诸神缄默不语-个人CSDN博文目录
这是我2020年写的笔记,我从印象笔记搬过来公开。
如果那年还在读本科的同学也许有印象,那年美赛出了道根据电商评论给商户提建议的题。其实这件事跟推荐系统关系不大,但我们当时病急乱投医,我打开了这本书。
然后发现还蛮好玩的就看完了。
这本书写于2012年,哦多么古早的时代……
小书,读得很快,但是能让用户迅速对早期推荐系统有个通览的了解。
如果我以后真的干推荐系统了,可能会再回来更新相应笔记内容。
文章目录
- 第一章 好的推荐系统
- 第二章 利用用户行为数据
- 2.1 用户行为数据
- 2.2 用户行为分析
- 第三章 推荐系统冷启动问题
- 第四章 利用用户标签数据
- 第五章 利用上下文信息
- 第六章 利用社交网络数据
- 第七章 推荐系统实例
- 第八章 评分预测问题
- 其他来源的相关参考资料
- 豆瓣书评
- 知乎
- CSDN
- 博客园
- 豆瓣用户整理的附录和参考资料
第一章 好的推荐系统
- 在推荐系统中,主要有3种评测推荐效果的实验方法,即离线实验( offline experiment)、用户调查( user study)和在线实验( online experiment)。
- 离线实验
离线实验的方法一般由如下几个步骤构成:- 通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
- 将数据集按照一定的规则分成训练集和测试集;
- 在训练集上训练用户兴趣模型,在测试集上进行预测;
- 通过事先定义的离线指标评测算法在测试集上的预测结果。
- 用户调查:尽量是双盲实验
- 在线实验:AB测试
- 周期长
- 切分流量(正交):控制变量,以防互相干扰
- 离线实验
- 推荐系统评测指标
- 用户满意度
- 用户调查:问卷
- 在线实验:一些对用户行为的统计
- 预测准确度:离线数据集做机器学习
- 评分预测
- RMSE,MAE
- Netflix认为RMSE加大了对预测不准的用户物品评分的惩罚(平方项的惩罚),因而对系统的评测更加苛刻。研究表明,如果评分系统是基于整数建立的(即用户给的评分都是整数),那么对预测结果取整会降低MAE的误差
- TopN推荐: 给用户一个个性化的推荐列表
- 准确率( precision) /召回率( recall)
- 用户在训练集上的行为给用户作出的推荐列表
- 用户在测试集上的行为列表
- 有的时候,为了全面评测TopN推荐的准确率和召回率,一般会选取不同的推荐列表长度N,计算出一组准确率/召回率,然后画出准确率/召回率曲线( precision/recall curve)
- 覆盖率( coverage):描述一个推荐系统对物品长尾的发掘能力
- 最简单的定义:推荐系统能够推荐出来的物品占总物品集合的比例
- 内容提供商会关心这一指标
- 其他衡量指标:信息熵、基尼系数

- 多样性


- 新颖性:给用户推荐那些他们以前没有听说过的物品
- 惊喜度 (serendipity):如果推荐结果和用户的历史兴趣不相似,但却让用户觉得满意,那么就可以说推荐结果的惊喜度很高,而推荐的新颖性仅仅取决于用户是否听说过这个推荐结果
- 信任度( trust)
- 提高推荐系统的信任度的方法
- 增加推荐系统的透明度( transparency):主要办法是提供推荐解释。只有让用户了解推荐系统的运行机制,让用户认同推荐系统的运行机制,才会提高用户对推荐系统的信任度
- 考虑用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推荐解释。这是因为用户对他们的好友一般都比较信任,因此如果推荐的商品是好友购买过的,那么他们对推荐结果就会相对比较信任。
- 提高推荐系统的信任度的方法
- 实时性
- 实时地更新推荐列表来满足用户新的行为变化
- 推荐系统需要能够将新加入系统的物品推荐给用户
- 健壮性(即robust,鲁棒性)指标:一个推荐系统抗击作弊的能力
- 著名作弊方法: 行为注入攻击 ( profile injection attack)
- 评测的主要方法:模拟攻击
- 提高系统健壮性的方法
- 选择健壮性高的算法
- 设计推荐系统时尽量使用代价比较高的用户行为
- 在使用数据前,进行攻击检测,从而对数据进行清理
- 商业目标

- 评测维度
- 用户维度:主要包括用户的人口统计学信息、活跃度以及是不是新用户等。
- 物品维度:包括物品的属性信息、流行度、平均分以及是不是新加入的物品等。
- 时间维度:包括季节,是工作日还是周末,是白天还是晚上等。
- 评分预测
- 用户满意度
第二章 利用用户行为数据
2.1 用户行为数据
- 日志 会话日志
- 显性反馈行为( explicit feedback)和隐性反馈行为( implicit feedback)
- 正反馈和负反馈
2.2 用户行为分析
- 用户活跃度和物品流行度的分布:长尾分布 Power Law
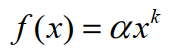
- 协同过滤算法
- 基于邻域的方法( neighborhood-based)
- 基于用户的协同过滤算法:这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于用户的协同过滤算法主要包括两个步骤:- 第一步:找到和目标用户兴趣相似的用户集合。
- 关键:计算两个用户的兴趣相似度
- 协同过滤算法主要利用行为的相似度计算兴趣的相似度
- 第二步:找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
- 物品-用户倒排表
- UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品

- 缺点
- 首先,随着网站的用户数目越来越大,计算用户兴趣相似度矩阵将越来越困难,其运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系
- 其次,基于用户的协同过滤很难对推荐结果作出解释
- 第一步:找到和目标用户兴趣相似的用户集合。
- 基于物品的协同过滤算法ItemCF:这种算法给用户推荐和他之前喜欢的物品相似的物品
基于物品的协同过滤算法主要分为两步:- 第一步:计算物品之间的相似度。
- 第二步:根据物品的相似度和用户的历史行为给用户生成推荐列表。
- 用ItemCF算法计算物品相似度时也可以首先建立用户—物品倒排表(即对每个用户建立一个包含他喜欢的物品的列表),然后对于每个用户,将他物品列表中的物品两两在共现矩阵C中加1。



- 哈利波特问题:惩罚热门商品
- 基于用户的协同过滤算法:这种算法给用户推荐和他兴趣相似的其他用户喜欢的物品。
- LFM隐语义模型( latent factor model)
- 物品分类(属于每个类的权重)

- 隐性反馈行为的负样本采集
- 物品分类(属于每个类的权重)
- 基于图的随机游走算法( random walk on graph)
- 用户行为数据的二分图表示
- 基于图的推荐算法
- 给用户u推荐物品的任务就可以转化为度量用户顶点和与没有边直接相连的物品节点在图上的相关性,相关性越高的物品在推荐列表中的权重就越高。
- 一般来说图中顶点的相关性主要取决于下面3 个因素:
- 两个顶点之间的路径数
- 两个顶点之间路径的长度
- 两个顶点之间的路径经过的顶点
- 基于随机游走的PersonalRank算法
- 基于邻域的方法( neighborhood-based)
第三章 推荐系统冷启动问题
- 用户冷启动
- 物品冷启动
- 系统冷启动
- 提供非个性化的推荐:非个性化推荐的最简单例子就是热门排行榜,我们可以给用户推荐热门排行榜,然后等到用户数据收集到一定的时候,再切换为个性化推荐。
- 利用用户注册时提供的年龄、性别等数据做粗粒度的个性化。
- 用户的注册信息分3种:
- 人口统计学信息:包括用户的年龄、性别、职业、民族、学历和居住地。
- 用户兴趣的描述:有一些网站会让用户用文字描述他们的兴趣。
- 从其他网站导入的用户站外行为数据:比如用户通过豆瓣、新浪微博的账号登录,就可以在得到用户同意的情况下获取用户在豆瓣或者新浪微博的一些行为数据和社交网络数据。
- 基于注册信息的个性化推荐流程基本如下:
- (1) 获取用户的注册信息;
- (2) 根据用户的注册信息对用户分类;
- (3) 给用户推荐他所属分类中用户喜欢的物品。
- 利用用户的社交网络账号登录(需要用户授权),导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。
- 要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。
- 启动物品的特点:比较热门、具有代表性和区分性、启动物品集合要有多样性
- 决策树

- 对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们相似的物品的用户。

- 话题模型LDA(物品的话题分布相似度:KL散度)
- 在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
第四章 利用用户标签数据

- 标签:特征表现方式
- 根据给物品打标签的人的不同,标签应用一般分为两种
- 一种是让作者或者专家给物品打标签
- 另一种是让普通用户给物品打标签,也就是UGC( User Generated Content,用户生成的内容)的标签应用。
- UGC
- 标签系统中的推荐问题主要有以下两个。
- 如何利用用户打标签的行为为其推荐物品(基于标签的推荐)?
- 如何在用户给物品打标签时为其推荐适合该物品的标签(标签推荐)?
- 标签扩展(标签相似度)
- 话题模型
- 基于邻域的方法

- 标签清理
- 有的标签不反应用户兴趣
- 有的标签是同义词
- 将标签作为推荐解释
- 方法
- 去除词频很高的停止词
- 去除因词根不同造成的同义词
- 去除因分隔符造成的同义词
- 基于图的推荐算法
- 节点:用户、物品、标签
- SimpleTagGraph
- PersonalRank
- 给用户推荐标签
- 方便用户输入
- 提高数据质量(同义词)
- 推荐的标签:热门标签,该物品常用,该用户常用
- 对新用户/新物品
- 抽取关键词作为标签
- 扩展标签(见上)
- 基于图的标签推荐算法
第五章 利用上下文信息
- 时间
- 用户历史兴趣变化
- 物品生命周期
- 季节效应
- 节日效应
- 推荐算法的时间多样性
- 实时推荐系统
- 在生成推荐结果时加入一定的随机性
- 对较久远的行为降权
- 随机应用不同的推荐算法
- 最近最热门
- ItemCF算法(数学衰减函数)
- UserCF算法(相似兴趣用户的最近行为)
- 时间段图模型(路径融合算法)
- 地点
- 基于位置的服务LBS
- (明尼苏达大学)LARS位置感知推荐系统
- 物品/用户:有无空间属性
- 用户有地理位置——金字塔模型:树,ItemCF。每一层训练推荐模型,叠加
- 物品有地理位置——TravelPenalty
- 心情
第六章 利用社交网络数据
- 社会化推荐
- 增加推荐的信任度
- 解决冷启动问题
- 社交图谱/兴趣图谱
- 双向确认的社交网络数据/单向关注的社交网络数据/基于社区的社交网络数据
- 基于邻域的社会化推荐算法
- 用户之间的熟悉程度(共同好友比例)
- 用户之间的兴趣相似度
- 图
- friendship/membership(同一社区)
- 时效问题——解决方案:做截断(只用相似度最高的N个好友、只用1个月的行为等)、重新设计数据库(Twitter的消息队列,每次更新都把所有人的写一遍)
- 评测:用户调查和在线实验(AB Test)
- 信息流推荐(Facebook的EdgeRank)
- 给用户推荐好友:链路预测link prediction
- 基于内容的匹配
- 基于共同兴趣的好友
- 基于社交网络图的好友推荐
- 随机图
- 中心度
第七章 推荐系统实例
外围架构
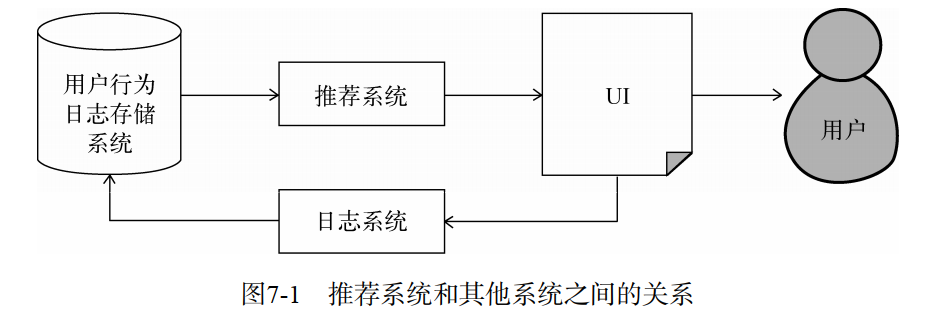
按照前面数据的规模和是否需要实时存取,不同的行为数据将被存储在不同的媒介中。一般来说,需要实时存取的数据存储在数据库和缓存中,而大规模的非实时地存取数据存储在分布式文件系统(如HDFS)中。
- 推荐系统架构
- 生成用户特征(人口统计学特征、行为特征、话题特征(历史行为→话题模型))
- 根据特征找到物品
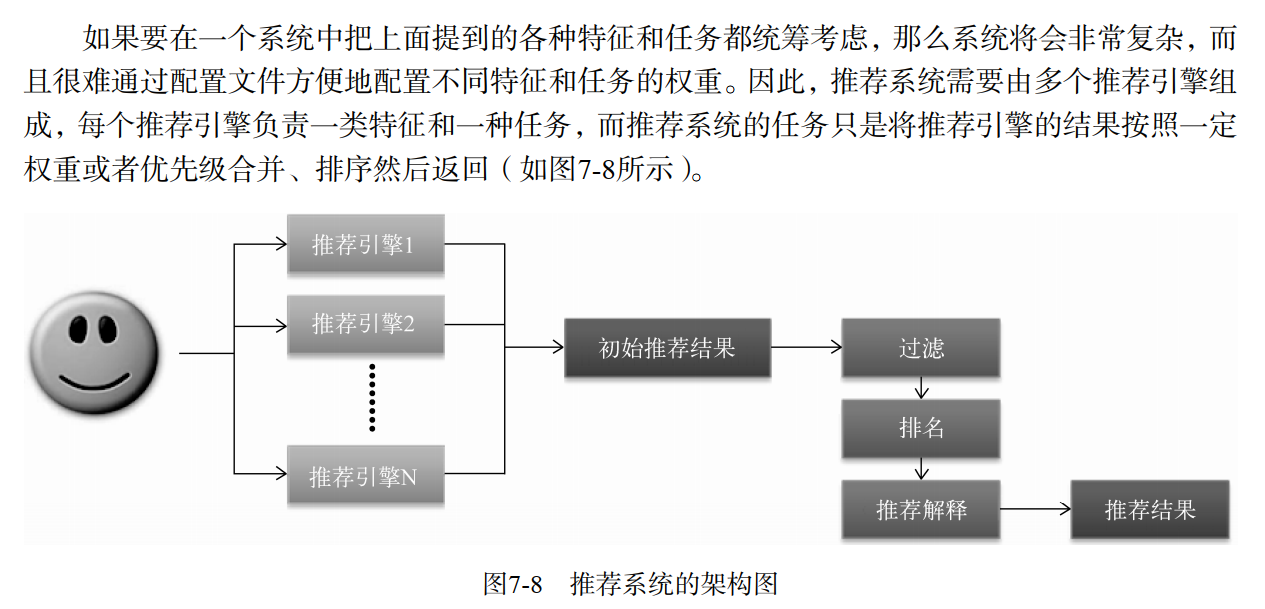
- 推荐引擎架构
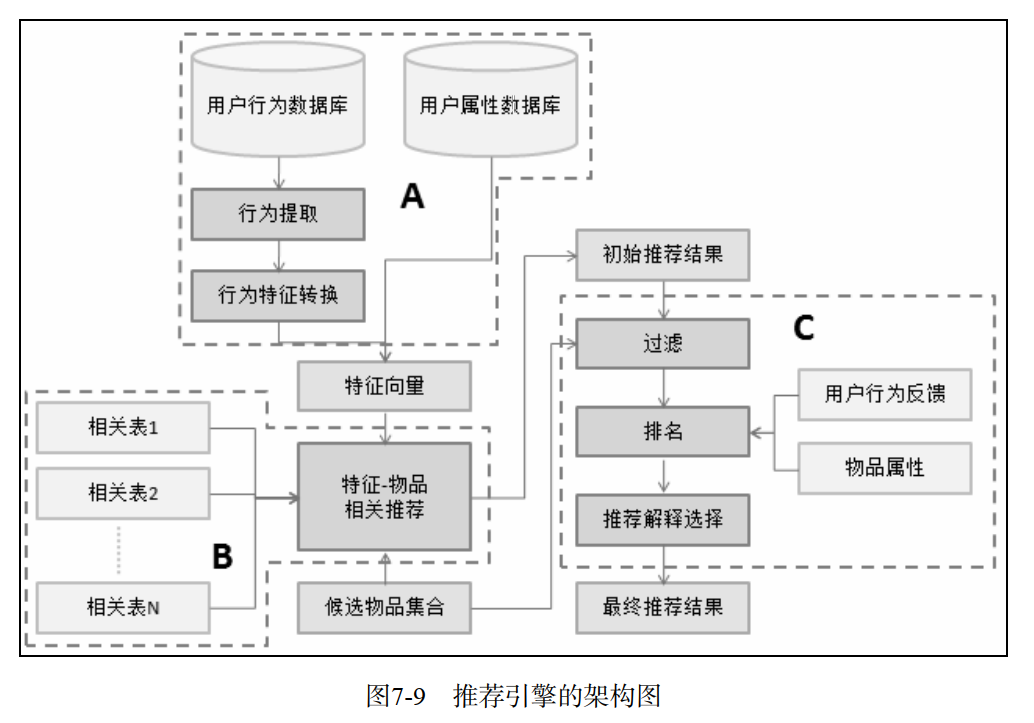
- 生成用户特征向量
- 特征和特征的权重
- 用户行为的种类(代价反映的偏爱)
- 用户行为产生的时间
- 用户行为的次数
- 物品的热门程度
- 生成用户推荐物品列表
- 过滤(用户已经产生过行为物品、候选物品以外的物品、某些质量很差的物品(用户评分))
- 排名
- 新颖性排名(内容相似度矩阵)
- 多样性(内容、属性上的)
- 时间多样性(实时性)
- 用户反馈(点击模型)
- 生成用户特征向量
第八章 评分预测问题
- 前:TopN推荐
- 按时间划分数据集
- 评分预测算法
- 平均值
- 全局平均值
- 用户评分平均值
- 物品评分平均值
- 用户分类对物品分类的平均值
- 分类: 用户和物品的平均分, 用户活跃度和物品流行度
- 基于邻域的方法
- 隐语义模型与矩阵分解模型: 如何通过降维的方法将评分矩阵补全
- SVD分解
- Funk-SVD/LFM
- 加入偏置项后的LFM
- 考虑邻域影响的LFM
- 加入时间信息
- 基于邻域的模型融合时间信息
- 基于矩阵分解的模型融合时间信息
- 模型融合
- 模型级联融合
- 模型加权融合
- 平均值
其他来源的相关参考资料
豆瓣书评
- 新一代推荐系统包含三个子模块
- 前台的展示页面
- 后台的日志系统
- 推荐算法系统
- 社交网站的API接口:好友行为
知乎
- 入门推荐系统,你不应该错过的知识清单 - 第四范式 先荐的文章 - 知乎
- 推荐系统入门要点哪些技能树? - 知乎
CSDN
- 《推荐系统实践》项亮 书中程序实现
- 推荐系统案例
博客园
- 协同滤波 Collaborative filtering 《推荐系统实践》 第二章
豆瓣用户整理的附录和参考资料
附上Reference 中的干货 (Paper,Blog等资料的链接)
http://en.wikipedia.org/wiki/Information_overload
P1
http://www.readwriteweb.com/archives/recommender_systems.php
(A Guide to Recommender System) P4
http://en.wikipedia.org/wiki/Cross-selling
(Cross Selling) P6
http://blog.kiwitobes.com/?p=58 , http://stanford2009.wikispaces.com/
(课程:Data Mining and E-Business: The Social Data Revolution) P7
http://thesearchstrategy.com/ebooks/an%20introduction%20to%20search%20engines%20and%20web%20navigation.pdf
(An Introduction to Search Engines and Web Navigation) p7
http://www.netflixprize.com/
p8
http://cdn-0.nflximg.com/us/pdf/Consumer_Press_Kit.pdf
p9
http://stuyresearch.googlecode.com/hg-history/c5aa9d65d48c787fd72dcd0ba3016938312102bd/blake/resources/p293-davidson.pdf
(The Youtube video recommendation system) p9
http://www.slideshare.net/plamere/music-recommendation-and-discovery
( PPT: Music Recommendation and Discovery) p12
http://www.facebook.com/instantpersonalization/
P13
http://about.digg.com/blog/digg-recommendation-engine-updates
(Digg Recommendation Engine Updates) P16
http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en//pubs/archive/36955.pdf
(The Learning Behind Gmail Priority Inbox)p17
http://www.grouplens.org/papers/pdf/mcnee-chi06-acc.pdf
(Accurate is not always good: How Accuracy Metrics have hurt Recommender Systems) P20
http://www-users.cs.umn.edu/~mcnee/mcnee-cscw2006.pdf
(Don’t Look Stupid: Avoiding Pitfalls when Recommending Research Papers)P23
http://www.sigkdd.org/explorations/issues/9-2-2007-12/7-Netflix-2.pdf
(Major componets of the gravity recommender system) P25
http://cacm.acm.org/blogs/blog-cacm/22925-what-is-a-good-recommendation-algorithm/fulltext
(What is a Good Recomendation Algorithm?) P26
http://research.microsoft.com/pubs/115396/evaluationmetrics.tr.pdf
(Evaluation Recommendation Systems) P27
http://mtg.upf.edu/static/media/PhD_ocelma.pdf
(Music Recommendation and Discovery in the Long Tail) P29
http://ir.ii.uam.es/divers2011/
(Internation Workshop on Novelty and Diversity in Recommender Systems) p29
http://www.cs.ucl.ac.uk/fileadmin/UCL-CS/research/Research_Notes/RN_11_21.pdf
(Auralist: Introducing Serendipity into Music Recommendation ) P30
http://www.springerlink.com/content/978-3-540-78196-7/#section=239197&page=1&locus=21
(Metrics for evaluating the serendipity of recommendation lists) P30
http://dare.uva.nl/document/131544
(The effects of transparency on trust in and acceptance of a content-based art recommender) P31
http://brettb.net/project/papers/2007%20Trust-aware%20recommender%20systems.pdf
(Trust-aware recommender systems) P31
http://recsys.acm.org/2011/pdfs/RobustTutorial.pdf
(Tutorial on robutness of recommender system) P32
http://youtube-global.blogspot.com/2009/09/five-stars-dominate-ratings.html
(Five Stars Dominate Ratings) P37
http://www.informatik.uni-freiburg.de/~cziegler/BX/
(Book-Crossing Dataset) P38
http://www.dtic.upf.edu/~ocelma/MusicRecommendationDataset/lastfm-1K.html
(Lastfm Dataset) P39
http://mmdays.com/2008/11/22/power_law_1/
(浅谈网络世界的Power Law现象) P39
http://www.grouplens.org/node/73/
(MovieLens Dataset) P42
http://research.microsoft.com/pubs/69656/tr-98-12.pdf
(Empirical Analysis of Predictive Algorithms for Collaborative Filtering) P49
http://vimeo.com/1242909
(Digg Vedio) P50
http://glaros.dtc.umn.edu/gkhome/fetch/papers/itemrsCIKM01.pdf
(Evaluation of Item-Based Top-N Recommendation Algorithms) P58
http://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf
(Amazon.com Recommendations Item-to-Item Collaborative Filtering) P59
http://glinden.blogspot.com/2006/03/early-amazon-similarities.html
(Greg Linden Blog) P63
http://www.hpl.hp.com/techreports/2008/HPL-2008-48R1.pdf
(One-Class Collaborative Filtering) P67
http://en.wikipedia.org/wiki/Stochastic_gradient_descent
(Stochastic Gradient Descent) P68
http://www.ideal.ece.utexas.edu/seminar/LatentFactorModels.pdf
(Latent Factor Models for Web Recommender Systems) P70
http://en.wikipedia.org/wiki/Bipartite_graph
(Bipatite Graph) P73
http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=4072747&url=http%3A%2F%2Fieeexplore.ieee.org%2Fxpls%2Fabs_all.jsp%3Farnumber%3D4072747
(Random-Walk Computation of Similarities between Nodes of a Graph with Application to Collaborative Recommendation) P74
http://www-cs-students.stanford.edu/~taherh/papers/topic-sensitive-pagerank.pdf
(Topic Sensitive Pagerank) P74
http://www.stanford.edu/dept/ICME/docs/thesis/Li-2009.pdf
(FAST ALGORITHMS FOR SPARSE MATRIX INVERSE COMPUTATIONS) P77
https://www.aaai.org/ojs/index.php/aimagazine/article/view/1292
(LIFESTYLE FINDER: Intelligent User Profiling Using Large-Scale Demographic Data) P80
http://research.yahoo.com/files/wsdm266m-golbandi.pdf
( adaptive bootstrapping of recommender systems using decision trees) P87
http://en.wikipedia.org/wiki/Vector_space_model
(Vector Space Model) P90
http://tunedit.org/challenge/VLNetChallenge
(冷启动问题的比赛) P92
http://www.cs.princeton.edu/~blei/papers/BleiNgJordan2003.pdf
(Latent Dirichlet Allocation) P92
http://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
(Kullback–Leibler divergence) P93
http://www.pandora.com/about/mgp
(About The Music Genome Project) P94
http://en.wikipedia.org/wiki/List_of_Music_Genome_Project_attributes
(Pandora Music Genome Project Attributes) P94
http://www.jinni.com/movie-genome.html
(Jinni Movie Genome) P94
http://www.shilad.com/papers/tagsplanations_iui2009.pdf
(Tagsplanations: Explaining Recommendations Using Tags) P96
http://en.wikipedia.org/wiki/Tag_(metadata)
(Tag Wikipedia) P96
http://www.shilad.com/shilads_thesis.pdf
(Nurturing Tagging Communities) P100
http://www.stanford.edu/~morganya/research/chi2007-tagging.pdf
(Why We Tag: Motivations for Annotation in Mobile and Online Media ) P100
http://www.google.com/url?sa=t&rct=j&q=delicious%20dataset%20dai-larbor&source=web&cd=1&ved=0CFIQFjAA&url=http%3A%2F%2Fwww.dai-labor.de%2Fen%2Fcompetence_centers%2Firml%2Fdatasets%2F&ei=1R4JUKyFOKu0iQfKvazzCQ&usg=AFQjCNGuVzzKIKi3K2YFybxrCNxbtKqS4A&cad=rjt
(Delicious Dataset) P101
http://research.microsoft.com/pubs/73692/yihgoca-www06.pdf
(Finding Advertising Keywords on Web Pages) P118
http://www.kde.cs.uni-kassel.de/ws/rsdc08/
(基于标签的推荐系统比赛) P119
http://delab.csd.auth.gr/papers/recsys.pdf
(Tag recommendations based on tensor dimensionality reduction)P119
http://www.l3s.de/web/upload/documents/1/recSys09.pdf
(latent dirichlet allocation for tag recommendation) P119
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.94.5271&rep=rep1&type=pdf
(Folkrank: A ranking algorithm for folksonomies) P119
http://www.grouplens.org/system/files/tagommenders_numbered.pdf
(Tagommenders: Connecting Users to Items through Tags) P119
http://www.grouplens.org/system/files/group07-sen.pdf
(The Quest for Quality Tags) P120
http://2011.camrachallenge.com/
(Challenge on Context-aware Movie Recommendation) P123
http://bits.blogs.nytimes.com/2011/09/07/the-lifespan-of-a-link/
(The Lifespan of a link) P125
http://www0.cs.ucl.ac.uk/staff/l.capra/publications/lathia_sigir10.pdf
(Temporal Diversity in Recommender Systems) P129
http://staff.science.uva.nl/~kamps/ireval/papers/paper_14.pdf
(Evaluating Collaborative Filtering Over Time) P129
http://www.google.com/places/
(Hotpot) P139
http://www.readwriteweb.com/archives/google_launches_recommendation_engine_for_places.php
(Google Launches Hotpot, A Recommendation Engine for Places) P139
http://xavier.amatriain.net/pubs/GeolocatedRecommendations.pdf
(geolocated recommendations) P140
http://www.nytimes.com/interactive/2010/01/10/nyregion/20100110-netflix-map.html
(A Peek Into Netflix Queues) P141
http://www.cs.umd.edu/users/meesh/420/neighbor.pdf
(Distance Browsing in Spatial Databases1) P142
http://www.eng.auburn.edu/~weishinn/papers/MDM2010.pdf
(Efficient Evaluation of k-Range Nearest Neighbor Queries in Road Networks) P143
http://blog.nielsen.com/nielsenwire/consumer/global-advertising-consumers-trust-real-friends-and-virtual-strangers-the-most/
(Global Advertising: Consumers Trust Real Friends and Virtual Strangers the Most) P144
http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en//pubs/archive/36371.pdf
(Suggesting Friends Using the Implicit Social Graph) P145
http://blog.nielsen.com/nielsenwire/online_mobile/friends-frenemies-why-we-add-and-remove-facebook-friends/
(Friends & Frenemies: Why We Add and Remove Facebook Friends) P147
http://snap.stanford.edu/data/
(Stanford Large Network Dataset Collection) P149
http://www.dai-labor.de/camra2010/
(Workshop on Context-awareness in Retrieval and Recommendation) P151
http://www.comp.hkbu.edu.hk/~lichen/download/p245-yuan.pdf
(Factorization vs. Regularization: Fusing Heterogeneous
Social Relationships in Top-N Recommendation) P153
http://www.infoq.com/news/2009/06/Twitter-Architecture/
(Twitter, an Evolving Architecture) P154
http://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=0CGQQFjAB&url=http%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.165.3679%26rep%3Drep1%26type%3Dpdf&ei=dIIJUMzEE8WviQf5tNjcCQ&usg=AFQjCNGw2bHXJ6MdYpksL66bhUE8krS41w&sig2=5EcEDhRe9S5SQNNojWk7_Q
(Recommendations in taste related domains) P155
http://www.ercim.eu/publication/ws-proceedings/DelNoe02/RashmiSinha.pdf
(Comparing Recommendations Made by Online Systems and Friends) P155
http://techcrunch.com/2010/04/22/facebook-edgerank/
(EdgeRank: The Secret Sauce That Makes Facebook’s News Feed Tick) P157
http://www.grouplens.org/system/files/p217-chen.pdf
(Speak Little and Well: Recommending Conversations in Online Social Streams) P158
http://blog.linkedin.com/2008/04/11/learn-more-abou-2/
(Learn more about “People You May Know”) P160
http://domino.watson.ibm.com/cambridge/research.nsf/58bac2a2a6b05a1285256b30005b3953/8186a48526821924852576b300537839/$FILE/TR%202009.09%20Make%20New%20Frends.pdf
(“Make New Friends, but Keep the Old” – Recommending People on Social Networking Sites) P164
http://www.google.com.hk/url?sa=t&rct=j&q=social+recommendation+using+prob&source=web&cd=2&ved=0CFcQFjAB&url=http%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.141.465%26rep%3Drep1%26type%3Dpdf&ei=LY0JUJ7OL9GPiAfe8ZzyCQ&usg=AFQjCNH-xTUWrs9hkxTA8si5fztAdDAEng
(SoRec: Social Recommendation Using Probabilistic Matrix) P165
http://olivier.chapelle.cc/pub/DBN_www2009.pdf
(A Dynamic Bayesian Network Click Model for Web Search Ranking) P177
http://www.google.com.hk/url?sa=t&rct=j&q=online+learning+from+click+data+spnsored+search&source=web&cd=1&ved=0CFkQFjAA&url=http%3A%2F%2Fwww.research.yahoo.net%2Ffiles%2Fp227-ciaramita.pdf&ei=HY8JUJW8CrGuiQfpx-XyCQ&usg=AFQjCNE_CYbEs8DVo84V-0VXs5FeqaJ5GQ&cad=rjt
(Online Learning from Click Data for Sponsored Search) P177
http://www.cs.cmu.edu/~deepay/mywww/papers/www08-interaction.pdf
(Contextual Advertising by Combining Relevance with Click Feedback) P177
http://tech.hulu.com/blog/2011/09/19/recommendation-system/
(Hulu 推荐系统架构) P178
http://mymediaproject.codeplex.com/
(MyMedia Project) P178
http://www.grouplens.org/papers/pdf/www10_sarwar.pdf
(item-based collaborative filtering recommendation algorithms) P185
http://www.stanford.edu/~koutrika/Readings/res/Default/billsus98learning.pdf
(Learning Collaborative Information Filters) P186
http://sifter.org/~simon/journal/20061211.html
(Simon Funk Blog:Funk SVD) P187
http://courses.ischool.berkeley.edu/i290-dm/s11/SECURE/a1-koren.pdf
(Factor in the Neighbors: Scalable and Accurate Collaborative Filtering) P190
http://nlpr-web.ia.ac.cn/2009papers/gjhy/gh26.pdf
(Time-dependent Models in Collaborative Filtering based Recommender System) P193
http://sydney.edu.au/engineering/it/~josiah/lemma/kdd-fp074-koren.pdf
(Collaborative filtering with temporal dynamics) P193
http://en.wikipedia.org/wiki/Least_squares
(Least Squares Wikipedia) P195
http://www.mimuw.edu.pl/~paterek/ap_kdd.pdf
(Improving regularized singular value decomposition for collaborative filtering) P195
http://public.research.att.com/~volinsky/netflix/kdd08koren.pdf
(Factorization Meets the Neighborhood: a Multifaceted
Collaborative Filtering Model) P195