论文作者:Weijia Wu,Yuzhong Zhao,Hao Chen,Yuchao Gu,Rui Zhao,Yefei He,Hong Zhou,Mike Zheng Shou,Chunhua Shen
作者单位:Zhejiang University; University of Chinese Academy of Sciences; National University of Singapore
论文链接:https://arxiv.org/pdf/2308.06160v1.pdf
项目链接:https://github.com/showlab/DatasetDM
https://weijiawu.github.io/Data
内容简介:
1)方向:基于生成模型的数据集生成
2)应用:数据集生成
3)背景:目前深度网络对大规模数据的需求较高,但采集和标注这些数据通常耗时。相比之下,使用生成模型(如DALL-E和扩散模型)可以生成无限数量的合成数据。
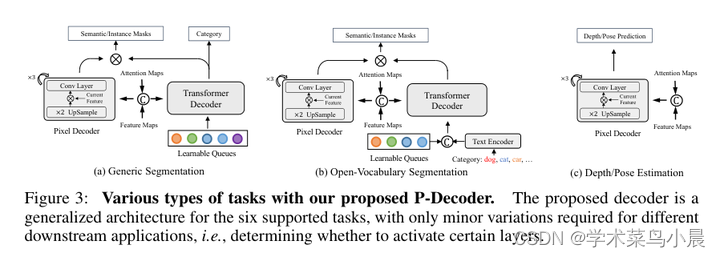
4)方法:本文提出了DatasetDM,一种通用的数据集生成模型,可以生成多样的合成图像以及相应的高质量感知标注。所提出方法基于预训练的扩散模型,将文本引导的图像合成扩展到感知数据生成。扩散模型的潜在代码可以通过解码器模块有效地解码为准确的感知标注。解码器只需使用少于1%(约100张图像)的手动标记图像进行训练,从而实现了无限大的带标注数据集的生成。随后,这些合成数据可用于训练各种感知模型以用于下游任务。
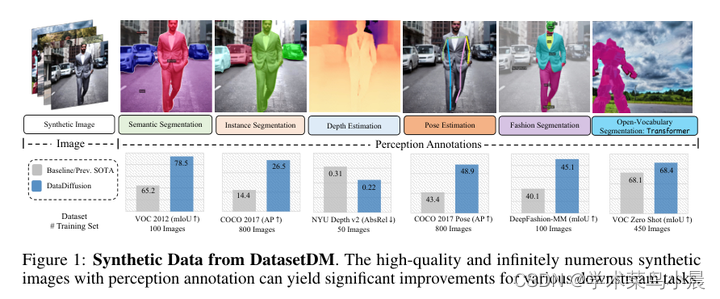
5)结果:通过所提出方法生成的数据集在各种下游任务中展示了强大的性能,包括语义分割、实例分割和深度估计。尤其值得注意的是,它在语义分割和实例分割方面取得了最先进的结果,并且在域泛化方面比仅使用真实数据更加稳健;在零样本分割设置中实现了最先进的结果;同时具备高效应用和新任务组合(例如图像编辑)的灵活性。
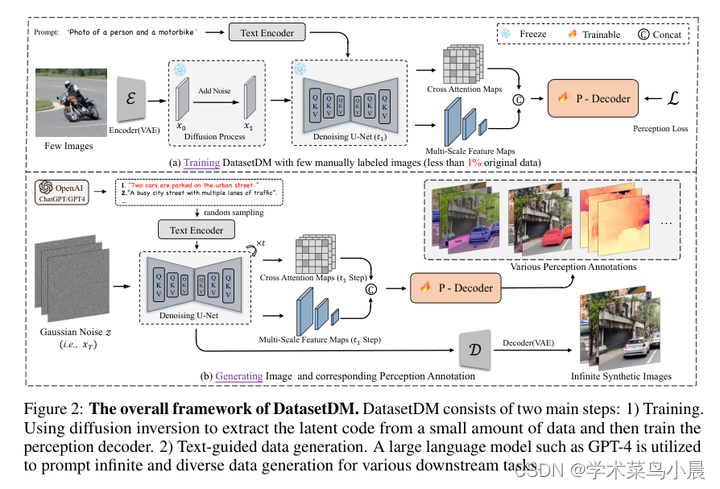
 GPT-4与扩散模型协同,生成的数据示例:
GPT-4与扩散模型协同,生成的数据示例:

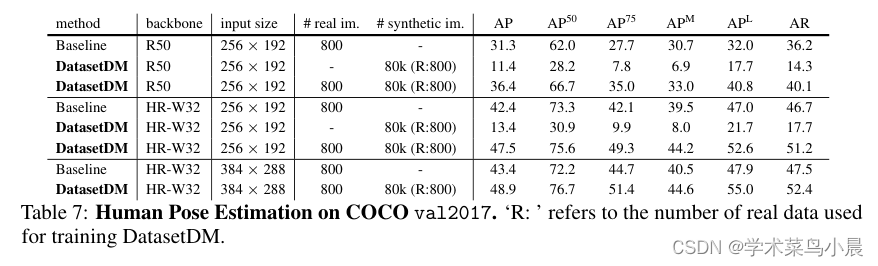
 新数据集加持,感知算法性能提升显著:
新数据集加持,感知算法性能提升显著: