经典嵌套if-else问题
这个也是老生常谈问题了,不管哪里都能看到。 那如何解决
方法一(重要):
如果逻辑分支过多, 即使你不解决嵌套if-slse,至少也要把每个 if的{}里的逻辑抽到一个独立的方法或者工具类或者策略模式类, 保证{}里只有一行或者简单几行代码, 保证住流程的清晰,比如:
Obejct data = null;
if(name > 3){data = buildData();if (age <= 4 && data != null) {getByName();}if (data.getAge() > 5){getByName();}else if (data.getAge() < 6) {getByName();}else {data = buildData();}
}else {data = buildData();
}
如果觉得麻烦, IDEA他是自带抽方法的功能的, 直接鼠标选择要抽出来的内容,然后点击右键的extract-method方法机会自动抽到一个方法里面。
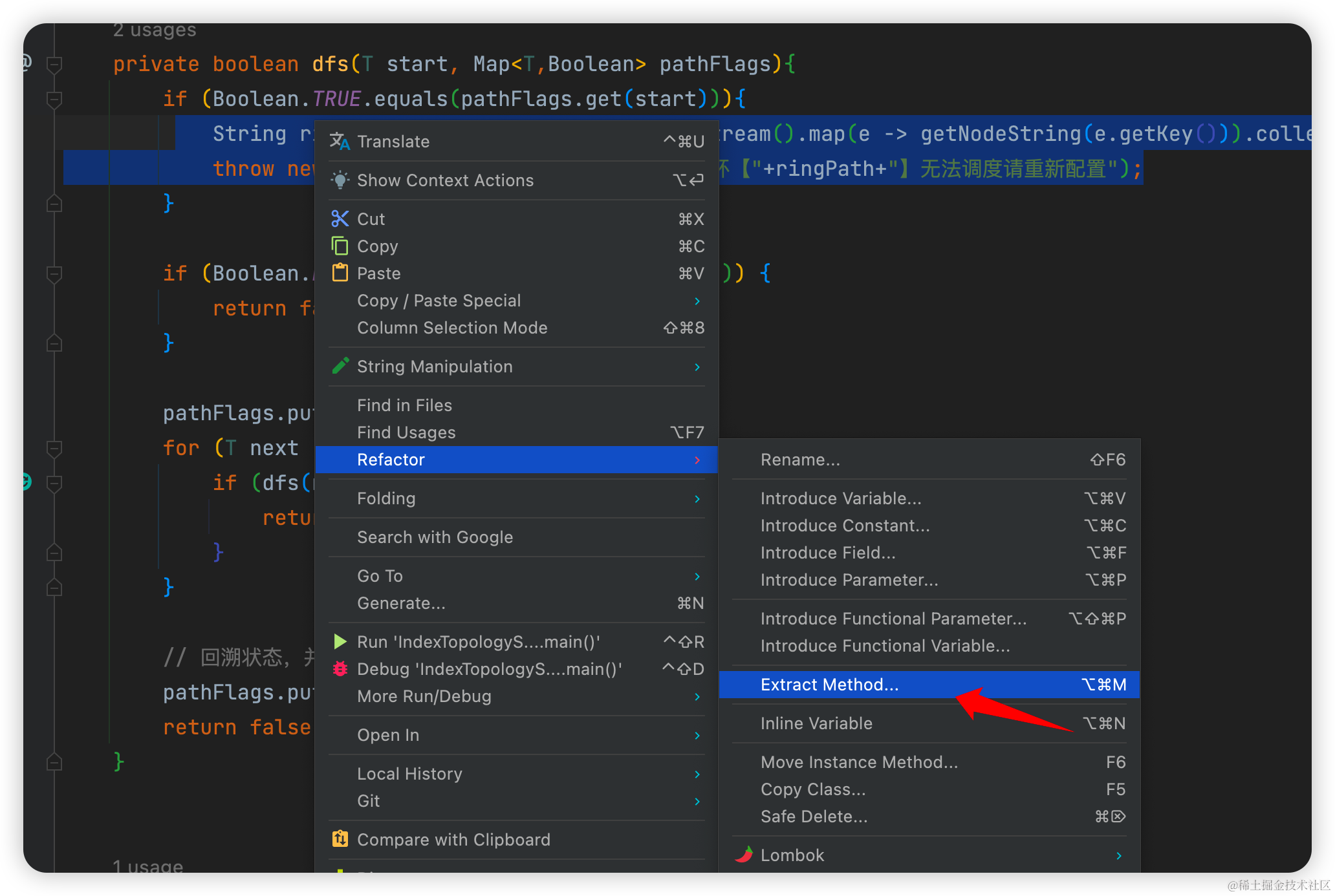
方法2: 提前返回: (卫语句)
我们先把不符合条件或者符合条件的提前处理,提前return或者continne, 而不是直接嵌套一层下去, 这种写法一般也被称为卫语句, 下面是两种不同的写法:
嵌套写法:
for(int i = 0 ; i < dataList ; i++){String name = dataList.get(i);if(name != null){if(name.equals("Xx")){doByXx();continue;}else {// ... 执行业务}}
}
提前返回处理写法:
for(int i = 0 ; i < dataList ; i++){String name = dataList.get(i);if(name == null){continue;}if(name.equals("Xx")){doByXx();continue;}// ... 执行业务
}
方法3: 使用Optional
很多时候我们要必须添加if是因为要做空值的判断过滤处理否则容易空指针异常,这时可以使用JDK自带的
Optional工具或者自行封装的一些空值处理工具。不过有时适用的业务比较有限,强行用也并不能使代码变得更清晰简洁, 具体根据场景判断哪种好 因为有时确实是真的是适合用。
方法4: 使用断言
是的断言也能减少if, 比如很多时候我们对一些条件判断然后抛出异常需要大量if,比如
if (list == null) {throw new BaseException("不能为空");
}
if (list.size() < 10) {throw new BaseException("数量过小");
}
if (list.size() > 100) {throw new BaseException("数量过大");
}
改造后:
Asset.whenTrue(list == null,"请xxx");
Asset.whenTrue(list.size() < 10,"数量过小");
Asset.whenTrue(list.size(),"数量过大");
方法5: 善用三目运算符
这个就不说了,保持好这个意识就行了。 但也别无脑三目,简洁清晰即可。
return data == null ? 3 : 4
方法5: 改变逻辑分支(治本)
改变逻辑分支, 其实我觉得这才是觉得嵌套if-else的根本。 为什么有些人会if-else越来越多。 是因为他已经按照固定的逻辑分支去写下去了, 就像一棵树一样不断产生各种分支叶子, 就像迷宫的出口一样, 虽然都能达到出口, 但是选择不一样的路线产生的逻辑代码是完全不一样的,所以产生的if-else也完全不一样, 你的代码能否清晰简洁在于你能否找到一条清晰的路线,而不是直线一股脑走下去。
那其实这个真的看个人逻辑, 也不太好去解释, 其实刷一些简单算法也是能提升逻辑能力的, 这样我想你写的逻辑分支代码一定跟别人不一样。
Util类是不值钱的
Util其实代表的就是Java里面封装的工具类而且大多数是静态方法调用, 很多初级开发其实都会去封装。 大多数封装的都是一些很通用的工具比如数据计算工具、上传下载, 序列化、反射这种工具型的工具类。但常常封装后发现这种东西封到最后发现其实网上人家早就封装好了比如那个Hutool。 但我觉得这些都不重要,因为Util在我看来是不值钱的,因为每个项目每个工程甚至每个人都有自己的Util类, 它所做的只是为了把通用方法抽象出来复用,以及减少正常业务代码的逻辑提高简洁性这个很重要, 不知道想过没其实业务也可以抽到工具类,即使抽不到复用的效果(当然还是尽量)也能提高可读性, 因为工具类的方法一定符合是独立的,单一的,无依赖,入参少且清晰,返回值明确,以及方法语义明确, 可复用的原则。 所以其实是建议大量使用工具类的只要符合我说的原则即使做不到复用,也一定能降低屎山代码。 当然优先还是要做好面向对象的抽象设计,工具类只是如虎添翼
Mybatis-Plus时代下的三层抽象
作为CRUD的码农这个三层抽象就是基本了无人不知, 就是Controller接口层 + Service业务层 + Dao数据访问层写代码三件套。
但我要说由于Mybatis-Plus的兴起很多人Service业务层和Dao数据访问层弄混了。 为什么呢? 因为
Mybatis-Plus的com.baomidou.mybatisplus.extension.service.impl.ServiceImpl的出现, 好巧不巧名字就包含Service(业务)。 于是很多人索性继承ServiceImpl后就直接在里面写业务了也就是业务层, 但是你仔细你看发现它继承是BaseMapper,也就是说它跟Mapper是一样的层级都是Dao数据访问层, 是用来在里面写SQL的, 但是现在却在ServiceImpl里面写业务。 这个很重要一定要把业务和SQL区分开来, 因为业务是业务, SQL是SQL, SQL是不值钱的, SQL可以到处写也不需要进行复杂的抽象设计, 每写一个SQL就像一个工具就像一套计算公式它就放在哪等着你去用。
并且一个ServiceImpl也可以有多个实现,它仅仅代表写SQL的位置在哪而已,而很多人固定认为一张表就对应一个ServiceImpl一个Mapper。 那其实你是不是也可以这样,比如有个资产表, 然后你可以创建一个 AssetForSatusServiceImpl用来写统计资产相关的SQL, 以及再创建一个 AssetForLinkServiceImpl用来写资产关联相关的SQL对吧。 也就是ServiceImpl它就是用来写SQL的不是用来写业务的, 所以你继承ServiceImpl的实现应该叫 XXXDao, 然后业务层要用什么SQL就注入使用这个XXDao。 你的业务层应该根据功能模块再独立创建Service和命名。 然后再里面注入使用Dao层,比如有个用户资产中心模块业务
class UserAssetCenter {@Autowiredprivate AssetForSatusDao dao1;@Autowiredprivate AssetForLinkDao dao2;// 使用dao写业务// .......
}
一定要区分什么是业务什么是SQL, 保证业务层的代码逻辑清晰这样才能更好对业务层进行负载抽象设计。
恶心的路径拼接
经常在生成以及访问文件的时候,都会去设置拼接的文件路径,类似下面
String path = dir + "/" + strings.get(i) + "/" + i + ".xls";
我们需要关注路径分隔符的拼接,确保拼接路径的语法是否正确,经常可能前后多一个分隔符少一个就可能报错了。那我们是不是可以抽一个方法去屏蔽路径的拼接语法,我们其实只关注路径的层级而已。比如下面这种,如果存在大量的拼接可以提升我们代码容错率和简洁性
String path1 = joinPath(dir,strings.get(i),(i + ".xls"));
简单实现:
/*** 拼接路径忽略是否带分割符* @return 返回格式: /a/b/c/*/
public String joinPath(Object...paths){List<String> cleanPaths = new ArrayList<>();for (Object tmp : paths) {String path = tmp.toString();if (path.startsWith(File.separator)){path = path.substring(1);}if (path.endsWith(File.separator)){path = path.substring(0, path.length() - 1);}cleanPaths.add(path);}StringBuilder stringBuilder = new StringBuilder();stringBuilder.append(File.separator);for (String cleanPath : cleanPaths) {stringBuilder.append(cleanPath).append(File.separator);}return stringBuilder.toString();
}
空值判断之使用BigDecimal的加减乘除
经常在使用BigDecimal进行加减乘除的时候,如果数值为null或者除数为0经常会报异常,但其实我们并不想报异常算不了就不算了就返回null就好了, 所以为了保证正常执行可能会进行大量的null值判断,比如下面对每个变量都进行判断
public static void main(String[] args) {BigDecimal a = null;BigDecimal b = null;BigDecimal c = null;BigDecimal d = null;// 计算 a - (b + c) / dif (a != null && b != null && c != null && d != null && d.compareTo(BigDecimal.ZERO) != 0){BigDecimal value = a.subtract((b.add(c).divide(d,2,RoundingMode.HALF_UP)));}
}
随着计算的变量越多代码只会越来越臃肿,所以我们需要一个方法去屏蔽空值的情况让代码正常执行。比如只要平时我们在原先数学计算方法上再抽一层,最终变成, 我们就不需要关注是否会空指针异常了,既能提高容错率和代码简洁性, 如下所示
// a - (b + c) / d
BigDecimal value = subtract(a, divide(add(b, c), d, 2));
public static BigDecimal add(BigDecimal a, BigDecimal b) {if (a == null || b == null){return null;}return a.subtract(b);
}public static BigDecimal subtract(BigDecimal a, BigDecimal b) {if (a == null || b == null){return null;}return a.subtract(b);}public static BigDecimal divide(BigDecimal dividend, BigDecimal divisor, int scale) {if (dividend == null || divisor == null || divisor.compareTo(BigDecimal.ZERO) == 0) {return null;}return dividend.divide(divisor, 8, RoundingMode.HALF_UP).setScale(scale, RoundingMode.HALF_UP);
}
既然谈到空值判断,像其他情况也可以使用JDK自带的Optional 或者 一些其他框架比如Hutool的Opt,当然最后是针对自己的业务定制化去封装提高简洁性和容错率就更好了,就像此处的BigDecimal调用一样针对自己的空值或者分母为0情况做一些定制化处理。
存在各种硬编码
硬编码就是用字符串去代替我们的变量去写代码, 使用字符串的话如果需要修改,则需到到处都修改, 而且也无法引用出这个字符串被哪里使用了。 而如果使用变量就没有这些问题, 直接利用IDEA右键Refactor一下就能全部修改了,而且不容易出错语义清晰, 也能利用变量的各种操作特性。
下面是硬编码的样例:
- 在取值、赋值时存在大量冗余操作,多了很多if-else。
// "成功" ==> 为硬编码
dataList.stream().filter(e -> "成功".equal(e.getStatus())).collect(toList());// Map硬编码 key ==> 为硬编码
Map<String, Object> paramMap = new HashMap<>();
CompanyDTO dto = new CompanyDTO();
paramMap.put("companyName", dto.getCompanyName());
paramMap.put("area", dto.getArea());if (dto.getId() != null) {paramMap.put("id",dto.getId());
}else {paramMap.put("id","");
}if (paramMap.get("id") != null){// ...
}
那如何结果硬编码, 基本上就是定义一个全局常量类、成员变量常量、或者枚举类这个就不说基本都知道。
但是还有一种情况的硬编码容易被忽略,甚至不认为是硬编码,那就是上面例子中的Map硬编码, 因为觉得要put的key可能是不固定的, 所以一直要put、put、put。
比如我们业务经常生成各种模版时就要用Map<String,Object>作为参数去生成,比如生成邮件模版、Excel模版、合同模版、pdf模版等等。
那其实有没可能 Map<String,Object> 跟 对象 是一一对应的呢? 所以为何不直接定义一个对应的类去接收,而且还能做各种空值处理,甚至还能面向对象设计做参数对象的内聚。
比如:你要生成一个 A合同模版,直接定义一个 A合同参数类, 如下所示,并且我们考虑到要做字段空值处理以及可能还有B合同模版,所以也抽一个合同模版参数基类, 然后直接使用基类的toObjMap()就可以直接转成Map<String,Object> 然后你们就可以传参到你们的工具去生成文件了。比如下面
// 基础合同模版参数
class BaseTemplateParam {// 当前日期private String curDate;// 用户名private String userName;// 将此参数对象转成Map, 并把null值字段存储默认空值public Map<String,Object> toObjMap(){String json = JSON.toJSONString(this, SerializerFeature.WriteMapNullValue);Map<String, Object> map = JSON.parseObject(json, new TypeReference<Map<String, Object>>() {});map.entrySet().stream().filter(e -> e.getValue() == null).forEach(e -> e.setValue(initEmptyValue(e.getKey())));return map;}private Object initEmptyValue(String key) {Field field = ReflectionUtils.findField(this.getClass(), key);if (field == null){return null;}Class<?> fieldType = field.getType();if (fieldType == String.class || fieldType == BigDecimal.class || fieldType == Integer.class || fieldType == Long.class || fieldType == Double.class || fieldType == Float.class || fieldType == Boolean.class) {return "";}else if (List.class.isAssignableFrom(fieldType)) {return new ArrayList<>();}else if (Map.class.isAssignableFrom(fieldType)) {return new HashMap<>();}else if (Temporal.class.isAssignableFrom(fieldType)) {return "";}return null;}
}// A合同模版参数
public class ATemplateParam extends BaseTemplatePatam {// 承诺内容private String promise;// 合同编号private String contractNo;
}
所以如果你要使用 Map<String,Object>, 不如直接定义一个对象, 如果你们但是字段值是有限的,在执行过程中可能会一直动态添加字段。 首先动态添加到底是有限的还是无限的? 如果是有限的也不是特别特别多几百个之类何不直接枚举完。 即使是无限是,那是不是可以动静结果一部分成字段,一部分成 Map<String,Object>, 然后扁平化成同一个级别参数(就是类似Jackson的@JsonAnyGetter实现的)。
对了还有一种硬编码容易被忽略,就是 各种注解的参数值比如@Component, 其实也可能配成常量。 不然如果根据name依赖, 到处都会硬编码。
最后要不要用硬编码得看会不会被多次使用, 如果只有这个地方有那也不用做多余其他封装
善用函数式接口
Java有几个常用的函数式接口比如Function、Supplier、Predicate、Consumer,很多人对函数式接口的印象其实只是停留在lambad表达式里面的匿名函数应用。 但是其实我们在开发的过程中,也可以创建自己的函数式接口以便于封装抽象。 其实在其他一些语言比如Python是可以直接把整个函数作为入参的, 也就是函数能够传递, 但是Java里面并没有这个特性,参数传递只能是对象类型和基本类型, 而函数式接口其实就是这方面的一个解决方案, 把外部方法的调用作为参数进行传递,可以大大提升我们代码的抽象封装和复用。
比如下面就是我利用函数式接口封装一个简单的功能 ,可以看到即使看起来好像无法封装的功能逻辑,通过方法传递好像也能封装起来
/*** 分组计算差集, 然后将差集补充到该分组内** 将原始集合(itemDTOList) 按照groupDim维度进分组, 然后将每个分组内的所有collectDim字段进行汇总* 汇总后 与 allAbscissa进行计算差集,这些差集就是需要补充的条目, 然后将这些差集按照getEmptyObject逻辑生成空对象添加到该分组内** @param itemDTOList 原始集合* @param groupDim 分组的维度字段* @param collectDim 组内收集的数据字段* @param allDim 组内需要展示的所有维度* @param getEmptyObject 生成空对象的逻辑** @param <T> 原始集合的类型* @param <G> 分组的类型* @param <C> 组内收集的类型** @return 补充后的集合*/
public static <T,G, C> List<T> replenish(List<T> itemDTOList,Function<T, G> groupDim,Function<T, C> collectDim,List<C> allDim,Function2<G,C,T> getEmptyObject){Map<G, List<T>> nameItemListMap = itemDTOList.stream().collect(groupingBy(groupDim));nameItemListMap.forEach((name, itemList) -> {List<C> tmpAll = new ArrayList<>(allDim);List<C> abasicssaList = itemList.stream().map(collectDim).collect(toList());tmpAll.removeAll(abasicssaList);if (CollectionUtils.isNotEmpty(tmpAll)) {List<T> missingList = tmpAll.stream().map(e -> getEmptyObject.apply(name, e)).collect(toList());itemList.addAll(missingList);}});return nameItemListMap.values().stream().flatMap(Collection::stream).collect(toList());
}
能用for循环解决就不要再写一遍
就是其实这几个逻辑的参数变量是能够跟随for循环而变化的逻辑其实就是能够放到for循环去处理,不必每个再调用一遍。
比如下面是原始写法:
- 分别去计算各个区间的数据,总共有三次方法调用
// 计算区间 (0,50万]的数据
BigDecimal amount = calcData(dataList,0,50);// 计算区间 (50万,100万]的数据
BigDecimal amount1 = calcData(dataList,50,100);// 计算区间 (100万,300万]的数据
BigDecimal amount1 = calcData(dataList,100,300);
乍一看好像每个调用方法入参都不一样有些是50,有些是300,怎么用for循环一次调用? 其实还是可以的,就是把每个调用的参数封装到列表里面,然后for循环列表,比如
- 我们把每次调用的入参封装到列表ranges里面,这样后续不管要计算其他区间代码只需要在ranges里面添加即可。不必每次添加一次方法调用。
// 区间 --前开后闭
Object[][] ranges = {{new BigDecimal(0),new BigDecimal(500000),"小于50万(含)"},{new BigDecimal(500000),new BigDecimal(1000000),"50-100万(含)"},{new BigDecimal(1000000),new BigDecimal(3000000),"100-300万(含)"},
};for (Object[] range : ranges) {BigDecimal amount = calcData(dataList,(BigDecimal) range[0],(BigDecimal) range[1]);
}
那这个思想往大了说其实就是能用算法/复杂逻辑解决的东西就不要用每次人工写代码的方式去实现,不然不利于扩展使用的人也不方便。 一个东西一定是用起来简单,但是内部一定是复杂的。
数据库表冗余字段的选择
其实到底什么时候我们要去设计表的冗余字段的时候很多新人可能没有去思考过, 甚至他都不觉得是冗余字段觉得这个字段就是这张表的,因为常常看需求页面字段展示啥他就建啥字段然后去维护这个字段,然后就开始一股脑CRUD(增删查改)了。
维护冗余好处就不用说了不用关联查询大大提升查询效率。 但是却大大提升了维护的成本, 而且我认为在大部分情况下这个风险回报是很低的。 仅仅方便了查,却为难了增删改,也更容易堆出屎山代码。
因为随便业务需求的迭代,我们可能存在各种各样更新这个冗余字段值的可能, 而且如果存在并发更新还要关注线程安全问题。
比如我们有个用户财产表, 里面冗余一个用户资产金额的字段, 那你想那是不是我们在新增、修改、删除用户相关资产的时候(比如关联的银行卡、债券)
我们不是得去修改这个冗余字段的值吗。 而且如果采用的是增量更新的方式又会增加维护成本。
- 什么是
增量更新就是比如 用户新关联了一张200元的债券,
然后就给这个冗余字段的值新增200, 对应sql ( set value += 200), - 还是一种就是
实时计算更新出最新的用户资产金额,然后重新set进去即可。 那如果是采用实时更新那是不是就类似于缓存的效果,当发生变更时就令缓存失效, 那还不如不维护直接每次实时计算呢何必维护这根冗余字段呢
其实冗余字段最适合就是那种压根不需要维护的,其次适合那种触发变更地方少,对查询效率有高要求或者要跨库要分页必须维护, 或者支持一定时间内的容错的。
比如操作人姓名这个字段就非常推荐, 因为如果只存操作人id还得跨表甚至跨库获取姓名, 而且操作人姓名这个字段在每次用户做了操作后其实就会实时更新。
最重要是我们一般也不维护这个字段就是用户更新姓名后也不去实时更新这个冗余字段,因为我觉得这个业务其实是合理的支持一定时间内的容错所以不需要维护。
维护冗余字段一定会带来大量的维护成本,容易出错, 所以一定要想好到底适不适合。
几千行代码的Service层
有没发现你写的一个Service业务层的代码写着写着就到了几千行代码, 排除这个所谓的独立业务真的超级究极无敌恶心和复杂且多的情况。 即使你做了Util类的封装, 也加了各种设计模式把代码放到其他地方,做了SQL区分把SQL放在Dao层, 也做了业务拆分放到不同业务层,但是总有一个业务层可能会超过上千行, 这是为什么?
我觉得有三个原因:
- 1、业务真的太复杂太多不好封装
- 2、逻辑太冗余,终点是一样但是逻辑分支有千万条,没有找到简洁清晰的逻辑分支
- 3、没有做合理的类图抽象设计
1和2就不说了纯看个人逻辑。 说说3, 没有做类图抽象设计就是你用仅仅一个类去包含了所有业务逻辑, 也就是一个独立业务层内聚了所有业务代码, 那我们来看Spring是怎么做类图抽象设计的。
这是Spring容器的BeanFactory其中几个大致类图抽象:
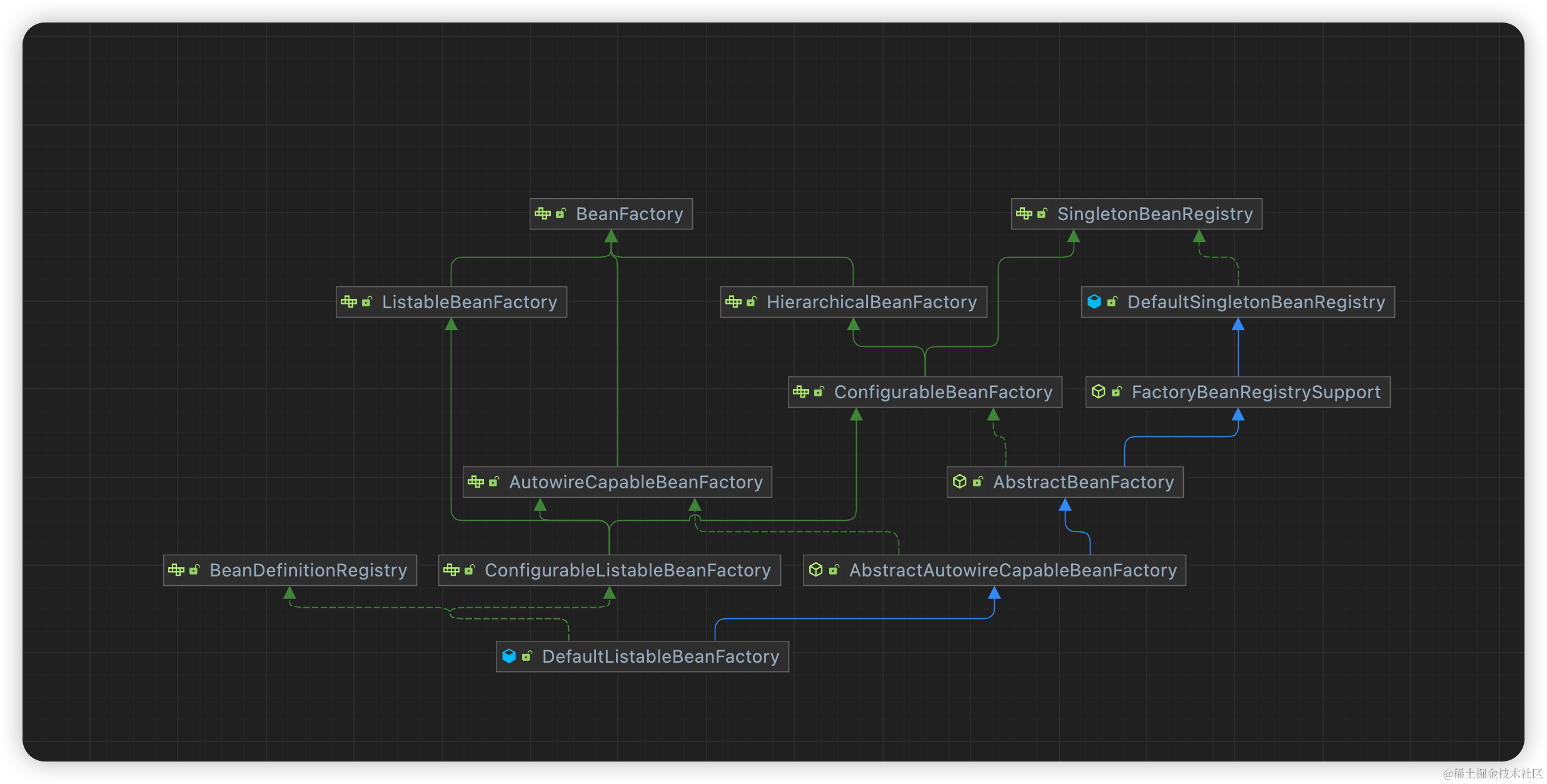
可以看到其实他只有一个业务实现类DefaultListableBeanFactory, 但是通过不同职责划分,将接口分层、抽象分层把不同的业务逻辑分到不同的类中。 比如接口层SingletonBeanRegistry就负责Bean实例对象的缓存和获取 ,然后 DefaultSingletonBeanRegistry 就负责具体实现怎么缓存。
然后 FactoryBeanRegistrySupport抽象层 就负责FactoryBean的Bean创建逻辑不再走原创建Bean的逻辑实现
然后 ConfigurableBeanFactory接口层,就负责配置功能相关的接口API,比如BeanPostProcessor的添加。
然后 AbstractBeanFactory就负责抽象实例化Bean的一些模版方法核心流程, 然后创建Bean的具体模版方法的核心实现又是放到下层AbstractAutowireCapableBeanFactory里, 包括通过代理工厂创建Bean,实例化 Bean、执行BeanPostProcessor属性修改、Bean 填充属性、执行 Bean 的初始化方法和 BeanPostProcessor 的前置和后置处理方法,注册DisposableBeanBean等等。
然后 BeanFactory接口层 就负责怎么创建实例化Bean包括依赖注入等等。
然后我想说就是其实理论上他是不是可以把所有接口的API都放到一个接口里,就好像你定义了一个Bean容器接口负责容器相关的功能。 然后我们写业务代码的时候是不是也是这样做的。 然后我们的实现类代码就越堆越多,最终超过数千行。
即使我们的业务不够复杂依然可以进行抽象分层,只是看你按什么维度去进行职责划分和抽象,反正我们的目的就是让代码变得简洁、可复用。
随便举个的分层抽象, 比方有个资产模块,那我们是不是定义几个接口层划分,比如资产统计接口层, 资产变更层,资产关联层,资产页面层, 类图如下所示
interface AssetWebService{// 资产页面层
}interface AssetStatService{// 资产统计层
}interface AssetUpdateService extend AssetStatService {// 资产变更层
}interface AssetLinkService extend AssetStatService{// 资产关联层
}public class AbstracAssetService implement AssetUpdateService, AssetLinkService {// 抽象业务实现}public class DefaultAssetServiceImpl extend AbstracAssetService implement AssetWebService{// 业务实现
}你看这样我们不就能将数千行代码按照不同的职责分分配到不同层中类了吗这个每个类代码量都可控制在1千行内。将代码量均摊到每层类只做好一件事就行。 当然具体业务职责拆分和抽象得根据你们具体业务来。
其他
// 持续更新。。好像还有很多东西想不起来想起来再说
最后
关于写代码这件事其实个人是有点强迫症和代码洁癖,如果代码写的格式不漂亮就很难受所以我可能会去额外追求一些东西, 但是其实很多写代码的一些东西好像大家都知道要这么去做, 但却没有这样做 ,排除不会做的原因, 还有情绪的原因, 比如懒的做了能跑就行,写都写了不想改了或者今天心情不好不改了, 或者想LastDay了,或者工作不开心了受委屈了, 被骂了,还有工资绩效不满意,于是乎。。。, 总之无解(狗头)