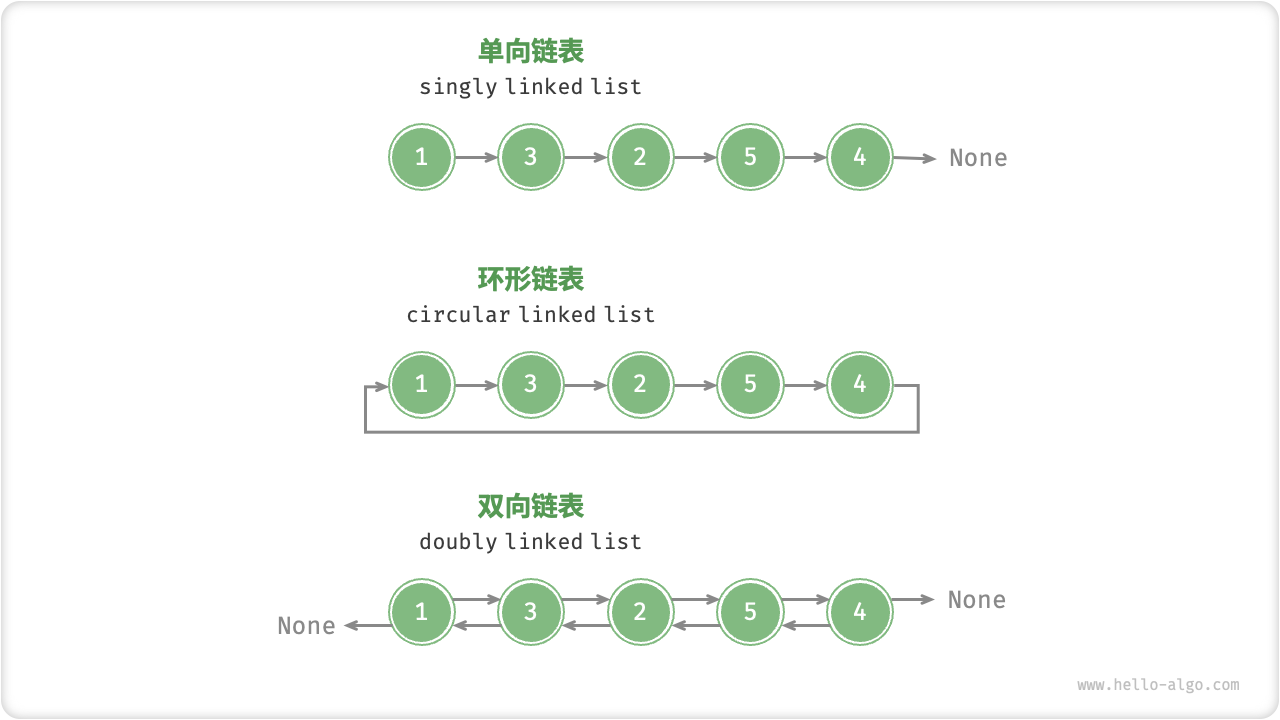
目录
1. 进程程序替换
1.1 程序替换原理
1.2 execl 接口
1.3 execv + execlp + execvp
1.4 exec 调各种程序
1.5 execle 接口
2. 实现简单的shell
2.1 打印提示和获取输入
2.2 拆开输入的命令和选项
2.3 创建进程和程序替换执行命令
2.4 内建命令实现路径切换
2.5 myshell里放置环境变量
3. 传上git(附完整代码)
4. 本篇完。
1. 进程程序替换
首先我们要知道,创建子进程的目的是什么?无非就是两种目的:
- 想让子进程执行父进程代码的一部分。
- 想让子进程执行一个全新的代码。
我们之前所写的程序,子进程都是在执行父进程代码的一部分,而要想让子进程执行全新的代码,就需要进行进程程序替换。
曾经创建的子进程和父进程是代码共享的,通过 if-else 同时执行(写时拷贝),经过同一个变量通过虚拟地址转化为物理地址,让父子进程得到不同的值,从而判断出来让父子进程执行不同的代码片段。这是我们之前的操作。
如果我们想让创建出来的子进程,执行全新的程序呢?
之前我们通过写时拷贝,让子进程和父进程在数据上互相解耦,保证独立性。如果想让子进程和父进程彻底分开,让子进程彻彻底底地执行一个全新的程序,我们就需要 进程的程序替换。
为什么要进行程序替换?因为我们想让我们的子进程执行一个全新的程序。
那为什么要让子进程执行新的程序呢?
我们一般在服务器设计的时候(Linux 编程)的时候,往往需要子进程干两件种类的事情:
让子进程执行父进程的代码片段(服务器代码…)
想让子进程执行磁盘中一个全新的程序(shell、想让客户端执行对应的程序、通过我们的进程执行其他人写的进程代码、C/C++ 程序调用别人写的 C/C++/Python/Shell/Php/Java...)
1.1 程序替换原理
程序替换原理:用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数 以执行另一个程序。当进程调用一种exec函数时,
该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。
调用exec并不创建新进程,所以调用exec前后该进程的id并未改变。
- 将磁盘中的内存,加载入内存结构。
- 重新建立页表映射,设执行程序替换,就重新建立谁的映射(下图为子进程建立)。
- 效果:让父进程和子进程彻底分离,并让子进程执行一个全新的程序。
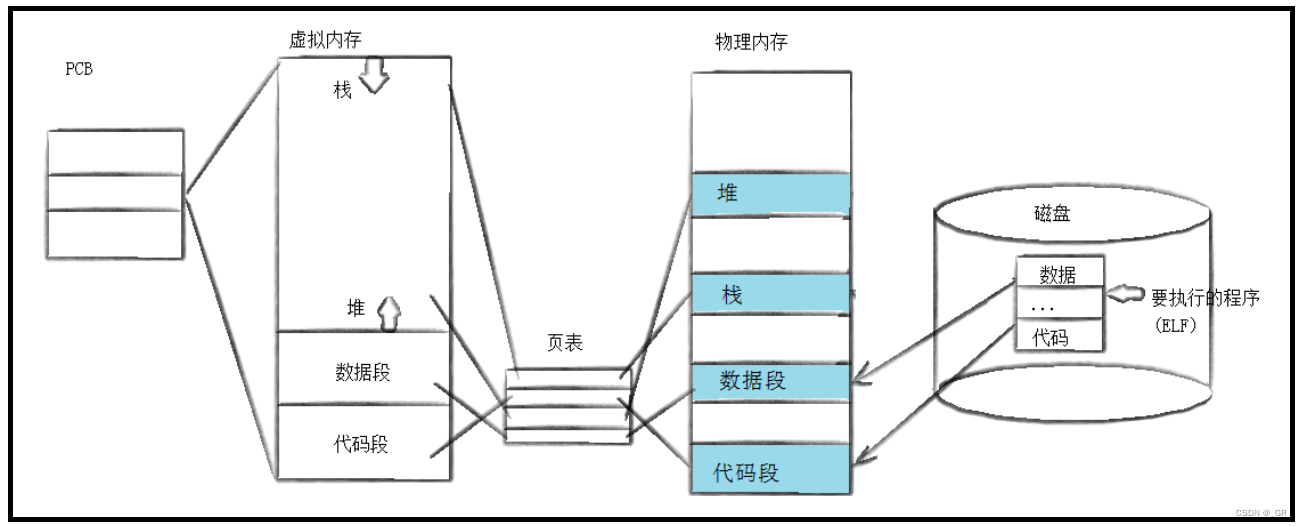
这里左边基本不发生变化,右边将新的磁盘上的程序加载到内存,并和当前进程的页表,重新建立映射,这就是进程替换。
这个过程有没有创建新的进程呢?
没有,因为子进程的内核数据结构根本没变,只是重新建立了虚拟的物理地址之间的映射关系。内核数据结构没有发生任何变化,包括子进程的pid都不变,说明压根没有创建新进程。
1.2 execl 接口
我们要调用接口,让操作系统去完成这个工作 —— 系统调用。
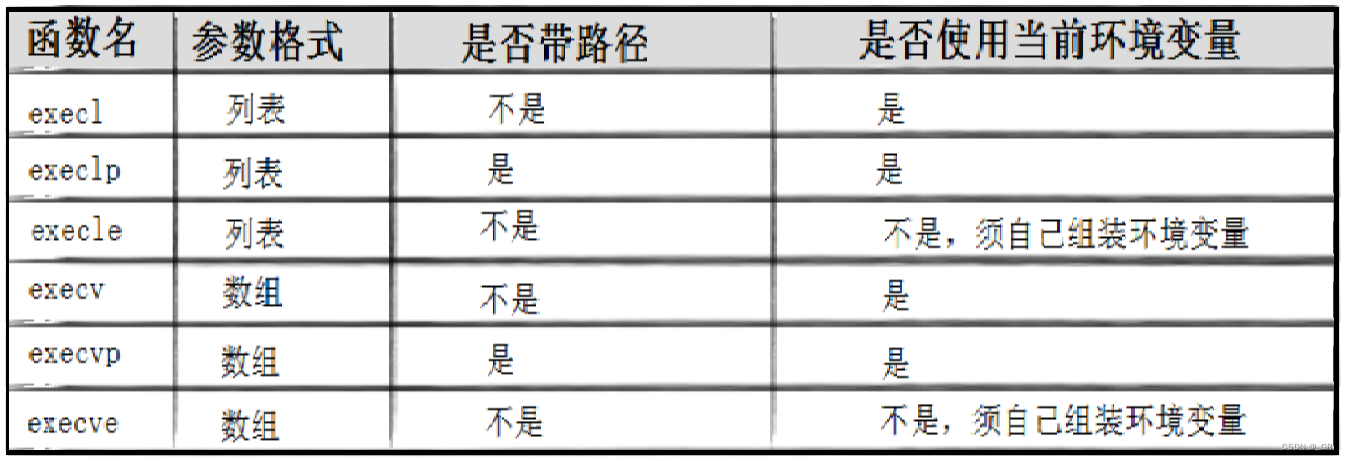
其实有六种以exec开头的接口函数(还有一个是系统调用接口),统称exec函数:
#include <unistd.h>int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char* file, char* const argv[], char* const envp[]);int execve(const char *path, char *const argv[], char *const envp[]);l(list) : 表示参数采用列表
v(vector) : 参数用数组
p(path) : 有p自动搜索环境变量PATH
e(env) : 表示自己维护环境变量
这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回。
如果调用出错则返回-1,所以exec函数只有出错的返回值而没有成功的返回值。
如何进行程序替换?先从第一个 execl 这个接口讲,看看它怎么跑的。
如果我们想执行一个全新的程序,我们需要做几件事情:
(要执行一个全新的程序,以我们目前的认识,程序的本质就是磁盘上的文件)
第一件事情:先找到这个程序在哪里。
第二件事情:程序可能携带选项进行执行(也可以不携带)。
明确告诉 OS,我想怎么执行这个程序?要不要带选项。
简单来说就是:① 程序在哪? ② 怎么执行?
所以,execl 这个接口就必须得把这两个功能都体现出来。
它的第一个参数是 path,属于路径。
参数 const char* arg, ... 中的 ... 表示可变参数,命令行怎么写(ls, -l, -a) 这个参数就怎么填。ls, -l, -a 最后必须以 NULL 结尾,表示 "如何执行程序的" 参数传递完毕。
代码演示:
这里先创建linux_11目录,进入目录写Makefil和test.c:

编译运行:

代码运行后,自动执行了ls -l -a 命令,但是为什么没有打印第10行的代码?
因为 一旦替换成功,是会将当前进程的代码和数据全部替换的。
所以自然后面的 printf 代码早就被替换了,这意味着该代码不复存在了。
因为在程序替换的时候,就已经把对应进程的代码和数据替换掉了。
而第一个 printf 执行了的原因自然是因为程序还没有执行替换,
所以,这里的程序替换函数用不用判断返回值?为什么?
一旦替换成功,还会执行返回语句吗?返回值有意义吗? 没有意义。
程序替换不用判断返回值,因为只要成功了,就不会有返回值。 而失败的时候,必然会继续向后执行。执行了后面的代码,一定是替换失败了;只要有返回值,就一定是替换失败了。
在上面的代码基础上引入进程创建:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>int main()
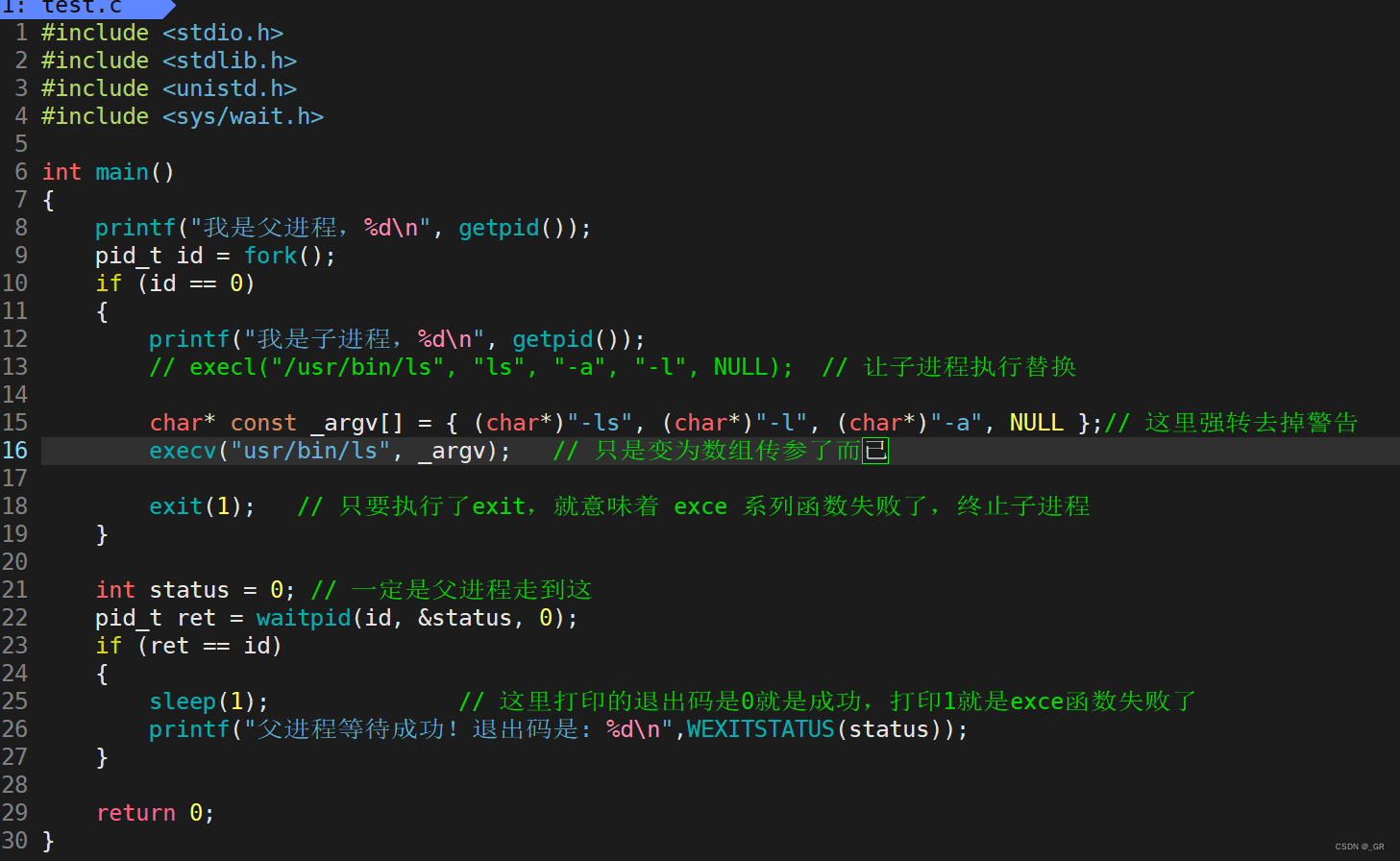
{printf("我是父进程,%d\n", getpid());pid_t id = fork();if (id == 0) {printf("我是子进程,%d\n", getpid());execl("/usr/bin/ls", "ls", "-a", "-l", NULL); // 让子进程执行替换exit(1); // 只要执行了exit,就意味着 excel 系列函数失败了,终止子进程}int status = 0; // 一定是父进程走到这pid_t ret = waitpid(id, &status, 0);if (ret == id) {sleep(1); printf("父进程等待成功!退出码是: %d\n",WEXITSTATUS(status));}return 0;
}
编译运行:
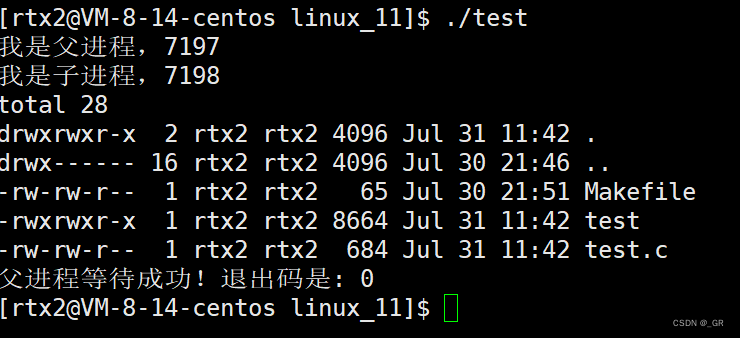
成功执行代码,父进程也等待成功了。这里的子进程没有执行父进程的代码,执行了自己的程序。
子进程执行程序替换,会不会影响父进程呢?不会,因为进程具有独立性。
为什么?子进程是如何做到代码和数据做分离的呢?
之前说过:fork 之后父子是共享的,如果要替换新的程序我能理解把新的程序的代码加载到内存里,我的子进程新的代码程序出来之后发生数据的写时拷贝,生成新的数据段。
不是说代码是共享的吗?我们该如何去理解呢?
当程序替换的时候,我们可以理解成 —— 代码和数据都发生了写时拷贝,完成了父子分离。
1.3 execv + execlp + execvp
前面介绍的六种以exec开头的接口函数(还有一个是系统调用接口),统称exec函数:
#include <unistd.h>int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char* file, char* const argv[], char* const envp[]);int execve(const char *path, char *const argv[], char *const envp[]);l(list) : 表示参数采用列表
v(vector) : 参数用数组
p(path) : 有p自动搜索环境变量PATH
e(env) : 表示自己维护环境变量
这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回。
如果调用出错则返回-1,所以exec函数只有出错的返回值而没有成功的返回值。
刚才我们学会了 execl 接口,我们下面开始学习更多的 exec 接口!它们都是用来替换的。
下面我们先来讲解一下和 execl 很近似的 execv:
int execl(const char *path, const char *arg, ...);int execv(const char* path, char* const argv[]);path 参数和 execl 一样,关注的都是 "如何找到"
argv[ ] 参数关注的是 "如何执行",是个指针数组,放 char* 类型,指向一个个字符串。
大家在命令行上 $ ls -a -l ,在 execl 里我们是这么传的: "ls", "-a", "-l", NULL 。
所以 execv 和 execl 只有传参方式的区别,一个是可变参数列表 (l),一个是指针数组 (v)。
值得注意的是,在构建 argv[] 的时,结尾仍然是要加上 NULL!
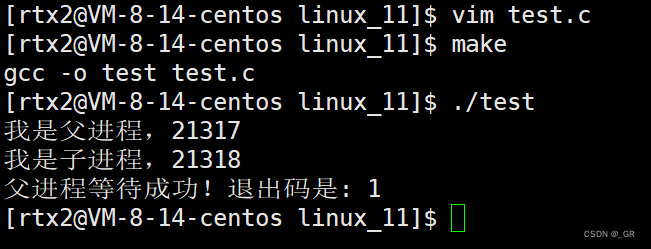
编译运行:
下面再用一下execlp函数:
int execl(const char *path, const char *arg, ...);int execlp(const char *file, const char *arg, ...);execlp,它的作用和 execv、execl 是一样的,它的作用也是执行一个新的程序。
仍然是需要两步:① 找到这个程序 ② 告诉我怎么执行
第一个参数 file 也是 "你想执行什么程序",第二个参数 arg 是 "如何去执行它"。
所以这一块的参数传递,和 execl 是一样的,唯一的区别是比 execl 多了一个 p!
我们执行指令的时候,默认的搜索路径在环境变量 中,所以这个 p 的意思是环境变量。
这意味着:执行 execlp 时,会直接在环境变量中找,不用去输路径了,只要程序名即可。
我们上面例子中的代码,无论是 execl 还是 execv,执行程序都得带上路径。
而 execlp 可以不带路径,只说出你要执行哪一个程序(这个程序应该在环境变量中有):

编译运行:
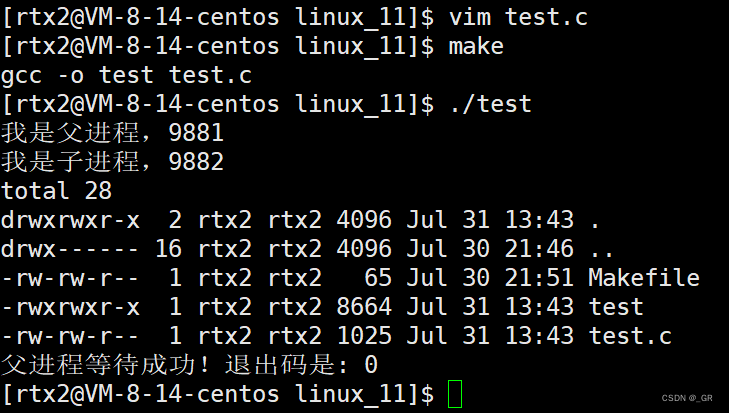
里出现的两个 ls 含义是不一样的,是不可以省略的,第一个参数是 "供系统去找你是谁的",后面的一堆全代表的是 "你想怎么去执行它" 。
现在讲了第1和2和4个,现在讲第5个execvp
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
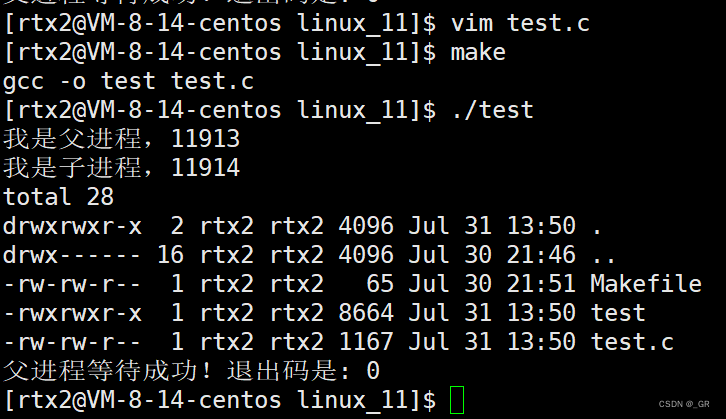
int execve(const char *path, char *const argv[], char *const envp[]);execvp 也是带 p 的,执行 execvp 时,会直接在环境变量中找,只要程序名即可。
简单来说就是 execv 的带 p 版本,将命令行参数字符串,统一放入数组中即可完成调用。

编译运行:
1.4 exec 调各种程序
目前上面子进程执行的程序,全部都是系统命令,如果我们要执行自己写的 C/C++ 程序呢?
如果我们要执行其他语言写的程序呢?
我们前几章写的 Makefile 文件只能形成一个可执行程序,现在我们学习如何形成多个。
比如,如果我们想一口气形成 2 个 可执行程序:
假设有两个可执行程序:test.c 和 test2.cpp 我们期望用 test.c 调用 test2.cpp:

也就是 C 语言的可执行程序调用 C++ 的可执行程序,我们先来设计一下 Makefile。
我们需要在前面添加 .PHONY:all ,让伪目标 all 依赖 mytest 和 test2。
如果不这样做,直接写,默认生成的是 test2,轮不到后面的 mytest。
且 Makefile 默认也只能形成一个可执行程序,想要形成多个就需要用到 all 了:

make一下:

Makefile 搞定了,现在我想用我的 test.c 去调用 test2 这个程序,如何做呢?
我们先 pwd 获取得到 test2.cpp 的绝对路径:(调用时在路径最后在加上test2)

通过使用 execl() 来调用自己写的程序:
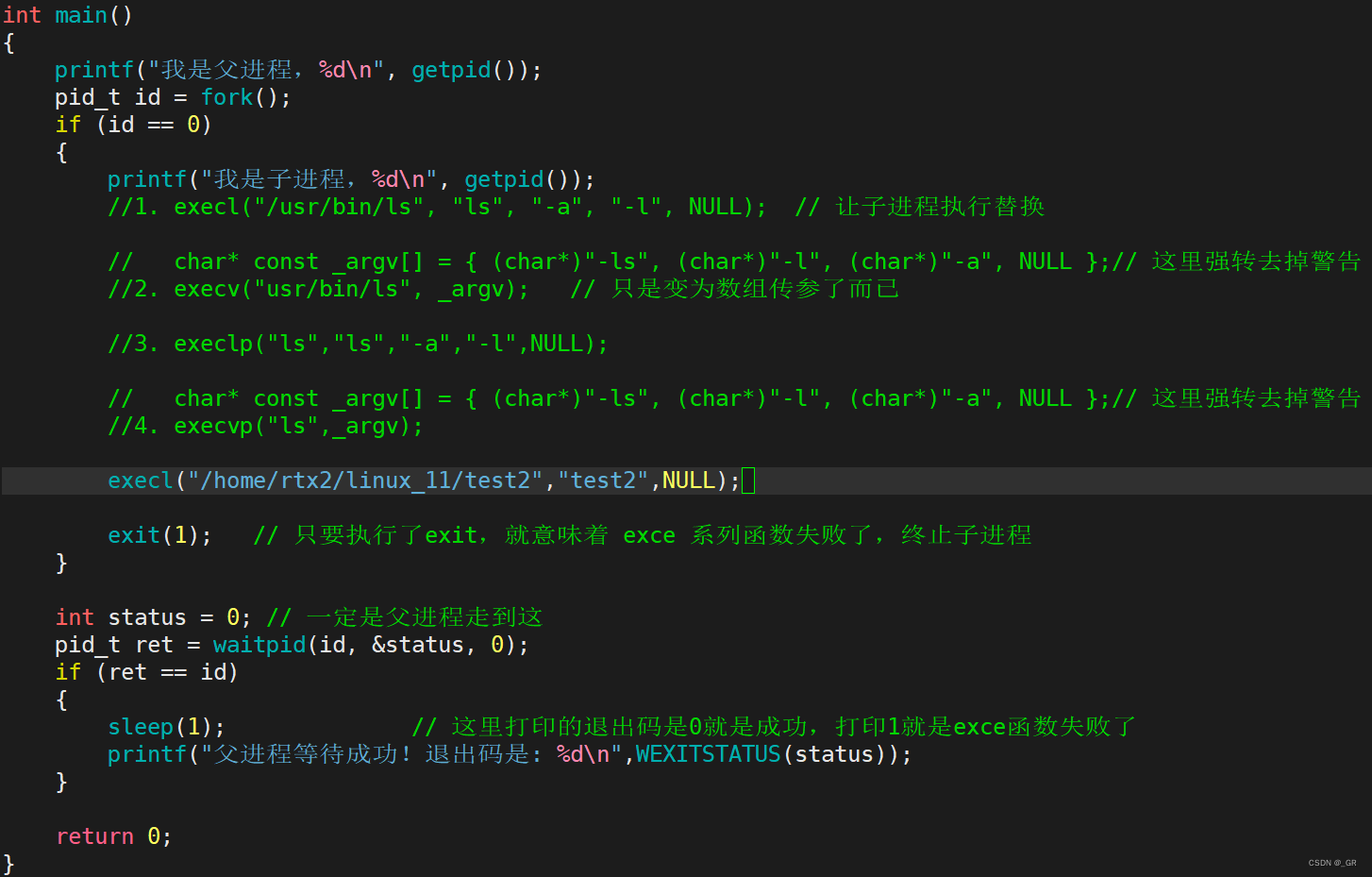
编译运行:
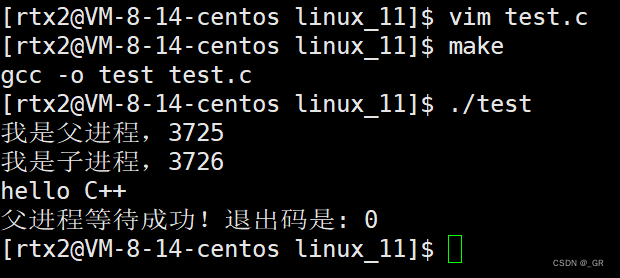
成功用C 语言程序调用我们的 C++ 程序,调用python也是可以的:

用vim写:

然后直接用python解释器编译运行看看:
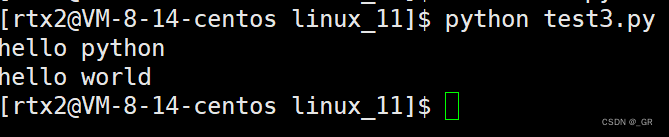
在test.c中调用test3.py:
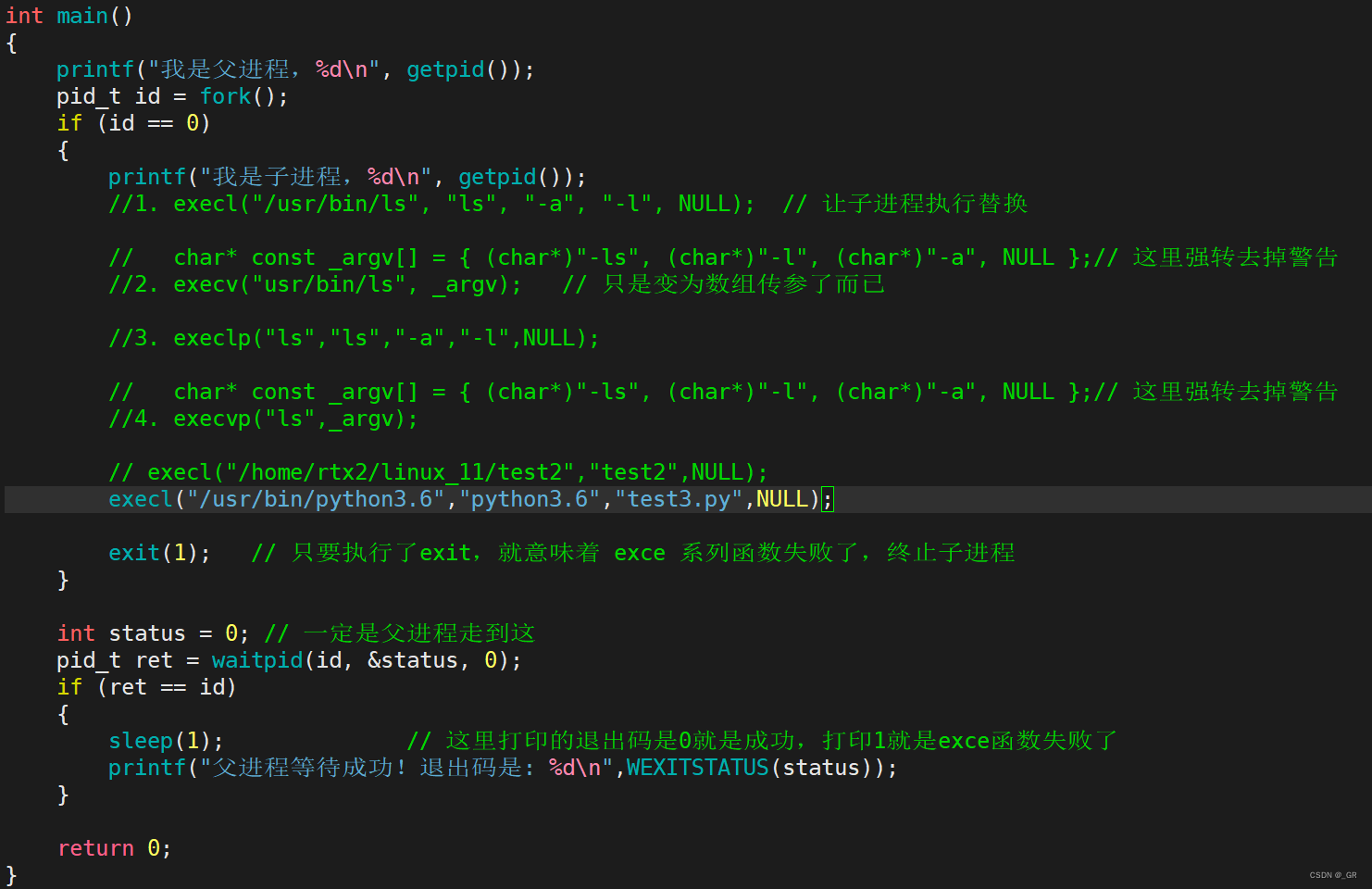
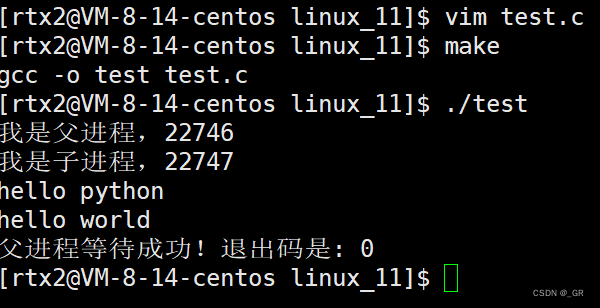
调用各种语言都是可以的,这里不再演示。
1.5 execle 接口
int execle(const char* path, const char* arg, ..., char* const envp[]);我们可以使用 execle 接口传递环境变量,相当于自己把环境变量导进去。
打开 test2.cpp文件,我们加上几句环境变量:
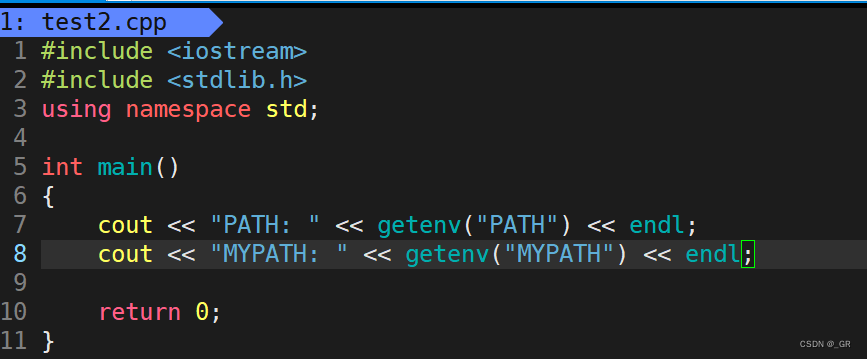
make然后直接./test2(有x权限就能这样,Python也是)

PATH 是自带的环境变量,MYPATH 是我们自己的环境变量,没设置所以没打印出来。
下面在 test.c,用 execle 给 test2.cpp 传递MYPATH 环境变量:
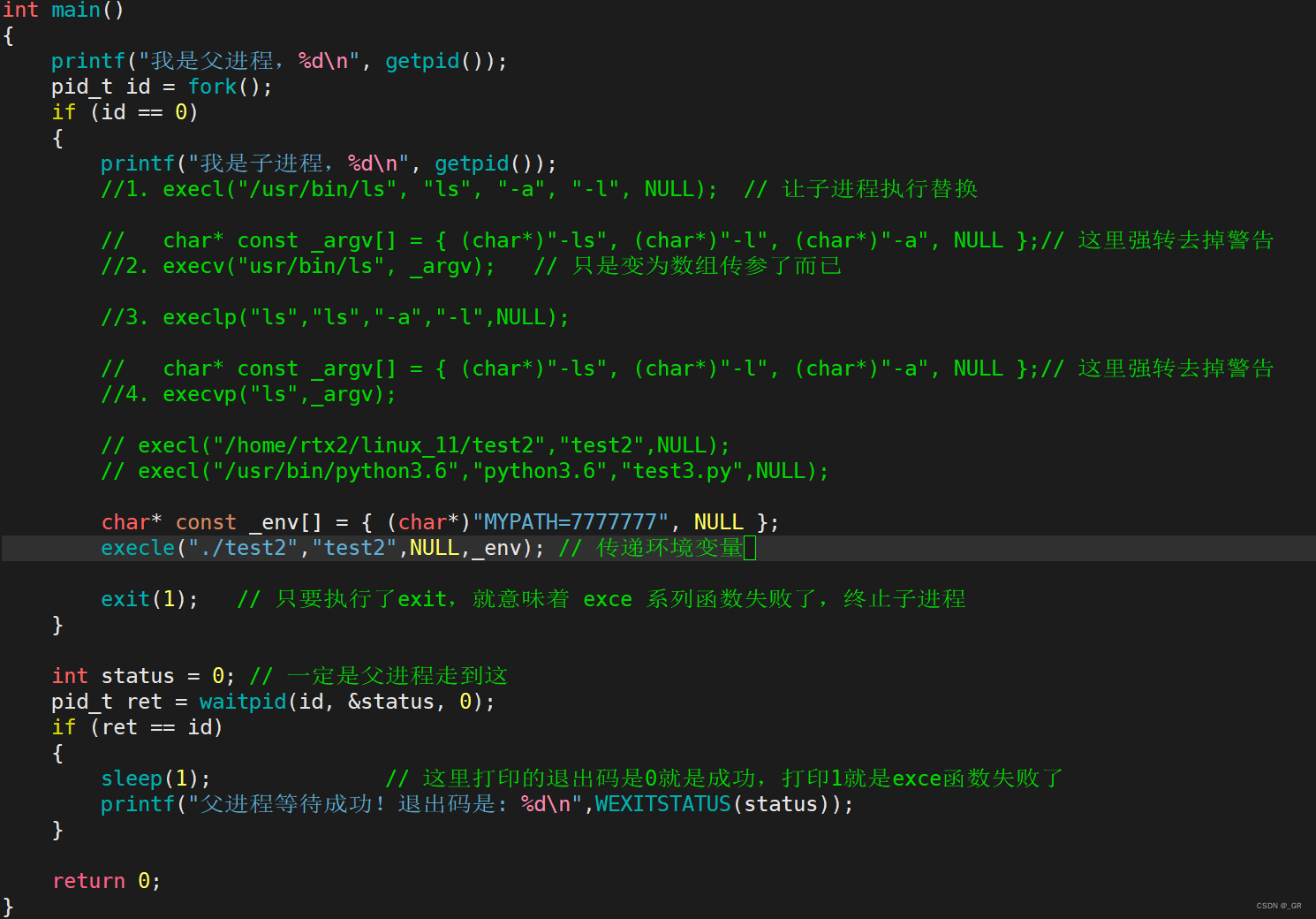
编译运行:
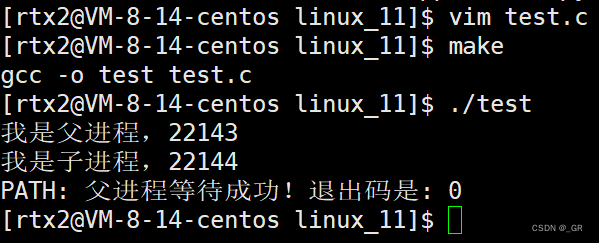
PATH没有打印,MYPATH更是看不到?
把test2.cpp的PATH注释掉:
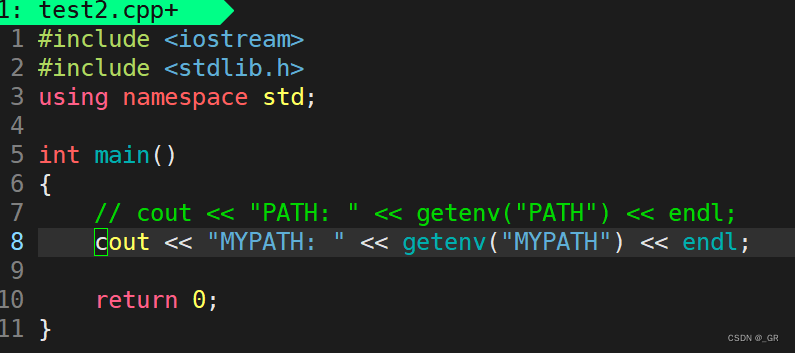
编译运行: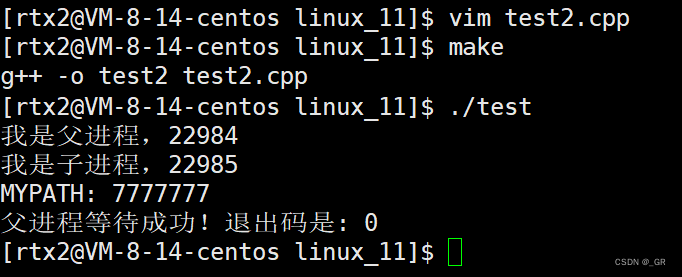
所以,为什么会出现这种情况?
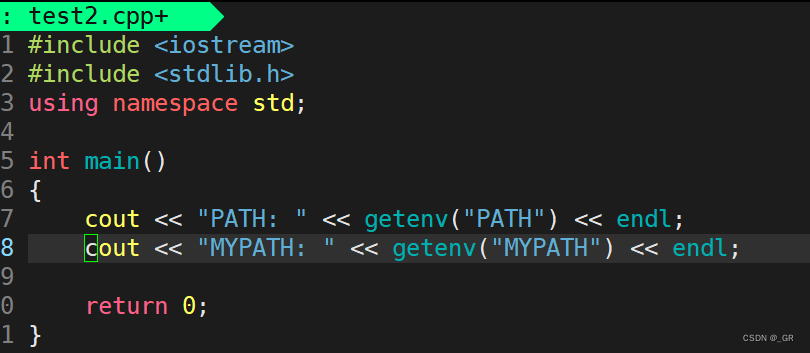
execle 接口,这个 e 表示的是 添加环境变量给目标进程,如果是自己的变量,那么是覆盖式的。如果你想把系统的环境变量 PATH 传给它,我们需要 extern 环境变量的指针申明:
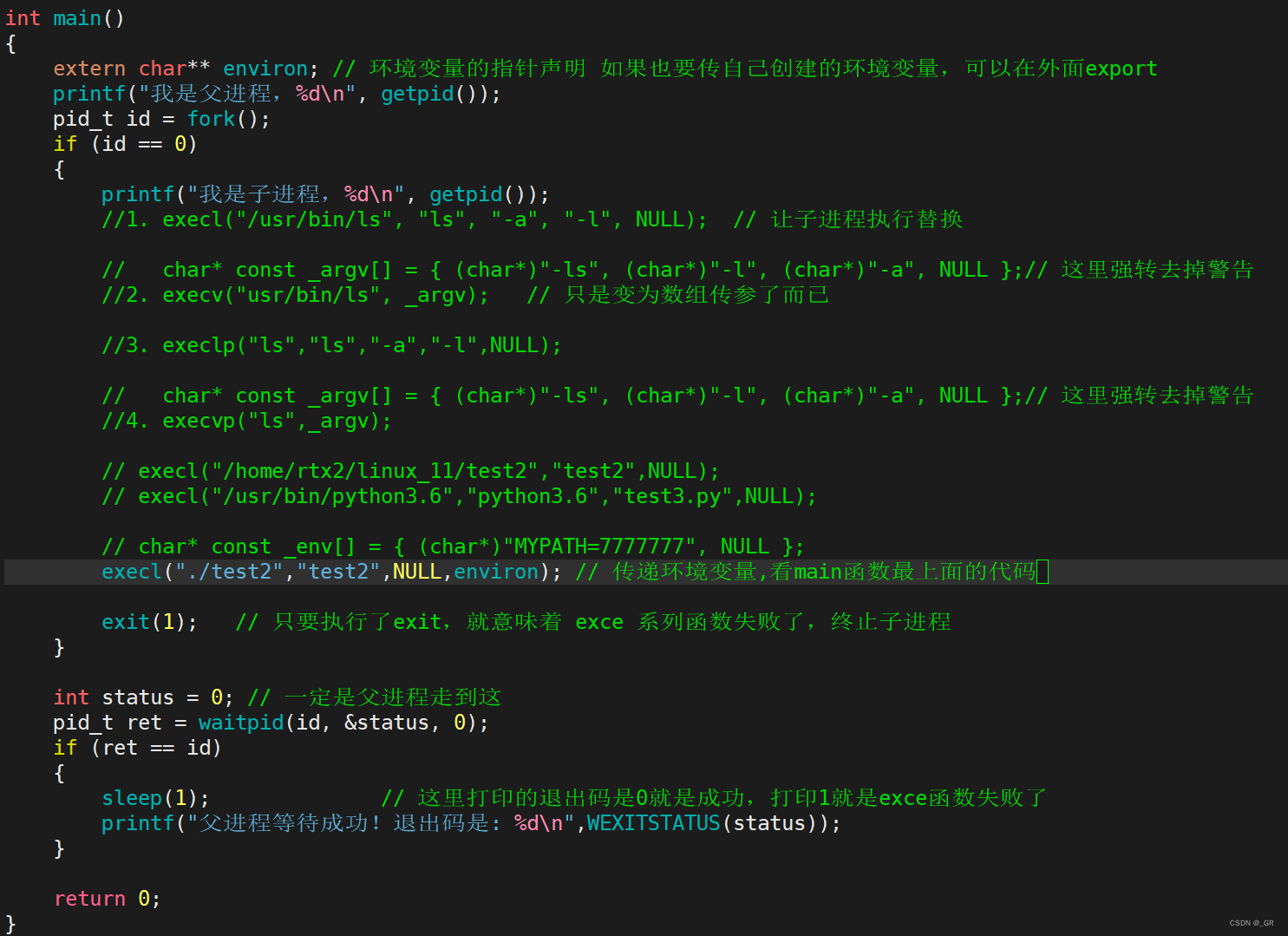
解开test2.cpp 的注释,编译运行:
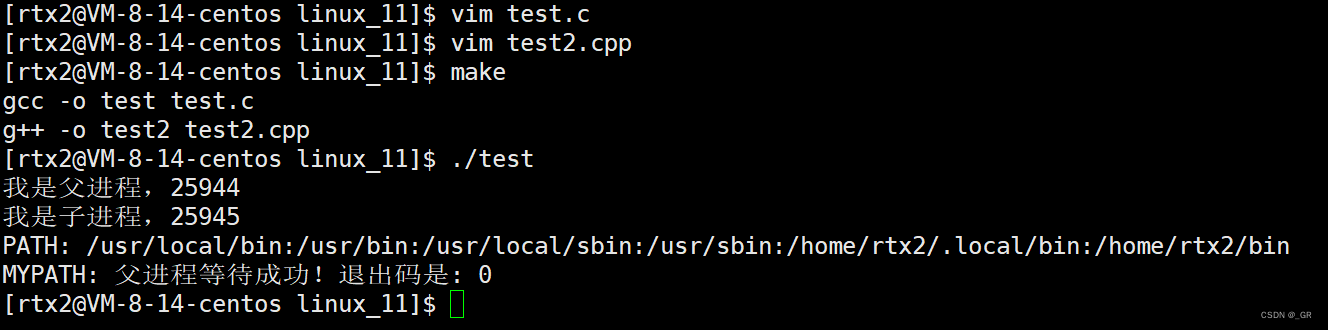
系统本来就没有 MYPATH,我们在外面export手动添加:
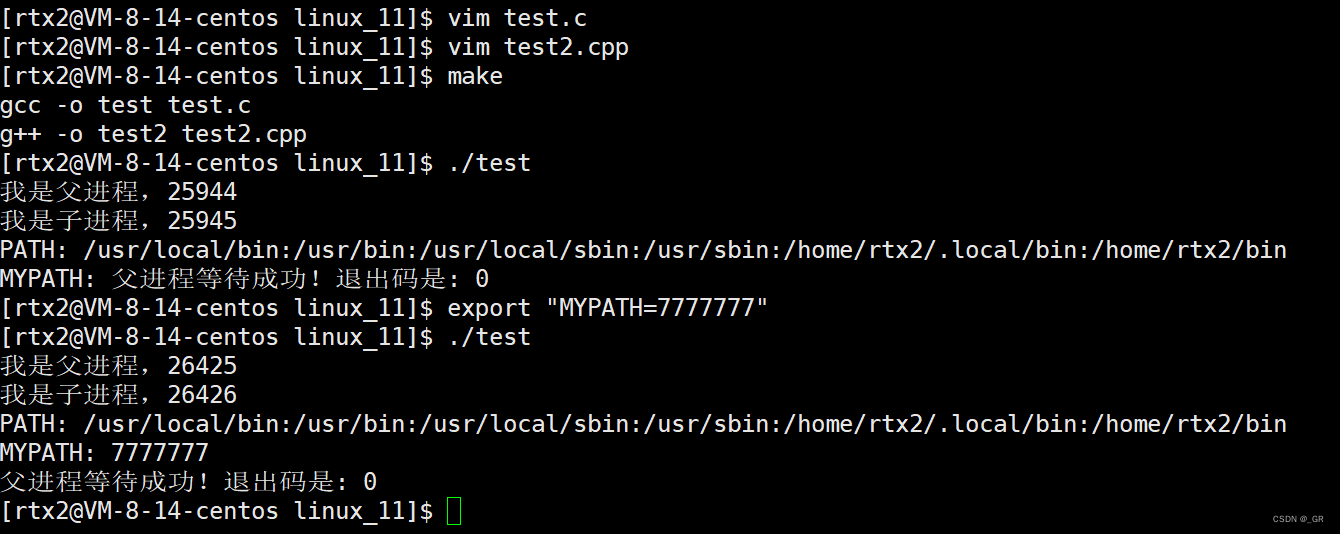
上面这也证明了环境变量的全局属性,看到这,剩下类似的接口看下就懂了,这里就不演示了
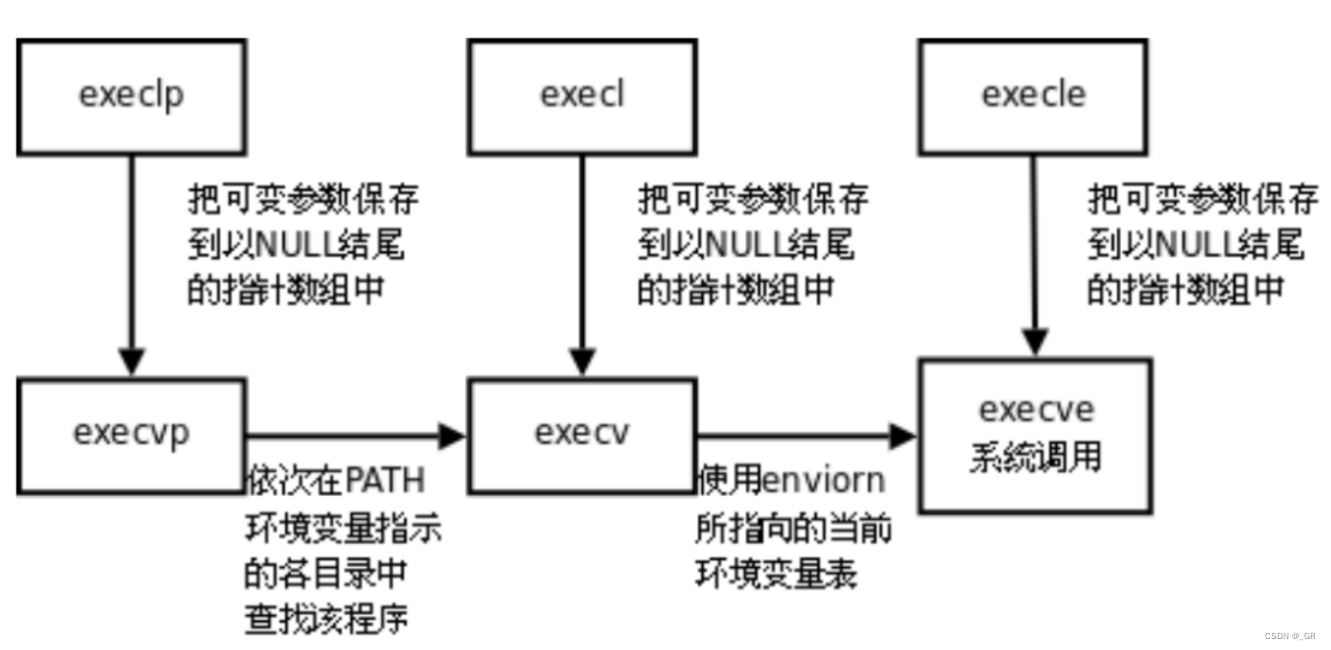
这么多接口,唯一的差别就是传参的方式不一样,有的带路径,有的不带路径,有的是列表传参,有的是数组传参,有的可带环境变量,有的不带环境变量。
因为要适配各种各样的应用场景,使用的场景不一样,有些人就喜欢列表传参,有些人喜欢数组传参。所以就配备了这么多接口,这就好比 C++ 函数重载的思想。
execve 处于 man 2 号手册,execve 才属于是真正意义上的系统调用接口。
刚才介绍的那些,实际上就是为了适配各种环境而封装的接口,每个的底层都调用execve:
2. 实现简单的shell
学到现在我们就可以更加清楚shell的运行机制了,bash是一个父进程,每输入一个指令就会创建一个子进程,并且进行相应的程序替换。
现在我们就来简单的模拟实现一下:(这里退出linux_11创建一个linux_11_shell)
写Makefile和myshell.c:

2.1 打印提示和获取输入
写myshell.c前先思考:shell 本质就是个死循环,先实现前两步写个框架:
① 打印显示提示符,比如:[rtx2@VM-8-14-centos linux_11_shell]$(这里就不获取了)
② 获取用户输入的指令和选项,比如:" ls -a -l ",->用fgets
man fgets:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>#define NUM 1024
char command_line[NUM]; // 用来接收命令行内容int main()
{while (1){// ① 打印显示提示符,比如:[rtx2@VM-8-14-centos linux_11_shell]$(这里就不获取了) printf("[用户名@主机名 当前目录]# ");fflush(stdout);// ② 获取用户输入的指令和选项,比如:" ls -a -l ",->用fgetsmemset(command_line,'\0',sizeof(command_line) * sizeof(char));if (fgets(command_line, NUM, stdin) == NULL) // 从键盘获取,stdin获取到C风格的字符串,默认添加\0{continue; // 读错了重新输入(基本不会读错)}printf("echo: %s\n", command_line); // 打印测试一下,后面注释掉}return 0;
}
编译运行试试:
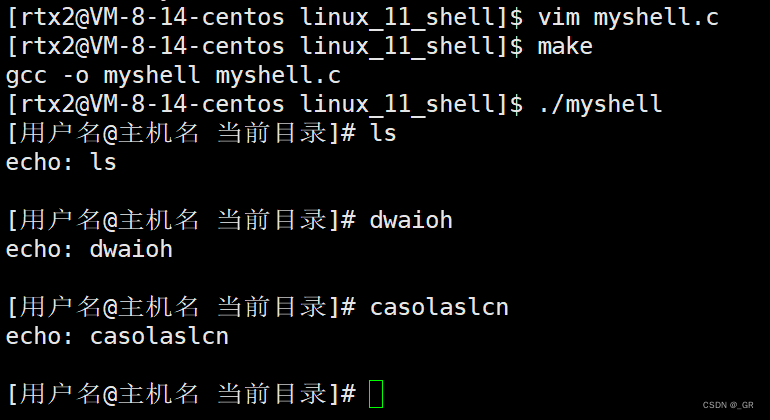
为什么多打了一行空行?
因为 command_line 里有一个 \n(fgets里获取到的),比如我们输入了ls -a -l,最后还会回车,
fgets把回车也获取到了,command_line 里就有“ls -a -l \n\0”,我们把它替换成 \n 即可:
command_line[strlen(command_line) - 1] = '\0'; // 消除 '\n'
'
编译运行:
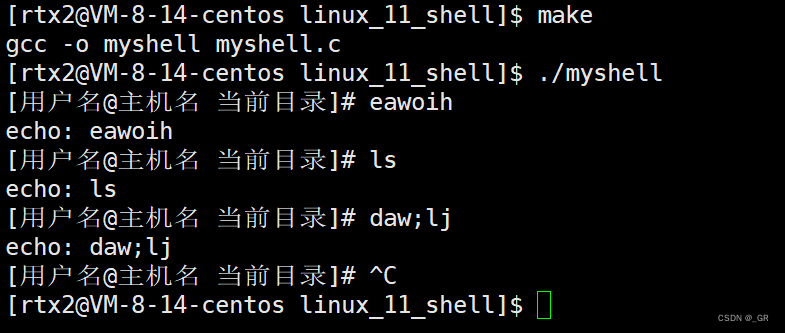
至此,我们已经完成了提示用户输入和获取用户输入了,然后把echo打印的那一行注释掉。
2.2 拆开输入的命令和选项
下面我们需要拆开输入的命令和选项,比如:把 "ls -a -l" 拆成 "ls" "-a" "-l"
因为 exec 函数簇无论是列表传参还是数组传参,一定是要逐个传递的。
我们可以使用以前学过的 strtok 函数,将一个字符串按照特定的分隔符打散,将子串依次返回:
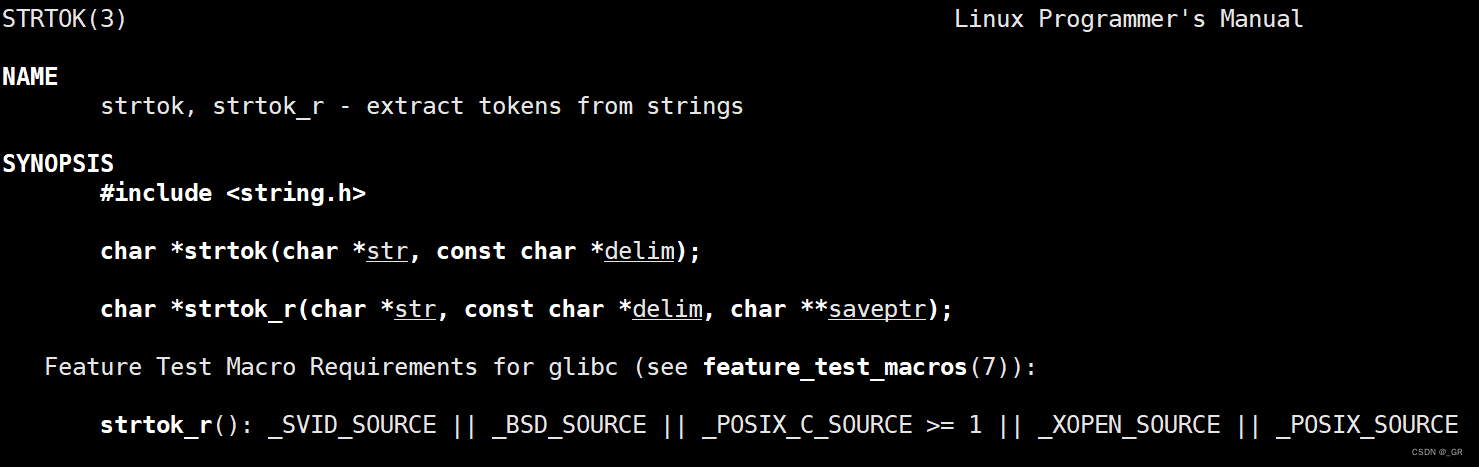
复习链接:C语言进阶⑬(字符串)(指针编程作业)(模拟实现字符串函数)__GR的博客-CSDN博客

写代码并且讲拆开的命令和选项打印出来:
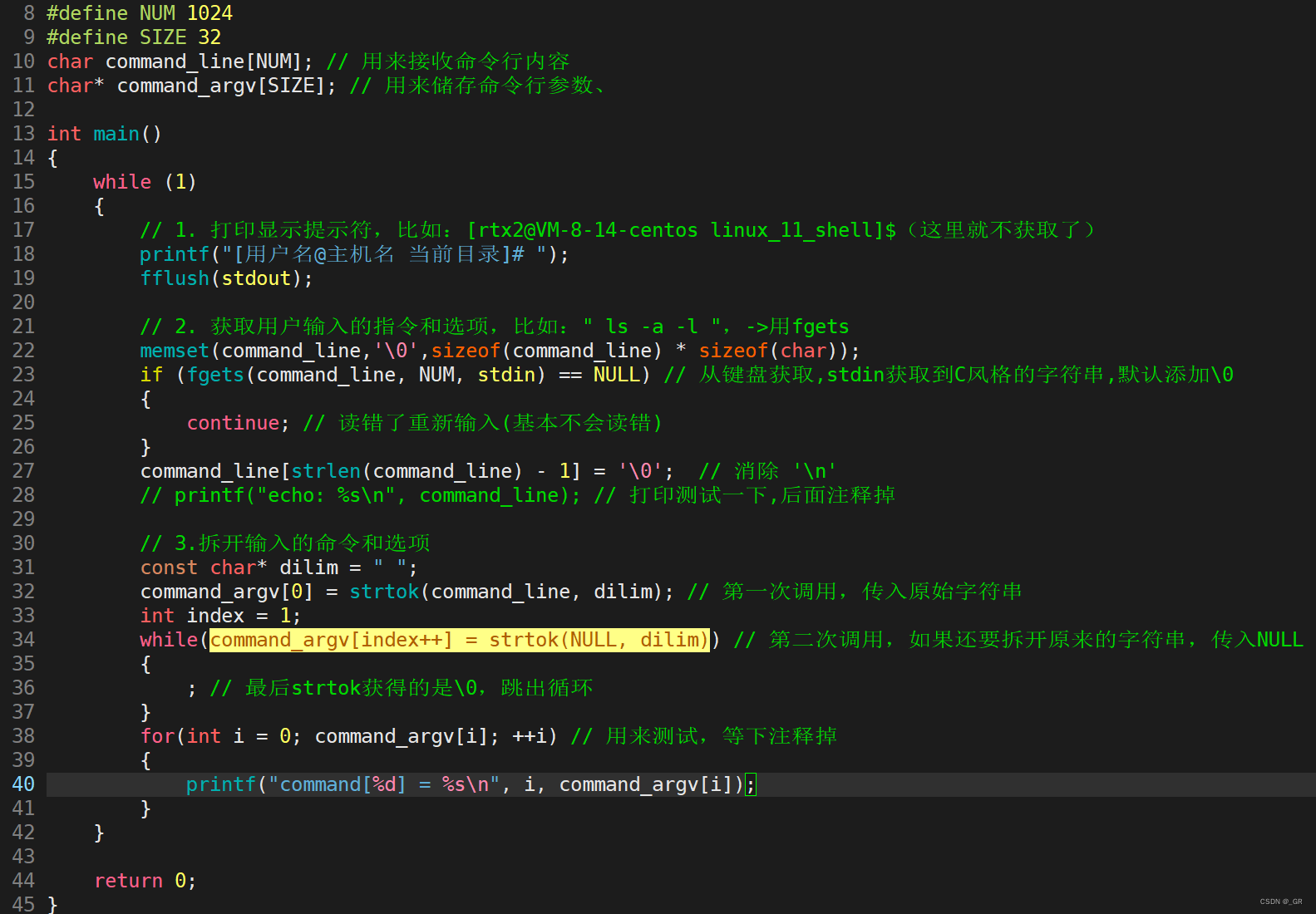 用到for循环:
用到for循环:
编译运行:
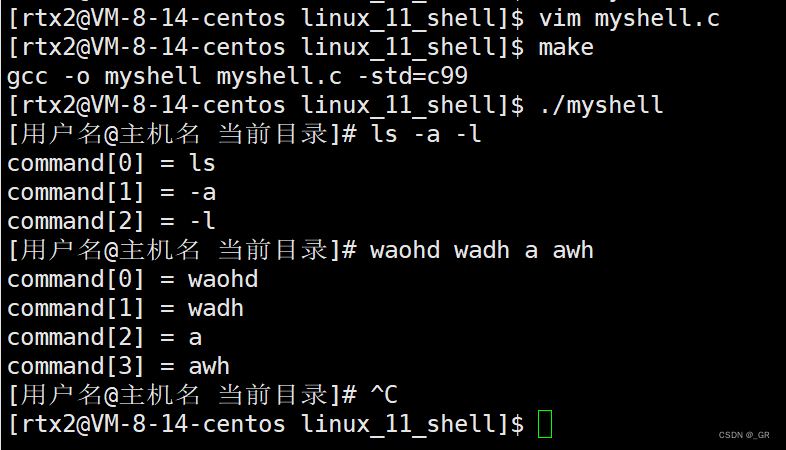
成功拆开输入的命令和选项,把测试的for循环注释掉。
2.3 创建进程和程序替换执行命令
下面我们实现创建子进程,执行上面获取到的命令。
#include <unistd.h>int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ...,char *const envp[]);int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char* file, char* const argv[], char* const envp[]);int execve(const char *path, char *const argv[], char *const envp[]);这么多接口选哪个?我们拆开的命令已经带数组了,当然选带v的,路径让它自己找,就选带p的,所以选用execvp这个接口:
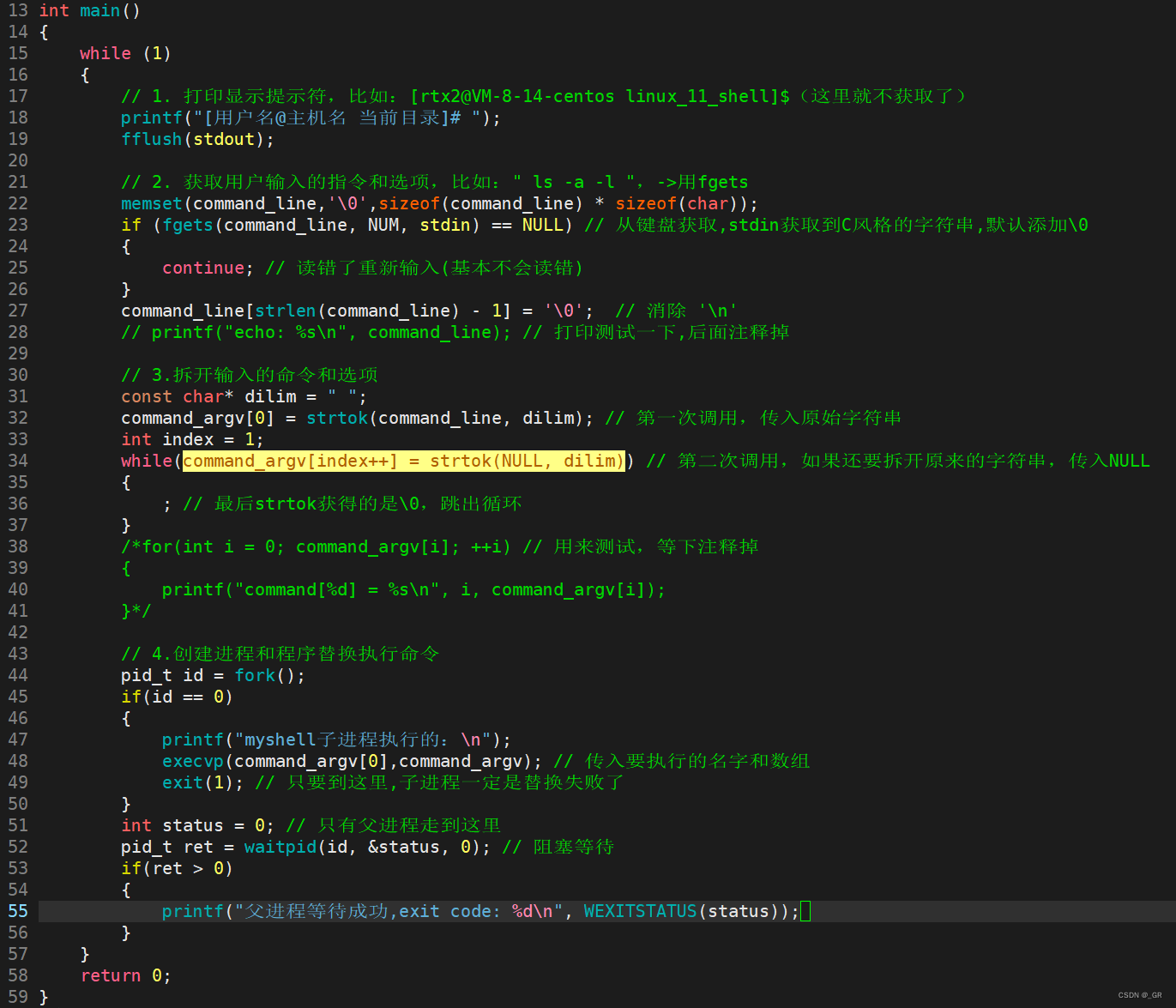
编译运行: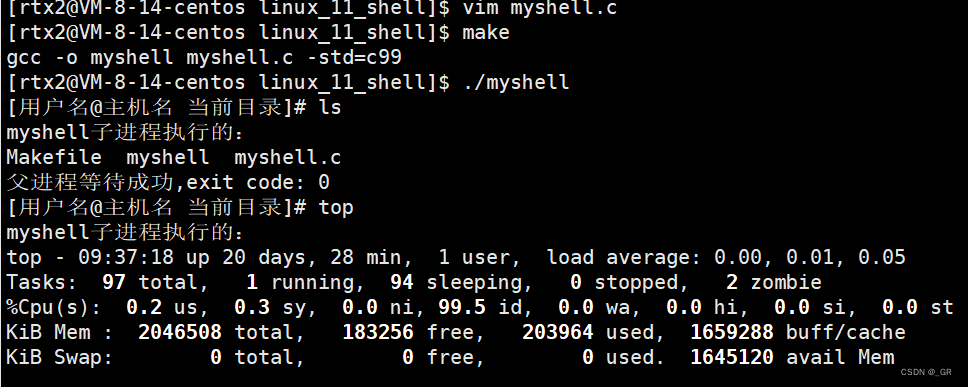
此时就可以调用各种命令了,但还有很多地方不够好,比如:如何让我们的命令带颜色呢?
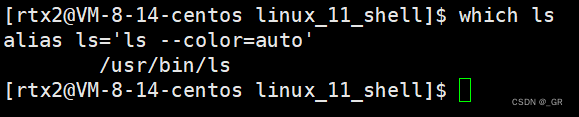
以前就看到过了这条命令,现在给我们myshell里的 ls 加上,在第3步给 ls 命令添加颜色:

编译运行:
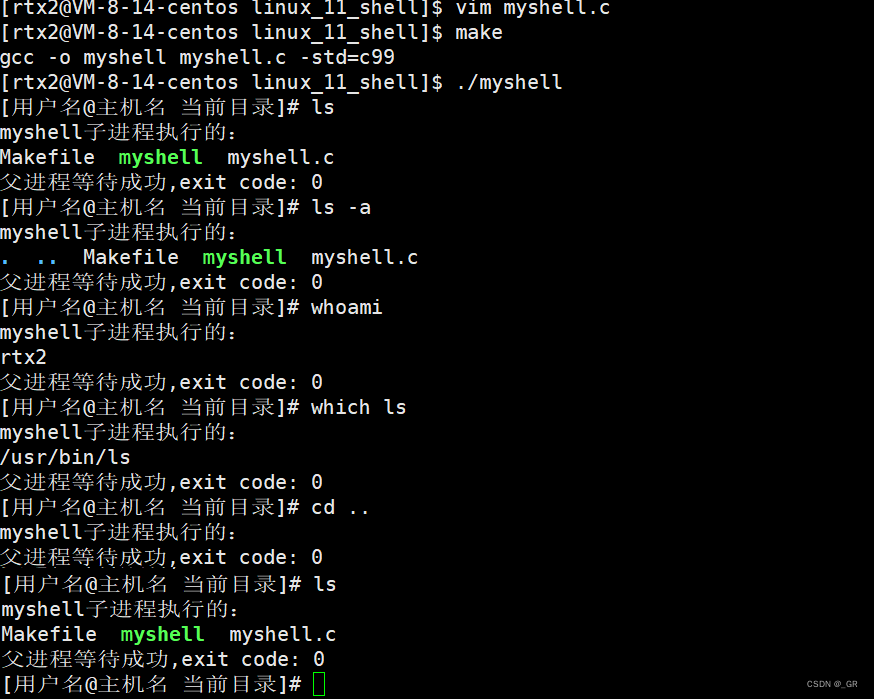
为什么我们 cd.. 回退到上级目录时,我们的路径是不发生变化的?

2.4 内建命令实现路径切换
虽然系统中存在 cd 命令,但我们写的 shell 脚本中用的根本就不是这个 cd 命令。
当你在执行 cd 命令时,调用 execvp 执行的实际上是系统特定路径下的 cd,
它只影响了子进程,如果我们直接 exec* 执行 cd,那么最多只是让子进程进行路径切换。
但是请不要忘了:子进程是一运行就完毕的进程,运行完了你切换它的路径,毫无意义。
所以,我们在 shell 中,更希望谁的路径发生变化呢?答案是父进程(shell 本身)
所以,对我们来说我们此时就有一个需求了:如果有些行为是必须让父进程 shell 执行的,不想让子进程执行,这样的场景下,绝对不能创建子进程,因为一旦创建了子进程最后执行任务的是子进程,和父进程就无关了,只能是父进程自实现对应的代码。
这部分由 shell 自己执行的命令,我们称之为 内建指令。
内建指令本质是shell中的一个函数调用。
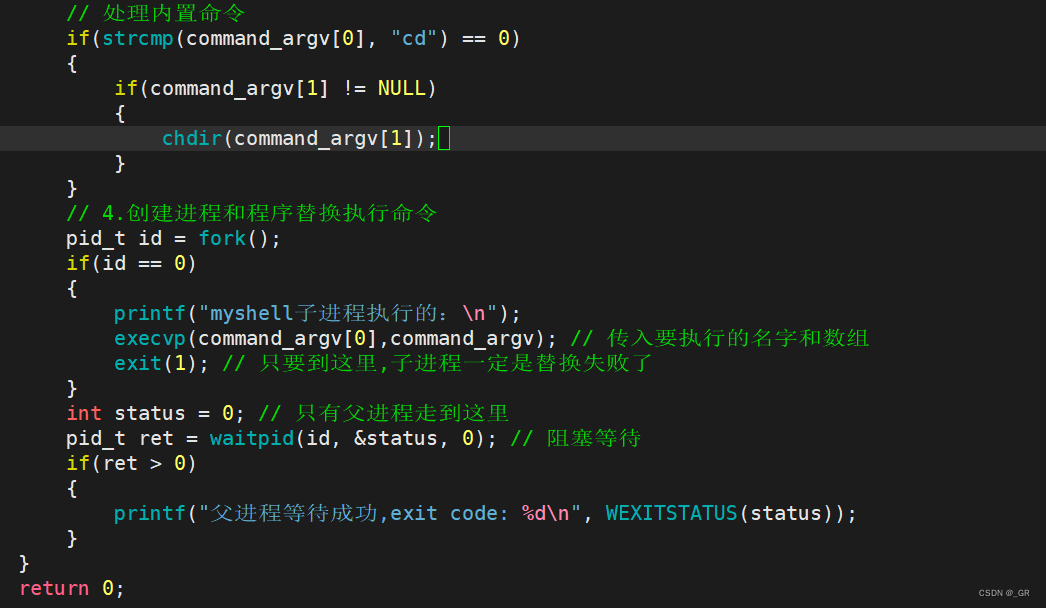
实现路径切换的函数的函数:chdir

在第4步创建子进程之前处理一下cd命令:
编译运行:
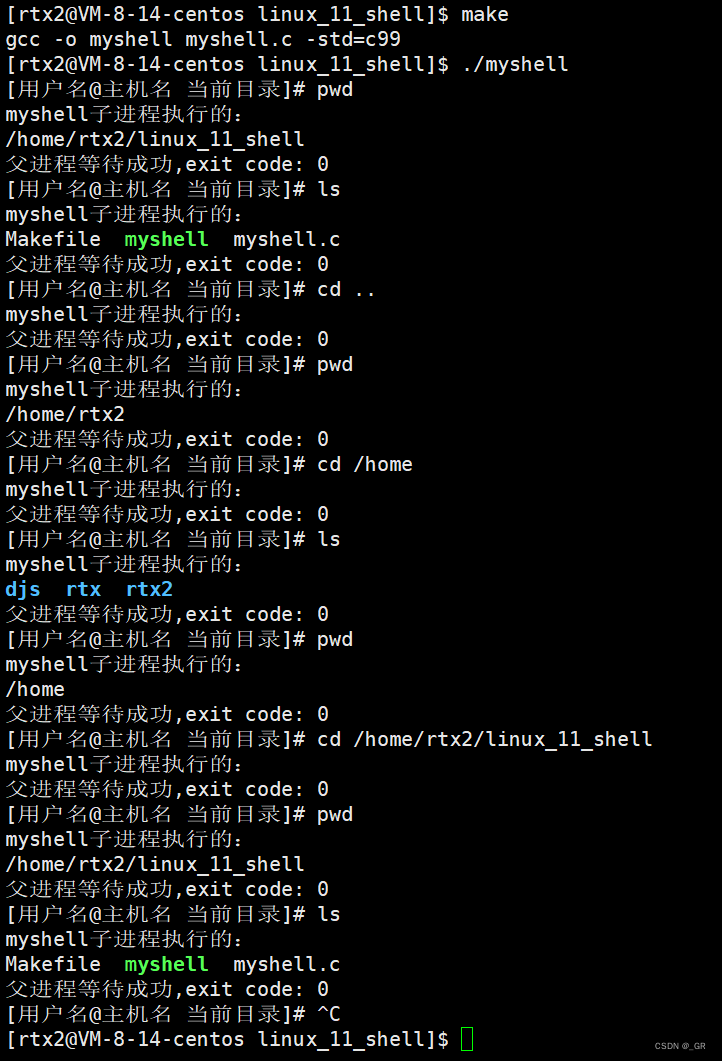
成功实现内建命令实现路径切换。
2.5 myshell里放置环境变量
前面 exec 的函数,是可以直接执行指定的命令、环境变量的。
在myshell.c里放置环境变量,函数putenv:
程序替换中,对于 exec 函数簇,如果如果函数名没 e,所有的环境变量是会被继承的。
不带 e,环境变量依旧是可以被继承的,所以我们自己定一个环境变量的数组,
它会覆盖我们的环境变量列表,我现在不想覆盖,我想新增,
环境变量也会随之清空而丢失,所以我么需要一个专门存储环境变量的:
编译运行:
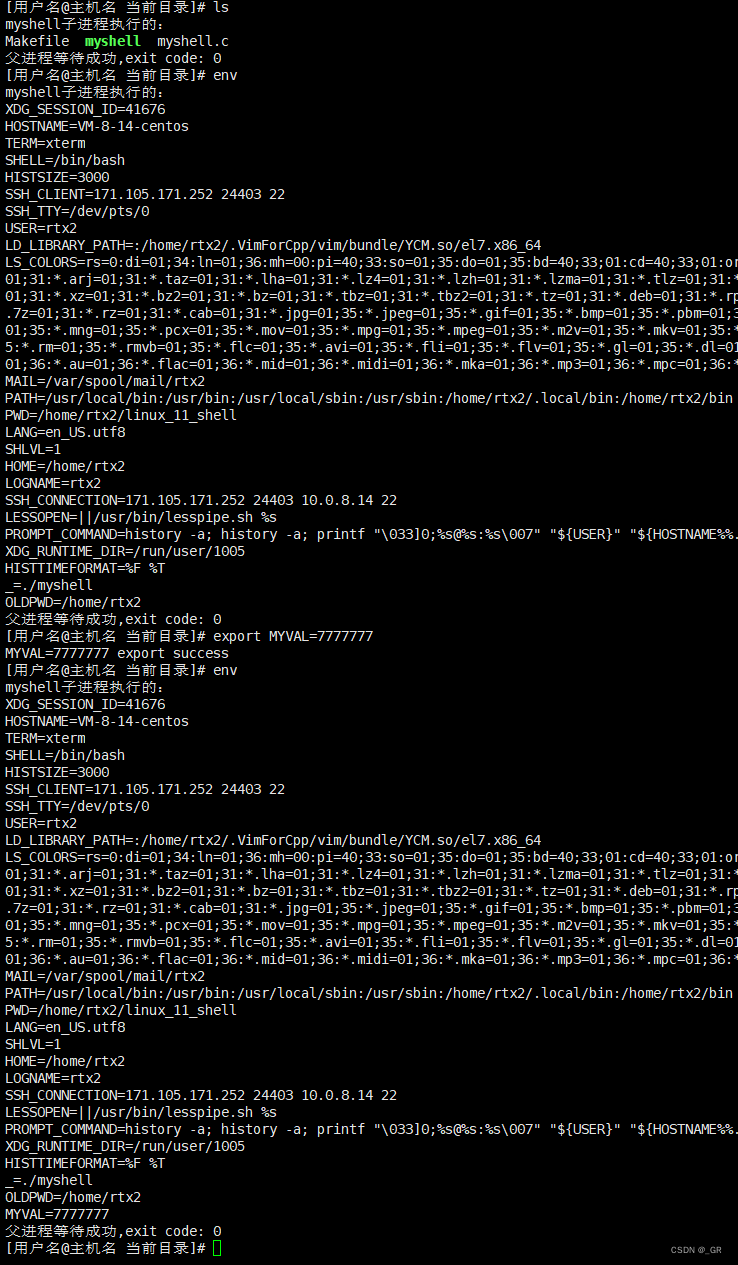
环境变量也放置成功了。
环境变量的数据在进程的上下文中:
① 环境变量会被子进程继承下去,所以它会有全局属性。
② 当我们进行程序替换时, 当前进程的环境变量非但不会替换,而且是继承父进程的。环境你不传,默认子进程全部都会自动继承。
如果你 exel 函数簇带 e,就相当于你选择了自己传,就会覆盖式地把原本的环境变量弄没,然后你自己交给子进程。如果不带 e,那么环境变量就会自己被子进程继承。
如果既不想覆盖系统,也不想新增,所以我们采用 putenv 的方式向父 shell 导入新增一个它自己的环境变量,这样的话原始的环境变量还在,我们能在 shell 上下文上给它新增环境变量。所以,如何理解环境变量具有全局属性?
因为所有的环境变量会被当前进程之下的所有子进程默认继承下去。
如何在 shell 内部自己导入新增自己的环境变量?
putenv,要注意的是,需要一个独立的空间,放置环境变量的数据被改写。
最后,有没有想过shell的环境变量是哪里来的?
环境变量是写在配置文件中的,shell启动的时候,通过读取配置文件获得起始的环境变量。
3. 传上git(附完整代码)
git clone https://gitee.com/GRTX/TestLinux.git(自己的网站+用户名+密码)
cp myshell.c TestLinux/myshell.c(复制myshell到TestLinux目录下)
cd TestLinux
git add myshell.c
git commit -m '第一次提交实现的简单myshell程序'
git push(需用户名密码)
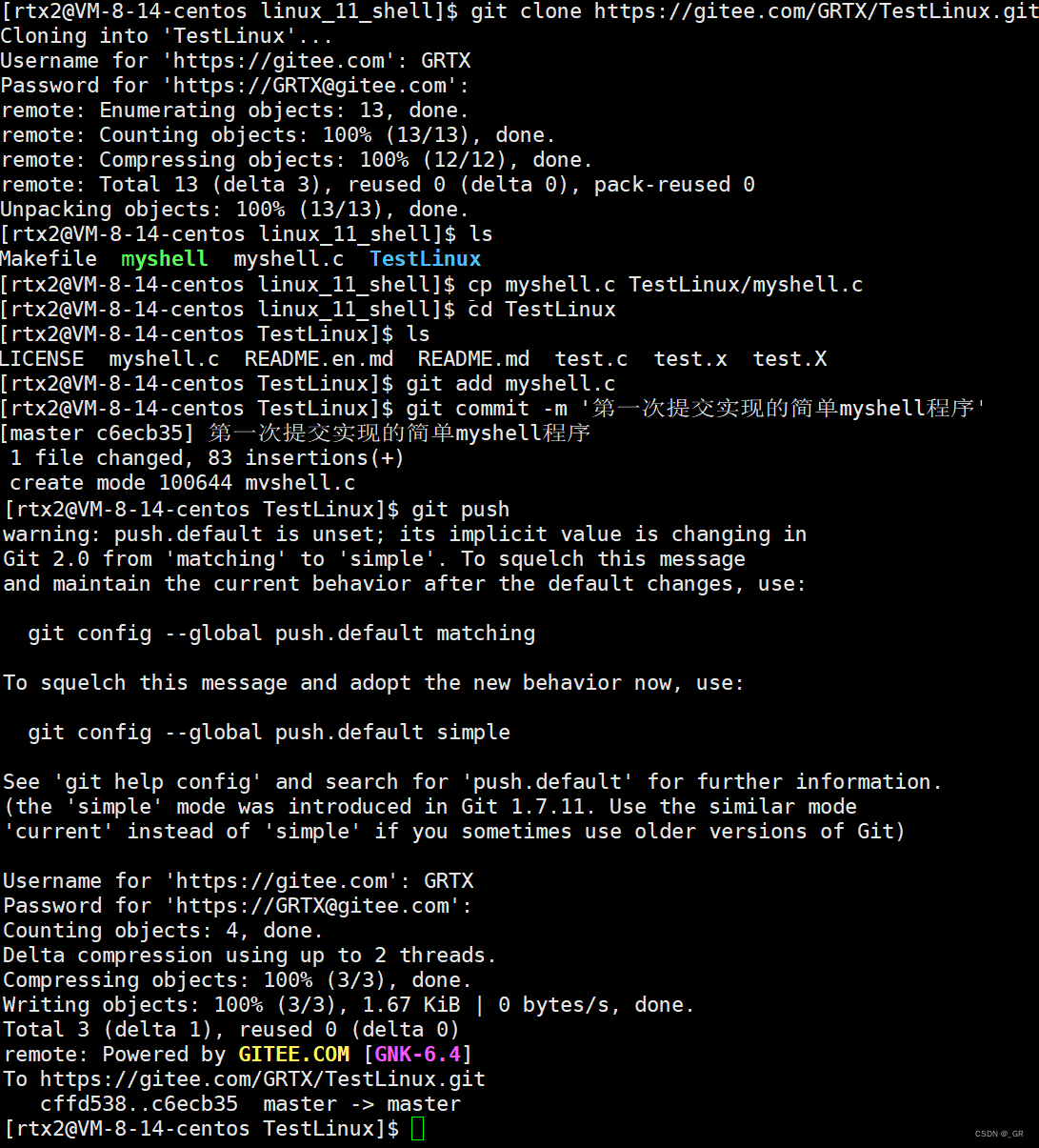
刷新git后,成功上传,完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>#define NUM 1024
#define SIZE 32
char command_line[NUM]; // 用来接收命令行内容
char* command_argv[SIZE]; // 用来储存命令行参数
char g_myval[64];// 写一个环境变量的buffer缓冲区int main()
{while (1){// 1. 打印显示提示符,比如:[rtx2@VM-8-14-centos linux_11_shell]$(这里就不获取了) printf("[用户名@主机名 当前目录]# ");fflush(stdout);// 2. 获取用户输入的指令和选项,比如:" ls -a -l ",->用fgetsmemset(command_line,'\0',sizeof(command_line) * sizeof(char));if (fgets(command_line, NUM, stdin) == NULL) // 从键盘获取,stdin获取到C风格的字符串,默认添加\0{continue; // 读错了重新输入(基本不会读错)}command_line[strlen(command_line) - 1] = '\0'; // 消除 '\n'// printf("echo: %s\n", command_line); // 打印测试一下,后面注释掉// 3.拆开输入的命令和选项const char* dilim = " ";command_argv[0] = strtok(command_line, dilim); // 第一次调用,传入原始字符串int index = 1;if(strcmp(command_argv[0],"ls") == 0){command_argv[index++] = "--color=auto"; // 成立的话下面while循环从2开始跑}while(command_argv[index++] = strtok(NULL, dilim)) // 第二次调用,如果还要拆开原来的字符串,传入NULL{; // 最后strtok获得的是\0,跳出循环}/*for(int i = 0; command_argv[i]; ++i) // 用来测试,等下注释掉{printf("command[%d] = %s\n", i, command_argv[i]);}*/// 放置环境变量if(strcmp(command_argv[0], "export") == 0 && command_argv[1] != NULL){strcpy(g_myval, command_argv[1]);int ret = putenv(g_myval);if(ret == 0){printf("%s export success\n", command_argv[1]);}continue;}// 处理内置命令if(strcmp(command_argv[0], "cd") == 0){if(command_argv[1] != NULL){chdir(command_argv[1]);}}// 4.创建进程和程序替换执行命令pid_t id = fork();if(id == 0){printf("myshell子进程执行的:\n");execvp(command_argv[0],command_argv); // 传入要执行的名字和数组exit(1); // 只要到这里,子进程一定是替换失败了}int status = 0; // 只有父进程走到这里pid_t ret = waitpid(id, &status, 0); // 阻塞等待if(ret > 0){printf("父进程等待成功,exit code: %d\n", WEXITSTATUS(status));}}return 0;
}
4. 本篇完。
进程控制内容是对前面进程学习内容的一种检验,很重要,尤其是进程程序替换,此时我们心中曾经的疑惑能够解开不少。还实现了简单的shell,相信大家对shell的理解也更深刻了。
下一篇是进程部分的笔试选择题汇总:零基础Linux_12(进程)笔试选择题:冯诺依曼结构+操作系统+进程
下一大部分:基础IO,再下一大部分是进程间通信然后是进程信号。