目录
创建两个表格
location 表格编辑
store_info 表格编辑
---- SELECT ----
---- DISTINCT ----
---- WHERE ----
---- AND OR ----
---- IN ----
---- BETWEEN ----
---- 通配符 ----
---- LIKE ----
---- ORDER BY ----
---- 函数 ----
---- GROUP BY ----
---- HAVING ----
---- 别名 ----
---- 子查询 ----
---- EXISTS ----
---- 连接查询 ----
内连接一:
编辑
内连接二:
编辑
创建两个表格
use awsl;
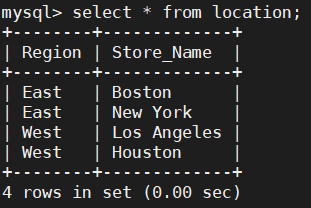
create table location (Region char(20),Store_Name char(20));
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');location 表格
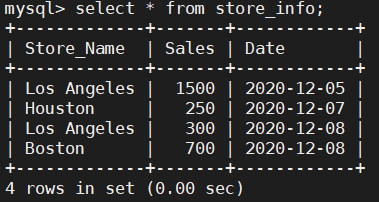
create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');store_info 表格
---- SELECT ----
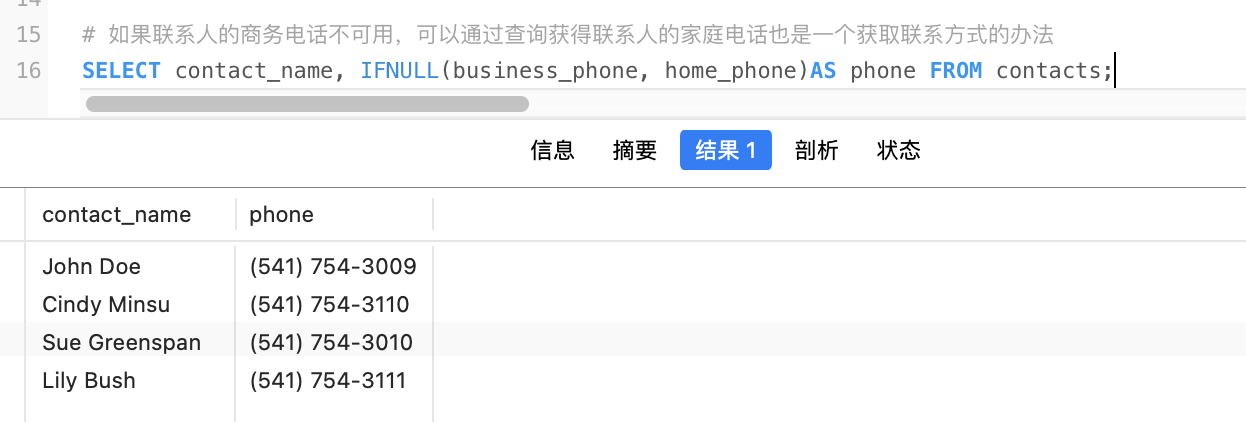
显示表格中一个或数个字段的所有数据记录
语法:SELECT "字段" FROM "表名";
SELECT Store_Name FROM store_info;
---- DISTINCT ----
不显示重复的数据记录
语法:SELECT DISTINCT "字段" FROM "表名";
SELECT DISTINCT Store_Name FROM store_info;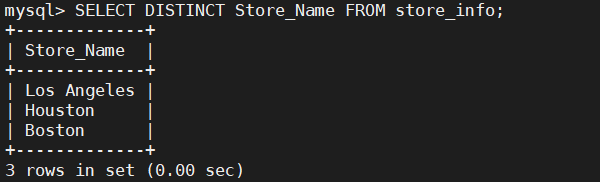
---- WHERE ----
有条件查询
语法:SELECT "字段" FROM "表名" WHERE "条件";
SELECT Store_Name FROM store_info WHERE Sales > 1000;
---- AND OR ----
且 或
语法:SELECT "字段" FROM "表名" WHERE "条件1" {[AND|OR] "条件2"} ;
SELECT Store_Name FROM store_info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);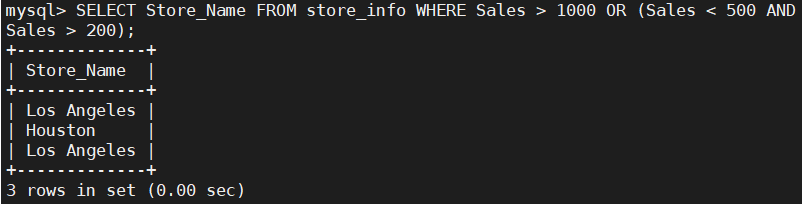
---- IN ----
显示已知的值的数据记录
语法:SELECT "字段" FROM "表名" WHERE "字段" IN ('值1', '值2', ...);
SELECT * FROM store_info WHERE Store_Name IN ('Los Angeles', 'Houston');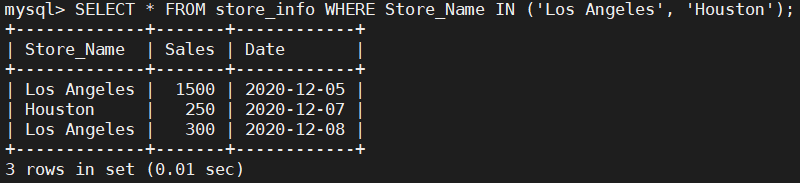
---- BETWEEN ----
显示两个值范围内的数据记录
语法:SELECT "字段" FROM "表名" WHERE "字段" BETWEEN '值1' AND '值2';
SELECT * FROM store_info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';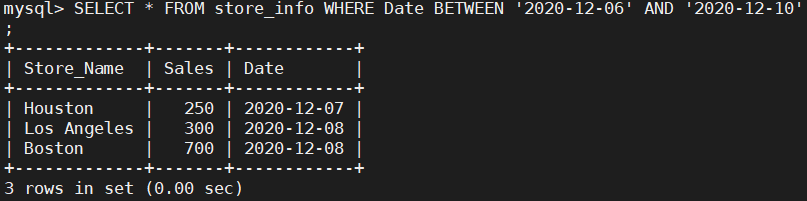
---- 通配符 ----
通常通配符都是跟 LIKE 一起使用的
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%' :所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ' :所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%' :所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%' : 所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
---- LIKE ----
匹配一个模式来找出我们要的数据记录
语法:SELECT "字段" FROM "表名" WHERE "字段" LIKE {模式};
SELECT * FROM store_info WHERE Store_Name like '%os%';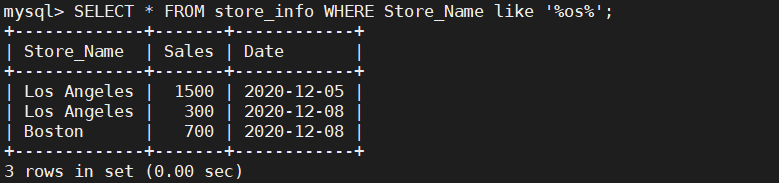
---- ORDER BY ----
按关键字排序
语法:SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。
SELECT Store_Name,Sales,Date FROM store_info ORDER BY Sales DESC;
---- 函数 ----
数学函数:
abs(x) 返回 x 的绝对值
rand( ) 返回 0 到 1 的随机数
mod(x,y) 返回 x 除以 y 以后的余数
power(x,y) 返回 x 的 y 次方
round(x) 返回离 x 最近的整数
round(x,y) 保留 x 的 y 位小数四舍五入后的值
sqrt(x) 返回 x 的平方根
truncate(x,y) 返回数字 x 截断为 y 位小数的值
ceil(x) 返回大于或等于 x 的最小整数
floor(x) 返回小于或等于 x 的最大整数
greatest(x1,x2...) 返回集合中最大的值,也可以返回多个字段的最大的值
least(x1,x2...) 返回集合中最小的值,也可以返回多个字段的最小的值
SELECT abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
SELECT round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);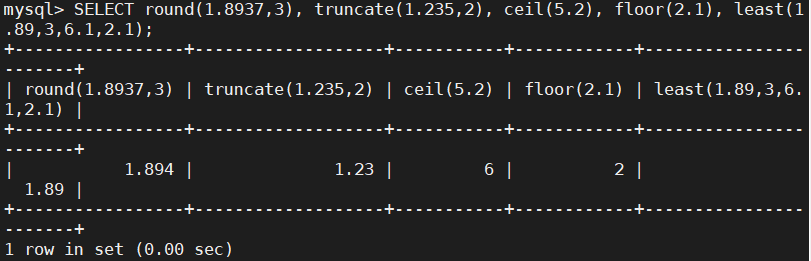 聚合函数:
聚合函数:
avg() 返回指定列的平均值
count() 返回指定列中非 NULL 值的个数
min() 返回指定列的最小值
max() 返回指定列的最大值
sum(x) 返回指定列的所有值之和SELECT avg(Sales) FROM store_info;
SELECT count(Store_Name) FROM store_info;
SELECT count(DISTINCT Store_Name) FROM store_info;
SELECT max(Sales) FROM store_info;
SELECT min(Sales) FROM store_info;
SELECT sum(Sales) FROM store_info;
City 表格 
SELECT count(name) FROM city;
SELECT count(*) FROM city;
#count(*) 包括了所有的列的行数,在统计结果的时候,不会忽略列值为 NULL
#count(列名) 只包括列名那一列的行数,在统计结果的时候,会忽略列值为 NULL 的行
字符串函数:
trim() 返回去除指定格式的值
concat(x,y) 将提供的参数 x 和 y 拼接成一个字符串
substr(x,y) 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同
substr(x,y,z) 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串
length(x) 返回字符串 x 的长度
replace(x,y,z) 将字符串 z 替代字符串 x 中的字符串 y
upper(x) 将字符串 x 的所有字母变成大写字母
lower(x) 将字符串 x 的所有字母变成小写字母
left(x,y) 返回字符串 x 的前 y 个字符
right(x,y) 返回字符串 x 的后 y 个字符
repeat(x,y) 将字符串 x 重复 y 次
space(x) 返回 x 个空格
strcmp(x,y) 比较 x 和 y,返回的值可以为-1,0,1
reverse(x) 将字符串 x 反转
SELECT concat(Region, Store_Name) FROM location WHERE Store_Name = 'Boston';
#如sql_mode开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';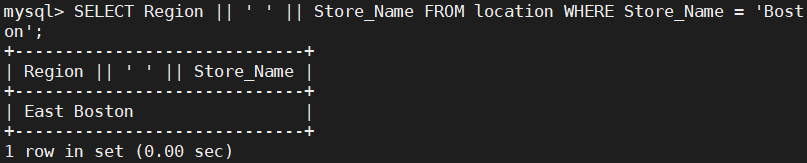
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';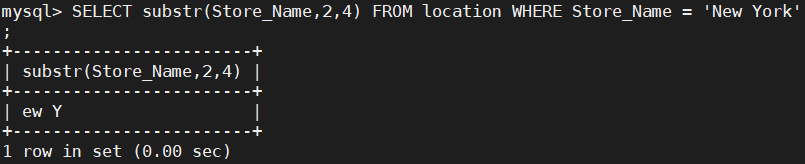
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
SELECT TRIM(LEADING 'Ne' FROM 'New York');
SELECT Region,length(Store_Name) FROM location;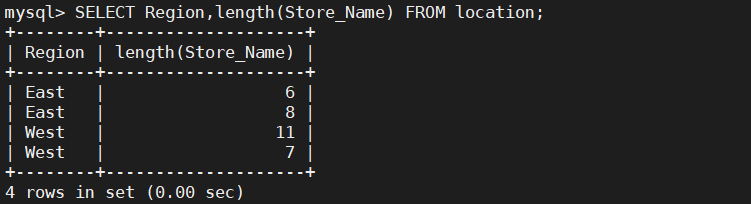
SELECT REPLACE(Region,'ast','astern')FROM location;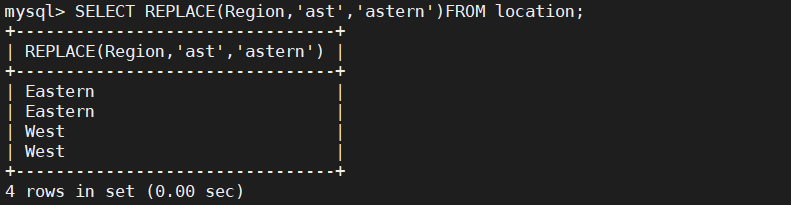
---- GROUP BY ----
对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY 有一个原则,凡是在 GROUP BY 后面出现的字段,必须在 SELECT 后面出现;
凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面
语法:SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;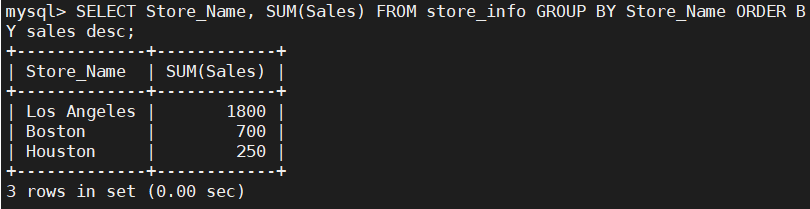
---- HAVING ----
用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
语法:SELECT "字段1", SUM("字段2") FROM "表格名" GROUP BY "字段1" HAVING (函数条件);
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM(Sales) > 1500;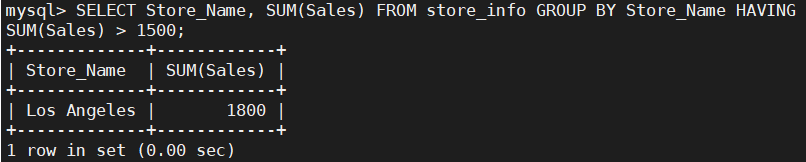
---- 别名 ----
字段別名 表格別名
语法:SELECT "表格別名"."字段1" [AS] "字段別名" FROM "表格名" [AS] "表格別名";
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;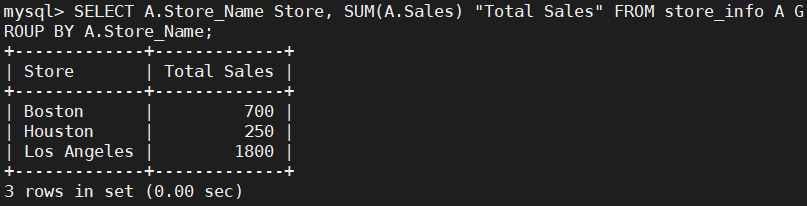
---- 子查询 ----
连接表格
在WHERE 子句或 HAVING 子句中插入另一个 SQL 语句
语法:SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] #外查询
(SELECT "字段1" FROM "表格2" WHERE "条件"); #内查询
#可以是符号的运算符,例如 =、>、<、>=、<= ;也可以是文字的运算符,例如 LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM store_info WHERE Store_Name IN (SELECT Store_Name FROM location WHERE Region = 'West');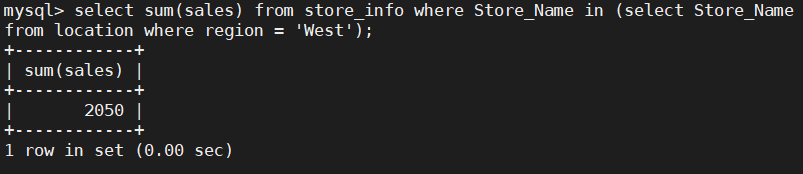
SELECT SUM(A.Sales) FROM store_info A WHERE A.Store_Name IN (SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);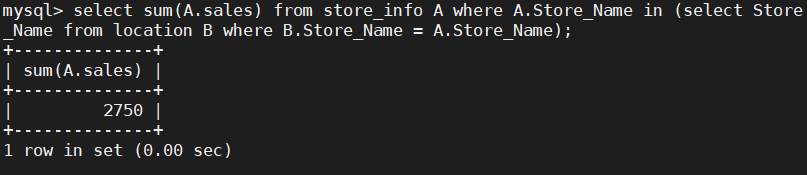
---- EXISTS ----
用来测试内查询有没有产生任何结果,类似布尔值是否为真
#如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
语法:SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');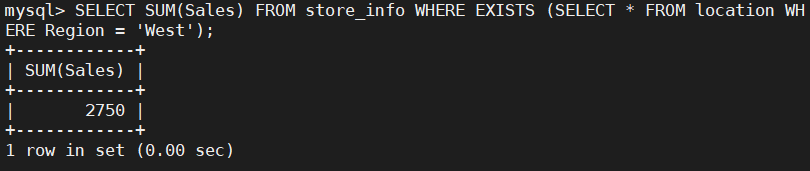
---- 连接查询 ----
location 表格

UPDATE store_info SET store_name='Washington' WHERE sales=300;Store_Info 表格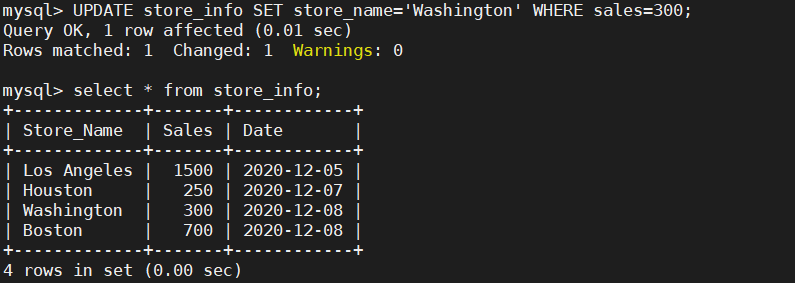
inner join(内连接):只返回两个表中联结字段相等的行
left join(左连接): 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接): 返回包括右表中的所有记录和左表中联结字段相等的记录
SELECT * FROM location A RIGHT JOIN store_info B on A.Store_Name = B.Store_Name ;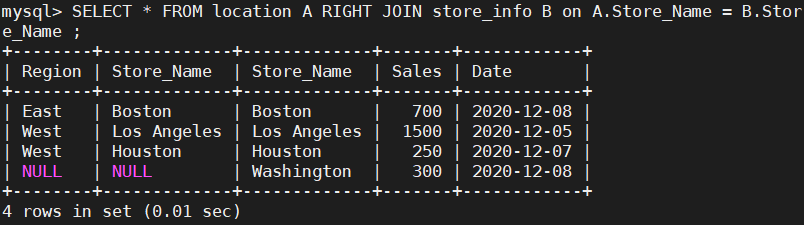
SELECT * FROM location A LEFT JOIN Store_Info B on A.Store_Name = B.Store_Name ;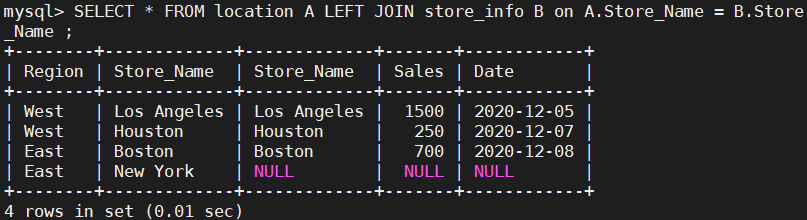
内连接一:
SELECT * FROM location A INNER JOIN store_info B on A.Store_Name = B.Store_Name ;
内连接二:
SELECT * FROM location A, store_info B WHERE A.Store_Name = B.Store_Name;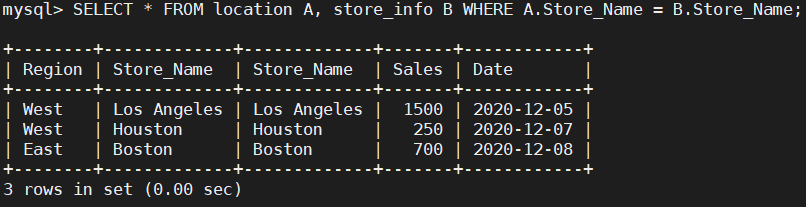
SELECT A.Region REGION, SUM(B.Sales) SALES FROM location A, store_info B WHERE A.Store_Name = B.Store_Name GROUP BY REGION;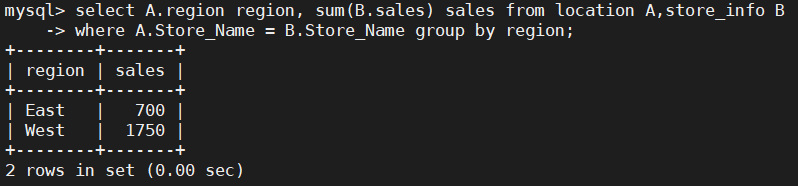
自我连接,算排名:
+----------+-------+
| name | score |
+----------+-------+
| lisi | 100 |
| zhaoliu | 90 |
| wangwu | 80 |
| zhangsan | 70 |
+----------+-------+
分组汇总后统计 score 字段的值是比自己本身的值小的以及 score 字段 和 name 字段都相同的数量
SELECT A.name, A.score, count(B.score) rank FROM class A, class B
WHERE A.score < B.score OR (A.score = B.score AND A.Name = B.Name)
GROUP BY A.name, A.score ORDER BY rank;
---- CREATE VIEW ----视图,可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
语法:CREATE VIEW "视图表名" AS "SELECT 语句";
CREATE VIEW V_REGION_SALES AS SELECT A.Region REGION,SUM(B.Sales) SALES FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION;
SELECT * FROM V_REGION_SALES;
DROP VIEW V_REGION_SALES;
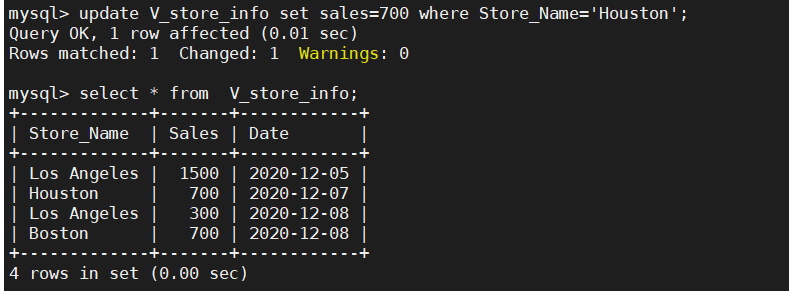
注:视图既可以修改也修改不了,视情况而定,当视图表保存的是原表数据就可以修改,select语句修改过的数据不行。
---- UNION ----联集,将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
UNION :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
UNION ALL :将生成结果的数据记录值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM Store_Info;
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM Store_Info;
---- 交集值 ----取两个SQL语句结果的交集
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
#取两个SQL语句结果的交集,且没有重复
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
SELECT A.Store_Name FROM (SELECT B.Store_Name FROM location B INNER JOIN Store_Info C ON B.Store_Name = C.Store_Name) A
GROUP BY A.Store_Name;
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM Store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;
---- 无交集值 ----显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NULL;
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM Store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) = 1;
---- CASE ----是 SQL 用来做为 IF-THEN-ELSE 之类逻辑的关键字
语法:
SELECT CASE ("字段名")
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"
...
[ELSE "结果N"]
END
FROM "表名";
# "条件" 可以是一个数值或是公式。 ELSE 子句则并不是必须的。
SELECT Store_Name, CASE Store_Name
WHEN 'Los Angeles' THEN Sales * 2
WHEN 'Boston' THEN 2000
ELSE Sales
END
"New Sales",Date
FROM Store_Info;
#"New Sales" 是用于 CASE 那个字段的字段名。
---- 空值(NULL) 和 无值('') 的区别 ----
1.无值的长度为 0,不占用空间的;而 NULL 值的长度是 NULL,是占用空间的。
2.IS NULL 或者 IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是无值的。
3.无值的判断使用=''或者<>''来处理。<> 代表不等于。
4.在通过 count()指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
City 表格
+----------+
| name |
|----------|
| beijing |
| nanjing |
| shanghai |
| <null> |
| <null> |
| shanghai |
| |
+----------+
SELECT length(NULL), length(''), length('1');
SELECT * FROM City WHERE name IS NULL;
SELECT * FROM City WHERE name IS NOT NULL;
SELECT * FROM City WHERE name = '';
SELECT * FROM City WHERE name <> '';
SELECT COUNT(*) FROM City;
SELECT COUNT(name) FROM City;
---- 正则表达式 ----
匹配模式 描述 实例
^ 匹配文本的开始字符 ‘^bd’ 匹配以 bd 开头的字符串
$ 匹配文本的结束字符 ‘qn$’ 匹配以 qn 结尾的字符串
. 匹配任何单个字符 ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串
* 匹配零个或多个在它前面的字符 ‘fo*t’ 匹配 t 前面有任意个 o
+ 匹配前面的字符 1 次或多次 ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串
字符串 匹配包含指定的字符串 ‘clo’ 匹配含有 clo 的字符串
p1|p2 匹配 p1 或 p2 ‘bg|fg’ 匹配 bg 或者 fg
[...] 匹配字符集合中的任意一个字符 ‘[abc]’ 匹配 a 或者 b 或者 c
[^...] 匹配不在括号中的任何字符 ‘[^ab]’ 匹配不包含 a 或者 b 的字符串
{n} 匹配前面的字符串 n 次 ‘g{2}’ 匹配含有 2 个 g 的字符串
{n,m} 匹配前面的字符串至少 n 次,至多m 次 ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次
语法:SELECT "字段" FROM "表名" WHERE "字段" REGEXP {模式};
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'os';
SELECT * FROM Store_Info WHERE Store_Name REGEXP '^[A-G]';
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'Ho|Bo';