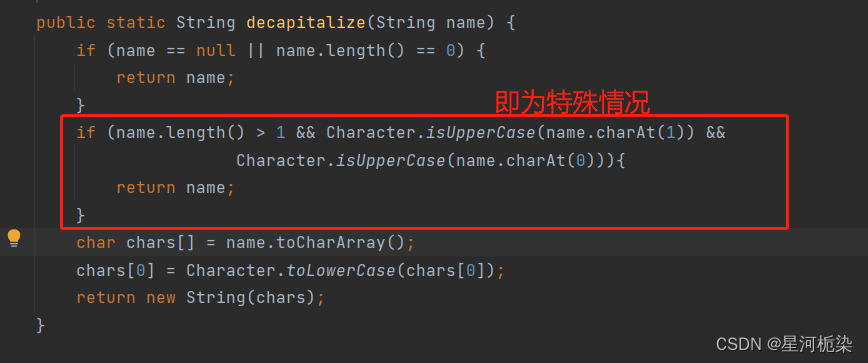
4)在该方法中,最关键就是第二个if语句,当Bean对象命名中的一个字母 和第二个字母都是大写时,直接返回原命名字符串,这就是为什么在getBean()从Spring中找Bean对象时,根据其原命名规则首字母小写找不到对象。因为我们存入的Bean对象命名是前两个字母大写,在Spring中获取时,是以其原Bean对象命名去查询获取的。
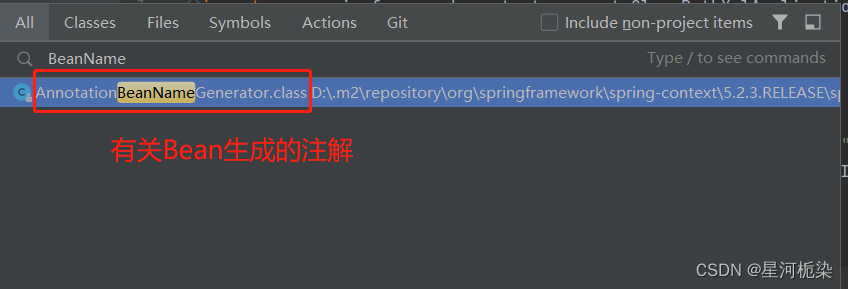
【总结】注解Bean的名称,要么是首字母小写,要么是原类名
因此正确的做法就是在getBean()时,如果是前两个字母为大写,就直接传入原对象类名即可.
//正确做法
@Controller
class IException {public void function(){System.out.println("成功!");}
}public class App2 {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");IException iException = context.getBean("IException",IException.class);iException.function();}
}3.4、使用方法注解@Bean
前面学习的类注解是只能应用到类上,而此处的方法注解只能用到方法上。可以通过方法注解修饰的方法,返回其类对象,将该对象存储到Spring中。
用法:在想要返回注册的Bean对象方法前面加上@Bean注解
但有最关键的一点,很容易出错,错误代码如下:
public class Test {@Beanpublic User user(){//此处不是说在spring中还是用new创建对象的意思,而是一种构建数据的方法User user = new User();return user;}
}public class App2 {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean("user",User.class);user.function();}
}
从报错信息上看,可以看出并没有找到名为user的Bean对象。
这是因为方法注解必须要配合类注解来使用,此处的场景跟原获取Bean对象时,Spring配置文件当中设置扫描路径差不多。
如果没有配合类注解的话,就会对程序中所有的类进行扫描,看哪些类中出现被@Bean方法注解修饰的方法,再去获取其对应返回的Bean对象,效率太低。配合了类注解,就会直接从加上类注解的类中去查找方法注解修饰的方法,不会扫描到其他普通的方法,大大提高了运行的效率。
3.5、方法注解的Bean命名规则/Bean重命名
🤔对于方法注解默认通过方法名去找Bean对象的规则,其实有一个很大的弊端。
因为可能出现不同包或同一包底下的类中出现具有相同方法名,且返回同一类型对象的方法。这两个方法同时被@Bean注解修饰,就意味着在从spring中获取Bean对象,不知道是获取哪一个。
但实际上次由@Bean注解,将方法的返回值对象注册到Spring中的方法,如果出现一样方法名时,第二个注册进spring的对象会覆盖前一个注册进去的对象,这就会导致当我们想获取的Bean对象是第一个被覆盖的时候,就无法获取到。
这种场景类似于 Map,存入的key值有且只有一个(相当于方法名),往后继续存入同一key值,就会覆盖上一个存入的key,而value值就可以是重复的。
1)User类
public class User {private int id;private String name;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}
}2)UserService类:
@Controller
public class UserService {@Beanpublic User user(){User user = new User();user.setName("测试一");return user;}
}3)UserRepository类
@Controller
public class UserRepository {@Beanpublic User user(){User user = new User();user.setName("测试二");return user;}
}4)启动类
public class App {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean("user",User.class);System.out.println(user.getName());}
}此处调用的结果是 “测试一”而不是“测试二”,这里就验证了同方法名覆盖导致无法获取理想Bean对象的问题。
为了解决这种问题,spring中有一规则,可以针对Bean对象进行重命名,使其可以针对特定命名的Bean对象进行存储或获取的处理。
重命名的方法有三种:
- 在@Bean注解后添加以name作为key值的参数修改。@Bean(name=" ")
- 直接在Bean注解后添加重命名的字符串 @Bean(" ")
- 也可以使用花括号形式【@Bean(name={"test1","test2"})】,进行多组命名,让一个Bean对象同时具有多个名字。【name也可以省略,如@Bean({"test1","test2"})】
当给这几个被@Bean注解修饰的方法进行重命名后,就可以通过指定新命名去获取Bean对象了。
比如:
@Controller
public class UserRepository {@Bean(name = "user2")//也可以是@Bean("user2")public User user(){User user = new User();user.setName("测试二");return user;}
}public class App {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean("user2",User.class);System.out.println(user.getName());}
}
//调用输出的结果就为:测试二【注意】使用@Bean注解重命名后,就无法再用原首字母小写的命名规则获取或存储Bean对象了 ;(以上述为例,已经重命名了@Bean("user2"),但还是使用方法名去spring找Bean对象,就会找不到)
public class App {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");User user = context.getBean("user",User.class);System.out.println(user.getName());}
}
※特殊情况:方法注解@Bean不能修饰有参的方法
在同一类中,出现多个方法重载(返回类型一样,参数列表不同)的场景中,如果要同时将这些方法返回的类对象注册到Spring中是无法做到的。
@Bean方法注解只能修饰在无参的方法上,如果是有参的方法,Spring初始化存储时并不能给该方法提供一个参数,因此就会出现该方法无法实现返回Bean对象给注册到Spring中。
3.6、简易地获取Bean对象(对象装配/对象注入)
Spring中获取Bean对象的方法称为:“对象装配”,也可以叫做“对象注入”,即把对象从spring中取出来放到某个类属性中。
对象注入一共可以分为三种方法:
- 属性注入;
- Setter注入;
- 构造方法注入;
1)属性注入
属性注入,直接在类中的成员变量前使用@AutoWired (自动装配)即可。
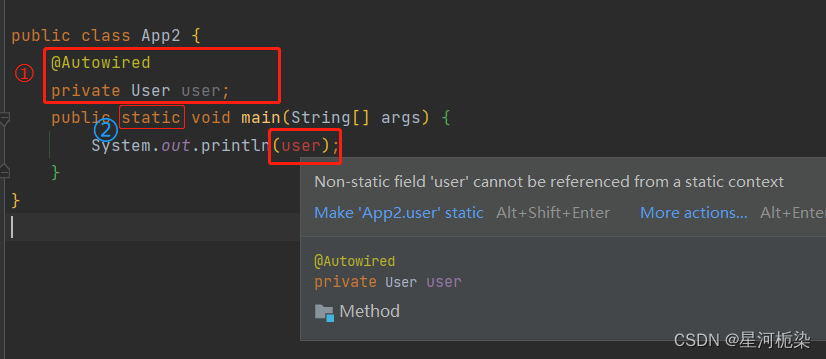
【注意】:不能直接(在main方法中)使用属性注入后的变量,,这是由于spring的加载比较靠后 ,对于静态方法来说,它是JVM启动的时候就加载可以使用的。
(static方法执行的时间非常早,比此处的属性注入还早,这就导致main执行后,属性注入还没有拿到spring中的Bean对象。此处主要是SpringCore项目才会出现这样的问题,后续的Spring boot、SpringMVC项目就不会担心出现这种情况,因为不需要main方法就可以直接启动spring,main方法已经内置在spring容器里(依靠内置容器启动),所以就可以随心所欲的进行对象注入)
 正确的做法(此处是将User对象注入到UserService,之后在启动类中获取UserService对象,就可以调用该类中的getUser()方法输出user,因为UserService中已经通过属性注入获取spring中的user对象):
正确的做法(此处是将User对象注入到UserService,之后在启动类中获取UserService对象,就可以调用该类中的getUser()方法输出user,因为UserService中已经通过属性注入获取spring中的user对象):
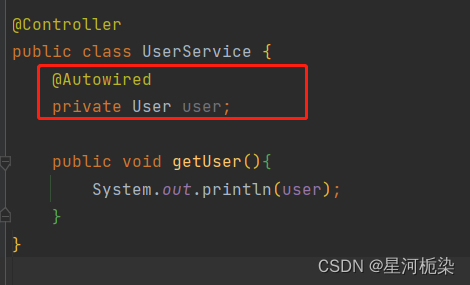
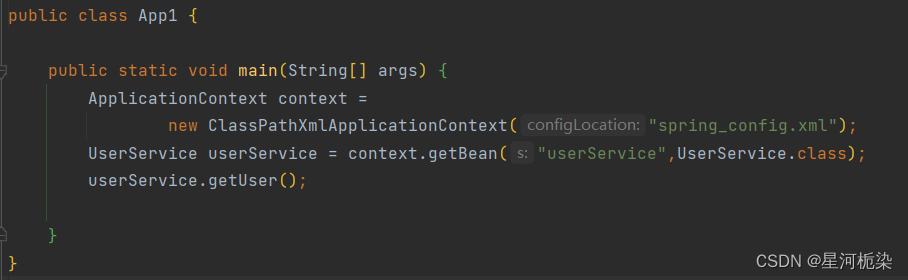
✔属性注入的缺点:
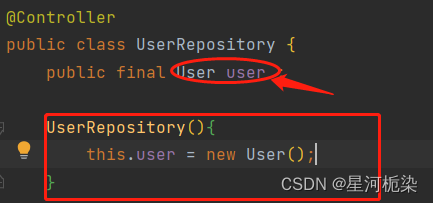
1)功能缺陷:不能注入final修饰的属性(final修饰的变量,一定得满足以下任一否则编译出错,这是java中对final这个关键字的限制 )
对于final修饰的使用:
①使用时得赋值不然报错;
②如果不在使用时就赋值,就得在构造方法中赋值)
2)通用性问题: 只适用于IoC容器(框架),如果移植到其他框架就无法使用
3)单一设计原则:属性注入过于简单地使用,会导致滥用,从而更容易地违背单一设计原则(比如,一个类设计出来就是单一职责,不能既干那又干那)
✔属性注入的优点:
1)属性注入优点也就是操作简单,只需在成员变量前加上注解,即可完成对象注入,并使用获取到的Bean对象
2)Setter注入
对于set方法,加上@Autowired注解后,spring会自动调用set方法,从spring中获取Bean对象,并注入到成员变量里去。
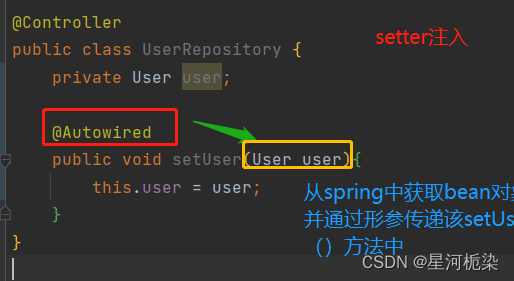
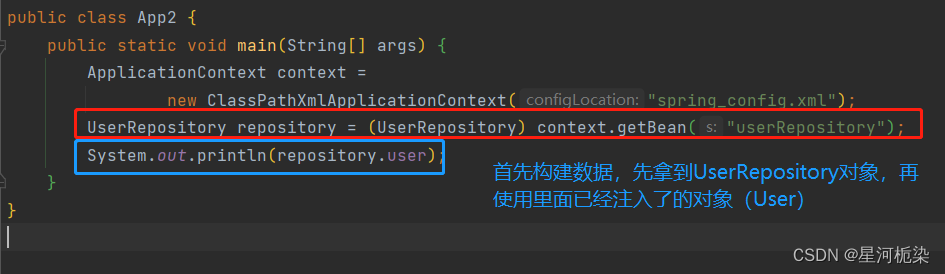
【注意】:上述代码运行成功的前提条件是,spring已经存进了Bean对象(User),不然对象注入也没得注入 。
✔Setter注入的优点:
1)符合单一设计原理,因为一个Setter方法就只针对一个对象
✔Setter注入的缺点::
1)注入的对象可能被修改,setter方法作为方法是可以被多次调用的,那么就有被修改的风险
2)不能注入一个不可变的变量
3)构造方法注入
构造方法注入,跟上述属性注入和Setter注入使用方法差不多,都是在一个类中对另一个类对象进行注入。
此处是在构造方法前加上@Autowired注解,spring就会自动调用该构造方法,从容器中获取对应的Bean对象并传进去。
UserController类:
@Controller
public class UserController {//构造方法注入private User user;@Autowiredpublic UserController(User user) {this.user = user;}public User getUser() {return user;}public void function(){System.out.println("UserController!");System.out.println(user.getName());}
}User类:
public class User {private int id;private String name;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}@Overridepublic String toString() {return "User{" +"id=" + id +", name='" + name + '\'' +'}';}
}启动类:
public class App3 {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");UserController controller = context.getBean("userController", UserController.class);controller.function();}
}🎈构造方法注入和其他两个注入最大的区别是:
如果当前类只有一个构造方法注入,可以省略@Autowired,spring依然会去找对应的Bean对象进行注入;但当出现多个构造方法注入时,就不能省略了,spring不知道要对具体哪个进行构造方法注入。
@Controller
public class UserController {//构造方法注入private User user;// @Autowired //即使省略了还是可以进行构造方法注入public UserController(User user) {this.user = user;}public User getUser() {return user;}public void function(){System.out.println("UserController!");System.out.println(user.getName());}
}而且需要注意的是,一个类中有且只能有一个被@Autowired注解修饰的构造方法,否则spring不知道要对哪个构造方法进行对象注入。如果加多了就会报错。spinrg规定只能在一个类中使用一次@Autowired修饰。
构造方法的注入可以一次性注入多个对象,但切记注入的对象一定得是spring中有的,这是最基本的要求,如果spring中都没有该Bean对象,那谁传一个参数过去呢🙌?
①构造方法的优点:
1)可以使用注入被final修饰的对象,这是因为不可变量要想能使用,
①在声明的时候就得进行赋值,否则报错
②在构造方法中进行赋值;这两种规范都是jdk的要求,即使是spring也得服从; 而构造方法注入正好满足不可变量要想使用的第二个条件;由于构造方法是在类加载的时候就调用,也就是说在在类加载的时候就执行构造方法注入,因此就会直接从spring中获取Bean对象注入到该不可变量中(给它赋值了)。
2)注入的对象(依赖对象)一定会完全初始化,因为依赖对象是在构造方法中执行的,而构造方法是在类加载的时候就执行,
因此依赖对象会在第一时间就初始化完成。
3)通用性好,不仅适用于IOC,还能使用多种框架,这是因为构造方法是jdk支持的(最底层的框架),所以更换任何框架,都是适用的。
4)注入的对象不会被修改,因为在一个类的生命周期中,构造方法只调用一次。
②构造方法的缺点:
构造方法的缺点也很明显,它可以进行多个注入,这就不满足单一设计原则了。
4)@Resource注解
✔@Resource注解和@Autowired注解功能一样,都是能进行对象注入;这两个注解各有各的优点、缺点,可以根据场景需求使用其中一个进行对象注入。
用法和@Autowired一样,只是没有构造方法注入
@Resource和@Autowired的区别:
- 指定spring中的Bean对象名称,从而获取Bean对象;这也是@Autowired无法做到的,它里面就只有一个属性required,默认为true,表示当前注解一定得注入一个存在的Bean对象,否则会报错。
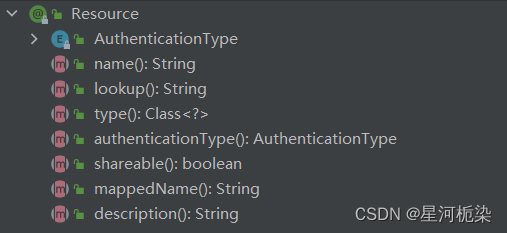
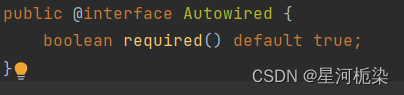
- @Resource和@Autowired出身不同,@Resource是jdk提供的,而@Autowired是spring提供的
- @Resource只能进行属性注入和Setter注入,无法进行构造方法注入,这是因为@Resource比较特殊,注入的时机比较慢,是在对象创建后才注入;而构造方法注入是类加载的时候就注入了,因此无法@Resource无法用于构造方法注入;
3.7、多个同类型Bean对象的指定获取
当spring存入了多个同类型的Bean对象时,如果只是使用@Autowired进行对象注入,很有可能无法准确拿到想要的Bean对象
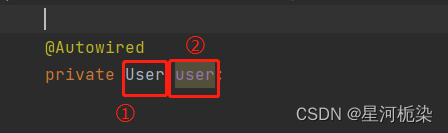
@Autowired对象注入,首先会根据类名去Spring中寻找符合的类型的Bean对象,但由于Spring当中存在多个同类型Bean对象,因此就会按变量名去寻找,但有时注入对象的命名跟Spring当中的Bean对象没有一个是匹配的,那么此时就很麻烦,在不更改注入对象命名的前提下,没法拿到对应的Bean对象。
以下述为例:(Spring 当中存入两个User类型的Bean对象,命名分别是user1、user2)
@Service
public class UserService {@Beanpublic User user1(){User user = new User();user.setName("1");return user;}//使用方法注解存储Bean对象@Beanpublic User user2(){User user = new User();user.setName("2");return user;}}此处通过属性注入,获取Bean对象
@Controller
public class UserController {@Autowiredprivate User user;public void function(){System.out.println("UserController!");System.out.println(user.getName());}
}启动类:
public class App3 {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");UserController controller = context.getBean("userController", UserController.class);controller.function();}
}启动类中调用UserController类中注入的User对象,发现没有找到对应的对象。这是因为在进行对象注入的时候,没有在spring当中找到User类名为user的Bean对象,前面存入spring中的对象有User user1,User user2,没有一个是User user。所以此处要获取到准确的Bean对象,需要在属性注入处进行指定。
1) 使用@Qualify
由于@Autowired不像@Resource一样有多个参数可以设置,但spring引入了另外一个注解来辅助@Autowired去指定Bean对象,也就是@Qualify注解
@Qualify(value="")
@Controller
public class UserController {@Autowired@Qualifier(value = "user1")private User user;public void function(){System.out.println("UserController!");System.out.println(user.getName());}
} 
2)使用@Resource
通过设置@Resource中的属性name,来指定Bean对象
@Controller
public class UserController {@Resource(name = "user2")private User user;public void function(){System.out.println("UserController!");System.out.println(user.getName());}
} 
三、Bean的作用域和生命周期
1、Bean作用域的理解
对于传统作用域,能想到的就是,例如:一个方法中定义了一个局部变量a,那么该变量a的作用域就只是作用在当前方法中,出了这个方法就没有用了,除非将它作为返回值或参数传递出去。
而Bean作用域不一样,它表示的是Bean对象在Spring当中的某一种行为模式,比如 单例作用域(单例行为模式),一个Bean对象在spring当中有且仅有一份(共享的),如果谁使用了这个Bean对象,并对其进行修改;其他方法去获取时,就会发现该对象发生了修改。
UserController类
@Controller
public class UserController {@Resource(name = "user1")private User user;public void function(){//此处声明一个新变量指向注入的Bean对象User user1 = user;user1.setName("修改了");System.out.println("UserController");System.out.println(user1.getName());}
}UserRepository类
@Repository
public class UserRepository {public User user;@Autowired@Qualifier(value = "user1")public void setUser(User user){this.user = user;}public void function(){System.out.println("UserRepository");System.out.println(user.getName());}
}启动类:
public class App3 {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");UserController controller = context.getBean("userController", UserController.class);UserRepository repository = context.getBean("userRepository",UserRepository.class);//获取spring中Bean对象user1controller.function(); //此处里面重新声明了一个user1repository.function(); //使用的是原spring中Bean对象user//得到的结果理想是://UserController//修改了//UserRepository//1}
}得到的真实结果是:
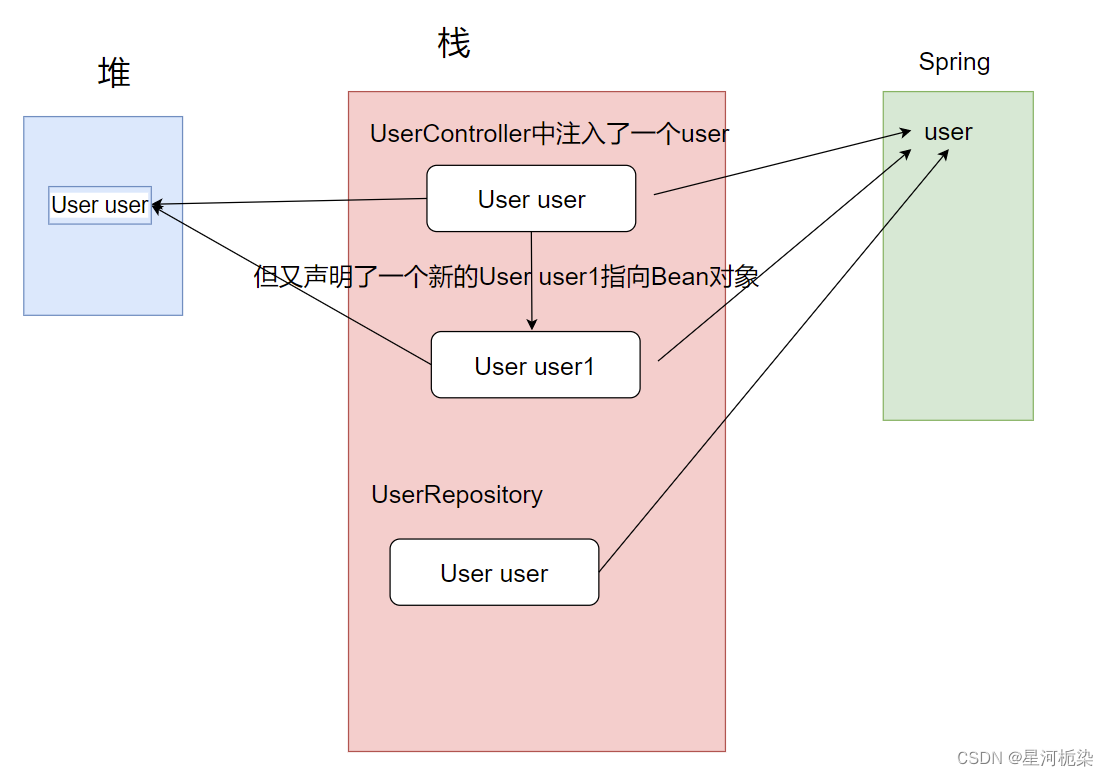
上述UserController类中,对属性注入后的user,又重新声明了一个新变量user1指向里面的user。但根据java语法来说,其实声明的user1是指向Bean对象本身的(只是更改了指向方而已),因此在里面对user1进行属性修改,会影响到Bean对象本身。
又由于Bean中的单例作用域,所有的同一个Bean对象都是共享,有一方对其进行修改,会影响到其他方的获取跟实际原对象信息不一样。
2、Bean的作用域
Bean的作用域一共可以分为五种,分别是:
-
- singleton:单例作用域
- prototype:原型作用域,又称为多例作用域
- application:全局作用域
- request:请求作用域
- session:会话作用域
- websocket:HTTP WebSocket作用域
上述的application、request、session、websocket作用域都是属于spring MVC中的。只适用于web环境中Spring ApplicationContext中有效。
2.1、singleton作用域
singleton作用域,在该作用域下IoC容器中的Bean只存在一个实例,且无论是通过ApplicationContext获取spring上下文从而获取Bean对象,还是使用对象注入的方式获取的Bean对象都是共享的,有且仅有一份,如果有一个类注入使用修改该Bean对象,另外一个类去使用时,该Bean对象就已经发生修改了。
适用场景:通常得是无状态的Bean对象才使用该作用域。(无状态:表示该Bean对象不发生任何属性修改)
【注意】:Spring存储的Bean对象默认是 singleton作用域
2.2、prototype作用域
prototype作用域,称为原型作用域又称为多例作用域,根据意思就知道跟singleton作用域恰好相反了,单例作用域中的Bean对象是共享的;而原型作用域中的Bean对象则不是,在spring中每次获取的Bean对象都是创建的一个新的实例,也就是说每次获取的Bean对象都是新的。就不会说A类修改a这个Bean对象,B类去获取这个a对象,该对象会发生修改,原型模式中是不存在这种情况。
适用场景:通常得是有状态的Bean对象才使用该作用域
2.3、application作用域
application作用域:在一个Http servlet context下定义了一个Bean对象,是全局的。但跟singleton又不一样,application作用域可以在多个类中创建获取上下文,因此这些类中上下文中的Bean对象又不是共享的(一个上下文中就有一个,多个上下文就有多个),只是在当前类中创建的上下文定义的Bean对象才是共享的。singleton作用域的Bean是spring容器中有且仅有一份,且彼此共享。
application作用域是作用于servlet容器,且是属于spring web的作用域
2.4、request作用域
request作用域:相比于prototype作用域而言,prototype作用域是每访问一次Bean对象就创建一个新的实例;而request作用域是每收到一次Htpp请求就创建一个实例,有可能收到的请求中包含多个Bean对象的访问,但一次请求就只创建一次实例,跟prototype差别还是挺大的
⼀次http的请求和响应的共享Bean,且仅支持在 Spring MVC 中使用
2.5、session作用域
session作用域,每一次http session都会创建一次实例,第一次登陆完成后创建session,之后登陆都是用的这个会话;当把会话关了,重新创建会话,这时就算重新登陆一次账号,此时获取的Bean对象是不一样的,因为删掉原有会话重新创建的session id是跟原来不一样的【(session不一样)-> Bean对象也就不一样了。】
用户回话的共享Bean, ⽐如:记录⼀个⽤户的登陆信息,且仅支持在 Spring MVC中 使用
2.6、websocket作用域
在⼀个HTTP WebSocket的生命周期中,定义⼀个Bean实例;对于网络聊天,聊天双方不可以用http进行通信,因为发送http请求是由服务器接受并被动的返回响应;
而用户双方的聊天一定是双向发送,双方都可以接受和发送,就得用到websocket,双方都是客户端WebSocket的每次会话中,保存了⼀个Map结构的头信息,将用来包裹客户端消息头。第⼀次初始化后,直到WebSocket结束都是同⼀个Bean;限定Spring WebSocket中使⽤
2.7、设置Bean对象作用域
使用@Scopre来设置Bean对象的作用域,设置作用域的方法有两种:
1)直接设置:@Scope(" "),字符串参数,直接指定作用域名,比如singleton、prototype
2)枚举设置:@Scope(ConfigurableBeanFactory.xxxx),xxx为一个字符串,如下图两个
String SCOPE_SINGLETON = "singleton";
String SCOPE_PROTOTYPE = "prototype";
下述演示修改将存入的Bean对象设置为 原型模式prototype
BeanUser类:
@Controller
//使用类注解将该对象存入spring当中
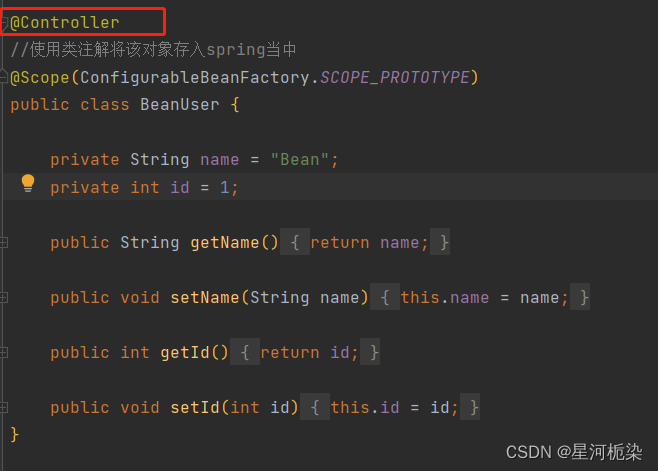
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public class BeanUser {private String name = "Bean";private int id = 1;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}
}
BeanService类(对Bean对象进行修改):
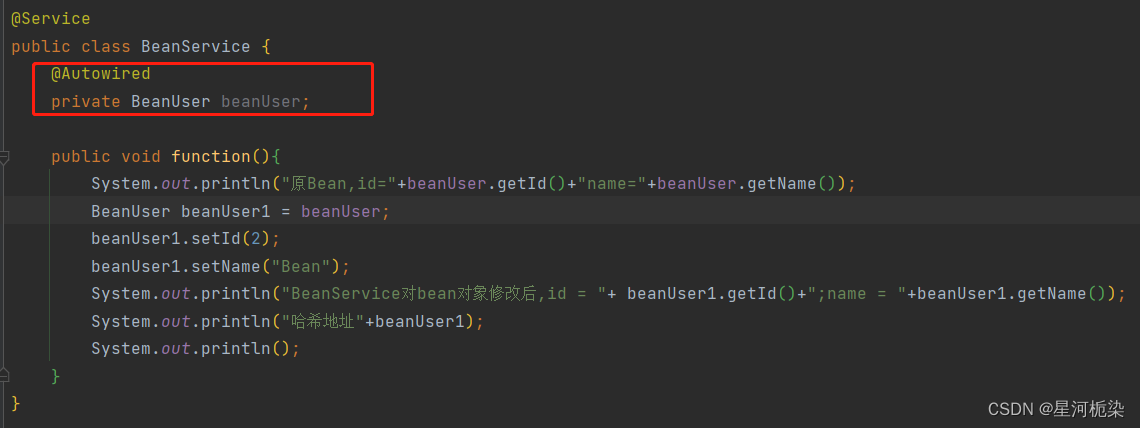
@Service
public class BeanService {@Autowiredprivate BeanUser beanUser;public void function(){System.out.println("原Bean,id="+beanUser.getId()+"name="+beanUser.getName());BeanUser beanUser1 = beanUser;beanUser1.setId(2);beanUser1.setName("Bean");System.out.println("BeanService对bean对象修改后,id = "+ beanUser1.getId()+";name = "+beanUser1.getName());System.out.println("哈希地址"+beanUser1);System.out.println();}
}BeanService2类(输出Bean对象的属性,看是否是同一个)
@Service
public class BeanService2 {@Autowiredprivate BeanUser beanUser;public void function(){System.out.println("BeanService只是获取Bean对象,id = "+ beanUser.getId()+";name = "+beanUser.getName());System.out.println("哈希地址"+beanUser);}
}
启动类:
public class App {public static void main(String[] args) {ApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");BeanService beanService =context.getBean("beanService",BeanService.class);beanService.function();BeanService2 beanService2 =context.getBean("beanService2",BeanService2.class);beanService2.function();}
}
通过输出结果,可以知道,确实prototype作用域下,每次获取的Bean对象都是重新创建的一个新实例。

3、Spring的执行流程
1)首先通过获取Spring Context上下文,来启动容器

2)配置spring中的xml文件

3)Bean的初始化(配置xml文件中的Bean、配置扫描包路径并加载看包路径下的类是否加上了注解)
4)将Bean对象存到到容器中
5)将Bean对象注入/装配到类中使用它
6)销毁Spring
4、Bean的生命周期
Bean的生命周期是Bean从创建到销毁的这一过程。Bean的生命周期(执行流程)相比于Spring的执行流程大有不同,Spring的执行流程是框架的,而Bean的执行流程属于是Spring执行流程中的一个环节
Bean的生命周期可以分为5个部分:
1. Bean的实例化(分配内存空间)
2. 将当前类依赖的 Bean 属性,进行注入和装配
3. Bean的初始化(该过程又可以分为以下几个步骤)【Bean对象的重命名是发生在初始化中的。@Bean(value="")】
- 实现了各种 Aware 通知的方法,如 BeanNameAware、BeanFactoryAware、ApplicationContextAware 的接口方法;(给Bean起一个名称,为一个事件设置完名称之后,就会有一个通知BeanNameAware)
- 执行BeanPostProcessor初始化的前置方法(初始化的前置方法:也就是在初始化之前的/构造方法之前执行的方法)
- 执行Bean的初始化方法(执⾏ @PostConstruct 初始化⽅法,依赖注⼊操作之后被执⾏)
- 执行BeanPostProcessor初始化的后置方
4. 使用Bean (在程序当中使用Bean对象)
5. 销毁Bean(使用@PreDestory、DisposableBean 接⼝⽅法、destroy-method)
【注意】:
1)实例化不等于初始化;实例化:分配内存空间,将之前自变量变成具体的内容,根据内存地址可以拿到它。
2)实例化和属性设置是 Java 级别的系统“事件”,其操作过程不可人工干预和修改;而初始化是给开发者提供的,可以在实例化之后,类加载完成之前进行自定义“事件”处理。
演示Bean对象生命周期的过程
spring的配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:content="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"><content:component-scan base-package="com.test"></content:component-scan><bean id="beanService" class="com.test.service.BeanService" init-method="initMethod"></bean>
</beans>BeanService类(此处为Bean的实例化,属性设置、Bean对象初始化的过程):
🎈配置Bean对象初始化的方法有两种:
1)使用@PostConstruct注解;
2)在xml配置文件中配置 Bean对象中的 init-method属性,指定一个方法为初始化方法,该属性的值对应初始化方法的方法名;
这两种方式创建的Bean的初始化方法有优先之分,注解配置的执行要快于xml中配置的。(init method属于是旧版本用的,后面才使用的PostConstruct,PostConstruct优先级高于init method创建(用新不用旧)
@Service
public class BeanService implements BeanNameAware {//实现BeanNameAware接口,重写setBeanName通知方法@Overridepublic void setBeanName(String s) {System.out.println("执行Bean对象的Aware通知"+s);}//进行Bean对象的初始化
// @PostConstruct
// public void function(){
// //执行Bean对象初始化方法
// System.out.println("@PostConstruct执行Bean对象初始化方法");
// }//也可以使用xml中配置一个初始化方法public void initMethod(){System.out.println("init-执行Bean对象初始化方法");}public void useBean(){System.out.println("使用Bean对象");}@PreDestroypublic void destory(){System.out.println("执行Bean对象的销毁");}}BeanProcessor类:
(将Bean对象的初始化前置和后置方法单独定义在一个类中使用,因为一般前置和后置方法是所有Bean对象通用使用的,不是单独为一个Bean对象所服务的(我为人人),所以这两个方法不能写在某个具体的 Bean 中,否则(这两个方法)不会执行)
@Service
public class BeanService implements BeanNameAware {@Overridepublic void setBeanName(String s) {System.out.println("执行Bean对象的Aware通知"+s);}//进行Bean对象的初始化
// @PostConstruct
// public void function(){
// //执行Bean对象初始化方法
// System.out.println("@PostConstruct执行Bean对象初始化方法");
// }//也可以使用xml中配置一个初始化方法public void initMethod(){System.out.println("init-执行Bean对象初始化方法");}public void useBean(){System.out.println("使用Bean对象");}@PreDestroypublic void destory(){System.out.println("执行Bean对象的销毁");}}启动类:
public class App {public static void main(String[] args) {//此处使用ConfigurableApplicationContext来获取spring中的上下文,因为ApplicationContext类中没有close()---处理spring的销毁方法ConfigurableApplicationContext context =new ClassPathXmlApplicationContext("spring_config.xml");BeanService beanService = context.getBean("beanService",BeanService.class);beanService.useBean(); //使用Beancontext.close(); //销毁Spring}
}🤞注意:Bean的注入和初始化的执行顺序不可以交换
一般我们总会认为,无论是对于要使用的变量还是对象,都是先初始化后再使用。
但对于Spring来说,Bean对象一定得先注入/装配到一个类中,才可以进行初始化。
因为Bean对象的初始化过程中,可能会使用到Bean对象本身,但此时如果是先初始化后注入,初始化方法中拿到的Bean对象就是一个空对象,从而引发 “空指针异常”,所以应该对于Bean的生命周期中,一定得先注入了Bean对象后才可以初始化。
对于spring的基础操作总结到这里就结束了,上述文字量较多,但讲的都是很基础,如果有什么错误,希望各路大神可以指点一二。