一、部署架构了解么?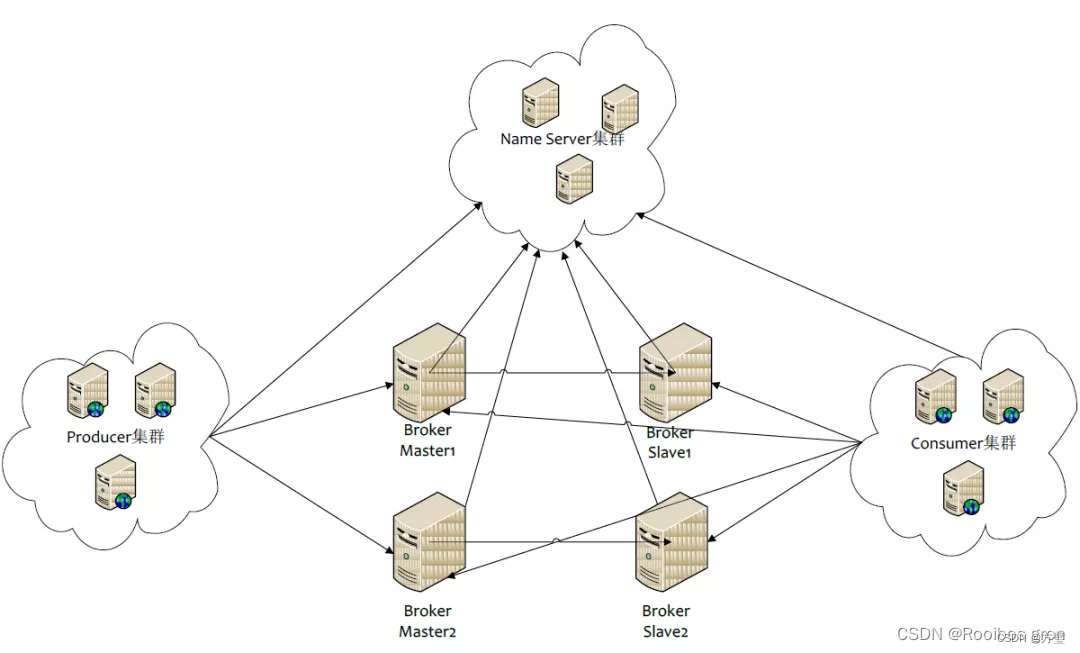
1.1、生产者
1.2、消费者
1.3、brocker
负责接收生产者的消息并且储存起来,同时转发给消费者;
1.4、nameServer
类似注册中心,所有的brocker通过长链接和nameserver链接;通过心跳的方式定期的发送消息给nameserver;每个nameserver节点是对等的;
二、部署类型
RocketMQ有4种部署类型
2.1、单Master
单机模式, 即只有一个Broker
2.1.1、优点
简单
2.1.2、缺点
高性能差
高可用差
单点问题, 如果Broker宕机了, 会导致RocketMQ服务不可用, 不推荐使用
2.2、多Master模式
组成一个集群, 集群每个节点都是Master节点, 配置简单, 性能也是最高, 某节点宕机重启不会影响RocketMQ服务
2.2.1、优点
解决了高性能
2.2.2、缺点
高可用未解决
如果某个节点宕机了, 会导致该节点存在未被消费的消息在节点恢复之前不能被消费
2.3、多Master多Slave模式,异步复制
每个Master配置一个Slave, 多对Master-Slave, Master与Slave消息采用异步复制方式, 主从消息一致只会有毫秒级的延迟
2.3.1、优点
是弥补了多Master模式(无slave)下节点宕机后在恢复前不可订阅的问题。在Master宕机后, 消费者还可以从Slave节点进行消费。采用异步模式复制,提升了一定的吞吐量。总结一句就是,采用多Master多Slave模式,异步复制模式进行部署,系统将会有较低的延迟和较高的吞吐量
2.3.2、优点
就是如果Master宕机, 磁盘损坏的情况下, 如果没有及时将消息复制到Slave, 会导致有少量消息丢失
2.4、多Master多Slave模式,同步双写
与多Master多Slave模式,异步复制方式基本一致,唯一不同的是消息复制采用同步方式,只有master和slave都写成功以后,才会向客户端返回成功
2.4.1、优点
数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
2.4.2、缺点
缺点就是会降低消息写入的效率,并影响系统的吞吐量
实际部署中,一般会根据业务场景的所需要的性能和消息可靠性等方面来选择后两种
三、rocketmq如何保证高可用性?
3.1、数据高可用
一主多从;多分数据容灾;
同步双写等;
3.2、服务高可用
3.2.1、nameServer的集群化部署
每一台nameserver都是对等的;存储的信息通过分布式同步机制,保证了数据的一致性;任何一台nameServer挂了都不影响整体的服务能力
3.2.2、broker的集群化部署
1、如果一台broker挂了,生产者通过负载均衡;会发送消息到其他broker;
2、如果一台broker的master节点挂了,consumer会自动切换到slaver节点
3.2.3、同步机制
1、异步:只要master写入成功,直接返回成功,异步复制到slave
2、同步:master和slave都写成功才返回成功
四、rocketmq的工作流程是怎样的?
1、首先启动nameServer:等待broker/productor/consumer连接上来
2、启动broker:会跟所有的NameServer建立并保持一个长连接,定时发送心跳包。心跳包中包含当前Broker信息(ip、port等)、Topic信息以及Borker与Topic的映射关系
3、创建topic:创建时需要制定topic储存在那些broker上,可以在发送消息都时候直接创建TOPIC
4、Producer发送消息:启动的时候先和NameServer集群上的一台机器建立长链接,获取到当前发送消息到TOPIC的所有boker信息;然后从队列列表中轮询选择一个队列,与队列所在的Broker建立长连接,进行消息的发送
5、Consumer消费消息:和其中一套NameServer建立长链接,获取topic在多broker,然后和broker建立长链接进行消费;
五、rocketmq的底层存储机制
5.1、commitLog顺序写
我们知道,操作系统每次从磁盘读写数据的时候,都需要找到数据在磁盘上的地址,再进行读写。而如果是机械硬盘,寻址需要的时间往往会比较长而一般来说,如果把数据存储在内存上面,少了寻址的过程,性能会好很多;
但Kafka 的数据存储在磁盘上面,依然性能很好,这是为什么呢?
这是因为,Kafka采用的是顺序写,直接追加数据到末尾。实际上,磁盘顺序写的性能极高,在磁盘个数一定,转数一定的情况下,基本和内存速度一致
因此,磁盘的顺序写这一机制,极大地保证了Kafka本身的性能
5.2、零拷贝
传统方式实现:
先读取、再发送,实际会经过以下四次复制
1、将磁盘文件,读取到操作系统内核缓冲区Read Buffer
2、将内核缓冲区的数据,复制到应用程序缓冲区Application Buffer
3、将应用程序缓冲区Application Buffer中的数据,复制到socket网络发送缓冲区
4、将Socket buffer的数据,复制到网卡,由网卡进行网络传输

传统方式,读取磁盘文件并进行网络发送,经过的四次数据copy是非常繁琐的
重新思考传统IO方式,会注意到在读取磁盘文件后,不需要做其他处理,直接用网络发送出去的这种场景下,第二次和第三次数据的复制过程,不仅没有任何帮助,反而带来了巨大的开销。那么这里使用了零拷贝,也就是说,直接由内核缓冲区Read Buffer将数据复制到网卡,省去第二步和第三步的复制。
那么采用零拷贝的方式发送消息,必定会大大减少读取的开销,使得RocketMq读取消息的性能有一个质的提升
此外,还需要再提一点,零拷贝技术采用了MappedByteBuffer内存映射技术,采用这种技术有一些限制,其中有一条就是传输的文件不能超过2G,这也就是为什么RocketMq的存储消息的文件CommitLog的大小规定为1G的原因
小结:RocketMq采用文件系统存储消息,并采用顺序写写入消息,使用零拷贝发送消息,极大得保证了RocketMq的性能
六、RocketMq的存储结构是怎样的
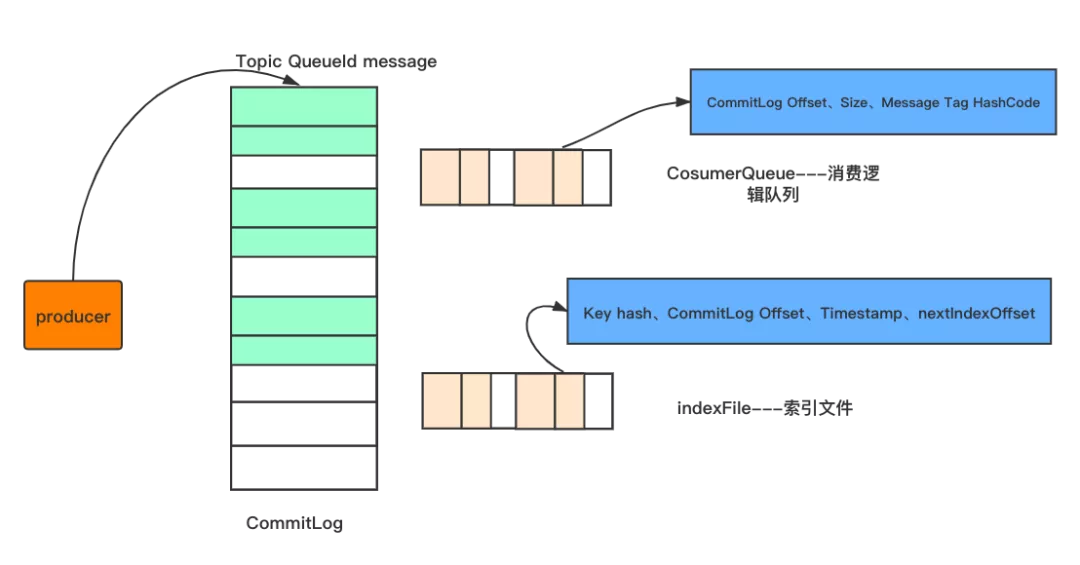
1、CommitLog-存储所有的消息元数据,包括Topic、QueueId以及message
2、CosumerQueue-消费逻辑队列:存储消息在CommitLog的offset
3、IndexFile-索引文件:存储消息的key和时间戳等信息,使得RocketMq可以采用key和时间区间来查询消息
也就是说,rocketMq将消息均存储在CommitLog中,并分别提供了CosumerQueue和IndexFile两个索引,来快速检索消息
七、RocketMq性能比较高的原因?
1、写入高性能:顺序写
2、消费的高性能:零拷贝
一、如何让RocketMQ保证消息的顺序消费
二、RocketMQ如何保证消息不丢失
三、rocketMQ的消息堆积如何处理
四、RocketMQ在分布式事务支持这块机制的底层原理?
五、让你来动手实现一个分布式消息中间件,整体架构
13、高吞吐量下如何优化生产者和消费者的性能?
开发
同一group下,多机部署,并行消费
单个Consumer提高消费线程个数
批量消费
消息批量拉取
业务逻辑批量处理
运维
网卡调优
jvm调优
多线程与cpu调优
Page Cache