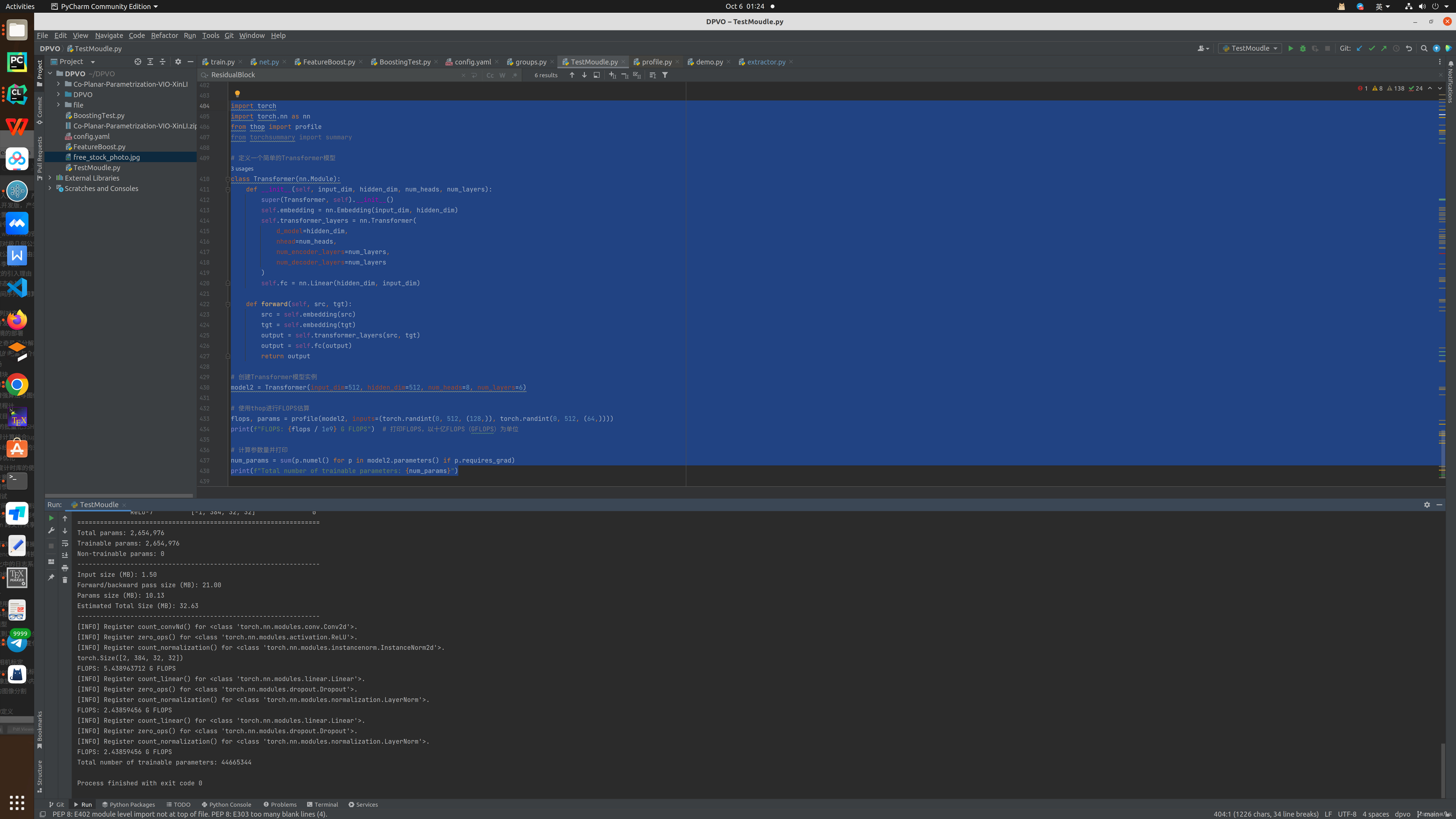
FocalNet
近些年,Transformers在自然语言处理、图像分类、目标检测和图像分割上均取得了较大的成功,归根结底是自注意力(SA :self-attention)起到了关键性的作用,因此能够支持输入信息的全局交互。但是由于视觉tokens的大量存在,自注意力的计算复杂度高,尤其是在高分辨的输入时,因此针对该缺陷,论文《Focal Modulation Networks》提出了FocalNet网络。
论文地址:Focal Modulation Networks
原理:使用新提出的Focal Modulation替代之前的SA自注意力模块,解耦聚合和单个查询过程,先将查询周围的上下文信息进行聚合,再根据聚合信息获取查询结果。如下图所示,图中红色表示query token。对比来看,Window-wise Self-Attention (SA)利用周围的token(橙色)来捕获空间上下文信息;在此基础上,Focal Attention扩大了感受野,还可以使用更远的summarized tokens(蓝色);而Focal Modulation更为强大,先利用诸如depth-wise convolution的方式将不同粒度级别的空间上下文编码为summarized tokens (橙色、绿色和蓝色),再根据查询内容,选择性的将这些summarized tokens融合为query token。而本文新提出的方式便是进行轻量化,将聚合和单个查询进行解耦,减少计算量。
在前两者中,绿色和紫色箭头分别代表注意力交互和基于查询的聚合,但是都存在一个缺陷,即:均需要涉及大量的交互和聚合操作。而Focal Modulation计算过程得到大量简化。

FocalNet代码实现
# --------------------------------------------------------
# FocalNets -- Focal Modulation Networks
# Copyright (c) 2022 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Jianwei Yang (jianwyan@microsoft.com)
# --------------------------------------------------------import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal___all__ = ['focalnet_tiny_srf', 'focalnet_tiny_lrf', 'focalnet_small_srf', 'focalnet_small_lrf', 'focalnet_base_srf', 'focalnet_base_lrf', 'focalnet_large_fl3', 'focalnet_large_fl4', 'focalnet_xlarge_fl3', 'focalnet_xlarge_fl4', 'focalnet_huge_fl3', 'focalnet_huge_fl4']def update_weight(model_dict, weight_dict):idx, temp_dict = 0, {}for k, v in weight_dict.items():if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):temp_dict[k] = vidx += 1model_dict.update(temp_dict)print(f'loading weights... {idx}/{len(model_dict)} items')return model_dictclass Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x) x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass FocalModulation(nn.Module):def __init__(self, dim, focal_window, focal_level, focal_factor=2, bias=True, proj_drop=0., use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.focal_window = focal_windowself.focal_level = focal_levelself.focal_factor = focal_factorself.use_postln_in_modulation = use_postln_in_modulationself.normalize_modulator = normalize_modulatorself.f = nn.Linear(dim, 2*dim + (self.focal_level+1), bias=bias)self.h = nn.Conv2d(dim, dim, kernel_size=1, stride=1, bias=bias)self.act = nn.GELU()self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.focal_layers = nn.ModuleList()self.kernel_sizes = []for k in range(self.focal_level):kernel_size = self.focal_factor*k + self.focal_windowself.focal_layers.append(nn.Sequential(nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1, groups=dim, padding=kernel_size//2, bias=False),nn.GELU(),)) self.kernel_sizes.append(kernel_size) if self.use_postln_in_modulation:self.ln = nn.LayerNorm(dim)def forward(self, x):"""Args:x: input features with shape of (B, H, W, C)"""C = x.shape[-1]# pre linear projectionx = self.f(x).permute(0, 3, 1, 2).contiguous()q, ctx, gates = torch.split(x, (C, C, self.focal_level+1), 1)# context aggreationctx_all = 0 for l in range(self.focal_level): ctx = self.focal_layers[l](ctx)ctx_all = ctx_all + ctx * gates[:, l:l+1]ctx_global = self.act(ctx.mean(2, keepdim=True).mean(3, keepdim=True))ctx_all = ctx_all + ctx_global * gates[:,self.focal_level:]# normalize contextif self.normalize_modulator:ctx_all = ctx_all / (self.focal_level+1)# focal modulationmodulator = self.h(ctx_all)x_out = q * modulatorx_out = x_out.permute(0, 2, 3, 1).contiguous()if self.use_postln_in_modulation:x_out = self.ln(x_out)# post linear porjectionx_out = self.proj(x_out)x_out = self.proj_drop(x_out)return x_outdef extra_repr(self) -> str:return f'dim={self.dim}'def flops(self, N):# calculate flops for 1 window with token length of Nflops = 0flops += N * self.dim * (self.dim * 2 + (self.focal_level+1))# focal convolutionfor k in range(self.focal_level):flops += N * (self.kernel_sizes[k]**2+1) * self.dim# global gatingflops += N * 1 * self.dim # self.linearflops += N * self.dim * (self.dim + 1)# x = self.proj(x)flops += N * self.dim * self.dimreturn flopsclass FocalNetBlock(nn.Module):r""" Focal Modulation Network Block.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resulotion.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.drop (float, optional): Dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormfocal_level (int): Number of focal levels. focal_window (int): Focal window size at first focal leveluse_layerscale (bool): Whether use layerscalelayerscale_value (float): Initial layerscale valueuse_postln (bool): Whether use layernorm after modulation"""def __init__(self, dim, input_resolution, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,focal_level=1, focal_window=3,use_layerscale=False, layerscale_value=1e-4, use_postln=False, use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.mlp_ratio = mlp_ratioself.focal_window = focal_windowself.focal_level = focal_levelself.use_postln = use_postlnself.norm1 = norm_layer(dim)self.modulation = FocalModulation(dim, proj_drop=drop, focal_window=focal_window, focal_level=self.focal_level, use_postln_in_modulation=use_postln_in_modulation, normalize_modulator=normalize_modulator)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)self.gamma_1 = 1.0self.gamma_2 = 1.0 if use_layerscale:self.gamma_1 = nn.Parameter(layerscale_value * torch.ones((dim)), requires_grad=True)self.gamma_2 = nn.Parameter(layerscale_value * torch.ones((dim)), requires_grad=True)self.H = Noneself.W = Nonedef forward(self, x):H, W = self.H, self.WB, L, C = x.shapeshortcut = x# Focal Modulationx = x if self.use_postln else self.norm1(x)x = x.view(B, H, W, C)x = self.modulation(x).view(B, H * W, C)x = x if not self.use_postln else self.norm1(x)# FFNx = shortcut + self.drop_path(self.gamma_1 * x)x = x + self.drop_path(self.gamma_2 * (self.norm2(self.mlp(x)) if self.use_postln else self.mlp(self.norm2(x))))return xdef extra_repr(self) -> str:return f"dim={self.dim}, input_resolution={self.input_resolution}, " \f"mlp_ratio={self.mlp_ratio}"def flops(self):flops = 0H, W = self.input_resolution# norm1flops += self.dim * H * W# W-MSA/SW-MSAflops += self.modulation.flops(H*W)# mlpflops += 2 * H * W * self.dim * self.dim * self.mlp_ratio# norm2flops += self.dim * H * Wreturn flopsclass BasicLayer(nn.Module):""" A basic Focal Transformer layer for one stage.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resolution.depth (int): Number of blocks.window_size (int): Local window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.focal_level (int): Number of focal levelsfocal_window (int): Focal window size at first focal leveluse_layerscale (bool): Whether use layerscalelayerscale_value (float): Initial layerscale valueuse_postln (bool): Whether use layernorm after modulation"""def __init__(self, dim, out_dim, input_resolution, depth,mlp_ratio=4., drop=0., drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False, focal_level=1, focal_window=1, use_conv_embed=False, use_layerscale=False, layerscale_value=1e-4, use_postln=False, use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.depth = depthself.use_checkpoint = use_checkpoint# build blocksself.blocks = nn.ModuleList([FocalNetBlock(dim=dim, input_resolution=input_resolution,mlp_ratio=mlp_ratio, drop=drop, drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer,focal_level=focal_level,focal_window=focal_window, use_layerscale=use_layerscale, layerscale_value=layerscale_value,use_postln=use_postln, use_postln_in_modulation=use_postln_in_modulation, normalize_modulator=normalize_modulator, )for i in range(depth)])if downsample is not None:self.downsample = downsample(img_size=input_resolution, patch_size=2, in_chans=dim, embed_dim=out_dim, use_conv_embed=use_conv_embed, norm_layer=norm_layer, is_stem=False)else:self.downsample = Nonedef forward(self, x, H, W):for blk in self.blocks:blk.H, blk.W = H, Wif self.use_checkpoint:x = checkpoint.checkpoint(blk, x)else:x = blk(x)if self.downsample is not None:x = x.transpose(1, 2).reshape(x.shape[0], -1, H, W)x, Ho, Wo = self.downsample(x)else:Ho, Wo = H, W return x, Ho, Wodef extra_repr(self) -> str:return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"def flops(self):flops = 0for blk in self.blocks:flops += blk.flops()if self.downsample is not None:flops += self.downsample.flops()return flopsclass PatchEmbed(nn.Module):r""" Image to Patch EmbeddingArgs:img_size (int): Image size. Default: 224.patch_size (int): Patch token size. Default: 4.in_chans (int): Number of input image channels. Default: 3.embed_dim (int): Number of linear projection output channels. Default: 96.norm_layer (nn.Module, optional): Normalization layer. Default: None"""def __init__(self, img_size=(224, 224), patch_size=4, in_chans=3, embed_dim=96, use_conv_embed=False, norm_layer=None, is_stem=False):super().__init__()patch_size = to_2tuple(patch_size)patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]self.img_size = img_sizeself.patch_size = patch_sizeself.patches_resolution = patches_resolutionself.num_patches = patches_resolution[0] * patches_resolution[1]self.in_chans = in_chansself.embed_dim = embed_dimif use_conv_embed:# if we choose to use conv embedding, then we treat the stem and non-stem differentlyif is_stem:kernel_size = 7; padding = 2; stride = 4else:kernel_size = 3; padding = 1; stride = 2self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)else:self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)if norm_layer is not None:self.norm = norm_layer(embed_dim)else:self.norm = Nonedef forward(self, x):B, C, H, W = x.shapex = self.proj(x) H, W = x.shape[2:]x = x.flatten(2).transpose(1, 2) # B Ph*Pw Cif self.norm is not None:x = self.norm(x)return x, H, Wdef flops(self):Ho, Wo = self.patches_resolutionflops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])if self.norm is not None:flops += Ho * Wo * self.embed_dimreturn flopsclass FocalNet(nn.Module):r""" Focal Modulation Networks (FocalNets)Args:img_size (int | tuple(int)): Input image size. Default 224patch_size (int | tuple(int)): Patch size. Default: 4in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000embed_dim (int): Patch embedding dimension. Default: 96depths (tuple(int)): Depth of each Focal Transformer layer.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4drop_rate (float): Dropout rate. Default: 0drop_path_rate (float): Stochastic depth rate. Default: 0.1norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.patch_norm (bool): If True, add normalization after patch embedding. Default: Trueuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False focal_levels (list): How many focal levels at all stages. Note that this excludes the finest-grain level. Default: [1, 1, 1, 1] focal_windows (list): The focal window size at all stages. Default: [7, 5, 3, 1] use_conv_embed (bool): Whether use convolutional embedding. We noted that using convolutional embedding usually improve the performance, but we do not use it by default. Default: False use_layerscale (bool): Whether use layerscale proposed in CaiT. Default: False layerscale_value (float): Value for layer scale. Default: 1e-4 use_postln (bool): Whether use layernorm after modulation (it helps stablize training of large models)"""def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,embed_dim=96, depths=[2, 2, 6, 2], mlp_ratio=4., drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, patch_norm=True,use_checkpoint=False, focal_levels=[2, 2, 2, 2], focal_windows=[3, 3, 3, 3], use_conv_embed=False, use_layerscale=False, layerscale_value=1e-4, use_postln=False, use_postln_in_modulation=False, normalize_modulator=False, **kwargs):super().__init__()self.num_layers = len(depths)embed_dim = [embed_dim * (2 ** i) for i in range(self.num_layers)]self.num_classes = num_classesself.embed_dim = embed_dimself.patch_norm = patch_normself.num_features = embed_dim[-1]self.mlp_ratio = mlp_ratio# split image into patches using either non-overlapped embedding or overlapped embeddingself.patch_embed = PatchEmbed(img_size=to_2tuple(img_size), patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim[0], use_conv_embed=use_conv_embed, norm_layer=norm_layer if self.patch_norm else None, is_stem=True)num_patches = self.patch_embed.num_patchespatches_resolution = self.patch_embed.patches_resolutionself.patches_resolution = patches_resolutionself.pos_drop = nn.Dropout(p=drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule# build layersself.layers = nn.ModuleList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=embed_dim[i_layer], out_dim=embed_dim[i_layer+1] if (i_layer < self.num_layers - 1) else None, input_resolution=(patches_resolution[0] // (2 ** i_layer),patches_resolution[1] // (2 ** i_layer)),depth=depths[i_layer],mlp_ratio=self.mlp_ratio,drop=drop_rate, drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],norm_layer=norm_layer, downsample=PatchEmbed if (i_layer < self.num_layers - 1) else None,focal_level=focal_levels[i_layer], focal_window=focal_windows[i_layer], use_conv_embed=use_conv_embed,use_checkpoint=use_checkpoint, use_layerscale=use_layerscale, layerscale_value=layerscale_value, use_postln=use_postln,use_postln_in_modulation=use_postln_in_modulation, normalize_modulator=normalize_modulator)self.layers.append(layer)self.norm = norm_layer(self.num_features)self.apply(self._init_weights)self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):return {''}@torch.jit.ignoredef no_weight_decay_keywords(self):return {''}def forward(self, x):input_size = x.size(2)scale = [4, 8, 16, 32]x, H, W = self.patch_embed(x)x = self.pos_drop(x)features = [x, None, None, None]for layer in self.layers:x, H, W = layer(x, H, W)if input_size // H in scale:features[scale.index(input_size // H)] = x# features[-1] = self.norm(features[-1]) # B L Cfor i in range(len(features)):features[i] = torch.transpose(features[i], dim0=2, dim1=1).view(-1,features[i].size(2), int(features[i].size(1) ** 0.5), int(features[i].size(1) ** 0.5))return featuresdef flops(self):flops = 0flops += self.patch_embed.flops()for i, layer in enumerate(self.layers):flops += layer.flops()flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)flops += self.num_features * self.num_classesreturn flopsmodel_urls = {"focalnet_tiny_srf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_tiny_srf.pth","focalnet_tiny_lrf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_tiny_lrf.pth","focalnet_small_srf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_small_srf.pth","focalnet_small_lrf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_small_lrf.pth","focalnet_base_srf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_base_srf.pth","focalnet_base_lrf": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_base_lrf.pth", "focalnet_large_fl3": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_large_lrf_384.pth", "focalnet_large_fl4": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_large_lrf_384_fl4.pth", "focalnet_xlarge_fl3": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_xlarge_lrf_384.pth", "focalnet_xlarge_fl4": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_xlarge_lrf_384_fl4.pth", "focalnet_huge_fl3": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_huge_lrf_224.pth", "focalnet_huge_fl4": "https://projects4jw.blob.core.windows.net/focalnet/release/classification/focalnet_huge_lrf_224_fl4.pth",
}def focalnet_tiny_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_tiny_srf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_small_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_small_srf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_base_srf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, **kwargs)if pretrained:url = model_urls['focalnet_base_srf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_tiny_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_tiny_lrf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_small_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, **kwargs)if pretrained:url = model_urls['focalnet_small_lrf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_base_lrf(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, **kwargs)if pretrained:url = model_urls['focalnet_base_lrf']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_tiny_iso(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=192, **kwargs)if pretrained:url = model_urls['focalnet_tiny_iso']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_small_iso(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=384, **kwargs)if pretrained:url = model_urls['focalnet_small_iso']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_base_iso(pretrained=False, **kwargs):model = FocalNet(depths=[12], patch_size=16, embed_dim=768, focal_levels=[3], focal_windows=[3], use_layerscale=True, use_postln=True, **kwargs)if pretrained:url = model_urls['focalnet_base_iso']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return model# FocalNet large+ models
def focalnet_large_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=192, **kwargs)if pretrained:url = model_urls['focalnet_large_fl3']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_large_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=192, **kwargs)if pretrained:url = model_urls['focalnet_large_fl4']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_xlarge_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=256, **kwargs)if pretrained:url = model_urls['focalnet_xlarge_fl3']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_xlarge_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=256, **kwargs)if pretrained:url = model_urls['focalnet_xlarge_fl4']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_huge_fl3(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=352, **kwargs)if pretrained:url = model_urls['focalnet_huge_fl3']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modeldef focalnet_huge_fl4(pretrained=False, **kwargs):model = FocalNet(depths=[2, 2, 18, 2], embed_dim=352, **kwargs)if pretrained:url = model_urls['focalnet_huge_fl4']checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")model.load_state_dict(update_weight(model.state_dict(), checkpoint["model"]))return modelif __name__ == '__main__':from copy import deepcopyimg_size = 640x = torch.rand(16, 3, img_size, img_size).cuda()model = focalnet_tiny_srf(pretrained=True).cuda()# model_copy = deepcopy(model)for i in model(x):print(i.size())flops = model.flops()print(f"number of GFLOPs: {flops / 1e9}")n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)print(f"number of params: {n_parameters}")print(list(model_urls.keys()))
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)# Parse a YOLOv5 model.yaml dictionaryLOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')if act:Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()LOGGER.info(f"{colorstr('activation:')} {act}") # printna = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)is_backbone = Falselayers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argstry:t = mm = eval(m) if isinstance(m, str) else m # eval stringsexcept:passfor j, a in enumerate(args):with contextlib.suppress(NameError):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept:args[j] = an = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in {Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, 8)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2elif isinstance(m, str):t = mm = timm.create_model(m, pretrained=args[0], features_only=True)c2 = m.feature_info.channels()elif m in {focalnet_tiny_srf}: #可添加更多Backbonem = m(*args)c2 = m.channelelse:c2 = ch[f]if isinstance(c2, list):is_backbone = Truem_ = mm_.backbone = Trueelse:m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []if isinstance(c2, list):ch.extend(c2)for _ in range(5 - len(ch)):ch.insert(0, 0)else:ch.append(c2)return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)if hasattr(m, 'backbone'):x = m(x)for _ in range(5 - len(x)):x.insert(0, None)for i_idx, i in enumerate(x):if i_idx in self.save:y.append(i)else:y.append(None)x = x[-1]else:x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return x
创建新的.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, focalnet_tiny_srf, [False]], # 4[-1, 1, SPPF, [1024, 5]], # 5]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]], # 6[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7[[-1, 3], 1, Concat, [1]], # cat backbone P4 8[-1, 3, C3, [512, False]], # 9[-1, 1, Conv, [256, 1, 1]], # 10[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11[[-1, 2], 1, Concat, [1]], # cat backbone P3 12[-1, 3, C3, [256, False]], # 13 (P3/8-small)[-1, 1, Conv, [256, 3, 2]], # 14[[-1, 10], 1, Concat, [1]], # cat head P4 15[-1, 3, C3, [512, False]], # 16 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]], # 17[[-1, 5], 1, Concat, [1]], # cat head P5 18[-1, 3, C3, [1024, False]], # 19 (P5/32-large)[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]