在当今数据驱动的世界中,从 PDF 文档中无缝提取结构化表格数据已成为开发人员的一项关键任务。借助GrapeCity Documents for PDF ( GcPdf ),您可以使用 C# 以编程方式轻松解锁这些 PDF 中隐藏的信息宝藏。
考虑一下 PDF(最常用的文档格式之一)的流行程度,以及它的表格中可以包含的大量数据。公司和组织一直在使用 PDF 文档来查看财务分析、股票趋势、联系方式等。现在,想象一下多年来检查季度报告的情况,其中数据的积累占据了中心位置。
从这些报告中获取数据最初看起来可能很容易(复制/粘贴)。尽管如此,由于 PDF 文件的结构,简单的复制和粘贴无需大量操作和修改即可获得表格数据的情况很少见。
再加上从许多其他文档复制和粘贴的可能性,这是一个漫长的一天(甚至一周或更长时间,取决于所需数据!)的秘诀。有效地处理此类需求需要一个能够自动执行此过程的工具,而 C# .NET GcPdf API 库是完成这项工作的完美工具!
本文适用于希望减少收集数据所需时间并提高数据收集过程准确性的开发人员。这些示例将帮助开发人员了解 GcPdf 工具,以便访问 PDF 文件中的表格并提取表格数据以便根据需要导出为 CSV 文件或其他格式(例如 XLSX)。
有关 PDF 文档中表格的重要信息
表格与 PDF 文件格式非常相似,是一种几乎流行的数据呈现方式。尽管如此,有必要了解 PDF 文档本质上缺乏表格的概念。换句话说,您在 PDF 中看到的表格纯粹是视觉元素。
这些 PDF“表格”与我们在 MS Excel 或 MS Word 等应用程序中常见的表格不同。相反,它们是通过负责在特定位置渲染文本和图形的运算符组合来构造的,类似于表格结构。
这意味着行、列和单元格的传统概念对于 PDF 文件来说是陌生的,没有底层代码组件来帮助识别这些元素。那么,让我们深入研究一下 GcPdf 的 C# API 库如何帮助我们实现这一任务!
如何使用 C# 以编程方式从 PDF 文档中提取表格数据
- 创建包含 GcPdf 的 .NET Core 控制台应用程序
- 加载包含数据表的示例 PDF
- 定义表识别参数
- 获取表数据
- 将提取的 PDF 表数据保存到另一种文件类型 (CSV)
- 奖励:将导出的 PDF 表格数据格式化为 Excel (XLSX) 文件
请务必下载示例应用程序 并尝试本博客文章中描述的用例场景和代码片段的详细实现。
创建包含 GcPdf 的 .NET Core 控制台应用程序
创建 .NET Core 控制台应用程序,右键单击“依赖项”,然后选择“管理 NuGet 包”。在“浏览”选项卡下,搜索“GrapeCity.Documents.Pdf”并单击“安装”。

安装时,您将收到“许可证接受”对话框。单击“我接受”继续。

在程序文件中,导入以下命名空间:
using System.Text;
using GrapeCity.Documents.Pdf;
using GrapeCity.Documents.Pdf.Recognition;
using System.Linq;加载包含数据表的示例 PDF
通过初始化GcPdfDocument 构造函数来加载将要解析的 PDF 文档来创建新的 PDF 文档。调用 GcPdfDocument 的 Load 方法来加载包含数据表的原始 PDF 文档。
using (var fs = File.OpenRead(Path.Combine("Resources", "PDFs", "zugferd-invoice.pdf")))
{// Initialize GcPdfvar pdfDoc= new GcPdfDocument();// Load a PDF documentpdfDoc.Load(fs);
}在此示例中,我们将使用此 PDF:
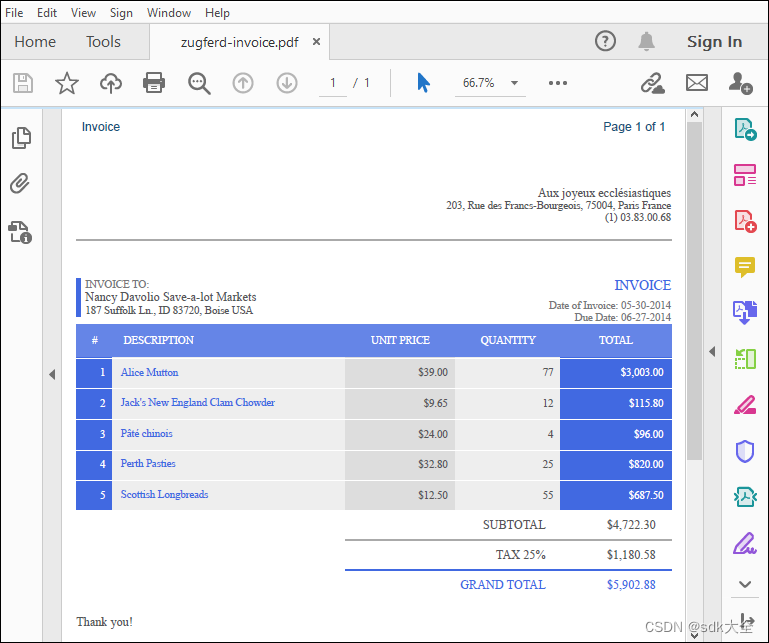
定义表识别参数
实例化RectangleF 类的新实例并定义 PDF 文档中的表格边界。
const float DPI = 72;
using (var fs = File.OpenRead(Path.Combine("Resources", "PDFs", "zugferd-invoice.pdf")))
{// Initialize GcPdfvar pdfDoc= new GcPdfDocument();// Load a PDF documentpdfDoc.Load(fs);// The approx table bounds:var tableBounds = new RectangleF(0, 2.5f * DPI, 8.5f * DPI, 3.75f * DPI);
}为了帮助在定义的参数内识别表格,我们使用TableExtractOptions类,允许我们微调表格识别,考虑表格格式的特性。TableExtractOptions 是一个参数,用于指定表格式选项,例如列宽、行高以及行或列之间的距离。
// TableExtractOptions allow to fine-tune table recognition accounting for
// specifics of the table formatting:
var tableExtrctOpt = new TableExtractOptions();
var GetMinimumDistanceBetweenRows = tableExtrctOpt.GetMinimumDistanceBetweenRows;// In this particular case, we slightly increase the minimum distance between rows
// to make sure cells with wrapped text are not mistaken for two cells:
tableExtrctOpt.GetMinimumDistanceBetweenRows = (list) =>
{var res = GetMinimumDistanceBetweenRows(list);return res * 1.2f;
};获取 PDF 的表格数据
创建一个列表来保存 PDF 页面中的表格数据。
// CSV: list to keep table data from all pages:
var data = new List<List<string>>();使用 定义的表边界(在上一步中定义)调用GetTable 方法,以使 GcPdf 搜索指定矩形内的表。
for (int i = 0; i < pdfDoc.Pages.Count; ++i)
{// Get the table at the specified bounds:var itable = pdfDoc.Pages[i].GetTable(tableBounds, tableExtrctOpt);
}使用ITable.GetCell(rowIndex, colIndex) 方法访问表中的每个单元格。使用 Rows.Count 和 Cols.Count 属性循环访问提取的表格单元格。
for (int i = 0; i < pdfDoc.Pages.Count; ++i)
{// Get the table at the specified bounds:var itable = pdfDoc.Pages[i].GetTable(tableBounds, tableExtrctOpt);if (itable != null){for (int row = 0; row < itable.Rows.Count; ++row){// CSV: add next data row ignoring headers:if (row > 0)data.Add(new List<string>());for (int col = 0; col < itable.Cols.Count; ++col){var cell = itable.GetCell(row, col);if (cell == null && row > 0)data.Last().Add("");else{if (cell != null && row > 0)data.Last().Add($"\"{cell.Text}\"");}}}}
}将提取的 PDF 表数据保存到另一种文件类型 (CSV)
对于此步骤,我们必须首先添加对“System.Text.Encoding.CodePages”NuGet 包引用的引用。
然后,为了保存上一步中从变量中提取的 PDF 表数据,我们将使用 File 类 并调用其 AppendAllLines 方法。
for (int i = 0; i < pdfDoc.Pages.Count; ++i)
{// Get the table at the specified bounds:var itable = pdfDoc.Pages[i].GetTable(tableBounds, tableExtrctOpt);if (itable != null){for (int row = 0; row < itable.Rows.Count; ++row){// CSV: add next data row ignoring headers:if (row > 0)data.Add(new List<string>());for (int col = 0; col < itable.Cols.Count; ++col){var cell = itable.GetCell(row, col);if (cell == null && row > 0)data.Last().Add("");else{if (cell != null && row > 0)data.Last().Add($"\"{cell.Text}\"");}} }}
}数据现在将以 CSV 文件形式提供:
|
|
|
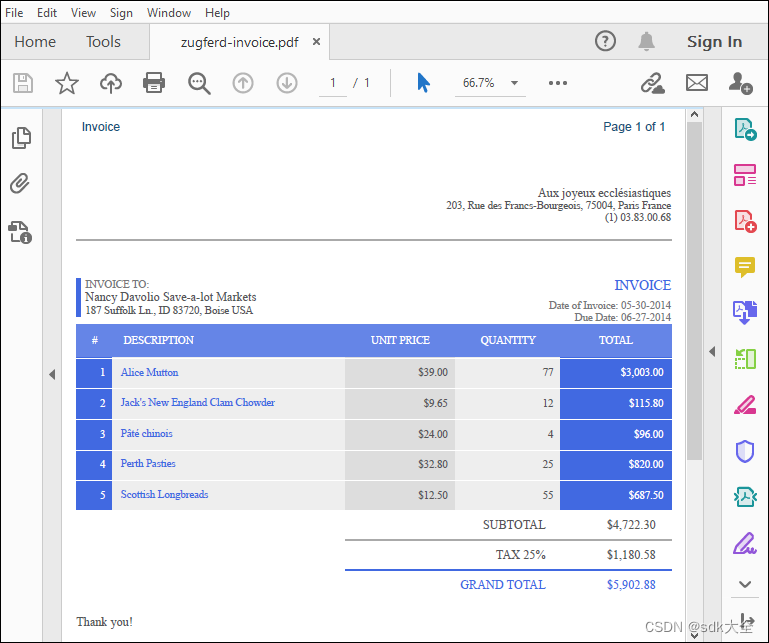 原版PDF
原版PDF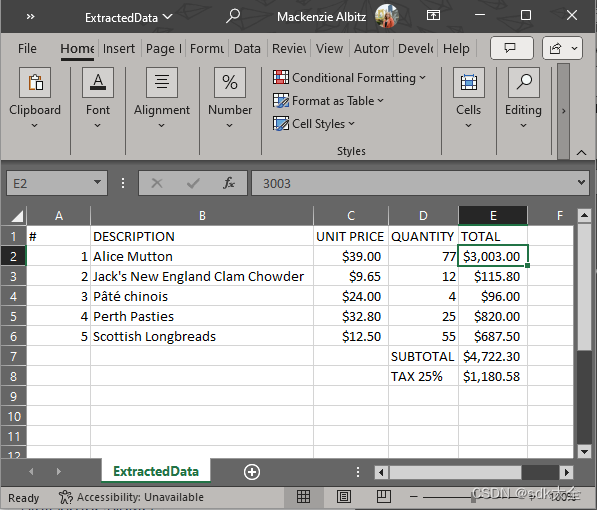 在 CSV 文件中提取 PDF 表数据
在 CSV 文件中提取 PDF 表数据奖励:将导出的 PDF 表格数据格式化为 Excel (XLSX) 文件
尽管数据现在以易于读取和操作的格式提供,但它是以 CSV 文件格式的原始格式保存的。为了更好地利用数据并使分析更容易进行,请使用 GrapeCity Documents for Excel (GcExcel) .NET 版本和 C# 将 CSV 文件加载到 Excel (XLSX) 文件中,并对提取的数据应用样式和格式。
要使用 GcExcel,请将NuGet 包“GrapeCity.Documents.Excel”添加到项目中并添加其命名空间。
using GrapeCity.Documents.Excel;初始化 GcExcel 工作簿实例并使用Open方法加载 CSV 文件。
var workbook = new GrapeCity.Documents.Excel.Workbook();workbook.Open($@"{fileName}", OpenFileFormat.Csv);获取提取数据的范围并包装单元格范围,对列应用自动调整大小,并应用带条件背景颜色的样式。
IWorksheet worksheet = workbook.Worksheets[0];
IRange range = worksheet.Range["A2:E10"];// wrapping cell content
range.WrapText = true;// styling column names
worksheet.Range["A1"].EntireRow.Font.Bold = true;// auto-sizing range
worksheet.Range["A1:E10"].AutoFit();// aligning cell content
worksheet.Range["A1:E10"].HorizontalAlignment = HorizontalAlignment.Center;
worksheet.Range["A1:E10"].VerticalAlignment = VerticalAlignment.Center;// applying conditional format on UnitPrice
IColorScale twoColorScaleRule = worksheet.Range["E2:E10"].FormatConditions.AddColorScale(ColorScaleType.TwoColorScale);twoColorScaleRule.ColorScaleCriteria[0].Type = ConditionValueTypes.LowestValue;
twoColorScaleRule.ColorScaleCriteria[0].FormatColor.Color = Color.FromArgb(255, 229, 229);twoColorScaleRule.ColorScaleCriteria[1].Type = ConditionValueTypes.HighestValue;
twoColorScaleRule.ColorScaleCriteria[1].FormatColor.Color = Color.FromArgb(255, 20, 20);Thread.Sleep(1000); 最后,使用Save方法将工作簿保存为 Excel 文件:
workbook.Save("ExtractedData_Formatted.xlsx");如您所见,使用 C# 和 GcPdf,开发人员可以以编程方式将 PDF 表格数据提取到另一个文件(如 CSV),然后使用 GcExcel,可以将数据转换为风格化和格式化的 Excel XLSX 文件,以便于数据分析:
|
|
|
|
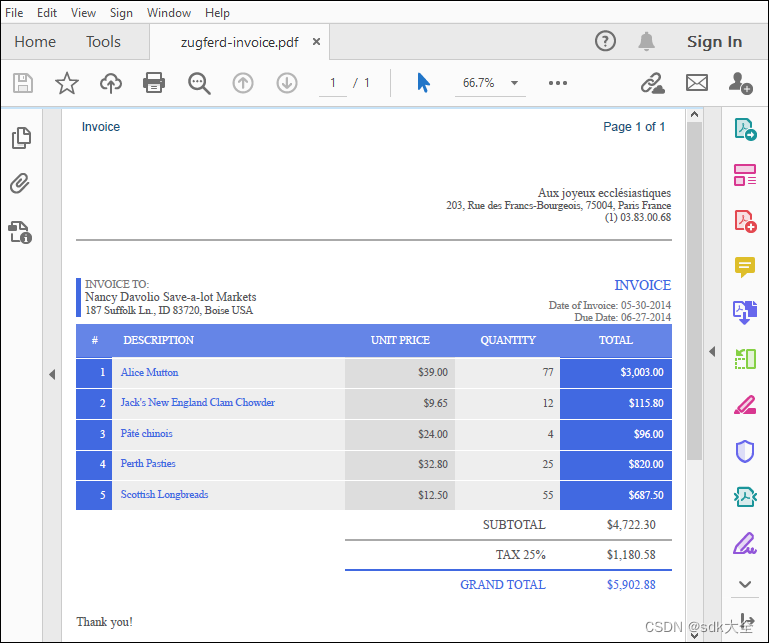 原版PDF
原版PDF 在 CSV 文件中提取 PDF 表数据
在 CSV 文件中提取 PDF 表数据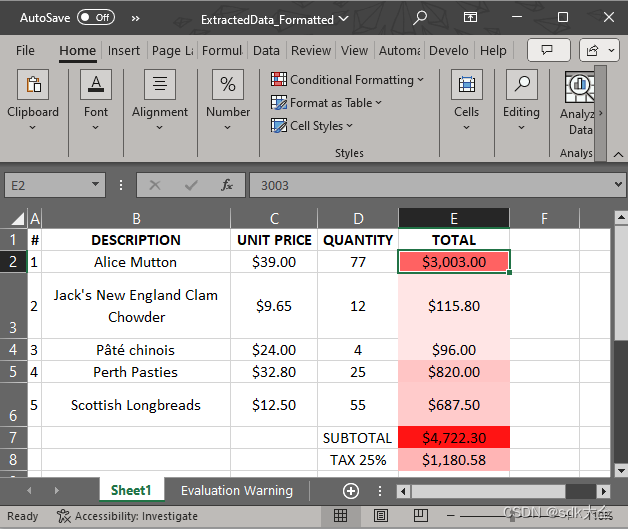 格式化 Excel XLSX 文件
格式化 Excel XLSX 文件GrapeCity 的 .NET PDF API 库
将此 .NET PDF 服务器端 API 集成到桌面或基于 Web 的应用程序中,使开发人员能够完全控制 PDF - 快速生成文档、提高内存效率且无依赖性。
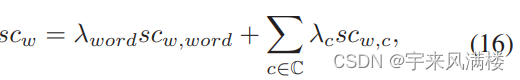



![2023年中国体育赛事行业现状及趋势分析:体育与科技逐步融合,推动产业高质量发展[图]](https://img-blog.csdnimg.cn/img_convert/2fc2b3f17b2b5ff4d1b90540be97d9f9.png)