目录
一、Apache Hive概述
1.1 什么是Hive
1.2 为什么使用 Hive
1.3 Hive 和 Hadoop 关系
二、场景设计:如何模拟实现Hive功能
2.1 如何模拟实现 Apache Hive 的功能
2.2 映射信息记录
2.3 SQL 语法解析、编译
2.4 最终效果
三、Apache Hive 架构、组件
3.1 架构图
3.2 组件
3.2.1 用户接口
3.2.2 元数据存储
3.2.3 Driver 驱动程序,包括语法解析器、计划编译器、优化器、执行器
3.2.3 执行引擎
四、Apache Hive 数据模型
4.1 Data Model 概念
4.2 Databases 数据库
4.3 Tables 表
4.4 Partitions 分区
4.5 Buckets 分桶
五、Apache Hive 是要取代 MySQL 吗?
5.1 思考
5.2 Hive 和 MySQL 对比
一、Apache Hive概述
1.1 什么是Hive
Apache Hive 是一款建立在 Hadoop 之上的开源数据仓库系统,可以将存储在 Hadoop 文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似 SQL 的查询模型,称为 Hive 查询语言(HQL),用于访问和分析存储在 Hadoop 文件中的大型数据集。
Hive 核心是将 HQL 转换为 MapReduce 程序,然后将程序提交到 Hadoop 群集执行。Hive 由 Facebook 实现并开源。
 1.2 为什么使用 Hive
1.2 为什么使用 Hive
- 使用 Hadoop MapReduce 直接处理数据所面临的问题
人员学习成本太高,需要掌握 java 语言;
MapReduce 实现复杂查询逻辑开发难度太大。
- 使用 Hive 处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手);
避免直接写MapReduce,减少开发人员的学习成本;
支持自定义函数,功能扩展很方便;
背靠 Hadoop,擅长存储分析海量数据集。
1.3 Hive 和 Hadoop 关系
从功能来说,数据仓库软件,至少需要具备下述两种能力:存储数据的能力、分析数据的能力 Apache Hive 作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过 Hive 并不是自己实现了上述两种能力,而是借助 Hadoop。
Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据。这样突然发现 Hive 没啥用,不过是套壳 Hadoop 罢了。其实不然,Hive 的最大的魅力在于用户专注于编写 HQL,Hive 帮您转换成为 MapReduce 程序完成对数据的分析。
二、场景设计:如何模拟实现Hive功能
2.1 如何模拟实现 Apache Hive 的功能
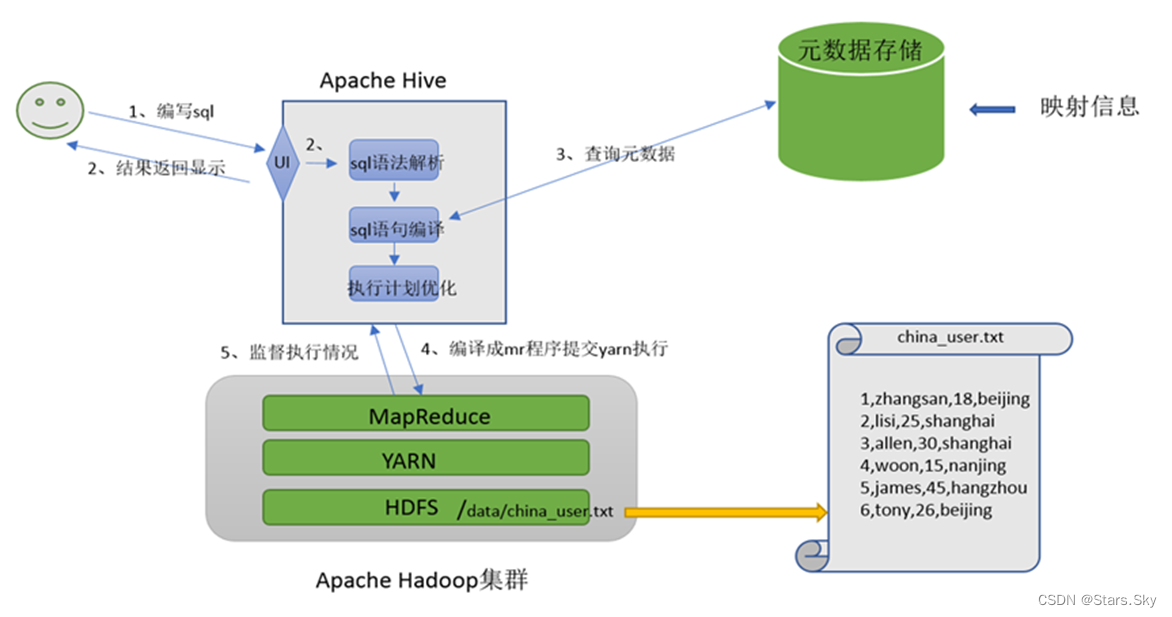
如果让您设计 Hive 这款软件,要求能够实现用户编写 sql 语句,Hive 自动将 sql 转换MapReduce 程序,处理位于 HDFS 上的结构化数据。如何实现?
在 HDFS 文件系统上有一个文件,路径为 /data/china_user.txt,其内容如下:

需求:统计来自于上海年龄大于 25 岁的用户有多少个?
2.2 映射信息记录
映射在数学上称之为一种对应关系,比如 y=x+1,对于每一个 x 的值都有与之对应的 y 的值。在 hive 中能够写 sql 处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据 metadata)。
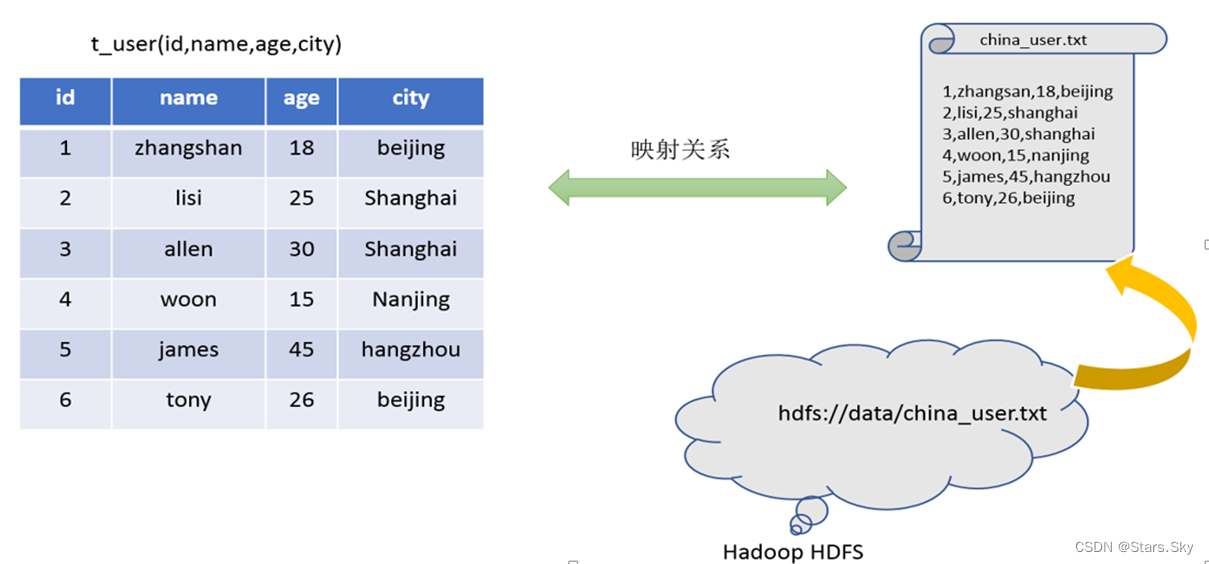 具体来看,要记录的元数据信息包括:
具体来看,要记录的元数据信息包括:
-
表对应着哪个文件(位置信息)
-
表的列对应着文件哪一个字段(顺序信息)
-
文件字段之间的分隔符是什么
2.3 SQL 语法解析、编译
用户写完 sql 之后,hive 需要针对 sql 进行语法校验,并且根据记录的元数据信息解读 sql 背后的含义,制定执行计划。并且把执行计划转换成 MapReduce 程序来执行,把执行的结果封装返回给用户。
- 重点理解下面两点:
Hive 能将数据文件映射成为一张表,这个映射是指什么?
文件和表之间的对应关系
Hive 软件本身到底承担了什么功能职责?
SQL 语法解析编译成为 MapReduce
2.4 最终效果
基于上述分析,最终要想模拟实现的 Hive 的功能,大致需要下图所示组件参与其中。从中可以感受一下 Hive 承担了什么职责,当然,也可以把这个理解为 Hive 的架构图。
 三、Apache Hive 架构、组件
三、Apache Hive 架构、组件
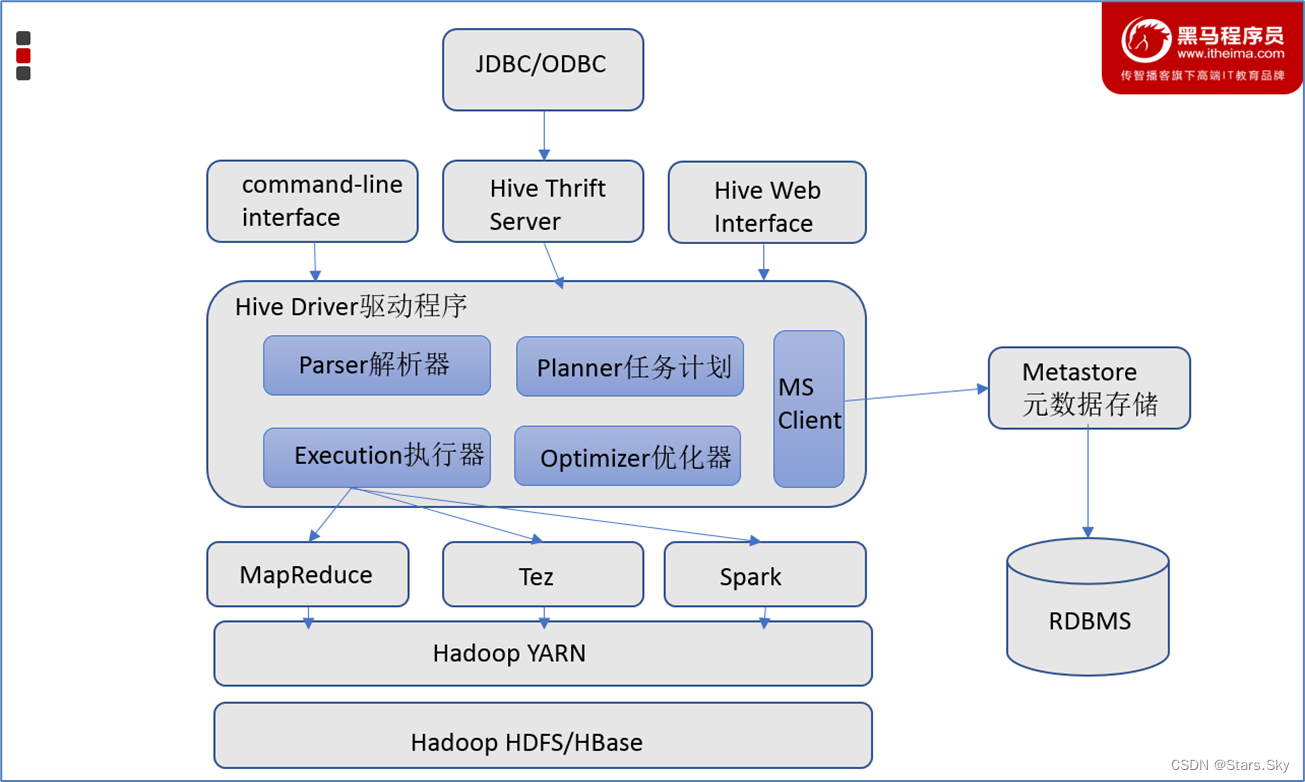
3.1 架构图
 3.2 组件
3.2 组件
3.2.1 用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为 shell 命令行;Hive 中的 Thrift 服务器允许外部客户端通过网络与 Hive 进行交互,类似于 JDBC 或 ODBC 协议。WebGUI 是通过浏览器访问 Hive。
3.2.2 元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3.2.3 Driver 驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
3.2.3 执行引擎
Hive 本身并不直接处理数据文件。而是通过执行引擎处理。当下 Hive 支持 MapReduce、Tez、Spark 3 种执行引擎。
四、Apache Hive 数据模型
4.1 Data Model 概念
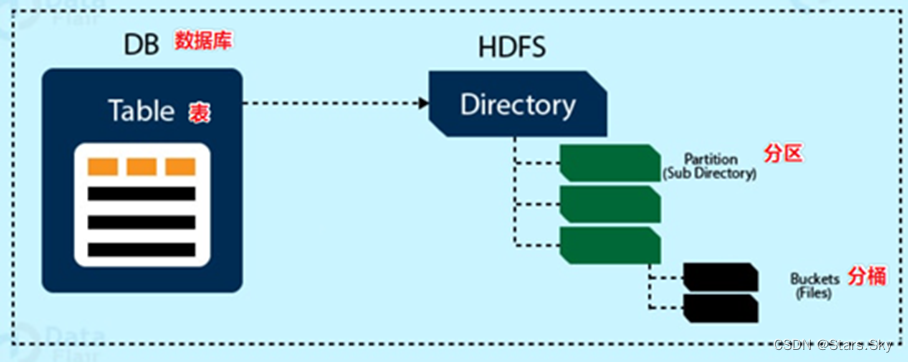
数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。Hive 的数据模型类似于 RDBMS 库表结构,此外还有自己特有模型。Hive 中的数据可以在粒度级别上分为三类:
-
Table 表
-
Partition 分区
-
Bucket 分桶
4.2 Databases 数据库
Hive 作为一个数据仓库,在结构上积极向传统数据库看齐,也分数据库(Schema),每个数据库下面有各自的表组成。默认数据库 default。
Hive 的数据都是存储在 HDFS 上的,默认有一个根目录,在 hive-site.xml 中,由参数hive.metastore.warehouse.dir 指定。默认值为 /user/hive/warehouse。因此,Hive 中的数据库在HDFS 上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db
比如,名为 test 的数据库存储路径为:/user/hive/warehouse/test.db
4.3 Tables 表
Hive 表与关系数据库中的表相同。Hive 中的表所对应的数据通常是存储在 HDFS 中,而表相关的元数据是存储在 RDBMS 中。
Hive 中的表的数据在 HDFS 上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db/tablename
比如 test 的数据库下 t_user 表存储路径为:/user/hive/warehouse/test.db/t_user
4.4 Partitions 分区
Partition 分区是 hive 的一种优化手段表。分区是指根据分区列(例如“日期 day”)的值将表划分为不同分区。这样可以更快地对指定分区数据进行查询。
分区在存储层面上的表现是:table 表目录下以子文件夹形式存在。一个文件夹表示一个分区。子文件命名标准:分区列=分区值
Hive 还支持分区下继续创建分区,所谓的多重分区。关于分区表的使用和详细介绍,后面模块会单独展开。
4.5 Buckets 分桶
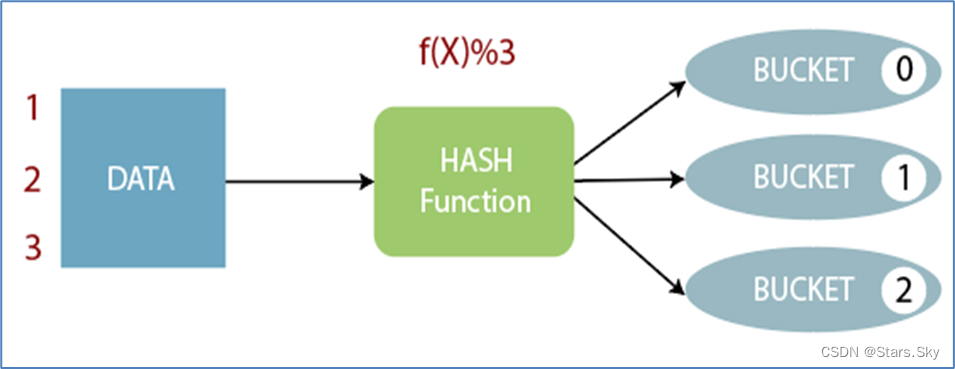
Bucket 分桶表是 hive 的一种优化手段表。分桶是指根据表中字段(例如“编号 ID”)的值,经过 hash 计算规则将数据文件划分成指定的若干个小文件。
分桶规则:hashfunc(字段) % 桶个数,余数相同的分到同一个文件。
分桶的好处是可以优化 join 查询和方便抽样查询。Bucket 分桶表在 HDFS 中表现为同一个表目录下数据根据 hash 散列之后变成多个文件。关于桶表以及分桶操作,后面模块会单独展开详细讲解。
五、Apache Hive 是要取代 MySQL 吗?
5.1 思考
- 从数据模型上来看 Hive 和 MySQL 非常相似,库,表字段之类的,难道 Hive 也是数据库?
- Hive 依赖 Hadoop,理论上可以无限存储,难道是大型数据库?取代 MySQL 的?
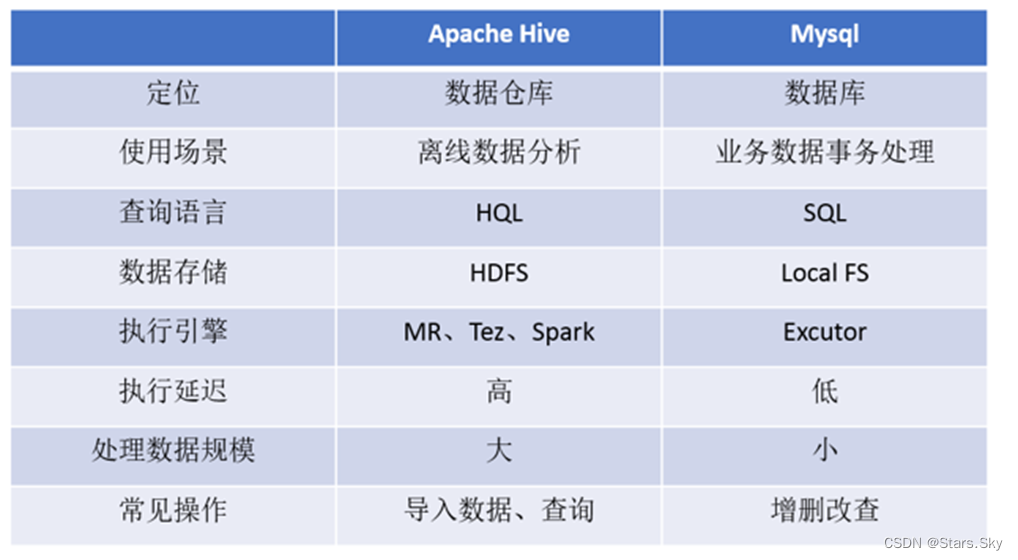
5.2 Hive 和 MySQL 对比
Hive虽然具有 RDBMS 数据库的外表,包括数据模型、SQL 语法都十分相似,但应用场景却完全不同。
Hive 只适合用来做海量数据的离线分析。Hive 的定位是数据仓库,面向分析的 OLAP 系统。因此时刻告诉自己,Hive 不是大型数据库,也不是要取代 MySQL 承担业务数据处理。
上一篇文章:大数据 Hive 数据仓库介绍_Stars.Sky的博客-CSDN博客