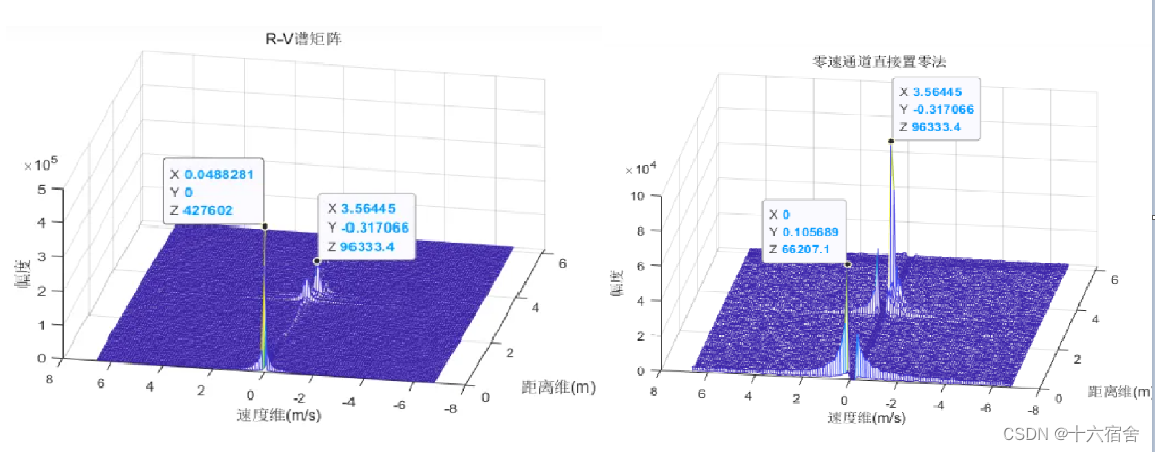
slide loss的主要作用是让模型更加关注难例,可以轻微的改善模型在难例检测上的效果
论文地址:https://arxiv.org/pdf/2208.02019.pdf
代码:GitHub - Krasjet-Yu/YOLO-FaceV2: YOLO-FaceV2: A Scale and Occlusion Aware Face Detector

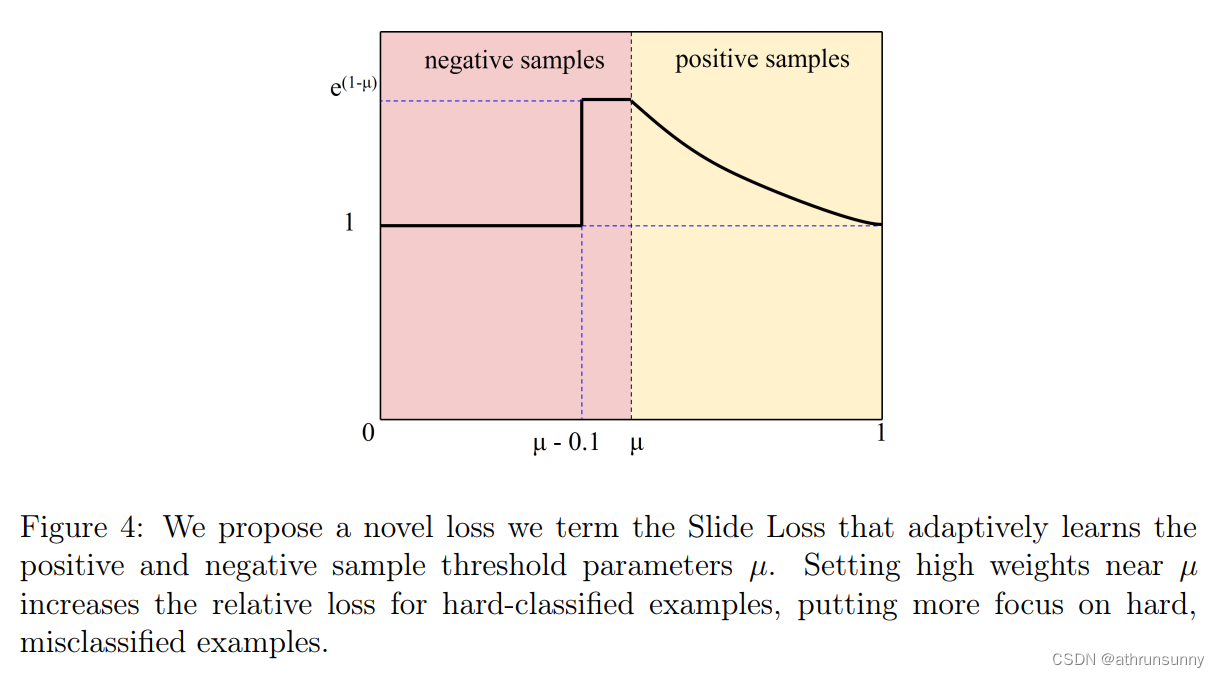
样本不平衡问题,即在大多数情况下,容易样本的数量很大,而困难样本相对稀疏,引起了很多关注。在本文的工作中,设计了一个看起来像“slide”的Slide Loss函数来解决这个问题。简单样本和困难样本之间的区别是基于预测框和ground truth 框的IoU大小。为了减少超参数,将所有边界框的 IoU 值的平均值作为阈值 µ,小于µ的取负样本,大于µ的取正样本。
然而,由于分类不明确,边界附近的样本往往会遭受较大的损失。希望模型能够学习优化这些样本,并更充分地使用这些样本来训练网络。然而,此类样本的数量相对较少。因此,尝试为困难样本分配更高的权重。首先通过参数μ将样本分为正样本和负样本。然后,通过加权函数Slide对边界处的样本进行强调,如图 4 所示。Slide加权函数可以表示为公式5。
在utils/loss.py增加
import math
class SlideLoss(nn.Module):def __init__(self, loss_fcn):super(SlideLoss, self).__init__()self.loss_fcn = loss_fcnself.reduction = loss_fcn.reductionself.loss_fcn.reduction = 'none' # required to apply SL to each elementdef forward(self, pred, true, auto_iou=0.5):loss = self.loss_fcn(pred, true)if auto_iou < 0.2:auto_iou = 0.2b1 = true <= auto_iou - 0.1a1 = 1.0b2 = (true > (auto_iou - 0.1)) & (true < auto_iou)a2 = math.exp(1.0 - auto_iou)b3 = true >= auto_ioua3 = torch.exp(-(true - 1.0))modulating_weight = a1 * b1 + a2 * b2 + a3 * b3loss *= modulating_weightif self.reduction == 'mean':return loss.mean()elif self.reduction == 'sum':return loss.sum()else: # 'none'return loss在data\hyps\hyp.scratch-low.yaml中增加
slide_ratio: 1 # >=1启用slide loss, <1关闭在utils/loss.py的ComputeLoss函数中做如下修改:
class ComputeLoss:# Compute lossesdef __init__(self, model, autobalance=False):super(ComputeLoss, self).__init__()device = next(model.parameters()).device # get model deviceh = model.hyp # hyperparameters# Define criteriaBCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets# slide lossself.slide_ratio = h['slide_ratio']if self.slide_ratio > 0:BCEcls, BCEobj = SlideLoss(BCEcls), SlideLoss(BCEobj)# Focal lossg = h['fl_gamma'] # focal loss gammaif g > 0:BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() moduleself.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, .02]) # P3-P7self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 indexself.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, model.gr, h, autobalancefor k in 'na', 'nc', 'nl', 'anchors':setattr(self, k, getattr(det, k))def __call__(self, p, targets): # predictions, targets, modeldevice = targets.devicelcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)lrepBox, lrepGT = torch.zeros(1, device=device), torch.zeros(1, device=device)tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets# Lossesfor i, pi in enumerate(p): # layer index, layer predictionsb, a, gj, gi = indices[i] # image, anchor, gridy, gridxtobj = torch.zeros_like(pi[..., 0], device=device) # target objn = b.shape[0] # number of targetsif n:ps = pi[b, a, gj, gi] # prediction subset corresponding to targets# Regressionpxy = ps[:, :2].sigmoid() * 2. - 0.5pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]pbox = torch.cat((pxy, pwh), 1) # predicted boxiou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)auto_iou = iou.mean()lbox += (1.0 - iou).mean() # iou loss# Objectnesstobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio# Classificationif self.nc > 1: # cls loss (only if multiple classes)t = torch.full_like(ps[:, 5:], self.cn, device=device) # targetst[range(n), tcls[i]] = self.cpif self.slide_ratio > 0:lcls += self.BCEcls(ps[:, 5:], t, auto_iou) # BCEelse:lcls += self.BCEcls(ps[:, 5:], t) # BCE# Append targets to text file# with open('targets.txt', 'a') as file:# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]if self.slide_ratio > 0 and n:obji = self.BCEobj(pi[..., 4], tobj, auto_iou)else:obji = self.BCEobj(pi[..., 4], tobj)lobj += obji * self.balance[i] # obj lossif self.autobalance:self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()if self.autobalance:self.balance = [x / self.balance[self.ssi] for x in self.balance]lbox *= self.hyp['box']lobj *= self.hyp['obj']lcls *= self.hyp['cls']bs = tobj.shape[0] # batch sizeloss = lbox + lobj + lclsreturn loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()主要修改如下:
1、__init__中增加
# slide lossself.slide_ratio = h['slide_ratio']if self.slide_ratio > 0:BCEcls, BCEobj = SlideLoss(BCEcls), SlideLoss(BCEobj)2、计算完iou后增加
auto_iou = iou.mean()3、在类别损失函数上
if self.slide_ratio > 0:lcls += self.BCEcls(ps[:, 5:], t, auto_iou) # BCEelse:lcls += self.BCEcls(ps[:, 5:], t) # BCE4、前背景损失函数上
if self.slide_ratio > 0 and n:obji = self.BCEobj(pi[..., 4], tobj, auto_iou)else:obji = self.BCEobj(pi[..., 4], tobj)![2023年“羊城杯”网络安全大赛 决赛 AWDP [Break+Fix] Web方向题解wp 全](https://img-blog.csdnimg.cn/img_convert/71ead415ff7eb0be14898eb0441a489f.png)