算法工程师在日常工作中大部分时间还是在和数据打交道。
诸如数据准备,数据清洗,特征分析(EDA) 等等。
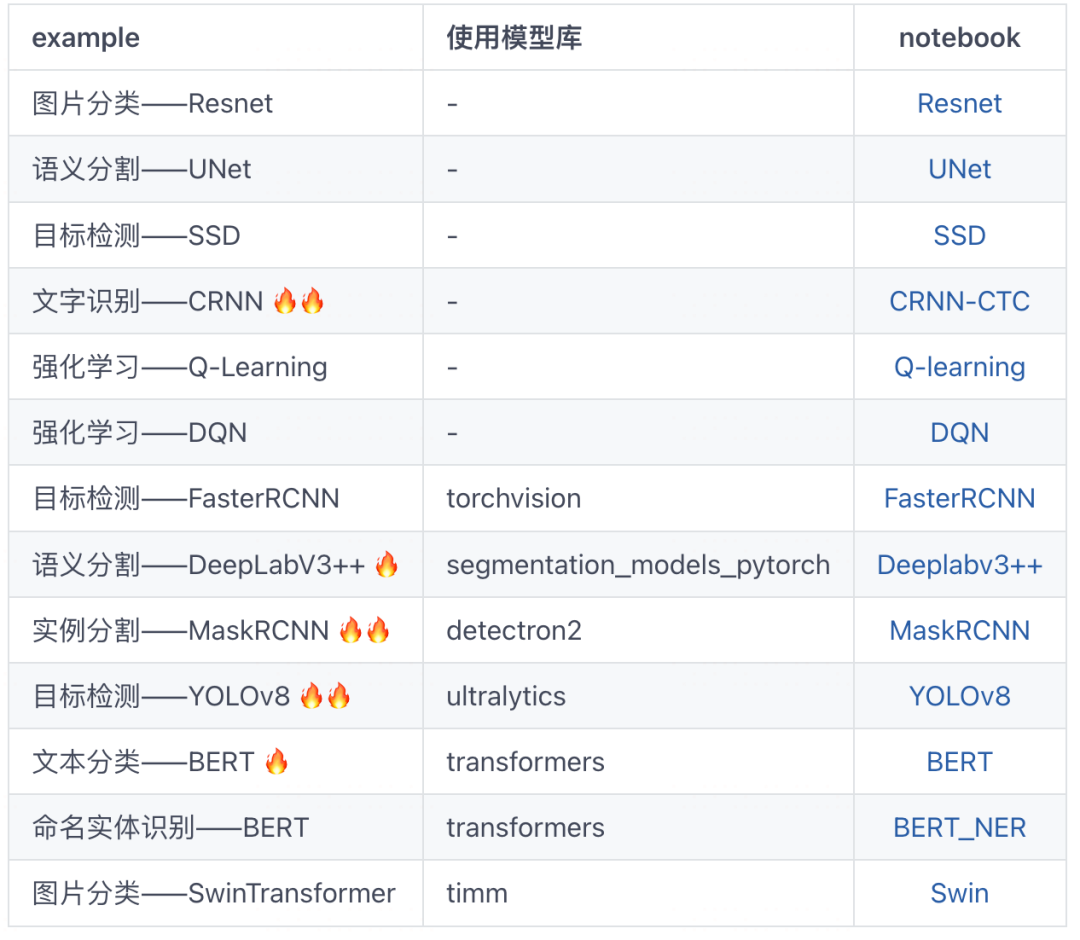
这里给大家介绍我非常喜爱的5个处理数据的小工具,
也是我个人使用比较高频的几个工具,相信可以解决大家的一些痛点。
1,一行代码根据关键词抓取百度图片 【数据准备】🔥🔥🔥
2,一行代码根据url获取图片 【数据准备】
3,一行代码合并多个数据集文件夹 【数据准备】
4,五行代码清洗数据集中的重复图片 【数据清洗】🔥🔥🔥
5,三行代码完成表格型数据的探索性分析 【特征分析】🔥🔥
这些工具都可以在梦中情炉🤗torchkeras中直接使用。😋😋
公众号算法美食屋后台回复关键词:torchkeras。获取本文notebook源码和更多有趣范例~
1,一行代码根据关键词抓取百度图片
在有些视觉任务场景下例如: 车牌OCR识别,红绿灯检测,猫的品种分类。根据关键词抓取百度图片可以帮助我们快速构建数据集。
from torchkeras.data import download_baidu_pictures
download_baidu_pictures(keyword='猫咪表情包', needed_pics_num=100, save_dir='cats')
#看几张试试
from pathlib import Path
from PIL import Image from ipywidgets import interact
files = [str(x) for x in Path('cats').rglob('*.jpg') if 'checkpoint' not in str(x)]
def browser_image(path):return Image.open(path)
interact(browser_image, path=files)

2,一行代码根据url获取图片
在很多应用场景下,图片数据都是以url的形式存在数据库中,使用以下函数可以快速将url转换成PIL中的Image
from torchkeras.data import download_image
img = download_image('https://pic1.zhimg.com/v2-10423b9e7bfccf690d7a0d16189029dd_1440w.jpg?source=d16d100b')
img
3,一行代码合并多个数据集文件夹
图像任务相关的数据集通常会整理成文件夹形式,例如yolo格式。有时候我们会以增量的形式不断地新做一些数据。
有没有什么办法可以快速地把新的数据集文件夹和老的数据集文件夹方便的合并呢?
#我们来手工模拟创建两个yolo格式的数据集(注,不限与yolo格式)
from pathlib import Path
for folder in ['ds1','ds2']:for tp in ['images','labels']:for part in ['train','val']:path = Path(folder)/tp/partpath.mkdir(parents=True, exist_ok=True)for i in range(3):if tp=='images':(path/f'{i}.jpeg').touch()else:(path/f'{i}.txt').touch()from torchkeras.data import merge_dataset_folders
merge_dataset_folders(from_folders=['ds1','ds2'],to_folder='ds_merge')before merge:
ds1: 12 files
ds2: 12 filesafter merge:
ds_merge: 24 files'ds_merge'4,五行代码清洗数据集中的重复图片
很多时候我们的数据集中可能会因为各种原因存在着一些重复图片。
如果在训练集和验证集有一些相同的图片,可能会导致验证集上评估指标被高估。
torchkeras继承了 fastdup这个库的图片分析和重复图片清理功能。
这个库会将 图片用卷积网络模型转换成 embedding向量。
并通过向量之间的余弦距离来判断两张图片是否(或者叫做相似度更好一些,越接近1越相似)
!pip install fastdupfrom torchkeras.data import ImageCleaner
cleaner = ImageCleaner(img_files = 'cats')
cleaner.run_summary(duplicate_similirity=0.99, outlier_percentile=0.02)
cleaner.vis_duplicates()cleaner.delete_duplicates()100%|██████████████████████████████████████████████████████████████████████████
██████████| 11/11 [00:00<00:00, 6646.12it/s]5,三行代码完成表格型数据的探索性分析 【特征分析】🔥🔥
from sklearn import datasets
from sklearn.model_selection import train_test_split
import pandas as pd breast = datasets.load_breast_cancer()
df = pd.DataFrame(breast.data,columns = breast.feature_names)
df["label"] = breast.target
dftrain,dftest = train_test_split(df,test_size = 0.3)from torchkeras.eda import pipeline
dfeda = pipeline(dftrain,dftest)
dfeda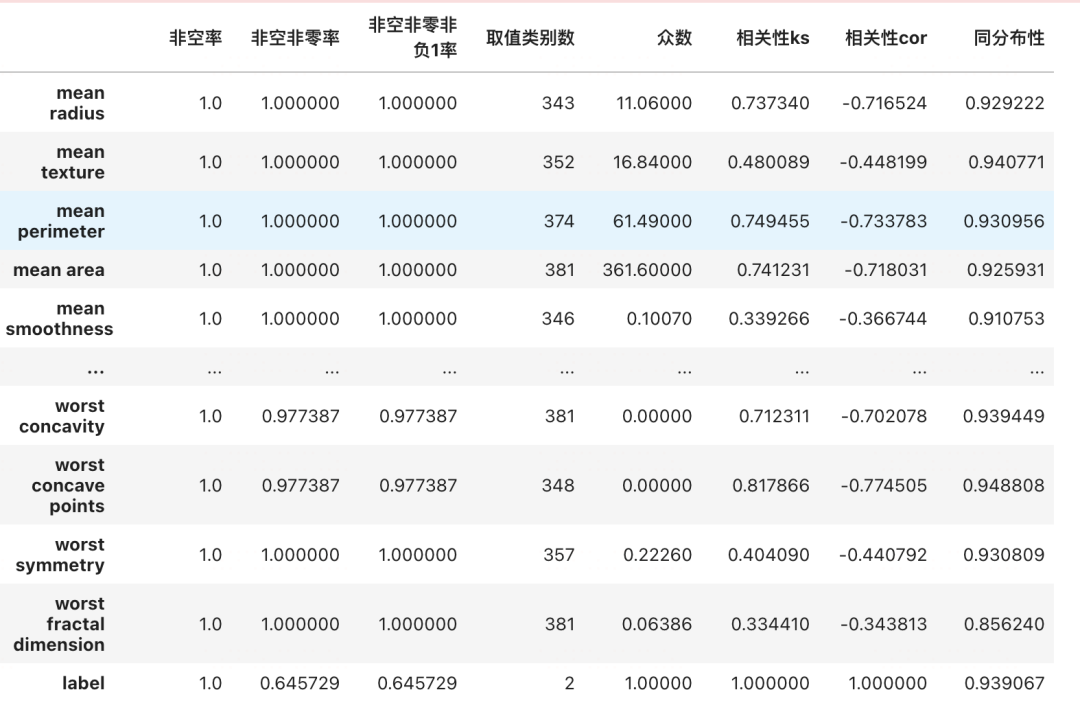
公众号算法美食屋后台回复关键词:torchkeras。获取本文notebook源码和更多有趣范例~