1.深度学习框架(Tensorflow、Pytorch)
1.1由来
可以追溯到2016年,当年最著名的事件是alphago战胜人类围棋巅峰柯洁,在那之后,学界普遍认为人工智能已经可以在一些领域超过人类,未来也必将可以在更多领域超过人类,所以时隔多年,人工智能再次成为业界研究的热点,但因为深度学习需要的计算量很大,对硬件要求高,过高的门槛很不利于技术的研发和推广,所以出现了国外包括:Tensorflow(谷歌)、Pytorch(脸书),Mxbet(亚马逊);国内包括:MegEngine(旷视天元),paddlepaddle(百度),Mindspore(华为),TNN(腾讯),Jittor(清华)等开源深度学习框架,可以提高计算速度,减轻对硬件的依赖。
1.2作用
首先我们要明确,深度学习是一个计算问题,我们所采取的一切策略都是为了提高计算的便利性和速率。在这个基础上有了深度学习框架,那么深度学习框架又是如何简化计算的呢,通常可以归为三类:
1.代替numpy(numpy能实现数值计算)使用GPU对Tensor进行操作,实现神经网络的操作
补充1:NumPy 是 Python 语言的一个第三方库,其支持大量高维度数组与矩阵运算。此外,NumPy 也针对数组运算提供大量的数学函数。机器学习涉及到大量对数组的变换和运算,NumPy 就成了必不可少的工具之一。
补充2:随着数据爆炸式增长,尤其是图像数据、音频数据等数据的快速增长,NumPy的计算能力遇到了瓶颈,迫切需要突破NumPy性能上的瓶颈,最终在硬件和软件上都有了突破,如硬件有GPU,软件有Theano(早期框架)、TensorFlow,算法有卷积神经网络、循环神经网络等。
GPU和CPU:简单理解,CPU一般由4或6个核组成,以此模拟出8个或12个处理进程来运算。但普通的GPU就包含了几百个核,高端的有上万个核,如果把一个核视为一个并行计算路径,CPU仅可以提供几个或者几十个并行计算的能力,GPU可以提供几万个并行计算的能力。所以说GPU专门为人工智能开发并不为过。
2.提供自动求导/求微分/求梯度的机制,让神经网络实现变得容易
3.内置许多基本网络组件,比如全连接网络,CNN,RNN/LSTM等,简化代码工作,让研究者可以专注于模型设计等其他步骤,减少编程。
1.3框架分析
一般来讲深度学习框架都包含以下五个核心组件:
1.张量(Tensor)
补充:可以简单理解为,标量是0维张量,向量是1维张量,矩阵是二维张量,将多个矩阵组合成一个新的数组,可以得到一个 3维张量,将多个 3维 张量组合成一个数组,可以创建一个 4维 张量,以此类推。深度学习处理的一般是 0维到 4维的张量,但处理视频数据时可能会遇到5维张量。
延深:
时间序列数据或序列数据:3D 张量,形状为 (samples, timesteps, features) 。
图像:4D张量,形状为 (samples, height, width, channels) 或 (samples, channels,
height, width) 。
视频:5D张量,形状为 (samples, frames, height, width, channels) 或 (samples,frames, channels, height, width) 。
2.基于张量的各种操作
补充:由于张量和张量的操作很多,难以理清关系的话可能会引发许多问题,比如:多个操作之间应该并行还是顺次执行,如何协同各种不同的底层设备,以及如何避免各种类型的冗余操作等等。这些问题有可能拉低整个深度学习网络的运行效率或者引入不必要的Bug,所以有了计算图的诞生。
3.计算图(Computation Graph)
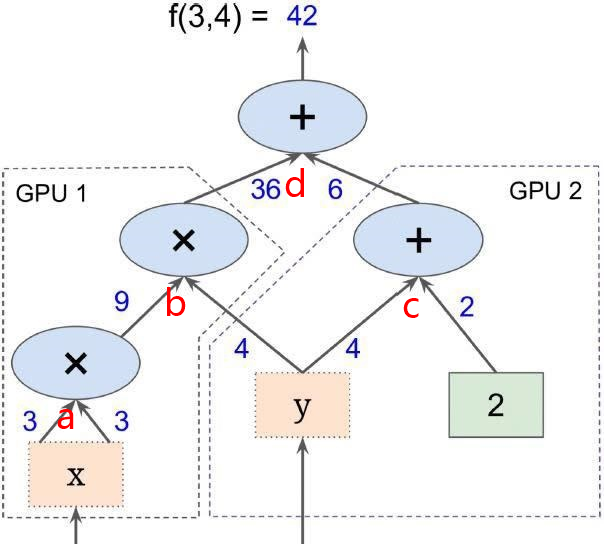
补充:计算图支持并行计算,如下图所示为一个简单的计算图,我们希望可以有固定的计算框架,仅输入相应值便可以得到计算结果,下图所包含的公式包括:
GPU1:① x*x=a ② x+y=b
GPU2 :③y+2=c
结果:④b+c=d
简单理解:计算图可以简单理解为下图的计算框架,我们仅用输入x=3,y=4就可以通过并行计算快速得到结果,而如果没有并行计算,通常会按照①②③④的顺序,进行串行计算,效率就会大大下降。在深度学习计算中,计算过程被分为无数个小模块进行并行计算,大大提高了计算速率。
结论:计算图的引入,使得开发者可以从俯瞰神经网络的内部结构,类似于编译器可以从整个代码的角度决定如何分配寄存器,计算图也可以决定代码运行时的GPU内存分配,以及分布式环境中不同底层设备间的相互协作方式。除此之外,现在也有许多深度学习框架将计算图应用于模型调试,可以实时输出当前某一操作类型的文本描述。
张量+基于张量的各种操作+计算图=加速计算
4.自动微分(Automatic Differentiation)工具
传统求解微分方式的缺点:针对一些非线性过程(如修正线性单元ReLU)或者大规模的问题,使用符号微分法成本高,甚至无法微分。
自动微分:相对于传统符号微分法,更加简单、高效、适应面更广。
5.BLAS、cuBLAS、cuDNN等拓展包(运算库)
问题:人工智能编程现在主要使用Python,虽然简单方便,但高级语言也会比底层语言(C++)消耗更多的CPU周期,更这在深度神经网络上尤为明显,因此运算缓慢就成了高级语言的缺陷。
解决:为了提高运算速度,就有了拓展包。最初用Fortran实现的BLAS( basic linear algebra subroutine,基础线性代数子程序),是一个非常优秀的基本矩阵(张量)运算库,此外还有英特尔的MKL(Math Kernel Library)等,开发者可以根据个人喜好灵活选择。一般的BLAS库只是针对普通的CPU场景进行了优化,但目前大部分的深度学习模型都已经开始采用并行GPU的运算模式,因此利用诸如NVIDIA推出的针对GPU优化的cuBLAS和cuDNN等更据针对性的库可能是更好的选择。
最后:要注意一些部署模型加速的工具GPU(英伟达的TensorRT),CPU(英特尔公司的OpenVINO)
2.Ray
简介:下一代人工智能应用程序将不断与环境交互,并从这些交互中学习。这些应用程序在性能和灵活性方面都对系统提出了新的和苛刻的要求。在本文中,我们考虑了这些需求,并提出了一个分布式系统来解决这些需求。ray实现了一个统一的接口,该接口可以表示任务并行计算和基于actor的计算,并由单个动态执行引擎支持。为了满足性能要求,Ray采用分布式调度程序和分布式容错存储来管理系统的控制状态。在我们的实验中,我们展示了超越每秒180万个任务的扩展能力,并且在一些具有挑战性的强化学习应用程序中比现有的专业系统具有更好的性能。
问题:在强化学习中的进化策略(论文《Evolution Strategies as a Scalable Alternative to Reinforcement Learning》)中算法包含数十行伪代码,其中的 Python 实现也并不多。然而,在较大的机器或集群上运行它需要更多的软件工程工作。作者的实现包含了上千行代码,以及必须定义的通信协议、信息序列化、反序列化策略,以及各种数据处理策略。
解决:Ray 可以实现让一个运行在笔记本电脑上的原型算法,仅需添加数行代码就能轻松转为适合于计算机集群运行的(或单个多核心计算机的)高性能分布式应用。这样的框架需要包含手动优化系统的性能优势,同时又不需要用户关心那些调度、数据传输和硬件错误等问题。
与深度学习框架:Ray 与 TensorFlow、PyTorch 和 MXNet 等深度学习框架互相兼容,可以,在很多应用上,在 Ray 中使用一个或多个深度学习框架都是非常自然的(例如,UC Berkeley 的强化学习库就用到了很多 TensorFlow 与 PyTorch)。
参考文献
1.深度学习框架有什么作用?_深度学习框架有什么用-CSDN博客
2.python学习笔记之numpy库的使用——超详细_手机插上u盘怎么传文件-CSDN博客
3. 什么是GPU?跟CPU有什么区别?终于有人讲明白了-CSDN博客
4.如何理解TensorFlow计算图? - 知乎
5.为什么Tensorflow需要使用"图计算"来表示计算过程-CSDN博客
6.什么是张量(Tensor)_醉Dowry的博客-CSDN博客
7.[深度学习]TensorRT为什么能让模型跑快快 - 知乎
8.PyTorch & 分布式框架 Ray :保姆级入门教程_分布式自然进化策略使用pytorch和ray构建_HyperAI超神经的博客-CSDN博客9.伯克利AI分布式框架Ray,兼容TensorFlow、PyTorch与MXNet-CSDN博客